堆排序与链式二叉树:数据结构与排序算法的双重探索

大家好,我是小卡皮巴拉
文章目录
目录
引言
一.堆排序
1.1 版本一
核心概念
堆排序过程
1.2 版本二
堆排序函数 HeapSort
向下调整算法 AdjustDown
向上调整算法 AdjustUp
二.链式二叉树
2.1 前中后序遍历
链式二叉树的结构
创建链式二叉树
前序遍历
中序遍历
后序遍历
2.2 链式二叉树的常见操作
二叉树的结点个数
二叉树叶子结点的个数
二叉树第k层结点的个数
求二叉树的高度/深度
二叉树查找值为x的结点
2.3 层序遍历
使用层序遍历检验是否为完全二叉树
兄弟们共勉 !!!
每篇前言
博客主页:小卡皮巴拉
咱的口号:🌹小比特,大梦想🌹
作者请求:由于博主水平有限,难免会有错误和不准之处,我也非常渴望知道这些错误,恳请大佬们批评斧正。

引言
在数据结构与算法的广阔天地中,堆排序与链式二叉树无疑是两颗璀璨的明珠。它们各自以其独特的魅力和广泛的应用场景,在数据处理和算法优化中发挥着举足轻重的作用。
堆排序,作为一种基于堆数据结构的比较排序算法,以其高效的排序速度和稳定的性能表现,成为了众多排序算法中的佼佼者。它利用堆的性质,通过一系列精心设计的操作,将无序的数据逐步转化为有序,从而实现了数据的快速排序。
而链式二叉树,则以其灵活的节点连接方式和高效的查找性能,成为了数据结构中不可或缺的一部分。它通过将数据元素组织成二叉树的形式,利用节点的指针域实现数据的动态存储和访问,为数据的查找、插入和删除等操作提供了极大的便利。
今天,我们将一起踏上一段探索之旅,深入剖析堆排序的算法实现与链式二叉树的构建细节。从堆的构建、调整与排序过程,到链式二叉树的节点定义、插入与遍历操作,我们将一步步揭开这两大数据结构的神秘面纱,带你领略它们背后的智慧与魅力。
一.堆排序
1.1 版本一
版本一:基于已有数组建堆、取堆顶元素完成排序版本
void HeapSort(int* arr,int n)
{HP hp;HPInit(&hp);//调用push将数组中的数据建堆for (int i = 0; i < n; i++){HPPush(&hp, arr[i]);}int i = 0;while (!HPEmpty(&hp)){arr[i++] = HPTop(&hp);HPPop(&hp);}HPDesTroy(&hp);
}核心概念
堆:一种特殊的完全二叉树,用于实现堆排序。这里我们假设使用最大堆。
空间复杂度:O(N),因为使用了额外的堆数据结构。
堆排序过程
构建堆:
将数组
a中的元素逐个添加到堆hp中。注意:传统堆排序直接在输入数组上构建堆,这里为了教学目的使用了额外的堆结构。
排序:
当堆不为空时,重复以下步骤:
取出堆顶元素(最大值),将其放到数组
a的当前位置。从堆中移除堆顶元素。
这个过程会持续到堆为空,此时数组
a将按降序排列。清理:
销毁堆
hp,释放任何动态分配的内存。
1.2 版本二
数组建堆,首尾交换,交换后的堆尾数据从堆中删掉,将堆顶数据向下调整选出次大的数据
堆排序函数
HeapSort
函数定义:
void HeapSort(int* arr, int n)
arr:指向待排序数组的指针。
n:数组的长度。建堆过程:
循环从最后一个非叶子节点开始(
(n - 1 - 1) / 2),逐步向上至根节点(i >= 0),对每个节点调用AdjustDown以确保以该节点为根的子树满足堆性质。注释中提到的向上调整算法
AdjustUp被注释掉了,但其实用向上调整算法也是能够建堆的(但向下调整更为高效)。排序过程:
如果要进行升序排序,需要构建最大堆(大堆);如果要进行降序排序,则需要构建最小堆(小堆)。
通过交换堆顶(当前最大值)与数组末尾元素,并减小堆的大小(
end--),然后调用AdjustDown来维护堆的性质,从而实现排序。这个过程重复进行,直到堆的大小减为1,此时数组已排序完成。
//堆排序 void HeapSort(int* arr, int n) {//根据给定的arr来进行建堆//child;n-1 parent:(n-1-1)/2//向下调整算法建堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(arr, i, n);}//向上调整算法建堆/*for (int i = 0; i < n; i++){AdjustUp(arr, i);}*///堆排序//排升序——建大堆//排降序——建小堆//建小堆大堆时,主要影响因素在向下调整算法中://1.左孩子和右孩子的比较//2.孩子和父亲的比较//如果要从构造小堆改为构造大堆,两个判断条件的><都要取反int end = n - 1;while (end > 0){Swap(&arr[0], &arr[end]);AdjustDown(arr, 0, end);end--;} }

向下调整算法
AdjustDown
函数定义:
void AdjustDown(HPDataType* arr, int parent, int n)
arr:指向堆数组的指针(这里HPDataType是int)。
parent:当前需要调整的父节点索引。
n:堆的大小(即当前堆中元素的数量)。调整过程:
计算左孩子节点的索引(
child = parent * 2 + 1)。在
while循环中,首先检查是否存在右孩子,并且右孩子的值是否小于左孩子的值。如果是,则更新child为右孩子的索引。接着,比较父节点与孩子节点的值。如果父节点的值大于孩子节点的值(对于最大堆而言),则交换它们,并继续向下调整(更新
parent和child)。如果父节点的值不大于孩子节点的值,则跳出循环,因为当前子树已经满足堆性质。
//向下调整算法 void AdjustDown(HPDataType* arr, int parent,int n) {int child = parent * 2 + 1;while (child < n){//先找最小的孩子if (child + 1 < n && arr[child] > arr[child + 1]){child++;}//parent和child比较if (arr[child] < arr[parent]){Swap(&arr[child], &arr[parent]);parent = child;child = parent * 2 + 1;}else{break;}} }



向上调整算法
AdjustUp
函数定义:
void AdjustUp(HPDataType* arr, int child)
arr:指向堆数组的指针(这里HPDataType是int类型,表示堆中存储的是整数)。
child:当前需要向上调整的节点的索引(也称为“孩子”节点)。调整过程:
初始化父节点索引:
根据孩子节点索引
child,计算出父节点索引parent = (child - 1) / 2。循环调整:
当
child大于0,并且孩子节点的值大于父节点的值时(对于最大堆):
交换孩子节点和父节点的值。
更新
child为当前父节点的索引。重新计算新的父节点索引。
终止条件:
当
child不大于0,或者孩子节点的值不大于新的父节点的值时,停止调整。//向上调整算法 void AdjustUp(HPDataType* arr, int child) {int parent = (child - 1) / 2;while (child > 0){// > 大堆// < 小堆 if (arr[child] > arr[parent]){Swap(&arr[child], &arr[parent]);child = parent;parent = (child - 1) / 2;}else {break;}} }



注意事项
-
注释中提到的向上调整算法
AdjustUp函数没有使用,在堆排序中,它通常用于在插入新元素后维护堆的性质,但是此处也是可以使用向上调整算法来建堆的,在这个特定的实现中,由于是从一个无序数组开始构建堆,所以使用向下调整算法AdjustDown更为高效。 -
堆排序是一种原地排序算法,因为它只需要一个额外的常数空间来存储临时变量(如
child、parent等),而不需要额外的数组来存储数据。 -
建小堆大堆时,主要影响因素在向下调整算法中:
1.左孩子和右孩子的比较
2.孩子和父亲的比较
如果要从构造小堆改为构造大堆,两个判断条件的><都要取反
二.链式二叉树
2.1 前中后序遍历
二叉树的操作离不开树的遍历,我们先来看看二叉树的遍历有哪些方式
遍历规则
按照规则,二叉树的遍历有:前序/中序/后序的递归结构遍历:
1)前序遍历(PreorderTraversal亦称先序遍历):访问根结点的操作发生在遍历其左右子树之前 访 问顺序为:根结点、左子树、右子树
2)中序遍历(InorderTraversal):访问根结点的操作发生在遍历其左右子树之中(间) 访问顺序为:左子树、根结点、右子树
3)后序遍历(PostorderTraversal):访问根结点的操作发生在遍历其左右子树之后 访问顺序为:左子树、右子树、根结点
图解遍历:
以前序遍历为例:
函数递归栈帧图:
 前序遍历结果:1 2 3 4 5 6
前序遍历结果:1 2 3 4 5 6
中序遍历结果:3 2 1 5 4 6
后序遍历结果:3 1 5 6 4 1
后面会进行代码的实现
链式二叉树的结构
结构体名称:
BTNode目的:定义二叉树节点。
字段:
BTDataType data;
- 类型:字符(
char的别名BTDataType)- 描述:节点值。
BTNode* left;
- 类型:指向
BTNode的指针- 描述:左孩子节点。
BTNode* right;
- 类型:指向
BTNode的指针- 描述:右孩子节点。
实现代码:
typedef char BTDataType; //二叉树结点结构的定义 typedef struct BinaryTreeNode {BTDataType data;//当前结点值域struct BinaryTreeNode* left;//指向当前结点左孩⼦struct BinaryTreeNode* right;//指向当前结点右孩⼦ }BTNode;
创建链式二叉树
函数一:申请新节点
函数名:
buyNode参数:
BTDataType x:要存储在新节点中的值。返回值:
- 指向新创建的
BTNode结构体的指针。功能:
- 分配内存以创建一个新的
BTNode节点。- 检查内存分配是否成功,如果失败则打印错误信息并退出程序。
- 初始化新节点的值域为参数
x。- 将新节点的左右孩子指针初始化为
NULL。- 返回指向新节点的指针。
函数二:手动构造二叉树
函数名:
CreateTree参数:无
返回值:
- 指向二叉树根节点的指针。
功能:
- 调用
buyNode函数创建六个新节点,分别存储字符'A'到'F'。- 设置这些节点之间的父子关系,以构造一个特定的二叉树结构:
- 'A'是根节点。
- 'B'和'C'是'A'的左右孩子。
- 'D'和'E'是'B'的左右孩子。
- 'F'是'C'的左孩子。
- 返回指向根节点'A'的指针。
实现代码:
//申请新结点 BTNode* buyNode(BTDataType x) {BTNode* node = (BTNode*)malloc(sizeof(BTNode));if (node == NULL){perror("malloc fail!");exit(1);}node->data = x;node->left = node->right = NULL;return node; } //手动构造一颗二叉树 BTNode* CreateTree() {BTNode* nodeA = buyNode('A');BTNode* nodeB = buyNode('B');BTNode* nodeC = buyNode('C');BTNode* nodeD = buyNode('D');BTNode* nodeE = buyNode('E');BTNode* nodeF = buyNode('F');nodeA->left = nodeB;nodeA->right = nodeC;nodeB->left = nodeD;nodeB->right = nodeE;nodeC->left = nodeF;return nodeA; }
前序遍历
函数名:
PreOrder参数:
BTNode* root:指向二叉树根节点的指针。返回值:无
功能:
- 实现二叉树的前序遍历算法。
- 前序遍历的顺序是:首先访问根节点,然后递归地前序遍历左子树,最后递归地前序遍历右子树。
实现细节:
递归终止条件:如果当前节点(
root)为空,则打印"NULL ",并返回。这个条件确保了递归能够正确终止。然而,在标准的前序遍历实现中,通常不会打印"NULL",因为空节点不产生输出。这里的打印是为了调试或满足特定要求。访问根节点:打印当前节点的值(
root->data)。递归遍历左子树:调用
PreOrder函数,传入当前节点的左孩子(root->left)作为参数。递归遍历右子树:调用
PreOrder函数,传入当前节点的右孩子(root->right)作为参数。实现代码:
//前序遍历——根左右 void PreOrder(BTNode* root) {if (root == NULL){printf("NULL ");return;}printf("%c ", root->data);PreOrder(root->left);PreOrder(root->right); }结合上述创建的链式二叉树,其运行结果为:

中序遍历
函数名:
InOrder参数:
BTNode* root:指向二叉树根节点的指针。返回值:无
功能:
- 实现二叉树的中序遍历算法。
- 中序遍历的顺序是:首先递归地中序遍历左子树,然后访问根节点,最后递归地中序遍历右子树。
实现细节:
递归终止条件:如果当前节点(
root)为空,则打印"NULL "(这里的打印是为了便于调试)。递归遍历左子树:调用
InOrder函数,传入当前节点的左孩子(root->left)作为参数。访问根节点:在左子树遍历完成后,打印当前节点的值(
root->data)。递归遍历右子树:调用
InOrder函数,传入当前节点的右孩子(root->right)作为参数。实现代码:
//中序遍历——左根右 void InOrder(BTNode* root) {if (root == NULL){printf("NULL ");return;}InOrder(root->left);printf("%c ", root->data);InOrder(root->right); }打印结果:

后序遍历
函数名:
PostOrder参数:
BTNode* root:指向二叉树根节点的指针。返回值:无
功能:
- 实现二叉树的后序遍历算法。
- 按照“左子树-右子树-根节点”的顺序访问节点。
实现细节:
递归终止条件:如果当前节点(
root)为空,则按照代码逻辑会打印"NULL "。递归遍历左子树:调用
PostOrder函数,传入当前节点的左孩子(root->left)作为参数,进行递归后序遍历。递归遍历右子树:同样地,调用
PostOrder函数,传入当前节点的右孩子(root->right)作为参数,进行递归后序遍历。访问根节点:在左右子树都被遍历之后,打印当前节点的值(
root->data)。实现代码:
//后序遍历——左右根 void PostOrder(BTNode* root) {if (root == NULL){printf("NULL ");return;}PostOrder(root->left);PostOrder(root->right);printf("%c", root->data); }打印结果:

2.2 链式二叉树的常见操作
二叉树的结点个数
函数名:BinaryTreeSize
参数:
BTNode* root:指向二叉树根节点的指针。返回值:
int:返回二叉树的节点总数。功能:
- 实现计算二叉树节点总数的算法。
- 递归地计算左子树和右子树的节点数,并将它们与根节点相加得到总节点数。
实现细节:
递归终止条件:如果当前节点(
root)为空,则根据二叉树的定义,空树没有节点,返回0。递归计算左子树节点数:调用
BinaryTreeSize函数,传入当前节点的左孩子(root->left)作为参数,递归地计算左子树的节点总数。递归计算右子树节点数:同样地,调用
BinaryTreeSize函数,传入当前节点的右孩子(root->right)作为参数,递归地计算右子树的节点总数。计算总节点数:将左子树的节点数、右子树的节点数与根节点(1个)相加,得到当前二叉树的总节点数。
实现代码:
//二叉树的结点个数 int BinaryTreeSize(BTNode* root) {if (root == NULL){return 0;}//递归//每一颗二叉树的结点个数都可以表示为//根结点(1)+左子树结点个数+右子树结点个数return 1 + BinaryTreeSize(root->left) + BinaryTreeSize(root->right); }
二叉树叶子结点的个数
函数名:BinaryTreeLeafSize
参数:
BTNode* root:指向二叉树根节点的指针。返回值:
int:返回二叉树中叶子节点的总数。功能:
- 实现计算二叉树叶子节点总数的算法。
- 递归地检查每个节点是否为叶子节点,并累加叶子节点的数量。
实现细节:
递归终止条件:如果当前节点(
root)为空,则根据二叉树的定义,空树没有叶子节点,返回0。叶子节点判断:如果当前节点的左孩子(
root->left)和右孩子(root->right)都为空,则当前节点是叶子节点,返回1。递归计算叶子节点数:如果当前节点不是叶子节点,则递归地调用
BinaryTreeLeafSize函数,分别传入当前节点的左孩子和右孩子作为参数,计算左子树和右子树的叶子节点总数,并将这两个数相加得到当前二叉树的叶子节点总数。实现代码:
//二叉树叶子结点的个数 int BinaryTreeLeafSize(BTNode* root) {if (root == NULL){return 0;}//递归//叶子结点:左孩子和右孩子都为空if (root->left == NULL && root->right == NULL){return 1;}//总数:左子树叶子结点个数+右子树叶子结点个数return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right); }
二叉树第k层结点的个数
函数名:BinaryTreeLevelKSize
参数:
BTNode* root:指向二叉树根节点的指针。int k:指定的层数,从1开始计数。返回值:
int:返回二叉树第k层节点的总数。功能:
- 实现计算二叉树第
k层节点总数的算法。- 递归地遍历二叉树,直到达到指定的层数,然后累加该层的节点数。
实现细节:
- 递归终止条件:
- 如果当前节点(
root)为空,则根据二叉树的定义,该层没有节点,返回0。- 如果当前层数
k等于1,说明已经到达了根节点所在的层(根节点位于第1层),因此该层有1个节点,返回1。- 递归计算第
k层节点数:
- 如果当前节点不是空节点且当前层数
k大于1,则递归地调用BinaryTreeLevelKSize函数,分别传入当前节点的左孩子和右孩子作为新的根节点,并将层数k减1(因为向下递归一层),计算左子树和右子树在第k-1层的节点总数。- 将左子树和右子树在第
k-1层的节点数相加,得到当前二叉树在第k层的节点总数。注意:
- 这里的递归逻辑有一点需要注意,即当我们想要计算第
k层的节点数时,实际上是递归地去计算左子树和右子树在第k-1层的节点数。这是因为当我们从根节点开始递归时,根节点是第1层,它的子节点(左孩子和右孩子)位于第2层,依此类推。实现代码:
//二叉树第k层结点的个数 int BinaryTreeLevelKSize(BTNode* root, int k) {if (root == NULL){return 0;}if (k == 1){return 1; // 根节点所在层,只有1个节点}//递归//总数:左子树第k-1层结点的个数+右子树第k-1层结点的个数return BinaryTreeLevelKSize(root->left, k - 1) + BinaryTreeLevelKSize(root->right, k - 1); }
求二叉树的高度/深度
函数名:BinaryTreeDepth
参数:
BTNode* root:指向二叉树根节点的指针。返回值:
int:返回二叉树的高度(或深度),即从根节点到最远叶子节点的最长路径上的节点数。功能:
- 实现计算二叉树高度的算法。
- 递归地计算左子树和右子树的高度,并返回其中较大的高度值加上1(根节点的高度)。
实现细节:
递归终止条件:如果当前节点(
root)为空,则根据二叉树的定义,空树的高度为0。递归计算子树高度:分别调用
BinaryTreeDepth函数,传入当前节点的左孩子(root->left)和右孩子(root->right)作为参数,递归地计算左子树和右子树的高度。计算总高度:将左子树的高度(
leftDep)和右子树的高度(rightDep)进行比较,取其中较大的值,然后加上1(根节点的高度),得到当前二叉树的总高度。实现代码:
//求二叉树的高度/深度 int BinaryTreeDepth(BTNode* root) {if (root == NULL){return 0;}//递归计算左子树和右子树的高度int leftDep = BinaryTreeDepth(root->left);int rightDep = BinaryTreeDepth(root->right);//返回当前树的高度:根节点的高度(1)加上左右子树中较大的高度return 1 + (leftDep > rightDep ? leftDep : rightDep); }
二叉树查找值为x的结点
函数名:BinaryTreeFind
参数:
BTNode* root:指向二叉树根节点的指针。BTDataType x:要查找的目标值,其类型应与二叉树节点的数据类型相匹配。返回值:
BTNode*:返回指向找到的值为x的节点的指针;如果未找到,则返回NULL。功能:
- 实现在二叉树中查找值为
x的节点的算法。- 递归地遍历二叉树,直到找到值为
x的节点或遍历完整个树。实现细节:
递归终止条件:如果当前节点(
root)为空,则根据二叉树的定义,该节点下不存在任何子节点,因此返回NULL表示未找到。查找目标值:如果当前节点的值(
root->data)等于目标值x,则找到了目标节点,返回当前节点的指针。递归查找:
- 首先,递归地调用
BinaryTreeFind函数,传入当前节点的左孩子(root->left)作为新的根节点和相同的目标值x,尝试在左子树中查找目标节点。- 如果左子树中找到了目标节点(即
leftFind不为NULL),则返回该节点的指针。- 如果左子树中没有找到目标节点,则继续递归地调用
BinaryTreeFind函数,传入当前节点的右孩子(root->right)作为新的根节点和相同的目标值x,尝试在右子树中查找目标节点。- 如果右子树中找到了目标节点(即
rightFind不为NULL),则返回该节点的指针。未找到目标值:如果左子树和右子树中都没有找到目标节点,则返回
NULL表示在整个二叉树中未找到值为x的节点。实现代码:
BTNode* BinaryTreeFind(BTNode* root, BTDataType x) {//先遍历左子树//找到了,直接返回//没有找到,再去遍历右子树if (root == NULL){return NULL;}if (root->data == x){return root;}BTNode* leftFind = BinaryTreeFind(root->left, x);if (leftFind){return leftFind;}BTNode* rightFind = BinaryTreeFind(root->right, x);if (rightFind){return rightFind;}return NULL; }
2.3 层序遍历
除了先序遍历、中序遍历、后序遍历外,还可以对二叉树进行层序遍历。设二叉树的根结点所在层数为1,层序遍历就是从所在二叉树的根结点出发,首先访问第1层的树根结点,然后从左到右访问第2层上的结点,接着是第3层的结点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历,实现层序遍历需要额外借助数据结构:队列

函数名:
LevelOrder参数:
BTNode* root:指向二叉树根节点的指针。功能:
- 实现二叉树的层序遍历(广度优先遍历),通过队列数据结构辅助完成。
实现细节:
- 初始化队列:
- 创建一个
Queue类型的变量q。- 调用
QueueInit(&q)函数初始化队列q,使其处于可用状态。- 根节点入队:
- 调用
QueuePush(&q, root)函数,将二叉树的根节点root添加到队列q的末尾。- 遍历队列:
- 使用
while循环遍历队列q,条件是队列不为空(!QueueEmpty(&q))。- 在循环体内,首先调用
QueueFront(&q)函数获取队列头部的节点指针,并将其赋值给BTNode* top。这里需要注意的是,QueueFront只是获取队列头部的节点指针,并不会将该节点从队列中移除。- 紧接着,调用
QueuePop(&q)函数从队列中移除刚才通过QueueFront获取的节点(即top指向的节点)。- 使用
printf("%c", top->data);语句打印当前节点(即top指向的节点)的值。这里假设节点值的数据类型为字符,因此使用%c格式说明符。- 孩子节点入队:
- 检查当前节点(
top)的左孩子是否存在(top->left)。如果存在,则调用QueuePush(&q, top->left);将其添加到队列q的末尾。- 同样地,检查当前节点的右孩子是否存在(
top->right)。如果存在,则调用QueuePush(&q, top->right);将其添加到队列q的末尾。- 销毁队列:
- 遍历完成后,调用
QueueDestroy(&q)函数销毁队列q,并释放其占用的资源。代码实现:
//层序遍历 void LevelOrder(BTNode* root) {//借助数据结构——队列Queue q;QueueInit(&q);QueuePush(&q, root);while (!QueueEmpty(&q)){//取队头,出队头BTNode* top = QueueFront(&q);QueuePop(&q);printf("%c", top->data);//将队头左右孩子入队列(不为空)if (top->left){QueuePush(&q, top->left);}if (top->right){QueuePush(&q, top->right);}}QueueDestroy(&q); }
上述是完整的解析,其中用队列实现层序遍历的核心思路如下:
- 初始化队列:
- 创建一个空队列,用于存储待访问的节点。
- 根节点入队:
- 将二叉树的根节点加入队列。
- 循环遍历:
- 当队列不为空时,执行以下步骤:
a. 从队列头部取出一个节点(访问该节点,例如打印其值)。
b. 如果该节点有左孩子,将左孩子加入队列。
c. 如果该节点有右孩子,将右孩子加入队列。- 结束:
- 当队列为空时,遍历结束,所有节点都已按层次顺序访问过。
学习了层序遍历,下面我们用层序遍历来检验二叉树是否为完全二叉树
使用层序遍历检验是否为完全二叉树
函数名:
BinaryTreeComplete参数:
BTNode* root:指向二叉树根节点的指针。返回值:
bool:如果二叉树是完全二叉树,则返回true;否则返回false。功能:
- 该函数通过层序遍历的方式验证给定的二叉树是否为完全二叉树。
实现细节:
- 空树处理:
- 首先检查根节点
root是否为NULL。如果是,根据完全二叉树的定义(有时空树也被认为是完全二叉树),函数返回true。- 队列初始化:
- 创建一个名为
q的队列,并调用QueueInit(&q)函数对其进行初始化。- 根节点入队:
- 将二叉树的根节点
root通过QueuePush(&q, root)函数加入队列q。- 遍历与检查:
- 使用
while循环遍历队列q,条件是队列不为空(!QueueEmpty(&q))。- 在循环内部,首先通过
QueueFront(&q)函数获取队列头部的节点指针,并将其赋值给BTNode* node。- 随后,调用
QueuePop(&q)函数将node节点从队列中移除。- 使用一个布尔变量
met_null来跟踪是否遇到了空节点。如果在遍历过程中遇到了空节点,并且之后还遇到了非空节点,则树不是完全二叉树。- 空节点与非空节点处理:
- 如果
node为空,则将met_null设置为true,表示之后应该只遇到空节点。- 如果
node不为空,则检查met_null是否为true。如果是,说明在之前已经遇到了空节点,但当前节点却是非空的,因此树不是完全二叉树。在这种情况下,函数会销毁队列并返回false。- 如果
node不为空且met_null为false,则将node的左右孩子(如果存在)加入队列。- 队列销毁与结果返回:
- 如果遍历完成后没有违反完全二叉树的性质,则函数销毁队列
q,并返回true,表示树是完全二叉树。代码实现:
#include <stdbool.h>// 假设已经定义了BTNode结构体、Queue结构体以及相关的队列操作函数bool BinaryTreeComplete(BTNode* root) {if (root == NULL) {// 空树被认为是完全二叉树(根据定义可有所不同,这里假设是)return true;}Queue q;QueueInit(&q);QueuePush(&q, root);bool met_null = false; // 标记是否遇到了空节点while (!QueueEmpty(&q)) {BTNode* node = QueueFront(&q);QueuePop(&q);// 如果已经遇到了空节点,但当前节点不是空,则不是完全二叉树if (met_null && node != NULL) {QueueDestroy(&q);return false;}// 如果当前节点是空,则设置标记为true,表示之后应该只遇到空节点if (node == NULL) {met_null = true;} else {// 否则,将当前节点的左右孩子加入队列QueuePush(&q, node->left);QueuePush(&q, node->right);}}QueueDestroy(&q);return true; }
简化提炼思路如下:
思路:
- 初始化:
- 使用一个队列来进行层序遍历。
- 将根节点加入队列。
- 初始化一个布尔变量
met_null为false,用于标记是否遇到了空节点。- 层序遍历:
- 遍历队列,直到队列为空。
- 在每次循环中,从队列头部取出一个节点。
- 如果
met_null为true(意味着之前已经遇到了空节点),但当前节点不是空节点,则树不是完全二叉树,返回false。- 如果当前节点是空节点,则将
met_null设置为true。- 如果当前节点不是空节点,则将其左右孩子(如果存在)加入队列。
- 结束条件:
- 如果遍历结束后没有违反完全二叉树的性质(即没有在遇到空节点后再遇到非空节点),则树是完全二叉树,返回
true。关键点:
- 一旦在层序遍历中遇到了空节点,之后的所有节点(如果存在)都应该是空节点,否则树就不是完全二叉树。
- 使用队列来保持层序遍历的顺序。
- 使用布尔变量
met_null来跟踪是否遇到了空节点。
兄弟们共勉 !!!
码字不易,求个三连
抱拳了兄弟们!

相关文章:
堆排序与链式二叉树:数据结构与排序算法的双重探索
大家好,我是小卡皮巴拉 文章目录 目录 引言 一.堆排序 1.1 版本一 核心概念 堆排序过程 1.2 版本二 堆排序函数 HeapSort 向下调整算法 AdjustDown 向上调整算法 AdjustUp 二.链式二叉树 2.1 前中后序遍历 链式二叉树的结构 创建链式二叉树 前序遍历…...
用 Python 从零开始创建神经网络(四):激活函数(Activation Functions)
激活函数(Activation Functions) 引言1. 激活函数的种类a. 阶跃激活功能b. 线性激活函数c. Sigmoid激活函数d. ReLU 激活函数e. more 2. 为什么使用激活函数3. 隐藏层的线性激活4. 一对神经元的 ReLU 激活5. 在隐蔽层中激活 ReLU6. ReLU 激活函数代码7. …...
使用 Flask 和 ONLYOFFICE 实现文档在线编辑功能
提示:CSDN 博主测评ONLYOFFICE 文章目录 引言技术栈环境准备安装 ONLYOFFICE 文档服务器获取 API 密钥安装 Flask 和 Requests 创建 Flask 应用项目结构编写 app.py创建模板 templates/index.html 运行应用功能详解文档上传生成编辑器 URL显示编辑器回调处理 安全性…...

【C++】【算法基础】序列编辑距离
编辑距离 题目 给定 n n n个长度不超过 10 10 10 的字符串以及 m m m 次询问,每次询问给出一个字符串和一个操作次数上限。 对于每次询问,请你求出给定的 n n n个字符串中有多少个字符串可以在上限操作次数内经过操作变成询问给出的字符串。 每个…...
【Android】轮播图——Banner
引言 Banner轮播图是一种在网页和移动应用界面设计中常见的元素,主要用于在一个固定的区域内自动或手动切换一系列图片,以展示不同的内容或信息。这个控件在软件当中经常看到,商品促销、热门歌单、头像新闻等等。它不同于ViewPgaer在于无需手…...
学SQL,要安装什么软件?
先上结论,推荐MySQLDbeaver的组合。 学SQL需要安装软件吗? 记得几年前我学习SQL的时候,以为像Java、Python一样需要安装SQL软件包,后来知道并没有所谓SQL软件,因为SQL是一种查询语言,它用来对数据库进行操…...

webstorm 设置总结
编辑器-》文件类型-》忽略的文件和文件夹-》加上node_modules 修改WebStorm 内存有两种方式。 1. 点击菜单中的Help -> change memory settings 弹出设置内存窗口,修改最大内存大小。然后点击Save and Restart 即可。 2. 点击菜单中的Help -> Edit Custom V…...
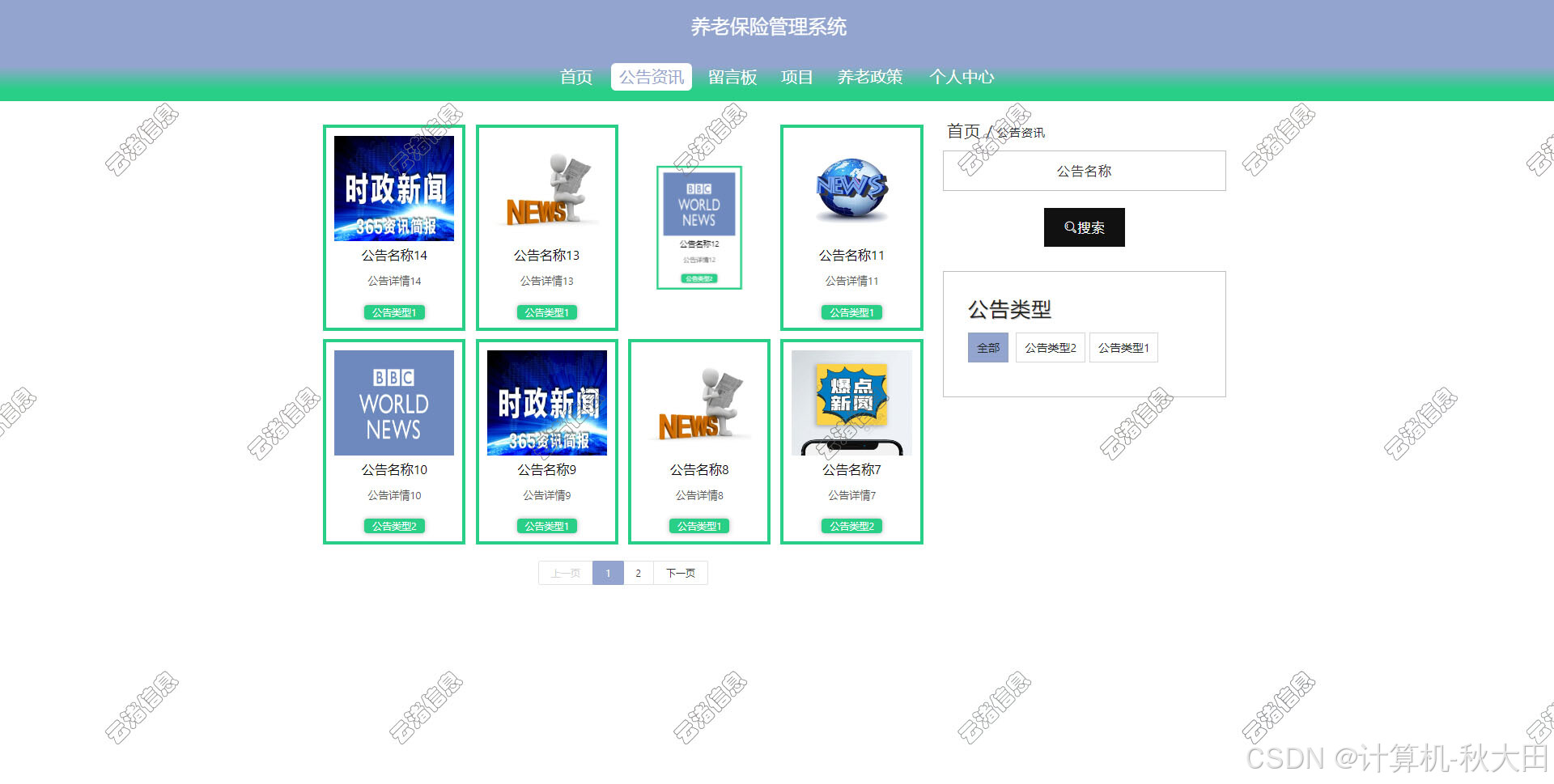
基于Spring Boot的养老保险管理系统的设计与实现,LW+源码+讲解
摘 要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统养老保险管理系统信息管理难度大,容错率低&a…...

Java | Leetcode Java题解之第541题反转字符串II
题目: 题解: class Solution {public String reverseStr(String s, int k) {int n s.length();char[] arr s.toCharArray();for (int i 0; i < n; i 2 * k) {reverse(arr, i, Math.min(i k, n) - 1);}return new String(arr);}public void reve…...

sql分区
将学员表student按所在城市使用PARTITION BY LIST 1、创建分区表。 CREATE TABLE public.student( sno numeric(4,0), sname character varying(20 char),gender character varying(2 char), phone numeric(11,0), …...

[OpenGL]使用OpenGL实现硬阴影效果
一、简介 本文介绍了如何使用OpenGL实现硬阴影效果,并在最后给出了全部的代码。本文基于[OpenGL]渲染Shadow Map,实现硬阴影的流程如下: 首先,以光源为视角,渲染场景的深度图,将light space中的深度图存储…...
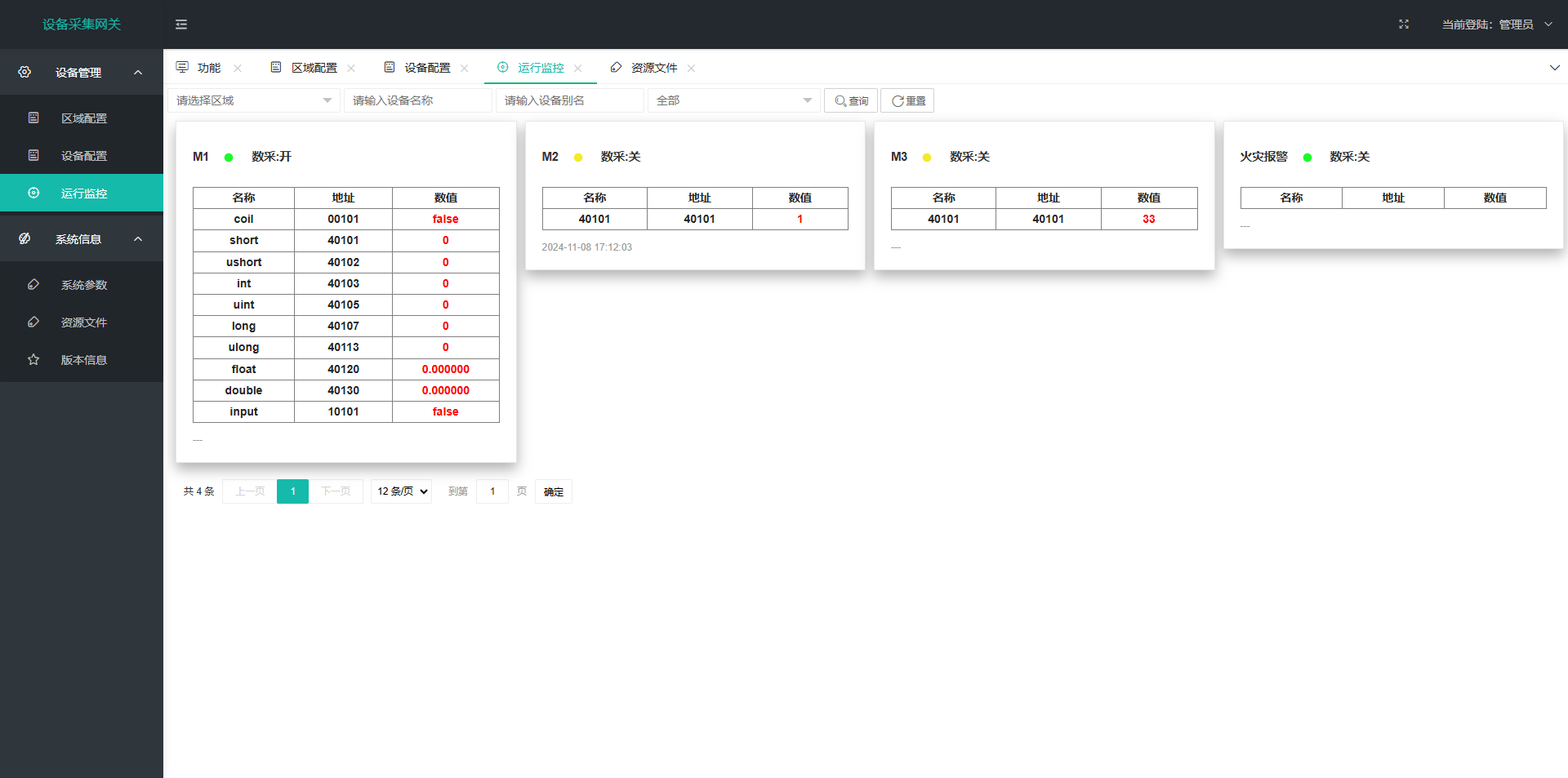
嵌入式采集网关(golang版本)
为了一次编写到处运行,使用纯GO编写,排除CGO,解决在嵌入式中交叉编译难问题 硬件设备:移远EC200A-CN LTE Cat 4 无线通信模块,搭载openwrt操作系统,90M内存...
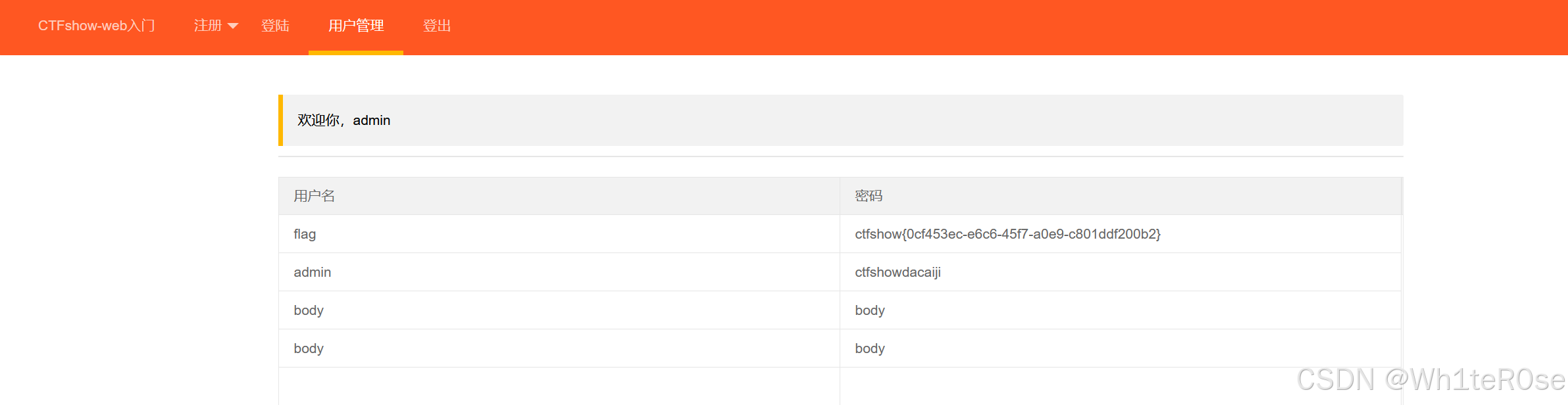
ctfshow(328)--XSS漏洞--存储型XSS
Web328 简单阅读一下页面。 是一个登录系统,存在一个用户管理数据库。 那么我们注册一个账号,在账号或者密码中植入HTML恶意代码,当管理员访问用户管理数据库页面时,就会触发我们的恶意代码。 思路 我们向数据库中写入盗取管理员…...

【C#】Thread.CurrentThread的用法
Thread.CurrentThread 是 System.Threading.Thread 类的一个静态属性,它返回当前正在执行的线程对象。通过 Thread.CurrentThread,可以访问和修改当前线程的各种属性和方法。 下面是一些常见的用法和示例: 1. 获取当前线程的信息 使用 Thr…...
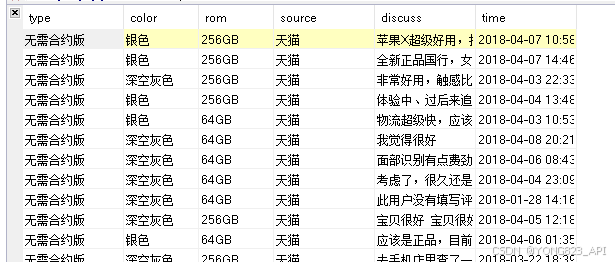
简单分享一下淘宝商品数据自动化抓取的技术实现与挑战
在电子商务领域,数据是驱动决策的关键。淘宝作为国内最大的电商平台之一,其商品数据对电商从业者来说具有极高的价值。然而,从淘宝平台自动化抓取商品数据并非易事,涉及多重技术和法律挑战。本文将从技术层面分析实现淘宝商品数据…...
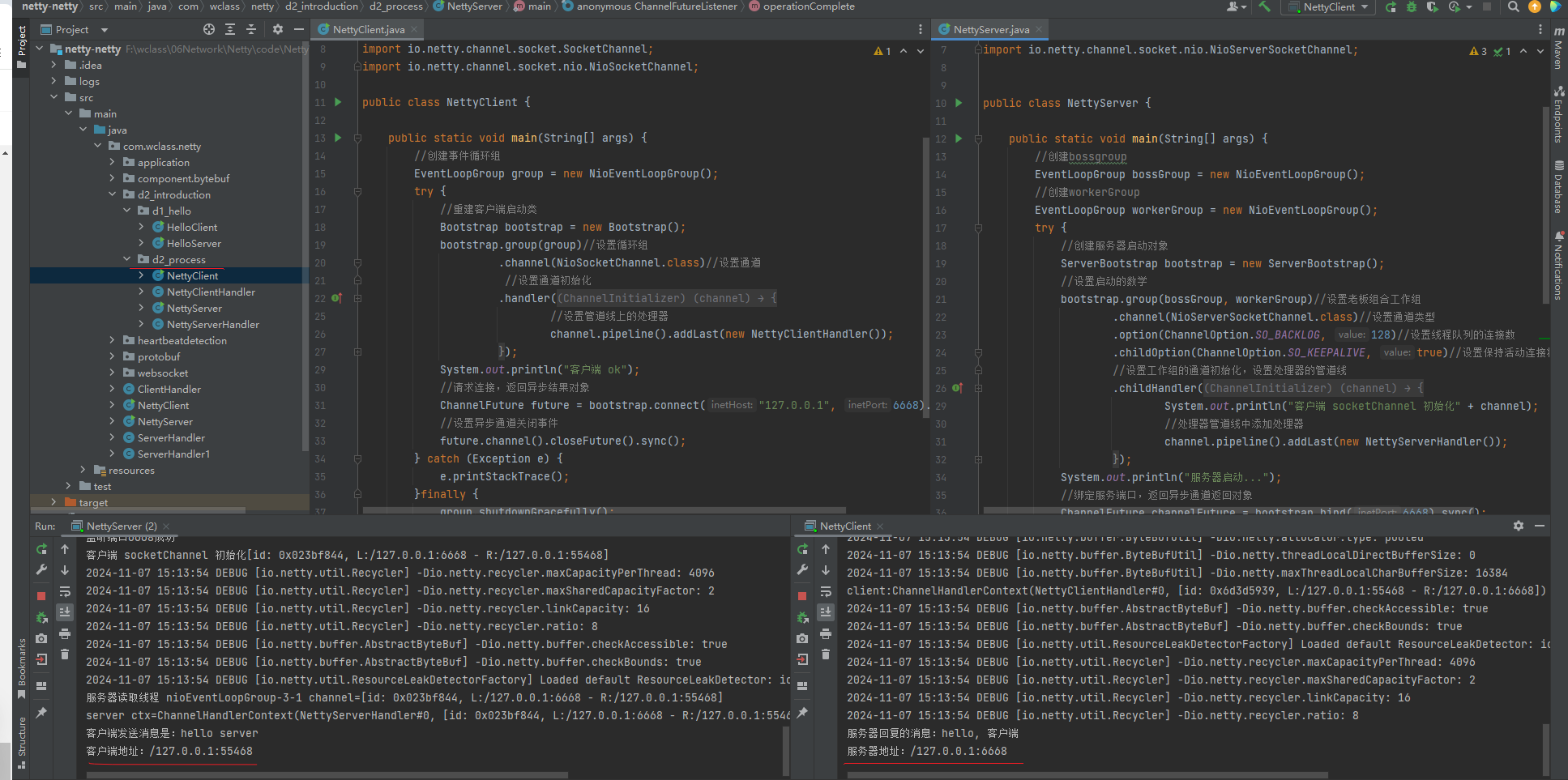
Netty篇(入门编程)
目录 一、Hello World 1. 目标 2. 服务器端 3. 客户端 4. 流程梳理 💡 提示 5. 运行结果截图 二、Netty执行流程 1. 流程分析 2. 代码案例 2.1. 引入依赖 2.2. 服务端 服务端 服务端处理器 2.3. 客户端 客户端 客户端处理器 2.4. 代码截图 一、Hel…...

【渗透测试】payload记录
Java开发使用char[]代替String保存敏感数据 Java Jvm会提供内存转储功能,当Java程序dump后,会生成堆内存的快照,保存在.hprof后缀的文件中,进而导致敏感信息的泄露。char[]可以在存储敏感数据后手动清零,String对象会…...

2024自动驾驶线控底盘行业研究报告
自动驾驶线控底盘是实现自动驾驶的关键技术之一,它通过电子信号来控制车辆的行驶,包括转向、制动、驱动、换挡和悬架等系统。线控底盘技术的发展对于自动驾驶汽车的实现至关重要,因为它提供了快速响应和精确控制的能力,这是自动驾驶系统所必需的。 线控底盘由五大系统组成…...

css3D变换用法
文章目录 CSS3D变换详解及代码案例一、CSS3D变换的基本概念二、3D变换的开启与景深设置三、代码案例 CSS3D变换详解及代码案例 CSS3D变换是CSS3中引入的一种强大功能,它允许开发者在网页上创建三维空间中的动画和交互效果。通过CSS3D变换,你可以实现元素…...

Rust:启动与关闭线程
在 Rust 编程中,启动和关闭线程是并发编程的重要部分。Rust 提供了强大的线程支持,允许你轻松地创建和管理线程。下面将详细解释如何在 Rust 中启动和关闭线程。 启动线程 在 Rust 中,你可以使用标准库中的 std::thread 模块来创建和启动新…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...

es6+和css3新增的特性有哪些
一:ECMAScript 新特性(ES6) ES6 (2015) - 革命性更新 1,记住的方法,从一个方法里面用到了哪些技术 1,let /const块级作用域声明2,**默认参数**:函数参数可以设置默认值。3&#x…...

数据结构第5章:树和二叉树完全指南(自整理详细图文笔记)
名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪) 原创笔记:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 上一篇:《数据结构第4章 数组和广义表》…...
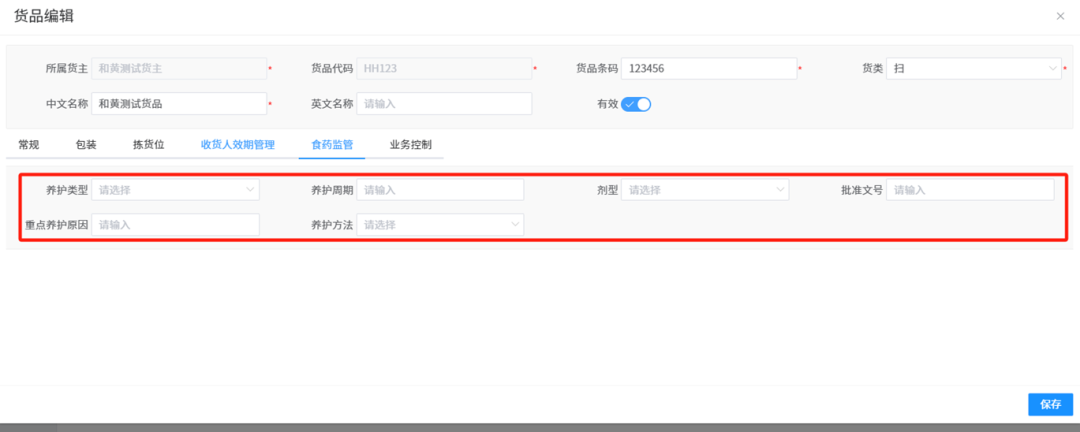
针对药品仓库的效期管理问题,如何利用WMS系统“破局”
案例: 某医药分销企业,主要经营各类药品的批发与零售。由于药品的特殊性,效期管理至关重要,但该企业一直面临效期问题的困扰。在未使用WMS系统之前,其药品入库、存储、出库等环节的效期管理主要依赖人工记录与检查。库…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...