Stable diffusion详细讲解

🌺系列文章推荐🌺
扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新)

SD模型原理:
- Stable Diffusion概要讲解
- Stable diffusion详细讲解
- Stable Diffusion的加噪和去噪详解
- Diffusion Model
- Stable Diffusion核心网络结构——VAE
- Stable Diffusion核心网络结构——CLIP Text Encoder
- Stable Diffusion核心网络结构——U-Net
- Stable Diffusion中U-Net的前世今生与核心知识
- SD模型性能测评
- Stable Diffusion经典应用场景
- SDXL的优化工作
微调方法原理:
- DreamBooth
- LoRA
- LORA及其变种介绍
- ControlNet
- ControlNet文章解读
- Textual Inversion 和 Embedding fine-tuning
目录
Stable Diffusion模型工作流程
CLIP
U-Net and Schedule算法
VAE
Stable Diffusion模型核心基础原理
【1】扩散模型的基本原理详解
【2】扩散模型的前向扩散过程详解
【3】扩散模型的反向扩散过程详解
1. 采样高斯噪声
2. 迭代去噪过程
3. 输出去噪后的图像
【4】引入Latent思想让Stable Diffusion模型彻底“进化破圈”
Stable Diffusion训练全过程
【1】SD训练集加入噪声
【2】SD训练中加噪与去噪
【3】文本信息对图片生成的控制
【4】SD模型训练时的输入
其他主流生成式模型介绍
摘录来源:https://zhuanlan.zhihu.com/p/632809634
Stable Diffusion模型工作流程
Stable Diffusion(SD)模型是由Stability AI和LAION等公司共同开发的生成式模型,可以用于文生图,图生图,图像inpainting,ControlNet控制生成,图像超分等丰富的任务,本节中以文生图(txt2img)和图生图(img2img)任务展开对Stable Diffusion模型的工作流程进行通俗的讲解。
文生图任务是指将一段文本输入到SD模型中,经过一定的迭代次数,SD模型输出一张符合输入文本描述的图片。比如下图中输入了“天堂,巨大的,海滩”,于是SD模型生成了一个美丽沙滩的图片。

而图生图任务在输入本文的基础上,再输入一张图片,SD模型将根据文本的提示,将输入图片进行重绘以更加符合文本的描述。比如下图中,SD模型将“海盗船”添加在之前生成的那个美丽的沙滩图片上。

CLIP
那么输入的文本信息如何成为SD模型能够理解的机器数学信息呢?
很简单,我们需要给SD模型一个文本信息与机器数据信息之间互相转换的“桥梁”——CLIP Text Encoder模型。如下图所示,我们使用CLIP Text Encoder模型作为SD模型中的前置模块,将输入的文本信息进行编码,生成与文本信息对应的Text Embeddings特征矩阵,再将Text Embeddings用于SD模型中来控制图像的生成:

完成对文本信息的编码后,就会输入到SD模型的“图像优化模块【U-Net】”中对图像的优化进行“控制”。
如果是图生图任务,我们在输入文本信息的同时,还需要将原图片通过图像编码器(VAE Encoder)生成Latent Feature(隐空间特征)作为输入。
如果是文生图任务,我们只需要输入文本信息,再用random函数生成一个高斯噪声矩阵作为Latent Feature的“替代”输入到SD模型的“图像优化模块”中。
U-Net and Schedule算法
“图像优化模块”作为SD模型中最为重要的模块,其工作流程是什么样的呢?
首先,“图像优化模块”是由一个U-Net网络和一个Schedule算法共同组成,U-Net网络负责预测噪声,不断优化生成过程,在预测噪声的同时不断注入文本语义信息。而schedule算法
对每次U-Net预测的噪声进行优化处理(动态调整预测的噪声,控制U-Net预测噪声的强度),从而统筹生成过程的进度。在SD中,U-Net的迭代优化步数(Timesteps)大概是50或者100次,在这个过程中Latent Feature的质量不断的变好(纯噪声减少,图像语义信息增加,文本语义信息增加)。整个过程如下图所示:

VAE
U-Net网络和Schedule算法的工作完成以后,SD模型会将优化迭代后的Latent Feature输入到图像解码器(VAE Decoder)中,将Latent Feature重建成像素级图像。
我们对比一下文生图任务中,初始Latent Feature和经过SD的“图像优化模块”处理后,再用图像解码器重建出来的图片之间的区别:
【文生图任务:没有经过U-Net处理的图像是随机噪声;和有U-Net处理的图像会逐渐接近prompts】

可以看到,上图左侧是初始Latent Feature经过图像解码器重建后的图片,显然是一个纯噪声图片;上图右侧是经过SD的“图像优化模块”处理后,再用图像解码器重建出来的图片,可以看到是一张包含丰富内容信息的有效图片。
我们再将U-Net网络+Schedule算法的迭代去噪过程的每一步结果都用图像解码器进行重建,我们可以直观的感受到从纯噪声到有效图片的全过程:

以上就是SD模型工作的完整流程,下面Rocky再将其进行总结归纳制作成完整的Stable Diffusion前向推理流程图,方便大家更好的理解SD模型的前向推理过程:

VAE在Stable Diffusion模型各阶段的作用:
VAE Encoder:用于将图像压缩到潜在空间,在训练阶段和图生图的推理阶段用于将真实图像转换为潜在表示。在文生图推理阶段,不需要使用VAE的Encoder,只使用VAE的Decoder。
VAE Decoder:训练阶段,一般不需要用VAE(Variational Autoencoder) 的 Decoder 将潜在空间中的表示解码回图像。模型训练的核心任务是让U-Net这样的神经网络学会从带有噪声的潜在表示中预测噪声,而不是直接生成图像。在文生图和图生图推理阶段需要用 VAE Decoder 将扩散模型生成的潜在表示解码为图像。
为什么文生图推理时不需要VAE Encoder?
在文生图推理过程中,输入的只有prompts,没有输入图像,而是使用随机噪声开始,随机噪声是在潜在空间中的,不需要再将图像编码到潜在空间。直接在生成阶段使用解码器将潜在表示解码为图像即可。换句话说,VAE Encoder的作用是在训练阶段/图生图推理阶段将真实图像压缩到潜在空间,而在文生图推理阶段,没有真实图像压缩的过程,因此只需要VAE的Decoder来进行解码。
图生图推理阶段,输入的是prompts和原始图像,VAE Encoder用于将输入图像编码到潜在空间,VAE Decoder用于将生成的潜在表示解码为图像。
文生图推理阶段:输入的是prompts,没有图像,生成一个随机噪声来替代,这个噪声是在潜在空间中的,不需要使用VAE Encoder,只使用VAE Decoder来解码生成的潜在表示。
Stable Diffusion模型核心基础原理
在传统深度学习时代,凭借生成器与判别器对抗训练这个开创性的哲学思想,GAN(Generative adversarial networks)可以说是在生成式模型中一枝独秀。同样的,在AIGC时代,以Stable Diffusion模型为代表的扩散模型接过GAN的衣钵,在AI绘画领域一路“狂飙”。
与GAN等生成式模型一致的是,SD模型同样拟合训练集分布,并能够生成与训练集分布相似的输出结果,但与GAN相比,SD模型训练过程更稳定,而且具备更强的泛化性能。这些都归功于扩散模型中核心的前向扩散过程(Forward Diffusion Process)和反向扩散过程(Reverse Diffusion Process)。
在前向扩散过程中,SD模型持续对一张图像添加高斯噪声直至变成随机噪声矩阵。而在反向扩散过程中,SD模型进行去噪声过程,【使用U-Net】将一个随机噪声矩阵逐渐去噪直至生成一张图像。具体流程与图解如下所示:
- 前向扩散过程(Forward Diffusion Process) → 图片中持续添加噪声
- 反向扩散过程(Reverse Diffusion Process) → 持续去除图片中的噪声

【1】扩散模型的基本原理详解
在Stable Diffusion这个扩散模型中,无论是前向扩散过程还是反向扩散过程都是一个参数化的马尔可夫链(Markov chain),如下图所示:

看到这里,大家是不是感觉概念有点复杂了,don‘t worry,大家只要知道Stable Diffusion模型的整个流程遵循参数化的马尔可夫链,前向扩散过程是对图像增加噪声,反向扩散过程是去噪过程即可,这对于面试、工业界应用、竞赛界厮杀来说,都已经足够了。
如果有想要深入理解扩散模型数学原理的读者,阅读原论文:Denoising Diffusion Probabilistic Models
【2】扩散模型的前向扩散过程详解
Stable Diffusion(SD)模型的前向扩散是一个逐步添加噪声的过程,它不是在 U-Net 中进行的,而是直接在输入图像数据上进行。
详细分析一下扩散模型的前向扩散过程,其是一个不断往图像上加噪声的过程。我们举个例子,如下图所示,我们在猫的图片中多次增加高斯噪声直至图片变成随机噪声矩阵。可以看到,对于初始数据,我们设置扩散步数为K步,每一步增加一定的噪声,如果我们设置的K足够大,那么我们就能够将初始数据转化成随机噪声矩阵。

一般来说,扩散过程是固定的,由上节中提到的Schedule算法(噪声调度器)进行统筹控制。同时扩散过程也有一个重要的性质:我们可以基于初始数据 X0 和任意的扩散步数 Ki ,采样得到对应的数据 Xi 。
加噪策略(Forward Diffusion Process):
加噪过程是扩散模型的前向扩散过程,也称为正向扩散,目的是从原始图像逐渐添加噪声,直至图像完全变成高斯噪声。
加噪的步骤:
- 给定一个初始图像
,模型在每个时间步 t 添加一定的高斯噪声,生成带噪的图像
。
- 这个过程可以被描述为逐步加入噪声,使得随着时间步的增加,图像中的噪声量不断增加,直到最后的图像变得完全随机。
加噪公式:
通过逐步增加噪声,最终在第 T 步时,图像
在加噪过程中需要使用到调度器,其作用是:调度器在加噪过程中每个时间步向图像中注入的噪声比例【速率和幅度】。常见的调度策略包括:
- 线性调度器:噪声以线性的方式逐步增加。
- 余弦调度器:噪声变化按照余弦函数曲线变化,使得噪声的增加在开始和结束时更为平滑。
加噪过程是确定的所以加噪不需要采样,不使用 DDIM、DDPM、PLMS:在扩散模型中,加噪过程是基于预定义的噪声调度器来实现的,而不是基于采样。也就是说,加噪过程没有不确定性,每一步都严格按照噪声调度器的规则添加噪声。
说明:公式推导和解读参考:
Diffusion Model
【3】扩散模型的反向扩散过程详解
Stable Diffusion(SD)模型的反向扩散过程在 U-Net 中进行。 U-Net的作用是噪声预测,之后使用Schedule算法和采样算法去噪。
说明:
噪声预测本身并不直接依赖于调度算法和采样算法。调度算法和采样算法主要用于推理阶段,而不是训练阶段。
扩散模型的反向扩散过程和前向扩散过程正好相反,是一个在图像上不断去噪的过程。下面是一个直观的例子,将随机高斯噪声矩阵通过扩散模型的反向扩散过程,预测噪声并逐步去噪,最后生成一个小别墅的清晰图片。

其中每一步预测并去除的噪声分布,都需要扩散模型在训练中学习。
讲好了扩散模型的前向扩散过程和反向扩散过程,他们的目的都是服务于扩散模型的训练,训练目标也非常简单:将扩散模型每次预测出的噪声 和 每次实际加入的噪声做回归,让扩散模型能够准确的预测出每次实际加入的真实噪声。
下面是扩散模型反向扩散过程的完整图解:

这张图展示了 扩散模型(Diffusion Model) 在图像生成阶段的逆扩散过程,其中模型逐步去噪,从纯噪声开始生成一张清晰的图像。具体分为以下几个步骤:
1. 采样高斯噪声
- 第一步,从高斯分布中采样一个初始噪声图像。在图中,初始图像
被采样自标准正态分布
,即一个全噪声图像。
- 这里的 T = 1000 表示有 1000 个去噪步骤,从 t = T 开始一步步去除噪声,直到生成最终的图像。
2. 迭代去噪过程
- 在第二步,扩散模型逐步去噪,生成更接近真实图像的潜在表示。这是通过逐步减少噪声来实现的,每一步的去噪过程如下:
- 2.1 输入噪声图像到 U-Net,预测噪声:
- 在每个时间步 t ,输入带噪声的图像
。
- 其中,时间步 t 通过时间步嵌入(Time step embedding)传递给 U-Net,以便模型知道当前在去噪过程中的位置。
- 2.2 根据公式去噪:
得到预测的噪声后,通过公式计算出上一时间步的去噪图像
:
这里,
和
是时间步相关的参数,用来控制噪声减少的程度。
是一个从标准正态分布采样的新噪声,用于保持采样的多样性(特别是 DDPM 中使用)。
2.3 重复上述过程:
每一步的去噪过程都会得到一个更清晰的图像表示(噪声逐步减少),直到最后一步 t=1,生成几乎无噪声的图像
3. 输出去噪后的图像
- 最后,当 t=0 时,模型完成所有去噪步骤,输出最终生成的图像
注:
- 在 DDPM 中,采样算法在每个时间步都使用一次,以采样新的高斯噪声,这样的逐步去噪过程增加了生成的多样性。【不确定性采样】
- 在 DDIM 中,采样算法在每一步不需要重新引入随机噪声,而是使用确定性的方式生成图像,因此可以减少生成的时间步数。【确定性采样】
去噪策略(Reverse Diffusion Process):
去噪过程是扩散模型的反向扩散过程,也称为 逆向扩散。在生成阶段,模型从随机噪声图像开始,逐步去除噪声,直到还原出清晰的图像。
去噪的步骤:
- 从纯噪声图像 x_T 开始,模型在每个时间步 t 使用条件生成网络(通常是 U-Net 结构)来预测图像中的噪声,并逐步去除噪声,从而得到图像的潜在表示 x_0。
去噪公式:
在去噪过程中,除了需要用到调度器,还需要用到采样算法,它们的作用:调度算法控制每个时间步去除的噪声比例【速率和幅度】,采样算法(上图反向扩散中的1. 采样高斯噪声)则用于推断每一步如何从当前噪声生成下一步图像,这个过程是不确定的。
常见的调度算法包括:
- 线性调度:噪声去除的比例按线性变化,噪声逐步减少,图像信息逐步恢复。
- 余弦调度:噪声去除比例按余弦曲线变化,初期和末期的去噪较为平滑,中期去噪速度较快。
常见的采样算法包括:
- DDPM(Denoising Diffusion Probabilistic Models):基于马尔可夫链的逐步采样方法,通过每一步从前一步的结果推导出下一步图像。通常需要较多的时间步(如 1000 步)才能生成高质量图像。【不确定性采样】
- DDIM(Denoising Diffusion Implicit Models):与 DDPM 类似,但它不依赖马尔可夫链,允许在更少的时间步内生成图像(如 50 或 100 步),加速了生成过程。
- PLMS(Pseudo Linear Multistep Sampling):通过多步线性预测,进一步加速生成过程,减少时间步数。【确定性采样】
去噪过程是基于预测和采样的:在去噪过程中,模型需要从噪声中恢复图像,这个过程涉及对噪声的预测、采样以及推断。因此,需要使用DDPM、DDIM、PLMS 等采样算法用于去噪过程。
说明:公式推导和解读参考:
Diffusion Model
【4】引入Latent思想让Stable Diffusion模型彻底“进化破圈”
如果说前面讲到的扩散模型相关基础知识是为SD模型打下地基的话,引入Latent思想则让SD模型“一遇风雨便化龙”,成为了AIGC时代图像生成模型的领军者。
那么Latent又是什么呢?为什么Latent有如此魔力呢?
首先,我们已经知道了扩散模型会设置一个迭代次数,并不会像GAN网络那样只进行一次输入和一次输出,虽然扩散模型这样输出的效果会更好更稳定,但是会导致生成过程耗时的增加。
再者,Stable Diffusion出现之前的扩散模型虽然已经有非常强的生成能力与泛化性能,但缺点是不管是前向扩散过程还是反向扩散过程,都需要在像素级的图像上进行,当图像分辨率和Timesteps很大时,不管是训练还是前向推理,都非常的耗时。
而SD模型基于Latent,可以【使用VAE】将这些过程压缩在低维的Latent隐空间,这样一来大大降低了显存占用和计算复杂度,这是常规扩散模型和基于Latent的扩散模型之间的主要区别,也是SD模型火爆出圈的关键一招。
我们举个形象的例子理解一下,如果SD模型将输入数据压缩的倍数设为8,那么原本尺寸为[3,512,512]的数据就会进入[3,64,64]的Latent隐空间中,显存和计算量直接缩小64倍,整体效率大大提升。也正是因为这样,SD模型能够在2080Ti级别的显卡上进行前向推理,生成各种各样精美的图像,大大推动了SD模型的普惠与AI绘画生态的繁荣。
到这里,大家应该对SD模型的核心基础原理有一个清晰的认识了,Rocky这里再帮大家总结一下:
- SD模型是生成式模型:输入可以是文本、文本和图像、以及更多控制条件等,输出是生成的图像。
- SD模型属于扩散模型:扩散模型的特点是生成过程分步化与可迭代,这让整个生成过程更加灵活,同时为引入更多约束与优化提供了可能。
- SD模型是基于Latent的扩散模型:将输入数据压缩到Latent隐空间中,这比起常规扩散模型,大幅提高计算效率的同时,降低了显存占用,成为了SD模型破圈的关键一招。
- 站在AIGC时代的视角,Rocky认为Stable Diffusion本质上是一个优化噪声的AI艺术工具。
在Stable Diffusion模型中,高斯噪声、Schedule算法和Latent隐空间是关键概念:
【本文中的调度算法直接指的就是DDPM高斯噪声的添加和去除,其实本质上不是这样的,本质的调度算法如下】
本文将DDPM列为了一个调度算法,其实DDPM是使用了线性调度器或余弦调度器的扩散架构
3. Latent隐空间:
【DDPM(Denoising Diffusion Probabilistic Models)最初的设计和应用是在图像像素空间中】Stable Diffusion模型并不直接在图像像素空间中操作,而是在一个低维的潜在空间中工作。输入图像通过VAE的 压缩为低维潜在向量,扩散模型在这个隐空间中进行噪声添加和去噪操作,最后通过VAE Decoder将潜在向量解码为图像。Latent空间的使用可以大大减少计算复杂度,同时保持图像生成的质量。
总结:
高斯噪声逐步添加到潜在表示中,通过反向去噪生成图像。
Schedule算法(线性或余弦)控制每个时间步的噪声强度变化。
Latent隐空间通过VAE将图像压缩为低维表示,提升模型生成效率。
这个过程使得Stable Diffusion模型能够高效地生成高质量的图像。
Stable Diffusion训练全过程
Stable Diffusion的整个训练过程在最高维度上可以看成是如何加噪声和如何去噪声的过程,并在针对噪声的“对抗与攻防”中学习到生成图片的能力。
【训练过程 ———》如何加噪声和如何预测噪声的过程】
Stable Diffusion整体的训练逻辑也非常清晰:
- 从数据集中随机选择一个训练样本
- 从K个噪声量级随机抽样一个timestep t
- 将timestep t对应的高斯噪声添加到图片中
- 将加噪图片输入U-Net中预测噪声
- 计算真实噪声和预测噪声的L2损失
- 计算梯度并更新SD模型参数
下图是SD训练过程Epoch迭代的图解:

下图是SD每个训练step的详细图解过程:

下面对SD模型训练过程中的一些关键环节进行详细的讲解。
【1】SD训练集加入噪声
SD模型训练时,我们需要把加噪的数据集输入模型中,每一次迭代我们用random函数生成从强到弱各个强度的噪声【这里写错了,应该是从弱到强】,通常来说会生成0-1000一共1001种不同的噪声强度【0(无噪声)到1001最大噪声强度】,通过Time Embedding嵌入到SD的训练过程中。
Time Embedding由Timesteps(时间步长)编码而来,引入Timesteps能够模拟一个随时间逐渐向图像加入噪声扰动的过程。每个Timestep代表一个噪声强度(较小的Timestep代表较弱的噪声扰动,而较大的Timestep代表较强的噪声扰动),通过多次增加噪声来逐渐改变干净图像的特征分布。
【从 Timestep 0 到 1000,噪声强度是逐步增大的,表示了从无噪声到最大噪声强度的逐步变化。Timestep 越大,加入图像的噪声强度越大。】
下图是一个简单的加噪声流程。首先从数据集中选择一张干净样本,然后再用random函数生成0-3一共4种强度的噪声,然后每次迭代中随机一种强度的噪声,增加到干净图片上,完成图片的加噪流程。

【2】SD训练中加噪与去噪
具体地,在训练过程中,我们首先看一下前向扩散过程,主要是对干净样本进行加噪处理,采用多次逐步增加噪声的方式,直至干净样本转变成为纯噪声。

接着,在前向扩散过程进行的每一步中,SD同样进行反向扩散过程。SD模型在每一步都会预测当前步加入的噪声,不断学习提升去噪能力。
其中,将去噪过程具像化,就得到使用U-Net预测噪声,并结合Schedule算法逐步去噪的过程。
【训练过程中不需要进行去噪,只是预测噪声;只有推理的时候,才需要预测噪声并且去除】【去噪声使用的是Schedule算法和采样算法】

我们可以看到,加噪和去噪过程都是逐步进行的,我们假设进行K步,那么每一步,SD都要去预测噪声,从而形成“小步快跑的稳定去噪”,类似于移动互联网时代的产品逻辑,这是足够伟大的关键一招。
与此同时,在加噪过程中,每次增加的噪声量级可以不同,假设有5种噪声量级,那么每次都可以取一种量级的噪声,增加噪声的多样性,如下图所示:

那么怎么让网络知道目前处于K的哪一步呢?【为什么要知道当前处于 K 的哪一步?K对应实际加入的噪声强度】本来SD模型其实需要K个噪声预测模型,这时我们可以增加一个Time Embedding(类似Positional embeddings)进行处理,通过将timestep编码进网络中,从而只需要训练一个共享的U-Net模型,就让网络知道现在处于哪一步。
我们希望SD中的U-Net模型在刚开始的反向扩散过程中可以先生成一些物体的大体轮廓,随着反向扩散过程的深入,在即将完成完整图像的生成时,再生成一些高频的特征信息。
我们了解了训练中的加噪和去噪过程,SD训练过程就是对每个加噪和去噪过程进行梯度计算,从而优化SD模型参数,如下图所示分为四个步骤:
- 从训练集中选取一张加噪过的图片和噪声强度(timestep),然后将其输入到U-Net中。
- 让U-Net预测噪声(下图中的U-Net Prediction)。
- 接着再计算预测噪声与真实噪声的误差(loss)。
- 最后通过反向传播更新U-Net的权重参数。
为什么没有去噪过程?
- 训练阶段:模型的任务是预测噪声,不进行去噪操作。
- 推理阶段:模型利用训练过程中学到的噪声预测能力,逐步去除噪声,生成图像

完成SD模型的训练,我们就可以用U-Net对噪声图片进行去噪,逐步重建出有效图像的Latent Feature了!
【推理时候】在噪声图上逐步减去被U-Net预测出来的噪声,从而得到一个我们想要的高质量的图像Latent特征,去噪流程如下图所示:

【3】文本信息对图片生成的控制
SD模型在生成图片时,需要输入prompt提示词,那么这些文本信息是如何影响图片的生成呢?
答案非常简单:通过注意力机制。
在SD模型的训练中,每个训练样本都会对应一个文本描述的标签,我们将对应标签通过CLIP Text Encoder输出Text Embeddings,并将Text Embeddings以Cross Attention的形式与U-Net结构耦合并注入,使得每次输入的图片信息与文本信息进行融合训练,如下图所示:

上图中的token是NLP领域的一个基础概念,可以理解为最小语义单元。与之对应的分词操作为tokenization。Rocky举一个简单的例子来帮助大家理解:“WeThinkIn是伟大的自媒体”是一个句子,我们需要将其切分成一个token序列,这个操作就是tokenization。经过tokenization操作后,我们获得["WeThinkIn", "是", "伟大的", "自媒体"]这个句子的token序列,从而完成对文本信息的预处理。
【4】SD模型训练时的输入
有了上面的介绍,我们在这里可以小结一下SD模型训练时的输入,一共有三个部分组成:图片、文本以及噪声强度。其中图片和文本是固定的,而噪声强度在每一次训练参数更新时都会随机选择一个进行叠加。

直接使用噪声强度而去掉时间步 𝑇 不可行的,原因在于时间步 𝑇 并不仅仅是噪声强度的简单表示,它还传达了生成过程的进程信息和结构信息。
【4 属于预测噪声,而不是去噪】
【7 是生成时候才用的,训练时候不需要生成最终图像】
其他主流生成式模型介绍
在AIGC时代中,虽然SD模型已经成为核心的生成式模型,但是曾在传统深度学习时代火爆的GAN、VAE、Flow-based model等模型也跨过周期在SD模型身边作为辅助模型,发挥了巨大的作用。
下面是主流生成式模型各自的生成逻辑:

生成式模型的主流架构
GAN网络在AIGC时代依然发挥了巨大的作用,配合SD模型完成了很多AI绘画算法工作流,比如:图像超分、脸部修复、风格迁移、图像编辑、图像重绘、图像定权等。
简单讲解一下GAN的基本原理。GAN由生成器G和判别器D组成。其中,生成器主要负责生成相应的样本数据,输入一般是由高斯分布随机采样得到的噪声Z。而判别器的主要职责是区分生成器生成的样本与gt(GroundTruth)样本,输入一般是gt样本与相应的生成样本,我们想要的是对gt样本输出的置信度越接近1越好,而对生成样本输出的置信度越接近0越好。与一般神经网络不同的是,GAN在训练时要同时训练生成器与判别器,所以其训练难度是比较大的。
二者互相博弈,随着时间的进行,都会越来越强。在图像生成任务中也是如此,生成器不断生成尽可能逼真的假图像。判别器则判断图像是gt图像还是生成的图像。二者不断博弈优化,最终生成器生成的图像使得判别器完全无法判别真假。
关于Flow-based models,其在AIGC时代的作用还未显现,可以持续关注。
最后,VAE将在本文后面的章节【Stable Diffusion核心网络结构】中详细讲解,因为正是VAE将输入数据压缩至Latent隐空间中,故其成为了SD模型的核心结构之一。
相关文章:
Stable diffusion详细讲解
🌺系列文章推荐🌺 扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新&…...

软件工程期末复习-用例建模
1、为什么需要用例建模 2、用例建模的表示 3、一个例子,ATM用例图 4、什么是用例? 5、用例包含的软件需求 6、参与者的定义 7、交互<->关联 8、用例建模的步骤 9、确定参与者 10、参与者检查项 11、MINILibrary...

【Golang】——Gin 框架中的表单处理与数据绑定
在 Web 应用开发中,表单是用户与服务器交互的重要手段。Gin 框架对表单处理提供了高效便捷的支持,包括数据绑定、验证等功能。在本篇博客中,我们将详细介绍如何使用 Gin 框架处理表单数据,涵盖基础操作与进阶技巧,帮助…...

hive-内部表外部表-详细介绍
1、表类型介绍 内部表: 表面来看,我们建的所有的表,默认都是内部表,内部表又叫做管理表,它的位置也很固定/user/hive/warehouse下面。 外部表: 创建的时候需要加关键字external 修饰,而且&a…...

Windows系统 ElasticSearch,分词器、Kibana安装
目录 1.wins安装ElasticSearch1.下载es安装包2.下载分词器3.注意事项4.学会看报错日志 2.将 elasticsearch 以服务的方式安装安装ES解压到根盘符下,如C或E盘等,因为 E:\Program Files文件夹下的都是默认的只读权限,所以换到没有只读权限&…...
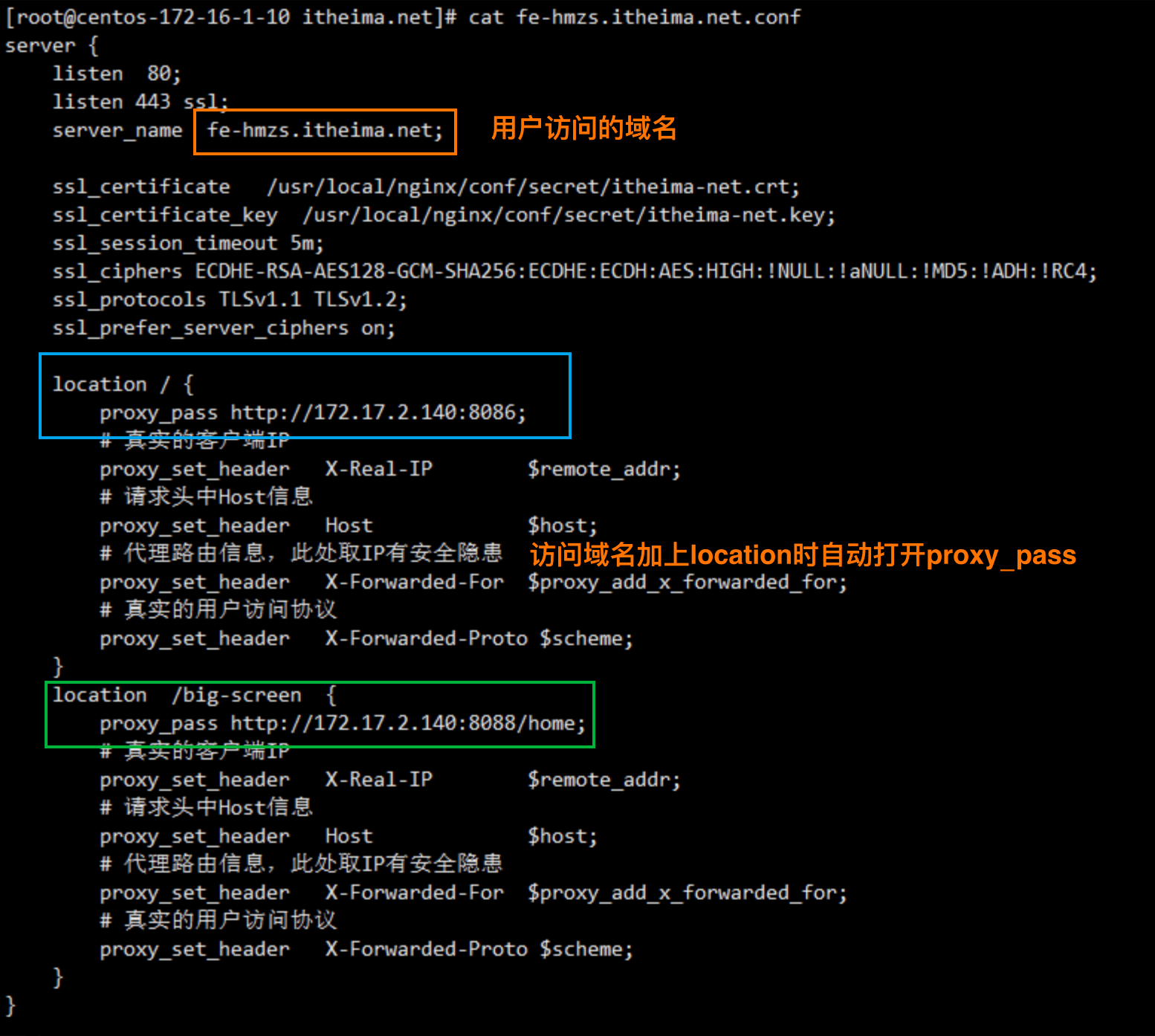
黑马智数Day10
项目背景说明 后台管理部分使用的技术栈是Vue2,前台可视化部分使用的技术栈是Vue3 前台可视化项目不是独立存在,而是和后台管理项目共享同一个登录页面 微前端的好处 微前端是一种前端架构模式,它将大型单体应用程序分解为小的、松散耦合的…...

网络传输:网卡、IP、网关、子网掩码、MAC、ARP、路由器、NAT、交换机
目录 网卡IP网络地址主机地址子网子网掩码网关默认网关 MACARPARP抓包分析 路由器NATNAPT 交换机 网卡 网卡(Network Interface Card,简称NIC),也称网络适配器。 OSI模型: 1、网卡工作在OSI模型的最后两层,物理层和数据链路层。物…...

MySQL45讲 第二十四讲 MySQL是怎么保证主备一致的?——阅读总结
文章目录 MySQL45讲 第二十四讲 MySQL是怎么保证主备一致的?——阅读总结一、MySQL 主备基本原理(一)主备切换流程(二)主备数据同步流程 二、binlog 格式及相关问题(一)binlog 的三种格式&#…...

Visual Studio 圈复杂度评估
VisualStudio自带的有工具 之后就可以看到分析结果...
Springboot之登录模块探索(含Token,验证码,网络安全等知识)
简介 登录模块很简单,前端发送账号密码的表单,后端接收验证后即可~ 淦!可是我想多了,于是有了以下几个问题(里面还包含网络安全问题): 1.登录时的验证码 2.自动登录的实现 3.怎么维护前后端…...

golang调用模组程序实现交互输入自动化,获取imei及iccid
应用场景:在openwrt下调用移远的测试程序,并实现输入自动话,获取imei rootOpenWrt:~# ql-api-test Test groups:0: ql_dsi1: ql_nw2: ql_sim3: ql_dev4: ql_voice5: ql_sms6: ql_adc7: ql_i2c8: …...

ACE之单例
单例簇 使用双重锁检查优化 #mermaid-svg-RMOXQ0KMo0VnJe7V {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-RMOXQ0KMo0VnJe7V .error-icon{fill:#552222;}#mermaid-svg-RMOXQ0KMo0VnJe7V .error-text{fill:#552222…...

泷羽sec学习打卡-云技术基础1-docker
声明 学习视频来自B站UP主 泷羽sec,如涉及侵权马上删除文章 笔记的只是方便各位师傅学习知识,以下网站只涉及学习内容,其他的都与本人无关,切莫逾越法律红线,否则后果自负 关于云技术基础的那些事儿-Base1 一、云技术基础什么是云架构?什么是云服务?什么…...

7天掌握SQL - 第一天:数据库基础与SQL入门
目标 在本章节中,我们将学习数据库的基本概念和SQL语言的基础操作,为后续的深入学习打下坚实的基础。 一级目录 数据库基本概念SQL语言基础SQL操作实践推荐资源总结 1. 数据库基本概念 1.1 表(Table) 表是数据库中存储数据的…...

A037-基于Spring Boot的二手物品交易的设计与实现
🙊作者简介:在校研究生,拥有计算机专业的研究生开发团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 赠送计算机毕业设计600…...

【异常记录】Junitmock之InvalidUseOfMatchersException异常
mock之InvalidUseOfMatchersException异常 新手小白对mock一知半解,就开始自测了,被这个InvalidUseOfMatchersException困扰了一晚上。排查了好久,大多数文章都把英文翻译了一遍,但自检无问题。最后发现是,注入的时候…...

Spring Boot3自定义starter
1、加入必要依赖 plugins {id javaid org.springframework.boot version 3.2.6id io.spring.dependency-management version 1.1.5 } group org.example.test.starter version 1.1.0jar{enabledtrue// resolveMainClassName }java {toolchain {languageVersion JavaLanguage…...

掌控 Solidity:事件日志、继承和接口的深度解析
Solidity 是以太坊智能合约的主要编程语言,它的强大之处在于能够帮助开发者构建安全、高效的去中心化应用。在我参与的多个项目中,事件日志、继承和接口这三个概念始终贯穿其中,成为构建复杂智能合约的关键技术。今天就来聊聊Solidity中的错误…...

新手教学系列——善用 VSCode 工作区,让开发更高效
引言 作为一名开发者,你是否曾经在项目中频繁地切换不同文件夹,打开无数个 VSCode 窗口?特别是当你同时参与多个项目或者处理多个模块时,这种情况更是家常便饭。很快,你的任务栏上挤满了 VSCode 的小图标,切换起来手忙脚乱,工作效率直线下降。这时候,你可能会问:“有…...

Vue3 虚拟列表组件库 virtual-list-vue3 的使用
Vue3 虚拟列表组件库 virtual-list-vue3 的基本使用 分享个人写的一个基于 Vue3 的虚拟列表组件库,欢迎各位来进行使用与给予一些更好的建议😊 概述:该组件组件库用于提供虚拟化列表能力的组件,用于解决展示大量数据渲染时首屏渲…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...