【Python】爬虫实战:高效爬取电影网站信息指南(涵盖了诸多学习内容)
本期目录
1 爬取思路
2 爬虫过程
2.1 网址
2.2 查看网页代码
3 爬取数据
3.1 导入包
3.2 爬取代码
01
爬取思路
\*- 第一步,获取页面内容\*- 第二步:解析并获取单个项目链接 \*- 第三步:获取子页面内容 \*- 第四步:解析子页面相关信息 \*- 第五步:保存json格式数据
02
爬虫过程
2.1 网址
*- 网址``url = 'https://ssr1.scrape.center'`` ``*- 目标` `爬取电影详情内容
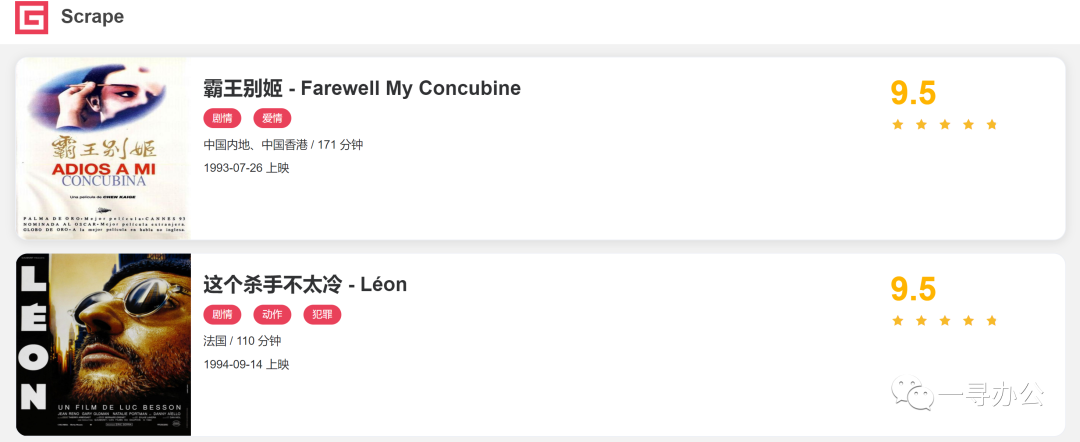

2.2 查看网页代码
*- 网页源代码没有数据``*- 采取正常requests爬取
03
爬取数据
3.1 导入包
import requests``import re``import logging``from lxml import etree``import json``import multiprocessing
3.2 爬取代码
url = 'https://ssr1.scrape.center'``page = 10
*- 爬取函数
def scrape_page(url):` `try:` `response = requests.get(url)` `if response.status_code ==200:` `return response.text` `logging.error(f'get invalid status_code{status_code} while scrape {url}')` `except requests.RequestException:` `logging.error(f'error occurred: {url}',exc_info = True)
*- 获取页面列表
def get_index_url(page):` `index_url = f'{url}/page/{page}'` `return scrape_page(index_url)
*- 解析列表页面获取单个网址:re
`def parse_index(html):` `pattern = re.compile('<a.*?href="(.*?)".*?class="name">')` `items = re.findall(pattern,html)` `for item in items:`` detail_url = url+item` `yield detail_url`
*- 爬取子页面
def scrape_detail(url):` `return scrape_page(url)
*- 解析子页面:xpath
def parse_detail(html):` `tree = etree.HTML(html)` `cover = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[1]/a/img/@src')).replace('\n','').replace(' ','')` `name = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/a/h2//text()')).replace('\n','').replace(' ','')` `categories = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[1]//text()')).replace('\n','').replace(' ','')` `published = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[2]//text()')).replace('\n','').replace(' ','')` `drama = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[2]/div[4]/p//text()')).replace('\n','').replace(' ','')` `score = ''.join(tree.xpath('//*[@id="detail"]/div[1]/div/div/div[1]/div/div[3]/p[1]//text()')).replace('\n','').replace(' ','')` `return {` `'cover':cover,` `'name':name,` `'categories':categories,` `'published':published,` `'drama':drama,` `'score':score` `}
*- 数据保存
def save_data(data):` `name = data.get('name')` `data_path = f'ResultData/{name}.json'` `json.dump(data,open(data_path,'w',encoding='utf-8'),ensure_ascii=False,indent=2)` `print(f'{data_path}处理完成')
*- 主函数
def main():` `for i in range(1,page+1):` `index_html = get_index_url(i)` `detail_urls = parse_index(index_html)` `for detail_url in detail_urls:` `detail_html = scrape_detail(detail_url)`` data = parse_detail(detail_html)` `save_data(data)`` ``if __name__ == '__main__':` `main()


最后学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、100道Python练习题
检查学习结果。


最后,如果你也想自学Python,可以关注我。我会把踩过的坑分享给你,让你不要踩坑,提高学习速度,这套资料涵盖了诸多学习内容:开发工具,基础视频教程,项目实战源码,51本电子书籍,100道练习题等。相信可以帮助大家在最短的时间内,能达到事半功倍效果,用来复习也是非常不错的。

相关文章:
【Python】爬虫实战:高效爬取电影网站信息指南(涵盖了诸多学习内容)
本期目录 1 爬取思路 2 爬虫过程 2.1 网址 2.2 查看网页代码 3 爬取数据 3.1 导入包 3.2 爬取代码 01 爬取思路 \*- 第一步,获取页面内容\*- 第二步:解析并获取单个项目链接 \*- 第三步:获取子页面内容 \*- 第四步:解析…...

MATLAB和C++及Python流式细胞术
🌵MATLAB 片段 流式细胞术(Flow Cytometry)是一种用于分析细胞或其他颗粒悬浮在流动介质中的方法。MATLAB 可以用来处理和分析流式细胞术的数据,例如用于数据预处理、可视化和分析。以下是一些常见的 MATLAB 处理流式细胞术数据的…...

Vue3 pinia使用
Pinia 是一个现代的状态管理库,专为 Vue 3 设计。它提供了一种简单、直观的方式来管理应用中的全局状态 (就是不同组件都希望去共享的一些变量,函数等)。Pinia 的设计灵感来自于 Vuex(Vue 2 的状态管理库),但进行了许多改进&#…...

tdengine学习笔记-建库和建表
目录 建库和建表 创建超级表 创建表 自动建表 创建普通表 多列模型 VS 单列模型 数据类型映射 示例程序汇总 在车联网领域的应用 1. 数据模型概述 2. 表结构设计 2.1 静态数据表 2.2 动态数据表 4. 查询数据 4.1 查询单个车辆的数据 4.2 查询多个…...

Django数据迁移出错,解决raise NodeNotFoundError问题
错误出现在: raise NodeNotFoundError(self.error_message, self.key, originself.origin) django.db.migrations.exceptions.NodeNotFoundError: Migration myApp.0003_alter_jobinfo_practise dependencies reference nonexistent parent node (myApp, 0002_renam…...

景联文科技:以全面数据处理服务推动AI创新与产业智能化转型
数据标注公司在人工智能领域扮演着重要角色,通过提供高质量的数据标注服务,帮助企业和组织训练和优化机器学习模型。从需求分析到数据交付,每一个步骤都需要严格把控,确保数据的质量和安全性。 景联文科技是一家专业的数据采集与标…...

MySQL学习/复习7表的内外连接
一、内连接...

Spring Cloud入门笔记2(OpenFeign)
场景: OpenFeign中集成了LoadBalancer,并简化了微服务调用,所以实际上使用该技术 技术栈:OpenFeign 步骤一:导入依赖 <!--openfeign--> <dependency><groupId>org.springframework.cloud</groupId><a…...

小程序中模拟发信息输入框,让textarea可以设置最大宽以及根据输入的内容自动变高的方式
<textarea show-confirm-bar"{{false}}" value"{{item.aValue}}" maxlength"301" placeholder"请输入" auto-height"{{true}}" bind:blur"onBlurTextarea" focus"{{true}}" bindinput"…...

学习HTML第二十九天
学习文章目录 二.单选框三.复选框 二.单选框 常用属性如下: name 属性:数据的名称,注意:想要单选效果,多个 radio 的 name 属性值要保持一致。 value 属性:提交的数据值。 checked 属性:让该单…...
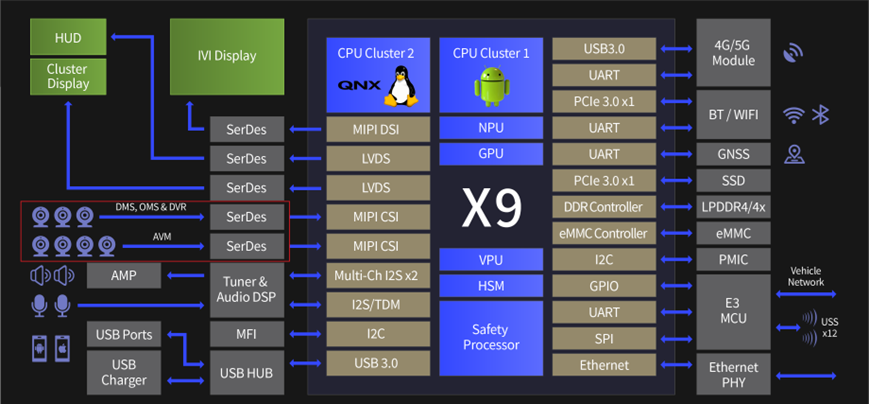
汽车安全再进化 - SemiDrive X9HP 与环景影像系统 AVM 的系统整合
当今汽车工业正面临著前所未有的挑战与机遇,随著自动驾驶技术的迅速发展,汽车的安全性与性能需求日益提高。在这样的背景下,汽车 AVM(Automotive Visual Monitoring)标准应运而生,成为促进汽车智能化和安全…...

QString 转 char*问题与方法(const_cast的使用问题)
1、背景:今天有QString的变量,将QString的值传递给void func(char * ptr),于是就有了类似下面这一段离谱的代码 当时我还在想为什么var的值为空了,为什么呢。 2、原因:就是因为右边函数返回的是一个临时指针对象,给到了右边&…...

flink cdc 应用
SQLServer 1. The db history topic or its content is fully or partially missing. Please check database history topic configuration and re-execute the snapshot. 遇到了一下问题,多次尝试,最终发现是数据库大小写要一致。 Caused by: io.deb…...

MyBlog(三) -- APP的应用
文章目录 前言一、APP是什么?二、创建APP三、使用APP1. 注册app2. 添加路由3. 运行过程4. 完善视图函数5. 结果展示 总结 前言 前面我们已经学习了如何创建一个新的项目,并且配置好了项目的启动文件,成功将项目启动! 那么接下来我们的主要任务就是需要完善这个项目中应该包含…...

docker有哪些网络模式
Docker 提供了多种网络模式(Networking Modes),每种模式都有其特定的用例和优缺点。以下是 Docker 的几种主要网络模式: 1. Bridge 网络(默认) 描述:在这种模式下,Docker 创建了一…...

npoi 如何设置单元格为文本类型
ICellStyle style workbook.CreateCellStyle(); var font workbook.CreateFont(); font.FontHeightInPoints 10; //font.FontName "Arial"; font.FontName "仿宋"; style.Alignment NP…...

Vue3、Vite5、Primevue、Oxlint、Husky9 简单快速搭建最新的Web项目模板
Vue3、Vite5、Oxlint、Husky9 简单搭建最新的Web项目模板 特色进入正题创建基础模板配置API自动化导入配置组件自动化导入配置UnoCss接入Primevue接入VueRouter4配置项目全局环境变量 封装Axios接入Pinia状态管理接入Prerttier OXLint ESLint接入 husky lint-staged…...

DataStream编程模型之数据源、数据转换、数据输出
Flink之DataStream数据源、数据转换、数据输出(scala) 0.前言–数据源 在进行数据转换之前,需要进行数据读取。 数据读取分为4大部分: (1)内置数据源; 又分为文件数据源; socket…...

海康IPC接入TRTC时,从海康中获取的数据显示时色差不正确
2021/1 记录海康IPC接入TRTC时的历史日志 从海康sdk接口获取数据,进行解码 org.MediaPlayer.PlayM4.Player.T_YV12;private void setDecodeCB() {Player.getInstance().setDecodeCB(m_iPort, (nPort, data, nDataLen, nWidth, nHeight, nFrameTime, nDataType,…...

『VUE』31. 生命周期的应用(详细图文注释)
目录 在合适的时间进行操作取dom元素利用生命周期模拟网络数据发送代码示例 总结 欢迎关注 『VUE』 专栏,持续更新中 欢迎关注 『VUE』 专栏,持续更新中 在合适的时间进行操作 假设网页一颗果树,我们要取dom(果实),一定要在渲染完成后才能取(果实) 通常…...

Qwen3.5-9B-AWQ-4bit Node.js环境配置指南:解决npm与模块安装问题
Qwen3.5-9B-AWQ-4bit Node.js环境配置指南:解决npm与模块安装问题 1. 环境准备与快速部署 在开始之前,我们需要确保星图GPU平台的基础环境已经就绪。Qwen3.5-9B-AWQ-4bit模型需要特定的GPU资源支持,而Node.js环境则是我们后续开发的基础。 …...

DeepChat案例分享:供应链异常描述→根因推测→应急方案建议三级输出
DeepChat案例分享:供应链异常描述→根因推测→应急方案建议三级输出 1. 案例背景与场景价值 供应链管理是企业运营的核心环节,但异常情况时有发生。传统的异常处理流程往往需要多个部门协作,耗时耗力且容易出错。DeepChat基于本地部署的Lla…...

【AGI】Harness Engineering 深度解析:AI Agent 时代的工程范式革命
Harness Engineering 深度解析:AI Agent 时代的工程范式革命 引言:当 AI Agent 开始"翻车" 一、什么是 Harness Engineering? 二、Harness Engineering 的三大核心领域 2.1 架构约束:为 AI 划定"奔跑边界" 2.2 反馈闭环:让 AI"自愈"而非&qu…...

光纤收发器指示灯故障排查指南:从状态解析到快速修复
1. 光纤收发器指示灯全解析:你的网络健康晴雨表 刚入行那会儿,我最怕遇到光纤网络故障。直到师傅教我:"看灯!那些小灯泡比网管系统反应还快。"确实,光纤收发器面板上那些彩色指示灯,就像设备的&q…...

使用VSCode高效开发OFA-VE应用
使用VSCode高效开发OFA-VE应用 1. 引言 如果你正在开发OFA-VE视觉蕴含分析应用,那么选择合适的开发工具能让你事半功倍。VSCode作为目前最受欢迎的代码编辑器之一,凭借其丰富的插件生态和强大的功能,能够显著提升你的开发效率。 无论你是刚…...

工业级音频响应式分形火焰生成器:从算法到工程实践
1. 项目概述1.1 背景与动机分形火焰(Fractal Flame)是一种基于迭代函数系统(IFS)的生成艺术,能够产生绚丽多彩、无限复杂的图案。传统实现通常只依赖随机性,缺乏与外部世界的交互。音频信号作为丰富的信息源…...

Z-Image-Turbo-辉夜巫女实战教程:GPU算力弹性伸缩——按需加载LoRA模型
Z-Image-Turbo-辉夜巫女实战教程:GPU算力弹性伸缩——按需加载LoRA模型 1. 快速了解Z-Image-Turbo-辉夜巫女 Z-Image-Turbo-辉夜巫女是基于Z-Image-Turbo模型的LoRA版本,专门优化用于生成辉夜巫女风格图片的AI模型。这个模型通过Xinference框架部署&am…...

汽车牌照数据集 YOLO 目标检测 | 可下载
点击下载数据集~ 关于数据集: 数据集:汽车牌照检测 该数据集包含车牌图像及其对应的YOLO格式标注。它旨在用于训练和评估专注于检测图像中车牌的模型。 数据集概览: 图片总数: 433 张车牌图片 图片格式: .png 标…...

Qwen3-Reranker-0.6B效果展示:中英文跨语言语义重排惊艳案例集
Qwen3-Reranker-0.6B效果展示:中英文跨语言语义重排惊艳案例集 1. 模型能力概览 Qwen3-Reranker-0.6B 是阿里云通义千问团队推出的新一代文本重排序模型,专门为文本检索和排序任务设计。这个模型虽然只有0.6B参数,但在语义相关性判断方面表…...
驱动M25P16 Flash:从SPI时序图到Verilog状态机的保姆级实战)
手把手教你用FPGA(EP4CE6)驱动M25P16 Flash:从SPI时序图到Verilog状态机的保姆级实战
FPGA实战:EP4CE6驱动M25P16 Flash的SPI状态机设计全解析 当我在实验室第一次成功通过FPGA读取到Flash芯片中的数据时,那种成就感至今难忘。对于初学者来说,理解如何将芯片手册中的时序图转化为可运行的Verilog代码,就像学习一门新…...