【大数据测试spark+kafka-详细教程(附带实例)】
大数据测试:Spark + Kafka 实时数据处理与窗口计算教程
- 1. 概述
- 1.1 大数据技术概述
- 1.2 Apache Kafka 与 Spark 的结合
- 2. 技术原理与流程
- 2.1 Kafka 简介
- 2.2 Spark Streaming 简介
- 2.3 数据流动与处理流程
- 3. 环境配置
- 3.1 安装依赖项
- 4. 实例:实时数据处理与窗口计算
- 4.1 Kafka 生产者代码
- 4.2 Spark Streaming 消费者代码
- 4.3 解释与操作
- 5. 运行与测试
- 5.1 创建 Kafka Topic
- 5.2 启动 Kafka 生产者
- 5.3 启动 Spark Streaming 程序
- 5.4 输出结果
- 6. 总结
1. 概述
1.1 大数据技术概述
大数据(Big Data)指的是无法用传统数据库技术和工具进行处理和分析的超大规模数据集合。在大数据技术中,实时数据流的处理尤为重要,尤其是如何高效地对海量的实时数据进行采集、存储、处理与分析。
在这方面,Apache Kafka 和 Apache Spark 是两个关键技术。Kafka 作为分布式流处理平台,可以高效地进行实时数据流的生产和消费,而 Spark 提供了强大的分布式计算能力,尤其是其扩展的流式计算模块 Spark Streaming,非常适合处理实时数据流。
1.2 Apache Kafka 与 Spark 的结合
- Kafka 是一个分布式消息队列,可以处理高吞吐量、低延迟的实时数据流。Kafka 被广泛用于日志收集、监控系统、实时数据传输等场景。
- Spark 是一个统一的分析引擎,支持批量处理、流式处理和图计算。Spark Streaming 是 Spark 的一个流式处理组件,用于实时处理流数据。
通过结合 Kafka 和 Spark,我们可以实现大规模数据的实时处理、聚合和窗口计算。Spark 可以从 Kafka 消费数据流,并进行实时计算与分析,适用于诸如实时日志分析、用户行为分析、实时推荐等场景。
2. 技术原理与流程
2.1 Kafka 简介
Kafka 是一个分布式的消息队列系统,能够实现高吞吐量、可扩展性、容错性。它的基本组成包括:
- Producer(生产者):负责向 Kafka 发送数据。
- Consumer(消费者):从 Kafka 中消费数据。
- Broker(代理):Kafka 的节点,每个节点负责存储消息。
- Topic(主题):消息被组织在 Topic 中,生产者向 Topic 发送数据,消费者从 Topic 中读取数据。
- Partition(分区):Kafka 支持水平分区,使得数据可以分布在多个 Broker 上。
2.2 Spark Streaming 简介
Spark Streaming 是 Spark 的流处理模块,它以 DStream(离散流)为基本数据结构,能够实时地处理数据流。DStream 是一个连续的 RDD(弹性分布式数据集),Spark Streaming 将实时流数据划分成一个个小的批次,使用批处理模型对这些小批次进行处理。
2.3 数据流动与处理流程
- Kafka Producer:将数据发送到 Kafka Topic。
- Kafka Broker:Kafka 集群负责存储和转发数据。
- Spark Streaming:通过 Kafka 的消费者接口从 Topic 中消费数据。
- 数据处理与计算:在 Spark Streaming 中进行数据聚合、过滤、窗口计算等操作。
- 输出结果:将处理后的数据输出到外部系统,如 HDFS、数据库或控制台。
3. 环境配置
3.1 安装依赖项
-
安装 Java:确保安装了 Java 8 或更高版本。
检查版本:
java -version -
安装 Apache Spark:从 Apache Spark 官网 下载并安装 Spark。
-
安装 Apache Kafka:从 Kafka 官网 下载并安装 Kafka。
-
Maven 配置:在 Java 项目中使用 Maven 作为构建工具,添加必要的 Spark 和 Kafka 依赖。
在 pom.xml 文件中添加 Spark 和 Kafka 的 Maven 依赖:
<dependencies><!-- Spark Core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.3.1</version></dependency><!-- Spark Streaming --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.3.1</version></dependency><!-- Spark Streaming Kafka --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.3.1</version></dependency><!-- Kafka Consumer --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.0.0</version></dependency>
</dependencies>
4. 实例:实时数据处理与窗口计算
4.1 Kafka 生产者代码
以下是一个简单的 Kafka 生产者,用于生成模拟的用户行为日志(如点击事件)并发送到 Kafka Topic logs。
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 模拟用户点击日志数据String[] actions = {"click", "view", "scroll"};String[] users = {"user1", "user2", "user3"};// 向 Kafka 发送模拟数据for (int i = 0; i < 100; i++) {String user = users[i % 3];String action = actions[i % 3];String timestamp = String.valueOf(System.currentTimeMillis() / 1000);String value = user + "," + action + "," + timestamp;producer.send(new ProducerRecord<>("logs", null, value));try {Thread.sleep(1000); // 每秒发送一条数据} catch (InterruptedException e) {e.printStackTrace();}}producer.close();}
}
4.2 Spark Streaming 消费者代码
以下是一个 Spark Streaming 程序,它从 Kafka Topic logs 中消费数据并进行窗口计算,统计每个用户在过去 10 秒内的点击次数。
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.*;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import org.apache.kafka.clients.consumer.ConsumerRecord;import java.util.HashMap;
import java.util.Map;
import java.util.Arrays;
import java.util.List;public class SparkKafkaWindowExample {public static void main(String[] args) throws InterruptedException {// 初始化 Spark StreamingContextJavaStreamingContext jssc = new JavaStreamingContext("local[2]", "SparkKafkaWindowExample", new Duration(2000));// Kafka 配置参数String brokers = "localhost:9092";String groupId = "spark-consumer-group";String topic = "logs";// Kafka 参数设置Map<String, Object> kafkaParams = new HashMap<>();kafkaParams.put("bootstrap.servers", brokers);kafkaParams.put("key.deserializer", StringDeserializer.class);kafkaParams.put("value.deserializer", StringDeserializer.class);kafkaParams.put("group.id", groupId);kafkaParams.put("auto.offset.reset", "latest");kafkaParams.put("enable.auto.commit", "false");List<String> topics = Arrays.asList(topic);// 从 Kafka 获取数据流JavaReceiverInputDStream<ConsumerRecord<String, String>> stream =KafkaUtils.createDirectStream(jssc,LocationStrategies.PreferConsistent(),ConsumerStrategies.Subscribe(topics, kafkaParams));// 处理每条记录:解析用户、动作和时间戳JavaPairRDD<String, String> userActions = stream.mapToPair(record -> {String[] fields = record.value().split(",");return new Tuple2<>(fields[0], fields[1]); // userId, action});// 定义窗口大小为 10 秒,滑动间隔为 5 秒JavaPairRDD<String, Integer> userClickCounts = userActions.window(new Duration(10000), new Duration(5000)) // 滑动窗口.reduceByKeyAndWindow((Function2<Integer, Integer, Integer>) Integer::sum,new Duration(10000), // 窗口大小:10秒new Duration(5000) // 滑动间隔:5秒);// 输出每个窗口的用户点击次数userClickCounts.foreachRDD(rdd -> {rdd.collect().forEach(record -> {System.out.println("User: " + record._1() + ", Click Count: " + record._2());});});// 启动流式处理jssc.start();jssc.awaitTermination();}
}
4.3 解释与操作
- Kafka 配置:配置 Kafka 参数,连接到 Kafka 服务,订阅 Topic
logs。 - 数据解析:从 Kafka 消费数据后,解析每条日志(如
user1,click,1609459200)。 - 窗口计算:使用
window()定义一个窗口,窗口大小为 10 秒,滑动间隔为 5 秒。使用reduceByKeyAndWindow()聚合每个窗口内的用户点击次数。 - 输出结果:每 5 秒统计一次过去 10 秒内的用户点击次数,输出到控制台。
5. 运行与测试
5.1 创建 Kafka Topic
在 Kafka 中创建 Topic logs:
kafka-topics.sh --create --topic logs --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
5.2 启动 Kafka 生产者
运行 Kafka 生产者代码,模拟数据发送到 Kafka:
java KafkaProducerExample
5.3 启动 Spark Streaming 程序
运行 Spark Streaming 程序,消费 Kafka 数据并执行窗口计算:
java SparkKafkaWindowExample
5.4 输出结果
每隔 5 秒输出用户的点击次数,如:
User: user1, Click Count: 3
User: user2, Click Count: 5
6. 总结
通过结合使用 Apache Kafka 和 Apache Spark,我们可以高效地处理大规模的实时数据流。Kafka 负责消息的可靠传输,而 Spark Streaming 负责实时计算和分析。使用窗口计算(如 window() 和 reduceByKeyAndWindow()),我们可以在不同时间段内对数据进行聚合,适用于实时监控、推荐系统、用户行为分析等场景。
此架构适用于需要处理大数据、实时响应的应用程序,并能满足高吞吐量、低延迟的要求。
推荐阅读:《大数据 ETL + Flume 数据清洗》,《大数据测试 Elasticsearch》
相关文章:
】)
【大数据测试spark+kafka-详细教程(附带实例)】
大数据测试:Spark Kafka 实时数据处理与窗口计算教程 1. 概述1.1 大数据技术概述1.2 Apache Kafka 与 Spark 的结合 2. 技术原理与流程2.1 Kafka 简介2.2 Spark Streaming 简介2.3 数据流动与处理流程 3. 环境配置3.1 安装依赖项 4. 实例:实时数据处理与…...

如何为 GitHub 和 Gitee 项目配置不同的 Git 用户信息20241105
🎯 如何为 GitHub 和 Gitee 项目配置不同的 Git 用户信息 引言 在多个代码托管平台(如 GitHub 和 Gitee)之间切换时,正确管理用户信息至关重要。频繁使用不同项目时,若用户配置不当,可能会导致意外提交或…...

【Lucene】原理学习路线
基于《Lucene原理与代码分析完整版》,借助chatgpt等大模型,制定了一个系统学习Lucene原理的计划,并将每个阶段的学习内容组织成专栏文章,zero2hero 手搓 Lucene的核心概念和实现细节。 深入的学习和专栏计划,覆盖Lucen…...

Go语言的并发安全与互斥锁
线程通讯 在程序中不可避免的出现并发或者并行,一般来说对于一个程序大多数是遵循开发语言的启动顺序。例如,对于go语言来说,一般入口为main,main中依次导入import导入的包,并按顺序执行init方法,之后在按…...

SpringBoot框架在资产管理中的应用
3系统分析 3.1可行性分析 通过对本企业资产管理系统实行的目的初步调查和分析,提出可行性方案并对其一一进行论证。我们在这里主要从技术可行性、经济可行性、操作可行性等方面进行分析。 3.1.1技术可行性 本企业资产管理系统采用Spring Boot框架,JAVA作…...

ElasticSearch备考 -- 集群配置常见问题
一、集群开启xpack安全配置后无法启动 在配置文件中增加 xpack.security.enabled: true 后无法启动,日志中提示如下 Transport SSL must be enabled if security is enabled. Please set [xpack.security.transport.ssl.enabled] to [true] or disable security b…...

【UE5】一种老派的假反射做法,可以用于移动端,或对反射的速度、清晰度有需求的地方
没想到大家这篇文章呼声还挺高 这篇文章是对它的详细实现,建议在阅读本篇之前,先浏览一下前面的文章,以便更好地理解和掌握内容。 这种老派的假反射技术,适合用于移动端或对反射效果的速度和清晰度有较高要求的场合。该技术通过一…...

FasterNet中Pconv的实现、效果与作用分析
发表时间:2023年3月7日 论文地址:https://arxiv.org/abs/2303.03667 项目地址:https://github.com/JierunChen/FasterNet FasterNet-t0在GPU、CPU和ARM处理器上分别比MobileViT-XXS快2.8、3.3和2.4,而准确率要高2.9%。我们的大型…...

QToolbar工具栏下拉菜单不弹出有小箭头
这里说了怎么弹出:Qt 工具栏QToolBar添加带有弹出菜单的QAction_qt如何将action添加到工具栏-CSDN博客 然后如果你是在UI里面建立的action,并拖到了toolbar,并在代码中设置菜单,例如: ui->mytoolbar->setMenu(…...

w025基于SpringBoot网上超市的设计与实现
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹赠送计算机毕业设计600个选题excel文件࿰…...

深度学习在推荐系统中的应用
参考自《深度学习推荐系统》,用于学习和记录。 前言 (1)与传统的机器学习模型相比,深度学习模型的表达能力更强,能够挖掘(2)深度学习的模型结构非常灵活,能够根据业务场景和数据特…...

软考系统架构设计师论文:论面向对象的建模及应用
试题三 论面向对象的建模及应用 软件系统建模是软件开发中的重要环节,通过构建软件系统模型可以帮助系统开发人员理解系统、抽取业务过程和管理系统的复杂性,也可以方便各类人员之间的交流。软件系统建模是在系统需求分析和系统实现之间架起的一座桥梁,系统开发人员按照软件…...

LSM-TREE和SSTable
一、什么是LSM-TREE LSM Tree 是一种高效的写优化数据结构,专门用于处理大量写入操作 在一些写多读少的场景,为了加快写磁盘的速度,提出使用日志文件追加顺序写,加快写的速度,减少随机读写。但是日志文件只能遍历查询…...

mysql 升级
# 备份数据库数据 mysqldump -u root -p --single-transaction --all-databases > backup20240830.sql; # 备份mysql数据目录: cp -r /data/mysql mysql20240902 # 备份mysql配置文件my.cnf cp -r /etc/my.cnf my.cnf20240902 systemctl stop mysqld tar -x…...

基于Multisim定时器倒计时器电路0-999计时计数(含仿真和报告)
【全套资料.zip】定时器倒计时器电路Multisim仿真设计数字电子技术 文章目录 功能一、Multisim仿真源文件二、原理文档报告资料下载【Multisim仿真报告讲解视频.zip】 功能 1.0-999秒定时功能,计时间隔1秒,数字显示。 2. 进行0-999秒减计时,…...

力扣11.5
1035. 不相交的线 在两条独立的水平线上按给定的顺序写下 nums1 和 nums2 中的整数。 现在,可以绘制一些连接两个数字 nums1[i] 和 nums2[j] 的直线,这些直线需要同时满足: nums1[i] nums2[j]且绘制的直线不与任何其他连线(非…...

arkUI:层叠布局(Stack)
arkUI:层叠布局(Stack) 1 主要内容说明2 相关内容2.1 层叠布局(Stack)2.1.1 源码1的相关说明2.1.2 源码1 (层叠布局)2.1.3 源码1运行效果2.1.3.1 当alignContent: Alignment.Bottom2.1.3.2 当al…...

【LeetCode】【算法】221. 最大正方形
LeetCode 221. 最大正方形 题目描述 在一个由 ‘0’ 和 ‘1’ 组成的二维矩阵内,找到只包含 ‘1’ 的最大正方形,并返回其面积。 思路 思路:动态规划。初始化时,第0列和第0行,若nums[i][j]1则dp[i][j]初始化为1&am…...

怎麼解除IP阻止和封禁?
IP地址被阻止的原因 安全問題如果有人使用 IP 地址試圖侵入某個網站或導致其他安全問題,則可能會禁止該 IP 以保護該網站。濫用或垃圾郵件如果IP地址發送過多垃圾郵件、發佈不當內容或濫用網站服務,則可能會被禁止,以保持網站清潔和友好。違…...

O-RAN Fronthual CU/Sync/Mgmt 平面和协议栈
O-RAN Fronthual CU/Sync/Mgmt 平面和协议栈 O-RAN Fronthual CU/Sync/Mgmt 平面和协议栈O-RAN前端O-RAN 前传平面C-Plane(控制平面):控制平面消息定义数据传输、波束形成等所需的调度、协调。U-Plane(用户平面)&#…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...
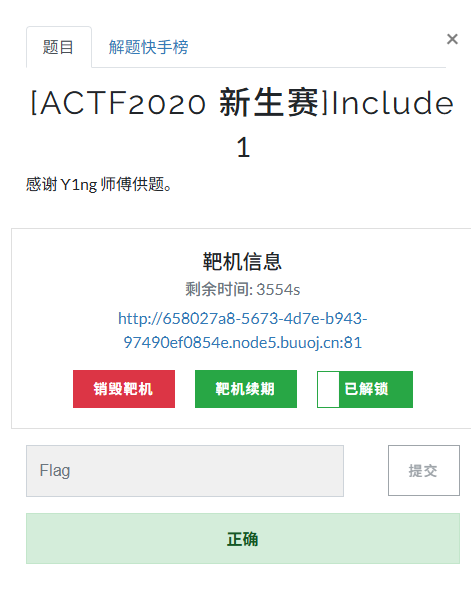
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...

认识CMake并使用CMake构建自己的第一个项目
1.CMake的作用和优势 跨平台支持:CMake支持多种操作系统和编译器,使用同一份构建配置可以在不同的环境中使用 简化配置:通过CMakeLists.txt文件,用户可以定义项目结构、依赖项、编译选项等,无需手动编写复杂的构建脚本…...
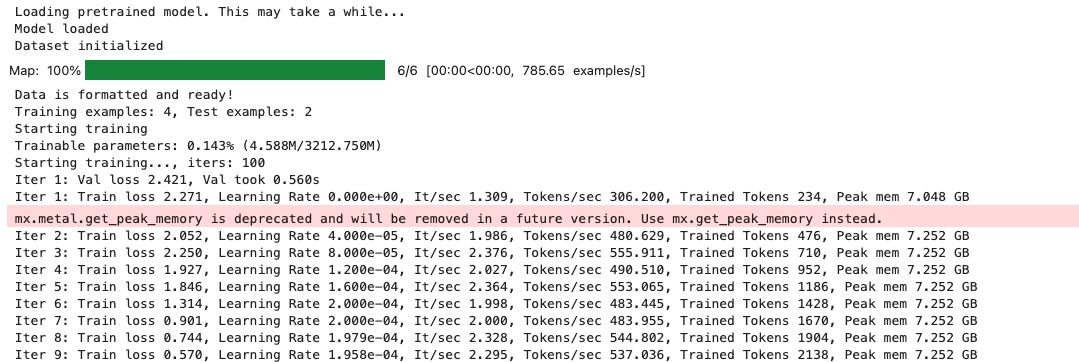
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...