mysql数据库(四)单表查询
单表查询
文章目录
- 单表查询
- 一、单表查询
- 1.1 简单查询
- 1.2where
- 1.3group by
- 1.4having
- 1.5order by
- 1.6limit
一、单表查询
记录的查询语法如下:
SELECT DISTINCT(去重) 字段1,字段2… FROM 表名
WHERE 筛选条件
GROUP BY 分组
HAVING 分组筛选
ORDER BY 排序
LIMIT 限制显示条数
这些关键词的执行顺序是:from(选出记录)、where、group by、having、select(根据指定字段保留记录内容)、distinct、order by、limit
1.1 简单查询
#常用的简单查询语句
select * from t1;
select name,age from t1;#对查询的出版社去重
select distinct publish from t1;#带运算和as的查询
#as的作用是将字段重起一个名字
select name,score*100 as Score from t2;#带函数的查询
#concat函数用于连接字符串
select concat("名字:",name) as student_name,concat("分数:",score) as student_score from t3;
#concat_ws函数也用于字符串拼接,不过第一个参数为分隔符
select concat_ws(":",name,score) as student from t3;#case的分支语句
select ( case when score>85 then '优秀' when score>60 then '合格' else '不合格' end) as new_score from t3;1.2where
where用于对记录进行初步筛选。
#单条件查询
select score from t1 where name='张三';#多条件查询select score_Math,score_English from t1 where name='张三';#between and表示区间[a,b]
select name from t1 where score between 60 and 100;#not表示取反
select name from t1 where score not between 60 and 100;#is null表示判断字段是否为空,需要注意的是''不是null
select name form t1 where score is null;
select name form t1 where score is not null;#in表示处于某个范围
#查询成绩为100、90、80分的学生姓名
select name from t1 where score=100 or score=90 or score=80;
select name from t1 where score in [100,90,80];#like表示模糊查询,_表示任意字符,%表示任何数量的字符
#匹配成绩在80至89的学生姓名
select name from t1 where score like '8_';
#匹配姓张的学生成绩
select score from t1 where name like '张%';#regexp表示正则表达式,正则表达式的内容不再介绍了,不了解的可以参考下面的链接
#匹配姓张的学生成绩
select score from t1 where name regexp '张.+';
正则表达式
1.3group by
group by用于对数据进行分组,分组的目的是将数据中某一字段的相同内容进行归类,并对归类后的数据进行一系列的操作。例如要计算每个部门的平均薪资就需要先对部门进行分组,然后对薪资字段使用avg函数聚合。
需要注意的是mysql默认的是ONLY_FULL_GROUP_BY模式的分组,简单来说就是分组后查询出来的字段中只能有一个明确的值,如果有多个就会报错。例如对部门进行分组,查询部门和员工两个字段,由于分组后的一个部门含有多个员工,这样的分组查询结果会报错。
+----+--------+--------+------------+
| id | name | salary | department |
+----+--------+--------+------------+
| 1 | 王五 | 9000 | IT |
| 2 | 张三 | 10000 | IT |
| 3 | 李四 | 6000 | 销售 |
| 4 | 赵六 | 6500 | 销售 |
+----+--------+--------+------------+#对部门进行分组,查询部门和员工两个字段
select department,name from t1 group by department;which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by#只对部门进行分组
select department from t1 group by department;
+------------+
| department |
+------------+
| IT |
| 销售 |
+------------+#使用group_concat对部门进行分组并查询部门和员工信息
select department,group_concat(name) from t1 group by department;
+------------+--------------------+
| department | group_concat(name) |
+------------+--------------------+
| IT | 王五,张三 |
| 销售 | 李四,赵六 |
+------------+--------------------+#使用聚合函数max、min、avg、count、sum
#求每个部门的平均薪资
select department,avg(salary) from t1 group by department;
+------------+-------------+
| department | avg(salary) |
+------------+-------------+
| IT | 9500.0000 |
| 销售 | 6250.0000 |
+------------+-------------+#求每个部门的员工数
select department,count(name) from t1 group by department;
+------------+-------------+
| department | count(name) |
+------------+-------------+
| IT | 2 |
| 销售 | 2 |
+------------+-------------+#补充:聚合函数也可以不跟group by,直接使用
#求表中员工的薪资总和
mysql> select sum(salary) from t1;
+-------------+
| sum(salary) |
+-------------+
| 31500 |
+-------------+
1.4having
having用于对分组结果进行筛选。
+----+--------+--------+------------+
| id | name | salary | department |
+----+--------+--------+------------+
| 1 | 王五 | 9000 | IT |
| 2 | 张三 | 10000 | IT |
| 3 | 李四 | 6000 | 销售 |
| 4 | 赵六 | 6500 | 销售 |
+----+--------+--------+------------+#求出平均薪资大于9000的部门及其薪资
select department,avg(salary) from t1 group by department having avg(salary)>9000;
+------------+-------------+
| department | avg(salary) |
+------------+-------------+
| IT | 9500.0000 |
+------------+-------------+
1.5order by
order by用于排序,其中asc表示升序,desc表示降序。(默认为升序)
+----+-------+-------+
| id | num | score |
+----+-------+-------+
| 1 | 10101 | 90 |
| 2 | 10102 | 88 |
| 3 | 10103 | 90 |
+----+-------+-------+#对表中数据按成绩降序排列,如果成绩一样则按学号升序排列
select * from t1 order by score desc,num asc;
+----+-------+-------+
| id | num | score |
+----+-------+-------+
| 1 | 10101 | 90 |
| 3 | 10103 | 90 |
| 2 | 10102 | 88 |
+----+-------+-------+1.6limit
limit用于限制显示的记录数。
+----+-------+-------+
| id | num | score |
+----+-------+-------+
| 1 | 10101 | 90 |
| 2 | 10102 | 88 |
| 3 | 10103 | 90 |
| 4 | 10104 | 70 |
| 5 | 10105 | 100 |
| 6 | 10106 | 79 |
+----+-------+-------+# 查询学号为10101的同学成绩
select * from t1 limit 1;
+----+-------+-------+
| id | num | score |
+----+-------+-------+
| 1 | 10101 | 90 |
+----+-------+-------+# 查询成绩的第二第三名
#limit 1,2表示从第一条记录开始向后显示两条记录(记录从0开始计数)
select * from t1 order by score desc limit 1,2;
+----+-------+-------+
| id | num | score |
+----+-------+-------+
| 1 | 10101 | 90 |
| 3 | 10103 | 90 |
+----+-------+-------+
相关文章:
单表查询)
mysql数据库(四)单表查询
单表查询 文章目录 单表查询一、单表查询1.1 简单查询1.2where1.3group by1.4having1.5order by1.6limit 一、单表查询 记录的查询语法如下: SELECT DISTINCT(去重) 字段1,字段2… FROM 表名 WHERE 筛选条件 GROUP BY 分组 HAVING 分组筛选 ORDER BY 排序 LIMIT 限…...
JavaEE初阶---properties类+反射+注解
文章目录 1.配置文件properities2.快速上手3.常见方法3.1读取配置文件3.2获取k-v值3.3修改k-v值3.4unicode的说明 4.反射的引入4.1传统写法4.2反射的写法(初识)4.3反射的介绍4.4获得class类的方法4.5所有类型的class对象4.6类加载过程4.7类初始化的过程4…...

HarmonyOS一次开发多端部署三巨头之功能级一多开发和工程级一多开发
功能级一多开发与工程级一多开发 引言功能级一多开发SysCaps机制介绍能力集canlUse接口 工程级一多开发三层架构规范 引言 一次开发多端部署 定义:一套代码工程,一次开发上架,多端按需部署 目标:支撑开发者快速高效的开发多终端设…...

STL常用遍历算法
概述: 算法主要是由头文件<algorithm> <functional> <numeric>组成。 <algorithm>是所有STL头文件中最大的一个,范围涉及到比较、 交换、查找、遍历操作、复制、修改等等 <numeric>体积很小,只包括几个在序列上面进行简…...

前端开发中常见的ES6技术细节分享一
var、let、const之间有什么区别? var: 在ES5中,顶层对象的属性和全局变量是等价的,用var声明的变量既是全局变量,也是顶层变量 注意:顶层对象,在浏览器环境指的是window对象,在 Node 指的是g…...

行业类别-智慧城市-子类别智能交通-细分类别自动驾驶技术-应用场景城市公共交通优化
1.大纲分析 针对题目“8.0 行业类别-智慧城市-子类别智能交通-细分类别自动驾驶技术-应用场景城市公共交通优化”的大纲分析,可以从以下几个方面进行展开: 一、引言 简述智慧城市的概念及其重要性。强调智能交通在智慧城市中的核心地位。引出自动驾驶…...

[High Speed Serial ] Xilinx
Xilinx 高速串行数据接口 收发器产品涵盖了当今高速协议的方方面面。GTH 和 GTY 收发器提供要求苛刻的光互连所需的低抖动,并具有世界一流的自适应均衡功能,具有困难的背板操作所需的 PCS 功能。 Versal™ GTY (32.75Gb/s)&…...

Unity学习笔记(3):场景绘制和叠层设置 Tilemap
文章目录 前言开发环境规则瓦片绘制拐角 动态瓦片总结 前言 这里学一下后面的场景绘制和叠层技巧。 开发环境 Unity 6windows 11vs studio 2022Unity2022.2 最新教程《勇士传说》入门到进阶|4K:https://www.bilibili.com/video/BV1mL411o77x/?spm_id_from333.10…...

不吹不黑,客观理性深入讨论中国信创现状
1. 题记: 随着美国大选尘埃落定,特朗普当选美国新一任总统,参考他之前对中国政策的风格,个人预计他将进一步限制中国半导体产业和信创产业的发展。本篇博文不吹不黑,客观理性深入探讨中国信创现状。文中数据来自权威媒…...
NoSQL数据库的基本原理)
NoSQL大数据存储技术测试(2)NoSQL数据库的基本原理
写在前面:未完成测试的同学,请先完成测试,此博文供大家复习使用,(我的答案)均为正确答案,大家可以放心复习 单项选择题 第1题 NoSQL的主要存储模式不包括 键值对存储模式 列存储模式 文件…...

「QT」几何数据类 之 QPoint 整型点类
✨博客主页何曾参静谧的博客📌文章专栏「QT」QT5程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasolid…...

植物明星大乱斗5
能帮到你的话,就给个赞吧 😘 文章目录 timer.htimer.cppcamera.hcamera.cppmenuScene.cpp timer.h #pragma once #include <functional>class Timer {public:void reStart();void setTimer(int timerMs);void setIsOneShot(bool isOneShot);void …...

每日算法练习
各位小伙伴们大家好,今天给大家带来几道算法题。 题目一 算法分析 首先,我们应该知道什么是完全二叉树:若一颗二叉树深度为n,那么前n-1层是满二叉树,只有最后一层不确定。 给定我们一棵完全二叉树,我们查看…...

把握鸿蒙生态崛起机遇:开发者如何在全场景操作系统中脱颖而出
把握鸿蒙生态崛起机遇:开发者如何在全场景操作系统中脱颖而出 随着鸿蒙系统的逐步成熟和生态体系的扩展,其与安卓、iOS 形成了全新竞争格局,为智能手机、穿戴设备、车载系统和智能家居等领域带来了广阔的应用前景。作为开发者,如…...

字符串类型排序,通过枚举进行单个维度多个维度排序
字符串类型进行排序通过定义枚举值实现 1.首先创建一个测试类,并实现main方法 2.如果是单个维度的排序,则按照顺序定义一个枚举 public enum Risk {高风险,中风险,一般风险,低风险 } public static void main(String[] args) { }3.main方法里实现如下…...

figma的drop shadow x:0 y:4 blur:6 spread:0 如何写成css样式
figma的drop shadow x:0 y:4 blur:6 spread:0 如何写成css样式 在CSS中,我们可以使用box-shadow属性来模拟Figma中的Drop Shadow效果。box-shadow属性接受的值分别是:横向偏移、纵向偏移、模糊半径、扩展半径和颜色。 但是,Figma的Drop Sha…...

基于Matlab 疲劳驾驶检测
Matlab 疲劳驾驶检测 课题介绍 该课题为基于眼部和嘴部的疲劳驾驶检测。带有一个人机交互界面GUI,通过输入视频,分帧,定位眼睛和嘴巴,通过眼睛和嘴巴的张合度,来判别是否疲劳。 二、操作步骤 第一步:最…...

Linux内核.之 init文件,/init/main.c
想要熟悉内核,看下源码,就非常清晰 Linux内核,head.s,汇编启动cpu相关设置后,启动init文件里的,文件在内核的/init/main.c,看下main函数,做了哪些工作 // SPDX-License-Identifier: …...

CentOS系统中查看内网端口映射的多种方法
在网络管理中,了解和控制内网端口映射是至关重要的。本文将为您详细介绍在CentOS系统中查看内网端口映射的多种方法,助您提升网络管理效率。 使用netstat命令查看端口映射 netstat是一个强大的网络诊断工具。要查看当前的端口映射情况,可以在…...
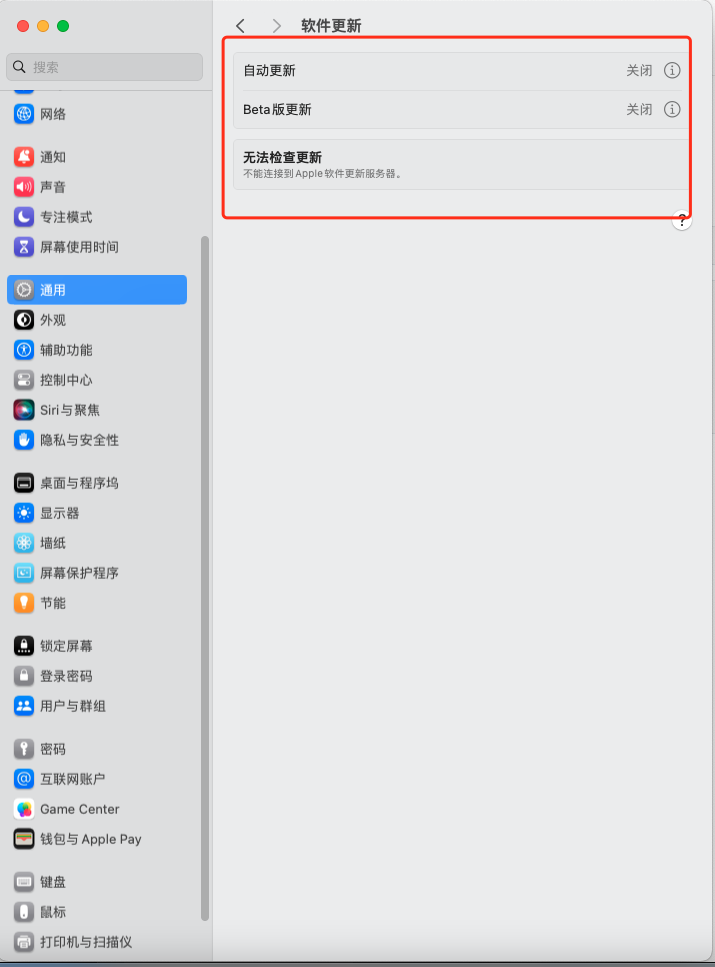
Mac中禁用系统更新
Mac中禁用系统更新 文章目录 Mac中禁用系统更新1. 修改hosts,屏蔽系统更新检测联网1. 去除系统偏好设置--系统更新已有的小红点标记 1. 修改hosts,屏蔽系统更新检测联网 打开终端,执行命令: sudo vim /etc/hosts127.0.0.1 swdis…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

04-初识css
一、css样式引入 1.1.内部样式 <div style"width: 100px;"></div>1.2.外部样式 1.2.1.外部样式1 <style>.aa {width: 100px;} </style> <div class"aa"></div>1.2.2.外部样式2 <!-- rel内表面引入的是style样…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

C++ 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...
C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...