【AI大模型】Transformer中的编码器详解,小白必看!!
前言
Transformer中编码器的构造和运行位置如下图所示,其中编码器内部包含多层,对应下图encoder1…encoder N,每个层内部又包含多个子层:多头自注意力层、前馈神经网络层、归一化层,而最关键的是多头自注意力层。

自注意力是什么?
当人类的视觉系统察觉到一个物体时,通常不会从头到尾地扫视整个场景;一般会根据个人的需求集中关注特定的部分。比如下面这张图,我们第一眼应该是看到一只动物,然后,眼睛会先注意到动物的脸,然后得出初步结论,这应该是一只狼;就像右边注意力图所示,颜色更深的部分表示一般是我们人类最先看见(注意)的。

注意力最早应用在机器视觉领域(CV,Computer Vision),后来才应用到 NLP 和 LLM 领域。
自注意力(Self-Attention) 是一种机制,允许模型在处理一个输入序列时,关注该序列中任意位置的其他元素。自注意力计算每个元素(如一个词语)与序列中其他元素的相关性,并根据这些相关性动态调整每个元素的表示。这使得模型能够捕捉长距离依赖关系,不受距离的影响,尤其适用于自然语言处理等需要理解上下文的任务。
假设有一句话:“小明和小花、小丽是好朋友,其中小花很漂亮,小明很喜欢她”。在传统的语言模型中,模型可能会依赖于顺序来处理每个词。但在自注意力机制下,模型会计算每个词与其他词的关联度,比如"小明"和"喜欢"之间的关联,以及"她"和"小花"之间的联系。通过这种机制,模型能够在理解一个词时同时参考整个句子中的其他词,尤其是长距离的依赖关系,从而捕捉到更复杂的语义信息,例如通过句子上下文就能很好理解“她”指的是“小花”而不是“小丽”。

好处:
-
捕捉长距离依赖:自注意力允许模型在不增加复杂度的情况下,捕捉输入序列中不同位置之间的依赖关系。这对于自然语言处理非常有用,因为语言中的词语依赖可能出现在很远的地方。例如,句子的主语和谓语可能相距甚远。
-
上下文敏感:每个元素的表示在每个自注意力层都会更新,逐渐包含更多的上下文信息,使模型能更准确地理解语义。
👀
在 Transformer 中编码器是如何运作的?
当输入一句话(如 “I love ai”)到大模型中进行翻译时,经过多个层次的处理,包括自注意力层(Self-Attention),模型逐渐生成输出。以下详细描述这一过程的步骤,从输入到自注意力层如何处理,直至生成翻译结果。
1、输入嵌入与位置编码首先,输入的句子 “I love ai” 通过词嵌入层将每个单词转换为向量表示。
假设我们有以下输入向量:
-
“I” → E_I
-
“love” → E_love
-
“ai” → E_ai
这些嵌入表示了单词的语义信息,此外还会加上位置编码(Positional Encoding),因为 Transformer 没有内置的序列处理能力(如 RNN)。位置编码会为每个位置加上唯一的标识,这样模型能够区分不同的单词顺序。
2、在自注意力层生成 Q、K、V 向量每个嵌入向量经过线性变换,生成 Query、Key 和 Value 向量:

Query (Q):表示当前单词需要从其他单词中获取的信息。
Key (K):表示每个单词的特征,用于与 Query 进行匹配。
Value (V):表示每个单词最终提供的信息,用于计算输出。假设我们对 “I love ai” 的三个单词分别生成了 Q、K 和 V 向量:
Q:Q_I, Q_love, Q_ai
K:K_I, K_love, K_ai
V:V_I, V_love, V_ai
说明:
-
在生成Query (Q)、Key (K) 和 Value (V) 向量的过程中,“线性变换”指的是使用矩阵乘法来转换原始的词嵌入向量。这种变换本质上是对输入向量的一个线性投影,目的是为了使Query、Key 和 Value 向量具有特定的属性,以便更好地服务于注意力机制的任务,可以简单理解为抽取出多不同维度的信息。
-
权重矩阵(Wq、Wk、Wv)是大模型在训练过程中生成的,当一个模型训练结束以后就固定了,只有后续微调训练才会发生变化。
3、计算注意力权重接下来在自注意力机制中,模型计算每个单词之间的注意力权重。这一步的核心是利用 Query 和 Key 之间的点积来确定当前单词与其他单词的相关性。对于句子中的每个单词(例如 “I”),模型将该单词的 Query 与句子中所有单词的 Key 进行点积运算:
score(QI,Kall) = [QI·KI ,QI · KIove,QI · Kai]

对每个单词都进行类似的计算,结果形成一个注意力分数矩阵。为了避免大数值问题,通常会对分数除以 d_k 的平方根(Key 向量的维度)进行缩放,并通过 softmax 函数归一化,使每个单词的注意力分数之和为 1

这个过程为每个单词计算它对其他单词的关注程度,形成注意力权重矩阵。假设在这句话中,“I” 更关注 “love” 而不是 “ai”。
说明:
向量点积运算(dot product),是可以衡量两个向量之间的相似程度。点积的结果越大,说明这两个向量越相似或越接近同一方向。反之,结果越小,说明它们相差越大,甚至方向相反。在自注意力机制中,模型会将输入的每个词转化为一个向量(如查询向量、键向量、值向量)。通过计算查询词向量和键向量之间的点积,模型可以得到每个词与其他词的相似度。这些相似度值决定了模型在生成输出时该“关注”哪些词,以及“关注”的程度。

计算it与这句话里的其他单词的关联度
4、加权求和生成新的表示,使用计算出的注意力权重对 Value 向量进行加权求和。每个单词的输出表示是所有单词的 Value 向量的加权求和:
output for “Love” =(weightI · VI + weightlove · Vlove + weightai · Vai
这意味着每个单词在新的表示中不只是自身的信息,还包含了其他单词的信息,这帮助模型捕捉输入序列中的依赖关系。
5、多头注意力机制自注意力 通常会扩展为多头注意力(Multi-Head Attention),即多个 Q、K、V 头并行运行,每个头学习不同的特征或依赖关系。最终,这些不同头的输出会被拼接在一起并通过线性变换进行整合。
为什么需要多头注意力机制?相比单一的自注意力,多头注意力提供了几个优势:
多样性:学习不同的模式
每个头都有自己独立的线性变换矩阵 W_Q, W_K, W_V,这意味着不同的头可以学习到不同的语义特征。例如:
-
一个头可能关注的是句子中的长距离依赖关系,比如句子的主语和动词的关系。
-
另一个头可能专注于短距离依赖关系,比如形容词和名词之间的联系。
通过多个头并行学习,模型能够在不同的特征维度上捕捉丰富的上下文信息。
信息并行处理
由于每个头的计算是并行进行的,模型可以高效地处理大规模输入。相比于顺序处理的 RNN,注意力机制本身支持并行,而多头机制进一步增强了这一点。这样可以在不增加计算复杂度的情况下提升表达能力。
防止信息丢失
如果只有一个头,可能会错过某些重要的依赖关系或特征。多头注意力可以从不同的角度分析同一个输入,从而降低了忽略重要信息的风险。例如:
- 一个头可能从词汇级别捕捉依赖,而另一个头可能关注句子结构或语义层面。
举例说明:生活场景类比
想象你在听一场演讲,但你邀请了几位朋友一起来,他们每个人都有不同的特长或关注点。你们每个人在听演讲时,都会关注不同的方面:
-
朋友A 对演讲者的语音语调感兴趣,专注于分析说话方式。
-
朋友B 专注于演讲内容的逻辑性,思考信息是否一致和有条理。
-
朋友C 关注演讲中的背景数据,试图理解数据的来源和合理性。
最终,你们会汇总每个人的理解,整合成对演讲的全面认识。
在这个例子中,每个朋友代表多头注意力中的一个头。每个朋友关注的点不同,但都是对同一个演讲的信息进行处理。最后,你将不同的意见和见解整合起来,形成对演讲的完整理解,这类似于多头注意力机制中不同头的输出拼接后,再通过线性变换生成最终的结果。
多头注意力机制通过并行运行多个注意力头,使得模型能够从多个角度分析输入序列,捕捉丰富的特征和依赖关系。每个头学习不同的语义特征,从长距离到短距离依赖关系都能得到有效建模。多头注意力的设计使 Transformer 模型在处理自然语言任务时既高效又具备强大的表达能力,这也是 Transformer 相比于传统序列模型的重要优势之一。
6、多层编码器串行
在 Transformer 模型中,编码器(Encoder) 是由多个串行的编码器层(Encoder Layers)堆叠而成的。每个编码器层内部包含自注意力机制、多头注意力、前馈网络等模块。那么,为什么我们需要将多个这样的编码器层串联起来,而不是使用单一层来完成任务呢?
原因:逐层构建更复杂的表示
多个串行编码器层的堆叠使得模型能够逐步构建输入的表示,这个过程类似于逐层“精炼”和“抽象”输入的信息。每一层编码器都在输入的基础上捕捉到更多的上下文信息,并将更复杂的特征传递给下一层,从而使得模型能够处理复杂的依赖关系和特征。这种逐层构建的方式有几个关键的原因:
捕捉更长距离的依赖关系
单层的自注意力机制可以帮助捕捉句子中不同位置的依赖关系,但是经过多层的堆叠,这种能力进一步增强。例如,在较低层次时,模型可能只捕捉到短距离的依赖关系,如名词与其形容词之间的联系;而在更高层,模型可以捕捉到更长距离的依赖关系,如主语和动词之间的联系。
-
低层次捕捉局部特征:底层编码器层倾向于捕捉输入的局部特征,比如单词的基础含义和相邻单词之间的简单关系。
-
高层次捕捉全局语义:越往高层,模型会逐渐捕捉到句子中整体语义和长距离依赖。这对于复杂的语言现象,如嵌套的从句、跨段落的联系,尤为重要。
信息的逐层处理与抽象
多层编码器堆叠类似于传统深度神经网络的多层抽象。每层编码器可以看作是对输入数据进行不同级别的抽象和处理,逐层提取出更高层次的特征。例如:
-
在前几层,编码器可能处理的是较为具体的词汇信息,如单词的词义。
-
随着层数增加,模型可能开始关注更复杂的句法结构,甚至语义信息。
这种逐层抽象的过程类似于人类的理解方式:我们首先通过观察具体的词句,接着再逐步理解它们的意思,并将这些信息整合到对全文的理解中。
提升模型的表达能力
通过增加编码器层的深度,Transformer 模型的表达能力显著增强。深层网络比浅层网络具有更强的非线性表达能力,能够学习到更复杂的数据模式。多层编码器能够捕捉更加多样化的特征,使得模型能够应对更多样的任务和数据集。
例如,在语言翻译任务中:
-
浅层编码器 可能专注于逐字翻译或简单的短语解析。
-
深层编码器 则可以处理更复杂的语义转换,跨越多个单词或短语进行重新组织以符合目标语言的语法和逻辑。
信息的逐步聚合与精炼
每层编码器都会从上一层获得输入,将其通过自注意力机制、多头注意力和前馈网络处理后,输出更加“精炼”的表示。多个编码器层的堆叠相当于对输入信息的逐步过滤和聚合,类似于通过多次迭代来找到最相关的信息和特征。
比如在句子“I love AI because it is revolutionary”中:
-
第1层编码器 可能只关注到单词的局部关系,如“love”和“AI”之间的联系。
-
第3层编码器 可能会识别到整个句子的逻辑关系,如“because”引导的因果关系。
-
第6层编码器 则可能完全理解到句子的语义层次:AI 被认为是革命性的原因。
处理复杂依赖关系
自然语言中的依赖关系往往是复杂的,不仅存在于局部短距离的词与词之间,还可能存在于整个句子或段落之间的长距离依赖。通过堆叠多层编码器,模型可以逐层从局部信息扩展到全局信息,逐步理解语言中的复杂结构和语义。
例如,在长句子中,主语和谓语动词可能相隔很远,单层的注意力机制可能难以捕捉这种长距离的依赖关系。多层编码器能够更好地捕捉这些复杂的关系,通过逐层信息传递,使模型能够建模语言中的层次结构。
生活中的类比
想象你正在学习一个新技能,比如打网球。刚开始学时,你可能会专注于简单的任务:如何握拍、如何站位。这类似于 Transformer 的低层编码器,处理简单的、局部的任务。
随着你逐渐熟悉基础操作,你开始学习如何控制球的方向、力度,并且开始注意到如何与对手互动。这类似于模型中的中层编码器,逐渐学会处理更复杂的关系。
最后,当你成为一名经验丰富的球员时,你不仅能够控制每一个动作,还能预判对手的行为,调整自己的策略。这相当于 Transformer 的高层编码器,处理的是全局的、高层次的策略和行为。
通过逐层训练和信息处理,你从最基础的技能一步步提升,直到能够处理最复杂的情况。这正是多层编码器在 Transformer 中的作用——逐层处理并聚合信息,从简单到复杂,逐步构建对输入序列的深层次理解。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相关文章:
【AI大模型】Transformer中的编码器详解,小白必看!!
前言 Transformer中编码器的构造和运行位置如下图所示,其中编码器内部包含多层,对应下图encoder1…encoder N,每个层内部又包含多个子层:多头自注意力层、前馈神经网络层、归一化层,而最关键的是多头自注意力层。 自注…...

PostgreSQL 字段按逗号分隔成多条数据的技巧与实践 ️
全文目录: 开篇语前言 📚1. PostgreSQL 字段拆分的基本概念 🎯2. 使用 string_to_array 函数拆分字段 💬示例:使用 string_to_array 拆分字段结果: 3. 使用 unnest 和 string_to_array 结合拆分 ǵ…...
)
设计模式学习总结(一)
设计模式学习笔记 面向对象、设计原则、设计模式、编程规范、重构之间的关系 面向对象、设计原则、设计模式、编程规范、重构之间的关系 面向对象 现在,主流的编程范式或者是编程风格有三种:面向过程、面向对象和函数式编程。 需要掌握七大知识点&#…...

软考中级 软件设计师 上午考试内容笔记(个人向)Part.1
软考上午考试内容 1. 计算机系统 计算机硬件通过高/低电平来模拟1/0信息;【p进制】: K n K n − 1 . . . K 2 K 1 K 0 K − 1 K − 2... K − m K n r n . . . K 1 r 1 K 0 r 0 K − 1 r − 1 . . . K − m r − m K_nK_{n-1}...K_2K_1K_0K…...

PHP API的数据交互类型设计
PHP API的数据交互类型设计涉及多个方面,包括请求方法、数据格式、安全性考虑等。以下是对PHP API数据交互类型设计的详细探讨: 一、请求方法 在PHP API中,常见的请求方法包括GET、POST、PUT、DELETE等。这些方法在数据交互中各有其用途和特…...

【EFK】Linux集群部署Elasticsearch最新版本8.x
【EFK】Linux集群部署Elasticsearch最新版本8.x 摘要环境准备环境信息系统初始化启动先决条件 下载&安装修改elasticsearch.yml控制台启动Linux服务启动访问验证查看集群信息查看es健康状态查看集群节点查询集群状态 生成service token验证service tokenIK分词器下载 摘要 …...

【大数据测试 Elasticsearch — 详细教程及实例】
大数据测试 Elasticsearch — 详细教程及实例 1. Elasticsearch 基础概述核心概念 2. 搭建 Elasticsearch 环境2.1 安装 Elasticsearch2.2 配置 Elasticsearch 3. 大数据测试的常见方法3.1 使用 Logstash 导入大数据3.2 使用 Elasticsearch 的 Bulk API3.3 使用 Benchmark 工具…...
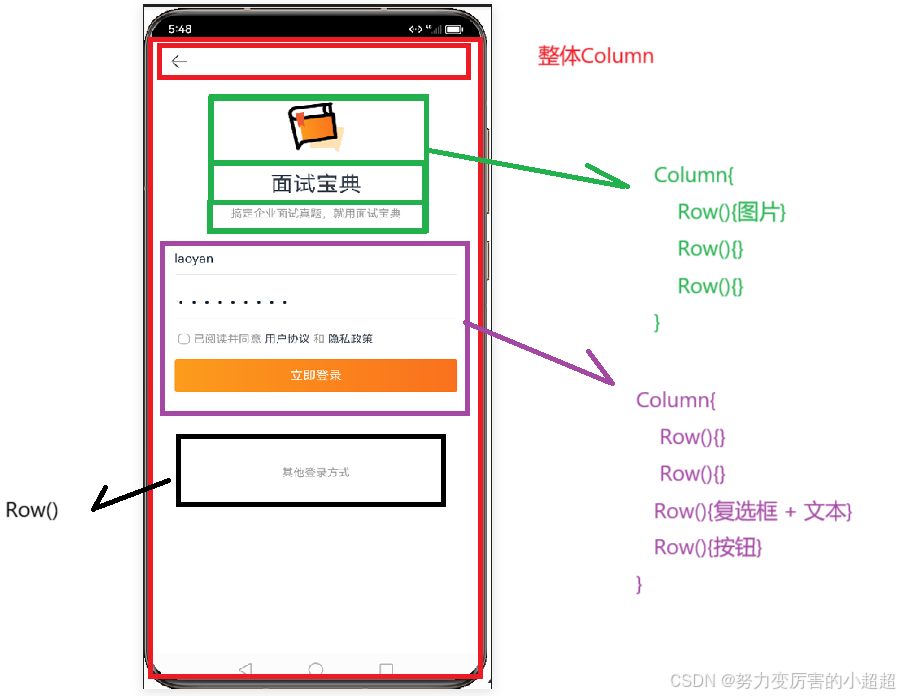
用ArkTS写一个登录页面(实现简单的逻辑)
登录页面 1.登录页面编码 Extend(TextInput) function customStyle(){.backgroundColor(#fff).border({width:{bottom:0.5},color:#e4e4e4}).borderRadius(1) //让圆角不明显.placeholderColor(#c3c3c5).caretColor(#fa711d) //input获取焦点样式 }Entry Component struct Log…...

matlab将INCA采集的dat文件多个变量批量读取到excel中
参考资料: MATLAB处理INCA采集数据(mdf,dat等)一 使用matlab处理INCF采集数据,mdf(.dat)格式文件,并将将其写入excel文件 这个资料只能一个变量一个变量的提取,本对其进…...

list集合常见去重方式以及效率对比
1.概述 list集合去重是开发中比较常用的操作,在面试中也会经常问到,那么list去重都有哪些方式?他们之间又该如何选择呢? 本文将通过LinkedHashSet、for循环、list流toSet、list流distinct等4种方式分别做1W数据到1000W数据单元测试…...

JavaWeb——Web入门(7/9)-Tomcat-介绍(Tomcat 的简介:轻量级Web服务器,支持Servlet/JSP少量JavaEE规范)
目录 Web服务器的作用 三个方面的讲解 Tomcat 的简介 小结 Web服务器的作用 封装 HTTP 协议操作:Web服务器是一个软件程序,对 HTTP 协议的操作进行了封装。这样开发人员就不需要再直接去操作 HTTP 协议,使得外部应用程序的开发更加便捷、…...

【SpringBoot】19 文件/图片下载(MySQL + Thymeleaf)
Git仓库 https://gitee.com/Lin_DH/system 介绍 从 MySQL 中,下载保存的 blob 格式的文件。 代码实现 第一步:配置文件 application.yml spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT8datasource:driver-class-name: com.mysql.…...

陪诊问诊APP开发实战:基于互联网医院系统源码的搭建详解
时下,开发一款功能全面、用户体验良好的陪诊问诊APP成为了医疗行业的一大热点。本文将结合互联网医院系统源码,详细解析陪诊问诊APP的开发过程,为开发者提供实用的开发方案与技术指导。 一、陪诊问诊APP的背景与功能需求 陪诊问诊APP核心目…...

Spark 中 RDD 的诞生:原理、操作与分区规则
Spark 的介绍与搭建:从理论到实践-CSDN博客 Spark 的Standalone集群环境安装与测试-CSDN博客 PySpark 本地开发环境搭建与实践-CSDN博客 Spark 程序开发与提交:本地与集群模式全解析-CSDN博客 Spark on YARN:Spark集群模式之Yarn模式的原…...

c++构造与析构
构造函数特性 名称与类名相同:构造函数的名称必须与类名完全相同,并且不能有返回值类型(包括void)。 自动调用:构造函数在对象实例化时自动调用,不需要手动调用。 初始化成员变量:构造函数的主…...

C++(函数重载,引用,nullptr)
1.函数重载 C⽀持在同⼀作⽤域中出现同名函数,但是要求这些同名函数的形参不同,可以是参数个数不同或者类型不同。传参时会自动匹配传入的参数,对应该函数的形参类型,进行函数调用,这样C函数调⽤就表现出了多态⾏为&a…...

django+postgresql
PostgreSQL概述 PostgreSQL 是一个功能强大的开源关系数据库管理系统(RDBMS),以其高度的稳定性、扩展性和社区支持而闻名。PostgreSQL 支持 SQL 标准并具有很多先进特性,如 ACID 合规、复杂查询、外键支持、事务处理、表分区、JS…...
)
前端滚动锚点(点击后页面滚动到指定位置)
三个常用方案:1.scrollintoView 把调用该方法的元素滚动到屏幕的指定位置,中间,底部,或者顶部 优点:方便,只需要获取元素然后调用 缺点:不好精确控制,只能让元素指定滚动到中间&…...

使用SSL加密465端口发送邮件
基于安全考虑,云虚拟主机的25端口默认封闭,如果您有发送邮件的需求,建议使用SSL加密端口(465端口)来对外发送邮件。本文通过提供.NET、PHP和ASP样例来介绍使用SSL加密端口发送邮件的方法,其他语言的实现思路…...
一些面试题总结(一)
1、string为什么是不可变的,有什么好处 原因: 1、因为String类下的value数组是用final修饰的,final保证了value一旦被初始化,就不可改变其引用。 2、此外,value数组的访问权限为 private,同时没有提供方…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

Java编程之桥接模式
定义 桥接模式(Bridge Pattern)属于结构型设计模式,它的核心意图是将抽象部分与实现部分分离,使它们可以独立地变化。这种模式通过组合关系来替代继承关系,从而降低了抽象和实现这两个可变维度之间的耦合度。 用例子…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...