文件路径模块os.path
文件路径模块os.path
文章目录
- 文件路径模块os.path
- 1.概述
- 2.解析路径
- 2.1.拆分路径和文件名split
- 2.2.获取文件名称basename
- 2.3.返回路径第一部分dirname
- 2.4.扩展名称解析路径splitext
- 2.5.返回公共前缀路径commonprefix
- 3.创建路径
- 3.1.拼接路径join
- 3.2.获取家目录
- 3.3.规范化路径normpath
- 3.4.相对路径转化为绝对路径abspath
- 4.获取文件属性
- 5.测试文件
1.概述
这篇文章介绍与文件操作相关的路径操作模块,包含解析路径、建立路径、规范化路径等相关操作。
2.解析路径
2.1.拆分路径和文件名split
split函数用来将文件路径查分为两部分,路径和文件名。它返回一个tuple,这个tuple第一个元素是路径,第二个元素是路径的最后一个部分,通常是文件名称。
import os.pathPATHS = ['/one/two/three','/one/two/three/','/','.','',
]for path in PATHS:print('{!r:>17} : {}'.format(path, os.path.split(path)))
运行上面的代码,split函数默认通过 / 拆分文件路径,以最后一个/ 为分界线,左边的是路径,右边的是文件名称。
# 最后一个/右边有three,返回的元组中第二个元素为three
'/one/two/three' : ('/one/two', 'three')
# 最后一个/右边没有内容,返回的元组中第二个元素为空
'/one/two/three/' : ('/one/two/three', '')'/' : ('/', '')'.' : ('', '.')'' : ('', '')
2.2.获取文件名称basename
basename函数接收一个代表文件系统路径的类路径对象,返回一个代表指定路径基本名称的字符串值。它返回的值等价于split函数返回值的第二部分,他会将整个路径剔除到最后一个元素,如果最后一个元素是文件名称,则获取的就是一个文件名称。
import os.pathPATHS = ['/one/two/three','/one/two/three/','/','.','',
]for path in PATHS:print('{!r:>17} : {!r}'.format(path, os.path.basename(path)))运行上面的代码,返回值是路径中最后一个元素,这个元素也称为路径的基本名称。
# 冒号左边是完整路径,右边是拆分路径获取的值
'/one/two/three' : 'three'
'/one/two/three/' : '''/' : '''.' : '.''' : ''
2.3.返回路径第一部分dirname
dirname函数返回解析路径的第一部分,将basename的结果和dirname结果结合就可以得到原来的路径。
import os.pathPATHS = ['/one/two/three','/one/two/three/','/','.','',
]for path in PATHS:print('{!r:>17} : {!r}'.format(path, os.path.dirname(path)))运行结果
'/one/two/three' : '/one/two'
'/one/two/three/' : '/one/two/three''/' : '/''.' : '''' : ''
2.4.扩展名称解析路径splitext
splitext函数与split函数相似,不过它不是根据目录分隔符拆分路径,而是根据扩展名分隔符。
import os.pathPATHS = ['filename.txt','filename','/path/to/filename.txt','/','','my-archive.tar.gz','no-extension.',
]for path in PATHS:print('{!r:>21} : {!r}'.format(path, os.path.splitext(path)))
运行结果
'filename.txt' : ('filename', '.txt')'filename' : ('filename', '')
'/path/to/filename.txt' : ('/path/to/filename', '.txt')'/' : ('/', '')'' : ('', '')'my-archive.tar.gz' : ('my-archive.tar', '.gz')'no-extension.' : ('no-extension', '.')2.5.返回公共前缀路径commonprefix
commonprefix函数返回路径列表中最大公共前缀,这个值可能表示一个不存在的路径,而且并不考虑路径的分隔符,所以这个前缀可能并不落在一个分隔符边界上。
import os.pathpaths = ['/one/two/three/four','/one/two/threefold','/one/two/three/',]
for path in paths:print('PATH:', path)print()
print('PREFIX:', os.path.commonprefix(paths))
运行结果
PATH: /one/two/three/four
PATH: /one/two/threefold
PATH: /one/two/three/PREFIX: /one/two/three3.创建路径
3.1.拼接路径join
使用join将多个路径拼接成一个路径,如果要拼接的参数以分隔符开头 ,前面所有的参数都会丢弃,新参数会成为返回这的开始部分。
import os.pathPATHS = [('one', 'two', 'three'),('/', 'one', 'two', 'three'),('/one', '/two', '/three'),
]for parts in PATHS:print('{} : {!r}'.format(parts, os.path.join(*parts)))
结果
('one', 'two', 'three') : 'one/two/three'
('/', 'one', 'two', 'three') : '/one/two/three'
('/one', '/two', '/three') : '/three'
3.2.获取家目录
一般如果你自己使用系统的时候,是可以用~来代表"/home/你的名字/"这个路径的,但是python是不认识~这个符号的,如果你写路径的时候直接写"~/balabala",程序是跑不动的。
expanduser函数可以将~获取服务器家目录,方便我们访问或创建家目录后面的路径。如果用户的家目录找不到,字符串将不做任何改动,直接返回。
import os.pathfor user in ['', '/dhellmann', '/nosuchuser']:lookup = '~' + userprint('{!r:>15} : {!r}'.format(lookup, os.path.expanduser(lookup)))
运行结果
# /Users/edy 是当前服务器上的家目录'~' : '/Users/edy''~/dhellmann' : '/Users/edy/dhellmann''~/nosuchuser' : '/Users/edy/nosuchuser'3.3.规范化路径normpath
使用join函数或者添加单独字符串路径时,得到的路径可能会有多余的分隔符。使用normpath函数可以清除这些内容
import os.pathPATHS = ['one//two//three','one/./two/./three','one/../alt/two/three',
]for path in PATHS:print('{!r:>22} : {!r}'.format(path, os.path.normpath(path)))
运行结果
'one//two//three' : 'one/two/three''one/./two/./three' : 'one/two/three'
'one/../alt/two/three' : 'alt/two/three'
3.4.相对路径转化为绝对路径abspath
abspath函数的作用是将给定的文件路径转为绝对路径,例如下面的例子PATHS列表中给的是文件相对路径,然后在他们的前面拼接上当前工作目录,将他们转为绝对路径。而不是根据给定的一个文件或相对路径,去查找该文件的绝对路径。
import os
import os.pathos.chdir('/usr')PATHS = ['.','..','./one/two/three','../one/two/three',
]for path in PATHS:print('{!r:>21} : {!r}'.format(path, os.path.abspath(path)))
运行结果
# 获取当前的工作目录的绝对路径'.' : '/usr''..' : '/'# 相对路径拼接上当前工作目录,转为绝对路径'./one/two/three' : '/usr/one/two/three'
# 当前工作目录的上级目录拼接上相对路径,转为绝对路径'../one/two/three' : '/one/two/three'
4.获取文件属性
os.path除了操作路径,还可以获取文件属性。
import os.path
import time
# 获取文件的绝对路径
print('File :', __file__)
# 获取文件访问时间
print('Access time :', time.ctime(os.path.getatime(__file__)))
# 获取文件修改时间
print('Modified time:', time.ctime(os.path.getmtime(__file__)))
# 获取创建时间
print('Change time :', time.ctime(os.path.getctime(__file__)))
# 获取文件大小以字节为单位
print('Size :', os.path.getsize(__file__))
运行结果
# 获取文件的绝对路径
File : /Users/edy/create_path.py
# 获取文件访问时间
Access time : Mon Feb 13 14:38:26 2023
# 获取文件修改时间
Modified time: Mon Feb 13 14:38:26 2023
# 获取创建时间
Change time : Mon Feb 13 14:38:26 2023
# 获取文件大小以字节为单位
Size : 1338
5.测试文件
当程序遇到一个路径时,需要判断当前路径是一个文件,文件夹,还是一个链接,是否存在等,这些os.path提供了函数用来判断。
import os.pathFILENAMES = [__file__,os.path.dirname(__file__),'/','./broken_link',
]for file in FILENAMES:print('File : {!r}'.format(file))# 是否是绝对路径print('Absolute :', os.path.isabs(file))# 是否是文件print('Is File? :', os.path.isfile(file))# 是否是目录print('Is Dir? :', os.path.isdir(file))# 是否是一个链接print('Is Link? :', os.path.islink(file))# 是否是一个挂载点print('Mountpoint? :', os.path.ismount(file))# 判断文件是否存在print('Exists? :', os.path.exists(file))# 判断路径是否存在,如果存在,则返回 True;反之,返回 Falseprint('Link Exists?:', os.path.lexists(file))print()
运行结果
File : '/Users/edy/my_path'
Absolute : True
Is File? : False
Is Dir? : True
Is Link? : False
Mountpoint? : False
Exists? : True
Link Exists?: TrueFile : '/'
Absolute : True
Is File? : False
Is Dir? : True
Is Link? : False
Mountpoint? : True
Exists? : True
Link Exists?: TrueFile : './broken_link'
Absolute : False
Is File? : False
Is Dir? : False
Is Link? : False
Mountpoint? : False
Exists? : False
Link Exists?: False相关文章:

文件路径模块os.path
文件路径模块os.path 文章目录文件路径模块os.path1.概述2.解析路径2.1.拆分路径和文件名split2.2.获取文件名称basename2.3.返回路径第一部分dirname2.4.扩展名称解析路径splitext2.5.返回公共前缀路径commonprefix3.创建路径3.1.拼接路径join3.2.获取家目录3.3.规范化路径nor…...
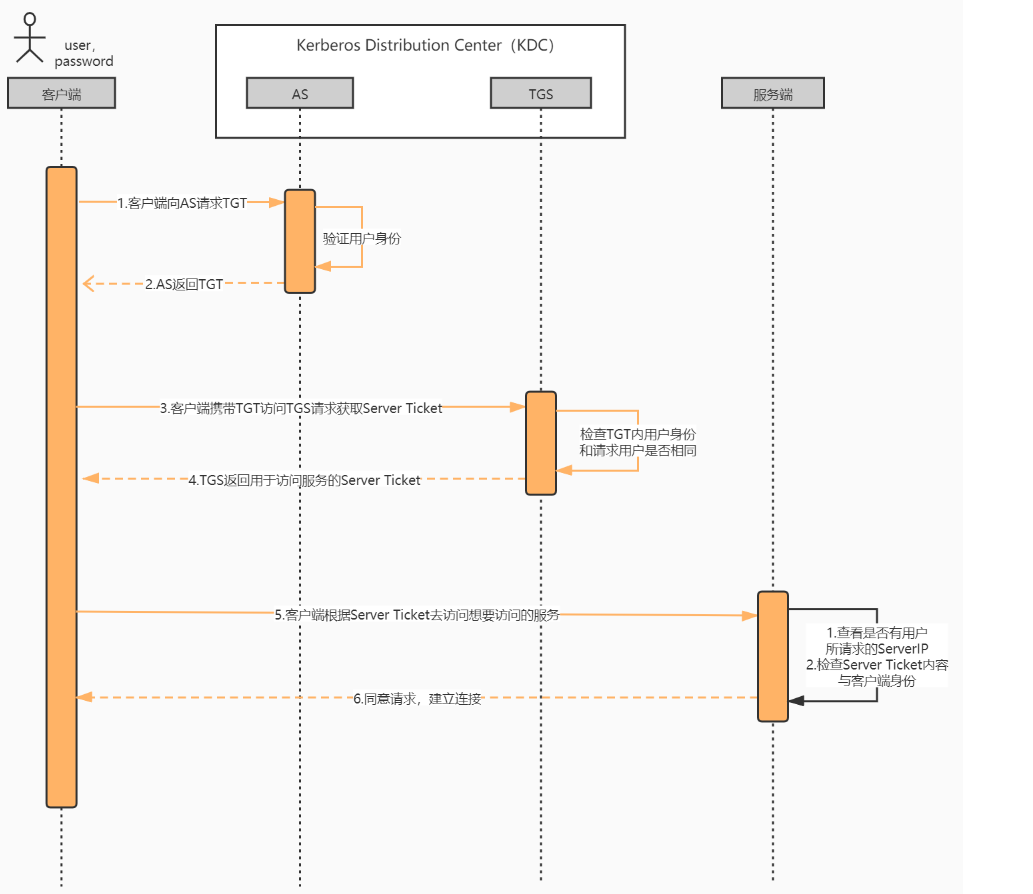
Kerberos简单介绍及使用
Kerberos作用 简单来说安全相关一般涉及以下方面:用户认证(Kerberos的作用)、用户授权、用户管理.。而Kerberos功能是用户认证,通俗来说解决了证明A是A 的问题。 认证过程(时序图) 核心角色/概念 KDC&…...

DOM编程-全选、全不选和反选
<!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>全选、全不选和反选</title> </head> <body bgcolor"antiquewhite"> <script type"text/jav…...

C++11可变模板参数
C11可变模板参数一、简介二、语法三、可变模版参数函数3.1、递归函数方式展开参数包3.2、逗号表达式展开参数包一、简介 C11的新特性–可变模版参数(variadic templates)是C11新增的最强大的特性之一,它对参数进行了高度泛化,它能…...

Linux多线程
目录 一、认识线程 1.1 线程概念 1.2 页表 1.3 线程的优缺点 1.3.1 优点 1.3.2 缺点 1.4 线程异常 二、进程 VS 线程 三、Linux线程控制 3.1 POSIX线程库 3.1 线程创建 3.3 线程等待 3.4 线程终止 3.4.1 return退出 3.4.2 pthread_exit() 3.4.3 pthread_cancel…...
Webpack5 环境下 Openlayers 标注(Icon) require 引入图片问题
Webpack5 环境下 Openlayers 标注(Icon) require 引入图片问题环境版本Openlayers 使用 require 问题Webpack5 正确配置构建新环境的时候,偶然发现 Openlayers 使用 require 的方式加载图片(Icon)报错,开始…...

Zookeeper安装部署
文章目录Zookeeper安装部署Zookeeper安装部署 将Zookeeper安装包解压缩, [rootlocalhost opt]# ll 总用量 14032 -rw-r--r--. 1 root root 12392394 10月 13 11:44 apache-zookeeper-3.6.0-bin.tar.gz drwxrwxr-x. 6 root root 4096 10月 18 01:44 redis-5.0.4 …...
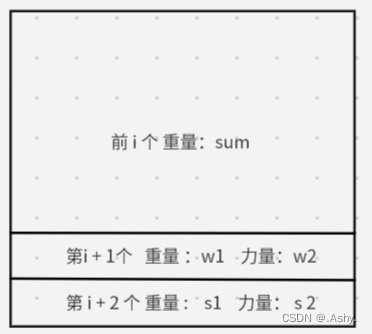
Cow Acrobats ( 临项交换贪心 )
题目大意: N 头牛 , 每头牛有一个重量(Weight)和一个力量(Strenth) , N头牛进行排列 , 第 i 头牛的风险值为其上所有牛总重减去自身力量 , 问如何排列可以使最大风险值最小 , 求出这个最小的最大风险值&am…...

MySQL:为什么说应该优先选择普通索引,尽量避免使用唯一索引
前言 在使用MySQL的过程中,随着表数据的逐渐增多,为了更快的查询我们需要的数据,我们会在表中建立不同类型的索引。 今天我们来聊一聊,普通索引和唯一索引的使用场景, 以及为什么说推荐大家优先使用普通索引…...

Spring Cloud alibaba之Feign
JAVA项目中如何实现接口调用?HttpclientHttpclient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持Http协议的客户端编程工具包,并且它支持HTTP协议最新版本和建议。HttpClient相比传统JDK自带的URL Connection&a…...
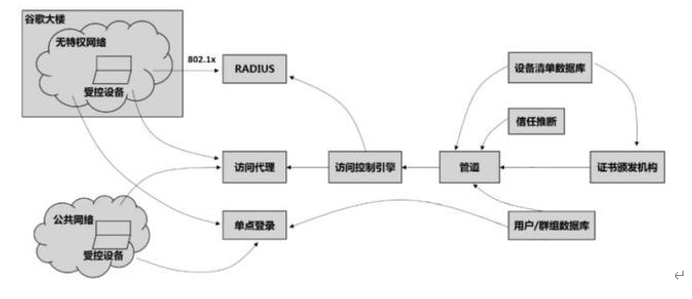
零信任-Google谷歌零信任介绍(3)
谷歌零信任的介绍? "Zero Trust" 是一种网络安全模型,旨在通过降低网络中的信任级别来防止安全威胁。在零信任模型中,不论请求来自内部网络还是外部网络,系统都将对所有请求进行详细的验证和审核。这意味着每次请求都需…...
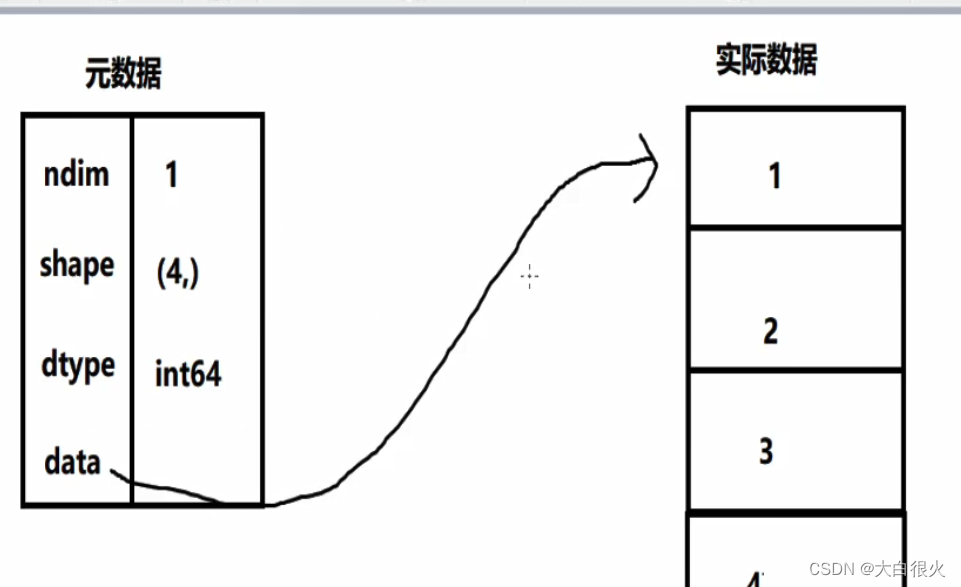
Numpy基础——人工智能基础
文章目录一、Numpy概述1.优势2.numpy历史3.Numpy的核心:多维数组4.numpy基础4.1 ndarray数组4.2 内存中的ndarray对象一、Numpy概述 1.优势 Numpy(Nummerical Python),补充了Python语言所欠缺的数值计算能力;Numpy是其它数据分析及机器学习库的底层库&…...

电商仓储与配送云仓是什么?
仓库是整个供给链的关键局部。它们是产品暂停和触摸的点,耗费空间和时间(工时)。空间和时间反过来也是费用。经过开发数学和计算机模型来微调仓库的规划和操作,经理能够显著降低与产品分销相关的劳动力本钱,进步仓库空间应用率,并…...

【零基础入门前端系列】—HTML介绍(一)
【零基础入门前端系列】—HTML介绍(一) 一、什么是HTML HTML是用来描述网页的一种语言HTML指的是超文本标记语言:HyperText Markup LanguageHTML不是一种编程语言,而是一种超文本标记语言,标记语言是一套标记标签(ma…...

Elasticsearch索引库和文档的相关操作
前言:最近一直在复习Elasticsearch相关的知识,公司搜索相关的技术用到了这个,用公司电脑配了环境,借鉴网上的课程进行了总结。希望能够加深自己的印象以及帮助到其他的小伙伴儿们😉😉。 如果文章有什么需要…...

使用Python,Opencv检测图像,视频中的猫
使用Python,Opencv检测图像,视频中的猫🐱 这篇博客将介绍如何使用Python,OpenCV库附带的默认Haar级联检测器来检测图像中的猫。同样的技术也可以应用于视频流。这些哈尔级联由约瑟夫豪斯(Joseph Howse)训练…...

浅谈域名和服务器集约化管理的误区
一个正常的网站通常由域名、网站程序、服务器三个部分组成,网站程序由单位开发设计,而域名和服务器则需要租用购买,那么域名和服务器之间的关系是什么?如何实现域名和服务器的有效管理呢? 服务器和域名的关系 服务器…...

迪赛智慧数——柱状图(正负条形图):20212022人才求职最关注的因素
效果图从近两年职场跳槽方向看,相比此前人们对高薪大厂趋之若鹜,如今职场人更关注业务前景。根据相关数据显示,职场人求职最关注的因素中,“薪资福利”权重下降,“个人发展”权重上升,“业务前景”首次进入…...

网络安全-黑帽白帽红客与网络安全法
网络安全-黑帽白帽红客与网络安全法 本章内容较少,因为刚开端。 黑客来源于hacker 指的是信息安全里面,能够自由出入对方系统,指的是擅长IT技术的电脑高手 黑帽黑客-坏蛋,研究木马的,找漏洞的,攻击网络或者…...

Xpath元素定位之同级节点,父节点,子节点
XPath学习:轴(8)——following-siblingXPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 同时被构建于 XPath 表达之上。推荐一个挺不错的网站:htt…...

OpenClaw学习助手:GLM-4.7-Flash自动整理网课字幕与生成思维导图
OpenClaw学习助手:GLM-4.7-Flash自动整理网课字幕与生成思维导图 1. 为什么需要自动化学习助手 作为一名经常通过网课充电的技术从业者,我长期被两个问题困扰:一是观看英文技术课程时,需要反复暂停视频手动整理中英对照笔记&…...

SenseVoice-small部署教程:Nginx反向代理+HTTPS加密访问WebUI安全配置
SenseVoice-small部署教程:Nginx反向代理HTTPS加密访问WebUI安全配置 1. 为什么需要安全配置? 当你把SenseVoice-small语音识别服务部署到服务器上,默认的访问方式是通过 http://服务器IP:7860 来使用。这种方式虽然简单,但存在…...

Windows 11界面改造终极方案:ExplorerPatcher完全指南
Windows 11界面改造终极方案:ExplorerPatcher完全指南 【免费下载链接】ExplorerPatcher 提升Windows操作系统下的工作环境 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 还在为Windows 11的现代界面感到困惑?ExplorerPatc…...

谷歌账号安全提示终极指南:为什么关闭插件就能登录?底层机制解析
谷歌账号安全机制深度解析:插件权限与登录拦截的底层逻辑 每次遇到谷歌账号登录被拦截的提示,大多数用户的第一反应是"换个浏览器试试"。但很少有人追问:为什么关闭插件就能解决问题?这背后涉及一套复杂的安全评估体系。…...

Jimeng AI Studio与IDEA集成:Java AI开发环境配置
Jimeng AI Studio与IDEA集成:Java AI开发环境配置 让Java开发者也能轻松玩转AI:5分钟搞定环境配置,快速开启智能应用开发 作为一名Java开发者,你可能已经习惯了在IntelliJ IDEA中编写代码、调试程序。但当想要尝试AI应用开发时&am…...

CosyVoice数据库应用实战:结合MySQL存储与管理海量语音资产
CosyVoice数据库应用实战:结合MySQL存储与管理海量语音资产 想象一下,你正在开发一个智能客服系统,每天需要为成千上万的用户生成个性化的语音回复。或者,你在做一个有声书平台,需要管理数万本图书的语音合成资产。很…...

【CDA干货】OpenClaw保姆级教程,3分钟高效搞定数据分析
2026 年初,一款被称为OpenClaw(俗称小龙虾)的AI工具火了。和只能提供建议的ChatGPT不同,OpenClaw被定义为个人AI智能体执行网关——它能直接操作你的电脑,执行文件整理、数据清洗、网页自动化等实际任务。对大多数职场…...

Linux 数据链路层
1.数据链路层的作用简单来说。TCP协议实现的是数据传输的可靠性,IP协议实现的是数据能跨主机送达目标主机的能力,数据链路层保证相邻的两台设备进行数据交互的问题。2.以太网以太网的帧格式如下所示:目的地址和源地址都是 mac 地址࿰…...

PID控制算法避坑指南:为什么你的自整定总震荡?5个调试技巧
PID控制算法避坑指南:为什么你的自整定总震荡?5个调试技巧 在工业自动化领域,PID控制算法就像一位经验丰富的舵手,默默掌控着无数设备的稳定运行。然而,这位"舵手"有时也会表现出令人头疼的脾气——要么反应…...

VSCode调试必备:快速添加项目根目录到PYTHONPATH的4种姿势
VSCode调试必备:快速添加项目根目录到PYTHONPATH的4种姿势 每次在VSCode中调试Python项目时,你是否遇到过"ModuleNotFoundError"的报错?这种问题往往源于Python解释器无法定位项目中的模块。作为Python开发者,我们经常需…...