常用命令之LinuxOracleHivePython
1. 用户改密
passwd app_adm
chage -l app_adm
passwd -x 90 app_adm -> 执行操作后,app_adm用户的密码时间改为90天有效期--查看该euser用户过期信息使用chage命令
--chage的参数包括
---m 密码可更改的最小天数。为零时代表任何时候都可以更改密码。
---M 密码保持有效的最大天数。
---W 用户密码到期前,提前收到警告信息的天数。
---E 帐号到期的日期。过了这天,此帐号将不可用。
---d 上一次更改的日期
---i 停滞时期。如果一个密码已过期这些天,那么此帐号将不可用。
---l 例出当前的设置。由非特权用户来确定他们的密码或帐号何时过期
2. 开机自启
#方式一
将开机自启脚本加到/etc/rc.d/rc.loacl
#方式二
systemctl enable nfs-server
systemctl enable rpcbind
#查看是否开机自启
systemctl list-unit-files|grep enabled | grep nfs-server
systemctl list-unit-files|grep enabled | grep rpcbind
3.查找&推送命令
find /home -size +1M --查找 /home 目录下大于 1MB 的文件
find . -name "*.c" --将当前目录及其子目录下所有文件后缀为 .c 的文件列出来
grep -irnl "dim_poia_capital_zone" /home/app_adm/etl/Hqlexec/sql --查询Linux文件中包含字符的文件名称
ssh -l app_adm 10.169.1.178 --ssh指定用户访问
scp -P 4588 hdfs@stmg102:/usr/local/sin.sh /home/administrator --以及scp集群间拷贝文件
hdfs dfs -chmod -R 777 /user/hive/warehouse/
hdfs dfs -chown -R hive:hive /user/hive/warehouse/
hdfs dfs -put -f /usr/local/sin.sh /user/hive/warehouse/sin.sh --如果文件已存在覆盖
hdfs dfs -get /user/hive/warehouse/sin.sh /usr/local/ --如果文件已存在覆盖
4.windows 获取目录下的文件名
# windows中将目录下面的文件名称写到list.txt文件中
dir *.* /B >list.txt
5. 建立软连接
--建议软连接
ln -s /usr/local/python3/bin/python3 /usr/bin/python
--删除软连接,源文件还在
rm mylink
--给当前目录下的所有文件赋权
chmod 766 ./*--注意:路径采用Linux的写法(/),防止符号转义 */
6.Linux查看wiondows共享盘的用户名和密码
--查看wiondows共享盘的用户名和密码
sudo cat /etc/samba/smb.conf | grep "共享盘名称"--配置开机自动挂载的可以查看开机自动挂载
cat /etc/fstab
7. kettle 解决数据库中文乱码
右键编辑spoon.bat 添加 "-Dfile.encoding=UTF-8"
保存重启
8.查看内核版本
--查看内核版本
cat /proc/version
--查看是x86
uname -m
9.Git
步骤 1:创建 Git 存储库
步骤 2:复制存储库并添加文件
步骤 3:从存储库中提取更改
步骤 4:使用源代码树分支合并更新
10. kettle 文件通配符
.*CRM.*.xml|EMP_.*.xml
11. linux中的环境变量
/etc/profile :用来设置系统的环境变量,对系统内所有用户生效,source /etc/profile
~/.bashrc:针对某一个特定的用户,设置环境变量只对该用户自己生效
--追加生效
source /etc/profile >> ~/.bashrc
--查看追加
cat /etc/profile >> ~/.bashrc
12. rpm命令
--这个命令可以使rpm 安装时不检查依赖关系
rpm -i software-2.3.4.rpm --nodeps
-- 这个命令可以强制安装rpm包
rpm -ivh software-2.3.4.rpm --force
13. finereport激活码
fd336a2a-4a7e3c38f-6433-d59127605172
14.shell分割字符串并赋值给变量
id=`echo $var | awk -F "=" '{print $2}'`
15. kettle变量
--job中设置--1.job中设置变量 ->2.下一个转换中[获取变量]组件(客户修改名称以及去空格)->3.转换中直接使用${变量名称} (范围设置在当前job中有效即可,否则变量有重复则会错误)--转换中设置--1.转换中设置变量不能在当前转换中使用(可以读取表中的数据->进行设置变量)->2.在下一个转换中使用[获取变量]组件->3.来${变量名称}进行使用 (范围设置在当前job中有效即可,否则变量有重复则会错误)
16. 更新kettle数据库脚本
create table repkettle.r_database_20240424bakup as select * from repkettle.r_database;
update repkettle.r_database tset t.host_name = '10.169.1.228', t.database_name = 'etltdb'where t.host_name = '10.169.1.42';
17.flink资源使用
1.任务具体的实现和数据规模其中数据规模:读取文件的大小 处理数据的行数2.并行度窗口大小:窗口越大需要的CPU和内存就越多并行度因子 :不同的并行度因子对应着不同的并行度3.JVM堆大小 JVM堆越大,可以同时运行的线程数就越多。 因此,JVM大小可以调整并发度4.架构
ngnix->flume->kafka->flink->存储(采集-计算-指标计算)
--其中要保证数据丢失问题、重复读取(偏移量)
18.shell脚本调用OracleSQL异常捕获
#add 20221216 捕获异常修复,由于执行OracleSQL进入新的进程,使用判断返回值是否为空的方式捕获异常
cmd=`echo "$cmd"| awk '{printf "%s\n", $0}'`
echo "cmd:"$cmdif [ ! ${cmd} ]; thenecho "EXECUTION SUCCEEDED"echo $cmdexit 0
elseecho "EXECUTION FAILED"echo $cmdexit -1
fi
19.jdbc双节点配置
jdbc:oracle:thin:@(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 10.163.128.79)(PORT = 1521))(ADDRESS = (PROTOCOL = TCP)(HOST = 10.163.128.80)(PORT = 1521))(LOAD_BALANCE = yes))(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = etldb)))
20. 创建用户及赋权
--创建用户
create user test123 identified by test123;
--赋权
grant connect,resource to test123;
21.表空间使用情况查询语句
--3. 表空间使用情况
select a.tablespace_name,total,free,total-free used from
( select tablespace_name,sum(bytes)/1024/1024 total from dba_data_filesgroup by tablespace_name) a,
( select tablespace_name,sum(bytes)/1024/1024 free from dba_free_spacegroup by tablespace_name) b
where a.tablespace_name=b.tablespace_name;---1、表占用空间
select segment_name, sum(bytes)/1024/1024 Mbytese from user_segments where segment_type='TABLE' group by segment_name;--增加表空间
ALTER TABLESPACE dc_dw ADD DATAFILE
'D:\oracle\product\10.2.0\oradata\irdcdev\DC_DW1.DBF' SIZE 500M
AUTOEXTEND ON NEXT 8G MAXSIZE unlimited;
22. 修改MYSQL密码
mysql
use mysql
update user set password=password("Ab123456") where user="root" and host='10.169.1.%';
flush privileges;select host,user,password from user;
23. 加载csv文件到hive表中
--建表
USE database;
CREATE TABLE table(ssid int comment 'ssid',orderid int comment 'orderid'
)
COMMENT 'table comment'
row format delimited fields terminated by ','STORED AS textfile
location '/data_coffe/ods/dim_channel';download[hdfs:///***/hotel.csv-20190904-172542.csv hotel.csv] --加载路径
LOAD DATA local INPATH 'hotel.csv' into table database.table;--将数据load到表中
24.MYSQL创建只读用户
--1.创建用户
CREATE USER 'readonly'@'%' IDENTIFIED BY '123456';
CREATE USER 'readonly'@'10.76.2.25' IDENTIFIED BY '123456';
CREATE USER 'readonly'@'10.76.2.26' IDENTIFIED BY '123456';
--2.给用户赋予只读权限
GRANT SELECT ON hive.* TO 'readonly'@'%';
GRANT SELECT ON hive.* TO 'readonly'@'10.76.2.25';
GRANT SELECT ON hive.* TO 'readonly'@'10.76.2.26';
--3.刷新权限
FLUSH PRIVILEGES;创建只读用户完成;账号:readonly 密码:123456 操作的数据库表:hive.* 指定登录的IP:’%’(所有)
GRANT [权限]
ON [库.表]
TO [用户名]@[IP]
IDENTIFIED BY [密码]
25. HIVE元数据乱码操作
--修改字段注释字符集
--①修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8
--②修改分区字段注解:
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
--③修改索引注解:
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;SELECT s.NAME,t.tbl_name,UPPER(g.column_name) AS column_name ,g.COMMENT,g.integer_idx, g.type_nameFROM TBLS t, SDS k, COLUMNS_V2 g,DBS sWHERE t.sd_id = k.sd_idAND k.cd_id = g.cd_idand t.DB_ID = s.DB_IDand g.COMMENT like '?%'ORDER BY s.NAME,t.tbl_name,g.integer_idx;SELECT distinct s.NAME,t.tbl_nameFROM TBLS t, SDS k, COLUMNS_V2 g,DBS sWHERE t.sd_id = k.sd_idAND k.cd_id = g.cd_idand t.DB_ID = s.DB_IDand g.COMMENT like '?%'ORDER BY s.NAME,t.tbl_name,g.integer_idx;1.修改表注释
alter table 表名 set tblproperties('comment' = '注释');2.修改字段注释
alter table 表名 change 旧字段名 新字段名 字段类型 comment '注释';3.修改分区字段注释,需要在元数据库中执行
update PARTITION_KEYS ps
join TBLS ts on ps.tbl_id = ts.tbl_id
join DBS ds on ts.db_id = ds.db_id
set ps.pkey_comment = '注释'
where lower(ds.name) = '库名' and lower(ts.tbl_name) = '表名' and lower(ps.pkey_name) = '分区字段名';STORED AS PARQUET
TBLPROPERTIES ( 'parquet.compression'='snappy');STORED AS TEXTFILE;
SELECT s.NAME,t.tbl_name,UPPER(g.column_name) AS column_name ,g.COMMENT,g.integer_idx, g.type_nameFROM TBLS t, SDS k, COLUMNS_V2 g,DBS sWHERE t.sd_id = k.sd_idAND k.cd_id = g.cd_idand t.DB_ID = s.DB_IDand g.COMMENT like '?%'and s.NAME='aml'ORDER BY s.NAME,t.tbl_name,g.integer_idx;SELECT s.TBL_NAME,t.PARAM_VALUE from TABLE_PARAMS t ,TBLS s
where t.TBL_ID = s.TBL_IDand t.PARAM_KEY='comment'order by s.TBL_NAME;update TABLE_PARAMS ps join TBLS ts on ps.tbl_id = ts.tbl_id set ps.PARAM_VALUE = '注释' where ps.PARAM_KEY='comment' and ts.TBL_NAME = SELECT d.NAME,s.TBL_NAME,t.PARAM_VALUE from TABLE_PARAMS t ,TBLS s,DBS d
where t.TBL_ID = s.TBL_IDand d.DB_ID = s.DB_IDand t.PARAM_KEY='comment' and PARAM_VALUE like '%?%'order by s.TBL_NAME
26. excel_to_csv
import pandas as pd
import argparseparser = argparse.ArgumentParser(description='manual to this script')
parser.add_argument("--input_path", type=str, required=True)
parser.add_argument("--output_path", type=str, required=True)
args = parser.parse_args()
print(args.input_path)
print(args.output_path)# 格式转换
def excel_to_txt(input_path, output_path):df = pd.read_excel(input_path, header=None)print('开始写入txt文件')with open(output_path,'w') as f:f.write(df.to_csv(header=False, sep=',', index=False))if __name__ == '__main__':print(args.input_path)print(args.output_path)input_path = args.input_pathoutput_path = args.output_pathexcel_to_txt(input_path, output_path)
27.文件编码转换,将文件编码转换为UTF-8
# -*- coding: utf-8 -*-
"""
@Author : @luyz
@File : FileToCharacter.py
@Project: ETLScript
@Time : 2023-02-23 10:41:18
@Desc : The file is ...
@Version: v1.0
"""
import sys
import os
import gc
import shutil
import traceback
import time
import chardet
import shutildef change_coding(src_file,dst_file):"""文件编码转换,将文件编码转换为UTF-8:param file::return:"""coding='GB18030'with open(src_file, 'r', encoding=coding) as fr, open(dst_file, 'w', encoding='utf-8') as fw:content=fr.read()content=str(content.encode('utf-8'),encoding='utf-8')#print(content,file=fw)fw.write(content)#拷贝文件
def copy_file(s_path,t_path): source_path = os.path.abspath(s_path)target_path = os.path.abspath(t_path)if not os.path.exists(target_path):os.makedirs(target_path)if os.path.exists(source_path):# root 所指的是当前正在遍历的这个文件夹的本身的地址# dirs 是一个 list,内容是该文件夹中所有的目录的名字(不包括子目录)# files 同样是 list, 内容是该文件夹中所有的文件(不包括子目录)for root, dirs, files in os.walk(source_path):for file in files:src_file = os.path.join(root, file)shutil.copy(src_file, target_path)#print(src_file)# 重新创建临时目录
def mkdir(tmp_path):for root, dirs, files in os.walk(tmp_path, topdown=False):for name in files:os.remove(os.path.join(root, name))for name in dirs:os.rmdir(os.path.join(root, name))if not os.path.exists(tmp_path):os.makedirs(tmp_path)#遍历文件统一将文件从gbk转utf-8
def iterate_file_to_utf8(target_path,tmp_path):for root,dirs,files in os.walk(target_path,topdown=False):for file in files:#获取文件所属目录#print("root: "+root)#获取文件路径src_file = os.path.join(root,file)fileprefix = os.path.splitext(src_file)[-1]#print("fileprefix :"+fileprefix)if fileprefix in (".txt") and fileprefix.strip():print("[INFO]: file: " + file)dst_file = os.path.join(tmp_path,file)#如果文件本身就是utf-8,直接复制encoding = get_encoding(src_file)print('[INFO]: ' + str(src_file) + " encoding is: " + str(encoding))if str(encoding) in ("utf-8"):print("[INFO]: start copy file.")shutil.copyfile(src_file, dst_file)else :print("[INFO]: file is not utf-8")change_coding(src_file,dst_file)def get_encoding(file):with open(file,'rb') as f:return chardet.detect(f.read())['encoding']#获取目录个数
def get_file_wc(path):count = 0files = os.listdir(path)for file in files:fileprefix = os.path.splitext(file)[-1]#print("fileprefix :"+fileprefix)if fileprefix in (".txt") and fileprefix.strip():#print("fileprefix :"+fileprefix)count = count + 1#count = len(files) print('[INFO]: '+ path + " count :" + str(count))return countdef get_utf8file_wc(path):count = 0files = os.listdir(path)for file in files:fileprefix = os.path.splitext(file)[-1]path_full = os.path.join(path,file)encoding = get_encoding(path_full)print('[INFO]: ' + path_full + " encoding :"+str(encoding))if fileprefix in (".txt") and fileprefix.strip() and str(encoding) in ("utf-8"):#print("fileprefix :"+fileprefix)count = count + 1#count = len(files) print('[INFO]: ' + path + " count :" + str(count))return countif __name__ == "__main__":# 验证入参个数if (len( sys.argv ) != 4):print("[ERROR]: arg error! please input:<src_file><dst_file><file_date> ")sys.exit(1)source_path = sys.argv[1]+'/'+sys.argv[3]target_path = sys.argv[2]+'/'+sys.argv[3]print("[INFO]: 0.Start printing parameters")print("[INFO]: source_path: " + sys.argv[1])print("[INFO]: target_path: " + sys.argv[2])print("[INFO]: file_date: " + sys.argv[3])try:if not os.path.exists(source_path):print('[INFO]: '+source_path + "dir is not exists")sys.exit(1)#1.拷贝文件print("[INFO]: 1.Start copying files")copy_file(source_path,target_path)print("[INFO]: 将文件 {source_path} 拷贝到 {target_path}".format(source_path = source_path,target_path = target_path))#2.重新创建临时目录tmp_path = target_path + '/tmp'print("[INFO]: 2.Create a temp dir: "+tmp_path)mkdir(tmp_path)#3.遍历文件统一将文件从gbk转utf8print("[INFO]: 3.Begins character set conversion")iterate_file_to_utf8(target_path,tmp_path)print("[INFO]: file conversion success!!!")#4.稽核转码之后的文件个数print("[INFO]: 4.Start auditing the number of files after transcoding")src_wc = get_file_wc(source_path)dst_wc = get_file_wc(tmp_path)result = abs(src_wc - dst_wc)if abs(result) > 0: # Decimalprint("[INFO]: This audit file count is not passed!!!")sys.exit(1)print("[INFO]: The audit was successful!!!")sys.exit(0)except Exception:exe = traceback.format_exc()print("[ERROR]: file conversion fail...")print("[ERROR]: source filePath : {source_path}".format(source_path=source_path))print(exe)sys.exit(1)
28.Linux定时任务
1.使用yum命令安装Crontab:yum install vixie-cron
yum install crontabs
注:vixie-cron软件包是cron的主程序;
crontabs软件包是用来安装、卸装、或列举用来驱动 cron 守护进程的表格的程序。
cron是linux的内置服务,但它不自动起来,可以用以下的方法启动、关闭这个服务:
/sbin/service crond start #启动服务
/sbin/service crond stop #关闭服务
/sbin/service crond restart #重启服务
/sbin/service crond reload #重新载入配置
复制
2.查看Crontab状态:service crond status
ntsysv #查看crontab服务是否已设置为开机启动
chkconfig –level 35 crond on #加入开机自动启动

3.添加定时任务:crontab -e #编辑cron任务模式
i #默认文字编辑器为vim,按i字母键即可添加cron任务
30 3 * * * /usr/local/etc/rc.d/lighttpd restart #将命令代码放入,此命令意义为每天的03:30 重启apache
ESC #按ESC键退出编辑模式
:wq #键入:wq保存
service crond restart #重启crontab服务
复制
4.查看任务列表:crontab -l
复制
5.Crontab相关命令:(1)语 法:
crontab [-u <用户名称>][配置文件] 或 crontab { -l | -r | -e }
-u #<用户名称> 是指设定指定<用户名称>的定时任务,这个前提是你必须要有其权限(比如说是 root)才能够指定他人的时程表。如果不使用 -u user 的话,就是表示设定自己的定时任务。
-l #列出该用户的定时任务设置。
-r #删除该用户的定时任务设置。
-e #编辑该用户的定时任务设置。(2)命令时间格式 :
* * * * * command
分 时 日 月 周 命令
第1列表示分钟1~59 每分钟用*或者 */1表示
第2列表示小时1~23(0表示0点)
第3列表示日期1~31
第4列表示月份1~12
第5列标识号星期0~6(0表示星期天)
第6列要运行的命令(3)一些Crontab定时任务例子:
30 21 * * * /usr/local/etc/rc.d/lighttpd restart #每晚的21:30 重启apache
45 4 1,10,22 * * /usr/local/etc/rc.d/lighttpd restart #每月1、10、22日的4 : 45重启apache
10 1 * * 6,0 /usr/local/etc/rc.d/lighttpd restart #每周六、周日的1 : 10重启apache
0,30 18-23 * * * /usr/local/etc/rc.d/lighttpd restart #每天18 : 00至23 : 00之间每隔30分钟重启apache
0 23 * * 6 /usr/local/etc/rc.d/lighttpd restart #每星期六的11 : 00 pm重启apache
* 23-7/1 * * * /usr/local/etc/rc.d/lighttpd restart #晚上11点到早上7点之间,每隔一小时重启apache
* */1 * * * /usr/local/etc/rc.d/lighttpd restart #每一小时重启apache
0 11 4 * mon-wed /usr/local/etc/rc.d/lighttpd restart #每月的4号与每周一到周三的11点重启apache
0 4 1 jan * /usr/local/etc/rc.d/lighttpd restart #一月一号的4点重启apache*/30 * * * * /usr/sbin/ntpdate cn.pool.ntp.org #每半小时同步一下时间
0 */2 * * * /sbin/service httpd restart #每两个小时重启一次apache
50 7 * * * /sbin/service sshd start #每天7:50开启ssh服务
50 22 * * * /sbin/service sshd stop #每天22:50关闭ssh服务
0 0 1,15 * * fsck /home #每月1号和15号检查/home 磁盘
1 * * * * /home/bruce/backup #每小时的第一分执行 /home/bruce/backup这个文件
00 03 * * 1-5 find /home "*.xxx" -mtime +4 -exec rm {} \; #每周一至周五3点钟,在目录/home中,查找文件名为*.xxx的文件,并删除4天前的文件。
30 6 */10 * * ls #每月的1、11、21、31日是的6:30执行一次ls命令yum install vixie-cron
yum install crontabsservice crond status
crontab -e #编辑cron任务模式
i #默认文字编辑器为vim,按i字母键即可添加cron任务
30 15 * * 3,5 chmod -R 775 /data/BI/tomcat/webapps/webroot/WEB-INF/reportlets#将命令代码放入,此命令意义为每周3,周5的15:30 执行chmodESC #按ESC键退出编辑模式
:wq #键入:wq保存
service crond restart #重启crontab服务
查看任务列表:crontab -l定时清理日志Crontab日志路径:
ll /var/log/cron*
29. windows下,使用putty软件以ssh的方式连接linux,中文显示乱码
问题说明: windows下,使用putty软件以ssh的方式连接linux,中文显示乱码
解决方案:
第一步:查看linux 机器的系统语言字符集。
操作命令:
locale -a命令执行结果表面,linux机器是utf-8字符集
第二步:打开putty,进行如下操作。
windows–>Translation–>Remote character set,选择与linux机器系统语言一致的字符集。
下图以utf-8为例进行演示:设置完成后,重新使用ssh连接linux机器,即可。
30.从mysql中提取hive建表语句 Python版本
#!/usr/bin/env python
#-*- coding:utf8 -*-
# 从mysql中提取hive建表语句
import os,sys
import fileinput
import datetime
import pymysql#reload(sys)
#sys.setdefaultencoding("utf8")def hive_create_table():conn = pymysql.Connect(host="10.169.1.102",user='scm',passwd='Ab123456!!',database='hive',charset='utf8')mycursor = conn.cursor()# 获取DB_IDselect_DB_ID = "select DB_ID from DBS;"mycursor.execute(select_DB_ID)result_DB_ID = mycursor.fetchall()fo = open("create_tab.sql", "w")for dir_DB_ID in result_DB_ID :# 获取数据库名DB_ID = str(dir_DB_ID)[1:].split(',')[0]print(DB_ID)select_DB_NAME = "select NAME from DBS where DB_ID="+DB_ID+";"print(select_DB_NAME)mycursor.execute(select_DB_NAME)result_DB_NAME = mycursor.fetchone()fo.write("\n--===========数据库:"+str(result_DB_NAME).split('\'')[1]+"===========\n")DBname=str(result_DB_NAME).split('\'')[1]print('数据库名字:' + DBname)print(result_DB_NAME)# 获取表名select_table_name_sql = "select TBL_NAME from TBLS where DB_ID="+DB_ID+";"mycursor.execute(select_table_name_sql)result_table_names = mycursor.fetchall()for table_name_ in result_table_names :#如果存在删除表fo.write("\nDROP TABLE IF EXISTS "+DBname +'.`'+str(table_name_).split('\'')[1]+"`;")fo.write("\n")for table_name in result_table_names :#建表语句fo.write("\nCREATE TABLE IF NOT EXISTS "+DBname +'.`'+str(table_name).split('\'')[1]+"`(\n")# 根据表名获取SD_IDselect_table_SD_ID = "select SD_ID from TBLS where tbl_name='"+str(table_name).split('\'')[1]+"' and DB_ID="+DB_ID+";"print(select_table_SD_ID)mycursor.execute(select_table_SD_ID)result_SD_ID = mycursor.fetchone()print(result_SD_ID )# 根据SD_ID获取CD_IDSD_ID=str(result_SD_ID)[1:].split(',')[0]select_table_CD_ID = "select CD_ID from SDS where SD_ID="+str(result_SD_ID)[1:].split(',')[0]+";"print(select_table_CD_ID)mycursor.execute(select_table_CD_ID)result_CD_ID = mycursor.fetchone()print(result_CD_ID) # 根据CD_ID获取表的列CD_ID=str(result_CD_ID)[1:].split(',')[0]select_table_COLUMN_NAME = "select COLUMN_NAME,TYPE_NAME,COMMENT from COLUMNS_V2 where CD_ID="+str(result_CD_ID)[1:].split(',')[0]+" order by INTEGER_IDX;"print(select_table_COLUMN_NAME)mycursor.execute(select_table_COLUMN_NAME)result_COLUMN_NAME = mycursor.fetchall()print(result_COLUMN_NAME) index=0for col,col_type,col_name in result_COLUMN_NAME:print(col)print(col_type)print(col_name)print(len(result_COLUMN_NAME) )# 写入表的列和列的类型到文件if col_name is None:fo.write(" `"+str(col)+"` "+str(col_type))else:fo.write(" `"+str(col)+"` "+str(col_type) + " COMMENT '" + str(col_name) + "'")if index < len(result_COLUMN_NAME)-1:index = index + 1fo.write(",\n")elif index == len(result_COLUMN_NAME)-1:fo.write("\n)")# 根据表名获取TBL_IDselect_table_SD_ID = "select TBL_ID from TBLS where tbl_name='"+str(table_name).split('\'')[1]+"' and DB_ID="+DB_ID+";"print(select_table_SD_ID)mycursor.execute(select_table_SD_ID)result_TBL_ID = mycursor.fetchone()print(result_TBL_ID)# 根据TBL_ID获取分区信息select_table_PKEY_NAME_TYPE = "select PKEY_NAME,PKEY_TYPE,PKEY_COMMENT from PARTITION_KEYS where TBL_ID="+str(result_TBL_ID)[1:].split(',')[0]+" order by INTEGER_IDX;"print(select_table_PKEY_NAME_TYPE)mycursor.execute(select_table_PKEY_NAME_TYPE)result_PKEY_NAME_TYPE = mycursor.fetchall()print(result_PKEY_NAME_TYPE)if len(result_PKEY_NAME_TYPE) > 0:fo.write("\nPARTITIONED BY (\n")else :fo.write("\n")i=0for pkey_name,pkey_type,PKEY_COMMENT in result_PKEY_NAME_TYPE:if str(PKEY_COMMENT) is None:fo.write(" `"+str(pkey_name)+"` "+str(pkey_type))else:fo.write(" `"+str(pkey_name)+"` "+str(pkey_type) + " COMMENT '" + str(PKEY_COMMENT) + "'\n")if i < len(result_PKEY_NAME_TYPE)- 1:i = i + 1fo.write(",")elif i == len(result_PKEY_NAME_TYPE) - 1:fo.write(")\n")# 根据表TBL_ID 获得中文名称select_PARAM_VALUE01 = "select PARAM_VALUE from TABLE_PARAMS WHERE TBL_ID=( select TBL_ID from TBLS where tbl_name='"+str(table_name).split('\'')[1]+"' and DB_ID="+DB_ID+") and PARAM_KEY='comment';"print(select_PARAM_VALUE01)mycursor.execute(select_PARAM_VALUE01)result_PARAM_VALUE01 = mycursor.fetchone()print(result_PARAM_VALUE01)if result_PARAM_VALUE01 is None:print('未设置表名')elif not result_PARAM_VALUE01[0]:print('表名为空')else:fo.write("COMMENT '" + str(result_PARAM_VALUE01[0]) +"' \n" )# 根据SD_ID和CD_ID获取SERDE_IDselect_SERDE_ID = "select SERDE_ID from SDS where SD_ID="+SD_ID+" and CD_ID="+CD_ID+";"print(select_SERDE_ID)mycursor.execute(select_SERDE_ID)result_SERDE_ID = mycursor.fetchone()print(result_SERDE_ID)# 根据SERDE_ID获取PARAM_VALUE(列分隔符)select_PARAM_VALUE = "select PARAM_VALUE from SERDE_PARAMS where SERDE_ID="+str(result_SERDE_ID)[1:].split(",")[0]+" and PARAM_KEY='field.delim';"print(select_PARAM_VALUE)mycursor.execute(select_PARAM_VALUE)result_PARAM_VALUE = mycursor.fetchone()print(result_PARAM_VALUE)if result_PARAM_VALUE is not None:fo.write("ROW FORMAT DELIMITED\n")fo.write("FIELDS TERMINATED BY '"+str(result_PARAM_VALUE).split('\'')[1]+"'\n")# 根据SERDE_ID获取PARAM_VALUE(行分隔符)select_PARAM_HNAG = "select PARAM_VALUE from SERDE_PARAMS where SERDE_ID="+str(result_SERDE_ID)[1:].split(",")[0]+" and PARAM_KEY='line.delim';"print(select_PARAM_HNAG)mycursor.execute(select_PARAM_HNAG)RESULT_PARAM_HNAG = mycursor.fetchone()print(RESULT_PARAM_HNAG)if RESULT_PARAM_HNAG is not None:fo.write("LINES TERMINATED BY '"+str(RESULT_PARAM_HNAG).split('\'')[1]+"'\n")# 根据SD_ID和CD_ID获取输入输出格式select_table_STORE_FORMAT = "select INPUT_FORMAT from SDS where SD_ID="+SD_ID+" and CD_ID="+CD_ID+";"print(select_table_STORE_FORMAT)mycursor.execute(select_table_STORE_FORMAT)result_table_STORE_FORMAT= mycursor.fetchall()print(result_table_STORE_FORMAT)for store_format in result_table_STORE_FORMAT:if "org.apache.hadoop.hive.ql.io.orc.OrcInputFormat" in str(store_format):fo.write("STORED AS ORC;\n")elif "org.apache.hadoop.mapred.TextInputFormat" in str(store_format):fo.write("STORED AS TEXTFILE\n")#fo.write("location "+"'/tmp/hive/"+DBname.lower()+"/"+str(table_name).split('\'')[1].lower()+"';\n")elif "org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat" in str(store_format):fo.write("STORED AS PARQUET\n")fo.write("TBLPROPERTIES('parquet.compression'='snappy');\n")elif "org.apache.kudu.mapreduce.KuduTableInputFormat" in str(store_format):fo.write("STORED AS KuduTable;\n")else :fo.write("STORED AS null;\n")fo.close()
hive_create_table()
31. html2txt
import requestsurl = "https://sc.sfc.hk/TuniS/www.sfc.hk/TC/Regulatory-functions/Corporates/Takeovers-and-mergers/offer-periods"
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7","Accept-Language": "zh-CN,zh;q=0.9",# "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
}def request_get(url):"""数据请求:param url: 请求的url:return: 返回html的文本"""try:response = requests.get(url, headers=headers)with open(r"C:\luyz\temp\html_con.txt", "w") as f:f.write(response.text)return response.textexcept Exception as e:print("[ERROR]:" + str(e))exit(-1)if __name__ == '__main__':try:response_text = request_get(url)except Exception as e:print("[ERROR]:" + str(e))exit(-1)
32.xml2excel
import requests
from lxml import etree
import pandas as pd
import os
import sys
import iosys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')url = "https://www.XXX.com/images/fund/fund_2697.xml"
headers = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7","Accept-Language": "zh-CN,zh;q=0.9",# "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0",
}def save_data(data, columns, excel_path, sheet_name):df = pd.DataFrame(data, columns=columns)if not os.path.exists(excel_path):df.to_excel(excel_path, sheet_name=sheet_name, index=False)else:with pd.ExcelWriter(excel_path, engine='openpyxl', mode='a') as writer:df.to_excel(writer, sheet_name=sheet_name, index=False)def xml2list(response_text):# 创建ElementTree对象并解析XML文档root = etree.fromstring(response_text.encode('utf-8'))excel_columns = ['Fund_code','shortname','Fund_name','Fund_investtype','Fund_desc','Fund_qcode','Fund_currency','Fund_trusteefee','Fund_type','Fund_manager','Fund_objective','Fund_trustee','Fund_risklevel','Fund_benmark','Fund_riskreturn','Fund_eatablishment','Fund_endtime','Fund_riskmanagement','Fund_issuedate','Fund_customertyp','Fund_administration','Fund_subscription','Fund_management','Fund_IP','Fund_sp','Fund_hotfund','Fund_scope']excel_data = []# 使用XPath定位元素并打印内容funds = root.xpath('//Fund')for fund in funds:excel_row_data = []for column_index in range(len(excel_columns)):if column_index != len(excel_columns) - 1:excel_row_data.extend(fund.xpath('@' + str(excel_columns[column_index])))else:excel_row_data.extend(fund.xpath(str(excel_columns[column_index]) + '/text()'))"""excel_row_data.extend(fund.xpath('@Fund_code'))excel_row_data.extend(fund.xpath('Fund_scope/text()'))"""excel_data.append(excel_row_data)return excel_columns, excel_dataif __name__ == '__main__':try:excel_path = "C:/luyz/temp/20231207/xml.xlsx"sheet_name = 'result_data'response_text = requests.get(url, headers=headers, timeout=(21, 300)).content.decode("utf8")excel_columns, excel_data = xml2list(response_text)print("=================excel_columns=======================")print(excel_columns)print("=================excel_data==========================")for x in excel_data:print(x)print("=====================================================")# 文件存在,则删除if os.path.exists(excel_path):os.remove(excel_path)# 保存文件save_data(excel_data, excel_columns, excel_path, sheet_name)print("save_data is end.")except Exception as e:print("[ERROR]:" + str(e))exit(-1)
33.
配置表结构
-- Create table
create table REPKETTLE.CTL_B2B_CONFIG
(filename VARCHAR2(100) not null,src_db_name VARCHAR2(100) not null,src_table VARCHAR2(50) not null,src_query VARCHAR2(4000) not null,trg_db_name VARCHAR2(200) not null,trg_table VARCHAR2(200) not null,trg_writemode VARCHAR2(2) not null,truncate_sql VARCHAR2(4000) not null,load_type VARCHAR2(2) not null,trg_schema VARCHAR2(50)
);
-- Add comments to the columns
comment on column REPKETTLE.CTL_B2B_CONFIG.filenameis '下载表的系统名+表名(该字段是下载表的主键)';
comment on column REPKETTLE.CTL_B2B_CONFIG.src_db_nameis '源数据库名称,需使用ctl_db_info定义的db_name';
comment on column REPKETTLE.CTL_B2B_CONFIG.src_tableis '源表名';
comment on column REPKETTLE.CTL_B2B_CONFIG.src_queryis '导出语句';
comment on column REPKETTLE.CTL_B2B_CONFIG.trg_db_nameis '目标数据库名称,需使用ctl_db_info定义的db_name';
comment on column REPKETTLE.CTL_B2B_CONFIG.trg_tableis '目标表名';
comment on column REPKETTLE.CTL_B2B_CONFIG.trg_writemodeis 'I:为增量模式,F:为全量模式(标识作用)';
comment on column REPKETTLE.CTL_B2B_CONFIG.truncate_sqlis '删数语句';
comment on column REPKETTLE.CTL_B2B_CONFIG.load_typeis '加载类型;1-O2M;2-O2O;3-M2O';
comment on column REPKETTLE.CTL_B2B_CONFIG.trg_schemais '目标表模式';-- Create table
create table REPKETTLE.CTL_DB_INFO
(db_name VARCHAR2(50),db_type VARCHAR2(1) default '0',db_user VARCHAR2(100),db_passwd VARCHAR2(100),db_host VARCHAR2(100),db_port INTEGER,db_instant VARCHAR2(100),base_passad VARCHAR2(100),charset VARCHAR2(50)
);
-- Add comments to the table
comment on table REPKETTLE.CTL_DB_INFOis '数据库配置';
-- Add comments to the columns
comment on column REPKETTLE.CTL_DB_INFO.db_nameis '数据库名';
comment on column REPKETTLE.CTL_DB_INFO.db_typeis '数据库类型-0:oracle,1:mysql,默认为0';
comment on column REPKETTLE.CTL_DB_INFO.db_useris '登陆用户';
comment on column REPKETTLE.CTL_DB_INFO.db_passwdis '登录密码(base64加密之后)';
comment on column REPKETTLE.CTL_DB_INFO.db_hostis '数据库IP';
comment on column REPKETTLE.CTL_DB_INFO.db_portis '数据端口号';
comment on column REPKETTLE.CTL_DB_INFO.db_instantis '实例名';
comment on column REPKETTLE.CTL_DB_INFO.base_passadis '存放密码-备用';
comment on column REPKETTLE.CTL_DB_INFO.charsetis '数据库字符集编码';代码
# -*- coding:utf-8 -*-# 安装依赖
# pip install PyMySQL-0.9.3-py2.py3-none-any.whlimport sys
import os
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
sys.path.append(os.path.abspath(sys.path[0]) + os.path.sep + "../utils")
import logging.config
import cx_Oracle
import pymysql
import datetime
import traceback
import timeimport ArgvParser
import GetOracleConfig
import GetConfig
import GetParamsConfig
import LogPathDao
import QueryFromArgs
import QueryFromGlobalVal#类似nvl()函数
def nvlx(x, y):if x is None:return yelse:return xdef close_conn(conn,cursor):cursor.close()conn.close()#获取数据库连接
def get_con(user, password, db_host, db_port, db_instant, db_charset,db_type,logger):try:con=Noneif db_type == '0':dsn = cx_Oracle.makedsn(db_host, db_port, db_instant)con = cx_Oracle.connect(user, password, dsn)if db_type == '1':con = pymysql.Connect(host=db_host,port=db_port,user=user,password=password,database=db_instant,charset=db_charset)logger.info("user: {}, password: {}, db_host: {}, db_port: {}, db_instant: {}, db_charset: {},db_type: {}".format(user, "******", db_host, db_port, db_instant, db_charset,db_type))return conexcept cx_Oracle.DatabaseError:traceback.print_exc()os._exit(1)#读取数据,加载数据以及字段
def read_from_db(conn, sql, logger):try:logger.info("execute Read SQL: {}".format(sql))cursor = conn.cursor()cursor.execute(sql)db_columns = []db_data = []for column in cursor.description:db_columns.append(column[0])#data_from_oracle = cursor.fetchall()logger.info("Get {} columns".format(db_columns))for row in cursor:db_data.append(row)logger.info("Get total {} rows".format(len(db_data)))close_conn(conn,cursor)logger.info("Connect to DB closed.")return db_columns,db_dataexcept Exception:exe = traceback.format_exc()print (exe)close_conn(conn,cursor)sys.exit(1)#获取插入表的sql语句
def get_insert_sql(db_columns, db_data, trg_table, db_type, logger):if len(db_data) == 0:return None#mysql %s,%S#Oracle :1,:2tmp_key=''tmp_value=''for i in range(1, len(db_columns)+1):tmp_value+=':'+str(i)+','tmp_key+="\""+db_columns[i-1]+"\","value=tmp_value[:-1]key=tmp_key[:-1]insert_sql=Noneif db_type == '1':insert_sql = f"INSERT INTO {trg_table} (`{'`,`'.join(db_columns)}`) VALUES ({','.join(['%s']*len(db_columns))})"if db_type == '0':insert_sql = f"INSERT INTO {trg_table} ({key}) VALUES ({value})"logger.info("Insert SQL: {}".format(insert_sql))return insert_sql#执行sql写入数据
def write_to_db(conn, db_columns, db_data, insert_sql, truncate_sql, logger):try:logger.info("Delete SQL: {}".format(truncate_sql))cursor = conn.cursor()cursor.execute(truncate_sql)logger.info("Truncate table success!")effectRow = 0if insert_sql is not None:#10000条提交一次for i in range(0, len(db_data), 10000):start = time.time()db_data_1w = db_data[i: i + 10000]logger.info("Write SQL: {}".format(insert_sql))#logger.info(db_data_1w)cursor.executemany(insert_sql, db_data_1w)#cursor.execute(sql)conn.commit()effectRow += cursor.rowcount#time.sleep(300)end = time.time()running_time = end-startlogger.info('Write data is : %.5f sec' %running_time)logger.info("Write data to table success! Effect row: {}".format(effectRow))else:logger.info("Total length of data is zero, no insert!")close_conn(conn,cursor)logger.info("Connect to DB closed.")return effectRowexcept Exception:exe = traceback.format_exc()print (exe)close_conn(conn,cursor)sys.exit(1)def audit(s_retval,t_retval):s_retval = nvlx(s_retval,0)t_retval = nvlx(t_retval,0)logger.info("s_retval: {}".format(s_retval))logger.info("t_retval: {}".format(t_retval))vn_biasval = abs(s_retval - t_retval)if abs(vn_biasval) > 0: # Decimallogger.info("This audit-rule is not passed!!!")sys.exit(1)else:logger.info("This audit-rule is passed")if __name__ == '__main__':parentdir = os.path.abspath(sys.path[0] + os.path.sep + "..")rootpath = os.path.abspath(parentdir + os.path.sep + "..")confpath = rootpath + "/config/config.ini"# 获取配置文件配置信息GetC = GetConfig.GetConfig(confpath)username, password, url, url2 = GetC.config()# 返回参数字典GetParamsC = GetParamsConfig.GetParamsConfig(username, password, url, url2)argv_type, globaldict = GetParamsC.getconfig()# 构建传递参数ArgP = ArgvParser.ArgvParser(1)argvdict = ArgP.parse(argv_type)# 将tablename计入参数与类型字典argv_type["filename"] = "string"sqlcommand = '''SELECT T.SRC_QUERY,T.TRUNCATE_SQL,T.TRG_SCHEMA||'.'|| T.TRG_TABLE AS TRG_TABLE,SDB.DB_USER AS SDB_USER,--SDB.DB_PASSWD AS SDB_PASSWD,UTL_RAW.CAST_TO_VARCHAR2(UTL_ENCODE.BASE64_DECODE(UTL_RAW.CAST_TO_RAW(SDB.DB_PASSWD))) AS SDB_PASSWD,SDB.DB_HOST AS SDB_HOST,SDB.DB_PORT AS SDB_PORT,SDB.DB_INSTANT AS SDB_INSTANT,SDB.DB_TYPE AS SDB_TYPE,SDB.CHARSET AS SDB_CHARSET,TDB.DB_USER AS TDB_USER,--TDB.DB_PASSWD AS TDB_PASSWD,UTL_RAW.CAST_TO_VARCHAR2(UTL_ENCODE.BASE64_DECODE(UTL_RAW.CAST_TO_RAW(TDB.DB_PASSWD))) AS TDB_PASSWD,TDB.DB_HOST AS TDB_HOST,TDB.DB_PORT AS TDB_PORT,TDB.DB_INSTANT AS TDB_INSTANT,TDB.DB_TYPE AS TDB_TYPE,TDB.CHARSET AS TDB_CHARSETFROM REPKETTLE.CTL_B2B_CONFIG TJOIN REPKETTLE.CTL_DB_INFO SDBON T.SRC_DB_NAME = SDB.DB_NAMEJOIN REPKETTLE.CTL_DB_INFO TDBON T.TRG_DB_NAME = TDB.DB_NAMEWHERE UPPER(FILENAME) = UPPER('{filename}') '''sql = sqlcommand.format(filename=argvdict["filename"])GetOracleC = GetOracleConfig.GetOracleConfig(username, password, url, url2, sql)diction = GetOracleC.getconfig()# 用全局变量替换掉字段里的$${.*}QueryFGL = QueryFromGlobalVal.QueryFromGlobalVal(globaldict)for key, value in list(diction.items()):if type(value) == str:diction[key] = QueryFGL.query(value)# 获取TRG_TABLEtrg_table = diction["TRG_TABLE"]# 对query字段做处理QueryFA = QueryFromArgs.QueryFromArgs(argvdict, argv_type)src_query = QueryFA.query(diction["SRC_QUERY"])truncate_sql = QueryFA.query(diction["TRUNCATE_SQL"])# 获取logging模块的loggerLogDao = LogPathDao.LogPathDao(argvdict["filename"])logconf, logpath = LogDao.getpath()logging.config.fileConfig(logconf, defaults={'logdir': logpath})logger = logging.getLogger('hivelog')try:#1.获取数据库连接logger.info("Source Conn")sconn = get_con(diction["SDB_USER"],diction["SDB_PASSWD"],diction["SDB_HOST"],diction["SDB_PORT"],diction["SDB_INSTANT"],diction["SDB_CHARSET"],diction["SDB_TYPE"],logger)logger.info("Trg Conn")tconn = get_con(diction["TDB_USER"],diction["TDB_PASSWD"],diction["TDB_HOST"],diction["TDB_PORT"],diction["TDB_INSTANT"],diction["TDB_CHARSET"],diction["TDB_TYPE"],logger)#2.读取数据,加载数据以及字段db_columns,db_data = read_from_db(sconn, src_query, logger)#3.获取插入表的sql语句insert_sql = get_insert_sql(db_columns, db_data, trg_table, diction["TDB_TYPE"], logger)#4.执行sql写入数据effectRow = write_to_db(tconn, db_columns, db_data, insert_sql, truncate_sql, logger)#5.稽核audit(len(db_data),effectRow)except Exception:exe = traceback.print_exc()logger.error("Error occurred!")logger.error(str(exe))os._exit(1)
相关文章:
常用命令之LinuxOracleHivePython
1. 用户改密 passwd app_adm chage -l app_adm passwd -x 90 app_adm -> 执行操作后,app_adm用户的密码时间改为90天有效期--查看该euser用户过期信息使用chage命令 --chage的参数包括 ---m 密码可更改的最小天数。为零时代表任何时候都可以更改密码。 ---M 密码…...

从dos上传shell脚本文件到Linux、麒麟执行报错“/bin/bash^M:解释器错误:没有那个文件或目录”
[rootkylin tmp]#./online_update_wars-1.3.0.sh ba51:./online_update_wars-1.3.0.sh:/bin/bash^M:解释器错误:没有那个文件或目录 使用scp命令上传文件到麒麟系统,执行shell脚本时报错 “/bin/bash^M:解释器错误:没有那个文件或目录” 解决方法: 执行…...

使用 Go 实现将任何网页转化为 PDF
在许多应用场景中,可能需要将网页内容转化为 PDF 格式,比如保存网页内容、生成报告、或者创建网站截图。使用 Go 编程语言,结合一些现有的库,可以非常方便地实现这一功能。本文将带你一步一步地介绍如何使用 Go 语言将任何网页转换…...

文件操作和IO
目录 一. 文件预备知识 1. 硬盘 2. 文件 (1) 概念 (2) 文件路径 (3) 文件类型 二. 文件操作 1. 文件系统操作 [1] File常见的构造方法 [2] File的常用方法 [3] 查看某目录下所有的目录和文件 2. 文件内容操作 (1) 打开文件 (2) 关闭文件 (3) 读文件 (4) 写文件 …...

【C++滑动窗口】1248. 统计「优美子数组」|1623
本文涉及的基础知识点 C算法:滑动窗口及双指针总结 LeetCode1248. 统计「优美子数组」 给你一个整数数组 nums 和一个整数 k。如果某个连续子数组中恰好有 k 个奇数数字,我们就认为这个子数组是「优美子数组」。 请返回这个数组中 「优美子数组」 的数…...

C语言导航 4.1语法基础
第四章 顺序结构程序设计 第一节 语法基础 语句概念 语句详解 程序详解 4.1.1语句概念 说明:构成高级语言源程序的基本单位。 特征:在C语言中语句以分号作为结束标志。 分类: (1)简单语句:空语句、…...

使用 Python 和 Py2Neo 构建 Neo4j 管理脚本
Neo4j 是一个强大的图数据库,适合处理复杂的关系型数据。借助 Python 的 py2neo 库,我们可以快速实现对 Neo4j 数据库的管理和操作。本文介绍一个功能丰富的 Python 脚本,帮助用户轻松管理 Neo4j 数据库,包含启动/停止服务、清空数…...

Centos 7 安装wget
Centos 7 安装wget 最小化安装Centos 7 的话需要上传wget rpm包之后再路径下安装一下。rpm包下载地址(http://mirrors.163.com/centos/7/os/x86_64/Packages/) 1、使用X-ftp 或者WinSCP等可以连接上传的软件都可以首先连接服务器,这里我用的…...

定时器的小应用
第一个项目 第一步,RCC开启时钟,这个基本上每个代码都是第一步,不用多想,在这里打开时钟后,定时器的基准时钟和整个外设的工作时钟就都会同时打开了 RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2, ENABLE);第二步&…...

linux企业中常用NFS、ftp服务
1.静态ip配置 修改ip地址为静态vim /etc/sysconfig/network-scripts/ifcfg-enxxx BOOTPROTO"static" IPADDR192.168.73.10 GATEWAY192.168.73.2 # 该配置与虚拟机网关一致 NETMASK255.255.255.0重启网卡:systemctl restart network.service ping不通域名…...

数据结构与算法分析模拟试题及答案5
模拟试题(五) 一、单项选择题(每小题 2 分,共20分) (1)队列的特点是( )。 A)先进后出 B)先进先出 C)任意位置进出 D࿰…...

.NET 9.0 中 System.Text.Json 的全面使用指南
以下是一些 System.Text.Json 在 .NET 9.0 中的使用方式,包括序列化、反序列化、配置选项等,并附上输出结果。 基本序列化和反序列化 using System; using System.Text.Json; public class Program {public class Person{public string Name { get; se…...

Python自动检测requests所获得html文档的编码
使用chardet库自动检测requests所获得html文档的编码 使用requests和BeautifulSoup库获取某个页面带来的乱码问题 使用requests配合BeautifulSoup库,可以轻松地从网页中提取数据。但是,当网页返回的编码格式与Python默认的编码格式不一致时,…...

11.12机器学习_特征工程
四 特征工程 1 特征工程概念 特征工程:就是对特征进行相关的处理 一般使用pandas来进行数据清洗和数据处理、使用sklearn来进行特征工程 特征工程是将任意数据(如文本或图像)转换为可用于机器学习的数字特征,比如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。 …...

RAG经验论文《FACTS About Building Retrieval Augmented Generation-based Chatbots》笔记
《FACTS About Building Retrieval Augmented Generation-based Chatbots》是2024年7月英伟达的团队发表的基于RAG的聊天机器人构建的文章。 这篇论文在待读列表很长时间了,一直没有读,看题目以为FACTS是总结的一些事实经验,阅读过才发现FAC…...

【配置后的基本使用】CMake基础知识
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀各种软件安装与配置_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1.…...
ollama+springboot ai+vue+elementUI整合
1. 下载安装ollama (1) 官网下载地址:https://github.com/ollama/ollama 这里以window版本为主,下载链接为:https://ollama.com/download/OllamaSetup.exe。 安装完毕后,桌面小图标有一个小图标,表示已安装成功&…...

【项目开发】理解SSL延迟:为何HTTPS比HTTP慢?
未经许可,不得转载。 文章目录 前言HTTP与HTTPS的耗时差异TCP握手HTTPS的额外步骤:SSL握手使用curl测量SSL延迟性能与安全的权衡前言 在互联网发展的早期阶段,Netscape公司设计了SSL(Secure Sockets Layer)协议,为网络通信提供加密和安全性。有人曾提出一个大胆的设想:…...

2.STM32之通信接口《精讲》之USART通信
有关通信详解进我主页观看其他文章!【免费】SPIIICUARTRS232/485-详细版_UART、IIC、SPI资源-CSDN文库 通过以上可以看出。根据电频标准,可以分为TTL电平,RS232电平,RS485电平,这些本质上都属于串口通信。有区别的仅是…...

Bootstrap和jQuery开发案例
目录 1. Bootstrap和jQuery简介及优势2. Bootstrap布局与组件示例:创建一个响应式的表单界面 3. jQuery核心操作与事件处理示例:使用jQuery为表单添加交互 4. Python后端实现及案例代码案例 1:用户登录系统Flask后端代码前端代码 5. 设计模式…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...
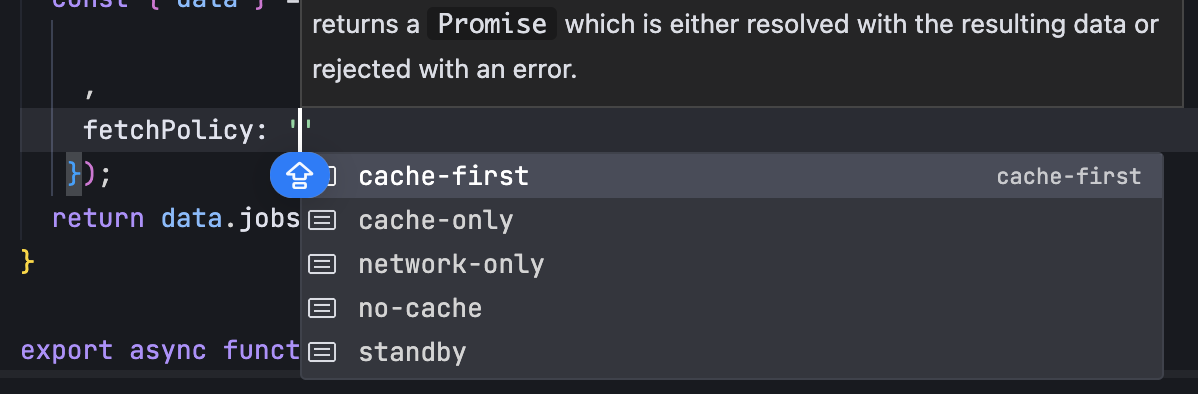
GraphQL 实战篇:Apollo Client 配置与缓存
GraphQL 实战篇:Apollo Client 配置与缓存 上一篇:GraphQL 入门篇:基础查询语法 依旧和上一篇的笔记一样,主实操,没啥过多的细节讲解,代码具体在: https://github.com/GoldenaArcher/graphql…...