自然语言处理——Hugging Face 详解
Hugging Face 是一个以自然语言处理(NLP)为核心的人工智能平台和开源社区,提供了一系列非常流行的机器学习工具和预训练模型,尤其在文本生成、分类、翻译、情感分析等任务中表现出色。Hugging Face 旗下最为著名的项目是 Transformers 库,它为 NLP 任务提供了大量的预训练模型,并且支持多种主流深度学习框架,如 PyTorch 和 TensorFlow。
一、Hugging Face 的背景和目标
Hugging Face 旨在降低机器学习和自然语言处理的入门门槛,并使机器学习模型的训练、应用和共享更加简单、透明。其最著名的工具和平台包括:
- Transformers:提供了多种预训练的 NLP 模型,可以快速地将其应用于各种 NLP 任务,如文本生成、文本分类、情感分析、机器翻译等。
- Datasets:提供了大量公开的 NLP 数据集,可以方便地进行数据预处理和加载。
- Tokenizers:为文本处理提供了高效的分词工具,支持多种分词算法。
- Hugging Face Hub:这是一个模型存储库,用户可以上传、下载、分享模型。
Hugging Face 通过开源技术和社区支持,极大地促进了 NLP 领域的发展,尤其是在预训练模型的应用上,它推动了从机器学习到深度学习的转变。
二、Hugging Face 的核心技术——Transformers
1. Transformers 模型
Transformers 是由 Vaswani 等人在 2017 年提出的一种神经网络架构,特别适用于序列到序列(sequence-to-sequence)任务。其核心创新在于自注意力(self-attention)机制,它可以捕捉输入数据中的长程依赖关系,而不需要像传统的递归神经网络(RNN)和长短时记忆网络(LSTM)那样逐步处理输入。
Transformers 模型的主要结构包括以下几个部分:
- 自注意力机制(Self-Attention):通过计算每个单词与其他单词之间的注意力权重来建模输入序列中的依赖关系。
- 位置编码(Positional Encoding):由于 Transformer 不使用递归结构,它需要显式地引入位置编码,以便模型能够理解输入的顺序信息。
- 编码器(Encoder)和解码器(Decoder):标准的 Transformer 架构包含两个主要部分:编码器和解码器。编码器将输入序列转换为隐状态,解码器根据隐状态生成输出序列。
- 多头注意力(Multi-head Attention):为了使模型能够捕捉到不同的上下文信息,Transformer 引入了多头注意力机制。
2. 模型的微调
Hugging Face 提供的 Transformer 模型都是 预训练模型,这些模型经过大规模的文本数据训练,具有很强的迁移能力。预训练模型可以通过少量的样本进行 微调(fine-tuning),从而适应特定任务,如情感分析、命名实体识别(NER)等。
通过 Hugging Face,用户可以快速地加载预训练模型,并将其应用到自己的任务上。下面是一个基本的微调流程:
- 加载预训练模型:通过
transformers库加载预训练模型(例如 BERT、GPT、T5 等)。 - 准备数据:准备特定任务的数据集,并进行必要的预处理(例如分词)。
- 微调:通过迁移学习和梯度下降等方法,利用特定任务的数据对预训练模型进行微调。
- 评估和应用:微调后的模型可以进行评估,并用于实际的预测任务。
三、Hugging Face 源代码实现
1. 安装 transformers 库
要使用 Hugging Face 的工具,我们首先需要安装 transformers 和 datasets 库:
pip install transformers datasets2. 加载和使用预训练模型
在 Hugging Face 中加载一个预训练模型非常简单。例如,加载 BERT 模型并进行文本分类的代码如下:
from transformers import pipeline# 加载预训练的文本分类模型
classifier = pipeline("sentiment-analysis")# 进行预测
result = classifier("I love using Hugging Face!")
print(result)
在上面的代码中,pipeline 是一个高层接口,可以用来快速加载和应用各种 NLP 模型。通过 "sentiment-analysis" 任务,我们加载了一个用于情感分析的预训练模型,并使用它对输入的文本进行预测。
3. 微调模型
假设我们想对一个文本分类任务进行微调。下面是一个完整的流程,使用 transformers 和 datasets 库进行文本分类任务的微调。
from transformers import Trainer, TrainingArguments, BertForSequenceClassification, BertTokenizer
from datasets import load_dataset# 加载数据集
dataset = load_dataset("imdb")# 加载BERT tokenizer和模型
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")# 数据预处理函数
def preprocess_function(examples):return tokenizer(examples["text"], truncation=True, padding="max_length")# 对数据集进行预处理
encoded_datasets = dataset.map(preprocess_function, batched=True)# 分割训练和验证数据集
train_dataset = encoded_datasets["train"]
eval_dataset = encoded_datasets["test"]# 设置训练参数
training_args = TrainingArguments(output_dir="./results",evaluation_strategy="epoch",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=64,num_train_epochs=3,weight_decay=0.01,
)# 使用Trainer API进行微调
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,
)# 开始训练
trainer.train()# 保存模型
trainer.save_model("./finetuned_bert")
代码解释:
- 加载数据集:我们从 Hugging Face Datasets Hub 加载了
IMDB数据集,并对其进行预处理。 - 加载模型:我们加载了 BERT 模型(
bert-base-uncased),并使用其进行文本分类。 - 数据预处理:使用 BERT 的 tokenizer 对数据集进行分词,并将文本转换为模型可以理解的输入格式。
- 训练设置:使用
TrainingArguments来设置训练参数,如学习率、批量大小和训练周期数。 - Trainer:
Trainer是 Hugging Face 提供的一个高层接口,它封装了训练和评估的流程,简化了模型的训练过程。
4. 模型的保存与加载
训练完成后,我们可以保存微调后的模型,并在未来的应用中重新加载使用:
from transformers import pipeline# 加载预训练的文本分类模型
classifier = pipeline("sentiment-analysis")# 进行预测
result = classifier("I love using Hugging Face!")
print(result)
四、Hugging Face 的其他功能
除了预训练模型和微调工具外,Hugging Face 还提供了许多强大的功能:
-
Hugging Face Hub:用户可以上传自己的模型到 Hugging Face Hub,并与社区共享。模型上传后可以通过简单的 API 调用进行加载。
-
Datasets 库:Hugging Face 还提供了
datasets库,它支持从多种格式的数据集进行加载(CSV、JSON、Parquet 等),并且具备数据预处理和转换的功能。 -
Tokenizers:Hugging Face 提供了高效的 Tokenizer 库,专门用于文本数据的处理,包括分词、编码和解码等。
-
Accelerate:这是一个旨在简化多GPU和分布式训练的工具,用户可以通过几行代码快速使用多GPU进行训练。
-
Spaces:Hugging Face 还提供了一个名为 Spaces 的平台,允许用户构建和分享机器学习应用程序,并能方便地在 Web 界面上进行交互。
五、总结
Hugging Face 通过提供易用的 API、预训练模型和社区支持,极大地降低了 NLP 和深度学习的使用门槛。它的 Transformers 库让研究人员和开发者能够快速上手并在各种任务上获得很好的效果。通过微调、模型共享和高效的训练工具,Hugging Face 为 NLU(自然语言理解)任务和 NLP 研究提供了强大的支持,帮助推动了该领域的进步。
相关文章:

自然语言处理——Hugging Face 详解
Hugging Face 是一个以自然语言处理(NLP)为核心的人工智能平台和开源社区,提供了一系列非常流行的机器学习工具和预训练模型,尤其在文本生成、分类、翻译、情感分析等任务中表现出色。Hugging Face 旗下最为著名的项目是 Transfor…...

本地保存mysql凭据实现免密登录mysql
本地保存mysql凭据 mysql加密登录文件简介加密保存mysql用户的密码到本地凭据 mysql加密登录文件简介 要在 mysql客户端 上连接 MySQL 而无需在命令提示符上输入用户名和口令,下列三个位置可用于存储用户的mysql 凭证来满足此要求。 配置文件my.cnf或my.ini /etc…...

Ubuntu 22 安装 Apache Doris 3.0.3 笔记
Ubuntu 22 安装 Apache Doris 3.0.3 笔记 1. 环境准备 Doris 需要 Java 17 作为运行环境,所以首先需要安装 Java 17。 sudo apt-get install openjdk-17-jdk -y sudo update-alternatives --config java在安装 Java 17 后,可以通过 sudo update-alter…...

构建智能防线 灵途科技光电感知助力轨交全向安全防护
10月27日,在南京南站至紫金山东站间的高铁联络线上,一头野猪侵入轨道,与D5515次列车相撞,导致设备故障停车。 事故不仅造成南京南站部分列车晚点,还在故障排查过程中导致随车机械师因被邻线限速通过的列车碰撞而不幸身…...

【go从零单排】泛型(Generics)、链表
🌈Don’t worry , just coding! 内耗与overthinking只会削弱你的精力,虚度你的光阴,每天迈出一小步,回头时发现已经走了很远。 📗概念 在Go语言中,泛型(Generics)允许你编写可以处理…...
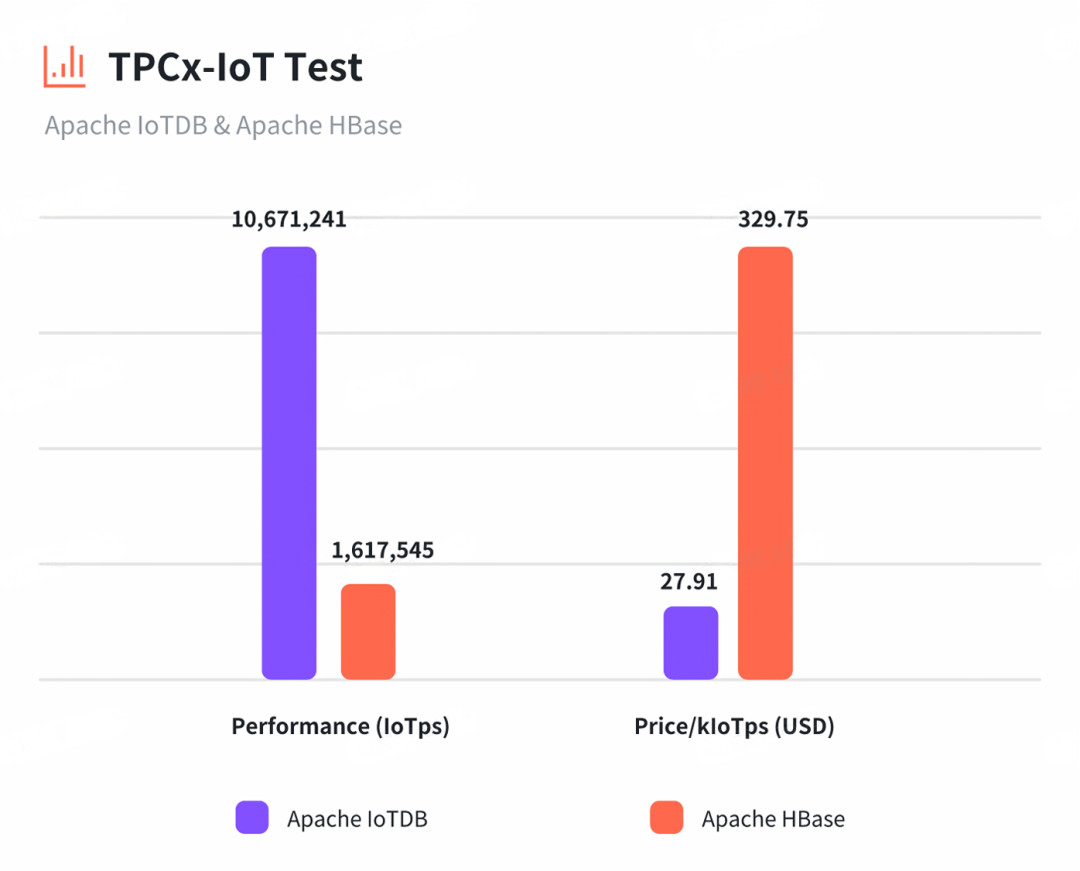
IoTDB 与 HBase 对比详解:架构、功能与性能
五大方向,洞悉 IoTDB 与 HBase 的详尽对比! 在物联网(IoT)领域,数据的采集、存储和分析是确保系统高效运行和决策准确的重要环节。随着物联网设备数量的增加和数据量的爆炸式增长,开发者和决策者们需要选择…...

推荐一款ETCD桌面客户端——Etcd Workbench
Etcd Workbench 我相信很多人在开始管理ETCD的时候都去搜了Etcd客户端工具,然后找到了官方的Etcd Manager,但用完之后发现它并不好用,还不支持多连接和代码格式化,并且已经好几年不更新了,于是市面上就有了好多其他客…...

01 Oracle 数据库存储结构深度解析:从数据文件到性能优化的全链路探究
文章目录 Oracle 数据库存储结构深度解析:从数据文件到性能优化的全链路探究一、Oracle存储结构的物理层次1.1 控制文件(Control File)1.2 联机重做日志文件(Online Redo Log File)1.3 数据文件(Data File&…...

AI教育革命:个性化学习的新篇章
内容概要 在 教育 领域,人工智能 的崭露头角带来了前所未有的变化。如今,个性化学习 已不再是一个遥不可及的梦想,而是通过 AI 技术真正实现的可能。借助先进的数据分析能力,教师可以实时跟踪和评估每位学生的学习进度࿰…...

【网络原理】万字详解 UDP 和 TCP
🥰🥰🥰来都来了,不妨点个关注叭! 👉博客主页:欢迎各位大佬!👈 文章目录 1. UDP1.1 UDP 报文格式1.1.1 源端口/目的端口1.1.2 报文长度1.1.3 校验和 2. TCP2.1 TCP 报文结构2.2 TCP 特…...

从零开始搭建Halo个人博客
前言 老话说得好,好记性不如烂笔头。对于程序员来说,学无止境,需要学习的东西很多,而如果不记录下来可能过不了多久就忘记了,而记录下来这一步也能很好地贯彻费曼学习法。 其实网上有很多博客平台,但是自…...

AMD显卡低负载看视频掉驱动(chrome edge浏览器) 高负载玩游戏却稳定 解决方法——关闭MPO
2024.11.9更新 开关mpo ulps 感觉有用但是还是掉驱动,现在确定是window顶驱动问题 按网上的改注册表和组策略会让自己也打不上驱动 目前感觉最好的办法就是,重置此电脑,然后你就摆着电脑挂个十分钟半小时别动,一开始他是不显示…...

数据结构——二叉树(续集)
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨个人…...
ElasticSearch学习篇16_《检索技术核心20讲》进阶篇之空间检索
背景 学习极客实践课程《检索技术核心20讲》https://time.geekbang.org/column/article/215243,文档形式记录笔记。 相关问题: 查询范围固定的需求 直接计算两点之间距离区域二进制编码GeoHash编码 查询范围不固定的需求 GeoHash编码索引结构设计 基于…...

uni-app跨域set-cookie
set-cookie的值是作为一个权限控制的 首先,无论什么接口都会返回一个set-cookie,但未登录时,set-cookie是没有任何权限的 其次,登录接口请求时会修改set-cookie,并且在后续其他接口发起请求时,会在请求头…...

移动应用开发:简易登录页
文章目录 简介一,创建新活动二,设计UI布局三,编写活动代码四,运行应用程序注意 简介 使用Android Studio编写的简单Android 登录应用程序,该应用程序包含一个登录界面,具有账号和密码两个文本框࿰…...

C++_ C++11的override和final
文章目录 1. override 关键字2. final 关键字在虚函数上使用 final在类上使用 final 1. override 关键字 用于明确表示派生类中的某个虚函数是用来重写基类中的虚函数的,这样编译器会检查基类,看看是否确实存在同样的虚函数,如果没有匹配&am…...

【MyBatis源码】SQL 语句构建器AbstractSQL
文章目录 介绍org.apache.ibatis.jdbc.SQLSQL类使用示例SelectProvider搭配动态SQLAbstractSQL类源码分析 介绍 当我们需要使用Statement对象执行SQL时,SQL语句会嵌入Java代码中。SQL语句比较复杂时,我们可能会在代码中对SQL语句进行拼接,查…...

C++OJ_二叉树的层序遍历
✨✨ 欢迎大家来到小伞的大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:C_OJ 小伞的主页:xiaosan_blog 二叉树的层序遍历 102. 二叉树的层序遍历 - 力扣(LeetCode࿰…...

什么是直方图算法
什么是直方图算法? 直方图算法是一种优化决策树分裂点搜索效率的算法,被广泛应用于像 LightGBM 和 XGBoost 这样的梯度提升决策树框架中。其核心思想是通过将连续特征的取值范围离散化为有限的区间(称为 bins),在这些…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

Python+ZeroMQ实战:智能车辆状态监控与模拟模式自动切换
目录 关键点 技术实现1 技术实现2 摘要: 本文将介绍如何利用Python和ZeroMQ消息队列构建一个智能车辆状态监控系统。系统能够根据时间策略自动切换驾驶模式(自动驾驶、人工驾驶、远程驾驶、主动安全),并通过实时消息推送更新车…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...

Vite中定义@软链接
在webpack中可以直接通过符号表示src路径,但是vite中默认不可以。 如何实现: vite中提供了resolve.alias:通过别名在指向一个具体的路径 在vite.config.js中 import { join } from pathexport default defineConfig({plugins: [vue()],//…...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...