ElasticSearch学习篇16_《检索技术核心20讲》进阶篇之空间检索
背景
学习极客实践课程《检索技术核心20讲》https://time.geekbang.org/column/article/215243,文档形式记录笔记。
相关问题:
- 查询范围固定的需求
- 直接计算两点之间距离
- 区域二进制编码
- GeoHash编码
- 查询范围不固定的需求
- GeoHash编码索引结构设计
- 基于哈希表的倒排
- 有序数组
- 四叉树、非满四叉树
- 前缀树
- GeoHash编码索引结构设计
查询范围固定的需求
比如社交软件可以浏览附近的人,查找某位置附近的餐厅等场景,范围是固定多远的查询
一个容易想到的方案就是把所有人的坐标取出来,计算每个人和当前坐标的距离,然后排序依次列出来。
这种方案在少量数据下或许可行,数据量大的时候计算成本、全排序成本会变非常大,尽管排序成本可以采用堆排序代替全排序来降低代价,但是计算成本也是很大的开销。
非精确查找附近的人
类似检索相关网页,不需要明确的检索目标,只需要保证质量足够高的结果包含在TopK中。
一种思路
- 缩小检索范围:一般而言相同城市的人比不同城市的人距离会更近,所以可以缩小检索范围,不需要计算全部目标到当前的距离。
- 建立区域索引:在这种限定 “附近”区域的检索方案中,为了进一步提高检索效率,我们可以将所有的检索空间划分为多个区域并编号,然后以区域编号为key做好索引,当需要查询附近的人的时候,先快速查询所属区域,然后将区域所有人位置取出来,然后在计算距离排序。
建立区域索引
采用二分的思想均匀划分平面区域,采用0、1进行编码,如下面图,每一次划分增加两位比特位
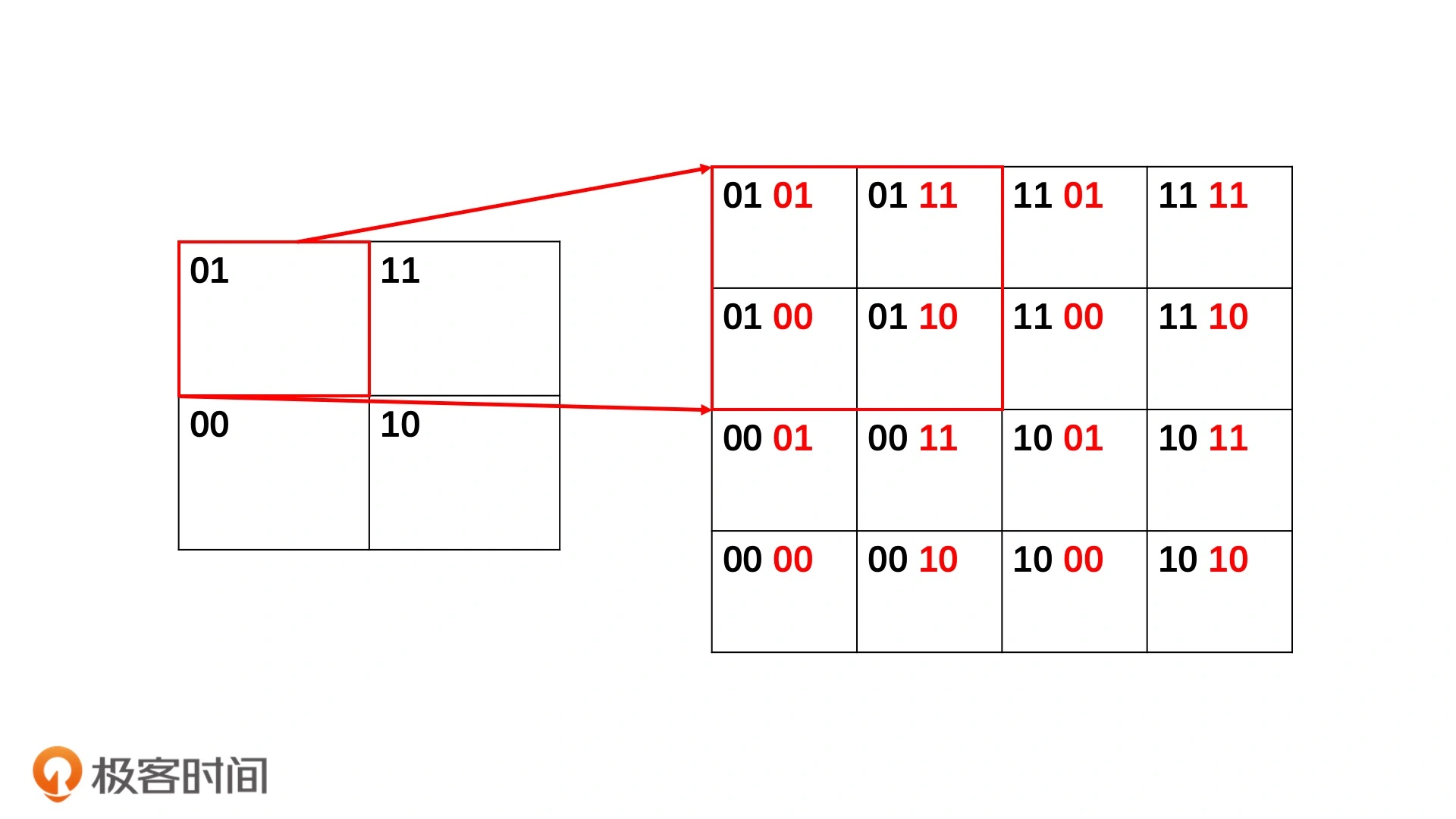
这样划分优点
- 区域有层次关系:如果两个区域的前缀是相同的,说明他们是由一大块区域切分的。
- 区域编码带有分割意义:垂直方向: 下0上1、水平方向:左0右1
区域检索
对区域编码划分之后,二维空间的两个维度可以使用一维的编码表示了,就能转为一维检索了,可以使用
- 有序的数组二分查找:适合固定的区域
- 哈希表:适合希望检索速度更高的场景
- 二叉检索树、跳表等:适合有效区域动态增加以及区域范围查询
查询某个区域,然后把全部的人位置都找出来,计算距离以及全排序
这种非精准的检索方案,对结果会带来一定的误差,因为二维空间计算距离使用的勾股定理,所以其他周边区域可能会存在更近的点。
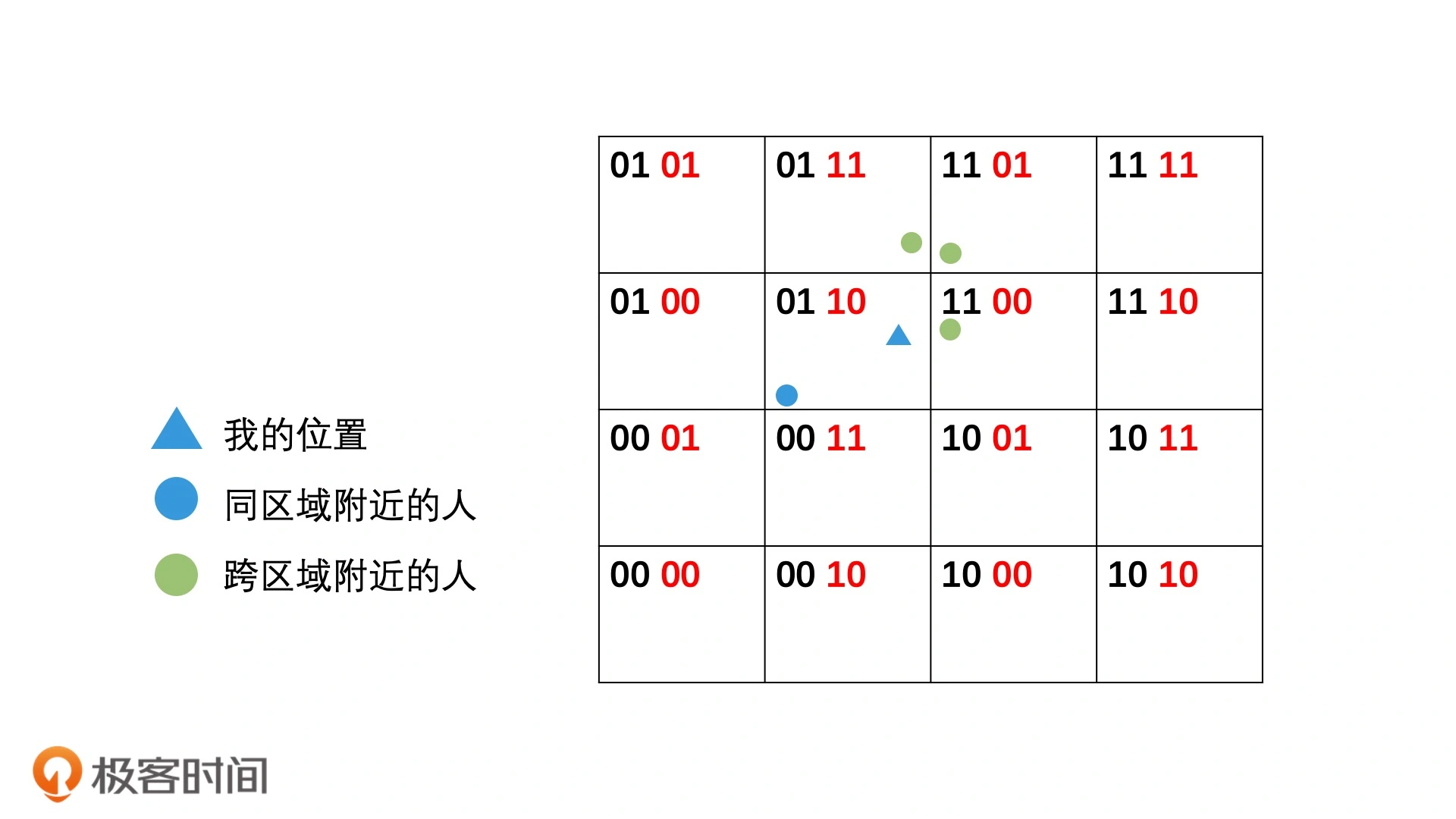
对于精确查询需求不高的应用中,如查找附近的人,也是可以接受的。
精确查询附近的人
针对非精确查询附近的人又可能会存在误差的情况,可以采用一些方式避免这种误差,这也就是精准查询场景需要的。
- 建立更大的候选集包含邻近集合:将8个邻接区域都放入候选集,会导致计算量提高8倍。
- 提高区域划分粒度减少计算量:在这9个区域划分更新粒度的区域,就是在这9个区域中找出一个边长为r的区域,可以减少需要排序的用户数量。
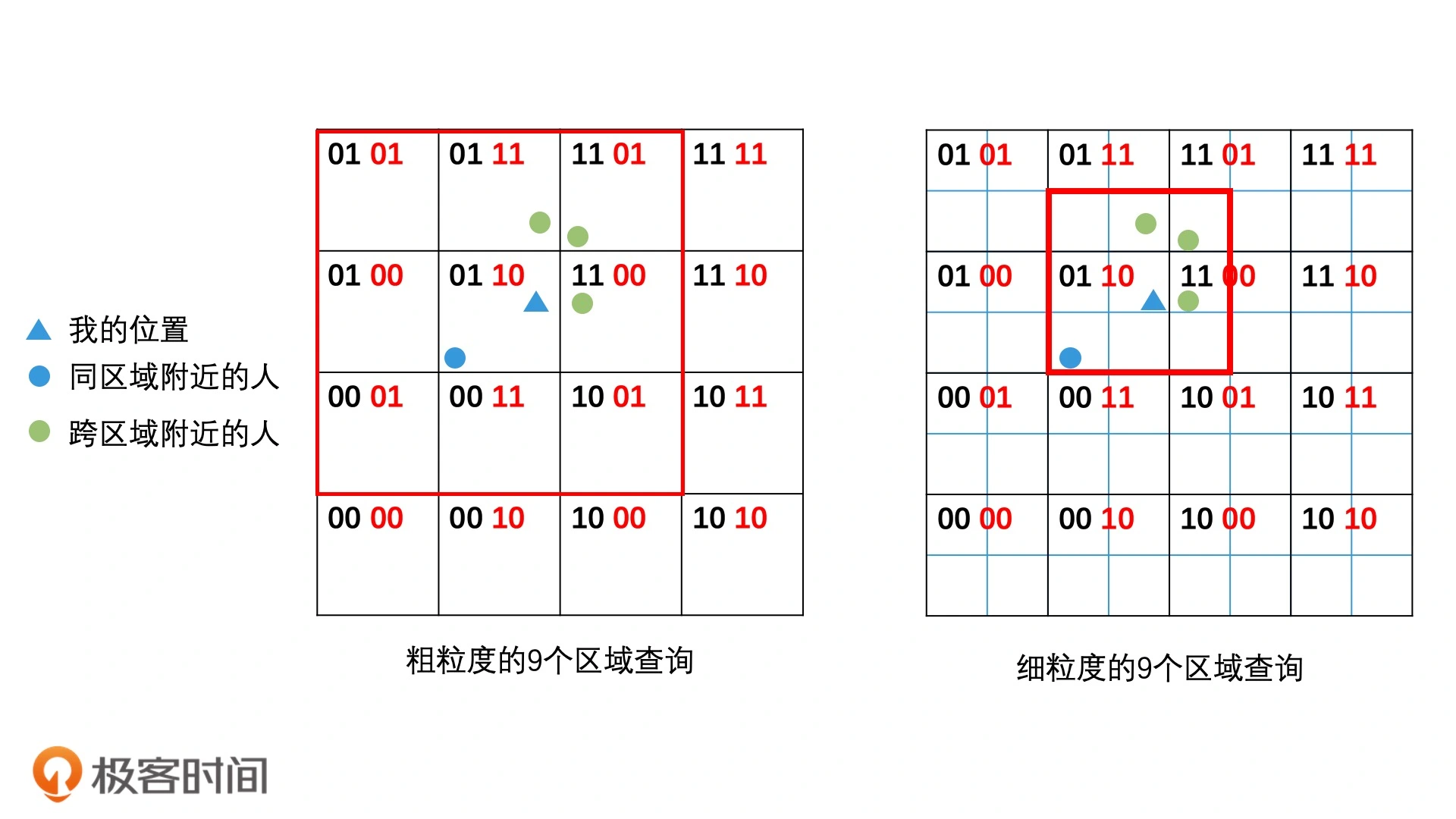
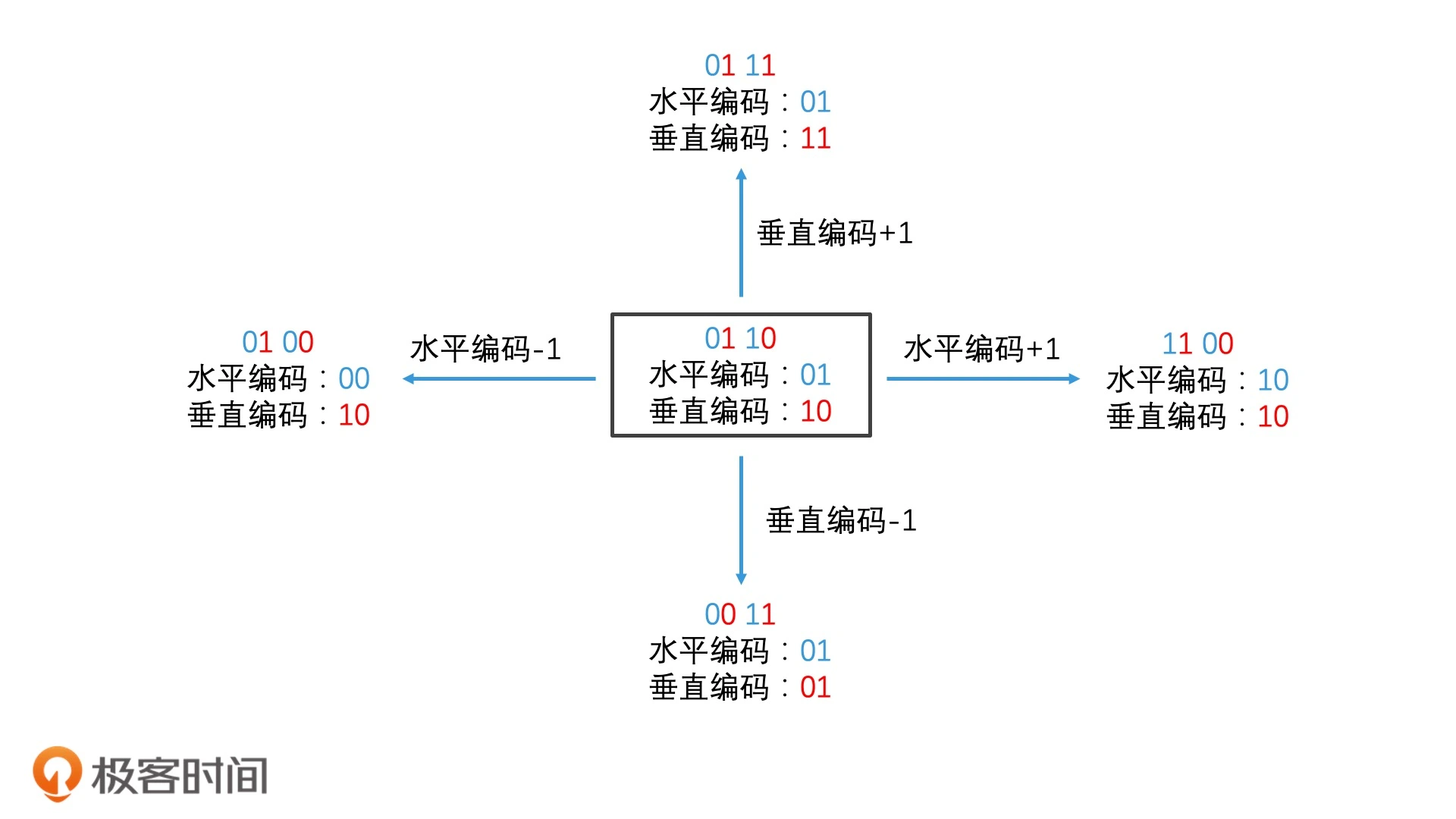
可以根据编码规律快速找邻接区域
Geohash编码
在实际场景中,用户对应的就是经纬度,如何转化为二维空间,依靠的就是按照经纬度将地球划分为一个巨大的二维空间。
地球的纬度区间是[-90,90],经度是[-180,180]。如果给出的用户纬度(垂直方向)坐标是 39.983429,经度(水平方向)坐标是 116.490273,按照粗粒度的两次划分,那我们求这个用户所属的区域编码的过程,就可以总结为 3 步:
- 在维度进行一次二分,第一次二分,39.98在[0,90]之间,属于北维,因此编码为0,然后在[0,90] 进行第二次二分,39.983429 在[0,45]之间,得到的编码为0,因此得到的编码就是00。
- 在经度进行一次二分,第一次二分,116.490273在[0,180],属于右半边,因此编码为1,然后再[0,180]进行第二次二分,116.490273 在 [90,180] 之间,还是属于区间的右半边,编码还是1,两次划分之后,得到的编码就是11。
- 把经度和纬度的编码交叉组合,先是经度再是维度,这样构成区域编码为0101.
上面进行了两次划分,如果划分的细的话就需要多次持续划分,每划分一位就是新增一位比特位。如经度和纬度各二分15次的话,那么比特位就是30位,为了解决长度较长的问题,可以将长编码转为base32,最终得到一个字符串如wx4g6y,只需要6位即可存储,而且具有相同前缀的属于同一大区域。这种将经纬度坐标转换为字符串的编码方式,就叫作 Geohash 编码。
编码规则,1位的base32编码可以最多表示5位的bit,因为32=25
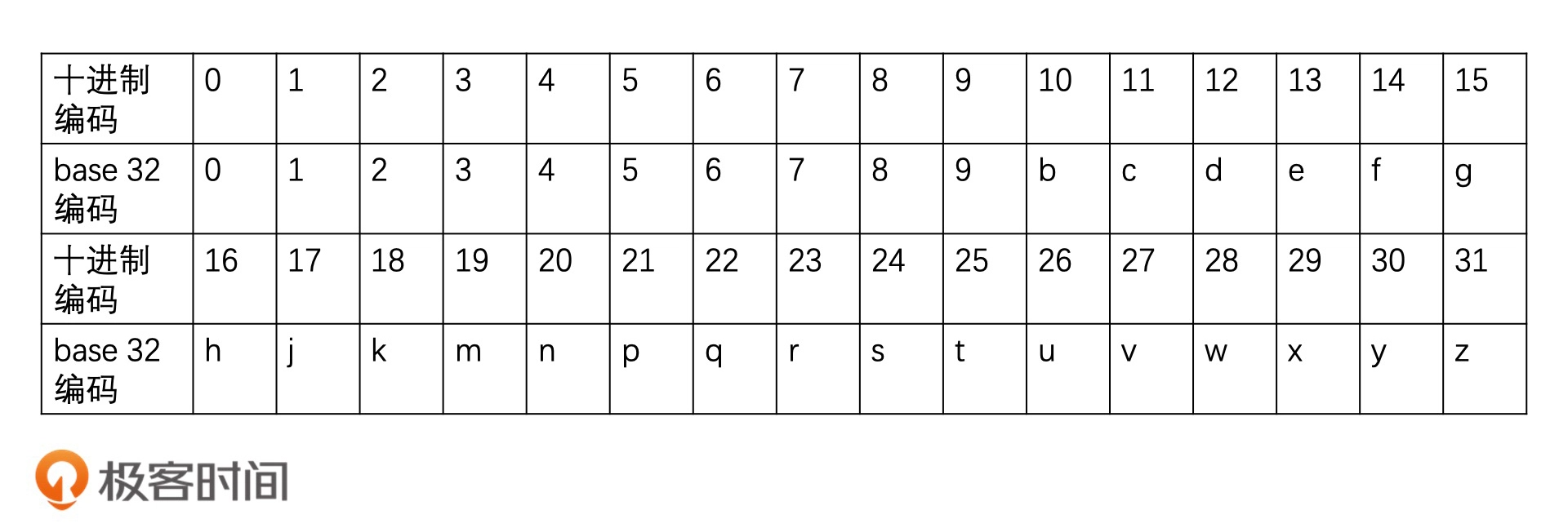
划分次数决定bit的长度,对应不同长度的Geohash编码对应表示的范围也不一样,对应的精度也不一样,

Geohash编码也有缺点,由于Geohash编码的一个字符就代表了5比特位,因此每当字符长度变化一个单位,区域的覆盖变化跨度就是32倍(2的5次方),导致区域划分不够精细。
因此对于存储和计算一般还是使用二进制bit来进行。
思考:如果一个应用期望支持“查找附近的人”的功能。在初期用户量不大的时候,我们使用什么索引技术比较合理?在后期用户量大的时候,为了加快检索效率,我们又可以采用什么检索技术?为什么?
- 初期用户量不大,可以采用直接计算距离的方式,用户会动态增长,另外需要支持范围查询,可以采用树、跳表保存区域的key,value保存用户的坐标数据。
- 后期用户量大了,可以使用倒排索引,以区域的key建 倒排索引。
思考:如果之前的应用选择了 5 个字符串的 Geohash 编码,进行区域划分(区域范围为 4.9 km * 4.9 km),那当我们想查询 10 公里内的人,这个时候该如何进行查询呢?使用什么索引技术会比较合适呢?
可以利用区域编码前缀一致的特点,大区域内的小区域前缀是一致的,转为bit之后向外取两圈。
查询范围不固定的需求
相比上面查询,范围不是固定的,而是具体需要多少个结果,系统会根据期望结果数量调整查询范围以便最终达到目标结果。
比如查询某个地址距离最近的前K个加油站,可能需要进行多次查询,多次扩大查询范围,查询多次外圈,最后合并查询结果。
将区域按照经纬度分块,然后在GeoHash编码
- 第一种思路:逐层向外查询区域,第一次查询当当前位置所在的块,第二次查找当前位置所在快的8个邻接块,第三次再向外层查找16个邻接块…。特点就是查询次数比较多。
- 第二种思路:每次查询去掉最后一位的GeoHash位置编码,大幅扩大查询范围,这样一个8位的GeoHash编码只需要查询8次即可,如果需要精确查询不漏数据,那么每次都需要向外扩展周围的8个和当前块大小相等的邻接区域。虽然查询次数比较少,但是需要选用合适的索引来处理GeoHash每层的数据,确保每层查询效率。
GeoHash每层的索引设计
比如GeoHash每次去除最后一位来扩大检索范围,为了保证效率,需要每个粒度层上都分别建立一个索引。可选的数据结构
- 基于哈希的倒排表实现:该倒排索引存储存储目标、目标位置(类似关键词和文档docId的关系),这种方式缺点是必须针对不同的粒度给某个目标创建多个GeoHash位置编码(如3-12位,表示8层)
- 基于GeoHash编码一维可排序的特点,使用数组或者二叉树实现,相比于上面的哈希表,只需要给最小粒度层建立一个有序数组,当需要检索更大的范围的时候,只需要调整左、右指针范围查询即可。这种方式的缺点是每次查询某个区域都需要一次完整完整的二分。
- 使用支持动态调整范围的四叉树,根据查询要求TopK支持动态调整查询区域,而不是每次都从root根节点查询,可快速的查询父节点的其他孩子节点区域,加快检索效率。
- 前缀树
1、基于哈希表的倒排索引
基于哈希表实现的倒排索引为什么每个层级需要存储全部的加油站索引信息?因为每个加油站在地区范围粒度不同的情况下可以对另不同位数的GeoHash编码,比如(3-12)位不等。
假设我们有一组加油站的数据,这些加油站分布在一个城市内。为了实现地理位置的快速检索,我们使用 GeoHash 进行编码,并基于此构建倒排索引。GeoHash 将地理位置编码为一串字符,这些字符的长度可以决定编码的粒度(即精度)。
假设我们有以下三个加油站,它们的坐标经过 GeoHash 编码后在不同层级的结果如下:
- 加油站A:城市粒度GeoHash 编码(3个字符)为
wx4,县城粒度(5个字符)为wx4g0 - 加油站B:城市粒度GeoHash 编码(3个字符)为
wx4,县城粒度(5个字符)为wx4g1 - 加油站C:城市粒度GeoHash 编码(3个字符)为
wx4,县城粒度(5个字符)为wx4g2
在3个字符的城市粒度GeoHash编码下,我们建立一个倒排表:
wx4-> [加油站A, 加油站B, 加油站C]
在5个字符的粒度下,我们也要建立各自的倒排表:
wx4g0-> [加油站A]wx4g1-> [加油站B]wx4g2-> [加油站C]
在这种情况下,加油站A、B、C的记录会在每个不同粒度的层级上都存储一次。这就导致数据的重复存储,如果城市中有成千上万的加油站和多个粒度级别,这种重复将非常显著,带来很大的存储开销。
优化方案之一是在不同粒度的级别上设计参考关系,而不是直接存储所有加油站详细信息,以避免重复冗余。
2、基于有序数组的索引
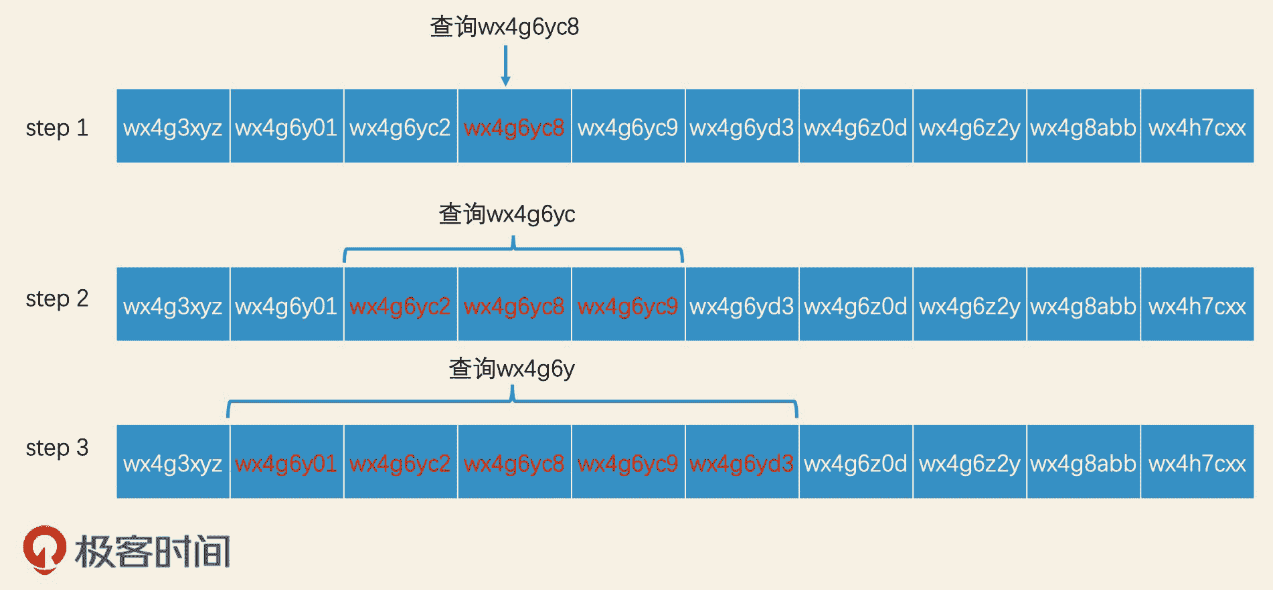
举个例子。在检索完 wx4g6yc8 这个区域编码以后,如果结果数量不够,还要检索 wx4g6yc 这个更大范围的区域编码,我们只要将查询改写为“查找区域编码在 wx4g6yc0 至 wx4g6ycz 之间的元素”,就可以利用同一个索引,来完成更高一个层级的区域查询了。同理,如果结果数量依然不够,那下一步我们就查询“区域编码在 wx4g6y00 至 wx4g6yzz 之间的元素”,依此类推。
3、支持动态调整范围的四叉树
许多系统对于GeoHash的底层实现一般都是使用二进制存储和计算的。二进制的区域编码的生成又是依赖二分,和树结构比较像,而且又是二维区域,因此可以使用树形结构索引,因此考虑四叉树。
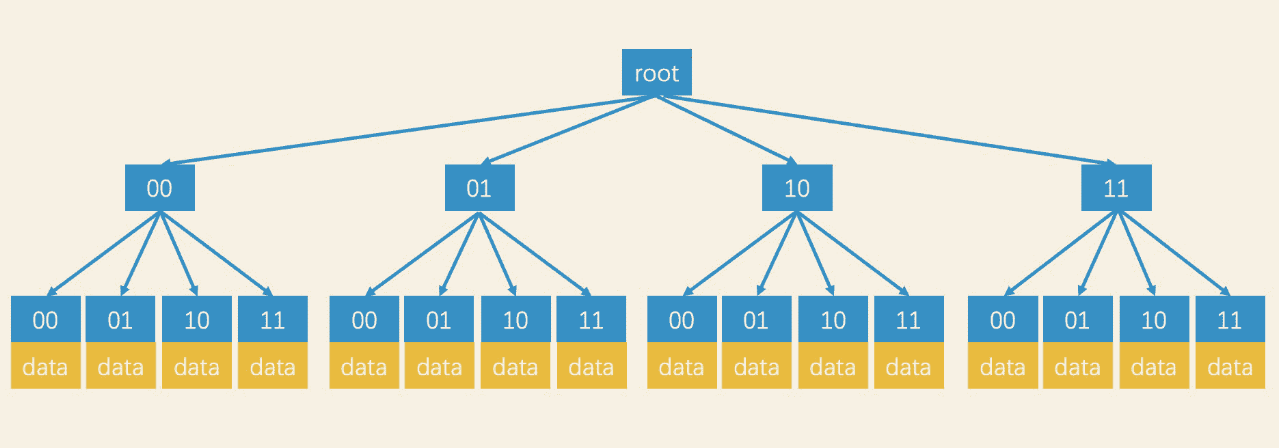
- 四叉树的根节点代表整个空间,不断四分形成子节点,直到最小粒度
- 叶子结点存数据,其他子节点存指针。
采用树的一个好处就是树的查询支持回溯,可以不用每次都从根节点。加入叶子结点的粒度是四位,如果查询目标区域编码是0110,那么在就可以四叉树上沿着分支查询,查询路径就是01–>10,如果
- 查找到了叶子节点,并且满足了TopK查询,直接返回
- 查找到了叶子节点,不满足TopK查询,需要递归回溯到上一层父节点,查询父节点的其他孩子。这样就避免了每次都从root根节点查询,加快了效率,从而实现动态调整查询范围。
支持动态节点分裂四叉树优化存储空间
前面说的都是满四叉树,最小区域单位为叶子节点,能够一定程度增加检索效率。
但是对于数据稀疏的时候,有些叶子节点仍然会会被划分占用空间,假设我们有一个大型的二维空间,其中只有少数几个数据点。如果我们使用满四叉树来划分,即使叶子节点不涉及存储具体的数据点信息,仍然需要开辟空间。
因此可以采用支持动态节点分裂的四叉树来优化存储空间,具体的设计
- 开局是一个根节点,规定每个节点存储的容量为N
- 当数据量小于N的时候,直接插入。读取的时候也是直接把所有数据读取出来,然后再排序。
- 当生活量大于N的时候,插入前需要分裂,具体就是将当前待分裂节点转为中间节点,生成1-4个子节点,然后转移数据到子节点。
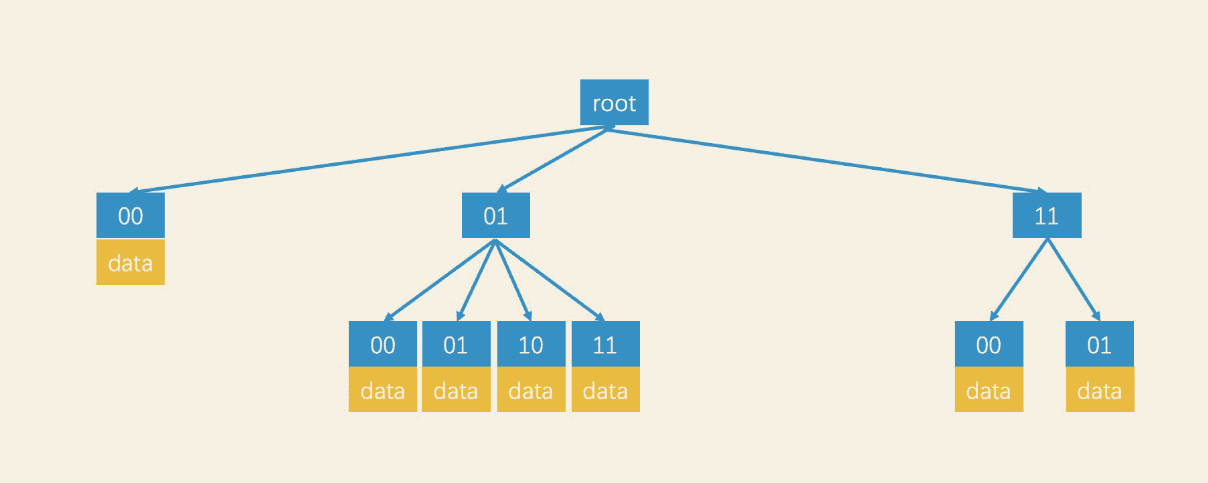
这种设计思路,可以减少无用叶子节点的数量,优化空间存储效率。
4、前缀树优化GeoHash索引
前面使用的都是将Geohash编码转为二进制,下面可以使用Trie前缀树进行优化GeoHash编码,直接使用字符的形式,相当于非满32叉树。
检索思路和四叉树类似,点就是树不会那么高了。
“举个例子,当我们查询 wx4g6yc8 这个区域时,我们会沿着 w-x-4-g-6-y-c-8 的路径,检索到对应的叶子节点,然后取出这个叶子节点上存储的数据。如果这个区域的数据不足 k 个,就返回到父节点上,检索对应的区域,直到返回结果达到 k 个为止。”
高维空间紧邻检索的其他结构
- 八叉树:三纬空间的一个树形检索结构
- k-d树:k-d 树一种是更通用的,对任意维度都可以使用的检索方案。不同于四叉树、八叉树,他不会划分为2^k个子空间,而是二分,只不过每次都二分的纬度不一样,实际上是一个二叉树。“k-d 树在维度规模不大的场景下,确实具有不错的检索效率。但是,在成百上千的超高维度的场景中,k-d 树的性能会急剧下降。
- bk-d树:参考往期博客ElasticSearch学习篇10_Lucene数据存储之BKD动态磁盘树(论文Bkd-Tree: A Dynamic Scalable kd-Tree)_bkd树-CSDN博客
相关文章:
ElasticSearch学习篇16_《检索技术核心20讲》进阶篇之空间检索
背景 学习极客实践课程《检索技术核心20讲》https://time.geekbang.org/column/article/215243,文档形式记录笔记。 相关问题: 查询范围固定的需求 直接计算两点之间距离区域二进制编码GeoHash编码 查询范围不固定的需求 GeoHash编码索引结构设计 基于…...

uni-app跨域set-cookie
set-cookie的值是作为一个权限控制的 首先,无论什么接口都会返回一个set-cookie,但未登录时,set-cookie是没有任何权限的 其次,登录接口请求时会修改set-cookie,并且在后续其他接口发起请求时,会在请求头…...

移动应用开发:简易登录页
文章目录 简介一,创建新活动二,设计UI布局三,编写活动代码四,运行应用程序注意 简介 使用Android Studio编写的简单Android 登录应用程序,该应用程序包含一个登录界面,具有账号和密码两个文本框࿰…...

C++_ C++11的override和final
文章目录 1. override 关键字2. final 关键字在虚函数上使用 final在类上使用 final 1. override 关键字 用于明确表示派生类中的某个虚函数是用来重写基类中的虚函数的,这样编译器会检查基类,看看是否确实存在同样的虚函数,如果没有匹配&am…...

【MyBatis源码】SQL 语句构建器AbstractSQL
文章目录 介绍org.apache.ibatis.jdbc.SQLSQL类使用示例SelectProvider搭配动态SQLAbstractSQL类源码分析 介绍 当我们需要使用Statement对象执行SQL时,SQL语句会嵌入Java代码中。SQL语句比较复杂时,我们可能会在代码中对SQL语句进行拼接,查…...

C++OJ_二叉树的层序遍历
✨✨ 欢迎大家来到小伞的大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:C_OJ 小伞的主页:xiaosan_blog 二叉树的层序遍历 102. 二叉树的层序遍历 - 力扣(LeetCode࿰…...

什么是直方图算法
什么是直方图算法? 直方图算法是一种优化决策树分裂点搜索效率的算法,被广泛应用于像 LightGBM 和 XGBoost 这样的梯度提升决策树框架中。其核心思想是通过将连续特征的取值范围离散化为有限的区间(称为 bins),在这些…...

pg_dump -Fc 导出的自定义格式数据库文件 相关操作
实例 将 test.dmp 文件转换为普通SQL内容, 并打印到屏幕 pg_restore -U postgres -Fc -f - test.dump将 test.dmp 文件转换为普通SQL内容, 并输出到 test.sql 文件中 pg_restore -U postgres -Fc -f test.sql -v test.dump备份得到自定义格式的数据库文件(dmp) pg_dump -U…...
Oh My Posh安装
nullSet up your terminalhttps://ohmyposh.dev/docs/installation/windows Git ee oh-my-posh: Windows上的oh-my-zsh,源地址 https://github.com/JanDeDobbeleer/oh-my-posh.git (gitee.com)https://gitee.com/efluent/oh-my-posh...

Node.js——fs模块-文件夹操作
1、借助Node.js的能力,我们可以对文件夹进行创建、读取、删除等操作 2、方法 方法 说明 mkdir/mkdirSync 创建文件夹 readdir/readdirSync 读取文件夹 rmdir/rmdirSync 删除文件夹 3、语法 其余的方法语法类似 本文的分享到此结束,欢迎大家评论区…...
)
15分钟学 Go 实战项目三 : 实时聊天室(学习WebSocket并发处理)
实时聊天室:学习WebSocket并发处理 目标概述 在本项目中,我们将创建一个实时聊天室,使用Go语言和WebSocket来处理并发消息交流。这将帮助你深入理解WebSocket协议的工作原理以及如何在Go中实现并发处理。 1. 项目需求 功能需求 用户可以…...

架构评估的方法
三种评估方法※ 第一是基于问卷(检查表)的方式,通过问卷调查对系统比较熟悉的相关人员,这种方式主观性很强。 专家问卷评估、用户问卷评估、内部团队问卷评估 第二是基于度量的方式,对系统指标完全量化,基于量化指标评价系统,这种方式需要评估者对系统非常熟悉。 软件质…...

羲和数据集收集器1.0
为了提升问答对的提取能力并完善GUI,我们从以下几个方面进行改进: 增强文本清理和解析能力:确保能够更准确地识别问答对。 支持更多文件格式:除了现有的 .txt, .docx, 和 .pdf,可以考虑支持其他常见格式如 .xlsx 等。 优化GUI设计:提供更友好的用户界面,包括进度条、日…...

ENSP OSPF和BGP引入
路由协议分为:内部网关协议和外部网关协议。内部网关协议用于自治系统内部的路由,包括:RIP和OSPF。外部网关协议用于自治系统之间的路由,包括BGP。内部网关协议和外部网关协议配合来共同完成网络的路由。 BGP:边界网关路由协议(b…...

软件工程 软考
开发大型软件系统适用螺旋模型或者RUP模型 螺旋模型强调了风险分析,特别适用于庞大而复杂的、高风险的管理信息系统的开发。喷泉模型是一种以用户需求为动力,以对象为为驱动的模型,主要用于描述面向对象的软件开发过程。该模型的各个阶段没有…...

证书学习(六)TSA 时间戳服务器原理 + 7 个免费时间戳服务器地址
目录 一、简介1.1 什么是时间戳服务器1.2 名词扩展1.3 用时间戳标记顺序1.4 7 个免费TSA时间戳服务器地址(亲测可用)1.5 RFC 3161 标准二、时间戳原理2.1 时间戳服务工作流程2.2 验证工作流程2.3 举个例子2.4 时间戳原理总结三、代码实现3.1 curl 命令请求时间戳3.2 java 代码…...

NVR设备ONVIF接入平台EasyCVR私有化部署视频平台如何安装欧拉OpenEuler 20.3 MySQL
在当今数字化时代,安防视频监控系统已成为保障公共安全和个人财产安全的重要工具。NVR设备ONVIF接入平台EasyCVR作为一款功能强大的智能视频监控管理平台,它不仅提供了视频远程监控、录像、存储与回放等基础功能,还涵盖了视频转码、视频快照、…...

c中柔性数组
c99中,结构中最后一个元素允许是未知大小的数组,这就叫柔性数组成员。 柔性数组的特点 1.结构中柔性数组前必须至少有一个其他成员 2.sizeof返回的这种结构大小不包括柔性数组的内存 3.包含柔性数组成员的结构用malloc函数进行动态分配,并…...

图像信号处理器(ISP,Image Signal Processor)详解
简介:个人学习分享,如有错误,欢迎批评指正。 图像信号处理器(ISP,Image Signal Processor) 是专门用于处理图像信号的硬件或处理单元,广泛应用于图像传感器(如 CMOS 或 CCD 传感器&a…...

越权访问漏洞
V2Board Admin.php 越权访问漏洞 ## 漏洞描述 V2board面板 Admin.php 存在越权访问漏洞,由于部分鉴权代码于v1.6.1版本进行了修改,鉴权方式变为从Redis中获取缓存判定是否存在可以调用… V2Board Admin.php 越权访问漏洞 漏洞描述 V2board面板 Admin.ph…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...