【Python · PyTorch】卷积神经网络 CNN(LeNet-5网络)
【Python · PyTorch】卷积神经网络 CNN(LeNet-5网络)
- 1. LeNet-5网络
- ※ LeNet-5网络结构
- 2. 读取数据
- 2.1 Torchvision读取数据
- 2.2 MNIST & FashionMNIST 下载解包读取数据
- 2. Mnist
- ※ 训练 LeNet5 预测分类
- 3. EMnist
- ※ 训练 LeNet5 预测分类
- 4. FashionMnist
- ※ 训练 LeNet5 预测分类
- 5. CIFAR-10
- ※ 训练 LeNet5 预测分类
1. LeNet-5网络
标志:经典的卷积神经网络
LeNet-5由Yann Lecun 提出,是一种经典的卷积神经网络,是现代卷积神经网络的起源之一。
Yann将该网络用于邮局的邮政的邮政编码识别,有着良好的学习和识别能力。
※ LeNet-5网络结构
LeNet-5具有一个输入层,两个卷积层,两个池化层,3个全连接层(其中最后一个全连接层为输出层)。

下面我们以灰度值黑白图像为例,描述LeNet网络结构,其中:”接纳“表示”中间层输入“,”传递“表示”中间层输出“。
层次结构:
- 输入层 (Input Layer)
- 输入尺寸:32 × 32 数据图
- 灰度值:0 ~ 255(一般进行预处理)
- 传递通道数:1
- 卷积层 C1 (Convolutional Layer c1)
- 卷积核尺寸:5 × 5
- 卷积核数量:6
- 步长:1
- 填充:0
- 传递尺寸:28 × 28 特征图
- 传递通道数:6
- 子采样/池化层 S2 (Subsampling Layer S2)
- 类型:MaxPooling
- 窗口尺寸:2 × 2
- 步长:2
- 传递尺寸:14 × 14 特征图
- 传递通道数:6
- 卷积层 C3 (Convolutional Layer c3)
- 卷积核尺寸:5 × 5
- 卷积核数量:16
- 步长:1
- 填充:0
- 传递尺寸:10 × 10 特征图
- 传递通道数:16
- 子采样/池化层 S4 (Subsampling Layer S4)
- 类型:MaxPooling
- 窗口尺寸:2 × 2
- 步长:2
- 传递尺寸:5 × 5 特征图
- 传递通道数:6
- 全连接层 C5 (Fully Connected Layer C5)
- 展平尺寸:400 ( 25 * 16 )
- 传递尺寸:120
- 全连接层 C6 (Fully Connected Layer C6)
- 接纳尺寸:120
- 传递尺寸:84
- 输出层 (Output Layer)
- 接纳尺寸:84
- 输出尺寸:10
Same卷积 & Full卷积 & Valid卷积:
- Same卷积:根据卷积核大小对输入特征图自适应 零填充 (以k定p),确保输出的特征图大小与输入的特征图尺寸相同。
- Full卷积:允许卷积核超出特征图范围,但须确保卷积核边缘与特征图边缘相交。Same卷积是特殊的Full卷积。
- Valid卷积:卷积过程中不使用填充,输出特征图的尺寸小于输入特征图的尺寸。
本文 Torch & Torchvision版本:

2. 读取数据
2.1 Torchvision读取数据
Datasets 使用
torchvision.datasets模块包含多种预定义类型的数据集,例如MNIST、EMNIST、FashionMNIST、CIFAR-10、ImageNet等。它封装了这些数据集的下载、加载和预处理步骤。
torchvision.datasets 4个参数
- root:字符串类型,指定存放路径
- train:布尔类型,区分训练集与测试集
- download:布尔类型,开启下载,若本地存在则不进行下载
- transform:用于对数据预先处理的转换
2.2 MNIST & FashionMNIST 下载解包读取数据
定义读取函数
""" 定义读取函数 """
def load_mnist(path, kind='train'):import osimport gzipimport numpy as np""" Load MNIST data for `path` """labels_path = os.path.join(path, '{}-labels-idx1-ubyte.gz'.format(kind))images_path = os.path.join(path, '{}-images-idx3-ubyte.gz'.format(kind))with gzip.open(labels_path, 'rb') as lbpath:labels = np.frombuffer(lbpath.read(), dtype=np.uint8, offset=8)with gzip.open(images_path, 'rb') as lbpath:images = np.frombuffer(lbpath.read(), dtype=np.uint8, offset=16).reshape(len(labels), 28*28)return images, labels
抽取:训练集测+ 试集
X_train, y_train = load_mnist(path="./data/mnist")
X_test, y_test = load_mnist(path="./data/mnist", kind='t10k')
自定义 Pytorch Dataset 类
""" 自定义 Pytorch Dataset 类 """
class MnistDataset(Dataset):def __init__(self, data_path, kind=None, transform=None):self.transform = transformimages, labels = load_mnist(path="./data/mnist", kind=kind)2. Mnist
Mnist数据集:手写数字识别数据集,数据集分为训练集和测试集,用以训练和评估机器学习模型。
该数据集在深度学习领域具有重要地位,尤其适合初学者学习和实践图像识别技术。
- 该数据集含有
10种类别,共70000张灰度图像。包含 60000个训练集样本 和 10000个测试集样本。 - 每张图像以 28×28 像素的分辨率提供。
MNIST是一个手写数字数据集,该数据集由美国国家标准与技术研究所(National Institute of Standards and Technology, NIST)发起整理。该数据集的收集目的是希望通过算法,实现对手写数字的识别。
1998年,Yan LeCun 等人首次提出了LeNet-5 网络,利用上述数据集实现了手写字体的识别。
MNIST数据集由4个部分组成,分别为训练集图像、训练集标签、测试集图像和测试集标签。其中训练集图像为 60,000 张图像,测试集图像为 10,000 张。每张图像即为一个28*28的像素数组,每个像素的值为0或255(黑白图像)。
每个标签则为长度为10的一维数组,代表其为0-9数字的概率。
卷积神经网络 - 手写数字 - 可视化:


代码
利用torchvision.datasets.MNIST()读取
""" 导入三方库 """
import torch
import torchvision
from torch.utils.data import DataSet, DataLoader
import torchvision.transforms as transforms# 定义转换实例
data_transform = transforms.Compose([transforms.ToTensor(), # transforms.ToTensor() 将给定图像转为Tensortransforms.Normalize(mean=[0.5,0.5,0.5], std=[0.5,0.5,0.5])] # transforms.Normalize() 归一化处理
)# 加载MNIST数据集
trainset = torchvision.datasets.MNIST(root='./data/',train=True, download=True, transform=data_transform)
testset = torchvision.datasets.MNIST(root='./data/',train=False, download=True, transform=data_transform)# 加载数据加载器,便于小批量优化
trainloader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True)
testloader = troch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
※ 训练 LeNet5 预测分类
① 导入三方库
导入三方库
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import seaborn as sns
import matplotlib.pyplot as plt
确定运行设备:判断cuda是否可用
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
② 读取数据集
利用torchvision.datasets.MNIST()读取
# 定义转换实例
data_transform = transforms.Compose([transforms.ToTensor(), # transforms.ToTensor() 将给定图像转为Tensortransforms.Normalize(mean=[0.5], std=[0.5])] # transforms.Normalize() 归一化处理
)# 加载FashionMNIST数据集
train_set = torchvision.datasets.FashionMNIST(root='./data/',train=True, download=True, transform=data_transform)
test_set = torchvision.datasets.FashionMNIST(root='./data/',train=False, download=True, transform=data_transform)# 加载数据加载器,便于小批量优化
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=100, shuffle=False)
③ 创建神经网络
创建神经网络
class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.layer1 = nn.Sequential( # 为匹配 LeNet 32*32 输入,故对 28*28 图像作 p=2 padding。nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(6),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer2 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer3 = nn.Sequential(nn.Flatten(),nn.Linear(in_features=16*5*5, out_features=120),nn.ReLU(),nn.Linear(in_features=120, out_features=84),nn.ReLU(),nn.Linear(in_features=84, out_features=10),nn.LogSoftmax())def forward(self, x):output = self.layer1(x)output = self.layer2(output)output = self.layer3(output)return output
④ 训练神经网络
预定义超参数
# 随机种子
torch.manual_seed(20)
# 创建神经网络对象
model = LeNet()
# 确定神经网络运行设备
model.to(device)
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练轮次
epochs = 5
# 小批量训练次数
batch_size = 100
# 训练损失记录
final_losses = []
定义神经网络训练函数
def train_model():count = 0for epoch in range(epochs):for images, labels in train_loader:images, labels = images.to(device), labels.to(device)train = images.view(100, 1, 28, 28)# 1. 正向传播preds = model(train)# 2. 计算误差loss = loss_function(preds, labels)final_losses.append(loss)# 3. 反向传播optimizer.zero_grad()loss.backward()# 4. 优化参数optimizer.step()count += 1if count % 100 == 0:print("Epoch: {}, Iteration: {}, Loss: {} ".format(epoch, count, loss.data))
调用训练函数 + 保存模型
train_model()
torch.save(model.state_dict(), "mlenet.pth")
print("Saved PyTorch Model State to mlenet.pth")
绘制训练损失图像
for i in range(len(final_losses)):final_losses[i] = final_losses[i].item()
plt.plot(final_losses)
plt.show()

⑤ 测试神经网络
定义混淆矩阵
confusion_matrix = np.zeros((10,10))
定义神经网络测试函数
def test_model():model = LeNet()model.to(device)model.load_state_dict(torch.load('mlenet.pth'))correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)preds = model(images)preds = torch.max(preds, 1)[1]labels = torch.max(labels, 1)[1]correct += (preds == labels).sum()total += len(images)print(f"accuracy: {correct/total}")
调用训练函数 + 输出混淆矩阵
# 调用训练函数
test_model()
# 输出混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix, annot=True, cmap='Oranges', linecolor='black', linewidth=0.5, fmt='.20g')


3. EMnist
EMnist数据集:手写字符识别数据集,Mnist数据集进阶版本,数据集分为训练集和测试集,用以训练和评估机器学习模型。
该数据集在深度学习领域具有重要地位,尤其适合初学者学习和实践图像识别技术。
- 该数据集含有
10种类别,共70000张灰度图像。包含 60000个训练集样本 和 10000个测试集样本。 - 每张图像以 28×28 像素的分辨率提供。
EMNIST 分为以下 6 类:
By_Class : 共 814255 张,62 类,与 NIST 相比重新划分类训练集与测试集的图片数。
By_Merge: 共 814255 张,47 类, 与 NIST 相比重新划分类训练集与测试集的图片数。
Balanced : 共 131600 张,47 类, 每一类都包含了相同的数据,每一类训练集 2400 张,测试集 400 张。
Digits :共 28000 张,10 类,每一类包含相同数量数据,每一类训练集 24000 张,测试集 4000 张。
Letters : 共 103600 张,37 类,每一类包含相同数据,每一类训练集 2400 张,测试集 400 张。
MNIST : 共 70000 张,10 类,每一类包含相同数量数据(注:这里虽然数目和分类都一样,但是图片的处理方式不一样,EMNIST 的 MNIST 子集数字占的比重更大)
Letter中相似的字母 (例如c或o) 被整合为1个字符,则共有37个字母可被识别,但因 未区分大小写&手写印刷体 最终被统一归为 26 类别,又因为包含未分类类别 [N/A] 故归为 27 类别。
本小节利用 EMNIST-Letters 数据集训练LeNet5模型,进行字符识别。
数据集排列:
| [N/A] | a | b | c | d | …… |
|---|
※ 训练 LeNet5 预测分类
① 导入三方库
导入三方库
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import seaborn as sns
import matplotlib.pyplot as plt
确定运行设备:判断cuda是否可用
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
② 读取数据集
利用torchvision.datasets.EMNIST()读取
# 定义转换实例
data_transform = transforms.Compose([transforms.ToTensor(), # transforms.ToTensor() 将给定图像转为Tensortransforms.Normalize(mean=[0.5], std=[0.5])] # transforms.Normalize() 归一化处理
)# 加载FashionMNIST数据集
train_set = torchvision.datasets.FashionMNIST(root='./data/',train=True, download=True, transform=data_transform)
test_set = torchvision.datasets.FashionMNIST(root='./data/',train=False, download=True, transform=data_transform)# 加载数据加载器,便于小批量优化
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=100, shuffle=False)
③ 创建神经网络
创建神经网络
class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.layer1 = nn.Sequential( # 为匹配 LeNet 32*32 输入,故对 28*28 图像作 p=2 padding。nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(6),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer2 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer3 = nn.Sequential(nn.Flatten(),nn.Linear(in_features=16*5*5, out_features=120),nn.ReLU(),nn.Linear(in_features=120, out_features=84),nn.ReLU(),nn.Linear(in_features=84, out_features=27),nn.LogSoftmax())def forward(self, x):output = self.layer1(x)output = self.layer2(output)output = self.layer3(output)return output
④ 训练神经网络
预定义超参数
# 随机种子
torch.manual_seed(20)
# 创建神经网络对象
model = LeNet()
# 确定神经网络运行设备
model.to(device)
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练轮次
epochs = 5
# 小批量训练次数
batch_size = 100
# 训练损失记录
final_losses = []
定义神经网络训练函数
def train_model():count = 0for epoch in range(epochs):for images, labels in train_loader:images, labels = images.to(device), labels.to(device)# 1. 正向传播preds = model(train)# 2. 计算误差loss = loss_function(preds, labels)final_losses.append(loss)# 3. 反向传播optimizer.zero_grad()loss.backward()# 4. 优化参数optimizer.step()count += 1if count % 100 == 0:print("Epoch: {}, Iteration: {}, Loss: {} ".format(epoch, count, loss.data))
调用训练函数 + 保存模型
train_model()
torch.save(model.state_dict(), "elenet.pth")
print("Saved PyTorch Model State to mlenet.pth")
绘制训练损失图像
for i in range(len(final_losses)):final_losses[i] = final_losses[i].item()
plt.plot(final_losses)
plt.show()

⑤ 测试神经网络
定义混淆矩阵
confusion_matrix = np.zeros((27,27))
定义神经网络测试函数
def test_model():model = LeNet()model.to(device)model.load_state_dict(torch.load('elenet.pth'))correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)preds = model(images)preds = torch.max(preds, 1)[1]correct += (preds == labels).sum()total += len(images)for i in range(len(preds)):confusion_matrix[preds[i]][labels[i]] += 1print(f"accuracy: {correct/total}")
调用训练函数 + 输出混淆矩阵
# 调用训练函数
test_model()
# 输出混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix, annot=True, cmap='Oranges', linecolor='black', linewidth=0.5, fmt='.20g')


4. FashionMnist
FashionMnist:衣物图标识别数据集,Mnist数据集进阶版本,数据集分为训练集和测试集,用以训练和评估机器学习模型。
该数据集在深度学习领域具有重要地位,尤其适合初学者学习和实践图像识别技术。
- 该数据集含有
10种类别,共70000张灰度图像。包含 60000个训练集样本 和 10000个测试集样本。 - 每张图像以 28×28 像素的分辨率提供。
| 标注编号 | 类别 |
|---|---|
| 0 | T恤 T-shirt |
| 1 | 裤子 Trousers |
| 2 | 套衫 Pullover |
| 3 | 裙子 Dress |
| 4 | 外套 Coat |
| 5 | 凉鞋 Sandal |
| 6 | 汗衫 Shirt |
| 7 | 运动鞋 Sneaker |
| 8 | 包 Bag |
| 9 | 踝靴 Ankle boot |
※ 训练 LeNet5 预测分类
① 导入三方库
导入三方库
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import seaborn as sns
import matplotlib.pyplot as plt
确定运行设备:判断cuda是否可用
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
② 读取数据集
利用torchvision.datasets.FashionMNIST()读取
# 定义转换实例
data_transform = transforms.Compose([transforms.ToTensor(), # transforms.ToTensor() 将给定图像转为Tensortransforms.Normalize(mean=[0.5], std=[0.5])] # transforms.Normalize() 归一化处理
)# 加载FashionMNIST数据集
train_set = torchvision.datasets.FashionMNIST(root='./data/',train=True, download=True, transform=data_transform)
test_set = torchvision.datasets.FashionMNIST(root='./data/',train=False, download=True, transform=data_transform)# 加载数据加载器,便于小批量优化
train_loader = torch.utils.data.DataLoader(train_set, batch_size=100, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=100, shuffle=False)
③ 创建神经网络
创建神经网络
class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.layer1 = nn.Sequential( # 为匹配 LeNet 32*32 输入,故对 28*28 图像作 p=2 padding。nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(6),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer2 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer3 = nn.Sequential(nn.Flatten(),nn.Linear(in_features=16*5*5, out_features=120),nn.ReLU(),nn.Linear(in_features=120, out_features=84),nn.ReLU(),nn.Linear(in_features=84, out_features=10),nn.LogSoftmax())def forward(self, x):output = self.layer1(x)output = self.layer2(output)output = self.layer3(output)return output
④ 训练神经网络
预定义超参数
# 随机种子
torch.manual_seed(20)
# 创建神经网络对象
model = LeNet()
# 确定神经网络运行设备
model.to(device)
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练轮次
epochs = 5
# 小批量训练次数
batch_size = 100
# 训练损失记录
final_losses = []
定义神经网络训练函数
def train_model():count = 0for epoch in range(epochs):for images, labels in train_loader:images, labels = images.to(device), labels.to(device)train = images.view(100, 1, 28, 28)# 1. 正向传播preds = model(train)# 2. 计算误差loss = loss_function(preds, labels)final_losses.append(loss)# 3. 反向传播optimizer.zero_grad()loss.backward()# 4. 优化参数optimizer.step()count += 1if count % 100 == 0:print("Epoch: {}, Iteration: {}, Loss: {} ".format(epoch, count, loss.data))
调用训练函数 + 保存模型
train_model()
torch.save(model.state_dict(), "fmlenet.pth")
print("Saved PyTorch Model State to fmlenet.pth")
绘制训练损失图像
for i in range(len(final_losses)):final_losses[i] = final_losses[i].item()
plt.plot(final_losses)
plt.show()

⑤ 测试神经网络
定义混淆矩阵
confusion_matrix = np.zeros((10,10))
定义神经网络测试函数
def test_model():model = LeNet()model.to(device)model.load_state_dict(torch.load('fmlenet.pth'))correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)preds = model(images)preds = torch.max(preds, 1)[1]correct += (preds == labels).sum()total += len(images)for i in range(len(preds)):confusion_matrix[preds[i]][labels[i]] += 1print(f"accuracy: {correct/total}")
调用训练函数 + 输出混淆矩阵
# 调用训练函数
test_model()
# 输出混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix, annot=True, cmap='Oranges', linecolor='black', linewidth=0.5, fmt='.20g')


由此得出,标准LeNet5网络拟合Fashion效果良好。
5. CIFAR-10
CIFAR10数据集共有60000个样本(32*32像素的RGB彩色图像),每个RGB图像包含3个通道(R通道、G通道、B通道)。
- 该数据集含有
10种类别,共60000张彩色图像。包含 50000个训练集样本 和 10000个测试集样本。
| 标注编号 | 类别 |
|---|---|
| 0 | 飞机 Airplane |
| 1 | 汽车 Automobile |
| 2 | 鸟 Bird |
| 3 | 猫 Cat |
| 4 | 鹿 Deer |
| 5 | 狗 Dog |
| 6 | 青蛙 Frog |
| 7 | 马 Horse |
| 8 | 船 Ship |
| 9 | 卡车 Truck |
CIFAR10数据集的内容,如图所示。

※ 训练 LeNet5 预测分类
① 导入三方库
导入三方库
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import seaborn as sns
import matplotlib.pyplot as plt
确定运行设备:判断cuda是否可用
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
② 读取数据集
利用torchvision.datasets.CIFAR10()读取
# 定义一个转换参数的实例
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)# 加载CIFAR10数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transforms.ToTensor())
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transforms.ToTensor())# 创建数据加载器
train_loader = torch.utils.data.DataLoader(trainset, batch_size=600, shuffle=True)
test_loader = torch.utils.data.DataLoader(testset, batch_size=600, shuffle=False)
③ 创建神经网络
创建神经网络
class LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.layer1 = nn.Sequential( nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5),nn.BatchNorm2d(6),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer2 = nn.Sequential(nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.layer3 = nn.Sequential(nn.Flatten(),nn.Linear(in_features=16*5*5, out_features=120),nn.ReLU(),nn.Linear(in_features=120, out_features=84),nn.ReLU(),nn.Linear(in_features=84, out_features=10),nn.LogSoftmax())def forward(self, x):output = self.layer1(x)output = self.layer2(output)output = self.layer3(output)return output
④ 训练神经网络
预定义超参数
# 随机种子
torch.manual_seed(20)
# 创建神经网络对象
model = LeNet()
# 确定神经网络运行设备
model.to(device)
# 损失函数
loss_function = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练轮次
epochs = 50
# 小批量训练次数
batch_size = 600
# 训练损失记录
final_losses = []
定义神经网络训练函数
def train_model():for epoch in range(epochs):count = 0for images, labels in train_loader:images, labels = images.to(device), labels.to(device)train = images# 1. 正向传播preds = model(train)# 2. 计算误差loss = loss_function(preds, labels)final_losses.append(loss)# 3. 反向传播optimizer.zero_grad()loss.backward()# 4. 优化参数optimizer.step()count += 1if count % 100 == 0:print("Epoch: {}, Iteration: {}, Loss: {} ".format(epoch, count, loss.data))
调用训练函数 + 保存模型
train_model()
torch.save(model.state_dict(), "clenet.pth")
print("Saved PyTorch Model State to clenet.pth")
绘制训练损失图像
for i in range(len(final_losses)):final_losses[i] = final_losses[i].item()
plt.plot(final_losses)
plt.show()

⑤ 测试神经网络
定义混淆矩阵
confusion_matrix = np.zeros((10,10))
定义神经网络测试函数
def test_model():model = LeNet()model.to(device)model.load_state_dict(torch.load('fmlenet.pth'))correct = 0total = 0with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)preds = model(images)preds = torch.max(preds, 1)[1]correct += (preds == labels).sum()total += len(images)for i in range(len(preds)):confusion_matrix[preds[i]][labels[i]] += 1print(f"accuracy: {correct/total}")
调用训练函数 + 输出混淆矩阵
# 调用训练函数
test_model()
# 输出混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix, annot=True, cmap='Oranges', linecolor='black', linewidth=0.5, fmt='.20g')

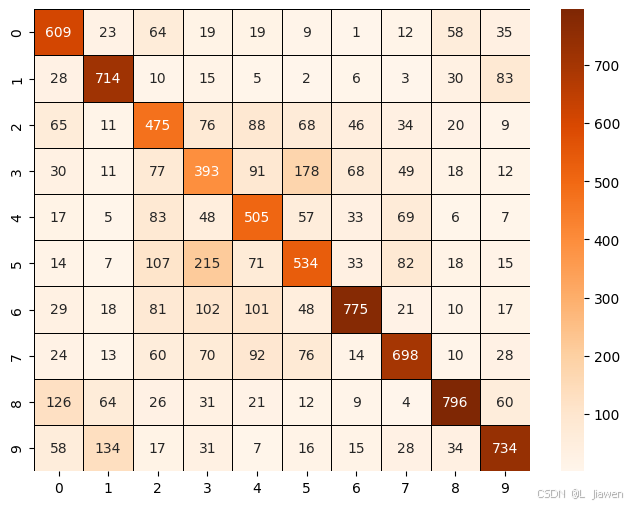
由此得出,未经修饰/改进的标准LeNet5网络对CIFAR10数据集的拟合效果不佳。
可改进的方向:
- 本文对CIFAR10数据集的拟合效果不佳,后续可对此问题再作探究。
- 本文所有网络的输出层采用了LogSoftmax函数,而非Softmax函数,后续可在此问题上继续探讨。
相关文章:
【Python · PyTorch】卷积神经网络 CNN(LeNet-5网络)
【Python PyTorch】卷积神经网络 CNN(LeNet-5网络) 1. LeNet-5网络※ LeNet-5网络结构 2. 读取数据2.1 Torchvision读取数据2.2 MNIST & FashionMNIST 下载解包读取数据 2. Mnist※ 训练 LeNet5 预测分类 3. EMnist※ 训练 LeNet5 预测分类 4. Fash…...

Git 拉取指定分支创建项目
一 背景 因为项目过大,只需要部分分支的代码即可。 二 实现 方法一:使用 --single-branch 参数 git clone 支持只拉取指定分支,而不是整个库的所有分支: git clone --branch <branch_name> --single-branch <reposi…...
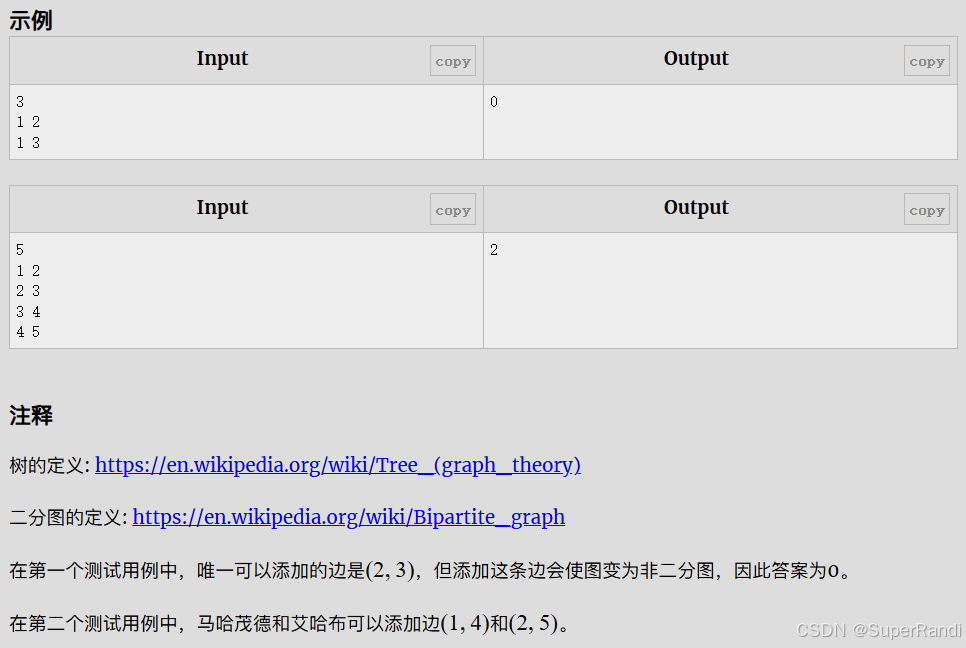
CF862B Mahmoud and Ehab and the bipartiteness(二分图的性质)
思路:一个二分图是由两个集合组成的,同一个集合中的节点间不能连边,所以一个二分图最多有cnt[1]*cnt[2]条边,题目给出一个树的n-1条边,要我们添加最多的边数使他成为二分图,添加的边数就是cnt[1]*cnt[2]-n1…...

React Native 全栈开发实战班 :数据管理与状态之React Hooks 基础
在 React Native 应用中,数据管理与状态管理是构建复杂用户界面的关键。React 提供了多种工具和模式来处理数据流和状态管理,包括 React Hooks、Context API 以及第三方状态管理库(如 Redux)。本章节将详细介绍 React Hooks 的基础…...

传奇996_22——自动挂机
登录钩子函数中执行 callscript(actor, "../QuestDiary/主界面基础按钮/主界面基础按钮QM", "基础按钮QM")基础按钮QM执行了已下代码 #IF Equal <$CLIENTFLAG> 1 #ACT goto PC端面板加载#IF Equal <$CLIENTFLAG> 2 #ACT goto 移动端面板加载…...

faiss 提供了多种索引类型
faiss 多种索引类型 在 faiss 中,IndexFlatL2 是一个简单的基于 L2 距离(欧几里得距离)进行索引的索引类型,但实际上,faiss 提供了多种索引类型,支持不同的度量方式和性能优化,您可以根据需求选…...

比rsync更强大的文件同步工具rclone
背景 多个复制,拷贝,同步文件场景,最大规模的是每次几千万规模的小文件需要从云上对象存储中拉取到本地。其他的诸如定期数据备份,单次性数据备份。 rsync是单线程的,开源的mrsync是多线程的,但适用范围没…...

《业务流程--穿越从概念到实践的丛林》读后感一:什么是业务流程
1.1 流程和业务流程概念辨析 业务流程建模标准(BPMN)对于业务流程的定义:一个业务流程由为了配合一个组织性或技术环境而一系列活动组成。这些活动共同实现一个业务目标。 业务流程再造最有名的倡导者托马斯.H.达文波特对于流程和业务流程的定义:流程是一组结构化且可度量的…...

解决docker mysql命令行无法输入中文
docker启动时,设置支持中文 docker run --name mysql-container -e MYSQL_ROOT_PASSWORDroot -d mysql:5.7 --character-set-serverutf8mb4 --collation-serverutf8mb4_unicode_ci --default-time-zone8:00 进入docker时,指定LANG即可 docker exec -it …...
基于Java Springboot城市公交运营管理系统
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 数据…...

Lc70--319.两个数组的交集(二分查找)---Java版
1.题目描述 2.思路 用集合求交集,因为集合里面的元素要满足不重复、无序、唯一。使得集合在去重、查找和集合操作(如交集、并集、差集等)中非常高效和方便。 3.代码实现 class Solution {public int[] intersection(int[] nums1, int[] nu…...

亿咖通科技应邀出席微软汽车行业智享会,分享ECARX AutoGPT全新实践
11月14日,全球出行科技企业亿咖通科技(纳斯达克股票代码:ECX)应邀于广州参加由微软举行的汽车行业智享会,揭晓了亿咖通科技对“AI定义汽车”时代的洞察与技术布局,分享了亿咖通科技汽车垂直领域大模型ECARX…...

Python教程:运算符重载
在Python中,运算符重载是通过定义特殊方法(也称为魔术方法)来实现的,这些特殊方法允许类的实例像内置类型那样使用运算符。 Python提供了一系列这样的特殊方法,用于重载各种运算符。 以下是一些常见的运算符重载特殊…...
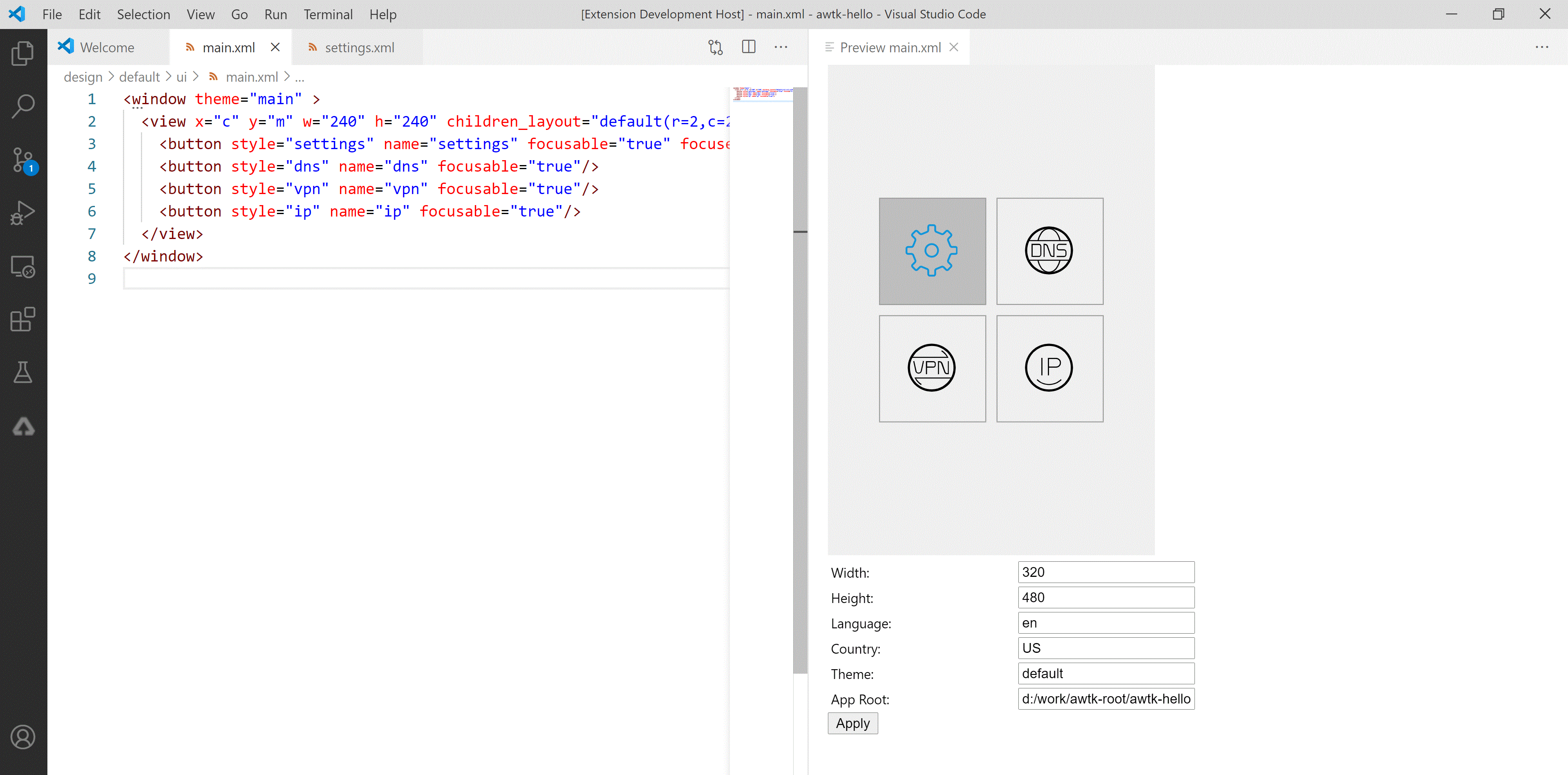
AWTK VSCode 实时预览插件端口冲突的解决办法
AWTK XML UI 预览插件:在 vscode 中实时预览 AWTK XML UI 文件,在 Copilot 的帮助下,可以大幅提高界面的开发效率。 主要特色: 真实的 UI 效果。可以设置主题,方便查看在不同主题下界面的效果。可以设置语言…...

【MySQL系列】深入理解MySQL中的存储、排序字符集
前言 在创建数据库时,我们经常会需要填写数据库的所用字符集、排序规则,字符集和排序规则是两个非常重要的概念,它们决定了数据库如何存储和比较字符串数据。在 MySQL 中,常用的存储字符集有 utf8、utf8mb4,而排序字符…...
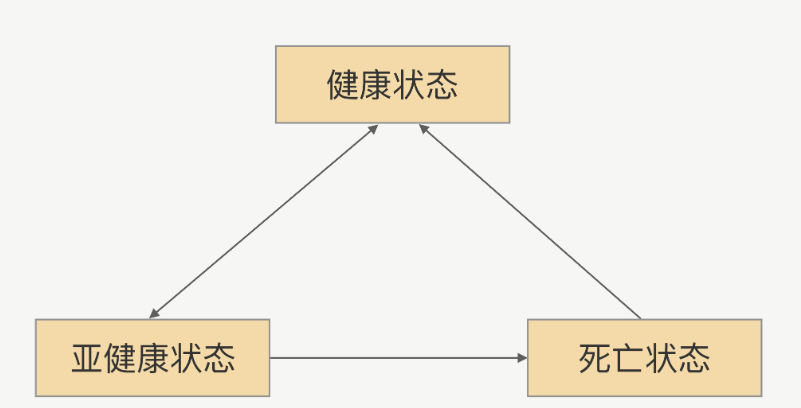
RPC-健康检测机制
什么是健康检测? 在真实环境中服务提供方是以一个集群的方式提供服务,这对于服务调用方来说,就是一个接口会有多个服务提供方同时提供服务,调用方在每次发起请求的时候都可以拿到一个可用的连接。 健康检测,能帮助从连…...
关于Java处理Excel常规列表记录,并入库的操作
1.描述 对于常规的Excel列表(二维表格)的入库处理,一般的mysql连接工具,例如Navicat就支持。但是,因为业务需要,不想每次都去手动导入,所以这里采用编码且定时任务的形式来实现。 2.Excel常规列…...

深入理解 JavaScript 中的 Array.find() 方法:原理、性能优势与实用案例详解
目录 深入理解 JavaScript 中的 Array.find() 方法:原理、性能优势与实用案例详解 一、引言:为什么要使用Array.find() 二、Array.find()的使用与技巧 1、基础语法 2、返回值 3、使用技巧 三、Array.find()的优势与实际应用案例 1、利用返回引用…...
计算机网络安全 —— 对称加密算法 DES (一)
一、对称加密算法概念# 我们通过计算机网络传输数据时,如果无法防止他人窃听, 可以利用密码学技术将发送的数据变换成对任何不知道如何做逆变换的人都不可理解的形式, 从而保证了数据的机密性。这种变换被称为加密( encryptio…...
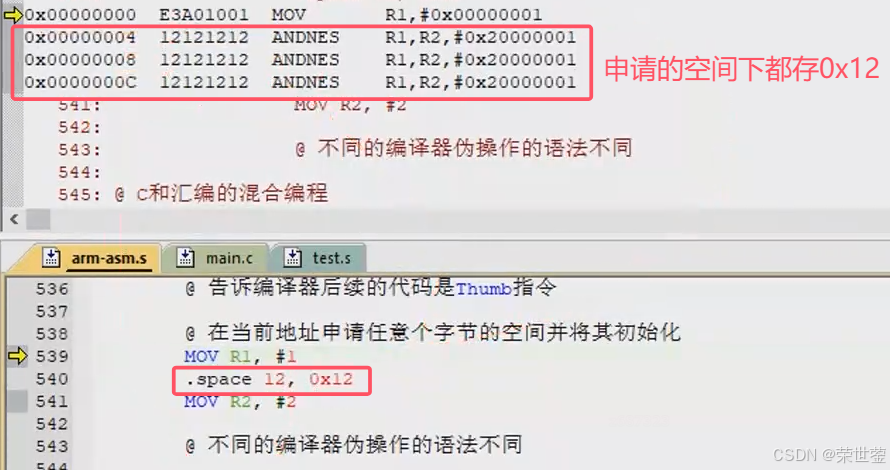
5. ARM_指令集
概述 分类 汇编中的符号: 指令:能够编译生成一条32位机器码,并且能被处理器识别和执行伪指令:本身不是指令,编译器可以将其替换成若干条指令伪操作:不会生成指令,只是在编译阶段告诉编译器怎…...

macOS桌面歌词终极解决方案:LyricsX 2.0完整指南
macOS桌面歌词终极解决方案:LyricsX 2.0完整指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics 你是否曾经在听音乐时,想要跟着歌词一起唱却发现…...

终极免费文档下载指南:如何用kill-doc脚本轻松获取百度文库、豆丁网等30+平台资源
终极免费文档下载指南:如何用kill-doc脚本轻松获取百度文库、豆丁网等30平台资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档&a…...

DeFi预测市场套利机器人:延迟套利与结构性对冲策略详解
1. 项目概述:在2.7秒的缝隙中寻找确定性如果你在DeFi世界里寻找一种“低风险、高确定性”的套利机会,那么Polymarket这类预测市场可能是一个被低估的宝藏。这个项目,genoshide/polymarket-arbitrage-trading-bot,本质上是一个高度…...

CipherChat:基于词元替换的端到端加密大模型对话方案解析
1. 项目概述:当大模型对话遇上密码学最近在折腾大语言模型(LLM)应用开发的朋友,可能都遇到过同一个头疼的问题:如何保证用户和模型之间对话的隐私和安全?我们辛辛苦苦搭建的智能客服、个人助理或者创意写作…...
)
STM32实战:用HAL库搞定RS485 Modbus液压传感器数据采集(附自动收发电路避坑)
STM32实战:HAL库驱动RS485 Modbus液压传感器全流程解析 液压系统压力监测的稳定性往往取决于传感器数据采集的可靠性。在工业现场,RS485总线搭配Modbus RTU协议已成为液压传感器数据传输的黄金标准。本文将深入探讨基于STM32 HAL库的完整解决方案&#x…...

macOS虚拟机解锁终极指南:在普通PC上运行苹果系统的完整解决方案
macOS虚拟机解锁终极指南:在普通PC上运行苹果系统的完整解决方案 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unlo/unlocker 想要在Windows或Linux电脑上体验macOS系统,但又不想花费高昂的价…...

【力扣100题】22. 矩阵置零
一、题目描述 给定一个 m x n 的矩阵,如果一个元素为 0,则将其所在行和列的所有元素都设为 0。请使用原地算法。 示例 1: 输入:matrix [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]]示例 2: …...

告别训练中断:在PyCharm中利用Tmux实现远程GPU服务器的持久化会话
1. 为什么需要持久化训练会话? 作为一名长期在深度学习领域摸爬滚打的工程师,我最头疼的就是训练过程中突然断网或者需要关闭电脑的情况。想象一下,你正在用PyCharm远程连接公司的GPU服务器训练一个需要48小时的模型,突然家里停电…...

Helm Git插件:实现K8s Chart的GitOps部署与CI/CD集成
1. 项目概述:为什么我们需要一个Helm Git插件?在Kubernetes生态中,Helm是当之无愧的“包管理器”,它通过Chart的概念,将复杂的K8s应用定义打包、版本化,极大地简化了部署流程。然而,标准的Helm工…...

YOLOv11室内展台飞机模型目标检测数据集-182张-Airplane-1_4_2
YOLOv11室内展台飞机模型目标检测数据集 📊 数据集基本信息 目标类别: [‘airplane’] 中文类别:[‘飞机’] 训练集:159 张 验证集:23 张 测试集:0 张 总计:182 张 📄 data.yaml 配置信息 该数据集提供了data.yaml文件,内容如下: train: ../train/images val: .…...