【NLP】使用 SpaCy、ollama 创建用于命名实体识别的合成数据集
命名实体识别 (NER) 是自然语言处理 (NLP) 中的一项重要任务,用于自动识别和分类文本中的实体,例如人物、位置、组织等。尽管它很重要,但手动注释大型数据集以进行 NER 既耗时又费钱。受本文 ( https://huggingface.co/blog/synthetic-data-save-costs#31-prompt-an-llm-to-annotate-your-data ) 的启发,我们讨论了一种创新方法,使用 qwen2.5:7b 生成的合成数据来有效应对这些挑战。通过使用合成数据,我们可以有效地训练 NER 模型,以从大量文本语料库(例如金融新闻文章)中提取有意义的信息。

在本教程中,我们将演示如何使用 SpaCy 构建 NER 管道,SpaCy 是一个流行的开源 NLP 库,以其速度和效率而闻名。SpaCy 广泛用于标记化、词性标记和命名实体识别等任务,尤其擅长在 CPU 上快速处理文本。其强大的架构使其无需专门的硬件即可处理大量数据,使其成为许多实际应用的理想选择。
我们将使用 SmoothNLP金融新闻数据集 进行案例研究,展示合成数据如何显著提高 NER 模型的性能并降低与传统数据注释方法相关的成本。通过将合成数据与 SpaCy 集成,我们旨在创建可扩展且准确的 NER 解决方案来处理大规模新闻数据集。
我们的方法
为了克服传统方法的局限性,我们利用合成数据生成在新闻文章中进行 NER。以下是我们流程的分步概述:
步骤 1:数据收集
数据下载地址
步骤 2:使用ollama加载 qwen2.5-7b
1、下载ollama
ollama下载地址(以windows版为例)

2、下载qwen2.5-7b模型
ollama pull qwen2.5如下图所示为下载完成

我们使用langchain_ollama来启用语言模型 qwen2.5-7b 来注释收集的数据。以下是如何加载模型:
from langchain_ollama import OllamaLLMmodel = OllamaLLM(model="qwen2.5:7b")
model.invoke("你是谁")
这里发生了什么事?
- qwen2.5-7b模型:我们加载一个大型预先训练的 Qwen模型
步骤 3:准备数据集
1.设置模型后,我们加载样本数据并准备数据集以供处理:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import pandas as pd
from tqdm import tqdm
from pydantic import BaseModel, Field, ValidationError
from typing import List
from datasets import Dataset
import spacy
from spacy.tokens import DocBin, Span
import re
import jsonnlp = spacy.load('zh_core_web_sm')financial_news_sample = pd.read_excel("./SmoothNLP金融新闻数据集样本20k.xlsx")
financial_news_sample.head()数据如图所示

2.合并标题和内容
financial_news_sample['text'] = financial_news_sample['title'].str.cat(financial_news_sample['content'], sep='\n')
financial_news_sample.head()
news_texts = [text for text in list(financial_news_sample["text"]) if type(text)==str][-100:]
dataset = Dataset.from_dict({"text": news_texts})步骤 4:使用 SpaCy 对文本进行标记
我们使用 SpaCy 对文本数据进行标记。标记化是将文本拆分为单个单词或子单词的过程。
def tokenize_with_spacy(texts):tokenized_texts = []token_offsets_list = []for text in texts:if isinstance(text, str):doc = nlp(text)tokens = [token.text for token in doc]token_offsets = [(token.idx, token.idx + len(token.text)) for token in doc]tokenized_texts.append(tokens)token_offsets_list.append(token_offsets)else:raise ValueError(f"Expected a string but got {type(text)}")return tokenized_texts, token_offsets_list第 5 步:准备 Qwen 的输入
def prepare_qwen_input(tokenized_texts):return [" ".join(tokens) for tokens in tokenized_texts]步骤 6:查询我们的 Qwen 的提示
接下来,我们创建一个查询 LLM 的系统提示。由于我们想从新闻文章中提取结构化信息,因此我们要求 LLM 以 JSON 格式响应。我们还包含示例输入和输出,以指导模型正确构建其响应。
system_prompt="""
你是一个在自然语言处理和信息提取方面受过训练的高级人工智能。你的任务是阅读以下新闻文章,并提取文中提到的所有人名。对于识别的每个人名,提供具有以下结构的JSON输出:[
{"entity_type":"人名","entity_value":"内容中的人名"}
]
确保提取人名的确切字符串,而不进行任何更正或转换。不要提供任何解释。仅使用JSON结构化数据进行响应。###示例1:
输入:
李明远当选陕西省西安市市长
新华社西安2月19日电 西安市第十六届人民代表大会第四次会议2月18日选举李明远为西安市人民政府市长。输出:
[
{"entity_type":"人名","entity_value":"李明远"},
]###示例2:
输入:
原央行征信中心主任王煜调任中国金融培训中心主任
中国金融培训中心官网显示,原中国人民银行征信中心主任王煜已出任该中心主任。
王煜毕业于五道口央行研究生部,在央行体系工作多年,先后出任过央行货币政策司副司长、央行货币政策委员会秘书长,随后王煜进入征信领域,先后出任央行征信管理局局长、中国人民银行征信中心主任。(澎湃)输出:
[
{"entity_type":"人名","entity_value":"王煜"}
]###示例3:
输入:
人民大学教授叶林:完善法制体系 提高我国期货市场核心竞争力本报见习记者 王宁中国期货市场经过二十多年的探索发展,已经成为金融体系的重要组成部分,为宏观决策部门预研预判经济形势、微观企业进行风险管理提供了有力支持。随着期货市场各项创新以及国际化业务的深入推进,需要的法律支持也越来越多,“尽快出台《期货法》”的呼声越来越高。法治强,则市场兴。如今,中国期货市场已经开启了多元、开放的新时代,这对中国期货市场的法律制度体系提出了更高要求。近日,记者采访了中国人民大学教授叶林,深入解读我国期货市场立法的探索、困境及出台《期货法》的重要意义。记者:目前我国期货市场的有关法律法规都有哪些,相较国际期货市场的主要差距是什么?叶林:二十多年来,我国期货市场法制建设取得了显著的进步,逐渐摸索出了一条适应期货市场发展需要、符合期货市场规律、有中国特色的期货市场法制建设道路。2007年3月,国务院颁布了《期货交易管理条例》,2012年10月、2013年7月、2016年2月和2017年3月进行了四次修订。目前初步形成了以《期货交易管理条例》、最高人民法院司法解释为支撑,以部门规章和规范性文件为配套,以期货交易所、期货业协会自律规则为补充的期货市场法规体系。这一制度体系对于规范期货市场的稳定运行起到了积极作用,但是相较域外期货市场法制而言,存在法律位阶较低、民事规范不完整、跨境监管与协作规范缺失等问题,法律制度并不完备。输出:[
{"entity_type":"人名","entity_value":"叶林"},
{"entity_type":"人名","entity_value":"王宁"}
]请使用相同的格式继续执行任务。
"""JSON 是一种轻量级的结构化数据格式,易于通过编程进行解析,因此非常适合自动化和一致性至关重要的机器学习流程。使用 JSON 可以明确定义提取的实体,确保每个识别的实体都遵循标准结构(具有“entity_type”和“entity_value”等字段)。此结构简化了下游任务(例如验证和存储),并确保输出可以轻松集成到其他处理工具或库中。
在提示中提供示例是有益的,因为它有助于指导语言模型理解所需的输出格式和结构。示例充当“指令调整”的一种形式,向模型展示如何以特定方式响应,从而降低生成的输出中出现错误和不一致的可能性。在我们的案例中,使用多个输入文本示例与相应的 JSON 输出配对,向模型展示如何一致地识别和格式化城市名称。这提高了模型响应的可靠性,尤其是在应用于多样化和复杂的现实世界数据时。
步骤 7:从模型响应中提取实体
系统提示准备好后,我们定义一个函数来从模型的输出中提取实体:
def extract_json_from_response(response):try:if isinstance(response, list):return responsematch = re.search(r'(\[.*)', response, re.DOTALL)if match:json_content = match.group(0).strip()if not json_content.endswith(']'):json_content += ']'return json.loads(json_content)except json.JSONDecodeError as e:print(f"Failed to decode JSON: {e}")return []此函数在响应中查找 JSON 格式的数据并提取它,确保即使响应结构不正确,我们的管道仍然保持稳健。
步骤 8:实体提取的批处理
然后我们设置批处理来有效地处理大型数据集:
rom loguru import loggerdef predict_entities_in_batches(test_dataset, model, system_prompt, batch_size=1):extracted_entities = []for i in tqdm(range(0, len(test_dataset), batch_size), desc="Processing batches"):batch_texts = test_dataset[i:i + batch_size]["text"]batch_prompts = [system_prompt+text for text in batch_texts]logger.info(batch_prompts)results = [model.invoke(batch_prompt) for batch_prompt in batch_prompts]for result in results:generated_text = resultlogger.info(f"result::{result}")assistant_response = generated_textif assistant_response:entities = extract_json_from_response(assistant_response)logger.info(f'entities::{entities}')extracted_entities.append(entities)else:extracted_entities.append(None)return extracted_entitiesprocessed_data = predict_entities_in_batches(dataset, model, system_prompt)当处理 Qwen2.5 等大型模型和大量数据集时,高效的内存管理至关重要。批处理是一种策略,它通过将数据集划分为较小的块或批次并按顺序处理每个批次来帮助管理内存使用量。这种方法可以防止系统内存耗尽,因为整个数据集不需要一次加载到内存中。它还允许通过根据可用硬件调整批处理大小来更好地控制计算资源(例如 GPU 内存)。
使用批处理还可以优化并行性,其中模型可以在一个批次内同时生成多个数据点的输出。这可以加快处理速度而不会使系统内存过载,从而可以处理数据集(如 SmoothNLP金融新闻数据集)。此外,在批次之间清除内存缓存有助于防止内存碎片化(在处理非常大的数据集时可能会发生这种情况),从而保持性能稳定性。总体而言,批处理可确保计算效率和资源管理之间的平衡,从而实现机器学习管道中大型数据集的可扩展处理。
步骤 9:验证和错误处理
我们使用 Pydantic 模型验证提取的实体,确保数据符合预期格式:
from validators import validatorclass EntityList(BaseModel):def validate_entity_type(entities):entities_last = []try:for entitie in entities:if entitie['entity_type'] != '人名':raise ValueError(f"{v} is not a valid entity type")else:entities_last.append(entitie)except:passreturn entities_lastvalidated_data = []
for i, entities in enumerate(processed_data):try:validated_output = EntityList.validate_entity_type(entities=entities)validated_data.append({"text": dataset[i], "entities": validated_output})except ValidationError as e:print("Validation error:", e)validated_data.append({"text": dataset[i], "entities": None})这可确保仅接受有效的实体类型(例如city_names)。如果实体类型与预期格式不匹配,则会引发错误。
步骤 10:准备 SpaCy 模型训练的数据
最后,我们使用 SpaCy 的DocBin来存储处理后的数据,包括实体跨度:
def create_spans(doc, entities):"""Creates spaCy spans for detected entities in the text."""spans = []warnings = []for entity in entities:entity_value = entity.get('entity_value', '').strip()entity_type = entity.get('entity_type', '')if not entity_value:warnings.append(f"Skipping empty entity for type: '{entity_type}'")continuestart = 0while True:start = doc.text.find(entity_value, start)if start == -1:breakend = start + len(entity_value)span = doc.char_span(start, end, label=entity_type, alignment_mode="contract")if span:spans.append(span)else:warnings.append(f"Could not create span for entity: '{entity_value}' at position {start}-{end}")start = endreturn spans, warningsdef filter_overlapping_spans(spans):"""Filters out overlapping spans, keeping non-overlapping spans."""filtered_spans = []for span in sorted(spans, key=lambda x: (x.start, -x.end)):if all(span.start >= s.end or span.end <= s.start for s in filtered_spans):filtered_spans.append(span)return filtered_spans
def process_data(data_list):doc_bin = DocBin(store_user_data=True)for item in tqdm(data_list, desc="Processing Data", unit="doc"):try:text = item.get('text', '')if not text.strip():continueentities = item.get('entities', {}).get('entities', [])doc = nlp(text)spans, warnings = create_spans(doc, entities)doc.ents = filter_overlapping_spans(spans)if warnings:doc._.warnings = warningsdoc_bin.add(doc)except:passreturn doc_bindoc_bin = process_data(validated_data)拆分训练测试集并保存到spacy文件
split_ratio = 0.8
split_idx = int(len(validated_data) * split_ratio)
doc_bin = process_data(validated_data[:split_idx])
test_doc_bin = process_data(validated_data[split_idx:])doc_bin.to_disk("./train.spacy")
test_doc_bin.to_disk("./test.spacy")结论
合成数据与 Qwen 等高级语言模型的集成对降低命名实体识别 (NER) 任务的成本和提高可扩展性具有重大影响。生成合成数据可以创建大型注释数据集,而无需耗时且昂贵的手动标记过程,从而可以快速训练用于各种 NER 应用程序的模型。大型语言模型 (LLM) 通过利用上下文理解从文本中提取有意义的信息,提供了一种注释这些数据集的有效方法。合成数据生成和 LLM 相结合,为开发高性能 NER 系统提供了一种可扩展的解决方案,能够处理来自 SmoothNLP金融新闻数据集 的大规模文本语料库,例如新闻文章。这种方法不仅可以降低注释成本,还可以确保即使在数据需求很大的情况下也可以大规模训练和部署模型。
相关文章:
【NLP】使用 SpaCy、ollama 创建用于命名实体识别的合成数据集
命名实体识别 (NER) 是自然语言处理 (NLP) 中的一项重要任务,用于自动识别和分类文本中的实体,例如人物、位置、组织等。尽管它很重要,但手动注释大型数据集以进行 NER 既耗时又费钱。受本文 ( https://huggingface.co/blog/synthetic-data-s…...

【C++练习】二进制到十进制的转换器
题目:二进制到十进制的转换器 描述 编写一个程序,将用户输入的8位二进制数转换成对应的十进制数并输出。如果用户输入的二进制数不是8位,则程序应提示用户输入无效,并终止运行。 要求 程序应首先提示用户输入一个8位二进制数。…...

Vue功能菜单的异步加载、动态渲染
实际的Vue应用中,常常需要提供功能菜单,例如:文件下载、用户注册、数据采集、信息查询等等。每个功能菜单项,对应某个.vue组件。下面的代码,提供了一种独特的异步加载、动态渲染功能菜单的构建方法: <s…...
)
云技术基础学习(一)
内容预览 ≧∀≦ゞ 声明导语云技术历史 云服务概述云服务商与部署模式1. 公有云服务商2. 私有云部署3. 混合云模式 云服务分类1. 基础设施即服务(IaaS)2. 平台即服务(PaaS)3. 软件即服务(SaaS) 云架构云架构…...

【优选算法篇】微位至简,数之恢宏——解构 C++ 位运算中的理与美
文章目录 C 位运算详解:基础题解与思维分析前言第一章:位运算基础应用1.1 判断字符是否唯一(easy)解法(位图的思想)C 代码实现易错点提示时间复杂度和空间复杂度 1.2 丢失的数字(easy࿰…...

MFC工控项目实例二十九主对话框调用子对话框设定参数值
在主对话框调用子对话框设定参数值,使用theApp变量实现。 子对话框各参数变量 CString m_strTypeName; CString m_strBrand; CString m_strRemark; double m_edit_min; double m_edit_max; double m_edit_time2; double …...

Java | Leetcode Java题解之第546题移除盒子
题目: 题解: class Solution {int[][][] dp;public int removeBoxes(int[] boxes) {int length boxes.length;dp new int[length][length][length];return calculatePoints(boxes, 0, length - 1, 0);}public int calculatePoints(int[] boxes, int l…...

【前端】Svelte:响应性声明
Svelte 的响应性声明机制简化了动态更新 UI 的过程,让开发者不需要手动追踪数据变化。通过 $ 前缀与响应式声明语法,Svelte 能够自动追踪依赖关系,实现数据变化时的自动重新渲染。在本教程中,我们将详细探讨 Svelte 的响应性声明机…...

PostgreSQL 性能优化全方位指南:深度提升数据库效率
PostgreSQL 性能优化全方位指南:深度提升数据库效率 别忘了请点个赞收藏关注支持一下博主喵!!! 在现代互联网应用中,数据库性能优化是系统优化中至关重要的一环,尤其对于数据密集型和高并发的应用而言&am…...

Flutter鸿蒙next 使用 BLoC 模式进行状态管理详解
1. 引言 在 Flutter 中,随着应用规模的扩大,管理应用中的状态变得越来越复杂。为了处理这种复杂性,许多开发者选择使用不同的状态管理方案。其中,BLoC(Business Logic Component)模式作为一种流行的状态管…...
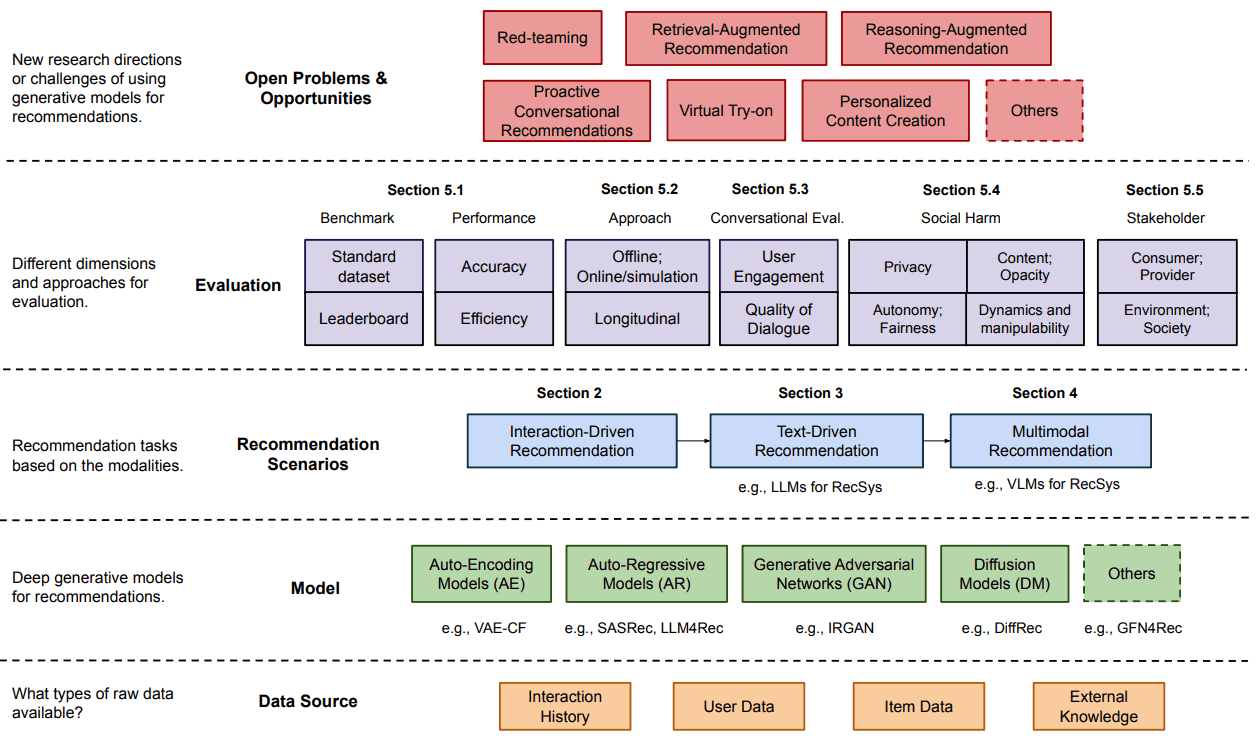
Gen-RecSys——一个通过生成和大规模语言模型发展起来的推荐系统
概述 生成模型的进步对推荐系统的发展产生了重大影响。传统的推荐系统是 “狭隘的专家”,只能捕捉特定领域内的用户偏好和项目特征,而现在生成模型增强了这些系统的功能,据报道,其性能优于传统方法。这些模型为推荐的概念和实施带…...

Android 重新定义一个广播修改系统时间,避免系统时间混乱
有时候,搞不懂为什么手机设备无法准确定义系统时间,出现混乱或显示与实际不符,需要重置或重新设定一次才行,也是真的够无语的!! vendor/mediatek/proprietary/packages/apps/MtkSettings/AndroidManifest.…...

第3章:角色扮演提示-Claude应用开发教程
更多教程,请访问claude应用开发教程 设置 运行以下设置单元以加载您的 API 密钥并建立 get_completion 辅助函数。 !pip install anthropic# Import pythons built-in regular expression library import re import anthropic# Retrieve the API_KEY & MODEL…...

【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
1.问题描述: 人脸活体检测页面会有声音提示,如何控制声音开关? 解决方案: 活体检测暂无声音控制开关,但可通过其他能力控制系统音量,从而控制音量。 活体检测页面固定音频流设置的是8(无障碍…...

【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
问题复现 项目上历史项目为解决漏洞扫描从Tomcat 6.0升级到了9.0版本,服务启动的日志显示如下警告,数据源是通过JNDI方式在server.xml中配置的,控制台上狂刷无法找到表空间的错误(没截图) 报错: 06-Nov-…...

Git LFS
Git LFS(Git Large File Storage)是一个用于管理和版本控制大文件的工具,它扩展了 Git 的功能,帮助处理大文件或二进制文件的存储和管理问题。 为什么需要 Git LFS? Git 默认是针对文本文件进行优化的,尤…...

基于Redis缓存机制实现高并发接口调试
创建接口 这里使用的是阿里云提供的接口服务直接做的测试,接口地址 curl http://localhost:8080/initData?tokenAppWithRedis 这里主要通过参数cacheFirstfalse和true来区分是否走缓存,正常的业务机制可能是通过后台代码逻辑自行控制的,这…...

数字化转型实践:金蝶云星空与钉钉集成提升企业运营效率
数字化转型实践:金蝶云星空与钉钉集成提升企业运营效率 本文介绍了深圳一家电子设备制造企业在数字化转型过程中,如何通过金蝶云星空与钉钉的高效集成应对挑战、实施解决方案,并取得显著成果。集成项目在提高沟通效率、自动化审批流程和监控异…...

Flutter 鸿蒙next 中使用 MobX 进行状态管理
Flutter & 鸿蒙next 中使用 MobX 进行状态管理 在应用开发中,状态管理是一个至关重要的环节,特别是在复杂的Flutter或鸿蒙next项目中。状态的变化往往会影响UI的更新,因此,选择一种高效、灵活的状态管理工具显得尤为重要。Mo…...

1.62亿元!812个项目立项!上海市2024年度“科技创新行动计划”自然科学基金项目立项
本期精选SCI&EI ●IEEE 1区TOP 计算机类(含CCF); ●EI快刊:最快1周录用! 知网(CNKI)、谷歌学术期刊 ●7天录用-检索(100%录用),1周上线; 免费稿件评估 免费匹配期…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...

comfyui 工作流中 图生视频 如何增加视频的长度到5秒
comfyUI 工作流怎么可以生成更长的视频。除了硬件显存要求之外还有别的方法吗? 在ComfyUI中实现图生视频并延长到5秒,需要结合多个扩展和技巧。以下是完整解决方案: 核心工作流配置(24fps下5秒120帧) #mermaid-svg-yP…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...