python成长技能之正则表达式
文章目录
- 一、认识正则表达式
- 二、使用正则表达式匹配单一字符
- 三、正则表达式之重复出现数量匹配
- 四、使用正则表达式匹配字符集
- 五、正则表达式之边界匹配
- 六、正则表达式之组
- 七、正则表达式之贪婪与非贪婪
一、认识正则表达式
- 什么是正则表达式
正则表达式(英语:Regular Expression,常简写为regex、regexp或RE),又称正则表示式、正则表
示法、规则表达式、常规表示法,是计算机科学的一个概念 - 正则表达式的作用
正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正
则表达式通常被用来检索、替换那些符合某个模式的文本 - 正则表达式的特点
灵活性、逻辑性和功能性非常强;
可以迅速地用极简单的方式达到字符串的复杂控制
如何在python中使用正则表达式----findall方法
python中,要使用正则表达式,需要导入re模块,基本格式如下:
re.findall(pattern, string, flags=0)
函数参数说明

flags可选值如下

举例,使用findall()方法
import restr = "hello,my name is jie"result = re.findall("jie",str)
print(result)
打印结果
['jie']
在python中使用正则表达式----match方法
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
import restr = "hello,my name is jie"# result = re.findall("jie",str)
# print(result)match = re.match("hello",str)
print(match.group(0))
hello
要获取匹配的结果,可以使用group(n),匹配结果又多个的时候,n从0开始递增
当匹配结果有多个的时候,也可以使用groups()一次性获取所有匹配的结果
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配
import re
s = 'hello world hello'
result = re.search('hello', s)
print(result.group(0))
二、使用正则表达式匹配单一字符
- 使用正则,匹配字符串中所有的数字
import re str = "12hellowordhello12"result = re.findall("\d",str)
print(result)
打印结果
['1', '2', '1', '2']
- 使用正则,匹配字符串中所有的非数字
import re str = "12hellowordhello12"result = re.findall("\D",str)
print(result)
打印结果
['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'd', 'h', 'e', 'l', 'l', 'o']
- 使用正则匹配换页符
import re str = "12hellowordhello12" + chr(12)result = re.findall("\f",str)
print(result)
打印结果
['\x0c']
- 使用正则,匹配换行符
import restr = "hello word my name is jie"
result = re.findall("/n",str)
print(result)
打印结果
[]
三、正则表达式之重复出现数量匹配

- 匹配0次到无限次
import res = "hello world helloo hell"
print(re.findall('hello*', s))
['hello', 'helloo', 'hell']
- 匹配一次或多次
import res = "hello world helloo hell"
print(re.findall('hello+', s))
['hello', 'helloo']
- 匹配零次或一次
import res = "hello world helloo hell"
print(re.findall('hello?', s))
['hello', 'hello', 'hell']
- 匹配n次
import res = "hello world helloo hell helloo hellooo helloo helloo"
print(re.findall('hello{2}', s))
['helloo', 'helloo', 'helloo', 'helloo', 'helloo']
- 匹配至少n次
import res = "hello world helloo hell helloo hellooo helloo helloo"
print(re.findall('hello{2,}', s))
['helloo', 'helloo', 'hellooo', 'helloo', 'helloo']
- 匹配n次以上,m次以下
import res = "hello world helloo hell helloo hellooo helloo helloo"
print(re.findall('hello{2,3}', s))
['helloo', 'helloo', 'hellooo', 'helloo', 'helloo']
四、使用正则表达式匹配字符集

- 如果是连续的范围,可以使用横杠-
import restr = "110,120,130,230,250,160"
result = re.findall("1[1-9]0",str)
print(result)
['110', '120', '130', '160']
- 表示不是某范围之内的,可以使用^取反
import restr = "110,120,130,230,250,160"
result = re.findall("1[^1-9]0",str)
print(result)
[]
五、正则表达式之边界匹配

- 匹配整个字符串开头
import restr = "hello jiejie"result = re.findall("^he",str)
print(result)
['he']
- 匹配整个字符串的结尾位置
import restr = "hello jiejie e e e"result = re.findall("e$",str)
print(result)
['e']
- 匹配单词开头
import restr = "hello jiejie hel"result = re.findall(r'\bhe',str)
print(result)
['he', 'he']
六、正则表达式之组
- 什么是组
将括号:() 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用
- 捕获组(Capturing Groups):
- 使用圆括号 () 定义的组被称为捕获组
- 捕获组可以捕获匹配的部分,并可以在后续的处理中引用这些捕获的内容
- 非捕获组(Non-Capturing Groups):
- 使用 (?:…) 定义的组被称为非捕获组
- 非捕获组不会捕获匹配的部分,仅用于分组和逻辑处理
- 假设我们有一个字符串,包含一些日期格式,如 “2023-10-01”,我们想分别捕获年、月和日
import re# 捕获组示例
text1 = "Today's date is 2023-10-01."
pattern1 = r'(\d{4})-(\d{2})-(\d{2})'
match1 = re.search(pattern1, text1)
if match1:year = match1.group(1)month = match1.group(2)day = match1.group(3)print(f'Year: {year}, Month: {month}, Day: {day}')# 输出结果
Year: 2023, Month: 10, Day: 01
代码解析
- text1:输入字符串,包含日期。
- pattern1:正则表达式模式,用于匹配日期格式。
- (\d{4}):匹配四位数字(年份),并将其捕获为第一个组。
- (\d{2}):匹配两位数字(月份),并将其捕获为第二个组。
- (\d{2}):匹配两位数字(日期),并将其捕获为第三个组。
- re.search(pattern1, text1):在 text1 中搜索与 pattern1 匹配的第一个子串。
- match1.group(1):获取第一个捕获组(年份)。
- match1.group(2):获取第二个捕获组(月份)。
- match1.group(3):获取第三个捕获组(日期)。
- print(f’Year: {year}, Month: {month}, Day: {day}'):打印捕获的年、月、日。
- 假设我们有一个字符串,包含一些电话号码,格式为 “123-456-7890”,我们想匹配这种格式,但不需要捕获每个部分
import retext = "Phone number: 123-456-7890."
pattern = r'(?:\d{3}-){2}\d{4}'match = re.search(pattern, text)
if match:print(f'Matched phone number: {match.group(0)}')# 输出结果
Matched phone number: 123-456-7890
- text2:输入字符串,包含电话号码。
- pattern2:正则表达式模式,用于匹配电话号码格式。
- (?:\d{3}-):匹配三位数字后跟一个连字符,但不捕获这个组(非捕获组)。
- {2}:前面的非捕获组重复两次。
- \d{4}:匹配四位数字。
- re.search(pattern2, text2):在 text2 中搜索与 pattern2 匹配的第一个子串。
- match2.group(0):获取整个匹配的子串(电话号码)。
- print(f’Matched phone number: {match2.group(0)}'):打印匹配的电话号码。
- 假设我们有一个字符串,包含一些重复的单词,我们想找到这些重复的单词
import retext = "This is a test test of repeated repeated words words."
pattern = r'\b(\w+)\b\s+\1\b'matches = re.findall(pattern, text, re.IGNORECASE)
if matches:print(f'Repeated words: {matches}')# 输出结果
Repeated words: ['test', 'repeated', 'words']
- text3:输入字符串,包含重复的单词。
- pattern3:正则表达式模式,用于匹配重复的单词。
- \b:单词边界。
- (\w+):匹配一个或多个字母或数字,并将其捕获为第一个组。
- \b:单词边界。
- \s+:匹配一个或多个空白字符。
- \1:反向引用第一个捕获组,确保匹配的单词相同。
- \b:单词边界。
- re.findall(pattern3, text3, re.IGNORECASE):在 text3 中查找所有与 pattern3 匹配的子串,忽略大小写。
- matches3:包含所有匹配的重复单词。
- print(f’Repeated words: {matches3}'):打印所有重复的单词。
- 假设我们有一个字符串,包含一些日期格式,如 “2023-10-01”,我们想分别捕获年、月和日,并使用命名组
import retext = "Today's date is 2023-10-01."
pattern = r'(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})'match = re.search(pattern, text)
if match:year = match.group('year')month = match.group('month')day = match.group('day')print(f'Year: {year}, Month: {month}, Day: {day}')# 输出结果Year: 2023, Month: 10, Day: 01
- text4:输入字符串,包含日期。
- pattern4:正则表达式模式,用于匹配日期格式。
- (?P\d{4}):匹配四位数字(年份),并将其捕获为名为 year 的组。
- (?P\d{2}):匹配两位数字(月份),并将其捕获为名为 month 的组。
- (?P\d{2}):匹配两位数字(日期),并将其捕获为名为 day 的组。
- re.search(pattern4, text4):在 text4 中搜索与 pattern4 匹配的第一个子串。
- match4.group(‘year’):获取名为 year 的捕获组。
- match4.group(‘month’):获取名为 month 的捕获组。
- match4.group(‘day’):获取名为 day 的捕获组。
- print(f’Year: {year}, Month: {month}, Day: {day}'):打印捕获的年、月、日。
总结:
- 捕获组:使用 () 定义,可以捕获匹配的部分
- 非捕获组:使用 (?:…) 定义,仅用于分组和逻辑处理
- 反向引用:使用 \n 引用第 n 个捕获组
- 命名组:使用 (?P…) 定义,可以按名称引用捕获组
七、正则表达式之贪婪与非贪婪
贪婪匹配
默认情况下,大多数量词都是贪婪的,这意味着它们会尽可能多地匹配字符。例如:
- *:匹配前面的表达式零次或多次
- +:匹配前面的表达式一次或多次
- ?:匹配前面的表达式零次或一次
- {m,n}:匹配前面的表达式至少 m 次,最多 n 次
假设我们有一个字符串,包含一些 HTML 标签,我们想提取标签内的内容
import retext = '<div>Hello</div><div>World</div>'
pattern = r'<div>(.*)</div>'matches = re.findall(pattern, text)
print(matches) # 输出结果
['Hello</div><div>World']
在这个例子中,.* 是贪婪的,它会尽可能多地匹配字符,因此匹配结果是从第一个 < div>到最后一个< /div>之间的所有内容
非贪婪匹配
非贪婪匹配(也称为懒惰匹配)是指量词会尽可能少地匹配字符。非贪婪匹配可以通过在量词后面加上 ? 来实现。例如:
- *?:匹配前面的表达式零次或多次,但尽可能少地匹配
- +?:匹配前面的表达式一次或多次,但尽可能少地匹配
- ??:匹配前面的表达式零次或一次,但尽可能少地匹配
- {m,n}?:匹配前面的表达式至少 m 次,最多 n 次,但尽可能少地匹配
import retext = '<div>Hello</div><div>World</div>'
pattern = r'<div>(.*?)</div>'matches = re.findall(pattern, text)
print(matches) # 输出结果:
['Hello', 'World']
相关文章:
python成长技能之正则表达式
文章目录 一、认识正则表达式二、使用正则表达式匹配单一字符三、正则表达式之重复出现数量匹配四、使用正则表达式匹配字符集五、正则表达式之边界匹配六、正则表达式之组七、正则表达式之贪婪与非贪婪 一、认识正则表达式 什么是正则表达式 正则表达式(英语&…...

解决docker报Error response from daemon Get httpsregistry-1.docker.iov2错误
解决docker报Error response from daemon: Get "https://registry-1.docker.io/v2/"错误 报错详情 首先先看一下问题报错效果,我想要拉去nacos-serve:1.1.4的镜像,报如下错误,从报错信息可以看到,用于网络的愿意&…...

【论文分享】利用多源大数据衡量街道步行环境的老年友好性:以中国上海为例
本次给大家带来一篇SCI论文的全文翻译!该论文考虑了绿化程度、可步行性、安全性、形象性、封闭性和复杂性这六个指标,提出了一种基于多源地理空间大数据的新型定量评价模型,用于从老年人和专家的角度评估街道步行环境的老年友好程度ÿ…...

说说软件工程中的“协程”
在软件工程中,协程(coroutine)是一种程序运行的方式,可以理解成“协作的线程”或“协作的函数”。以下是对协程的详细解释: 一、协程的基本概念 定义:协程是一组序列化的子过程,用户能像指挥家…...

使用IDE实现java端远程调试功能
使用IDE实现java端远程调试功能 1. 整体描述2. 前期准备3. 具体操作3.1 修改启动命令3.2 IDE配置3.3 打断点3.4 运行Debug 4. 总结 1. 整体描述 在做项目时,有些时候,需要和第三方进行调式,但是第三方不在一起,需要进行远程调试&…...

javaScript交互案例2
1、京东侧边导航条 需求: 原先侧边栏是绝对定位当页面滚动到一定位置,侧边栏改为固定定位页面继续滚动,会让返回顶部显示出来 思路: 需要用到页面滚动事件scroll,因为是页面滚动,所以事件源是document滚动…...

JavaScript 浏览器对象模型 BOM
浏览器对象模型(Browser Object Model,BOM)是指一组与浏览器进行交互的 JavaScript 对象。它允许 JavaScript 与浏览器的组件进行交互,比如窗口、文档、历史记录等。BOM 不同于 DOM(文档对象模型)ÿ…...

基于MATLAB的激光雷达与相机联合标定原理及实现方法——以标定板为例
1.为什么要进行激光雷达和相机的联合标定? 激光雷达和相机的联合标定是为了将两种传感器的数据统一到同一坐标系中,从而实现更准确的环境感知。激光雷达提供精准的三维距离信息,而相机捕捉丰富的纹理和颜色,通过联合标定可以结合两…...

React(一)
文章目录 项目地址一、创建第一个react项目二、JSX语法2.1 生成列表2.2 大括号识别JS的表达式2.3 列表循环array2.4 条件判断以及假值显示2.5 复杂条件渲染2.6 事件处理2.7 添加CSS样式2.8 添加图片2.9 使用Fregments返回多个根标签2.10多条件渲染2.11 导出子组件2.12 给子组件…...

Liunx-Ubuntu22.04.1系统下配置Anaconda+pycharm+pytorch-gpu环境配置
这里写自定义目录标题 Liunx-Ubuntu22.04.1系统下配置Anacondapycharmpytorch-gpu环境配置一、Anaconda3配置1.Anaconda安装2.Anaconda更新3.Anaconda删除 二、pycharm配置1.pycharm安装 三、pytorch配置 Liunx-Ubuntu22.04.1系统下配置Anacondapycharmpytorch-gpu环境配置 一…...

Postman之数据提取
Postman之数据提取 1. 提取请求头\request中的数据2. 提取响应消息\response中的数据3. 通过正在表达式提取4. 提取cookies数据 本文主要讲解利用pm对象对数据进行提取操作,虽然postman工具的页面上也提供了一部分的例子,但是实际使用时不是很全面&#…...

selenium元素定位校验以及遇到的元素操作问题记录
页面元素定位方法及校验 使用比较多的是通过id、class和xpath来对元素进行定位。在定位前可以现在浏览器验证是否可以找到指定的元素。这样就不用每添加一个元素定位都运行代码来检查定位方式表达式是否正确。 使用XPATH定位 在浏览器F12,找到元素,在元…...

在AndroidStudio中新建项目时遇到的Gradle下载慢问题,配置错的按我的来,镜像地址不知道哪个网页找的,最主要下载要快
android-studio-2024.2.1.11-windows Android 移动应用开发者工具 – Android 开发者 | Android Developers https://r4---sn-j5o76n7z.gvt1-cn.com/edgedl/android/studio/install/2024.2.1.11/android-studio-2024.2.1.11-windows.exe?cms_redirectyes&met1731775…...

用mv命令替换rm命令
# 用mv命令替换rm命令 主要内容来源自以上博文 rm命令穷凶极恶,以下为替换命令的方式,必做 步骤 修改vim ~/.bashrc加入以下代码 mkdir -p ~/.trash #在家目录下创建一个.trash文件夹(隐藏文件,ls -a 查看) alias rmdel #使用别名…...

电解车间铜业机器人剥片技术是现代铜冶炼过程中自动化和智能化的重要体现
电解车间铜业机器人剥片技术是现代铜冶炼过程中自动化和智能化的重要体现 电解车间铜业机器人剥片技术是现代铜冶炼过程中自动化和智能化的重要体现,它主要应用于铜电解精炼的最后阶段,即从阴极板上剥离出纯铜的过程。以下是该技术的几个关键点ÿ…...
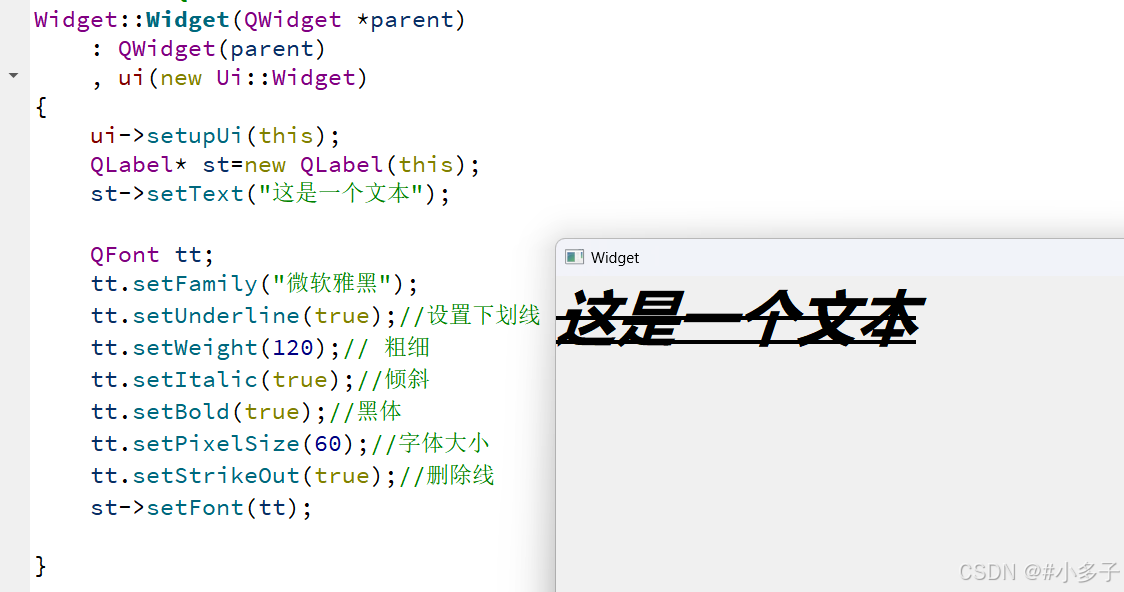
【qt】控件2
1.frameGeometry和Geometry区别 frameGeometry是开始从红圈开始算,Geometry从黑圈算 程序证明:使用一个按键,当按键按下,qdebug打印各自左上角的坐标(相当于屏幕左上角),以及窗口大小 Widget::Widget(QWid…...

Frida反调试对抗系列(四)百度加固
本文只是交流技术,如有侵权请联系我删除。 知识星球:https://t.zsxq.com/kNlj4 前言: 上一篇文章我们提到 我们使用github开源魔改好的frida server 但是仍然有一些厂商的server不能通过,那么这篇文章针对百度加固 进行快速通…...

Redis 安全
Redis 安全 Redis是一个开源的,高性能的键值存储系统,它通常被用作数据库,缓存和消息代理。由于其高性能和简单的API,Redis在全球范围内被广泛使用。然而,与其他数据库系统一样,Redis的安全性也是至关重要…...
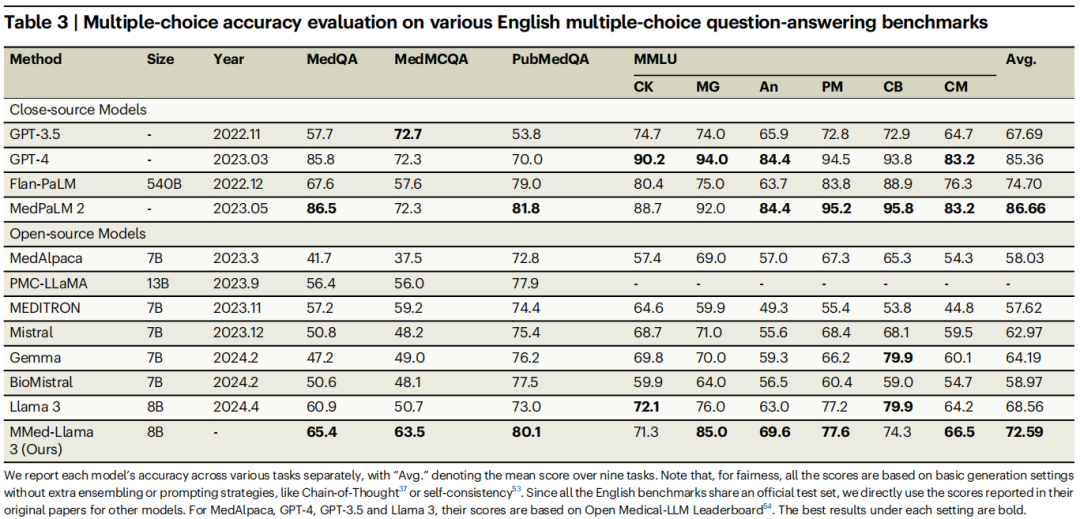
上交大与上海人工智能研究所联合推出医学多语言模型,模型数据代码开源
今天为大家介绍的是来自上海交通大学的王延峰与谢伟迪团队的一篇论文。开源的多语言医学语言模型的发展可以惠及来自不同地区、语言多样化的广泛受众。 来源丨 DrugAI、 机器人的脑电波 论文:https://www.nature.com/articles/s41467-024-52417-z MMedC࿱…...

网络安全:我们的安全防线
在数字化时代,网络安全已成为国家安全、经济发展和社会稳定的重要组成部分。网络安全不仅仅是技术问题,更是一个涉及政治、经济、文化、社会等多个层面的综合性问题。从宏观到微观,网络安全的重要性不言而喻。 宏观层面:国家安全与…...

19 openclaw数据库迁移策略:平滑升级数据库结构
背景/痛点在OpenClaw项目的演进过程中,数据库结构的变更几乎是不可避免的。随着业务需求的迭代,表结构、索引设计、字段类型等都可能需要调整。然而,直接在生产环境执行ALTER TABLE操作往往会导致锁表、性能抖动,甚至服务不可用。…...

5种数字内容访问优化技术:从原理到实战的全方位指南
5种数字内容访问优化技术:从原理到实战的全方位指南 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在信息驱动的数字时代,高效获取优质内容已成为知识工作者的…...

企业级智能客服系统实战:基于RAG与语义检索的架构设计与避坑指南
最近在做一个企业级智能客服系统的项目,客户对传统客服的响应速度和知识更新效率很不满意。我们团队尝试了多种方案,最终决定采用RAG(检索增强生成)结合语义检索的技术路线。今天就来分享一下我们的实战经验,特别是架构…...

StarRocks新手入门:如何用CloudDM个人版快速验证四种数据模型的特点?
StarRocks数据模型实战指南:用可视化工具快速掌握四大核心特性 刚接触StarRocks时,最让人困惑的莫过于四种数据模型的选择。官方文档虽然详细,但缺乏直观对比。本文将带你使用CloudDM个人版,通过同一组测试数据在四种模型下的不同…...
)
用Pyecharts玩转动态图表:Flask整合3种数据源实战教程(CSV/MySQL/Linux集群)
用Pyecharts玩转动态图表:Flask整合3种数据源实战教程(CSV/MySQL/Linux集群) 数据可视化是现代数据分析不可或缺的一环,而将数据以动态、交互式的方式呈现则能极大提升信息传达的效率。对于Python开发者来说,Pyecharts…...
·面经深度解析)
前端八股文面经大全: 蓝色光标前端一面OC(2026-03-23)·面经深度解析
前言 大家好,我是木斯佳。 相信很多人都感受到了,在AI浪潮的席卷之下,前端领域的门槛在变高,纯粹的“增删改查”岗位正在肉眼可见地减少。曾经热闹非凡的面经分享,如今也沉寂了许多。但我们都知道,市场的…...

Audio Flamingo 3:打破模态壁垒的音频智能突破性技术解析
Audio Flamingo 3:打破模态壁垒的音频智能突破性技术解析 【免费下载链接】audio-flamingo-3 项目地址: https://ai.gitcode.com/hf_mirrors/nvidia/audio-flamingo-3 在音频AI领域面临"模态孤岛"困境与长音频理解需求激增的双重挑战下࿰…...

Win11Debloat开源工具深度解析:从系统诊断到性能优化的完整实践
Win11Debloat开源工具深度解析:从系统诊断到性能优化的完整实践 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更改…...

LaWGPT性能优化终极指南:10个技巧让法律AI响应速度翻倍
LaWGPT性能优化终极指南:10个技巧让法律AI响应速度翻倍 【免费下载链接】LaWGPT LaWGPT - 一系列基于中文法律知识的开源大语言模型,专为法律领域设计,增强了法律内容的理解和执行能力。 项目地址: https://gitcode.com/gh_mirrors/la/LaWG…...

安装包制作教程:将Qwen3-ForcedAligner-0.6B打包为Windows应用
安装包制作教程:将Qwen3-ForcedAligner-0.6B打包为Windows应用 1. 引言 如果你用过Qwen3-ForcedAligner-0.6B这个音文对齐工具,肯定知道它有多实用——能精确到毫秒级的时间戳标注,让字幕制作变得轻松简单。但每次都要在命令行里敲代码、配…...