智能网页内容截图工具:AI助力内容提取与可视化
我们每天都会接触到大量的网页内容。然而,如何从这些内容中快速提取关键信息,并有效地进行整理和分享,一直是困扰我们的问题。本文将介绍一款我近期完成的基于AI技术的智能网页内容截图工具,它能够自动分析网页内容,截取重要区域,为用户提供便捷的内容提取与可视化服务。
一、项目背景与价值
在撰写文章或进行学术研究时,我们常常需要从网页中提取关键信息。然而,许多网页内容丰富,需要截图的内容较多,手动截图不仅费时费力,还容易遗漏重要信息。为了解决这一问题,我们开发了一款智能网页内容截图工具,通过AI技术自动分析网页内容,并截取重要区域,提高内容提取的效率和准确性。
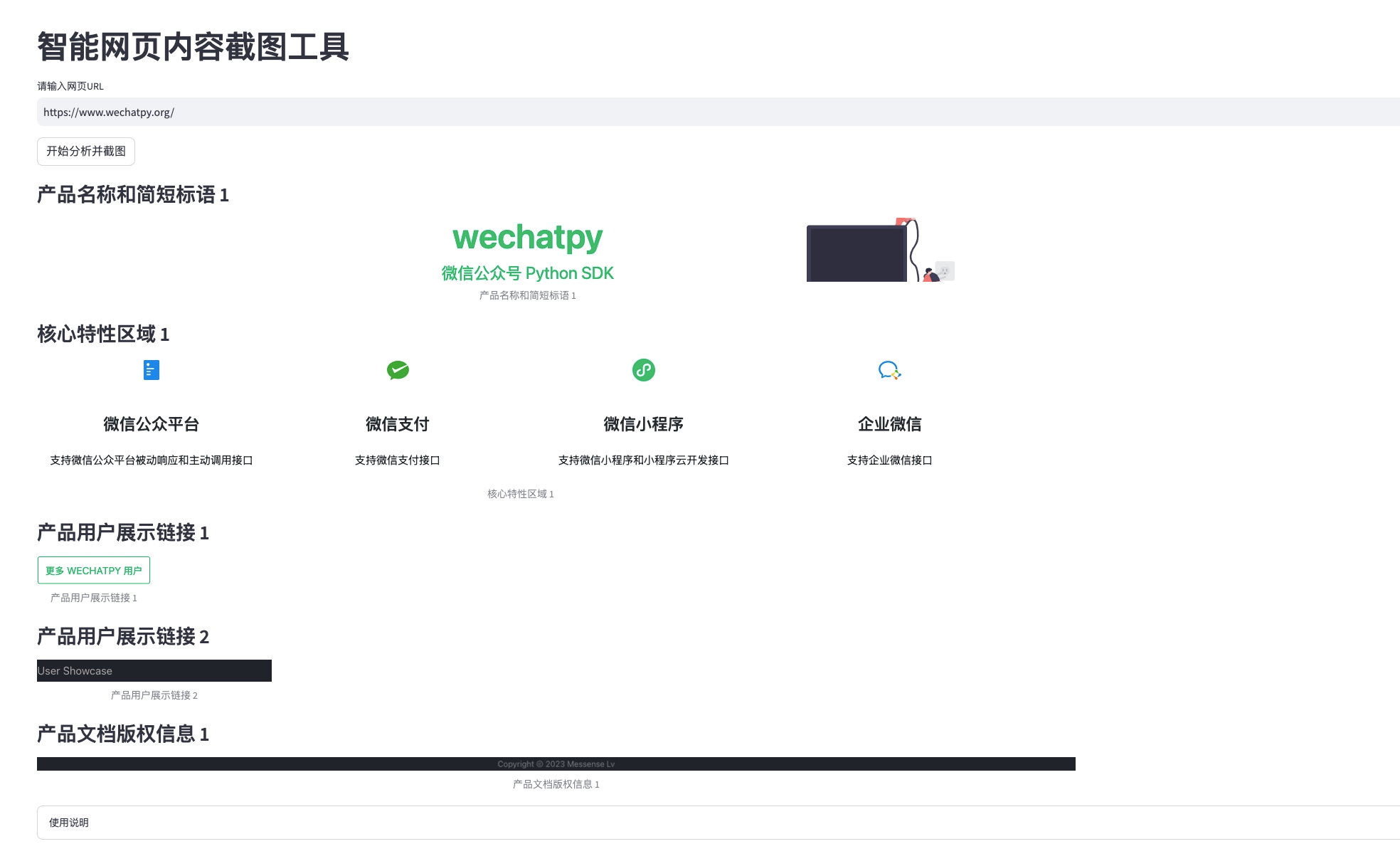

二、技术实现
-
技术选型
本项目采用Python编程语言,结合Streamlit、Playwright、Pillow等库实现。Streamlit用于构建交互式Web应用,Playwright用于网页自动化操作,Pillow用于图像处理。
-
核心逻辑
(1)数据预处理:从用户输入的URL获取网页内容,并进行初步处理,如去除HTML标签、提取文本等。
(2)核心业务逻辑:使用AI技术分析网页内容,识别关键区域,并生成JSON格式的区域列表。
(3)结果处理:根据区域列表,使用Playwright截取对应区域的截图,并展示给用户。
-
关键设计决策
(1)使用Playwright进行网页自动化操作,实现快速、稳定的内容提取。
(2)结合Pillow库进行图像处理,确保截图质量。
(3)采用Streamlit构建交互式Web应用,提高用户体验。
三、核心逻辑说明:
class AnalyzeWebPage(Action):
"""分析网页内容的动作"""
PROMPT_TEMPLATE: ClassVar[str] = """分析以下HTML内容,识别包含关键商业和产品信息的区域。将较长的内容区域分成多个独立的小区块。
重点关注以下内容(每个区域建议不超过一屏幕高度):
1. 产品标题区域:
- 产品名称和简短标语
- 一句话价值主张
2. 核心特性区域:
- 识别所有产品功能或特点
- 每个技术优势说明
- 所有应用场景
3. 产品亮点:
- 所有产品优势点
- 所有核心功能说明
- 所有用户价值点
请严格按照以下JSON格式返回结果,不要包含任何其他说明文字:
[
{{
"description": "产品名称和简短标语",
"selector": "h1.product-title"
}},
{{
"description": "AI自动操作特性介绍",
"selector": "div.feature-block:nth-child(1)"
}}
]
注意:
- 必须返回JSON数组格式
- 每个区域必须包含 description 和 selector 两个字段
- 不要返回任何其他格式的内容
- 不要包含任何解释或说明文字
HTML内容:
{html_content}
"""
REVIEW_PROMPT: ClassVar[str] = """作为网页内容分析专家,请仔细审查以下已识别的内容区域,并检查是否有遗漏或不准确的地方。
当前已识别的区域:
{areas}
原始HTML内容:
{html_content}
请重点检查:
1. 产品核心信息是否完整(标题、简介、价格等)
2. 产品特性和功能说明是否完整
3. 技术规格和参数是否完整
4. 使用场景和用户价值是否完整
5. 产品优势和亮点是否完整
如果发现遗漏,请严格按照以下JSON格式返回完整的区域列表:
[
{{
"description": "区域描述",
"selector": "CSS选择器"
}}
]
如果当前区域划分已经完整,直接返回"PASS"。
注意:
- 必须返回JSON数组或"PASS"
- 不要返回任何其他格式的内容
- 不要包含任何解释或说明文字
"""
name: str = "AnalyzeWebPage"
async def run(self, html_content: str) -> list:
"""实现网页分析逻辑"""
try:
# 使用模板分析页面内容
prompt = self.PROMPT_TEMPLATE.format(html_content=html_content)
logger.debug(f"发送给AI的提示: {prompt[:200]}...")
try:
# 添加明确的格式要求
response = await self._aask(prompt + "\n请严格按照JSON数组格式返回结果,不要包含任何其他内容。")
logger.debug(f"AI的原始响应: {response}")
except Exception as e:
logger.error(f"调用AI接口失败: {str(e)}")
return self.get_default_areas()
# 尝试从响应中提取JSON部分
areas = None
try:
# 尝试直接解析
if response and response.strip().startswith("["):
areas = json.loads(response.strip())
# 尝试从代码块中提取
elif response and "```" in response:
code_blocks = response.split("```")
for block in code_blocks:
block = block.strip()
if block.startswith("json"):
block = block[4:].strip()
try:
parsed = json.loads(block)
if isinstance(parsed, list):
areas = parsed
break
except:
continue
if not areas:
logger.warning("无法从响应中提取有效的JSON,使用默认区域")
return self.get_default_areas()
except json.JSONDecodeError as e:
logger.error(f"JSON解析错误: {str(e)}")
logger.error(f"尝试解析的文本: {response}")
return self.get_default_areas()
except Exception as e:
logger.error(f"解析过程中的其他错误: {str(e)}")
logger.error(f"错误类型: {type(e)}")
logger.error(f"出错时的响应内容: {response}")
return self.get_default_areas()
# 确保areas不为None后再进行审查
try:
logger.info("开始审查区域完整性...")
reviewed_areas = await self.review_areas(html_content, areas)
logger.info(f"审查完成,最终区域数量: {len(reviewed_areas)}")
return reviewed_areas
except Exception as e:
logger.error(f"区域审查失败: {str(e)}")
return areas # 如果审查失败,返回原始区域
except Exception as e:
logger.exception(f"分析页面失败: {str(e)}")
# 如果前面的步骤都失败了,返回默认区域
logger.warning("使用默认区域")
return self.get_default_areas()
这是最主要的代码部分,用来分析网页内容,该智能体会根据playwright抓取到的网页源码,分析其中的内容部分,做一遍阅读理解,找到内容的重点,然后,选出内容重点所在页面元素的所在父级元素,调用相应的类库,把它渲染成图片,并保存下来。
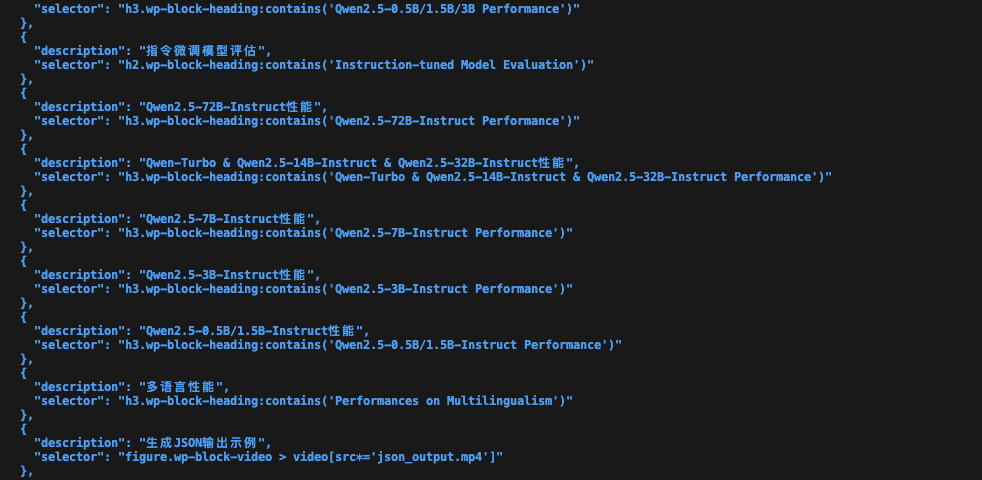
我还加了一个“审阅选取的区域是否合理完整”的智能体,以及用来截图的工具类。
最后,通过streamlit把结果展示出来,这样,我可以通过预览来决定,那些截图是我想要,我直接用就可以了。
这款工具不仅能够提高内容提取的效率和准确性,还能为用户提供便捷的内容可视化服务。奇奇怪怪的小工具又增加了!但话不多说,你说它是不是也挺使用的啊?
本文由 mdnice 多平台发布
相关文章:
智能网页内容截图工具:AI助力内容提取与可视化
我们每天都会接触到大量的网页内容。然而,如何从这些内容中快速提取关键信息,并有效地进行整理和分享,一直是困扰我们的问题。本文将介绍一款我近期完成的基于AI技术的智能网页内容截图工具,它能够自动分析网页内容,截…...

Axure设计之文本编辑器制作教程
文本编辑器是一个功能强大的工具,允许用户在图形界面中创建和编辑文本的格式和布局,如字体样式、大小、颜色、对齐方式等,在Web端实际项目中,文本编辑器的使用非常频繁。以下是在Axure中模拟web端富文本编辑器,来制作文…...

【MyBatis源码】深入分析TypeHandler原理和源码
🎮 作者主页:点击 🎁 完整专栏和代码:点击 🏡 博客主页:点击 文章目录 原始 JDBC 存在的问题自定义 TypeHandler 实现TypeHandler详解BaseTypeHandler类TypeReference类型参考器43个类型处理器类型注册表&a…...

号卡分销系统,号卡系统,物联网卡系统源码安装教程
号卡分销系统,号卡系统,物联网卡系统,,实现的高性能(PHP协程、PHP微服务)、高灵活性、前后端分离(后台),PHP 持久化框架,助力管理系统敏捷开发,长期持续更新中。 主要特性 基于Auth验证的权限…...

常用命令之LinuxOracleHivePython
1. 用户改密 passwd app_adm chage -l app_adm passwd -x 90 app_adm -> 执行操作后,app_adm用户的密码时间改为90天有效期--查看该euser用户过期信息使用chage命令 --chage的参数包括 ---m 密码可更改的最小天数。为零时代表任何时候都可以更改密码。 ---M 密码…...

从dos上传shell脚本文件到Linux、麒麟执行报错“/bin/bash^M:解释器错误:没有那个文件或目录”
[rootkylin tmp]#./online_update_wars-1.3.0.sh ba51:./online_update_wars-1.3.0.sh:/bin/bash^M:解释器错误:没有那个文件或目录 使用scp命令上传文件到麒麟系统,执行shell脚本时报错 “/bin/bash^M:解释器错误:没有那个文件或目录” 解决方法: 执行…...

使用 Go 实现将任何网页转化为 PDF
在许多应用场景中,可能需要将网页内容转化为 PDF 格式,比如保存网页内容、生成报告、或者创建网站截图。使用 Go 编程语言,结合一些现有的库,可以非常方便地实现这一功能。本文将带你一步一步地介绍如何使用 Go 语言将任何网页转换…...

文件操作和IO
目录 一. 文件预备知识 1. 硬盘 2. 文件 (1) 概念 (2) 文件路径 (3) 文件类型 二. 文件操作 1. 文件系统操作 [1] File常见的构造方法 [2] File的常用方法 [3] 查看某目录下所有的目录和文件 2. 文件内容操作 (1) 打开文件 (2) 关闭文件 (3) 读文件 (4) 写文件 …...

【C++滑动窗口】1248. 统计「优美子数组」|1623
本文涉及的基础知识点 C算法:滑动窗口及双指针总结 LeetCode1248. 统计「优美子数组」 给你一个整数数组 nums 和一个整数 k。如果某个连续子数组中恰好有 k 个奇数数字,我们就认为这个子数组是「优美子数组」。 请返回这个数组中 「优美子数组」 的数…...

C语言导航 4.1语法基础
第四章 顺序结构程序设计 第一节 语法基础 语句概念 语句详解 程序详解 4.1.1语句概念 说明:构成高级语言源程序的基本单位。 特征:在C语言中语句以分号作为结束标志。 分类: (1)简单语句:空语句、…...

使用 Python 和 Py2Neo 构建 Neo4j 管理脚本
Neo4j 是一个强大的图数据库,适合处理复杂的关系型数据。借助 Python 的 py2neo 库,我们可以快速实现对 Neo4j 数据库的管理和操作。本文介绍一个功能丰富的 Python 脚本,帮助用户轻松管理 Neo4j 数据库,包含启动/停止服务、清空数…...

Centos 7 安装wget
Centos 7 安装wget 最小化安装Centos 7 的话需要上传wget rpm包之后再路径下安装一下。rpm包下载地址(http://mirrors.163.com/centos/7/os/x86_64/Packages/) 1、使用X-ftp 或者WinSCP等可以连接上传的软件都可以首先连接服务器,这里我用的…...

定时器的小应用
第一个项目 第一步,RCC开启时钟,这个基本上每个代码都是第一步,不用多想,在这里打开时钟后,定时器的基准时钟和整个外设的工作时钟就都会同时打开了 RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2, ENABLE);第二步&…...

linux企业中常用NFS、ftp服务
1.静态ip配置 修改ip地址为静态vim /etc/sysconfig/network-scripts/ifcfg-enxxx BOOTPROTO"static" IPADDR192.168.73.10 GATEWAY192.168.73.2 # 该配置与虚拟机网关一致 NETMASK255.255.255.0重启网卡:systemctl restart network.service ping不通域名…...

数据结构与算法分析模拟试题及答案5
模拟试题(五) 一、单项选择题(每小题 2 分,共20分) (1)队列的特点是( )。 A)先进后出 B)先进先出 C)任意位置进出 D࿰…...

.NET 9.0 中 System.Text.Json 的全面使用指南
以下是一些 System.Text.Json 在 .NET 9.0 中的使用方式,包括序列化、反序列化、配置选项等,并附上输出结果。 基本序列化和反序列化 using System; using System.Text.Json; public class Program {public class Person{public string Name { get; se…...

Python自动检测requests所获得html文档的编码
使用chardet库自动检测requests所获得html文档的编码 使用requests和BeautifulSoup库获取某个页面带来的乱码问题 使用requests配合BeautifulSoup库,可以轻松地从网页中提取数据。但是,当网页返回的编码格式与Python默认的编码格式不一致时,…...

11.12机器学习_特征工程
四 特征工程 1 特征工程概念 特征工程:就是对特征进行相关的处理 一般使用pandas来进行数据清洗和数据处理、使用sklearn来进行特征工程 特征工程是将任意数据(如文本或图像)转换为可用于机器学习的数字特征,比如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。 …...

RAG经验论文《FACTS About Building Retrieval Augmented Generation-based Chatbots》笔记
《FACTS About Building Retrieval Augmented Generation-based Chatbots》是2024年7月英伟达的团队发表的基于RAG的聊天机器人构建的文章。 这篇论文在待读列表很长时间了,一直没有读,看题目以为FACTS是总结的一些事实经验,阅读过才发现FAC…...

【配置后的基本使用】CMake基础知识
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀各种软件安装与配置_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1.…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案
yuzu模拟器完整指南:在电脑上畅玩Switch游戏的终极解决方案 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上体验任天堂Switch游戏的魅力吗?yuzu模拟器正是你寻找的完美答案。作为…...

claude code用户如何迁移到taotoken解决封号与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何迁移到 Taotoken 解决封号与 Token 不足问题 应用场景类,针对 Claude Code 用户常遇封号与 Token…...