大数据-227 离线数仓 - Flume 自定义拦截器(续接上节) 采集启动日志和事件日志
点一下关注吧!!!非常感谢!!持续更新!!!
Java篇开始了!
目前开始更新 MyBatis,一起深入浅出!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(正在更新…)
章节内容
上节我们完成了如下的内容:
- Flume 自定义拦截器
- 拦截原理 拦截器实现 Java

自定义拦截器
(续接上节,上节已经到了打包的部分)
上传结果
将刚才的打包上传到这个目录下:
我拷贝的是带依赖的:“flume-test-1.0-SNAPSHOT-jar-with-dependencies.jar”
/opt/servers/apache-flume-1.9.0-bin/lib/
测试效果
我们创建刚才说的conf文件:
vim /opt/wzk/flume-conf/flumetest1.conf
编写的内容如下图所示:

启动进行测试:
flume-ng agent --conf-file /opt/wzk/flume-conf/flumetest1.conf -name a1 -Dflume.roog.logger=INFO,console
启动结果如下图所示:

我们启动 telnet 来传入数据:
telnet h122.wzk.icu 9999
启动之后输入数据:
2020-07-30 14:18:47.339 [main] INFO com.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"1","action":"1","error_code":"0"},"time":1596111888529},"attr":{"area":"泰安","uid":"2F10092A9","app_v":"1.1.13","event_type":"common","device_id":"1FB872-9A1009","os_type":"4.7.3","channel":"DK","language":"chinese","brand":"iphone-9"}}此时控制台的数据内容部分为:
4/08/27 15:31:31 INFO source.NetcatSource: Source starting
24/08/27 15:31:31 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/172.16.1.130:9999]
24/08/27 15:32:09 INFO sink.LoggerSink: Event: { headers:{logtime=2020-07-30} body: 32 30 32 30 2D 30 37 2D 33 30 20 31 34 3A 31 38 2020-07-30 14:18 }
对应的截图如下图所示:

采集启动日志(使用自定义拦截器)
配置文件
新建一个配置文件:
vim /opt flume-log2hdfs2.conf
写入的内容如下所示:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# taildir source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/wzk/conf/startlog_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/wzk/logs/start/.*log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = icu.wzk.CustomerInterceptor$Builder
# memorychannel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 2000
# hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/start/dt=%{logtime}/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# 配置文件滚动方式(文件大小32M)
a1.sinks.k1.hdfs.rollSize = 33554432
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 1000
# 使用本地时间
# a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
内容的截图如下所示:

修改的内容如下:
- 给source增加自定义拦截器
- 去掉时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp = true
- 根据header中的logtime写文件
测试运行
flume-ng agent --conf-file /opt/wzk/flume-conf/flume-log2hdfs2.conf -name a1 -Dflume.roog.logger=INFO,console
拷贝日志
修改日志的内容:
vim /opt/wzk/logs/start/test.log
继续写入如下的内容:
2020-07-30 14:18:47.339 [main] INFO com.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"1","action":"1","error_code":"0"},"time":1596111888529},"attr":{"area":"泰安","uid":"2F10092A9","app_v":"1.1.13","event_type":"common","device_id":"1FB872-9A1009","os_type":"4.7.3","channel":"DK","language":"chinese","brand":"iphone-9"}}
写入内容如下图所示:

测试效果
可以看到HDFS上,已经有了读出日志中的时间的内容:

采集启动日志和事件日志
本系统中要采集两种日志:
- 启动日志
- 事件日志
不同的日志放置在不同的目录下,要想一次拿到全部日志需要监控多个目录。

总体思路
- taildir 监控多个目录
- 修改自定义拦截器,不同来源的数据加上不同标志
- HDFS、Sink 根据标志写文件
Agent 介绍
Flume 是一个分布式、高可靠、可用来收集、聚合和传输大量日志数据的系统。在 Flume 的体系结构中,Agent 是一个关键的组件。每个 Agent 是一个独立的 JVM 进程,负责从数据源获取数据并将其传递到下游(如文件系统、数据库、或者另一个 Agent)
Agent 的核心组成部分
Flume Agent 的架构是高度模块化的,它由以下三个核心组件构成:
Source (源)
Source 是数据流的起点,负责接收外部数据。它支持多种数据传输协议和格式,能够从日志文件、网络端口、消息队列等数据源中接收事件。
支持的 Source 类型:
- Avro Source:接收来自其他 Flume Agent 的 Avro 格式数据。
- Syslog Source:处理 Syslog 消息。
- Exec Source:从本地命令或脚本的输出中读取数据。
- HTTP Source:通过 HTTP 接口接收数据。
- Spooling Directory Source:监控特定目录中的文件并读取内容。
Channel (通道)
Channel 是 Agent 的数据缓冲区域,用于在 Source 和 Sink 之间暂存事件。Channel 的设计保证了在数据流动中断(如网络故障)时,数据不会丢失。
常见的 Channel 类型:
- Memory Channel:将事件存储在内存中,速度快,但可能会丢失数据(如果 Agent 崩溃)。
- File Channel:将事件存储在磁盘文件中,提供高可靠性但性能较低。
- Kafka Channel:使用 Kafka 作为中转通道,适合分布式场景。
Sink (接收器)
Sink 是数据流的终点,负责将事件传递到下游存储或处理系统。
支持的 Sink 类型:
- HDFS Sink:将事件写入 Hadoop HDFS。
- Kafka Sink:将事件发送到 Kafka。
- Elasticsearch Sink:将事件写入 Elasticsearch。
- Logger Sink:将事件输出到日志。
- Avro Sink:将事件传递到另一个 Flume Agent 的 Avro Source。
Agent配置
vim /opt/wzk/flume-conf/flume-log2hdfs3.conf
写入的内容如下图所示:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# taildir source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/wzk/conf/startlog_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /opt/wzk/logs/start/.*log
a1.sources.r1.headers.f1.logtype = start
a1.sources.r1.filegroups.f2 = /opt/wzk/logs/event/.*log
a1.sources.r1.headers.f2.logtype = event
# 自定义拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = icu.wzk.LogTypeInterceptor$Builder
# memorychannel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 2000
# hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/%{logtype}/dt=%
{logtime}/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# 配置文件滚动方式(文件大小32M)
a1.sinks.k1.hdfs.rollSize = 33554432
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- filegroups:指定filegroups,可以有多个,以空格分割(taildir source可以同时监控多个目录中的文件)
- headers.filegroups.headerKey
给Event增加header Key,不同的filegroup,可配置不同的value。
相关文章:
大数据-227 离线数仓 - Flume 自定义拦截器(续接上节) 采集启动日志和事件日志
点一下关注吧!!!非常感谢!!持续更新!!! Java篇开始了! 目前开始更新 MyBatis,一起深入浅出! 目前已经更新到了: Hadoop࿰…...

【热门主题】000054 ECMAScript:现代 Web 开发的核心语言
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏关注哦 💕 目录 【热…...
【Pytorch】torch.nn.functional模块中的非线性激活函数
在使用torch.nn.functional模块时,需要导入包: from torch.nn import functional 以下是常见激活函数的介绍以及对应的代码示例: tanh (双曲正切) 输出范围:(-1, 1) 特点:中心对称,适合处理归一化后的数据…...

reactflow 中 useNodesState 模块作用
1. 节点状态管理核心功能 useNodesState是一个关键的钩子函数,用于专门管理节点(Nodes)的状态。节点是流程图的核心元素,它们可以代表各种实体,如流程中的任务、系统中的组件或者数据结构中的元素。 useNodesState提…...

Go语言内存分配源码分析学习笔记
大家好,我是V 哥。GO GO GO,今天来说一说Go语言内存分配问题,Go语言内存分配的源码主要集中在runtime包中,它实现了Go语言的内存管理,包括初始化、分配、回收和释放等。下面来对这些过程详细分析一下,先赞后…...

【jvm】方法区常用参数有哪些
目录 1. -XX:PermSize2. -XX:MaxPermSize3. -XX:MetaspaceSize(Java 8及以后)4. -XX:MaxMetaspaceSize(Java 8及以后)5. -Xnoclassgc6. -XX:TraceClassLoading7.-XX:TraceClassUnLoading 1. -XX:PermSize 1.设置JVM初始分配的永久…...

JAVA环境的配置
首先找到JDK环境的官网。 Java Archive Downloads - Java SE 8u211 and laterhttps://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html 我下载的最后一个x64.exe,下载后,直接双击运行,我这里默认安装到…...

LLM文档对话 —— pdf解析关键问题
一、为什么需要进行pdf解析? 最近在探索ChatPDF和ChatDoc等方案的思路,也就是用LLM实现文档助手。在此记录一些难题和解决方案,首先讲解主要思想,其次以问题回答的形式展开。 二、为什么需要对pdf进行解析? 当利用L…...

MySQL单表查询时索引使用情况
本文针对 MySQL 单表查询时索引使用的几种场景情况进行分析。 假设有一个表如下: CREATE TABLE single_table (id INT NOT NULL AUTO_INCREMENT,key1 VARCHAR(100),key2 INT,key3 VARCHAR(100),key_part1 VARCHAR(100),key_part2 VARCHAR(100),key_part3 VARCHAR(1…...

Qt邮箱程序改良版(信号和槽)
上一版代码可以正常使用,但是会报错 上一篇文章 错误信息 "QSocketNotifier: Socket notifiers cannot be enabled or disabled from another thread" 指出了一个问题,即在非主线程中尝试启用或禁用套接字通知器(QSocketNotifier)…...

入门到精通mysql数据(四)
5、运维篇 5.1、日志 5.1.1、错误日志 错误日志是MySQL中最重要的日志之一,它记录了当mysqld启动和停止,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。 该日志是默认开启的,默认存放目录/var/log…...

Java 设计模式 详解
在Java开发中,设计模式是一种常见的、成熟的解决方案,用于应对特定的设计问题和复杂性管理。以下是一些常用的设计模式,它们可以分为三类:创建型模式、结构型模式和行为型模式。 一、创建型模式 创建型模式主要负责对象的创建&a…...

卡尔曼滤波学习资料汇总
卡尔曼滤波学习资料汇总 其实,当初的目的,是为了写 MPU6050 的代码的,然后不知不觉学了那么多,也是因为好奇、感兴趣吧 有些还没看完,之后笔记也会同步更新的 学习原始材料 【卡尔曼滤波器】1_递归算法_Recursive P…...

linux003.在ubuntu中安装cmake的方法
1.cmake安装程序下载 https://cmake.org/files/v3.30/ 2.解压并下载包 解压cmake压缩包 tar -xvzf cmake.tar.gz进入解压目录 cd cmake-<version>编辑~/.bashrc nano ~/.bashrc在文件的末尾添加如下代码 export PATH/home/xwl/software/cmake/bin:$PATH然后运行以…...

EtherNet/IP转Profinet网关连接发那科机器人配置实例解析
本案例主要展示了如何通过Ethernet/IP转Profinet网关实现西门子1200PLC与发那科搬运机器人的连接。所需的设备有西门子1200PLC、开疆智能Ethernet/IP转Profinet网关以及Fanuc机器人。 具体配置步骤:打开西门子博图配置软件,添加PLC。这是配置的第一步&am…...
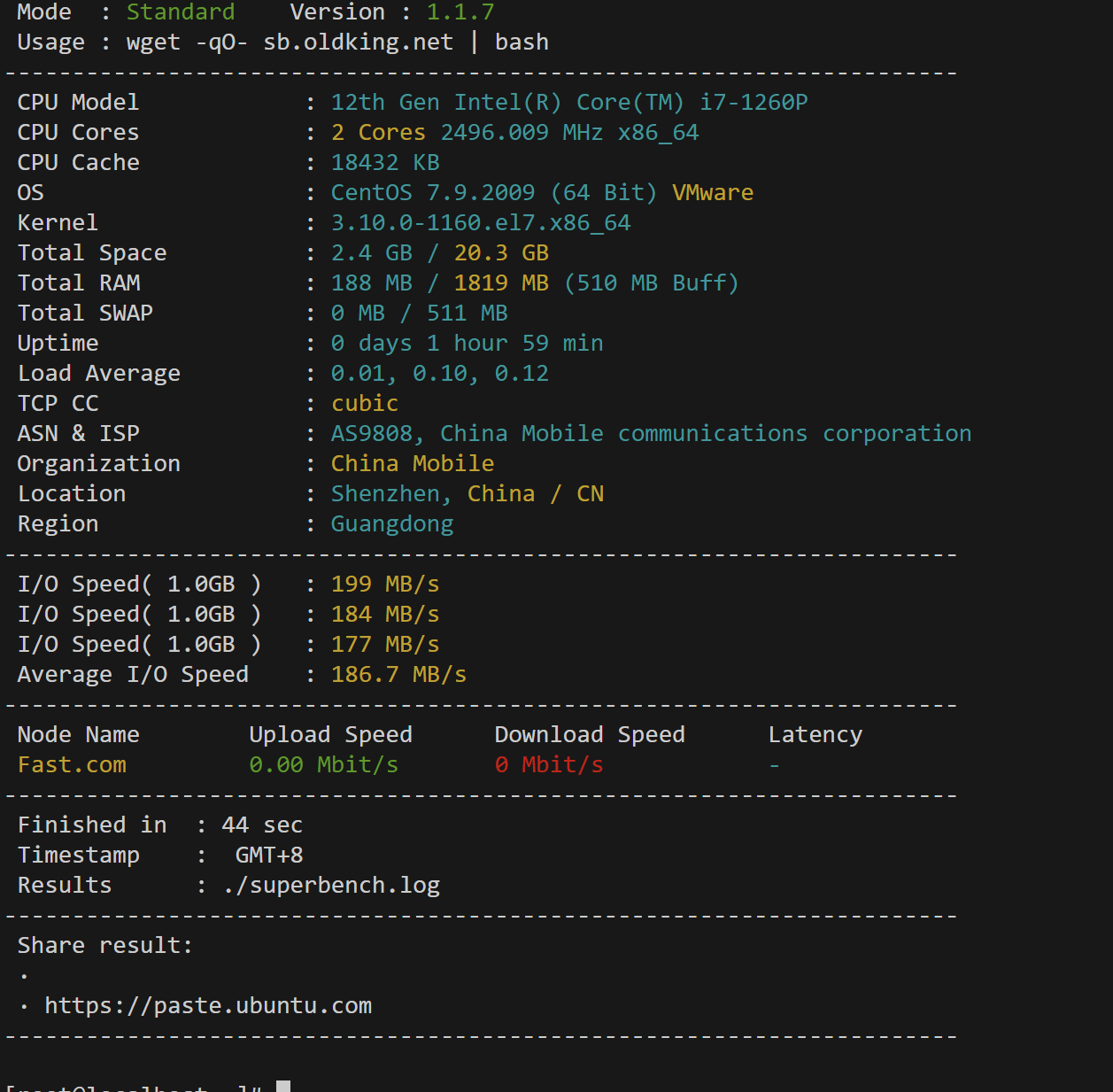
自动化运维-检测Linux服务器CPU、内存、负载、IO读写、机房带宽和服务器类型等信息脚本
前言:以上脚本为今年8月1号发布的,当时是没有任何问题,但现在脚本里网络速度测试py文件获取不了了,测速这块功能目前无法实现,后面我会抽时间来研究,大家如果有建议也可以分享下。 脚本内容: #…...

ubuntu24.04设置开机自启动Eureka
ubuntu24.04设置开机自启动Eureka 之前我们是在/root/.bashrc的文件中增加了一条命令 nohup java -jar /usr/software/eurekaServer-auth-prd-03.jar > /usr/software/log.log 2>&1 &但上面这条命令只有在登录root的用户时,才会执行,如果…...

从视频帧生成点云数据、使用PointNet++模型提取特征,并将特征保存下来的完整实现。
文件地址 https://github.com/yanx27/Pointnet_Pointnet2_pytorch?spm5176.28103460.0.0.21a95d27ollfze Pointnet_Pointnet2_pytorch\log\classification\pointnet2_ssg_wo_normals文件夹改名为Pointnet_Pointnet2_pytorch\log\classification\pointnet2_cls_ssg "E:…...

工化企业内部能源能耗过大 落实能源管理
一、精准监测与数据分析 实时准确的数据采集 企业能耗管理系统能够对企业内各种能源(如电、水、气、热等)的使用情况进行实时监测。通过安装在能源供应线路和设备上的智能传感器,可以精确地采集能源消耗的各项数据,包括瞬时流量、…...

LSTM 和 LSTMCell
1. LSTM 和 LSTMCell 的简介 LSTM (Long Short-Term Memory): 一种特殊的 RNN(循环神经网络),用于解决普通 RNN 中 梯度消失 或 梯度爆炸 的问题。能够捕获 长期依赖关系,适合处理序列数据(如自然语言、时间序列等&…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...