基于BERT的情感分析
基于BERT的情感分析
1. 项目背景
情感分析(Sentiment Analysis)是自然语言处理的重要应用之一,用于判断文本的情感倾向,如正面、负面或中性。随着深度学习的发展,预训练语言模型如BERT在各种自然语言处理任务中取得了显著的效果。本项目利用预训练语言模型BERT,构建一个能够对文本进行情感分类的模型。
2. 项目结构
sentiment-analysis/
├── data/
│ ├── train.csv # 训练数据集
│ ├── test.csv # 测试数据集
├── src/
│ ├── preprocess.py # 数据预处理模块
│ ├── train.py # 模型训练脚本
│ ├── evaluate.py # 模型评估脚本
│ ├── inference.py # 模型推理脚本
│ ├── utils.py # 工具函数(可选)
├── models/
│ ├── bert_model.pt # 保存的模型权重
├── logs/
│ ├── training.log # 训练日志(可选)
├── README.md # 项目说明文档
├── requirements.txt # 依赖包列表
└── run.sh # 一键运行脚本
3. 环境准备
3.1 系统要求
- Python 3.6 或以上版本
- GPU(可选,但建议使用以加速训练)
3.2 安装依赖
建议在虚拟环境中运行。安装所需的依赖包:
pip install -r requirements.txt
requirements.txt内容:
torch>=1.7.0
transformers>=4.0.0
pandas
scikit-learn
tqdm
4. 数据准备
4.1 数据格式
数据文件train.csv和test.csv的格式如下:
| text | label |
|---|---|
| I love this product. | 1 |
| This is a bad movie. | 0 |
- text:输入文本
- label:目标标签,
1为正面情感,0为负面情感
将数据文件保存至data/目录下。
4.2 数据集划分
可以使用train_test_split将数据划分为训练集和测试集。
5. 代码实现
5.1 数据预处理 (src/preprocess.py)
import pandas as pd
from transformers import BertTokenizer
from torch.utils.data import Dataset
import torchclass SentimentDataset(Dataset):"""自定义的用于情感分析的Dataset。"""def __init__(self, data_path, tokenizer, max_len=128):"""初始化Dataset。Args:data_path (str): 数据文件的路径。tokenizer (BertTokenizer): BERT的分词器。max_len (int): 最大序列长度。"""self.data = pd.read_csv(data_path)self.tokenizer = tokenizerself.max_len = max_lendef __len__(self):"""返回数据集的大小。"""return len(self.data)def __getitem__(self, idx):"""根据索引返回一条数据。Args:idx (int): 数据索引。Returns:dict: 包含input_ids、attention_mask和label的字典。"""text = str(self.data.iloc[idx]['text'])label = int(self.data.iloc[idx]['label'])encoding = self.tokenizer(text, padding='max_length', truncation=True, max_length=self.max_len, return_tensors="pt")return {'input_ids': encoding['input_ids'].squeeze(0), # shape: [seq_len]'attention_mask': encoding['attention_mask'].squeeze(0), # shape: [seq_len]'label': torch.tensor(label, dtype=torch.long) # shape: []}
5.2 模型训练 (src/train.py)
import torch
from torch.utils.data import DataLoader
from transformers import BertForSequenceClassification, AdamW, BertTokenizer, get_linear_schedule_with_warmup
from preprocess import SentimentDataset
import argparse
import os
from tqdm import tqdmdef train_model(data_path, model_save_path, batch_size=16, epochs=3, lr=2e-5, max_len=128):"""训练BERT情感分析模型。Args:data_path (str): 训练数据的路径。model_save_path (str): 模型保存的路径。batch_size (int): 批次大小。epochs (int): 训练轮数。lr (float): 学习率。max_len (int): 最大序列长度。"""# 初始化分词器和数据集tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')dataset = SentimentDataset(data_path, tokenizer, max_len=max_len)# 划分训练集和验证集train_size = int(0.8 * len(dataset))val_size = len(dataset) - train_sizetrain_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])# 数据加载器train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=batch_size)# 初始化模型model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)# 优化器和学习率调度器optimizer = AdamW(model.parameters(), lr=lr)total_steps = len(train_loader) * epochsscheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)# 设备设置device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device)# 训练循环for epoch in range(epochs):model.train()total_loss = 0progress_bar = tqdm(train_loader, desc=f"Epoch {epoch + 1}/{epochs}")for batch in progress_bar:optimizer.zero_grad()input_ids = batch['input_ids'].to(device) # shape: [batch_size, seq_len]attention_mask = batch['attention_mask'].to(device) # shape: [batch_size, seq_len]labels = batch['label'].to(device) # shape: [batch_size]outputs = model(input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.lossloss.backward()optimizer.step()scheduler.step()total_loss += loss.item()progress_bar.set_postfix(loss=loss.item())avg_train_loss = total_loss / len(train_loader)print(f"Epoch {epoch + 1}/{epochs}, Average Loss: {avg_train_loss:.4f}")# 验证模型model.eval()val_loss = 0correct = 0total = 0with torch.no_grad():for batch in val_loader:input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)labels = batch['label'].to(device)outputs = model(input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.losslogits = outputs.logitsval_loss += loss.item()preds = torch.argmax(logits, dim=1)correct += (preds == labels).sum().item()total += labels.size(0)avg_val_loss = val_loss / len(val_loader)val_accuracy = correct / totalprint(f"Validation Loss: {avg_val_loss:.4f}, Accuracy: {val_accuracy:.4f}")# 保存模型os.makedirs(os.path.dirname(model_save_path), exist_ok=True)torch.save(model.state_dict(), model_save_path)print(f"Model saved to {model_save_path}")if __name__ == "__main__":parser = argparse.ArgumentParser(description="Train BERT model for sentiment analysis")parser.add_argument('--data_path', type=str, default='data/train.csv', help='Path to training data')parser.add_argument('--model_save_path', type=str, default='models/bert_model.pt', help='Path to save the trained model')parser.add_argument('--batch_size', type=int, default=16, help='Batch size')parser.add_argument('--epochs', type=int, default=3, help='Number of training epochs')parser.add_argument('--lr', type=float, default=2e-5, help='Learning rate')parser.add_argument('--max_len', type=int, default=128, help='Maximum sequence length')args = parser.parse_args()train_model(data_path=args.data_path,model_save_path=args.model_save_path,batch_size=args.batch_size,epochs=args.epochs,lr=args.lr,max_len=args.max_len)
5.3 模型评估 (src/evaluate.py)
import torch
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from preprocess import SentimentDataset
from torch.utils.data import DataLoader
from transformers import BertForSequenceClassification, BertTokenizer
import argparse
from tqdm import tqdmdef evaluate_model(data_path, model_path, batch_size=16, max_len=128):"""评估BERT情感分析模型。Args:data_path (str): 测试数据的路径。model_path (str): 训练好的模型的路径。batch_size (int): 批次大小。max_len (int): 最大序列长度。"""# 初始化分词器和数据集tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')dataset = SentimentDataset(data_path, tokenizer, max_len=max_len)loader = DataLoader(dataset, batch_size=batch_size)# 加载模型model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))model.eval()# 设备设置device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device)all_preds = []all_labels = []with torch.no_grad():for batch in tqdm(loader, desc="Evaluating"):input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)labels = batch['label'].to(device)outputs = model(input_ids, attention_mask=attention_mask)logits = outputs.logitspreds = torch.argmax(logits, dim=1)all_preds.extend(preds.cpu().numpy())all_labels.extend(labels.cpu().numpy())accuracy = accuracy_score(all_labels, all_preds)precision, recall, f1, _ = precision_recall_fscore_support(all_labels, all_preds, average='binary')print(f"Accuracy: {accuracy:.4f}")print(f"Precision: {precision:.4f}, Recall: {recall:.4f}, F1-score: {f1:.4f}")if __name__ == "__main__":parser = argparse.ArgumentParser(description="Evaluate BERT model for sentiment analysis")parser.add_argument('--data_path', type=str, default='data/test.csv', help='Path to test data')parser.add_argument('--model_path', type=str, default='models/bert_model.pt', help='Path to the trained model')parser.add_argument('--batch_size', type=int, default=16, help='Batch size')parser.add_argument('--max_len', type=int, default=128, help='Maximum sequence length')args = parser.parse_args()evaluate_model(data_path=args.data_path,model_path=args.model_path,batch_size=args.batch_size,max_len=args.max_len)
5.4 推理 (src/inference.py)
import torch
from transformers import BertTokenizer, BertForSequenceClassification
import argparsedef predict_sentiment(text, model_path, max_len=128):"""对输入的文本进行情感预测。Args:text (str): 输入的文本。model_path (str): 训练好的模型的路径。max_len (int): 最大序列长度。Returns:str: 预测的情感类别。"""# 初始化分词器和模型tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))model.eval()# 设备设置device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model.to(device)# 数据预处理inputs = tokenizer(text, return_tensors="pt", truncation=True, padding='max_length', max_length=max_len)inputs = {key: value.to(device) for key, value in inputs.items()}# 模型推理with torch.no_grad():outputs = model(**inputs)logits = outputs.logitsprediction = torch.argmax(logits, dim=1).item()sentiment = "Positive" if prediction == 1 else "Negative"return sentimentif __name__ == "__main__":parser = argparse.ArgumentParser(description="Inference script for sentiment analysis")parser.add_argument('--text', type=str, required=True, help='Input text for sentiment prediction')parser.add_argument('--model_path', type=str, default='models/bert_model.pt', help='Path to the trained model')parser.add_argument('--max_len', type=int, default=128, help='Maximum sequence length')args = parser.parse_args()sentiment = predict_sentiment(text=args.text,model_path=args.model_path,max_len=args.max_len)print(f"Input Text: {args.text}")print(f"Predicted Sentiment: {sentiment}")
6. 项目运行
6.1 一键运行脚本 (run.sh)
#!/bin/bash# 训练模型
python src/train.py --data_path=data/train.csv --model_save_path=models/bert_model.pt# 评估模型
python src/evaluate.py --data_path=data/test.csv --model_path=models/bert_model.pt# 推理示例
python src/inference.py --text="I love this movie!" --model_path=models/bert_model.pt
6.2 单独运行
6.2.1 训练模型
python src/train.py --data_path=data/train.csv --model_save_path=models/bert_model.pt --epochs=3 --batch_size=16
6.2.2 评估模型
python src/evaluate.py --data_path=data/test.csv --model_path=models/bert_model.pt
6.2.3 模型推理
python src/inference.py --text="This product is great!" --model_path=models/bert_model.pt
7. 结果展示
7.1 训练结果
- 损失下降曲线:可以使用
matplotlib或tensorboard绘制训练过程中的损失变化。 - 训练日志:在
logs/training.log中记录训练过程。
7.2 模型评估
- 准确率(Accuracy):模型在测试集上的准确率。
- 精确率、召回率、F1-score:更全面地评估模型性能。
7.3 推理示例
示例:
python src/inference.py --text="I absolutely love this!" --model_path=models/bert_model.pt
输出:
Input Text: I absolutely love this!
Predicted Sentiment: Positive
8. 注意事项
- 模型保存与加载:确保模型保存和加载时的路径正确,特别是在使用相对路径时。
- 设备兼容性:代码中已考虑CPU和GPU的兼容性,确保设备上安装了相应的PyTorch版本。
- 依赖版本:依赖的库版本可能会影响代码运行,建议使用
requirements.txt中指定的版本。
9. 参考资料
- BERT论文
- Hugging Face Transformers文档
- PyTorch官方文档
相关文章:

基于BERT的情感分析
基于BERT的情感分析 1. 项目背景 情感分析(Sentiment Analysis)是自然语言处理的重要应用之一,用于判断文本的情感倾向,如正面、负面或中性。随着深度学习的发展,预训练语言模型如BERT在各种自然语言处理任务中取得了…...

推荐15个2024最新精选wordpress模板
以下是推荐的15个2024年最新精选WordPress模板,轻量级且SEO优化良好,适合需要高性能网站的用户。中文wordpress模板适合搭建企业官网使用。英文wordpress模板,适合B2C网站搭建,功能强大且兼容性好,是许多专业外贸网站的…...

AWTK-WIDGET-WEB-VIEW 实现笔记 (2) - Windows
在 Windows 平台上的实现,相对比较顺利,将一个窗口嵌入到另外一个窗口是比较容易的事情。 1. 创建窗口 这里有点需要注意: 父窗口的大小变化时,子窗口也要跟着变化,否则 webview 显示不出来。创建时窗口的大小先设置…...

Linux四剑客及正则表达式
正则表达式 基础正则(使用四剑客命令时无需加任何参数即可使用) ^ # 匹配以某一内容开头 如:^grep匹配所有以grep开头的行。 $ # 匹配以某一内容结尾 如:grep$ 匹配所有以grep结尾的行。 ^$ # 匹配空行。 . # 匹配…...
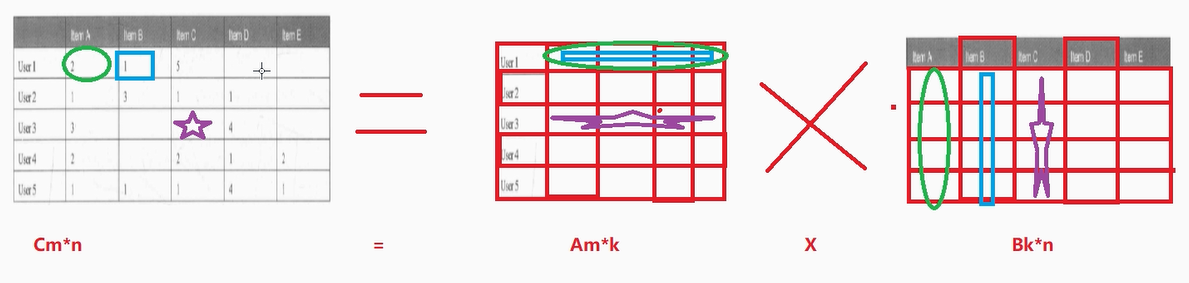
ALS 推荐算法案例演示(python)
数学知识补充:矩阵 总结来说: Am*k X Bk*n Cm*n ----至于乘法的规则,是数学问题, 知道可以乘即可,不需要我们自己计算 反过来 Cm*n Am*k X Bk*n ----至于矩阵如何拆分/如何分解,是数学问题,知道可以拆/可以分解即可 ALS 推荐算法案例:电影推…...

labview中连接sql server数据库查询语句
当使用数据库查询功能时,我们需要用到数据库的查询语句,这里已调用sql server为例,我们需要按照时间来查询,这里在正常调用数据库查询语句时,我们需要在前面给他加一个限制条件这里用到了,数据库的查询语句…...

leetcode_二叉树最大深度
对二叉树的理解 对递归调用的理解 对内存分配的理解 基础数据结构(C版本) - 飞书云文档 每次函数的调用 都会进行一次新的栈内存分配 所以lmax和rmax的值不会混在一起 /*** Definition for a binary tree node.* struct TreeNode {* int val;* …...

Elasticsearch 重建索引 数据迁移
Elasticsearch 重建索引 数据迁移 处理流程创建临时索引数据迁移重建索引写在最后 大家都知道,es的索引创建完成之后就不可以再修改了,包括你想更改字段属性或者是分词方式等。那么随着业务数据量的发展,可能会出现需要修改索引,或…...

2411rust,异步函数
原文 Rust异步工作组很高兴地宣布,在实现在特征中使用异步 fn的目标方面取得了重大进度.将在下周发布稳定的Rust1.75版,会包括特征中支持impl Trait注解和async fn. 稳定化 自从RFC#1522在Rust1.26中稳定下来以来,Rust就允许用户按函数的返回类型(一般叫"RPIT")编…...

前端网络性能优化问题
DNS预解析 DNS 解析也是需要时间的,可以通过预解析的⽅式来预先获得域名所对应的 IP。 <link rel"dns-prefetch" href"//abcd.cn"> 缓存 强缓存 在缓存期间不需要请求, state code 为 200 可以通过两种响应头实现&#…...
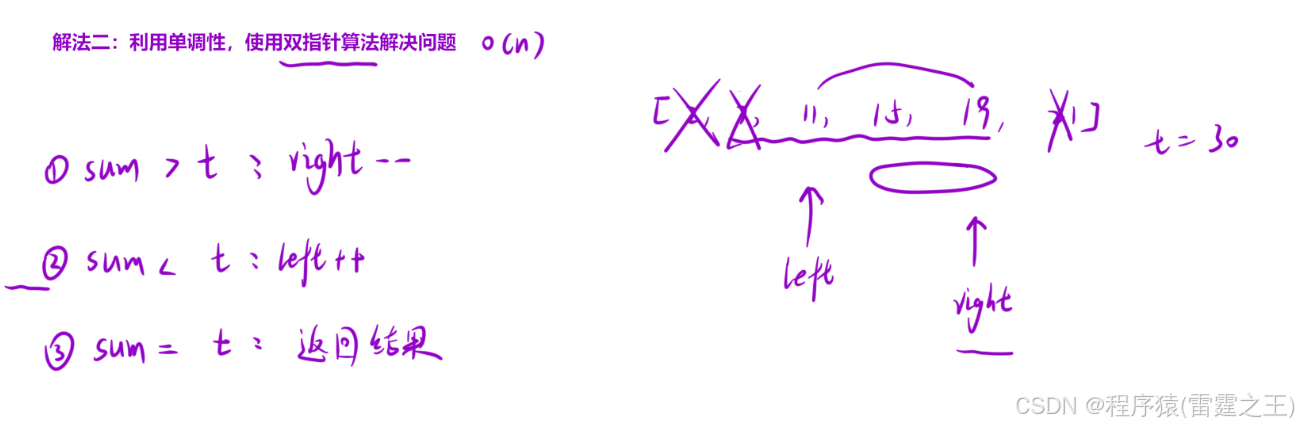
优选算法——双指针
前言 本篇博客为大家介绍双指针问题,它属于优选算法中的一种,也是一种很经典的算法;算法部分的学习对我们来说至关重要,它可以让我们积累解题思路,同时也可以大大提升我们的编程能力,本文主要是通过一些题…...

【Rabbitmq篇】RabbitMQ⾼级特性----消息确认
目录 前言: 一.消息确认机制 • ⾃动确认 • ⼿动确认 手动确认方法又分为三种: 二. 代码实现(spring环境) 配置相关信息: 1). AcknowledgeMode.NONE 2 )AcknowledgeMode.AUTO 3&…...
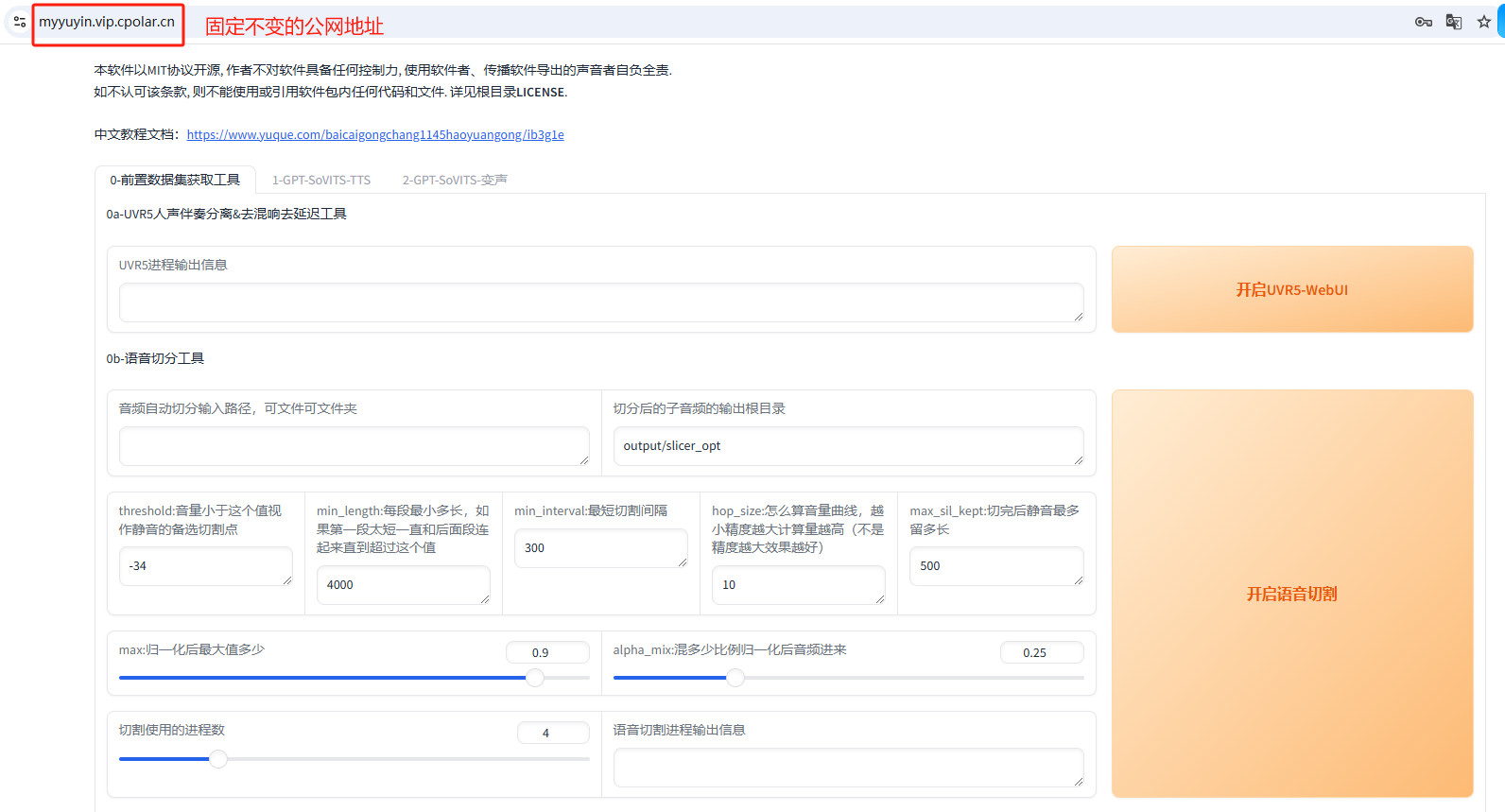
开源TTS语音克隆神器GPT-SoVITS_V2版本地整合包部署与远程使用生成音频
文章目录 前言1.GPT-SoVITS V2下载2.本地运行GPT-SoVITS V23.简单使用演示4.安装内网穿透工具4.1 创建远程连接公网地址 5. 固定远程访问公网地址 前言 本文主要介绍如何在Windows系统电脑使用整合包一键部署开源TTS语音克隆神器GPT-SoVITS,并结合cpolar内网穿透工…...

【idea】更换快捷键
因为个人习惯问题需要把快捷键替换一下。我喜欢用CTRLD删除一下,用CTRLY复制一样。恰好这两个快捷键需要互换一下。 打开file——>setting——>Keymap——>Edit Actions 找到CTRLY并且把它删除 找到CTRLD 并且把它删除 鼠标右键添加CTRLY 同样操作在Delet…...

最小的子数组(leetcode 209)
给定一个正整数数组,找到大于等于s的连续的最小长度的区间。 解法一:暴力解法 两层for循环,一个区间终止位置,一个区间起始位置,找到大于等于s的最小区间长度(超时了) 解法二:双指…...
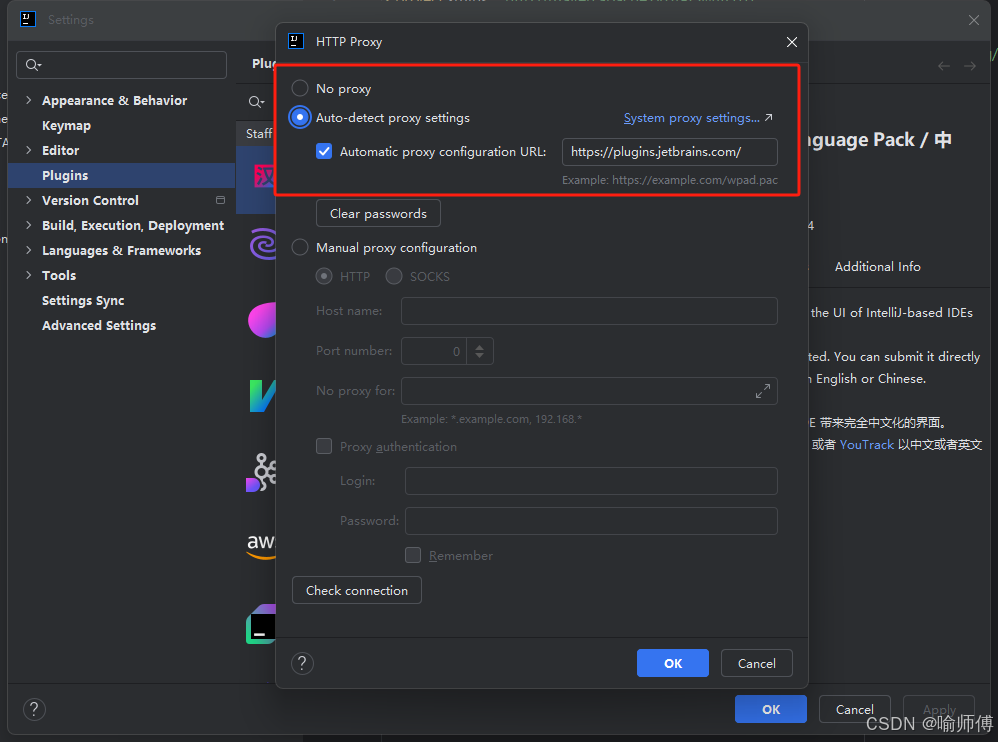
IDEA-Plugins无法下载插件(网络连接问题-HTTP Proxy Settings)
IDEA-Plugins无法下载插件(网络连接问题) 改成如下配置: 勾选 添这个url即可:https://plugins.jetbrains.com/ 重启插件中心,问题解决。...

AWTK-WIDGET-WEB-VIEW 发布
awtk-widget-web-view 是通过 webview 提供的接口,实现的 AWTK 自定义控件,使得 AWTK 可以方便的显示 web 页面。 项目网址: https://gitee.com/zlgopen/awtk-widget-web-view webview 提供了一个跨平台的 webview 接口,是一个非…...

Mysql每日一题(if函数)
两种写法if()和case if()函数 select *,if(T.xT.y>T.z and T.xT.z>T.y and T.yT.z>T.x,Yes,No) as triangle from Triangle as T; case方法 select *, case when T.xT.y>T.z and T.xT.z>T.y and T.yT.z>T.x then Yes else No end as triangle from Trian…...

Spring Cloud Alibaba [Gateway]网关。
1 简介 网关作为流量的入口,常用功能包括路由转发、权限校验、限流控制等。而springcloudgateway 作为SpringCloud 官方推出的第二代网关框架,取代了Zuul网关。 1.1 SpringCloudGateway特点: (1)基于Spring5,支持响应…...

【动手学深度学习Pytorch】2. Softmax回归代码
零实现 导入所需要的包: import torch from IPython import display from d2l import torch as d2l定义数据集参数、模型参数: batch_size 256 # 每次随机读取256张图片 train_iter, test_iter d2l.load_data_fashion_mnist(batch_size) # 将展平每个…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...

在树莓派上添加音频输入设备的几种方法
在树莓派上添加音频输入设备可以通过以下步骤完成,具体方法取决于设备类型(如USB麦克风、3.5mm接口麦克风或HDMI音频输入)。以下是详细指南: 1. 连接音频输入设备 USB麦克风/声卡:直接插入树莓派的USB接口。3.5mm麦克…...
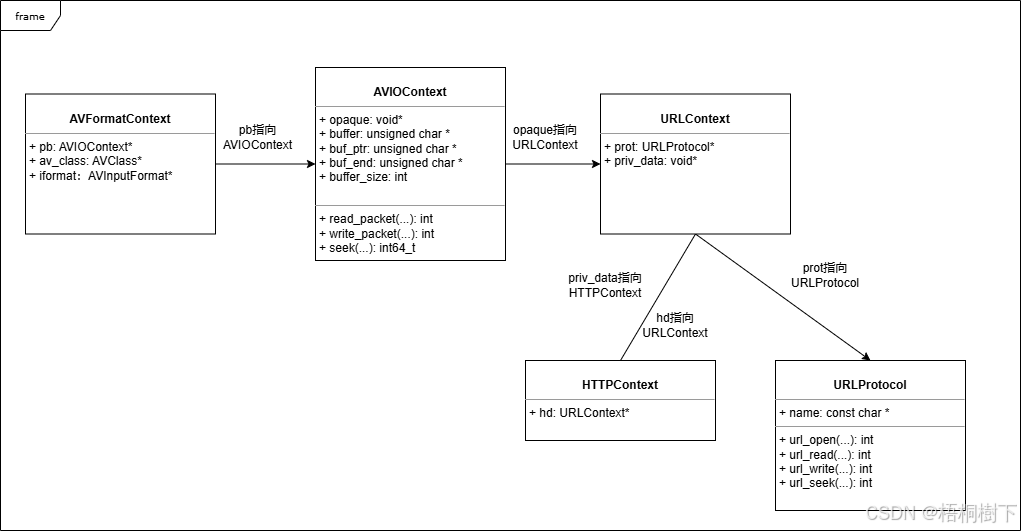
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...

拟合问题处理
在机器学习中,核心任务通常围绕模型训练和性能提升展开,但你提到的 “优化训练数据解决过拟合” 和 “提升泛化性能解决欠拟合” 需要结合更准确的概念进行梳理。以下是对机器学习核心任务的系统复习和修正: 一、机器学习的核心任务框架 机…...

「Java基本语法」变量的使用
变量定义 变量是程序中存储数据的容器,用于保存可变的数据值。在Java中,变量必须先声明后使用,声明时需指定变量的数据类型和变量名。 语法 数据类型 变量名 [ 初始值]; 示例:声明与初始化 public class VariableDemo {publi…...