漫谈分布式唯一ID
文章目录
- 本系列
- 前言
- UUID
- DB自增主键
- Redis incr命令
- 号段模式
- 雪花算法
本系列
- 漫谈分布式唯一ID(本文)
- 分布式唯一ID生成(二):leaf
- 分布式唯一ID生成(三):uid-generator(待完成)
- 分布式唯一ID生成(四):tinyid(待完成)
前言
在大多数业务场景中,需要对每条数据分配一个唯一ID作为标识。大部分关系型数据库提供了自增主键功能来支持该需求
但若数据量较大,需要分库分表时,就不能使用每个数据库实例提供的自增键功能,因为不能保证在所有表中唯一,分布式全局唯一ID的需求应运而生
分布式唯一ID有以下功能需求:
- 全局唯一性:在某个业务场景下唯一,避免数据冲突,这是最基本的要求
- 高性能:生成速度快,不能阻塞业务流程
- 趋势递增:通常会将该ID作为数据库主键,由于mysql innoDB采用聚集索引,若新增的记录主键无序,可能造成
叶分裂和空间利用率不高的问题,降低写入性能 - 严格单调递增:适用于需要这种特性的场景,例如IM场景中需要根据此生成消息ID,用于给消息排序,并判断是否有消息丢失
- 安全性:防止泄露业务信息,若生成的ID严格递增,在电商场景可根据一段时间的id差算出订单量
- 方便追踪:例如在ID融入时间戳,就能知道是什么时间范围生成的
上述4,5需求是互斥的,无法同时满足。不同业务场景根据需求选择
还有一些非功能需求:
-
高可用:可用性至少5个9
-
低延迟:生成速度一定要快,TP50和TP99.9都要非常快,不能因为这个导致业务接口响应变慢
-
高并发:假如一下来10w个生成分布式 ID 的请求,要能扛得住
接下来介绍一些常见的分布式ID生成方案
UUID
UUID(Universally unique identifier)一般包含32个十六进制的字符,128位,通过一定的算法计算出来,通常基于时间戳,mac地址,随机数等
优点为:
- 性能好:本地生成,无网络消耗
- 唯一性:可以认为不会发生冲突
某些版本基于命名空间能保证唯一性,某些版本基于随机数生成,不保证唯一性,但出现相同UUID的概率非常小,根据百度百科的说法,以java.util.UUID为例,每秒产生10亿笔UUID,100年后只产生一次重复的机率是50%
缺点:
- 没有趋势递增特性:作为数据库主键时插入性能不高,会导致叶分裂
- 数据较宽:通常UUID为128bit,不能用mysql的bigint存储,需使用字符串类型,对性能有一定影响
- 信息不安全:基于mac生成的uuid可能造成mac地址泄露
应用:生成traceId或logId
DB自增主键
以mysql为例,我们可以专门建一张表,利用其自增键来生成唯一ID
表结构如下:
CREATE TABLE unique_id (id bigint(20) unsigned NOT NULL auto_increment, value char(20) NOT NULL default '',PRIMARY KEY (id),UNIQUE KEY unique_v(value)
) ENGINE=MyISAM;
使用以下sql获取id
begin;
replace into unique_id (value) VALUES ('placeword');
select last_insert_id();
commit;
这里 使用replace而不是insert ,是为了保证整个表只有一条记录,因为不需要多余的记录也能生成自增id
这种方式利用数据库的自增主键保证生成id的唯一性,严格单调递增。缺点为:
- 性能问题:每次生成id需要一次数据库远程IO,发号器的瓶颈取决于db的读写性能
- 可用性问题:只用到一台db实例,存在单点问题,可用性没有保障
针对上面两个问题,可以引入多台mysql:每台实例的表使用不同的初始值
以2台mysql实例为例,分别做如下配置:
mysql1:
set @@auto_increment_offset = 1; -- 起始值 set @@auto_increment_increment = 2; -- 步长
mysql2:
set @@auto_increment_offset = 2; -- 起始值 set @@auto_increment_increment = 2; -- 步长
mysql1从 1 开始发号,mysql2从 2 开始发号,每次发号后递增2
这样mysql1生成的id序列为:
1,3,5,7,9....
mysql2为:
2,4,6,8....
当请求到来时,采用随机或轮询的方式请求这些实例,这样得到的id序列总体为趋势递增,既减少了单台实例的访问压力,也提高了可用性。缺点为:
- 从单调递增变为趋势递增
- 性能问题: 每次生成ID还是有一次远程数据库IO,对DB的压力还是大
- 伸缩性问题:当需要扩展更多的机器时,需要调整之前所有实例的步长,且需要保证再次期间生成ID不冲突,实现起来较麻烦
Redis incr命令
为了解决数据库自增键遇到的性能问题,可以利用 redis的incr 命令来生成不重复的递增ID。该策略相较于数据库方案,优点为:
- 从远程磁盘IO变为为远程内存IO,性能有一定提升,毕竟redis号称10w qps
但为了保证唯一性需要费一番功夫,依次讨论redis的各种持久化策略:
- 若不开启 redis 持久化,则redis宕机后会丢失已生成的ID,再生成会导致ID重复
- 若开启 RDB 或 AOF 中非AOF_FSYNC_ALWAYS模式的持久化,可能丢失最近一段时间的ID,一样会出现ID重复
- 若开启 AOF 中AOF_FSYNC_ALWAYS模式的持久化,能保证即使在宕机的情况下也不会出现ID重复,但性能会下降,相较于数据库方案没有太大的优势
号段模式
号段模式是为了解决数据库自增主键和redis incr方案中,每次获取ID都需要远程请求的问题
即每次从db获取一个ID范围,作为一个号段加载到内存,这样生成唯一ID时不需要每次都从数据库获取,而是从本地内存里获取,大大提高性能。本地缓存的号段用完时才请求db获取下一批号段
以mysql为例,数据库表结构如下:
CREATE TABLE unique_id ( id bigint(20) NOT NULL, max_id bigint(20) NOT NULL COMMENT '下个号段从哪开始分配', step int(10) NOT NULL COMMENT '一批ID的数量', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT
每次获取一个号段时,执行如下sql:
update unique_id set max_id = {max_id} + step where max_id = {max_id}
当执行成功后判断 affectRows等于1,就能保证只有当前实例获得了 [max_id,max_id + step) 这个区间的号段,就能愉快地在内存发号了
若affectRows不等于1,说明有其他实例获取了这个号段,需要重试再次获取
号段模式的优点如下:
- 性能很高:大部分情况下直接在内存发号,无需远程请求,号段范围越大,远程请求的比例越低
- 可用性较高:若数据库宕机,可以使用之前获取的号段进行发号,号段范围越大,能撑的时间越久
- 趋势递增
缺点如下:
-
号段浪费:若某实例在号段没用完时就重启或宕机,则其号段剩余的ID就浪费了。解决方案为较小号段长度,但根据优点中的描述,这会降低性能和可用性,因此需要选择一个适中的号段长度
-
不够平滑:当号段用完时,会请求一次数据库,如果此时网络抖动,会使得该次请求响应较慢
- 为了解决这种情况,可以在号段即将用完时就异步请求数据库获取下一个号段,而不是等到要用完再请求
-
可用性问题:和数据库自增键策略一样的单点问题
如何解决上面提到的可用性问题呢?使用多台实例。这里还是以2台实例为例进行说明:
每次生获取完号段后,将max_id增加 号段长度 * 实例数量:
例如初始化时,mysql1.max_id=0,mysql2.max_id=1000。step都是1000
- 第一次访问mysql1,获取[0:1000)的号段,将mysql1.max_id更新成2000
- 第二次访问mysql2,获取[1000:2000)的号段,将mysql2.max_id更新成3000
- 第三次访问mysql1,获取[2000:3000)的号段,将mysql1.max_id更新成4000
- 第四次访问mysql2,获取[3000:4000)的号段,将mysql2.max_id更新成5000
这样既降低了单台数据库实例的访问压力,又提高了可用性
buffer数量设为多大?峰值qps的600倍,这样db宕机还能提供至少10分钟的服务(容灾性高)
优点:
- id位64bit的数字,趋势递增
- 对db的压力小
- 可以很方便线性扩展:按照bizkey分库分表即可
- 高可用:内部有缓存,如果数量为峰值qps的600倍,那么db宕机10分钟内都可用
- id可以做到几乎单调递增
- 可自定义maxId大小,方便原有业务迁移
缺点:
- TP999波动大:其他时候查本地缓存,但当号段用完时要查读写一次db
- 解决:双buffer,例如当第一个buffer用到10%时就异步请求第二个buffer的号段
- id不够随机,泄露发号数量
雪花算法
雪花算法使用一个64位的数字来表示唯一ID,而这64位中的每一位怎么用,就是其精髓所在
标准的雪花算法每一位含义如下:

- [0:0] 1位符号位:ID一般为正数,所以该位为0
- [1:41] 41位时间:通常用来表示
当前时间 - 业务开始时间的时间差,而不是相对于1970年的时间戳,这样能支持的时间更久,若41位时间戳的单位为毫秒,则能支持大约(1 << 41) / (1000 * 60 * 60 * 24 * 365) =69年 - [42:51] 10位机器:一般机器数没那么多,可以将 10位中分5位给机房,分5位给机器。这样就可以表示32个机房,每个机房下可以有32台机器
- [52:63] 12位自增序列号:表示某台机器上在某一毫秒(如果表示时间的单位为毫秒)内的生成的ID序列号,每毫秒支持1<<12 = 4096个ID,按照
qps算有409.6万
位的分配可以根据业务的不同进行调整,例如若机器数没那么多,不需要10位表示,可增大时间位,以支持更长的时间范围。或者业务并发量不高时,可将时间单位改为秒,将节省出来的位用于表示其他含义
只要每个实例的机器ID不同,则不同机器间生成的ID一定不同,因为其[42:51]位不一样
这样划分后,在一毫秒内一个数据中心的一台机器上可以产生4096个的不重复的ID
其优点为:
- 不依赖数据库,性能和可用性非常好
- 如果时间戳在高位,能保证ID趋势递增
- 理论上支持超高的并发,因为qps有409万,基本不可能有业务的写操作能达到这个qps
缺点为:
- ID的生成强依赖于服务器时钟,如果发生时钟回拨,则可能和以前生成过的ID产生冲突
时钟回拨:硬件时钟可能会因为各种原因发生不准的情况,网络中提供了ntp服务来做时间校准,做校准的时候就会发生时钟的跳跃或者回拨的问题
- 10位的机器号较难指定,最好不要手工指定,而是实例去自动获取
针对时钟回拨问题,可分两种情况讨论:
- 实例运行过程中发生时钟回拨:此时可以在内存中
记录上次时间戳,若这次获取的时间戳比上次小,说明发生了时钟回拨,可以等待一段时间再进行ID生成,若回拨幅度较大,则可选择继续等待,或给上层报错,因为在短时间内无法生成正确的ID
也可以完全不依赖系统时间,例如百度的uid-generator使用一个原子变量,每次加一来生成下一个时间
- 实例重启过程中发生时钟回拨:此时没办法从内存中获取上次的时间戳,因此需要将上次时间戳放到外部存储中。美团leaf的方案为,每3s往zookeeper上报一次当前时间戳,这样在实例重启时,也能判断出是否发生了时钟回拨
但存在外部不能完全避免时钟回拨,例如在t时刻将t保存在zk,在 t+1 时刻分配了一个ID,在 t+2 时刻宕机,时钟回退了1s到t+1,此时检测 t+1 > zk 中的时间t,没问题。但依然会产生 t+1 时刻的重复ID
因此最保险的办法时:宕机后sleep一段时间再重启,这段时间要超过时钟回退的时间
针对机器号生成困难问题:有以下几种解决方案:
-
使用zookeeper:每次实例启动时,都去zookeeper下创建一个节点,利用其节点编号当做机器id,zookeeper保证每次生成的节点编号唯一
-
使用mysql:也可以在实例启动时,去数据库的表插入一条记录,利用自增主键当做机器ID,同样能保证机器ID的唯一性
适用场景:订单中,不想让别人根据早上和晚上的订单id号猜到销量的场景
相关文章:
漫谈分布式唯一ID
文章目录 本系列前言UUIDDB自增主键Redis incr命令号段模式雪花算法 本系列 漫谈分布式唯一ID(本文)分布式唯一ID生成(二):leaf分布式唯一ID生成(三):uid-generator(待完…...

【复旦微FM33 MCU 开发指南】ADC
前言 本系列基于复旦微FM33LC0系列单片机的DataSheet编写,旨在提供手册解析和开发指南。 本文章及本系列其他文章将持续更新,本系列其它文章请跳转【复旦微FM33 MCU 外设开发指南】总集篇 本文章最后更新日期:2024/11/09 全文字数ÿ…...

ORB_SLAM3安装
ORB_SLAM3安装 一.前期准备1.1ubuntu查看当前版本的命令1.2 根据ubuntu版本,更新下载软件源1.3 先下载git1.4 vim语法高亮1.5 常见的linux命令 二.ORB-SLAM3下载2.1 ORB_SLAM3源码下载2.2 安装依赖库2.2.1 依赖库2.2.2 安装pangolin2.2.3 安装opencv2.2.4 Eigen3安装…...
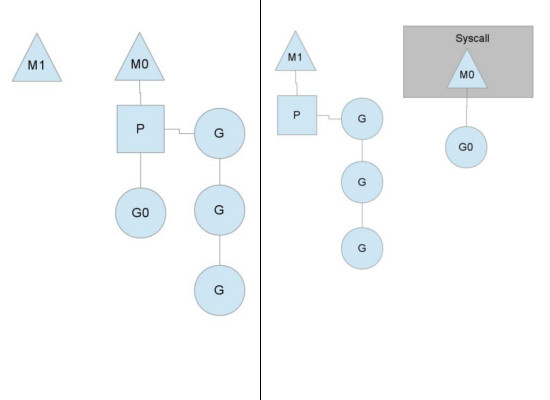
GoLang协程Goroutiney原理与GMP模型详解
本文原文地址:GoLang协程Goroutiney原理与GMP模型详解 什么是goroutine Goroutine是Go语言中的一种轻量级线程,也成为协程,由Go运行时管理。它是Go语言并发编程的核心概念之一。Goroutine的设计使得在Go中实现并发编程变得非常简单和高效。 以下是一些…...
全文检索ElasticSearch到底是什么?
学习ElasticSearch之前,我们先来了解一下搜索 1 搜索是什么 ① 概念:用户输入想要的关键词,返回含有该关键词的所有信息。 ② 场景: 1互联网搜索:谷歌、百度、各种新闻首页; 2 站内搜索ÿ…...

FPGA实现串口升级及MultiBoot(五)通过约束脚本添加IPROG实例
本文目录索引 一个指令和三种方式通过约束脚本添加Golden位流工程MultiBoot位流工程验证example1总结代码缩略词索引: K7:Kintex 7V7:Vertex 7A7:Artix 7MB:MicroBlaze上一篇文章种总结了MultiBoot 关键技术,分为:一个指令、二种位流、三种方式、四样错误。针对以上四句话我…...

文献阅读 | Nature Methods:使用 STAMP 对空间转录组进行可解释的空间感知降维
文献介绍 文献题目: 使用 STAMP 对空间转录组进行可解释的空间感知降维 研究团队: 陈金妙(新加坡科学技术研究局) 发表时间: 2024-10-15 发表期刊: Nature Methods 影响因子: 36.1࿰…...

【模块化大作战】Webpack如何搞定CommonJS与ES6混战(1-3)
在前端开发中,模块化是一个重要的概念,不同的模块化标准有不同的特点和适用场景。webpack 同时支持 CommonJS 和 ES6 Module,因此需要理解它们在互操作时 webpack 是如何处理的。 同模块化标准 如果导出和导入使用的是同一种模块化标准&…...

[NewStar 2024] week5完结
每次都需要用手机验证码登录,题作的差不多就没再进过。今天把week5解出的部分记录下。好像时间过去很久了。 Crypto 没e也能完 这题给了e,p,q,dp,dq。真不清楚还缺啥 long_to_bytes(pow(c,dp,p)) 格格你好棒 给了a,b和提示((p2*r) * 3*a q) % b < 70 其中r…...

IntelliJ IDEA的快捷键
IntelliJ IDEA 是一个非常强大的集成开发环境,它提供了大量的快捷键来加速开发者的日常工作。这里为您整理了一份 IntelliJ IDEA 的快捷键大全,包含了编辑、导航、重构、运行等多个方面的快捷键。请注意,这些快捷键是基于 Windows 版本的 Int…...

暮雨直播 1.3.2 | 内置直播源,频道丰富,永久免费
暮雨直播是一款内置直播源的电视直播应用程序,提供丰富的频道内容,包括教学、首页、一线、博主、解说、动漫、堆堆等。该应用的内置直播源持续更新维护,确保用户可以稳定地观看各种电视频道。暮雨直播承诺永久免费,为用户提供了一…...

单相锁相环,原理与Matlab实现
单相锁相环基本原理 单相锁相环的基本原理图如下所示, u α u_\alpha uα u β u_\beta uβ经Park变换、PI控制实现对角频率 ω \omega ω和角度 θ \theta θ的估算。不同锁相环方案之间的差异,主要表现在正交电压 u β u_\beta uβ的生成&#x…...

PICO+Unity 用手柄点击UI界面
如果UI要跟随头显,可将Canvas放置到XR Origin->Camera Offset->Main Camera下 1.Canvas添加TrackedDeviceGraphicRaycaster组件 2.EventSystem移动默认的Standard Input Module,添加XRUIInputModule组件 3.(可选)设置射线可…...

Rust移动开发:Rust在iOS端集成使用介绍
iOS调用Rust 上篇介绍了 Rust移动开发:Rust在Android端集成使用介绍, 这篇主要看下iOS上如何使用Rust,Rust可以给移动端开发提供跨平台,通用组件支持。 该篇适合对iOS、Rust了解,想知道如何整合调用和编译的,如果想要…...

虚拟现实技术在旅游行业的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 虚拟现实技术在旅游行业的应用 虚拟现实技术在旅游行业的应用 虚拟现实技术在旅游行业的应用 引言 虚拟现实技术概述 定义与原理…...

《Java核心技术 卷I》Swing使用颜色
使用颜色 使用Graphics2D类的setPaint方法可以为图形上下文上的所有后续的绘制操作选择颜色。例如: g2.setPaint(Color.RED); g2.drawString("Warning!",100,100); 可以用一种颜色填充一个封闭图像(例如:矩形或椭圆)的内部。为此ÿ…...

神书《从零构建大模型》分享,尚未发布,GitHub标星22k!!
《从零构建大模型》是一本即将于今年10月底发布的书籍,github已经吸引了惊人的21.7k标星!作者是威斯康星大学麦迪逊分校的终身教授,在GitHub、油管、X上拥有大量粉丝,是一位真正的大佬。 本书免费获取地址 在本书中࿰…...

【JavaEE进阶】Spring AOP 原理
在之前的博客中 【JavaEE进阶】Spring AOP使用篇_aop多个切点-CSDN博客 我们主要学习了SpringAOP的应用, 接下来我们来学习SpringAOP的原理, 也就是Spring是如何实现AOP的. SpringAOP 是基于动态代理来实现AOP的,咱们学习内容主要分以下两部分 1.代理模式 2.Spring AOP源码剖…...

【网络安全】2.3 安全的网络设计_2.防御深度原则
文章目录 一、网络架构二、网络设备三、网络策略四、处理网络安全事件五、实例学习:安全的网络设计结论 网络设计是网络安全的基础,一个好的网络设计可以有效的防止攻击者的入侵。在本篇文章中,我们将详细介绍如何设计一个安全的网络&#…...
测绘程序设计|C#字符串及其操作|分割|取子串|格式化数值|StringBuilder类
由于微信公众号改变了推送规则,为了每次新的推送可以在第一时间出现在您的订阅列表中,记得将本公众号设为星标或置顶喔~ 简单介绍了C#字符串分割、取子串、拼接、格式化数值以及StringBuilder类,拿捏测绘程序设计大赛~ 🌿前言 字…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...
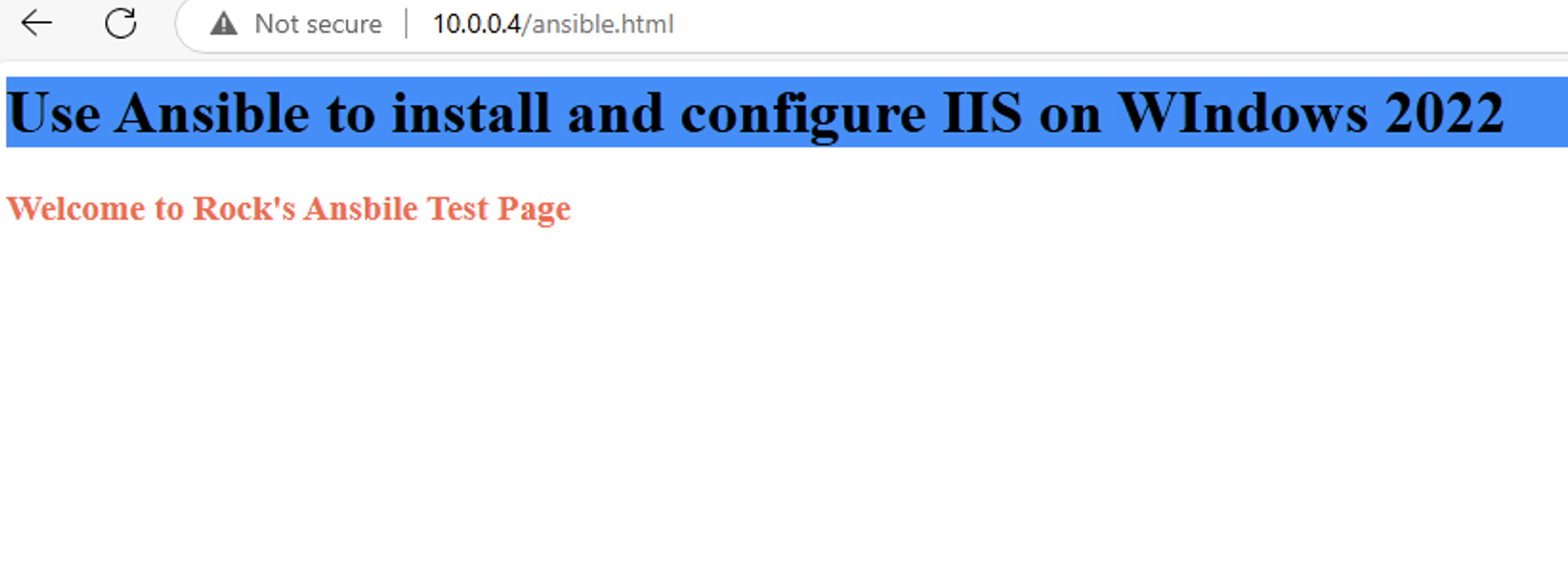
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...

Visual Studio Code 扩展
Visual Studio Code 扩展 change-case 大小写转换EmmyLua for VSCode 调试插件Bookmarks 书签 change-case 大小写转换 https://marketplace.visualstudio.com/items?itemNamewmaurer.change-case 选中单词后,命令 changeCase.commands 可预览转换效果 EmmyLua…...