实现链式结构二叉树
目录
需要实现的操作
链式结构二叉树实现
结点的创建
前序遍历
中序遍历
后序遍历
计算结点个数
计算二叉树的叶子结点个数
计算二叉树第k层结点个数
计算二叉树的深度
查找值为x的结点
销毁
层序遍历
判断是否为完全二叉树
总结
需要实现的操作
//前序遍历
void PreOrder(BTNode* root);//中序遍历
void InOrder(BTNode* root);//后序遍历
void PostOrder(BTNode* root);//计算结点个数
int BinaryTreeSize(BTNode* root);//二叉树的叶子结点个数
int BinaryTreeLeafSize(BTNode* root);//二叉树第k层结点个数
int BinaryTreeLevelKSize(BTNode* root, int k);//二叉树的深度
int BinaryTreeDepth(BTNode* root);//二叉树查找值为x的结点
BTNode* BinaryTreeFind(BTNode* root, BTDatatype x);//销毁
void BinaryTreeDestroy(BTNode** root);//层序遍历
void LevelOrder(BTNode* root);//判断是否为完全二叉树
bool BinaryTreeComplete(BTNode* root);链式结构二叉树实现
结点的创建
⽤链表来表⽰⼀棵⼆叉树,即⽤链来指⽰元素的逻辑关系。 通常的⽅法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别⽤来给出该结点左孩⼦和右孩⼦所在的链结点的存储地址 , 其结构如下:
typedef int BTDataType;
// ⼆叉链
typedef struct BinaryTreeNode
{
struct BinTreeNode* left; // 指向当前结点左孩⼦
struct BinTreeNode* right; // 指向当前结点右孩⼦
BTDataType val; // 当前结点值域
}BTNode;⼆叉树的创建⽅式⽐较复杂,为了更好的步⼊到⼆叉树内容中,我们先⼿动创建⼀棵链式⼆叉树
BTNode* BuyNode(int val)
{BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));if (newnode == NULL){perror("malloc fail!");exit(1);}newnode->data = val;newnode->left = newnode->right = NULL;return newnode;
}
void CreatTree()
{BTNode* n1 = BuyNode(1);BTNode* n2 = BuyNode(2);BTNode* n3 = BuyNode(3);BTNode* n4 = BuyNode(4);n1->left = n2;n1->right = n3;n2->left = n4;
}
int main()
{CreatTree();return 0;
}前序遍历
前序遍历:访问根结点的操作发⽣在遍历其左右⼦树之前
访问顺序为:根结点、左⼦树、右⼦树

以该图为例,前序遍历从我们创建链式二叉树的根节点1开始,按照“根左右”的顺序,先遍历自己,在遍历左子树2,同时以2为中心,遍历2的左子树,当遍历完4时,同样以4为中心遍历4的左子树,但是4的左子树为NULL,只能返回,再以4为中心遍历4的右子树,同样为NULL返回。2的左子树遍历完后遍历2的右子树,为NULL返回。这样1的左子树遍历完了,再用同样方法遍历1的右子树。
从以上实现步骤来看,前序遍历在遍历时一环套一环,当遇到NULL时,需要返回。可以利用递归的方式实现前序遍历。
//前序遍历
void PreOrder(BTNode* root)
{if (root == NULL)//遇到NULL时返回{return;}//按照根左右顺序遍历printf("%d ", root->data);PreOrder(root->left);//一环套一环先遍历左子树PreOrder(root->right);
}中序遍历
中序遍历:访问根结点的操作发⽣在遍历其左右⼦树之中
访问顺序为:左⼦树、根结点、右⼦树

以该图为例,中序遍历从我们创建链式二叉树的根节点1开始,按照“左根右”的顺序,先以1为中心往左子树找,直到找到NULL返回,遍历4,再遍历右子树,为NULL返回。2的左子树遍历完,遍历2,之后遍历右子树,为NULL返回。这样1的左子树遍历完,再遍历1,最后以同样方式遍历右子树。
从以上实现步骤来看,中序遍历在遍历时一环套一环,当遇到NULL时,需要返回。可以利用递归的方式实现中序遍历。
//中序遍历
void InOrder(BTNode* root)
{if (root == NULL){return;}//根据左根右的顺序遍历InOrder(root->left);printf("%d ", root->data);InOrder(root->right);
}后序遍历
后序遍历:访问根结点的操作发⽣在遍历其左右⼦树之后
访问顺序为:左⼦树、右⼦树、根结点

以该图为例,后序遍历从我们创建链式二叉树的根节点1开始,按照“左右根”的顺序,先以1为中心往左子树找,直到找到NULL返回,再以4为中心遍历右子树,为NULL返回,最后遍历4。2的左子树遍历完,遍历右子树,为NULL返回,最后遍历2。这样1的左子树遍历完,再遍历1的右子树,最后遍历1。
从以上实现步骤来看,后序遍历在遍历时一环套一环,当遇到NULL时,需要返回。可以利用递归的方式实现后序遍历。
计算结点个数
计算链式二叉树的结点个数,我们可以利用递归的方式找到每一个结点,遇到NULL返回0,先找左子树上的结点,再找右子树上的结点。可以得出以下代码:
int size = 0;
int BinaryTreeSize(BTNode* root, int size)
{if(root == NULL){return 0;//遇到非结点返回0}++size;//遍历完一个结点记一次BinaryTreeSize(root->left, size);//遍历左子树结点BinaryTreeSize(root->right, size);//遍历右子树结点return size;
}但是这样写得出的结果却是错误的,因为在传递参数时,传的是值,当函数栈帧遍历到4时,++size总共进行了3次,size为3,但是返回后栈帧自动回收,当进行遍历右结点的操作时,全局变量size的值为1,没有得到保存。

那么是否可以通过传递地址的方式来永久改变size的值呢?
void BinaryTreeSize(BTNode* root, int* size)//传地址
{if(root == NULL){return 0;}++(*size);BinaryTreeSize(root->left, size);BinaryTreeSize(root->right, size);
}
这样写成功将size的值进行了正确的计算,结果在栈帧销毁时得到了保存。但是如果在实际运用中需要两次及以上计算结点的个数,size的值一直得到保存后,必然发生错误。
如何做到size的值既能在一次计算中得到保存,还能不会影响之后计算结点的个数?
我们可以将递归的发生保存在返回值中,遇到NULL时返回0,如果左右子树都为0,则只返回1来表示自身的结点个数。
//计算结点个数
int BinaryTreeSize(BTNode* root)
{if (root == NULL){return 0;}return BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1;
}计算二叉树的叶子结点个数
叶子结点:度为 0 的结点称为叶结点
计算二叉树叶子结点的个数,可以根据结点是否有左右子树来判断,当结点同时不存在左右子树时,该结点就是叶子结点。
联系上文,利用递归方法对二叉树进行遍历。

//二叉树的叶子结点个数
int BinaryTreeLeafSize(BTNode* root)
{if (root == NULL){return 0;}if (root->left == NULL && root->right == NULL)//叶子结点{return 1;}return BinaryTreeLeafSize(root->left) +BinaryTreeLeafSize(root->right);
}计算二叉树第k层结点个数
若规定根结点的层数为 i ,则⼀棵⾮空⼆叉树的第i层上最多有 2^(i-1) 个结点
第k层结点个数 = 第k层左子树结点 + 第k层右子树结点

以该图为例,若想要计算第三层的结点个数,则需要将k调整为1,当k值为1时,返回1个结点。
同理,利用递归的方法遍历左右子树,同时利用 k-1 的方式不断向下调整,当遇到 k == 1 时,返回1,遇到NULL时返回0。
//二叉树第k层结点个数
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL)//为空返回0{return 0;}if (k == 1)//第k层的结点{return 1;}return BinaryTreeLevelKSize(root->left, k - 1) +BinaryTreeLevelKSize(root->right, k - 1);//k-1向下寻找第k层结点
}计算二叉树的深度
计算二叉树的深度时,需要比较左右子树两边的深度值,找到较大一方的深度进行返回来代表二叉树的整体深度。
利用递归向下调整计算深度
根据分析绘制图例:

当递归过程中遭遇NULL时,返回0。遇到结点时向上返回1。最后比较左右子树计算而来的深度,取大值2,+1得出最后的深度为3。
由此我们可以设置两个变量 leftdep 和 rightdep ,leftdep计算左子树深度,rightdep计算右子树深度。递归的结束条件为 root == NULL 时返回0。
像这样不断向下递归,以1为中心左右子树向下递归,而后再以左右子树为中心递归自身的左右子树,返回值取每一个左右子树的较大值+1进行返回。
//二叉树的深度
int BinaryTreeDepth(BTNode* root)
{if (root == NULL)//递归结束条件{return 0;}int leftdep = BinaryTreeDepth(root->left);//左子树深度int rightdep = BinaryTreeDepth(root->right);//右子树深度return leftdep > rightdep ? leftdep + 1 : rightdep + 1;
}查找值为x的结点
依据前文,查找结点需要不断向下查找,所以依然可以利用递归的方式查找结点。
当向下递归查找找到x时,返回当前结点。当没有查找到x时,返回NULL。
可以先查找左子树,再查找右子树。当左子树先一步查找到值为x的结点时,可以提前返回结点。
进一步查找右子树,查找到时返回值为x的结点。

//二叉树查找值为x的结点
BTNode* BinaryTreeFind(BTNode* root, BTDatatype x)
{if (root == NULL)//左子树没有找到,右子树没有找到,二叉树没找到{return NULL;}if (root->data == x)//查找到值为x的结点{return root;}BTNode* leftfind = BinaryTreeFind(root->left, x);//先查找左子树if (leftfind)//如果左子树不为空,提前返回结点{return leftfind;}BTNode* rightfind = BinaryTreeFind(root->right, x);if (rightfind){return rightfind;}return NULL;//没有查找到值为x的结点
}销毁
销毁二叉树需要先销毁左子树,再销毁右子树,最后销毁根结点。
同样利用递归的方式找结点,先找左子树,后找右子树。递归结束条件为结点为NULL,这样就可以从每一个子树的尾部向上销毁每一个结点。
因为需要对二叉树进行改变,所以传参时需要传递地址。

//销毁
void BinaryTreeDestroy(BTNode** root)//传一级指针的地址,也就是二级指针
{if (*root == NULL)//找到每一个子树最后的结点{return;}BinaryTreeDestroy(&((*root)->left));BinaryTreeDestroy(&((*root)->right));free(*root);//销毁*root = NULL;
}层序遍历
除了先序遍历、中序遍历、后序遍历外,还可以对⼆叉树进⾏层序遍历。设⼆叉树的根结点所在层数为1,层序遍历就是从所在⼆叉树的根结点出发,⾸先访问第⼀层的树根结点,然后从左到右访问第2 层上的结点,接着是第三层的结点,以此类推,⾃上⽽下,⾃左⾄右逐层访问树的结点的过程就是层序遍历。
实现层序遍历需要额外借助数据结构:队列
根据先前创建的结点进行层序遍历,得出以下图示:

考虑递归的方式分别从左右子树进行遍历,无法达到层序遍历的效果。所以需要利用队列“先进先出”的特点来实现。
为了实现层序遍历,我们可以利用队列,插入根节点,再取出队列,判断该结点是否有左孩子和右孩子,如果有则插入。直到队列为空结束循环。

队列的实现:
typedef struct BinaryTreeNode* QDatatype;typedef struct QueueNode
{QDatatype data;struct QueueNode* next;
}QueueNode;
typedef struct Queue
{QueueNode* phead;QueueNode* ptail;int size;
}Queue;//初始化
void QueueInit(Queue* pq);//销毁队列
void QueueDestroy(Queue* pq);//入队列
void QueuePush(Queue* pq, QDatatype x);//出队列
void QueueBack(Queue* pq);//判空
bool QueueEmpty(Queue* pq);层序遍历:
//层序遍历
void LevelOrder(BTNode* root)
{Queue q;//创建队列QueueInit(&q);//初始化QueuePush(&q, root);//插入根节点while (!QueueEmpty(&q))//当队列不为空时循环{//打印队头数据,出队列BTNode* front = QueueTou(&q);QueueBack(&q);printf("%d ", front->data);//判断这个数据是否有左右子树,插入if (front->left)QueuePush(&q, front->left);if (front->right)QueuePush(&q, front->right);}//销毁队列QueueDestroy(&q);
}判断是否为完全二叉树
完全二叉树:一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
判断是否为完全二叉树时,我们可以利用层序遍历的原理,利用队列“先进先出”的特点来实现。
往队列中插入根节点,再取出队列,判断该结点是否有左孩子和右孩子,如果有则插入,如果没有则将NULL也插入到队列中,当出队列时,出队列的数据为NULL,提前跳出循环。
存在两种情况,当出队列的数据为NULL时,跳出循环后:
队列中仍存在有效数据,则这个二叉树不是完全二叉树。
队列中只剩NULL时,这个二叉树是完全二叉树。

//判断是否为完全二叉树
bool BinaryTreeComplete(BTNode* root)
{Queue q;QueueInit(&q);QueuePush(&q, root);while (!QueueEmpty(&q)){//插入数据,直到插入的数据为空BTNode* front = QueueTou(&q);QueueBack(&q);if (front == NULL)//出队列的数据为NULL时提前结束循环{break;}QueuePush(&q, front->left);QueuePush(&q, front->right);}//队列要么只剩下NULL,要么还有非空结点while (!QueueEmpty(&q)){BTNode* front = QueueTou(&q);QueueBack(&q);if (front != NULL)//队列中还有非空结点{QueueDestroy(&q);return false;}}QueueDestroy(&q);return true;
}总结
实现链式二叉树主要依靠队列和递归的知识来实现,代码量虽然少,但是展开递归后的操作却是较为复杂的。队列和递归的结合也帮助我们更好地实现二叉树。
相关文章:
实现链式结构二叉树
目录 需要实现的操作 链式结构二叉树实现 结点的创建 前序遍历 中序遍历 后序遍历 计算结点个数 计算二叉树的叶子结点个数 计算二叉树第k层结点个数 计算二叉树的深度 查找值为x的结点 销毁 层序遍历 判断是否为完全二叉树 总结 需要实现的操作 //前序遍历 void …...

在vscode中如何利用git 查看某一个文件的提交记录
在 Visual Studio Code (VSCode) 中,你可以使用内置的 Git 集成来查看某个文件的提交历史。以下是具体步骤: 使用 VSCode 内置 Git 功能 打开项目: 打开你的项目文件夹,确保该项目已经是一个 Git 仓库(即项目根目录下…...

【ShuQiHere】️`adb kill-server` 和 `adb start-server` 命令的作用
📟🔧 【ShuQiHere】️ 🔧📟 在使用 scrcpy 或其他依赖于 ADB(Android Debug Bridge) 的工具时,您可能会遇到需要重启 ADB 服务器的情况。今天,我们将详细解释两个常用的 ADB 命令&a…...

植物明星大乱斗1
能帮到你的话,就给个赞吧 😘 文章目录 scene.hmenuScene.hgameScene.hmainscene.cppmenuScene.cppgameScene.cpp scene.h #pragma once #include <graphics.h>/* 场景菜单角色选择游戏 */ class Scene { public:virtual ~Scene() 0; public:virt…...

信息安全工程师(84)UNIX/Linux操作系统安全分析与防护
前言 UNIX/Linux操作系统,尤其是Linux,以其开放性、稳定性和安全性在服务器、桌面、嵌入式设备和超级计算机中占据重要地位。然而,没有任何操作系统可以百分之百地保证安全,UNIX/Linux也不例外。 一、UNIX/Linux操作系统安全分析 …...

全面解析 Python typing模块与静态类型注解:从基础到高级
在现代软件开发中,代码的可读性、维护性和可靠性至关重要。Python 作为一门动态类型语言,尽管灵活,但也可能带来一些类型上的困扰。Python 的 typing 模块和静态类型注解提供了一种在编写代码时明确类型信息的方法,从而提升代码质…...
Jekins篇(搭建/安装/配置)
目录 一、环境准备 1. Jenkins安装和持续集成环境配置 2. 服务器列表 3. 安装环境 Jekins 环境 4. JDK 环境 5. Maven环境 6. Git环境 方法一:yum安装 二、JenKins 安装 1. JenKins 访问 2. jenkins 初始化配置 三、Jenkins 配置 1. 镜像配置 四、Mave…...

【工具变量】排污权交易政策试点DID(2000-2023)
数据简介:在过去几十年间的“高增长、高能耗、高污染”的经济发展背景下,随着社会各界不断反应高经济增长背后付出的巨大环境代价,中国ZF将节能环保减排纳入长期规划治理中。在2007年,我国开始启动了二氧化硫(SO2&…...

Proteus中数码管动态扫描显示不全(已解决)
文章目录 前言解决方法后记 前言 我是直接把以前写的 51 数码管程序复制过来的,当时看的郭天祥的视频,先送段选,消隐后送位选,最后来个 1ms 的延时。 代码在 Proteus 中数码管静态是可以的,动态显示出了问题——显示…...

证件照尺寸168宽240高,如何手机自拍更换蓝底
在提供学籍照片及一些社会化考试报名时,会要求我们提供尺寸为168*240像素的电子版证件照,本文将介绍如何使用“报名电子照助手”,借助手机拍照功能完成证件照的拍摄和背景更换,特别是如何将照片尺寸调整为168像素宽和240像素高&am…...

力扣.167 两数之和 II two-sum-ii
数组系列 力扣数据结构之数组-00-概览 力扣.53 最大子数组和 maximum-subarray 力扣.128 最长连续序列 longest-consecutive-sequence 力扣.1 两数之和 N 种解法 two-sum 力扣.167 两数之和 II two-sum-ii 力扣.170 两数之和 III two-sum-iii 力扣.653 两数之和 IV two-…...

ipconfig
本文内容来自智谱清言的回答。 ------ 以太网适配器 以太网: 媒体状态 . . . . . . . . . . . . : 媒体已断开连接 连接特定的 DNS 后缀 . . . . . . . : 以太网适配器 以太网: 这部分表示正在显示名为“以太网”的网络适配器的信息。在 Windows 中,默认的以太…...

Qt_day3_信号槽
目录 信号槽 1. 概念 2. 函数原型 3. 连接方式 3.1 自带信号 → 自带槽 3.2 自带信号 → 自定义槽 3.3 自定义信号 4. 信号槽传参 5. 对应关系 5.1 一对多 5.2 多对一 信号槽 1. 概念 之前的程序界面只能看,不能交互,信号槽可以让界面进行人机…...

求从2开始的第n个素数
方法一:暴力法 思路:从2开始,逐个判断每个数是否为素数。素数是除了1和它自身外,不能被其他自然数整除的数。对于每个数m,从2到sqrt(m)遍历,如果能被整除则不是素数。当找到n个素数时停止。 C 代码如下&am…...

【Android】View—基础知识,滑动,弹性滑动
基础知识 什么是View 在 Android 中,View 是用户界面(UI)中的基本组件,用于绘制图形和处理用户交互。所有的 UI 组件(如按钮、文本框、图片等)都是 View 的子类。可以说,View 是构建 Android …...

MYSQL中的两种转义操作
在 MySQL 中,转义字符用于处理特殊字符,以防止语法错误或 SQL 注入攻击,而单双引号都是需要重点注意的字符 可以用转义符\ 和 两个连续的引号 来起到转义引号的作用 转义符转义: 这是users表中的数据 如果查询admin 或者 admin" 用户,可以用转义符\ 两个连…...
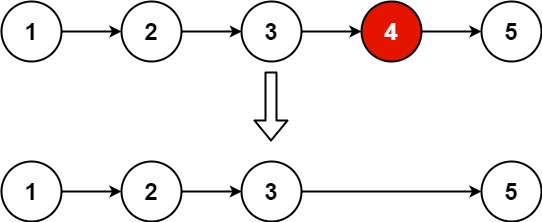
力扣题目解析--删除链表的倒数第n个节点
题目 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5]示例 2: 输入:head [1], n 1 输出:[]示例 3&…...
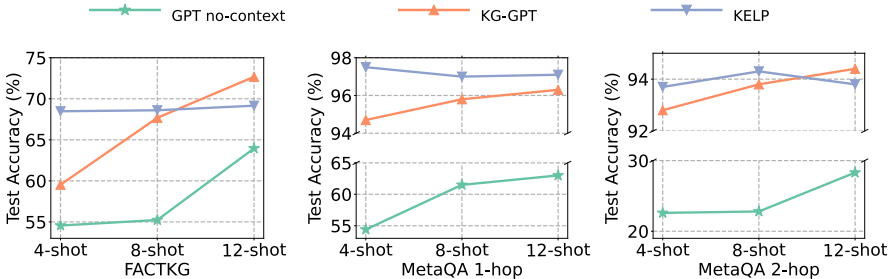
Knowledge Graph-Enhanced Large Language Models via Path Selection
研究背景 研究问题:这篇文章要解决的问题是大型语言模型(LLMs)在生成输出时存在的事实不准确性,即所谓的幻觉问题。尽管LLMs在各种实际应用中表现出色,但当遇到超出训练语料库范围的新知识时,它们通常会生…...

Android 项目模型配置管理
Android 项目配置管理 项目模型相关的配置管理config.gradle文件:build.gradle文件: 参考地址 项目模型相关的配置管理 以下是一个完整的build.gradle和config.gradle示例: config.gradle文件: ext {// 模型相关配置࿰…...

「QT」几何数据类 之 QSizeF 浮点型尺寸类
✨博客主页何曾参静谧的博客📌文章专栏「QT」QT5程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasolid…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...