【AI大模型】大型语言模型LLM基础概览:技术原理、发展历程与未来展望

目录
🍔 大语言模型 (LLM) 背景
🍔 语言模型 (Language Model, LM)
2.1 基于规则和统计的语言模型(N-gram)
2.2 神经网络语言模型
2.3 基于Transformer的预训练语言模型
2.4 大语言模型
🍔 语言模型的评估指标
3.1 BLEU
3.2 ROUGE
3.3 困惑度PPL(perplexity)
🍔 小结

学习目标
🍀 了解LLM背景的知识.
🍀 掌握什么是语言模型
🍔 大语言模型 (LLM) 背景
大语言模型 (英文:Large Language Model,缩写LLM) 是一种人工智能模型, 旨在理解和生成人类语言. 大语言模型可以处理多种自然语言任务,如文本分类、问答、翻译、对话等等.

通常, 大语言模型 (LLM) 是指包含数千亿 (或更多) 参数的语言模型(目前定义参数量超过10B的模型为大语言模型),这些参数是在大量文本数据上训练的,例如模型 GPT-3、ChatGPT、PaLM、BLOOM和 LLaMA等.
截止23年,语言模型发展走过了三个阶段:
-
第一阶段 :设计一系列的自监督训练目标(MLM、NSP等),设计新颖的模型架构(Transformer),遵循Pre-training和Fine-tuning范式。典型代表是BERT、GPT、XLNet等;
-
第二阶段 :逐步扩大模型参数和训练语料规模,探索不同类型的架构。典型代表是BART、T5、GPT-3等;
-
第三阶段 :走向AIGC(Artificial Intelligent Generated Content)时代,模型参数规模步入千万亿,模型架构为自回归架构,大模型走向对话式、生成式、多模态时代,更加注重与人类交互进行对齐,实现可靠、安全、无毒的模型。典型代表是InstructionGPT、ChatGPT、Bard、GPT-4等。
🍔 语言模型 (Language Model, LM)
语言模型(Language Model)旨在建模词汇序列的生成概率,提升机器的语言智能水平,使机器能够模拟人类说话、写作的模式进行自动文本输出。
通俗理解: 用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率.
标准定义:对于某个句子序列, 如S = {W1, W2, W3, …, Wn}, 语言模型就是计算该序列发生的概率, 即P(S). 如果给定的词序列符合语用习惯, 则给出高概率, 否则给出低概率.
举例说明:
-
假设我们要为中文创建一个语言模型,$V$表示词典,$V$={一起、来、学习},$W_i$ 属于$V$。语言模型描述:给定词典$V$, 能够计算出任意单词序列$S={W_1,W_2,W_3,…,W_n}$是一句话的概率$P(S)$, 其中$P >= 0$
-
那么如何计算一个句子的$P(S)$呢?最简单的方法就是计数,假设数据集中共有$N$个句子,我们可以统计一下数据集中$S={W_1,W_2,W_3,…,W_n}$每个句子出现的次数,如果假设为$n$,则$P(S)=\frac{n}{N}$. 那么可以想象一下,这个模型的预测能力几乎为0,一旦单词序列没在之前数据集中出现过,模型的输出概率就是0,显然相当不合理。
-
我们可以根据概率论中的链式法则,将$P$可以表示为:

如果能计算$P(W_n|W_1,W_2,…W_{n-1})$,那么就能轻松得到$P(W_1,W_2,…,W_n)$, 所以在某些文献中,我们也可以看到语言模型的另外一个定义:能够计算出$P(W_1,W_2,…,W_n)$的模型就是语言模型。
从文本生成角度,也可以这样定义语言模型:给定一个短语(一个词组或者一句话),语言模型可以生成(预测)接下来的一个词。
基于语言模型技术的发展,可以将语言模型分为四种类型:
-
基于规则和统计的语言模型
-
神经语言模型
-
预训练语言模型
-
大语言模型
2.1 基于规则和统计的语言模型(N-gram)
由人工设计特征并使用统计方法对固定长度的文本窗口序列进行建模分析,这种建模方式也被称为N-gram语言模型。在上述例子中计算句子序列概率我们使用链式法则计算, 该方法存在两个缺陷:
-
参数空间过大:条件概率$P(W_n|W_1, W_2,….W_n)$的可能性太多,无法估算,也不一定有用
-
数据稀疏严重:许多词对的组合,在语料库中都没有出现,依据最大似然估计得到的概率为0
为了解决上述问题,引入马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。
-
如果一个词的出现与它周围的词是独立的,那么我们就称之为unigram也就是一元语言模型.

-
如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram.

-
如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram.

-
一般来说,N元模型就是假设当前词的出现概率只与它前面的N-1个词有关,而这些概率参数都是可以通过大规模语料库来计算,比如三元概率:

在实践中用的最多的就是bigram和trigram,接下来以bigram语言模型为例,理解其工作原理:
-
首先我们准备一个语料库(简单理解让模型学习的数据集),为了计算对应的二元模型的参数,即$P(W_i|W{i-1})$,我们要先计数即$C(W{i-1},W_i)$,然后计数 $C(W_{i-1})$ , 再用除法可得到概率。
-
$C(W_{i-1}, W_i)$ 计数结果如下:

-
$C(W_{i-1})$ 的计数结果如下:

-
那么bigram语言模型针对上述语料的参数计算结果如何实现?假如,我想计算$P(想|我)\approx0.38$ ,计算过程如下显示:(其他参数计算过程类似)

-
如果针对这个语料库的二元模型(bigram)建立好之后,就可以实现我们的目标计算。
-
计算一个句子的概率,举例如下:

-
预测一句话最可能出现的下一个词汇,比如:我想去打【mask】? 思考:mask = 篮球 或者 mask = 晚饭。


-
可以看出$P(我想去打篮球) > P(我想去打晚饭)$,因此mask = 篮球,对比真实语境下,也符合人类习惯。
N-gram语言模型的特点:
-
优点:采用极大似然估计, 参数易训练; 完全包含了前n-1个词的全部信息; 可解释性强, 直观易理解。
-
缺点:缺乏长期以来,只能建模到前n-1个词; 随着n的增大,参数空间呈指数增长3.数据稀疏,难免会出现OOV问题; 单纯的基于统计频次,泛化能力差.
2.2 神经网络语言模型
伴随着神经网络技术的发展,人们开始尝试使用神经网络来建立语言模型进而解决N-gram语言模型存在的问题。

上图属于一个最基础的神经网络架构:
-
模型的输入:$w{t-n+1}, …, w{t-2}, w_{t-1}$就是前n-1个词。现在需要根据这已知的n-1个词预测下一个词$w_t$。$C(w)$表示$w$所对应的词向量.
-
网络的第一层(输入层)是将$C(w{t-n+1}),…,C(w{t-2}), C(w_{t-1})$这n-1个向量首尾拼接起来形成一个$(n-1)*m$大小的向量,记作$x$.
-
网络的第二层(隐藏层)就如同普通的神经网络,直接使用一个全连接层, 通过全连接层后再使用$tanh$这个激活函数进行处理。
-
网络的第三层(输出层)一共有$V$个节点 ($V$ 代表语料的词汇),本质上这个输出层也是一个全连接层。每个输出节点$y_i$表示下一个词语为 $i$ 的未归一化log 概率。最后使用 softmax 激活函数将输出值$y$进行归一化。得到最大概率值,就是我们需要预测的结果。
神经网络特点:
-
优点:利用神经网络去建模当前词出现的概率与其前 n-1 个词之间的约束关系,很显然这种方式相比 n-gram 具有更好的泛化能力,只要词表征足够好。从而很大程度地降低了数据稀疏带来的问题。
-
缺点:对长序列的建模能力有限,可能会出现长距离遗忘以及训练时的梯度消失等问题,构建的模型难以进行稳定的长文本输出。
2.3 基于Transformer的预训练语言模型

Transformer模型由一些编码器和解码器层组成(见图),学习复杂语义信息的能力强,很多主流预训练模型在提取特征时都会选择Transformer结构,并产生了一系列的基于Transformer的预训练模型,包括GPT、BERT、T5等.这些模型能够从大量的通用文本数据中学习大量的语言表示,并将这些知识运用到下游任务中,获得了较好的效果.
预训练语言模型的使用方式:
-
预训练:预训练指建立基本的模型,先在一些比较基础的数据集、语料库上进行训练,然后按照具体任务训练,学习数据的普遍特征。
-
微调:微调指在具体的下游任务中使用预训练好的模型进行迁移学习,以获取更好的泛化效果。
预训练语言模型的特点:
-
优点:更强大的泛化能力,丰富的语义表示,可以有效防止过拟合。
-
缺点:计算资源需求大,可解释性差等
2.4 大语言模型
随着对预训练语言模型研究的开展,人们逐渐发现可能存在一种标度定律(Scaling Law),即随着预训练模型参数的指数级提升,其语言模型性能也会线性上升。2020年,OpenAI发布了参数量高达1750亿的GPT-3,首次展示了大语言模型的性能。
相较于此前的参数量较小的预训练语言模型,例如,3.3亿参数的Bert-large和17亿参数的GPT-2,GPT-3展现了在Few-shot语言任务能力上的飞跃,并具备了预训练语言模型不具备的一些能力。后续将这种现象称为能力涌现。例如,GPT-3能进行上下文学习,在不调整权重的情况下仅依据用户给出的任务示例完成后续任务。这种能力方面的飞跃引发研究界在大语言模型上的研究热潮,各大科技巨头纷纷推出参数量巨大的语言模型,例如,Meta公司1300亿参数量的LLaMA模型以及谷歌公司5400亿参数量的PaLM。国内如百度推出的文心一言ERNIE系列、清华大学团队推出的GLM系列,等等。
大语言模型的特点:
-
优点:像“人类”一样智能,具备了能与人类沟通聊天的能力,甚至具备了使用插件进行自动信息检索的能力
-
缺点:参数量大,算力要求高、生成部分有害的、有偏见的内容等等
🍔 语言模型的评估指标
3.1 BLEU
BLEU (双语评估替补)分数是评估一种语言翻译成另一种语言的文本质量的指标。它将“质量”的好坏定义为与人类翻译结果的一致性程度。
BLEU算法实际上就是在判断两个句子的相似程度. BLEU 的分数取值范围是 0~1,分数越接近1,说明翻译的质量越高。
BLEU有许多变种,根据n-gram可以划分成多种评价指标,常见的评价指标有BLEU-1、BLEU-2、BLEU-3、BLEU-4四种,其中n-gram指的是连续的单词个数为n,BLEU-1衡量的是单词级别的准确性,更高阶的BLEU可以衡量句子的流畅性.实践中,通常是取N=1~4,然后对进行加权平均。
下面举例说计算过程:
-
基本步骤:
-
分别计算candidate句和reference句的N-grams模型,然后统计其匹配的个数,计算匹配度:
-
公式:candidate和reference中匹配的 n−gram 的个数 /candidate中n−gram 的个数
-
-
假设机器翻译的译文candidate和一个参考翻译reference如下:
candidate: It is a nice day today reference: Today is a nice day
-
使用1-gram进行匹配
candidate: {it, is, a, nice, day, today}
reference: {today, is, a, nice, day}
结果:其中{today, is, a, nice, day}匹配,所以匹配度为5/6
-
使用2-gram进行匹配
candidate: {it is, is a, a nice, nice day, day today}
reference: {today is, is a, a nice, nice day}
结果:其中{is a, a nice, nice day}匹配,所以匹配度为3/5
-
使用3-gram进行匹配
candidate: {it is a, is a nice, a nice day, nice day today}
reference: {today is a, is a nice, a nice day}
结果:其中{is a nice, a nice day}匹配,所以匹配度为2/4
-
使用4-gram进行匹配
candidate: {it is a nice, is a nice day, a nice day today}
reference: {today is a nice, is a nice day}
结果:其中{is a nice day}匹配,所以匹配度为1/3
对匹配的N-grams计数进行修改,以确保它考虑到reference文本中单词的出现,而非奖励生成大量合理翻译单词的候选结果.
-
举例说明:
candidate: the the the the reference: The cat is standing on the ground 如果按照1-gram的方法进行匹配,则匹配度为1,显然是不合理的,所以计算某个词的出现次数进行改进
-
将计算某个词的出现次数的方法改为计算某个词在译文中出现的最小次数,如下所示的公式:

-
其中$k$表示在机器译文(candidate)中出现的第$k$个词语, $c_k$则代表在机器译文中这个词语出现的次数,而$s_k$则代表在人工译文(reference)中这个词语出现的次数。
python代码实现:
# 第一步安装nltk的包-->pip install nltk
from nltk.translate.bleu_score import sentence_bleu
def cumulative_bleu(reference, candidate):
bleu_1_gram = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0))bleu_2_gram = sentence_bleu(reference, candidate, weights=(0.5, 0.5, 0, 0))bleu_3_gram = sentence_bleu(reference, candidate, weights=(0.33, 0.33, 0.33, 0))bleu_4_gram = sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25))
# print('bleu 1-gram: %f' % bleu_1_gram)# print('bleu 2-gram: %f' % bleu_2_gram)# print('bleu 3-gram: %f' % bleu_3_gram)# print('bleu 4-gram: %f' % bleu_4_gram)
return bleu_1_gram, bleu_2_gram, bleu_3_gram, bleu_4_gram
# 生成文本
generated_text = "This is some generated text."
# 参考文本列表
reference_texts = ["This is a reference text.", "This is another reference text."]
# 计算 Bleu 指标
c_bleu = cumulative_bleu(reference_texts, generated_text)
# 打印结果
print("The Bleu score is:", c_bleu)
# The Bleu score is: (0.8571, 0.6900, 0.5711, 0.4920)3.2 ROUGE
ROUGE指标是在机器翻译、自动摘要、问答生成等领域常见的评估指标。ROUGE通过将模型生成的摘要或者回答与参考答案(一般是人工生成的)进行比较计算,得到对应的得分。
ROUGE指标与BLEU指标非常类似,均可用来衡量生成结果和标准结果的匹配程度,不同的是ROUGE基于召回率,BLEU更看重准确率。
ROUGE分为四种方法:ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S.
下面举例说计算过程(这里只介绍ROUGE_N):
-
基本步骤:
-
Rouge-N实际上是将模型生成的结果和标准结果按N-gram拆分后,计算召回率
-
-
假设模型生成的文本candidate和一个参考文本reference如下:
candidate: It is a nice day today reference: Today is a nice day
-
使用ROUGE-1进行匹配
candidate: {it, is, a, nice, day, today}
reference: {today, is, a, nice, day}
结果::其中{today, is, a, nice, day}匹配,所以匹配度为5/5=1,这说明生成的内容完全覆盖了参考文本中的所有单词,质量较高。
-
通过类似的方法,可以计算出其他ROUGE指标(如ROUGE-2、ROUGE-L、ROUGE-S)的评分,从而综合评估系统生成的文本质量。
python代码实现:
# 第一步:安装rouge-->pip install rouge
import Rouge
# 生成文本
generated_text = "This is some generated text."
# 参考文本列表
reference_texts = ["This is a reference text.", "This is another generated reference text."]
# 计算 ROUGE 指标
rouge = Rouge()
scores = rouge.get_scores(generated_text, reference_texts[1])
# 打印结果
print("ROUGE-1 precision:", scores[0]["rouge-1"]["p"])
print("ROUGE-1 recall:", scores[0]["rouge-1"]["r"])
print("ROUGE-1 F1 score:", scores[0]["rouge-1"]["f"])
# ROUGE-1 precision: 0.8
# ROUGE-1 recall: 0.6666666666666666
# ROUGE-1 F1 score: 0.72727272231404963.3 困惑度PPL(perplexity)
PPL用来度量一个概率分布或概率模型预测样本的好坏程度。
PPL基本思想:
-
给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好.
-
基本公式(两种方式):


-
由公式可知,句子概率越大,语言模型越好,迷惑度越小。
python代码实现:
import math
# 定义语料库
sentences = [
['I', 'have', 'a', 'pen'],
['He', 'has', 'a', 'book'],
['She', 'has', 'a', 'cat']
]
# 定义语言模型
unigram = {
'I': 1/11,
'have': 1/11,
'a': 3/11,
'pen': 1/11,
'He': 1/11,
'has': 2/11,
'book': 1/11,
'She': 1/11,
'cat': 1/11
}
# 计算困惑度
perplexity = 0
for sentence in sentences:sentence_prob = 1for word in sentence:sentence_prob *= unigram[word]sentence_perplexity = 1/sentence_probperplexity += math.log(sentence_perplexity, 2) #以2为底
perplexity = 2 ** (-perplexity/len(sentences))
print('困惑度为:', perplexity)
# 困惑度为: 0.000325🍔 小结
-
本小节主要介绍LLM的背景知识,了解目前LLM发展基本历程
-
对语言模型的类别分别进行了介绍,如基于统计的N-gram模型,以及深度学习的神经网络模型


💘若能为您的学习之旅添一丝光亮,不胜荣幸💘
🐼期待您的宝贵意见,让我们共同进步共同成长🐼
相关文章:
【AI大模型】大型语言模型LLM基础概览:技术原理、发展历程与未来展望
目录 🍔 大语言模型 (LLM) 背景 🍔 语言模型 (Language Model, LM) 2.1 基于规则和统计的语言模型(N-gram) 2.2 神经网络语言模型 2.3 基于Transformer的预训练语言模型 2.4 大语言模型 🍔 语言模型的评估指标 …...

ubuntu 22.04 server 安装 和 初始化 LTS
ubuntu 22.04 server 安装 和 初始化 下载地址 https://releases.ubuntu.com/jammy/ 使用的镜像是 ubuntu-22.04.5-live-server-amd64.iso usb 启动盘制作工具 https://rufus.ie/zh/ rufus-4.6p.exe 需要主板 支持 UEFI 启动 Ubuntu22.04.4-server安装 流程 https://b…...

大数据机器学习算法与计算机视觉应用03:数据流
Data Stream Streaming ModelExample Streaming QuestionsHeavy HittersAlgorithm 1: For Majority elementMisra Gries AlgorithmApplicationsApproximation of count Streaming Model 数据流模型 数据流就是所有的数据先后到达,而不是同时存储在内存之中。在现…...

【代码随想录day25】【C++复健】491.递增子序列;46.全排列;47.全排列 II;51. N皇后;37. 解数独
491.递增子序列 本题做的时候除了去重逻辑之外,其他的也勉强算是写出来了,不过还是有问题的,总结如下: 1 本题的关键:去重 与其说是不知道用什么去重,更应该说是完全没想到本题需要去重,说明…...

AI智能识物(微信小程序)
AI智能识物,是一款实用的小程序。可以拍照智能识物,可识别地标、车型、花卉、植物、动物、果蔬、货币、红酒、食材等等,AI智能技术识别准确度高。 更新说明: 此源码为1.2.0版本。 主要更新内容:新增security.imgSec…...

游戏引擎学习第三天
视频参考:https://www.bilibili.com/video/BV1XTmqYSEtm/ 之前的程序不能退出,下面写关闭窗体的操作 PostQuitMessage 是 Windows API 中的一个函数,用于向当前线程的消息队列发送一个退出消息。其作用是请求应用程序退出消息循环,通常用于处…...
帝国CMS7.5仿模板堂柒喜模板建站网 素材资源下载站源码
环境要求:phpmysql、支付伪静态 本套模板采用帝国cms7.5版UTF-8开发,一款非常不错的高端建站源码模板, 适用于中小型网络建站工作室源码模板下载站,支持自定义设置会员组。 源码下载:https://download.csdn.net/down…...
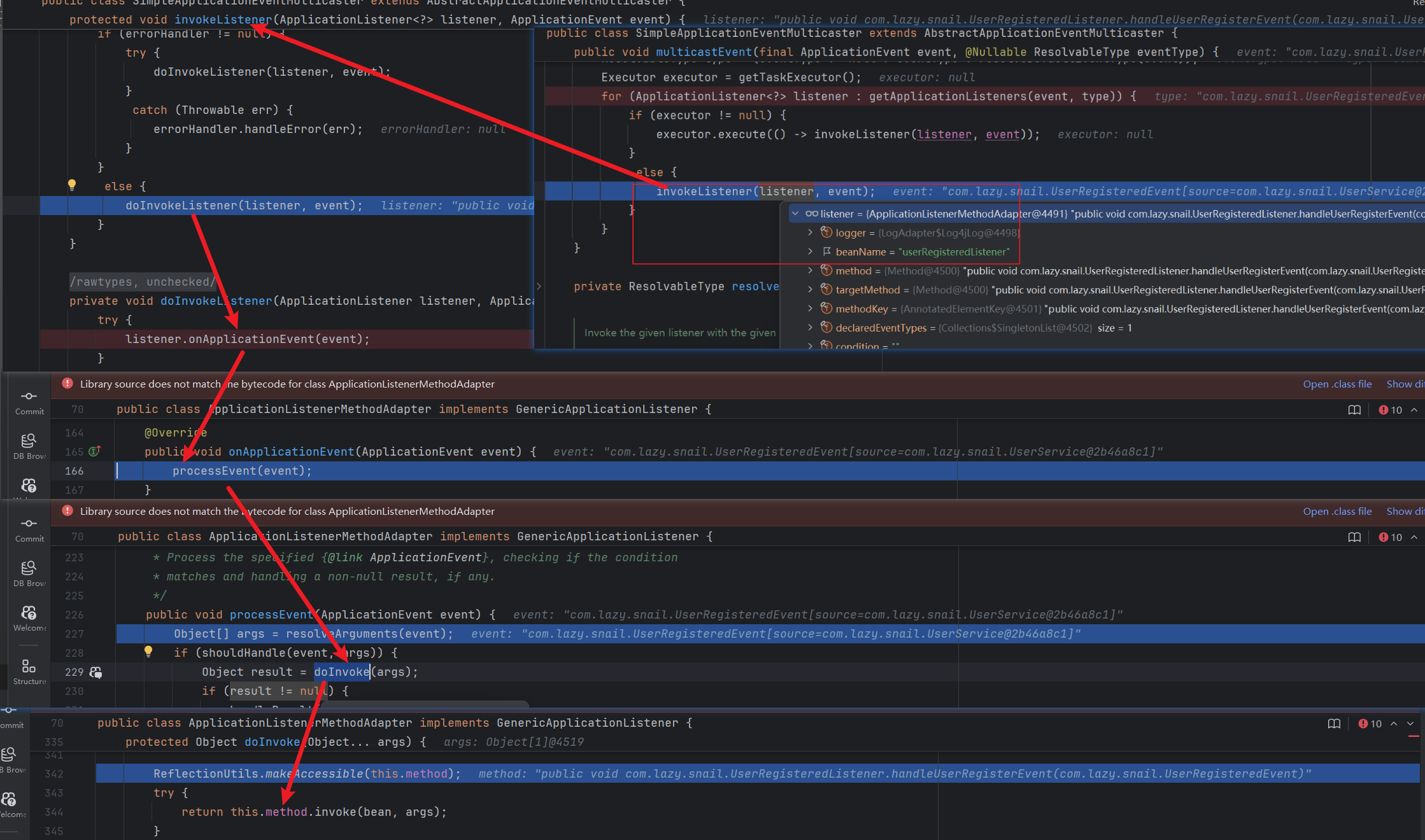
聊一聊Spring中的自定义监听器
前言 通过一个简单的自定义的监听器,从源码的角度分一下Spring中监听的整个过程,分析监听的作用。 一、自定义监听案例 1.1定义事件 package com.lazy.snail;import lombok.Getter; import org.springframework.context.ApplicationEvent;/*** Class…...
【王木头】最大似然估计、最大后验估计
目录 一、最大似然估计(MLE) 二、最大后验估计(MAP) 三、MLE 和 MAP 的本质区别 四、当先验是均匀分布时,MLE 和 MAP 等价 五、总结 本文理论参考王木头的视频: 贝叶斯解释“L1和L2正则化”ÿ…...

智谱AI视频生成模型CogVideoX v1.5开源 支持5/10秒视频生成
今日,智谱技术团队发布了其最新的视频生成模型 CogVideoX v1.5,并将其开源。这一版本是自8月以来,智谱技术团队推出的 CogVideoX 系列中的又一重要进展。 据了解,此次更新大幅提升了视频生成能力,包括支持5秒和10秒的视…...

算法(第一周)
一周周五,总结一下本周的算法学习,从本周开始重新学习许久未见的算法,当然不同于大一时使用的 C 语言以及做过的简单题,现在是每天一题 C 和 JavaScript(还在学,目前只写了一题) 题单是代码随想…...

Linux服务器进程的控制与进程之间的关系
在 Linux 服务器中,进程控制和进程之间的关系是系统管理的一个重要方面。理解进程的生命周期、控制以及它们之间的父子关系对于系统管理员来说至关重要。以下是关于进程控制、进程之间的关系以及如何管理进程的详细介绍: 1. 进程的概念 进程࿰…...

机器学习Housing数据集
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from sklearn.datasets import fetch_openml 设置Seaborn的美观风格 sns.set(style“whitegrid”) Step 1: 下载 Housing 数据集,并读入计算机 def load_housing_data(): housing …...

随着最新的补丁更新,Windows 再次变得容易受到攻击
SafeBreach专家Alon Leviev发布了一款名为 Windows Downdate的工具,可用于对Windows 10、Windows 11 和 Windows Server 版本进行降级攻击。 这种攻击允许利用已经修补的漏洞,因为操作系统再次容易受到旧错误的影响。 Windows Downdate 是一个开源Pyth…...

【Python】爬虫通过验证码
1、将验证码下载至本地 # 获取验证码界面html url http://www.example.com/a.html resp requests.get(url) soup BeautifulSoup(resp.content.decode(UTF-8), html.parser)#找到验证码图片标签,获取其地址 src soup.select_one(div.captcha-row img)[src]# 验证…...
dc-aichat(一款支持ChatGPT+智谱AI+讯飞星火+书生浦语大模型+Kimi.ai+MoonshotAI+豆包AI等大模型的AIGC源码)
dc-aichat 一款支持ChatGPT智谱AI讯飞星火书生浦语大模型Kimi.aiMoonshotAI豆包AI等大模型的AIGC源码。全网最易部署,响应速度最快的AIGC环境。PHP版调用各种模型接口进行问答和对话,采用Stream流模式通信,一边生成一边输出。前端采用EventS…...

检索增强生成
检索增强生成 检索增强生成简介 检索增强生成(RAG)旨在通过检索和整合外部知识来增强大语言模型生成文本的准确性和丰富性,其是一个集成了外部知识库、信息检索器、大语言模型等多个功能模块的系统。 RAG 利用信息检索、深度学习等多种技术…...

操作系统--进程
2.1.1 进程的概念、组成、特征 进程的概念 进程的组成 进程的特征 总结 2.1.2 进程的状态与转换,进程的组织 创建态、就绪态 运行态 阻塞态 终止态 进程状态的转换 进程的组织 链式方式 索引方式 2.1.3 进程控制 如何实现进程控制? 在下面的例子,将PCB2的是state设为1和和把…...

abap 可配置通用报表字段级日志监控
文章目录 1.功能需求描述1.1 功能1.2 效果展示2.数据库表解释2.1 表介绍3.数据库表及字段3.1.应用日志数据库抬头表:ZLOG_TAB_H3.2.应用日志数据库明细表:ZLOG_TAB_P3.3.应用日志维护字段配置表:ZLOG_TAB_F4.日志封装类5.代码6.调用方式代码7.调用案例程序demo1.功能需求描述 …...

OpenCV视觉分析之目标跟踪(11)计算两个图像之间的最佳变换矩阵函数findTransformECC的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 根据 ECC 标准 78找到两幅图像之间的几何变换(warp)。 该函数根据 ECC 标准 ([78]) 估计最优变换(warpMatri…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

Bean 作用域有哪些?如何答出技术深度?
导语: Spring 面试绕不开 Bean 的作用域问题,这是面试官考察候选人对 Spring 框架理解深度的常见方式。本文将围绕“Spring 中的 Bean 作用域”展开,结合典型面试题及实战场景,帮你厘清重点,打破模板式回答,…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...
高考志愿填报管理系统---开发介绍
高考志愿填报管理系统是一款专为教育机构、学校和教师设计的学生信息管理和志愿填报辅助平台。系统基于Django框架开发,采用现代化的Web技术,为教育工作者提供高效、安全、便捷的学生管理解决方案。 ## 📋 系统概述 ### 🎯 系统定…...

Java并发编程实战 Day 11:并发设计模式
【Java并发编程实战 Day 11】并发设计模式 开篇 这是"Java并发编程实战"系列的第11天,今天我们聚焦于并发设计模式。并发设计模式是解决多线程环境下常见问题的经典解决方案,它们不仅提供了优雅的设计思路,还能显著提升系统的性能…...
深入解析光敏传感技术:嵌入式仿真平台如何重塑电子工程教学
一、光敏传感技术的物理本质与系统级实现挑战 光敏电阻作为经典的光电传感器件,其工作原理根植于半导体材料的光电导效应。当入射光子能量超过材料带隙宽度时,价带电子受激发跃迁至导带,形成电子-空穴对,导致材料电导率显著提升。…...

AT模式下的全局锁冲突如何解决?
一、全局锁冲突解决方案 1. 业务层重试机制(推荐方案) Service public class OrderService {GlobalTransactionalRetryable(maxAttempts 3, backoff Backoff(delay 100))public void createOrder(OrderDTO order) {// 库存扣减(自动加全…...