Redis常见面试题(二)
Redis性能优化
Redis性能测试
阿里Redis性能优化
使用批量操作减少网络传输
Redis命令执行步骤:1、发送命令;2、命令排队;3、命令执行;4、返回结果。其中 1 与 4 消耗时间 --> Round Trip Time(RTT,往返时间),也就是数据在网络上传输的时间,使用批量操作大幅减少RTT。
实现:Lua脚本
Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作一条命令执行,可以看作是 原子操作 。也就是说,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰,Lua 脚本中支持一些简单的逻辑处理比如使用命令读取值并在 Lua 脚本中进行处理。
存在问题:
-
如果 Lua 脚本运行时出错并中途结束,之后的操作不会进行,但是之前已经发生的写操作不会撤销,所以即使使用了 Lua 脚本,也不能实现类似数据库回滚的原子性。
-
Redis Cluster 下 Lua 脚本的原子操作也无法保证了,原因同样是无法保证所有的 key 都在同一个 hash slot(哈希槽)上。
大量Key集中过期问题
Redsi采用定期删除 + 惰性 / 懒汉式删除策略
问题:如果遇到大量过期key的话,客户端请求必须等待定期清理过期key任务线程执行完成,因为定期删除任务是在Redis主线程中执行的,就导致客户端请求无法被及时处理。
解决方案:
- 给key设置随机过期时间。(建议)
- 惰性删除 / 延迟释放。采用异步方式延迟释放key使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
Redis bigKey(大Key)
概念:一个key的value所占的内存比较大,这个key就可以看作是bigkey。
大概标准:
- String类型的value不超过1MB
- 符合类型(List、Hash、Set、Sorted Set)不超过5000个
处理工具:
- redis-rdb-tools
- rdb_bigkeys
- 阿里云Redis分析
Redis hotKey(热Key)
概念:一个Key访问的次数明显多于其他Key,例如Redis实例每秒处理请求达5000次,其中一个key的每秒访问量就达2000次 --> hotKey
出现原因:某热点数据访问量暴涨(重大搜索事件、参与秒杀的商品)
导致问题:
- 占用大量CPU 和 带宽
- 如果访问突然访问的hotKey突然超出Redis的处理能力,Redis就会直接宕机,在此情况下,大量请求将落到后面的数据库上,导致数据库崩溃。
处理工具:
-
京东开源工具
-
阿里云Redis分析
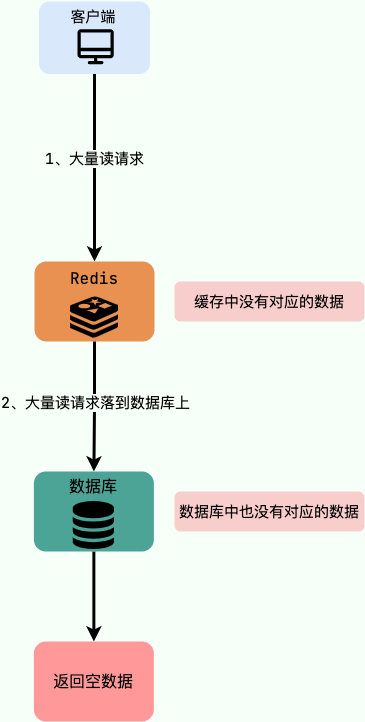
缓存穿透
概念:大量请求的Kye是不合理的,根本不存在与缓存中,也不存在于数据库中。就会导致这些请求直接到数据库上,根本没有经过缓存着一层,对数据库造成压力。
举个例子:某个黑客故意制造一些非法的 key 发起大量请求,导致大量请求落到数据库,结果数据库上也没有查到对应的数据。也就是说这些请求最终都落到了数据库上,对数据库造成了巨大的压力。
解决办法:参数校验
1. 布隆过滤器
目的:解决海量数据(缓存穿透、海量数据去重)
概念:二进制向量 / 位数组 和 一系列随机映射函数(哈希函数)两部分组成的数据结构。
特点:占用空间少效率高,但是返回的结果是概率性的,而不是非常准确,添加到集合中的元素越多,报错的可能性越大,并且放在布隆过滤器中的元素不容易删除。

Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1(代表 false 或者 true),这也是 Bloom Filter 节省内存的核心所在。这样来算的话,申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 KB ≈ 122KB 的空间。
原理:
- 当一个元素加入布隆过滤器中:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)
- 根据得到的哈希值,在位数组中把对应下标的值设置为1。
- 判断一个元素是否存在于布隆过滤器中:
- 对给定元素再次进行相同的哈希函数计算。
- 的到值之后判断位数组中的每个元素是否都为1,如果值都为1,那么说明这个值在布隆过滤器中,如果存在的值不为1,说明该元素不在布隆过滤器中。

使用场景:
- 判断给定数据是否存在:黑名单功能(判断一个IP或手机号码是否在黑名单中)、判断一个数字是否在搜索数据集中(数据集很大,上亿),防止缓存穿透(判断缓存中是否包含某个元素)。
- 去重:爬给定网站的时候对已经爬取过的URL去重、对巨量的QQ号/订单号去重。
实现:
- 一个合适大小的位数组保存数据
- 几个不同的哈希函数
- 添加元素到位数组(布隆过滤器)的方法实现
- 判断元素是否存在于位数组的方法实现
import java.util.BitSet;public class MyBloomFilter {/*** 位数组的大小*/private static final int DEFAULT_SIZE = 2 << 24;/*** 通过这个数组可以创建 6 个不同的哈希函数*/private static final int[] SEEDS = new int[]{3, 13, 46, 71, 91, 134};/*** 位数组。数组中的元素只能是 0 或者 1*/private BitSet bits = new BitSet(DEFAULT_SIZE);/*** 存放包含 hash 函数的类的数组*/private SimpleHash[] func = new SimpleHash[SEEDS.length];/*** 初始化多个包含 hash 函数的类的数组,每个类中的 hash 函数都不一样*/public MyBloomFilter() {// 初始化多个不同的 Hash 函数for (int i = 0; i < SEEDS.length; i++) {func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);}}/*** 添加元素到位数组*/public void add(Object value) {for (SimpleHash f : func) {bits.set(f.hash(value), true);}}/*** 判断指定元素是否存在于位数组*/public boolean contains(Object value) {boolean ret = true;for (SimpleHash f : func) {ret = ret && bits.get(f.hash(value));}return ret;}/*** 静态内部类。用于 hash 操作!*/public static class SimpleHash {private int cap;private int seed;public SimpleHash(int cap, int seed) {this.cap = cap;this.seed = seed;}/*** 计算 hash 值*/public int hash(Object value) {int h;return (value == null) ? 0 : Math.abs((cap - 1) & seed * ((h = value.hashCode()) ^ (h >>> 16)));}}
}
Redis中的布隆过滤器
使用Docker安装Redis中的布隆过滤器redis-stack
2. 接口限流
根据用户或者IP对接口限流,对于一场频繁访问的行为,采取黑名单机制,例如将异常IP列入黑名单。
缓存击穿和雪崩都可以配合接口限流来解决
分布式服务限流实战
缓存击穿
概念:请求的key对应的是热点数据,该数据存在于数据库中,但不存在于缓存中(缓存中的那份数据已经过期),瞬间大量的请求直接发送到数据库,对于数据库造成了巨大的压力,有可能会直接多请求宕机。
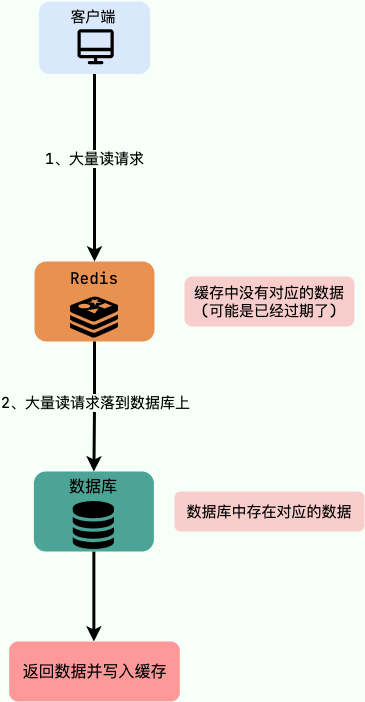
例子:秒杀进行过程中,缓存中的某个秒杀商品的数据突然过期,这就导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成了巨大的压力。
解决:
- 提前预热(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
- 加锁(看情况):在缓存失效后,通过设置互斥锁确保只有一个请求去查询数据库并更新缓存。
缓存穿透和缓存击穿有什么区别?
缓存穿透中,请求的 key 既不存在于缓存中,也不存在于数据库中。
缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期) 。
缓存雪崩
概念:缓存在同一时间大面积的失效,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力
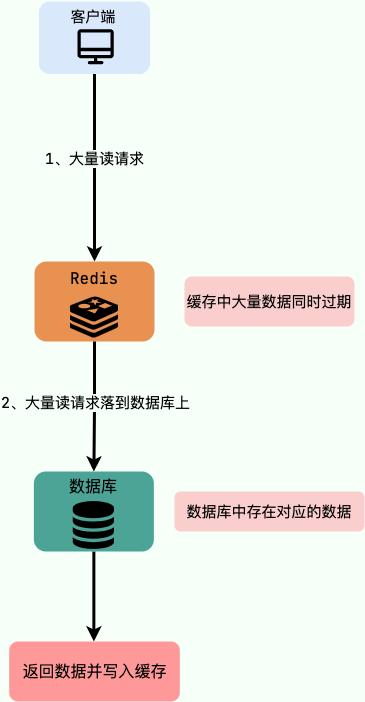
例子:数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
解决:
针对 Redis 服务不可用的情况:
- Redis 集群:采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。Redis Cluster 和 Redis Sentinel 是两种最常用的 Redis 集群实现方案。
- 多级缓存:设置多级缓存,例如本地缓存 + Redis 缓存的二级缓存组合,当 Redis 缓存出现问题时,还可以从本地缓存中获取到部分数据。
针对大量缓存同时失效的情况:
- 设置随机失效时间(可选):为缓存设置随机的失效时间,例如在固定过期时间的基础上加上一个随机值,这样可以避免大量缓存同时到期,从而减少缓存雪崩的风险。
- 提前预热(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
- 持久缓存策略(看情况):虽然一般不推荐设置缓存永不过期,但对于某些关键性和变化不频繁的数据,可以考虑这种策略。
缓存预热如何实现?
常见的缓存预热方式有两种:
- 使用定时任务,比如 xxl-job,来定时触发缓存预热的逻辑,将数据库中的热点数据查询出来并存入缓存中。
- 使用消息队列,比如 Kafka,来异步地进行缓存预热,将数据库中的热点数据的主键或者 ID 发送到消息队列中,然后由缓存服务消费消息队列中的数据,根据主键或者 ID 查询数据库并更新缓存。
缓存雪崩和缓存击穿有什么区别?
缓存雪崩和缓存击穿比较像,但缓存雪崩导致的原因是缓存中的大量或者所有数据失效,缓存击穿导致的原因主要是某个热点数据不存在与缓存中(通常是因为缓存中的那份数据已经过期)。
Redis集群面试题
Redis Sentinel:
- 什么是 Sentinel? 有什么用?
- Sentinel 如何检测节点是否下线?主观下线与客观下线的区别?
- Sentinel 是如何实现故障转移的?
- 为什么建议部署多个 sentinel 节点(哨兵集群)?
- Sentinel 如何选择出新的 master(选举机制)?
- 如何从 Sentinel 集群中选择出 Leader ?
- Sentinel 可以防止脑裂吗?
Redis Cluster:
- 为什么需要 Redis Cluster?解决了什么问题?有什么优势?
- Redis Cluster 是如何分片的?
- 为什么 Redis Cluster 的哈希槽是 16384 个?
- 如何确定给定 key 的应该分布到哪个哈希槽中?
- Redis Cluster 支持重新分配哈希槽吗?
- Redis Cluster 扩容缩容期间可以提供服务吗?
- Redis Cluster 中的节点是怎么进行通信的?
相关文章:
Redis常见面试题(二)
Redis性能优化 Redis性能测试 阿里Redis性能优化 使用批量操作减少网络传输 Redis命令执行步骤:1、发送命令;2、命令排队;3、命令执行;4、返回结果。其中 1 与 4 消耗时间 --> Round Trip Time(RTT,…...
业务模块部署
一、部署前端 1.1 window部署 下载业务模块前端包。 (此包为耐威迪公司发布,请联系耐威迪客服或售后获得) 包名为:业务-xxxx-business (注:xxxx为发布版本号) 此文件部署位置为:……...

【LeetCode】【算法】48. 旋转图像
LeetCode 48. 旋转图像 题目描述 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 思路 思路:再次拜见K神…...

【STM32F1】——9轴姿态模块JY901与串口通信(上)
【STM32F1】——9轴姿态模块JY901与串口通信(上) 一、简介 本篇主要对调试JY901模块的过程进行总结,实现了以下功能。 串口普通收发:使用STM32F103C8T6的USART2实现9轴姿态模块JY901串口数据的读取,并利用USART1发送到串口助手。 串口DMA收发:使用STM32F103C8T6的USART…...

Docker网络概述
1. Docker 网络概述 1.1 网络组件 Docker网络的核心组件包括网络驱动程序、网络、容器以及IP地址管理(IPAM)。这些组件共同工作,为容器提供网络连接和通信能力。 网络驱动程序:Docker支持多种网络驱动程序,每种驱动程…...

Vite与Vue Cli的区别与详解
它们的功能非常相似,都是提供基本项目脚手架和开发服务器的构建工具。 主要区别 Vite在开发环境下基于浏览器原生ES6 Modules提供功能支持,在生产环境下基于Rollup打包; Vue Cli不区分环境,都是基于Webpack。 在生产环境下&…...

深究JS底层原理
一、JS中八种数据类型判断方法 在JavaScript中,数据类型分为两大类:基本(原始)数据类型和引用(对象)数据类型。 基本数据类型(Primitive Data Types) 基本数据类型是表示简单的数…...

数据分析-41-时间序列预测之机器学习方法XGBoost
文章目录 1 时间序列1.1 时间序列特点1.1.1 原始信号1.1.2 趋势1.1.3 季节性和周期性1.1.4 噪声1.2 时间序列预测方法1.2.1 统计方法1.2.2 机器学习方法1.2.3 深度学习方法2 XGBoost2.1 模拟数据2.2 生成滞后特征2.3 切分训练集和测试集2.4 封装专用格式2.5 模型训练和预测3 参…...

json转java对象 1.文件读取为String 2.String转为JSONObject 3.JSONObject转为Class
一.参考王广帅的 服务器起服时的加载 private void readConfigFile(String configDir, Class<?> clazz) throws Exception {String fileName getConfigFileName(clazz);File configFile new File(configDir, fileName);// 读取所有的行,因此,应…...

基于卷积神经网络的农作物病虫害识别系统(pytorch框架,python源码)
更多图像分类、图像识别、目标检测等项目可从主页查看 功能演示: 基于卷积神经网络的农作物病虫害检测(pytorch框架)_哔哩哔哩_bilibili (一)简介 基于卷积神经网络的农作物病虫害识别系统是在pytorch框架下实现的…...
ETLCloud异常问题分析ai功能
在数据处理和集成的过程中,异常问题的发生往往会对业务运营造成显著影响。为了提高ETL(提取、转换、加载)流程的稳定性与效率,ETLCloud推出了智能异常问题分析AI功能。这一创新工具旨在实时监测数据流动中的潜在异常,自…...

【1】 Kafka快速入门-从原理到实践
文章目录 🔍 一、引言📜 二、Kafka 的历史🏗️ 三、Kafka 的核心结构🖥️ (一)Broker📋 (二)Topic📄 (三)Partition📤 (四)Producer📥 (五)Consumer🐒 (六)Zookeeper💡 四、Kafka 的重点概念📨 (一)消息📏 (二)偏移量(Offset)🔄 (…...

go语言中的map类型详解
在Go语言中,map是一种内建的数据结构,提供了键值对(key-value)的存储方式。map通常用于实现快速的查找和关联数组,适合在需要根据键来高效查找值的场景下使用。 基本概念 map是一个无序的集合,它存储了键…...

GBase 8a MPP Cluster V9安装部署
GBase 8a MPP Cluster V9安装部署 安装环境准备 节点角色操作系统地址配置GBASE版本gbase01.gbase.cnGCWARE,COOR,DATACentOS 7.9192.168.20.1422C4GGBase 8a MPP Cluster V9 9.5.3.28.12gbase02.gbase.cnGCWARE,COOR,DATACentOS 7.9192.168.20.1432C4GGBase 8a MPP Cluster …...

静态库、动态库、framework、xcframework、use_frameworks!的作用、关联核心SDK工程和测试(主)工程、设备CPU架构
1.1库的概念 库:程序代码的集合,编译好的二进制文件加上头文件供使用,共享程序代码的一种方式。 1.2库的分类 根据开源情况分为:开源库(能看到具体实现)、闭源库(只公开调用的的接口…...

C++ | Leetcode C++题解之第552题学生出勤记录II
题目: 题解: class Solution { public:static constexpr int MOD 1000000007;vector<vector<long>> pow(vector<vector<long>> mat, int n) {vector<vector<long>> ret {{1, 0, 0, 0, 0, 0}};while (n > 0) {…...

网站架构知识之Ansible(day020)
1.Ansible架构 Inventory 主机清单:被管理主机的ip列表,分类 ad-hoc模式: 命令行批量管理(使用ans模块),临时任务 playbook 剧本模式: 类似于把操作写出脚本,可以重复运行这个脚本 2.修改配置 配置文件:/etc/ansible/ansible.cfg 修改配置文件关闭主机Host_key…...

K8s使用nfs
改动点 ip和路径改为自己的 --- apiVersion: v1 kind: ServiceAccount metadata:name: nfs-client-provisioner# replace with namespace where provisioner is deployednamespace: nfs-client --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata:nam…...

【大数据学习 | kafka高级部分】kafka的kraft集群
首先我们分析一下zookeeper在kafka中的作用 zookeeper可以实现controller的选举,并且记录topic和partition的元数据信息,帮助多个broker同步数据信息。 在新版本中的kraft模式中可以这个管理和选举可以用kafka自己完成,而不再依赖zookeeper。…...

爬虫策略规避:Python爬虫的浏览器自动化
网络爬虫作为一种自动化获取网页数据的技术,被广泛应用于数据挖掘、市场分析、竞争情报等领域。然而,随着反爬虫技术的不断进步,简单的爬虫程序往往难以突破网站的反爬虫策略。因此,采用更高级的爬虫策略,如浏览器自动…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...