京东零售推荐系统可解释能力详解
作者:智能平台 张颖
本文导读
本文将介绍可解释能力在京东零售推荐系统中的应用实践。主要内容包括以下几大部分:推荐系统可解释定义、系统架构、排序可解释、模型可解释、流量可解释。
推荐系统可解释定义
推荐系统可解释的核心包括三部分,即排序可解释、模型可解释、流量可解释。
-
排序可解释:即解释推荐系统的排序结果。推荐系统一般会包括召回、排序、策略等主要节点,排序可解释会详细记录物料从召回到过滤、排序、策略等各个阶段的流转,这些数据将作为可解释的基石。
-
模型可解释:即解释推荐系统的模型结果。目前大多数推荐系统的模型都是黑盒模型,但已有相关技术来解释这些黑盒模型,从特征的角度解释模型对某些SKU得分高低的根因。
-
流量可解释:即解释推荐系统的流量结果。主要是从整体流量的角度解释商品的差异。比如某些尾部SKU是从推荐系统的哪个阶段被过滤掉的,是不是从来就没有被召回过,如果没有被召回,那么召回引擎是否需要升级?此外,在排查一些问题的时候,我们经常需要拿到用户的一些行为,假如我们拿到所有用户的所有埋点数据进行分析,那么是不是能得到一个用户行为模型,利用这个模型去分析用户行为,发现用户行为的热点和阻塞点是更加有意义的。
具体来看排序可解释,下图左侧是推荐系统里常见的四大模块,几乎每个推荐系统都必须有这些模块或者是这些模块的变种。

整个推荐系统是一个非常长的链路,出现的bad case多种多样。
-
最常见的是推荐有无问题,也就是为什么给我推或不推某个商品,比如我是一个男生,对美妆类商品不感兴趣,也从来没有过相关行为,但是为什么总是给我推荐美妆类的产品?又比如,我想买一块智能手表,因此搜索了智能手表,我的购买习惯一般都是先搜索一下,然后再看看给我推荐的相关商品,综合来看买哪个商品,但是这次不知道为什么没有给我推智能手表。这些都属于推荐有无的问题。
-
相似推荐问题,比如一次下拉推荐了很多相同或者相似的商品。
-
推荐场景问题,比如在情人节给我推荐了花圈,这个问题在后面还会有详细展示。
-
复购周期问题,比如生鲜食品和电器类产品的复购周期肯定是不一样的,因此,短期内给我推荐已经购买的生鲜食品等是没问题的,但是短期内给我推荐已购的电器类商品就会有些问题了。
-
推荐排序问题,比如为什么给我推荐的商品排序是 ABCDE 而不是 EDCAB。
推荐系统中可能遇到的问题远不止这些。
再来看一下模型可解释,还是从遇到的问题出发来解释什么是模型可解释。

如上图中所示,这里主要是解决模型推荐相关的一些问题,推荐系统的“rank”模块,包括粗排、精排、重排,还有EE都算是模型可解释的一部分。
模型可解释分为局部可解释和全局可解释。比如面对一个模型,提问“你认为猫有什么特征”,这种类似全局画像的问题就称为全局可解释;而如果问“你为什么觉得这个图片是只猫”,这种问题就称为局部可解释,因为这个对于模型来说是一个个例。
局部可解释在电商场景的应用主要有下面这些场景,比如为什么模型给我的排序中该SKU得分最高,为什么某个SKU的竞争力比其它相同品类/产品词高,成为头部商品,当然这里的竞争力需要局限到模型的维度,再比如为什么我没有相关类目的行为,但是模型打分对这类SKU较高,这些问题都可以认为是局部可解释在电商场景下的应用。
全局可解释的一个常见场景就是解释输入给模型的上千维特征的必要性,有没有一些边际效应或者是具有重复效用的特征,这些问题都可以用全局可解释来解决。
系统架构
在介绍可解释系统的架构之前,先来分析一下可解释系统的难点。
-
量极大。推荐系统量级是非常大的,整个召回、排序、策略链路复杂且单条数据量非常大,很容易达到天级PB级的增长,这对整个数据链路都是一个巨大的挑战。
-
治理难。整个链路中数据非常混乱,推荐系统通常由多个团队共同负责,大家的日志和代码会有不同的标准,因此我们常遇到的一个问题就是日志不统一,导致上报内容杂乱,稍微不谨慎就会造成识别失败这种问题。其次,模型也是非常复杂的,整个数据链路复用困难。
场景多。可解释系统面临的场景众多,比如召回分析、策略分析,以及模型分析等,对系统的数据质量和灵活性有很高要求。
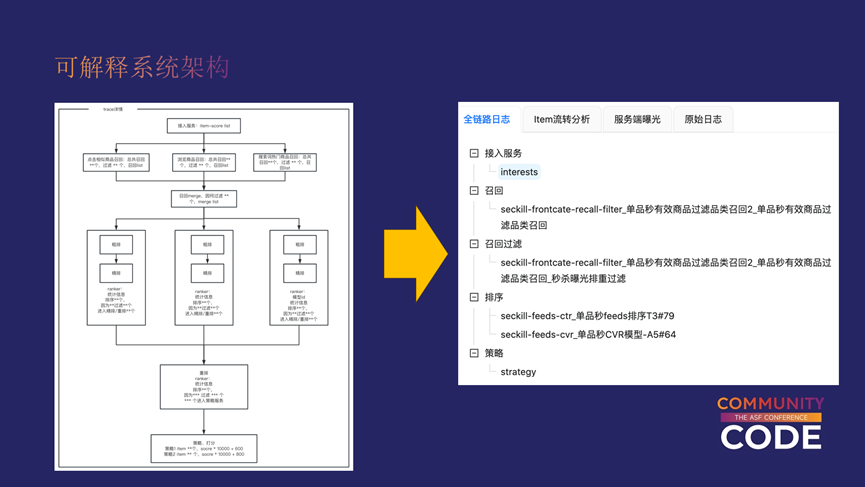
上图左侧是一个简单的推荐系统的变形,从用户使用的角度描绘了用户的一次刷新在推荐系统里面所经过的过程。用户刷新时,首先会触发一个称为“接入服务”的模块,这一模块起到了串接流程的作用,首先会调用召回服务对商品进行召回,比如我们可以进行行为召回,这些比较精确的就是点击商品的相似商品召回,再比如浏览商品召回,或是搜索词下的热门商品召回等等。召回之后,为了保证接下来排序阶段的性能,一般会进行过滤和截断,经过粗排对数据进行初筛,接下来把数据灌入精排,精排之后一般会把数据汇总之后写入重排,重排其实就相当于是策略的一种了,重排和EE都可以类比为策略。
可解释系统的本质就是把图中链路透明化,变得可观测,也就是推荐系统的白盒化。右侧图是在我们系统中推荐系统白盒化的一个简单示例,图中可以看到,针对左图那些关键节点都有相应的聚合。
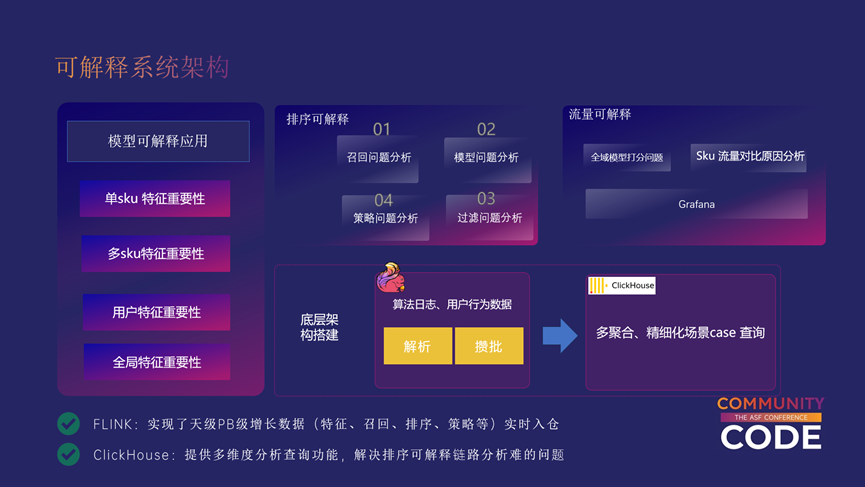
整个可解释系统的底层是由Flink和ClickHouse来处理的,其中Flink主要负责实现天级PB级的模块数据实时入仓,包括特征、召回、排序、策略等链路。ClickHouse 主要提供多维的分析查询功能,帮助我们解决可解释链路分析的问题。
基于这些数据链路,我们在上游构建了排序可解释和流量可解释链路,排序可解释主要解决推荐系统排序的一些问题,包括但不限于召回问题的分析、模型问题的分析、策略问题的分析以及过滤问题的分析等。针对流量可解释,我们搭建了一些指标监控,目前还在建设完善中,目前完成了全域模型打分问题的监控和SKU流量差异的原因分析,这主要实现的是一个全域的漏斗。
可解释系统中模型的可解释也是不可或缺的,模型可解释虽然是一个成熟的技术,但是在电商领域的应用并不多。我们创新性地引入了电商场景下几个场景的问题,这些问题如果没有模型可解释技术的引入其实是很难有说服力的,比如SKU特征重要性、用户特征重要性等等。
排序可解释
接下来将从以下几个方面详细介绍排序可解释:trace链路的推荐物料可解释,debug链路的推荐物料可解释,以及推荐系统排查问题必不可少的用户画像、行为画像和商品画像。
Trace链路的推荐物料可解释
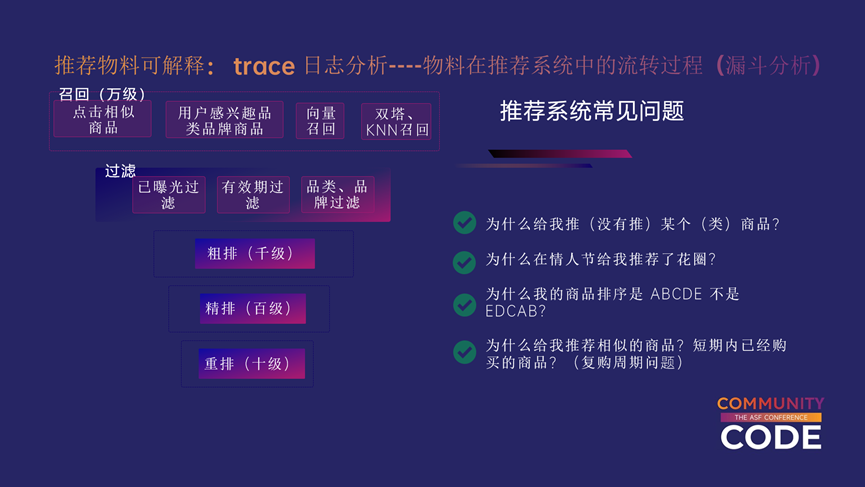
整个推荐系统主要包括召回、过滤、粗排、精排和重排等几个链路。其中召回是要从亿级的底池里面挑选出万级的商品;召回过滤之后是粗排,粗排是将召回万级的数据截取到千级,传给精排;精排是推荐系统中最重要的一部分,主要是从千级的符合用户的商品里面挑选出百级的商品供给后续模块做策略;策略模块会将百级的商品做到十级。
推荐系统常见问题,比如为什么给我推(没有推)某个(类)商品,为什么在情人节给我推荐了花圈,这些问题都可以通过可解释系统解决。

针对trace级别的可解释,我们主要通过两种平台化的模式来解决,一个是左图所示的日志tree的方式,另一个是右图的漏斗分析的方式。
通过日志tree的方式,我们可以知道这次请求经过的主要模块,比如这次请求经过了哪些召回,哪些过滤,分别过了哪几个模型,以及分别过滤哪几个策略等,日志tree可以从架构的角度帮助算法工程师分析此次日志是否合理等问题。
右图中是经典的推荐系统漏斗图,非常直观地展示了推荐系统的SKU漏斗分布,解释了商品是如何在漏斗里面流转的。
Debug链路的推荐物料可解释

上图中展示的是debug模拟请求在推荐物料可解释里面的作用,下面先来介绍一下什么是debug模拟请求,以及debug模拟请求在推荐系统里面的重要性。
大家都知道,推荐系统的链路是非常复杂的,因此想要debug 也是非常困难的,比如我加上的一些过滤逻辑是否有生效,模型的一些加权或者减权、多样性策略有没有生效等等,这些问题都是难以debug 的。Debug链路主要解决的就是线上问题能否快速复现以及快速发现一些逻辑有没有生效等问题。
还有一类问题,比如我有A、B两个实验,其中A实验的效果比B差一些,那么针对具体请求差异是什么样子的呢?利用debug模拟请求,可以快速diff 两个实验针对同样请求的结果差异。
用户画像
接下来介绍可解释系统中的一个重要模块,用户画像。

推荐系统的召回是根据用户的行为习惯和爱好来做的,这里的用户行为习惯和爱好都统一称之为用户画像。
上图中列举了一些画像的例子,比如从用户人口属性维度,是否有小孩儿,以及用户价值维度,有用户消费的活跃分层。除了这种基础类画像,还会有一些这种挖掘类画像,比如用户的品类、品牌偏好,购买力偏好等等。
除了一些基础召回之外,推荐系统中还会做一些个性化召回,这些召回基本上都是与这些画像维度相对应的。
行为画像

再来看一下用户的行为画像。本质上,行为画像也是用户画像的一部分,在这里我们之所以把它提出来,是因为它除了用作于召回之外,还可以用作一些场景问题的分析,行为画像可以复现用户在app上的所有行为,为分析提供参考。
行为画像包括两部分,即宏观行为和精细行为。宏观行为主要是浏览、点击、加购、下单等电商类APP中的常见行为。仅凭这些行为,我们是无法准确判断用户意图的,因此我们还会加上一些精细行为的埋点,比如用户在浏览一个商品或者搜索一个商品的时候,如果仅用一些宏观的行为,比如点击,我们完全没有办法判断用户是不是真的要买。但是如果点进去了商详页,并且查看了一些评论,或点击了大图,又或者在这个商品上停留了较长时间,对这个商品的操作达到了一定的次数,那么我们就可以认为用户有比较有强烈的购买意图了。
针对不同的宏观行为和精细行为,需要构建不同的召回策略,比如点击商品的相关、相似商品,评论、分享、查看大图等一些i2i召回,这些宏观行为和精细行为需要有不同的得分策略。一旦出现问题,我们可以根据不同的行为来判断他的这些召回是否正确,或者与用户行为是否匹配。
商品画像
接下来看一下商品画像对推荐系统的重要性,以及可解释系统里面的商品画像是什么样子的。
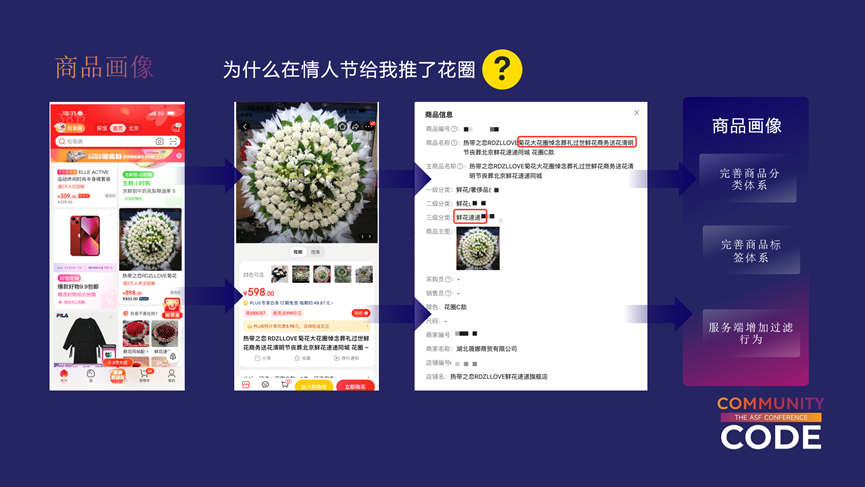
如上图中的例子,在情人节的时候,首页通常会推一些鲜花速递类似的礼品,但给用户推了一个花圈。这在严格意义上来讲是一个场景推荐的问题,针对这个问题我们要具体分析。从商详页来看,它确实是丧葬类产品,而在第三幅图中,这是可解释系统的一个商品画像的展示,可以看到它的title确实是丧葬用品,但是它的三级分类却是鲜花速递。针对这种场景,商品分类本身是没有问题的,因为它确实是鲜花,只不过标签不够细化,至此我们就知道了问题的原因和优化的方向。
模型可解释
接下来介绍模型可解释在电商的应用。

在电商的场景下为什么需要模型可解释呢?如上图所示,如果不引入模型可解释,那么图中这个问题是没有办法解释的,某个SKU在召回、过滤阶段都很正常,但是偏偏被模型过滤了很多,其实这个问题的本质是全域商品下模型打分偏低。
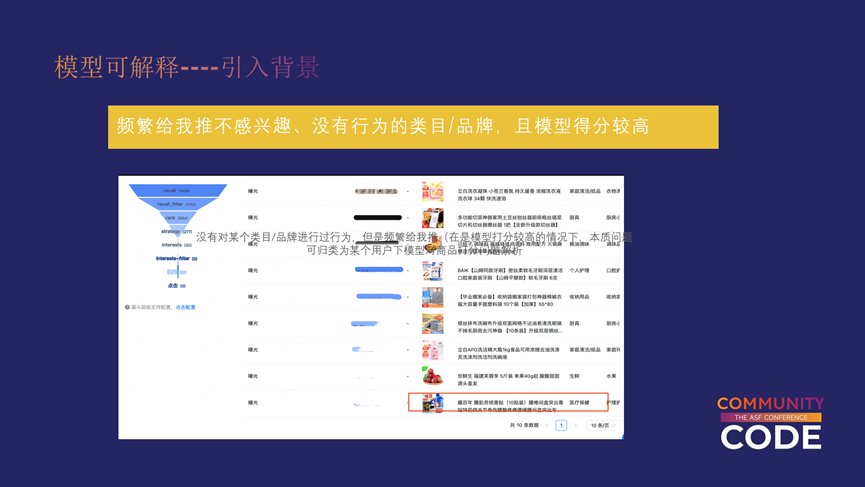
第二个例子,明明没有对某个类目/品牌产生过行为,并且我也不感兴趣,但是频繁给我推,这个问题是在模型打分较高的情况下,本质可归类为某个用户下模型对商品打分的问题。
以上两类问题都是线上频发的问题,如果没有引入模型可解释,都是无法解决的。
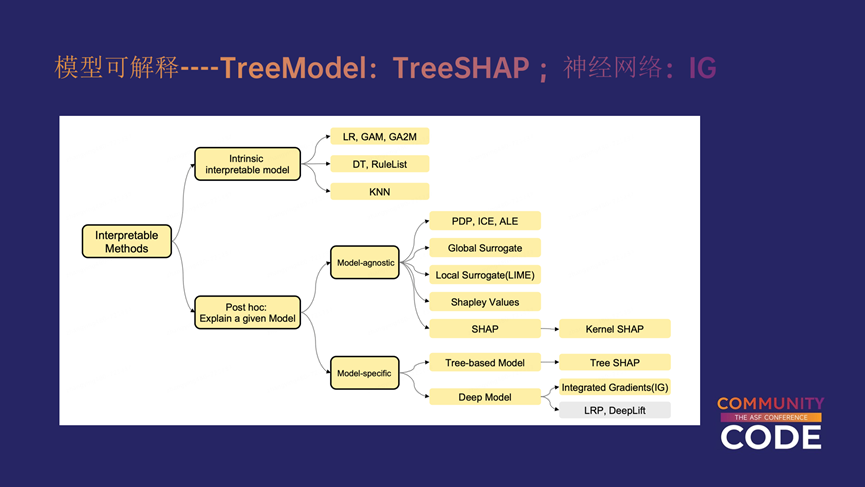
上图中列出了一些常用的模型可解释的方法,其中有一些模型本身就是可解释的,比如一些简单的线性模型和规则类的模型;还有一些模型本身是一个黑盒,但已有较为成熟的方案来解释。针对一些Tree Model,我们选择Tree SHAP的方法去解释,针对神经网络模型,我们采用IG的方式。

在介绍Tree SHAP之前先来介绍一下Shapely Value。Shapely Value的本质是为了研究一个团体中各个参与者对最终结果的贡献,这个算法可以准确地计算出相应的贡献值,在电商场景下应用也是主要在特征的领域,可以确定模型各个特征对预估结果的影响。但是这个算法的劣势也是不能忽略的,那就是在数据量级较大时计算的复杂度会指数级增长。Tree SHAP的引入极大降低了计算的复杂度,它不再遍历特征,转而遍历所有叶子结点,并且通过根节点到叶子结点的路径来修改特征的贡献计算方式和权重计算,使得时间和空间复杂度都极大降级,这使得我们的千级特征模型有了可解释的可能。
右边这段代码是我们解释SKU在具体的品牌、品类或者产品词的特征重要性的代码片段,SKU的样本作为目标样本,品牌、品类或者产品词的样本作为背景样本去解释。
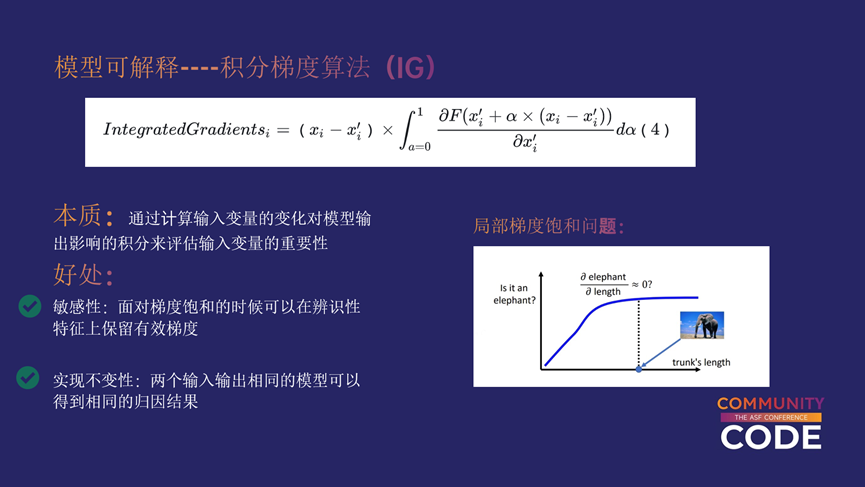
针对神经网络的可解释我们采用的是积分梯度算法,这个算法的本质是通过计算输入变量的变化对模型输出影响的积分来评估输入变量的重要性。这个模型的好处是具有敏感性和实现不变性,敏感性指的是面对梯度饱和的时候可以在辨识性特征上保留有效梯度,实现不变性指的是两个输入输出相同的模型可以得到相同的归因结果。
比如右边这个图,针对大象鼻子长短的问题,在一定范围内,鼻子越长越可能是个大象,但是长到一定程度,那鼻子长短就不再是关键特征了。

接下来回到模型可解释在电商的具体应用。在筛选关键特征因子的场景下,全局特征的重要性主要在于衡量所有样本中各个特征对模型预测结果影响的相对显著程度。如左图中,特征值越低,越接近蓝色,值越高越接近红色;第一维特征表示,value越小效果越差;大部分的样本shap value集中在0-1之间,越粗表示点越密集,样本量越多。
右图是模型影响最大的top20特征。这里需要特别说明一下绝对平均值存在的意义,是为了更加直观地展示特征对效果的意义,因为有时候得分不一定是越高越好的,比如不合适的商品得分就要低,“绝对平均值”对这类特征非常有用。
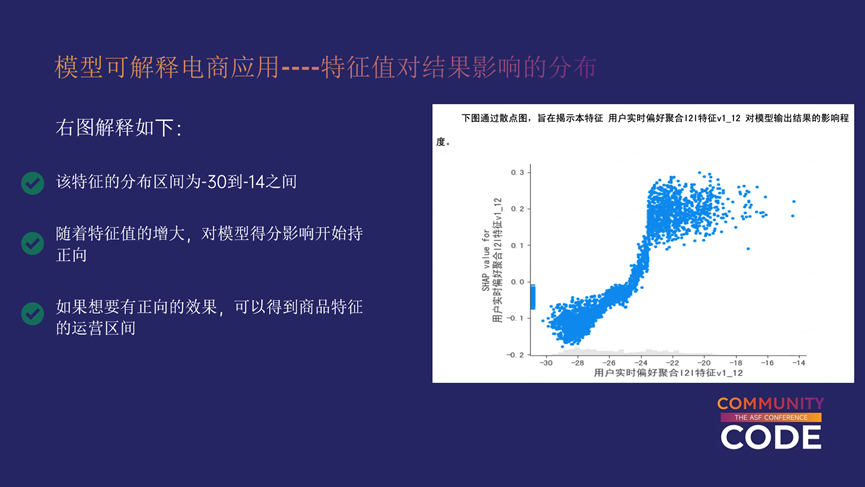
通过前面一张图片,我们可以看到整体特征对模型的影响,但是仅有这些仍无法对运营起到指导作用,因此我们还需要第二个功能,即特征值对结果的影响的分布。
上图中右图是我们的一个结果图,通过该图可以知道特征值越大对效果越呈正向,并且可以得到该特征一定的运营区间。当然,推荐系统的变化是非常多的,仅仅解释一维特征的意义有限,因此这个功能仅起到一个指导意义。

接下来是电商的一个更加深度的应用,我们称之为单SKU特征重要性。大家都知道,只要样本训练合理,模型打分是很公平的,但是电商场景下商品是不公平的,商品的分层现象非常明显,比如模型就是可能对某个类目下商品打分分布较广,但是涉及到敏感类目得分就是会很低,比如苹果品牌得分却会偏高,因此,我们知道某个SKU在某个品类、品牌下的特征重要性,比针对全域商品更有说服力,更加能说明该SKU的流量获取情况。
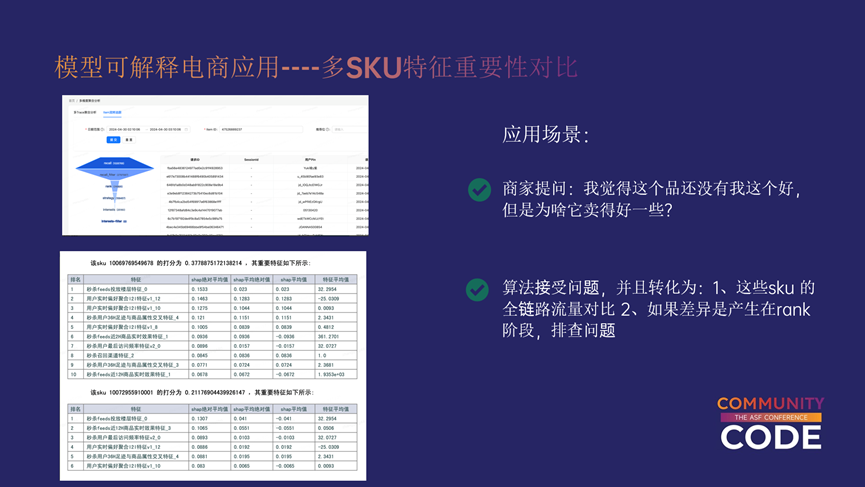
运营经常会提出这样的问题:“我觉得这个品还没有我这个好,但是为啥它卖得好一些?”
我们接收到这个问题,排除掉一些其它影响因素,归咎到推荐系统里面,首先做的就是对比这两个SKUK在全链路的流量情况,如果他们在召回、过滤、策略比例都相同,但是唯独在模型这块相差较大,那么我们就需要知道这两个SKU在模型维度的pk结果了。
上图左下的表格中展示的是两个SKU pk的结果,可以看到,第一个要比第二个高很多。
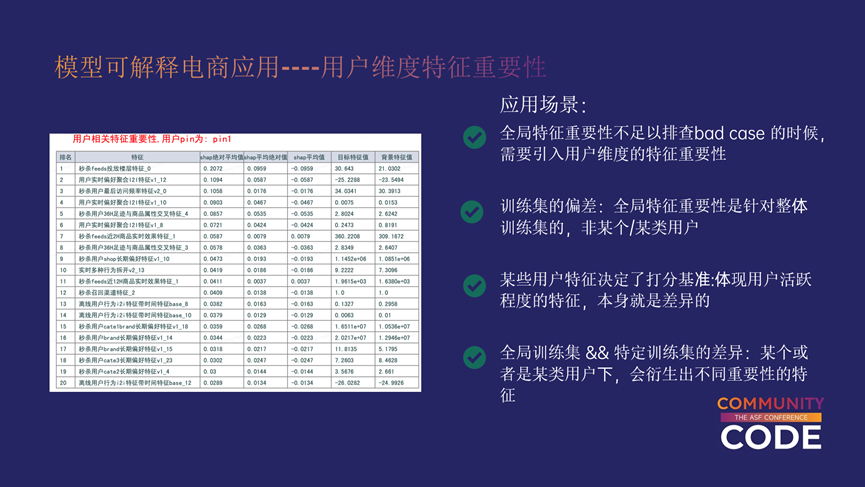
当全局特征重要性不足以排查bad case 的时候,需要引入用户维度的特征重要性,之前全局特征重要性会带来训练集偏差的问题,在具体的一个用户上,比如全局特征重要性是针对整体训练集的,非某个/某类用户,这些用户的数据分布在整体上不见得和整体用户分布一致,因此,某个或者是某类用户下,会衍生出不同重要性的特征。因此,引入用户维度的特征重要性是很有必要的。
体现用户活跃程度的特征容易成为重要特征,但是有时候在某个或者是某类用户的排序下不太合适,因为这个用户的特征都是一致的,用户不一样的情况下,那就是这些特征本身就存在不一致的情况。
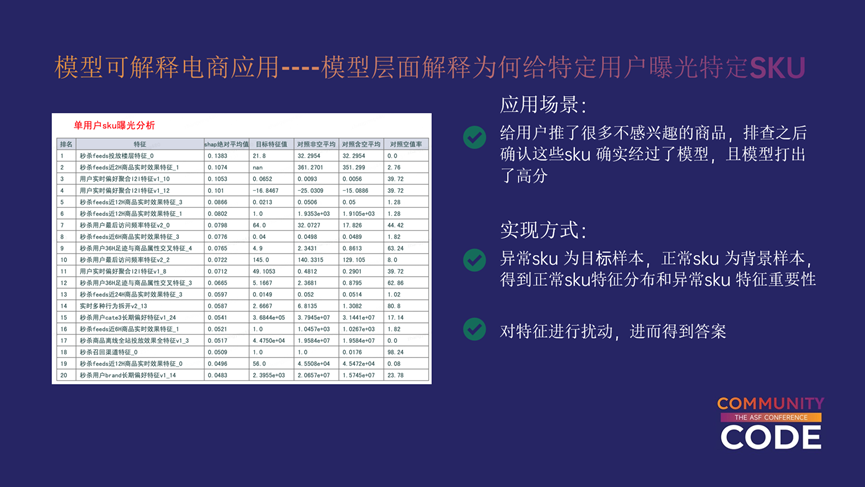
接下来看一下我们是如何在模型层面解释为何给特定用户曝光特定SKU的。比如我们经常会遇到这种case,我是一个直男,没有女朋友,我就对电子产品感兴趣,但是为啥首页给我推项链化妆品呢?
针对此类问题,我们首先要保证这些排序确实是经过了模型,且模型打出了较高的分,并且没有触发兜底等策略。因此,我们将异常SKU作为目标样本,正常SKU作为背景样本,得到正常SKU特征分布和异常SKU特征重要性,并且对特征进行扰动,进而得到答案。
流量可解释
接下来介绍的是流量可解释。
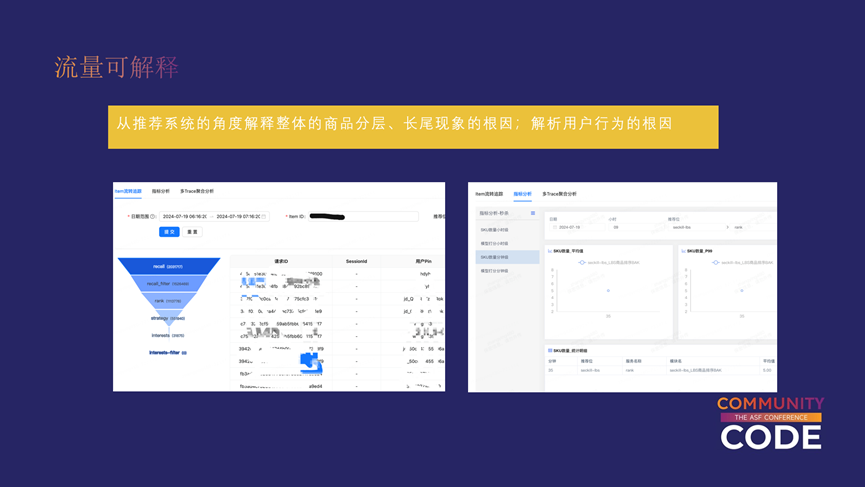
流量可解释的目的是从推荐系统的角度解释整体的商品分层、长尾现象的根因,以及解析用户行为的根因。这部分仍在建设阶段,目前只有三个应用。
一个是该图里面的这个全局漏斗,可以查看全局的流量漏斗转化。另一个应用是右边这个图里的一些具体的指标,拿到推荐系统不同阶段的SKU数量、模型得分等。
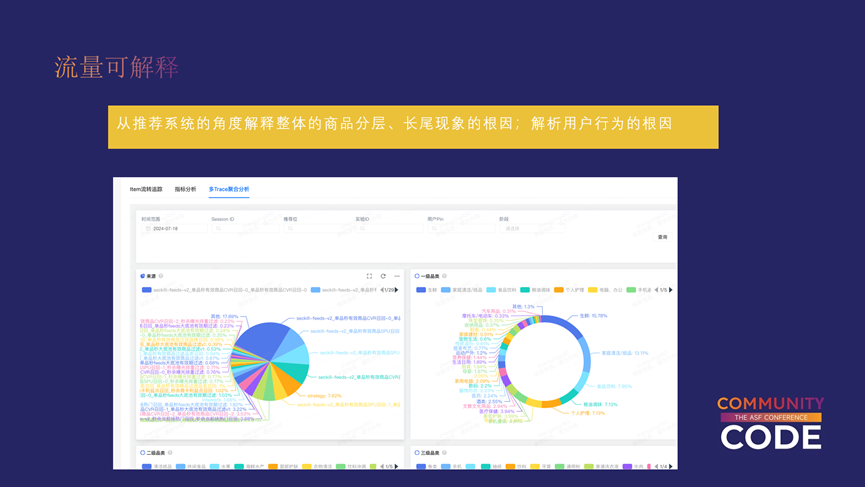
还有一个是全局维度的召回、排序、策略阶段对所有品类品牌的流量分布情况,当然还可以输入一些具体的条件。
鸣谢
感谢京东零售技术专家安伟亭在技术上的指导,以及营销研发部肖军波、阮辉等人的大力支持。
整理者:DataFun 李瑶
相关文章:
京东零售推荐系统可解释能力详解
作者:智能平台 张颖 本文导读 本文将介绍可解释能力在京东零售推荐系统中的应用实践。主要内容包括以下几大部分:推荐系统可解释定义、系统架构、排序可解释、模型可解释、流量可解释。 推荐系统可解释定义 推荐系统可解释的核心包括三部分࿰…...

蓝桥杯 懒洋洋字符串--字符串读入
题目 代码 #include <iostream>using namespace std;int main(){int n;cin>>n;char s[210][4];int ans0;for(int i0;i<n;i){scanf("%s",s[i]);}for(int i0;i<n;i){char as[i][0];char bs[i][1];char cs[i][2];// cout<<a<< <<b…...

SDL打开YUV视频
文章目录 问题1:如何控制帧率?问题2:如何触发退出事件?问题3:如何实时调整视频窗口的大小问题4:YUV如何一次读取一帧的数据? 问题1:如何控制帧率? 单独用一个子线程给主线…...

微服务架构面试内容整理-Archaius
Archaius 是由 Netflix 开发的一个配置管理库,主要用于处理动态配置和环境配置。在微服务架构中,Archaius 允许开发者以灵活的方式管理配置,从而更好地应对变化的需求。以下是 Archaius 的主要特点、工作原理和使用场景: 主要特点 1. 动态配置: Archaius 支持动态更新配置…...

实现 Nuxt3 预览PDF文件
安装必要的库,这里使用PDF.js库 npm install pdfjs-dist --save 为了解决跨域问题,在server/api 下 创建一个请求api, downloadFileByProxy.ts import { defineEventHandler } from h3;export default defineEventHandler(async event >…...

udp为什么会比tcp 有更低的延迟
UDP(User Datagram Protocol,用户数据报协议)相比TCP(Transmission Control Protocol,传输控制协议)具有更低的延迟,这主要归因于UDP协议的设计特点和机制。以下是对UDP比TCP延迟低的原因的详细…...

基于java+SpringBoot+Vue的洗衣店订单管理系统设计与实现
项目运行 环境配置: Jdk1.8 Tomcat7.0 Mysql HBuilderX(Webstorm也行) Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。 项目技术: Springboot mybatis Maven mysql5.7或8.0等等组成&#x…...

HarmonyOS-消息推送
一. 服务简述 Push Kit(推送服务)是华为提供的消息推送平台,建立了从云端到终端的消息推送通道。所有HarmonyOS 应用可通过集成 Push Kit,实现向应用实时推送消息,使消息易见,构筑良好的用户关系࿰…...

数据分析:宏基因组DESeq2差异分析筛选差异物种
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍原理:计算步骤:结果:加载R包准备画图主题数据链接导入数据Differential abundance (No BP vs 2BP TA)构建`countData`矩阵过滤低丰度物种构建DESeq数据对象DESeq2差异分析画图Di…...

出海企业如何借助云计算平台实现多区域部署?
云计算de小白 如需进一步了解,请单击链接了解有关 Akamai 云计算的更多信息 在本文中我们将告诉大家如何在Linode云计算平台上借助VLAN快速实现多地域部署。 首先我们需要明确一些基本概念和思想: 部署多区域 VLAN 为了在多区域部署中在不同的 VLAN …...

硬件---1电路设计安全要点以及欧姆定律
前言: 一直搞的东西都偏软件,硬件也一直在学,元器件、基础电路知识、PCB设计、模电运放都学的马马虎虎,因此决定进行系统性学习,内容基本来源于手里的视频和书本以及自己的感悟。 一电路安全 1电路安全 在初期基础…...

Linux如何更优质调节系统性能
一、硬件优化 增加物理内存:最直接的提升系统性能的方法。内存不足时,系统会频繁进行交换(swapping)活动,这会显著降低系统的响应速度,因为磁盘IO速度远低于内存访问速度。通过增加内存,可以减…...

第三十五章 Vue路由进阶之声明式导航(跳转传参)
目录 一、引言 二、查询参数传参 2.1. 使用方式 2.2. 完整代码 2.2.1. main.js 2.2.2. App.vue 2.2.3. Search.vue 2.2.4. Home.vue 2.2.5. index.js 三、动态路由传参 3.1. 使用方式 3.2. 完整代码 3.2.1. main.js 3.2.2. App.vue 3.2.3. Search.vue 3.2.4. Hom…...

python爬虫自动库DrissionPage保存网页快照mhtml/pdf/全局截图/打印机另存pdf
目录 零一、保存网页快照的三种方法二、利用打印机保存pdf的方法 零 最近星球有人问如何使用页面打印功能,另存为pdf 一、保存网页快照的三种方法 解决方案已经放在星球内:https://articles.zsxq.com/id_55mr53xahr9a.html当然也可以看如下代码&…...

基于毫米波雷达和TinyML的车内检测、定位与分类
英文标题:In-Cabin Detection, Localization and Classification based on mmWave Radar with TinyML 作者信息: 王志飞,程一格,彭辉,周会强,王铮,刘宏全所属机构:Calterah Semico…...

小E的射击训练
问题描述 小E正在训练场进行射击练习,靶有10个环,靶心位于坐标(0, 0)。每个环对应不同的得分,靶心内(半径为1)得10分,依次向外的每个环分数减少1分。若射击点在某个半径为i的圆内,则得11-i分。…...

React的概念以及发展前景如何?
React是一个由Facebook开发的用于构建用户界面的的开源JavaScript库,它主要用于构建大型、动态的Web应用程序。React的主要特点是使用VirtualDOM(虚拟DOM)来优化性能,并使用声明式的编程方式来编写UI。 React的主要概念包括&#…...
生成PDF文档,包括如何将位图图像嵌入PDF中。)
PDF生成:全面解析,C# 如何使用iTextSharp库(或其他类似库)生成PDF文档,包括如何将位图图像嵌入PDF中。
一、概述 PDF(Portable Document Format)是一种广泛使用的文档格式,由Adobe公司在1993年推出。PDF的目标是能够在任何设备上呈现固定格式的文档,无论是在不同的操作系统、硬件设备,还是在打印时,都能保证文…...

如何选择最适合的消息队列?详解 Kafka、RocketMQ、RabbitMQ 的使用场景
引言 在日常开发中,消息队列已经成为业务场景中几乎不可或缺的一部分。无论是订单系统、日志收集、分布式事务,还是大数据实时流处理,消息队列都在支撑着这些关键环节。目前市面上常用的消息队列有三种(ActiveMQ 虽然在企业集成中仍有应用&a…...

gitlab项目如何修改主分支main为master,以及可能遇到的问题
如果你希望将 Git 仓库的主分支名称从 main 修改为 master: 1. 本地修改分支名称 首先,切换到 main 分支: git checkout main将 main 分支重命名为 master: git branch -m main master2. 更新远程仓库 将本地更改推送到远程仓库…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...