Cpp学习手册-进阶学习
C++标准库和C++20新特性
C++标准库概览:
核心库组件介绍:
容器:
C++ 标准库提供了多种容器,它们各有特点,适用于不同的应用场景。
-
std::vector:vector:动态数组,支持快速随机访问。#include <iostream> #include <vector>int main(){// vectorstd::vector<int> vec = {1,2,3,4,5};for (auto &item:vec) {item *= 2;}for (auto &item:vec) {std::cout << item << ' ';}return 0; }对于上面的代码我存在一些疑问:
-
auto有什么用:auto是一个类型说明符,它允许编译器自动推断变量的类型。就以上面这个为例:
auto &item:vec这里的vec是一个std::vector<int>对象,所以这里的item会被自动解析为int&类型。这表示item指向vec存储的某块内存的其中一个引用即指向当前元素的引用。使用引用的话,不需要重新复制元素,提高性能。
-
-
std::mapmap:存储键值对,基于红黑树实现。#include <map> int main(){// mapstd::map<std::string,int> mapList = {{"caiping",30},{"chengfeng",20}};// map 赋值mapList["qianwei"] = 24;// map 循环for (const auto &[key,value] : mapList) {std::cout << "key: " << key << " " << "value: " << value << std::endl;}return 0; }-
const auto &[key,value] : mapList是什么用法?有什么用?这里采取的是结构化绑定,
auto其实跟上面的用法一样,std::map<std::string,int> mapList这里的mapList是一个对象,它存储的是一个键值对,键是std::string类型,值是int类型。相当于这里的
auto &[key,value]拆分了mapList对象。这里的const的作用是它是一个修饰符,表示这里的引用是只读的,你不能通过它们修改原始数据。
-
-
std::list#include <list> // std::list int main(){std::list <int> intList = {1,2,3,4,5};// 这里的 it 代表的是迭代器,在这里指向的是第一个元素auto it = intList.begin();++it; // 即指向第二个元素intList.insert(it,10); // 在第二个位置插入 10std::cout << "origin: ";for(const auto& item:intList){std::cout << item << " ";}std::cout << std::endl;++it; // 移动到第二个元素intList.erase(it); std::cout << "after: ";for(const auto& item:intList){std::cout << item << " ";}return 0; }输出结果:
origin: 1 10 2 3 4 5 after: 1 10 2 4 5通过输出结果我们可以观察得出:
迭代器
it指向在开始的时候确实是指向第二个元素的即2, 然后我们插入了一个元素之后在2之前插入的10这也是正确的,但是我们发现我们再次执行++it之后去删除元素之后打印出来的结果发现3被删除了,并不是2被删除,表示it迭代器指向的还是之前的元素2的,然后执行++it之后,指向了3,所以删除的是3。 -
std::unordered_map#include <unordered_map>// unordered_map int main() {std::unordered_map<std::string, int> mapList = {{"apple", 3},{"banana", 5},{"orange", 2}};// 插入数据mapList["grape"] = 4;// 查找元素auto it = mapList.find("grape");if (it != mapList.end()) {std::cout << "Found grape: " << it->second << '\n';} else {std::cout << "grape not found\n";}// 遍历并打印所有元素for (const auto& [key, value] : mapList) {std::cout << key << ": " << value << '\n';}return 0; }输出结果:
grape not found orange: 2 banana: 5 grape: 4 apple: 3这里我们需要注意的是
it != mapList.end()这个判断为什么没有问题呢?我们find的grape不就是在最后一项吗?mapList.end()是一个尾后迭代器,不指向任何实际的元素,而是表示遍历的终点。it != mapList.end()用于检查find是否成功找到指定的键。无论"grape"在容器中的实际位置如何,只要find成功找到它,it就不会等于mapList.end()。std::unordered_map不保证任何特定的顺序,所以"grape"可能不在容器的 “最后” 位置。
这里因为使用的是迭代器所以使用的是
it->second用来指向value。 -
std::set#include <set> // std::set int main(){std::set<int> setList = {5, 3, 1, 4, 2};setList.insert(6);for(auto & item : setList){std::cout << item << " ";}return 0; }输出结果:
1 2 3 4 5 6 -
std::unordered_set#include <unordered_set> // std::unordered_set int main(){std::unordered_set<int> setList = {5, 3, 1, 4, 2};setList.insert(6);for(auto & item : setList){std::cout << item << " ";}return 0; }输出结果:
6 2 4 1 3 5对于
set和unordered_set来说最主要的特征是存储的元素都是唯一的,只是说set是有序的而unordered_set是无序的。
总结:
std::vector 基于动态数组构造,因此支持随机访问,并且因为是动态的所以会自动管理内存。
std::list 基于双向列表,插入和删除操作快,但不支持随机访问。
std::map 基于红黑树实现,按键排序,提供对数时间复杂度的查找、插入和删除。
std::unordered_map 基于哈希表实现,平均常数时间复杂度的查找、插入和删除。
std::set 基于红黑树实现,存储唯一元素并按顺序排列。
std::unordered_set 基于哈希表实现,存储唯一元素,无序。
算法:
std::sort:对范围内的元素进行排序。std::find:在范围内查找指定值。std::transform:将一个范围内的每个元素通过函数转换后存储到另一个范围。std::for_each:对范围内的每个元素应用一个函数。std::copy:将一个范围内的元素复制到另一个范围。std::remove:移除范围内的指定值(不会真正删除元素,而是移动到范围末尾)。
举例:
#include <algorithm>int main() {std::vector<int> vec = {5, 2, 9, 1, 7, 3, 8, 4, 6};// std::sortstd::sort(vec.begin(), vec.end());std::cout << "Sorted: ";for (auto &item: vec) {std::cout << item << " ";}std::cout << std::endl;// std::findauto it = std::find(vec.begin(), vec.end(), 7);if (it != vec.end()) {// std::distance(vec.begin(), it) 用于计算std::cout << "Found 7 at position: " << std::distance(vec.begin(), it) << std::endl;} else {std::cout << "7 not found" << std::endl;}// std::transform// 定义一个初始长度的动态数组std::vector<int> increase_vec(vec.size());std::transform(vec.begin(), vec.end(), increase_vec.begin(), [](int n) { return n + 2; });std::cout << "increased: ";for (auto & item: increase_vec) {std::cout << item << " ";}std::cout << std::endl;// std::for_eachstd::cout << "Printing each element: ";std::for_each(increase_vec.begin(),increase_vec.end(),[](int item){ std::cout << item << " ";});std::cout << std::endl;// std::copystd::vector<int> copy_vec;// std::back_inserter是用于创建一个特殊的输出迭代器。它可以被用来在容器的末尾添加元素,类似于调用容器的 push_back 方法。// 具体来说,std::back_inserter(copy_of_numbers) 实际上返回的是一个 std::back_insert_iterator 对象,// 这个对象重载了赋值操作符(operator=),使得每次向它赋值时都会调用目标容器的 push_back 方法来添加新的元素。std::copy(vec.begin(),vec.end(), std::back_inserter(copy_vec));std::cout << "Printing each element of copy_vec: ";std::for_each(copy_vec.begin(),copy_vec.end(),[](int item){ std::cout << item << " ";});std::cout << std::endl;// std::remove// 使用 std::remove 移除所有值为 3 的元素it = std::remove(copy_vec.begin(), copy_vec.end(), 3);// 注意:这不会改变容器的实际大小,需要手动调整大小或删除多余的元素copy_vec.erase(it, copy_vec.end()); // 删除从 it 到末尾的元素std::cout << "After removing 3: ";for (int num : copy_vec) std::cout << num << " ";std::cout << std::endl;return 0;
}
输出结果:
Sorted: 1 2 3 4 5 6 7 8 9
Found 7 at position: 6
increased: 3 4 5 6 7 8 9 10 11
Printing each element: 3 4 5 6 7 8 9 10 11
Printing each element of copy_vec: 1 2 3 4 5 6 7 8 9
After removing 3: 1 2 4 5 6 7 8 9
注意点:
这里 std::back_inserter 在我们 std::copy 的时候经常会配合使用,它对应的具体的一些补充上面代码注释也写了。
最后这个 std::remove 方法,虽然我们看到的确实做到了删除的效果,但它并不会真的做到删除的效果,实际上它并没有改变容器的大小,也没有释放内存。我现在举一个例子:比如说现在有一个容器 vec = {1, 2, 2, 3, 4, 5}; 在它调用remove方法之后,可能会改变容器的内容为 {1, 3, 4, 5, 2, 2} 或者 {1, 3, 4, 5, 2, 2} 中的任何一种排列,只要所有的 2 被移动到了末尾。it 会指向 5 后面的位置。所以为什么我们为什么在这里remove之后调用 erase 方法来删除 it 到向量末尾之间的所有元素。
智能指针:
C++11引入了智能指针来帮助管理动态分配的对象,从而避免内存泄漏和其他资源管理问题。
-
std::unique_ptr:独占所有权的智能指针,不能被复制,只能被移动。对于
std::unique_ptr使用场景:-
当你只需要一个对象的所有者时:
- 当你创建一个对象并且希望只有单一的所有者来管理它的生命周期时,可以使用
std::unique_ptr。这避免了多个所有者同时管理同一个对象导致的复杂性和潜在错误。
// 案例 1: 单一所有者 // 假设你有一个数据库连接对象,你希望在整个程序中只有一份这个连接对象,并且确保它在不再需要时被正确释放。 class DatabaseConnection { public:DatabaseConnection() { std::cout << "连接数据库...." << std::endl; }~ DatabaseConnection() { std::cout << "断开连接数据库...." << std::endl; } };void useDatabase(std::unique_ptr<DatabaseConnection> databaseConnection){std::cout << "使用数据库连接" << std::endl; }int main(){auto db = std::unique_ptr<DatabaseConnection>();// 这样就将连接对象转移到方法useDatabase身上了useDatabase(std::move(db));if(!db){std::cout << "连接对象已转移" << std::endl;}return 0; }输出结果:
使用数据库连接 连接对象已转移 - 当你创建一个对象并且希望只有单一的所有者来管理它的生命周期时,可以使用
-
在函数之间传递所有权,但不想复制对象:
- 当你需要将一个动态分配的对象从一个函数传递到另一个函数,并且不希望进行深拷贝(因为深拷贝可能会很昂贵),你可以使用
std::unique_ptr来转移所有权。这样,接收方会成为新的唯一所有者。
- 当你需要将一个动态分配的对象从一个函数传递到另一个函数,并且不希望进行深拷贝(因为深拷贝可能会很昂贵),你可以使用
-
作为类成员变量,自动管理类内部的资源:
- 当你的类需要管理一个动态分配的资源时,可以使用
std::unique_ptr作为成员变量。这样可以确保当类的对象被销毁时,资源会被自动释放,从而避免内存泄漏。
- 当你的类需要管理一个动态分配的资源时,可以使用
-
-
std::shared_ptr:共享所有权的智能指针,允许多个指针指向同一个对象,引用计数为零时释放对象。对于
std::shared_ptr使用场景:-
当你需要多个所有者共享同一个资源时:
- 当多个对象都需要访问同一个资源,并且每个对象都希望拥有该资源的所有权时,可以使用
std::shared_ptr。这样,只要有一个std::shared_ptr指向该资源,资源就不会被释放。
#include <thread>// 案例 1: 多个所有者共享同一个资源 // 假设你有一个日志记录器对象,多个线程或模块都需要访问这个日志记录器,并且每个线程或模块都希望拥有该日志记录器的所有权。 class Logger { public:void log(const string &message) {cout << "Log: " << message << "\n";} };void threadFunction(shared_ptr<Logger> logger, const string &message) {// 这里为什么不是使用.而是使用->的原因就在于我们这里的logger并不是一个对象实例而是一个智能指针,所以指针要调用对象的方法的话需要使用->logger->log(message); }int main() {auto logger = make_shared<Logger>();thread t1(threadFunction, logger, "Thread 1");thread t2(threadFunction, logger, "Thread 2");// 等待线程完成t1.join();t2.join();return 0; }输出结果:
Log: Thread 1 Log: Thread 2这里我发现会有可能出现其他情况的输出,我发现是因为并发导致的。
- 当多个对象都需要访问同一个资源,并且每个对象都希望拥有该资源的所有权时,可以使用
-
当资源的所有权需要在多个对象之间传递,而每个对象都需要访问该资源:
-
在某些情况下,资源的所有权可能需要在多个对象之间传递,但每个对象都需要访问该资源。
std::shared_ptr可以方便地实现这一点,因为复制std::shared_ptr会增加引用计数,确保资源不会过早释放。// 案例 2: 资源所有权在多个对象之间传递 // 假设你有一个图形库,其中包含多个图形对象(如 Circle 和 Rectangle),并且这些图形对象需要共享同一个绘图上下文(如 GraphicsContext)。 class GraphicsContext{ public:void draw(const std::string& shape){cout << "Drawing: " << shape << endl;} };class Shape { protected:shared_ptr<GraphicsContext> context; public:Shape(shared_ptr<GraphicsContext> context): context(context) {}virtual void draw() = 0; };class Circle : public Shape { public:// 其实这个语法就是将Circle的构造函数的ctx赋值给shape中的contextCircle(std::shared_ptr<GraphicsContext> ctx) : Shape(ctx) {}void draw() override {context->draw("Circle");} };class Rectangle : public Shape { public:Rectangle(std::shared_ptr<GraphicsContext> ctx) : Shape(ctx) {}void draw() override {context->draw("Rectangle");} };int main(){auto context = make_shared<GraphicsContext>();Circle circle(context);Rectangle rectangle(context);circle.draw();rectangle.draw();return 0; }输出结果:
Drawing: Circle Drawing: Rectangle
-
-
在复杂的对象图中,当多个对象需要引用同一个资源时:
-
在复杂的数据结构或对象图中,可能存在多个对象需要引用同一个资源的情况。使用
std::shared_ptr可以简化这些引用关系的管理,避免手动管理资源的生命周期。// 案例 3: 复杂对象图中的资源共享 // 假设你有一个树形结构,其中每个节点都包含一个共享的数据块,并且多个节点可能引用同一个数据块。 #include <vector> class DataBlock { public:int value;DataBlock(int val):value(val){} };class TreeNode { private:shared_ptr<DataBlock> data;vector<TreeNode> children;public:TreeNode(shared_ptr<DataBlock> d) :data(d){}void addChild(TreeNode child){children.push_back(child);}void printData() const {cout << "Data:" << data->value << endl;}void printChildrenData() const{for (const auto& item: children) {item.printData();}} };int main(){auto shareData = make_shared<DataBlock>(42);TreeNode root(shareData);TreeNode child1(shareData);TreeNode child2(shareData);root.addChild(child1);root.addChild(child2);root.printData();cout << "--------------------------" << endl;root.printChildrenData();return 0; }输出结果:
Data:42 -------------------------- Data:42 Data:42
-
-
-
std::weak_ptr:不控制对象生命周期的智能指针,用于解决循环引用问题。- 当你需要观察
std::shared_ptr所管理的对象,但不希望增加引用计数时:- 有时你需要观察一个由
std::shared_ptr管理的对象,但不想影响其生命周期。例如,在缓存或观察者模式中,你可能希望在对象仍然存在时访问它,但在对象被销毁后不再访问。
- 有时你需要观察一个由
- 解决
std::shared_ptr之间的循环引用问题:- 当两个或多个
std::shared_ptr相互引用时,可能会导致内存泄漏,因为每个std::shared_ptr都会增加其他std::shared_ptr的引用计数,从而永远不会释放资源。使用std::weak_ptr可以打破这种循环引用,确保资源能够被正确释放。
- 当两个或多个
- 在缓存或观察者模式中,当你需要检查对象是否仍然存在而不影响其生命周期时:
- 在某些设计模式中,如观察者模式或缓存机制,你可能需要存储对对象的弱引用,以便在需要时检查对象是否仍然存在。如果对象已经被销毁,你可以采取相应的措施(如删除缓存条目)。
- 当你需要观察
多线程:
C++11引入了多线程支持,包括线程创建、同步机制和异步任务处理。
-
<thread>:创建和管理线程。这个头文件提供了创建和管理线程的功能。你可以使用std::thread来创建一个新线程,并传递给它一个可调用对象(如函数、lambda表达式等)。当线程运行完毕后,可以使用join()方法等待线程结束,或者使用detach()方法让线程独立于创建它的线程执行。#include <iostream> #include <thread>void threadFuc(){std::cout << "Hello from a thread!" << std::endl; }// thread int main(){std::thread t(threadFuc);t.join(); // 等待线程t完成return 0; } -
<mutex>:互斥锁,用于保护共享数据。这个头文件提供了一系列的互斥锁类型,用于同步访问共享资源,防止数据竞争。std::mutex是最基本的一种互斥锁,而std::lock_guard或std::unique_lock是用于简化锁定/解锁过程的RAII风格的包装器。#include <mutex>std::mutex m; int shared_data = 0;void safe_increment() {std::lock_guard<std::mutex> lock(m); // 自动管理锁++shared_data; }int main(){std::thread t1(safe_increment), t2(safe_increment);t1.join();t2.join();std::cout << "Shared data: " << shared_data << std::endl;return 0; }这里最重要的是
std::lock_guard<std::mutex> lock(m);结合std::mutex m;使用。 -
<future>:异步计算的结果,可以通过std::async或std::promise来获取。这个头文件允许你进行异步计算,并且能够获取结果。
std::async是一个非常方便的工具,它可以启动一个异步任务,并返回一个std::future对象,该对象可以用来查询任务的状态或获取最终的结果。另外,std::promise和std::future一起工作,可以在不同的线程之间安全地传递结果。#include <future>int compute(int x) {return x * x; }int main() {std::future<int> result = std::async(compute, 5); // 异步调用computestd::cout << "Result: " << result.get() << std::endl; // 获取结果return 0; }
C++20新特性:
-
概念(Concepts):学习如何定义和使用约束来改进模板代码。
概念允许我们为模板参数指定更具体的约束条件。这不仅增加了代码的可读性,还帮助编译器在早期发现类型错误。
比如说我们可以定义一个整数类型的概念,在使用的时候直接通过定义好的这个类型并配合关键字
auto进行调用,如果传入是一个浮点数值,则会出现编译错误。 -
模块(Modules):探索模块化编程以提高构建效率和代码组织。
模块旨在替代传统的头文件机制,提供更好的封装性和更快的编译速度。
比如说我们可以创建一个包含数学方法的模块文件,通过
export将定义好的模块以及方法暴露出去,在我们程序中想要使用这个模块的内容时,使用import导入并直接调用对应的方法即可。 -
其他特性:
std::span:提供了对数组或容器的一段连续元素的轻量级视图。std::format:用于格式化字符串输出constexpr if:它允许在编译时根据常量表达式的值选择性地编译代码分支。
模板元编程、类型推导和 constexpr
模板元编程:
基础概念:
-
模板参数:可以是类型、非类型参数(如整数或指针)或模板。
比如说,
template<typename T, int N> class Array {}; -
特化:为特定类型的模板提供具体的实现。
比如说,
template<> class Array<int, 10> {}; -
偏特化:对模板的部分参数进行特化,通常用于类模板。
比如说,
template<typename T> class Array<T, 5> {};
这里只做一个简单的描述,后期会出详细的一些讲解。
泛型编程:
#include <iostream>template <typename T>
T max(T a, T b) {return (a > b) ? a : b;
}int main(){int a = 1;int b = 2;auto maxValue = max(a,b);std::cout << "max Value is " << maxValue << std::endl;return 0;
}
输出结果:
max Value is 2
类型推导:
-
auto:正确地使用
auto关键字简化变量声明。举个例子:
int main(){std::vector<int> numbers = {1,2,3,4,5,6};for (auto item: numbers) {std::cout << item << " ";}return 0; }在这里
auto允许编译器自动推断出变量的类型即item就是对应的int类型。 -
decltype:获取表达式的类型,并用于更复杂的类型推导。
int main(){int x = 5;const int& y = x;auto z1 = y; // 这里使用 auto 推导出来的 z1 的类型是 intdecltype(y) z2 = y; // 这里如果使用 decltype 推导出来的 z2 的类型是 const int & 类型return 0; }
constexpr:
-
常量表达式:编写可以在编译期求值的函数和变量。
-
编译期计算:利用
constexpr进行数学运算和其他计算,减少运行时开销。举例:
constexpr int square (int x) {return x * x; }constexpr int factorial(int n) {return (n <= 1) ? 1 : (n * factorial(n - 1)); }int main(){constexpr int result = square(5); // 编译时计算结果std::cout << "result: " << result << std::endl;constexpr int fact_5 = factorial(5); // 在编译时计算阶乘std::cout << "fact_5: " << fact_5 << std::endl;return 0; }输出结果:
result: 25 fact_5: 120
总结:
这一章节我们学会了进阶的 C++ 的理论知识。包括对一些核心库的内容介绍:容器、算法、智能指针、多线程等等。接着我们讲述了 C++20 新特性以及模板元编程、类型推导和 constexpr。接下来我会做一个实战来练习一下我们之前所学的内容,实现一个高性能数值计算库。
相关文章:

Cpp学习手册-进阶学习
C标准库和C20新特性 C标准库概览: 核心库组件介绍: 容器: C 标准库提供了多种容器,它们各有特点,适用于不同的应用场景。 std::vector: vector:动态数组,支持快速随机访问。 #in…...

代码随想录-字符串-反转字符串中的单词
题目 题解 法一:纯粹为了做出本题,暴力解 没有技巧全是感情 class Solution {public String reverseWords(String s) {//首先去除首尾空格s s.trim();String[] strs s.split("\\s");StringBuilder sb new StringBuilder();//定义一个公共的字符反转…...
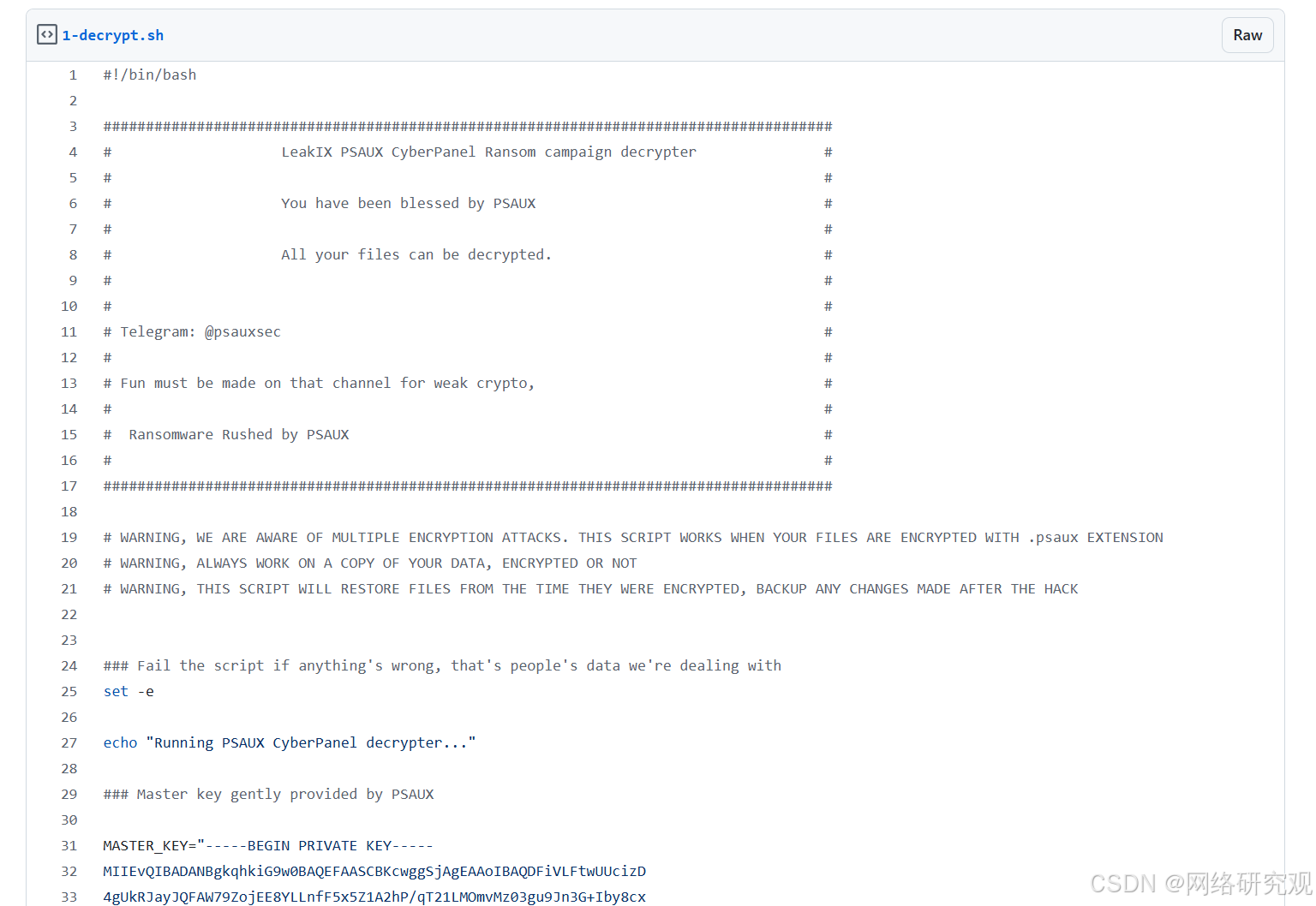
勒索软件通过易受攻击的 CyberPanel 实例攻击网络托管服务器
一个威胁行为者(或可能多个)使用 PSAUX 和其他勒索软件攻击了大约 22,000 个易受攻击的 CyberPanel 实例以及运行该实例的服务器上的加密文件。 PSAUX 赎金记录(来源:LeakIX) CyberPanel 漏洞 CyberPane…...

Open WebUI + openai API / vllm API ,实战部署教程
介绍Open WebUI + Ollama 的使用: https://www.dong-blog.fun/post/1796 介绍vllm 的使用:https://www.dong-blog.fun/post/1781 介绍 Ollama 的使用: https://www.dong-blog.fun/post/1797 本篇博客玩个花的,Open WebUI 本身可以兼容openai 的api, 那来尝试一下。 仅供…...

InsuranceclaimsController
目录 1、 InsuranceclaimsController 1.1、 保险理赔结算 1.2、 生成预约单号 1.3、 保存索赔表 InsuranceclaimsController using QXQPS.Models; using QXQPS.Vo; using System; using System.Collections; using System.Collections.Generic; using System.Li…...
如何成为开源代码库Dify的contributor:解决issue并提交PR
前言 Dify 是一个开源的大语言模型(LLM)应用开发平台,它融合了后端即服务(Backend as Service)和LLMOps的理念,旨在简化和加速生成式AI应用的创建和部署。Dify提供了一个用户友好的界面和一系列强大的工具…...
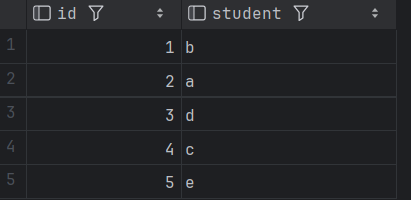
SQL进阶技巧:巧用异或运算解决经典换座位问题
目录 0 问题描述 1 数据准备 2 问题分析 2.1 什么是异或 2.2异或有什么特性? 2.3 异或应用 2.4 本问题采用异或SQL解决方案 3 小结 0 问题描述 表 seat中有2个字段id和student id 是该表的主键(唯一值)列,student表示学生姓名。 该表的每一行都表示学生的姓名和 ID。…...
进行监控)
【MySQL】 运维篇—数据库监控:使用MySQL内置工具(如SHOW命令、INFORMATION_SCHEMA)进行监控
随着应用程序的增长,数据库的性能和稳定性变得至关重要。监控数据库的状态和性能可以帮助数据库管理员(DBA)及时发现问题,进行故障排查,并优化数据库的运行效率。通过监控工具,DBA可以获取实时的性能指标、…...
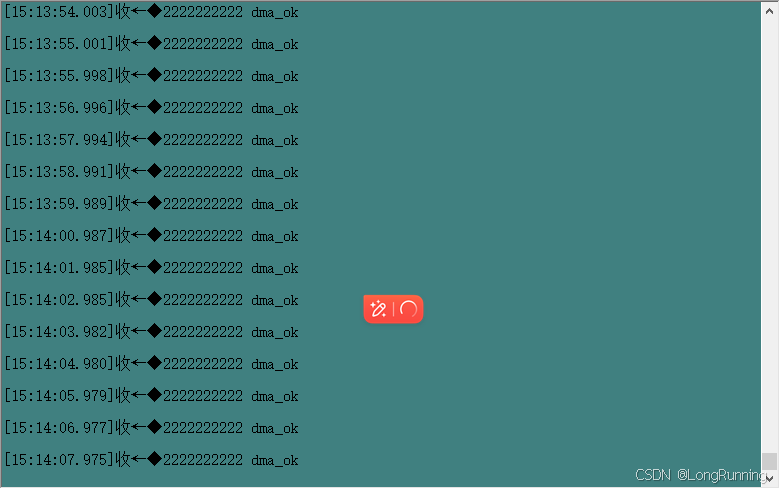
【温酒笔记】DMA
参考文档:野火STM32F103 1. Direct Memory Access-直接内存访问 DMA控制器独立于内核 是一个单独的外设 DMA1有7个通道DMA2有5个通道DMA有四个等级,非常高,高,中,低四个优先级如果优先等级相同,通道编号越…...

力扣判断字符是否唯一(位运算)
文章目录 给一个数n,判断它的二进制位中第x位是0还是1(从0开始计数)将一个数n的二进制位第X位修改为1(从0开始计数)将一个数n的二进制第x位修改为0(从0开始计数)提取一个数n二进制中最右侧的1去掉一个数n二进制表示中最右侧的1 今天我们通过判断字符是否唯一这个题来了解位运算…...
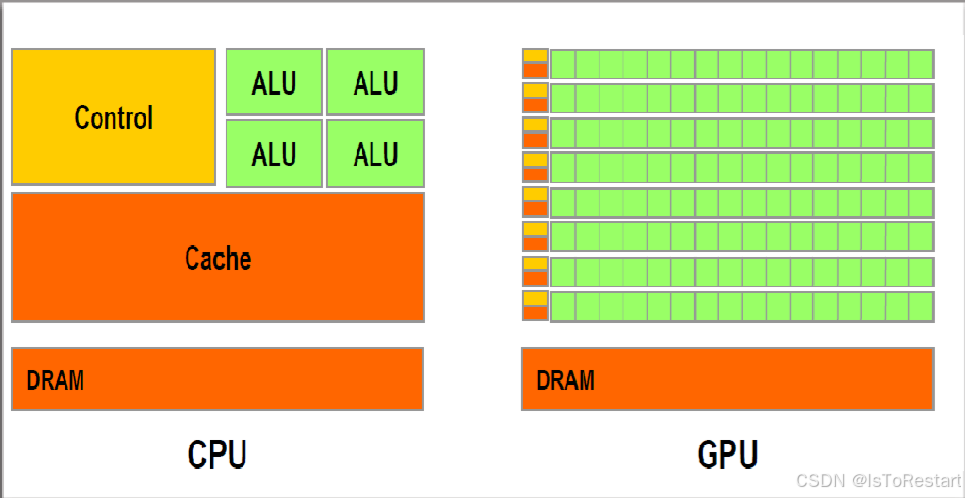
GPU和CPU区别?为什么挖矿、大模型都用GPU?
GPU(图形处理单元)和CPU(中央处理单元)是计算机中两种不同类型的处理器,它们在设计和功能上有很大的区别。 CPU是计算机的大脑,专门用于执行各种通用任务,如操作系统管理、数据处理、多任务处理等。它的架构设计旨在适应多种任务,…...
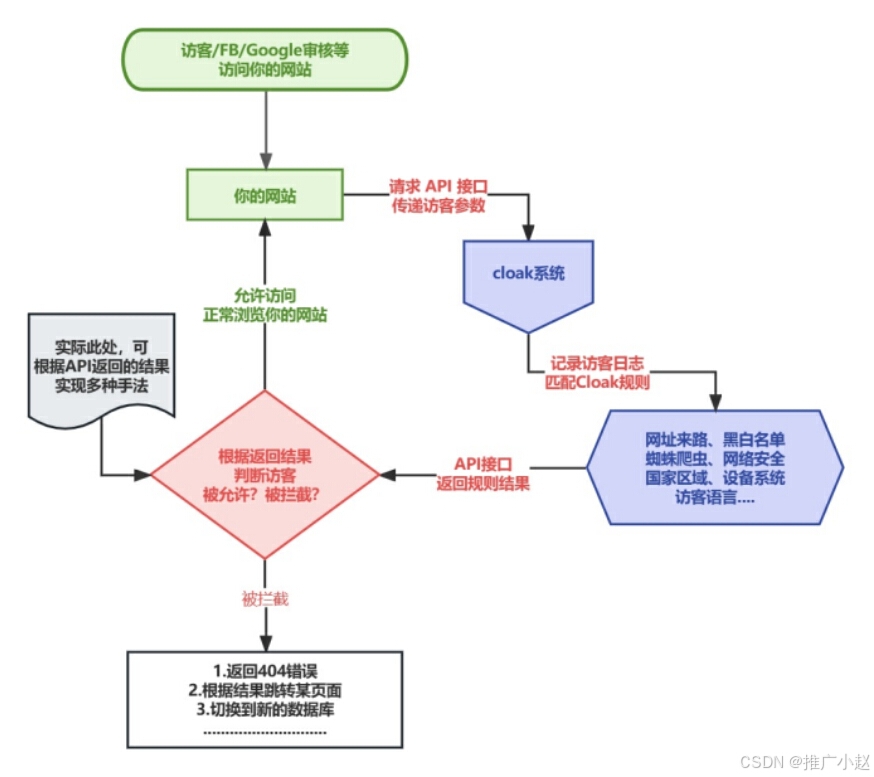
新兴斗篷cloak技术,你了解吗?
随着互联网技术的飞速发展,网络营销领域也经历了翻天覆地的变革。 从最早的网络横幅广告到如今主流的搜索引擎和社交媒体营销,广告形式变得越来越多样。 其中,搜索引擎广告一直以其精准投放而备受青睐,但近年来,一项名…...
:不变子群的几道例题)
【抽代复习笔记】34-群(二十八):不变子群的几道例题
例1:证明,交换群的任何子群都是不变子群。 证:设(G,o)是交换群,H≤G, 对任意的a∈G,显然都有aH {a o h|h∈H} {h o a|h∈H} Ha。 所以H⊿G。 【注:规范的不变子群符号是一个顶角指向左边…...
Chrome和Firefox如何保护用户的浏览数据
在当今数字化时代,保护用户的浏览数据变得尤为重要。浏览器作为我们日常上网的主要工具,其安全性直接关系到个人信息的保密性。本文将详细介绍Chrome和Firefox这两款主流浏览器如何通过一系列功能来保护用户的浏览数据。(本文由https://chrom…...

CentOS 7镜像下载
新版本系统镜像下载(当前最新是CentOS 7.4版本) CentOS官网 官网地址 http://isoredirect.centos.org/centos/7.4.1708/isos/x86_64/ http://mirror.centos.org/centos/7/isos/ 国内的华为云,超级快:https://mirrors.huaweiclou…...

opencv-windows-cmake-Mingw-w64,编译opencv源码
Windows_MinGW_64_OpenCV在线编译动态库,并使用在C项目: (mingw-w64 cmakegithub actions方案) 修改版opencv在线编译: 加入opencv-contrib库, 一起编译生成动态库,在线编译好的opencv动态库,可以下载使用.验证opencv动态库是否可用的模板项目,测试opencv动态库是否可用的模板…...

Puppeteer点击系统:解锁百度流量点击率提升的解决案例
在数字营销领域,流量和搜索引擎优化(SEO)是提升网站可见性的关键。我开发了一个基于Puppeteer的点击系统,旨在自动化地提升百度流量点击率。本文将介绍这个系统如何通过模拟真实用户行为,优化关键词排名,并…...
Kyber原理解析
Kyber是一种IND-CCA2安全的密钥封装机制。Kyber的安全性基于在模格(MLWE问题)中解决LWE问题的难度。Kyber的构造采⽤两阶段⽅法:⾸先介绍⼀种⽤来加密固定32字节⻓度的消息原⽂的IND-CPA安全性的公钥加密⽅案,我们称之为 CPAPKE&a…...
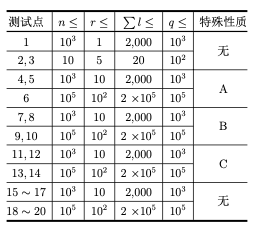
2024 CCF CSP-J/S 2024 第二轮认证 真题试卷
2024年信息学奥赛CSP-J2入门级复赛真题试卷 题目总数:4 总分数:400 编程题 第 1 题 问答题 扑克牌(poker) 【题目描述】 小 P 从同学小 Q 那儿借来一副 n 张牌的扑克牌。 本题中我们不考虑大小王,此时每张牌具有两个属性:花色和…...

Android 无障碍服务常见问题梳理
android 无障碍服务本意是为了帮助盲人操作手机而设计,但是现在也有人利用这个做自动化操作。 本片文章讲述的主要用作自动化方面。 官方文档 关于配置方法和接口列表,参考 无障碍 比较常用的接口: 1. 执行点击操作 2. 触摸屏幕…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...

掌握 HTTP 请求:理解 cURL GET 语法
cURL 是一个强大的命令行工具,用于发送 HTTP 请求和与 Web 服务器交互。在 Web 开发和测试中,cURL 经常用于发送 GET 请求来获取服务器资源。本文将详细介绍 cURL GET 请求的语法和使用方法。 一、cURL 基本概念 cURL 是 "Client URL" 的缩写…...