【网络编程】字节序:大端序和小端序
端序(Endianness),又称字节顺序,又称尾序,在计算机科学领域中,指存储器中或在数字通信链路中,组成多字节的字的字节的排列顺序。
在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如在C语言中,一个类型为int的变量x地址为0x100,那么其对应地址表达式&x的值为0x100。且x的四个字节将被存储在存储器的0x100, 0x101, 0x102, 0x103位置。
计算机硬件的字节的排列方式有两个通用规则:
- 大端序(Big-endian):将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址。这种排列方式与数据用字节表示时的书写顺序一致,符合人类的阅读习惯。
- 小端序(Little-Endian),将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序。小端序与人类的阅读习惯相反,但更符合计算机读取内存的方式,因为CPU读取内存中的数据时,是从低地址向高地址方向进行读取的。因为计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
在计算机内部,小端序被广泛应用于现代 CPU 内部存储数据;而在其他场景,符合人类的习惯还是读写大端字节序,所以,除了计算机的内部处理,其他的场景下几乎都是大端字节序,比如网络传输和文件存储。
在网络应用中,字节序是一个必须被考虑的因素,因为不同机器类型可能采用不同标准的字节序,所以均按照网络标准转化。例如假设上述变量x类型为int,位于地址0x100处,它的值为0x01234567,地址范围为0x100~0x103字节,其内部排列顺序依赖于机器的类型。大端序从首位开始将是:0x100: 0x01, 0x101: 0x23, 0x102: 0x45, 0x103: 0x67。而小端序将是:0x100: 0x67, 0x101: 0x45, 0x102: 0x23, 0x103: 0x01。
上面的文字描述有点抽象,举个例子:
大端序:
//对于一个整数 0x12345678,在内存中的存储顺序是:
地址: 0 1 2 3
数据: 12 34 56 78//网络协议通常采用大端序(例如,TCP/IP)。
小端序:
//对于一个整数 0x12345678,在内存中的存储顺序是:
地址: 0 1 2 3
数据: 78 56 34 12//大多数现代PC(如x86架构)使用小端序。
在内存中存放整型数值168496141 需要4个字节,这个数值的对应的16进制表示是0X0A0B0C0D,这个数值在用大端序和小端序排列时的在内存中的图示更易于理解:

字节序的作用
了解字节序对于数据存储和处理非常重要,理解字节序有助于调试跨平台应用和网络协议。在数据处理时,在不同字节序的系统间传输数据时,需转换字节序以确保正确性。
由于计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读第一个字节,再读第二个字节。如果是大端字节序,先读到的就是高位字节,后读到的就是低位字节。小端字节序正好相反。
字节序的处理,只有读取的时候,才必须区分字节序,其他情况都不用考虑。
处理器读取外部数据的时候,必须知道数据的字节序,将其转成正确的值。然后,就正常使用这个值,完全不用再考虑字节序。即使是向外部设备写入数据,也不用考虑字节序,正常写入一个值即可。外部设备会自己处理字节序的问题。
将数据的外部格式 (文件格式、网络协议、硬件寄存器)转换为内部格式 (软件操作的数据结构)的过程实际上比你想象的要困难得多。黑客利用的软件漏洞大多也是由于解析错误造成的。由于程序员没有正式学习解析,他们自己摸索,创建了容易出错的临时解决方案。例如,程序员假设外部缓冲区不能大于内部缓冲区,从而导致缓冲区溢出。 因此, 外部格式必须定义明确。第一个字节的含义必须写在某处,然后是第二个字节的含义,依此类推。
假如说,传递或存储一个整数,定义必须包括大小、有符号/无符号、位的含义(几乎总是 2 的补码)和字节顺序。超过取值范围0~255的整数则必须用多个字节表示。这些字节是从左到右还是从右到左称为字节顺序。 我们也称之为字节序,一种形式是大端序 ,另一种形式是小端序。
在 1970 年代,当 CPU 只有几千个逻辑门时,小端序对于逻辑电路来说可以更高效。因此,许多内部处理都是小端序的,并且这也渗透到外部格式中。
另一方面,大多数网络协议和文件格式仍然是大端序的。因为格式规范是为人类理解而编写的,大端序对我们人类来说更容易阅读和理解。
因此,一旦理解了外部格式中的字节顺序问题,下一个问题就是弄清楚如何解析它,将其转换为内部数据结构。首先,我们必须要了解它是如何解析的:
解析有两种方式:缓冲或流式传输。
- 在缓冲模型中,你首先读入整个输入(例如整个文件或整个网络数据包),然后解析它。
- 在流式传输模式下,你一次读取一个字节,解析该字节,然后读取下一个字节。流式传输模式最适合非常大的文件或跨 TCP 网络连接的流式传输数据。
缓冲解析是大多数人使用的一般方法。假设你已经将文件(或网络数据)读入我们称为buf的缓冲区。你在当前偏移量处解析该缓冲区 ,直到到达末尾。
假设如此,我们在处理器中读入一个16位整数。如果是大端字节序,就按下面的方式转成值。那么解析大端序 整数x 的方式 就是以下代码行:
x = buf[offset] * 256 + buf[offset+1];// buf是整个数据块在内存中的起始地址,offset是当前正在读取的位置。第一个字节乘以256,再加上第二个字节,就是大端字节序的值。
或者,也可以使用逻辑运算符的形式进行改写,则按以下方式执行:
x = buf[offset]<<8 | buf[offset+1];
// 第一个字节左移8位(即后面添8个0),然后再与第二个字节进行或运算。
编译器始终将 2 的幂乘法转换为移位指令,因此两个语句都会执行相同的操作。某些编译器足够智能,可以将此模式识别为解析整数,并且可能会将其替换为从内存中加载两个字节并进行字节交换。
对于外部数据中的小端序整数,你可以反转解析方式,例如以下两个语句之一。
x = buf[offset+1] * 256 + buf[offset];
x = buf[offset] + buf[offset+1] * 256;
32位整数的求值公式也是一样的:
/* 大端字节序 */
i = (data[3]<<0) | (data[2]<<8) | (data[1]<<16) | (data[0]<<24);/* 小端字节序 */
i = (data[0]<<0) | (data[1]<<8) | (data[2]<<16) | (data[3]<<24);
对于 JavaScript、C# 或其他一些语言而言,关于字节序的讨论到此就结束了。但如果你使用的是 C/C++,我们还需要处理一些额外的问题。因为 C 的问题在于它是一种低级语言。这意味着它向程序员公开了整数的内部格式。换句话说,上面的代码关注整数的外部表示,而不关心内部表示。它并不关心你使用的是 x86 小端序 CPU 还是某些 RISC 大端序 CPU。
但在 C语言 中,你可以依靠内部 CPU 表示来解析整数。它看起来类似于以下内容:
x = *(short*)(buf + offset);
这段代码在小端序机器和大端序机器上产生了不同的结果。
如果两个字节分别为 0x22 和 0x11,那么在大端序机器上会产生一个值为0x2211的短整数,但小端序机器会产生值为0x1122。如果外部格式是大端序,那么在小端序机器上,你必须对结果进行字节交换。
那么,代码看起来像是:
x = *(short*)(buf + offset);#ifdef LITTLE_ENDIANx = (x >> 8) | ((x & 0xFF) << 8);#endif
当然,我们不会这样写代码。相反,你应该使用宏,如下所示:
x = ntohs(*(short*)(buf + offset));
该宏表示network-to-host-short,其中 网络 字节序为大端字节序,主机 字节序未定义。在小端字节序主机 CPU 上,字节交换方式如上所示。在大端字节序 CPU 上,该宏未定义任何内容。该宏在标准套接字库(如 <arpa/inet.h>)中定义。其他库中还有大量用于字节交换整数的类似宏。
事实上,这并不是真正的做法,一次解析一个整数。相反,程序员要做的是定义一个与 他们试图解析的外部格式相对应的 打包 C 结构,然后将 缓冲区 转换为该 结构。
例如,在 Linux 中,包含文件<netinet/ip.h>定义了Internet协议头:
struct ip {
#if BYTE_ORDER == LITTLE_ENDIAN u_char ip_hl:4, / *请求头长度* /ip_v:4; / *版本* /
#endif
#if BYTE_ORDER == BIG_ENDIAN u_char ip_v:4, /*版本*/ip_hl:4; /*请求头长度 */
#endifu_char ip_tos; /* 服务类型 */short ip_len; /* 总长度 */u_short ip_id; /* 标识*/short ip_off; /*片段偏移量字段*/u_char ip_ttl; /*生存时间 */u_char ip_p; /* 协议 */u_short ip_sum; /* 校验和* /struct in_addr ip_src,ip_dst; / *源和目标地址* /
};
要“解析”协议头,需要执行以下操作:
strict ip *hdr = (struct ip *)buf;printf("checksum = 0x%04x\n", ntohs(ip->ip_sum));
这被认为是“优雅”的执行方式,因为根本没有“解析”。在 big-endian CPU 上,它也是一个无操作——它精确地花费零指令来“解析”协议头,因为内部和外部结构都完全映射。
然而,在 C 中,结构的确切格式未定义。结构成员之间通常会有填充,以使整数在自然边界上对齐。因此,编译器有指令将结构声明为“packed”以摆脱这种填充,这严格定义内部结构以匹配外部结构。
然而,这是错误的做法。因为它仅仅在 C 中是可能的,但这并不代表它是个好主意。
有些人认为它的效率可以更快。它并不是真的更快了。如今,即使是低端 ARM CPU 也非常快,深度管道也带来了多重问题。决定其速度的往往是分支预测错误和长链依赖性等因素。指令数量几乎是事后才考虑的。因此,在外部数据之上“零开销”映射结构与一次解析一个字节之间的性能优化差异几乎是无法估量的。
另一方面,存在“正确性”成本。C 语言中,没有定义强制转换整数的结果,正如上例所示。所以,这里有一个笑话提到:“可以接受擦除整个硬盘的行为,却不是返回预期的两字节数字。”
在现实世界中,未定义的代码会导致编译器问题,因为它们试图优化问题。有的时候,重要的代码行会从程序中删除,因为编译器严格解释 C 语言 标准的规则。在 C 中使用未定义的行为确实会产生未定义的结果——与程序员的预期完全相反。
一次解析一个字节的结果是定义的。转换整数和结构的结果不是。因此,应该避免这种做法。它使编译器感到困惑。它使试图验证代码正确性的静态和动态分析器感到困惑。
此外,实际问题是转换这些东西会让程序员感到困惑。程序员 相当了解解析外部格式,但混合内部/外部字节序会导致无尽的混乱。它会导致有缺陷的代码无穷无尽。 它会导致屎山代码无穷无尽。许开源代码中同样是如此,以正确方式解析整数的代码始终比使用ntohs()等宏的代码更容易阅读。这样的代码混乱且容易出现各种问题,困惑的程序员不断地来回交换整数,不理解到底发生了什么,并且只要函数的输入顺序错误,就简单地添加另一个字节交换。
所以,字节序也是一个解析器问题,处理外部数据格式/协议。在 C/C++ 中处理它的方式与在 JavaScript、C# 或任何其他语言中相同。这样的处理方式是最优的。
还有一种字节序的错误方式,这是 C/C++ 中的 CPU 问题,将内部和外部结构混合在一起,交换字节。多年以来,这造成了无尽的麻烦。
所以,我们也需要停止旧方法并采用新方法。
在C语言中实现大端序和小端序的转换,可以使用按位操作:
#include <stdio.h>// 交换端序的函数
unsigned int swap_endian(unsigned int num) {return ((num >> 24) & 0xFF) | // 将 字节3 移动到 字节0((num << 8) & 0xFF0000) | // 将 字节1 移动到 字节2((num >> 8) & 0xFF00) | // 将 字节2 移动到 字节1((num << 24) & 0xFF000000); // 将 字节0 移动到 字节3
}int main() {unsigned int original = 0x12345678;unsigned int swapped = swap_endian(original);printf("Original: 0x%x\n", original);printf("Swapped: 0x%x\n", swapped);return 0;
}//使用移位和按位与操作,将各字节重新排列
//应用场景:
// 在需要处理不同字节序的数据时使用,比如网络通信或文件读写。
了解字节序的意义
了解字节序的意义在于确保数据在不同计算机系统之间能够正确地传输和解释。字节序决定了多字节数据类型(如整数、浮点数)在内存中的存储顺序。
跨平台兼容性问题,不同系统可能使用不同的字节序,了解字节序可以避免跨平台数据传输中的错误;在网络通信中,网络协议通常采用大端序(网络字节序),需要在发送和接收数据时进行转换。在数据存储中,在文件中存储多字节数据时,使用一致的字节序可以确保在不同平台上读取时一致。对开发人员而言,知道系统的字节序,在调试开发低级别代码时能够理解数据的内存布局。
理解和正确处理字节序是系统编程、网络编程和跨平台开发中的一个重要环节。
正因为以上种种原因,所以才有了字节序。
我们在阅读代码时,也不需要搞得这么底层,大部分时候,我们只需要知道计算机处理字节序的时候,如果是大端字节序,先读到的就是高位字节,后读到的就是低位字节。小端字节序则正好相反。
以上。
我是一个十分热爱技术的程序员,希望这篇文章能够对您有帮助,也希望认识更多热爱程序开发的小伙伴。
感谢!
相关文章:
【网络编程】字节序:大端序和小端序
端序(Endianness),又称字节顺序,又称尾序,在计算机科学领域中,指存储器中或在数字通信链路中,组成多字节的字的字节的排列顺序。 在几乎所有的机器上,多字节对象都被存储为连续的字…...

视频融合×室内定位×数字孪生
随着物联网技术的迅猛发展,室内定位与视频融合技术在各行各业中得到了广泛应用。不仅能够提供精确的位置信息,还能通过实时视频监控实现全方位数据的可视化。 与此同时,数字孪生等技术的兴起为智慧城市、智慧工厂等应用提供了强大支持&#…...

RK3568平台开发系列讲解(platform虚拟总线驱动篇)注册 platform 驱动
🚀返回专栏总目录 文章目录 一、注册 platform 驱动二、platform_driver 结构体沉淀、分享、成长,让自己和他人都能有所收获!😄 一、注册 platform 驱动 platform_driver_register 函数用于在 Linux 内核中注册一个平台驱动程序。 下面是对该函数的详细介绍: 函数原型…...
杀掉Tomcat的几种方法)
Jmeter进阶篇(26)杀掉Tomcat的几种方法
📚Jmeter性能测试大全:Jmeter性能测试大全系列教程❤,这里有你想要的一切,欢迎订阅哦~ 📚前言 Tomcat 是一个广泛使用的开源 Java Servlet 容器,用于部署和运行 Java Web 应用程序。在我们进行压测测试过程中,很可能遇到被测系统崩溃,需要我们来操作一下子Tomcat的情…...

Solana 区块链的技术解析及未来展望 #dapp开发#公链搭建
随着区块链技术的不断发展和应用场景的扩展,性能和可拓展性成为各大公链竞争的关键因素。Solana(SOL)因其高吞吐量、低延迟和低成本的技术特性,在众多区块链项目中脱颖而出,被誉为“以太坊杀手”之一。本文将从技术层面…...
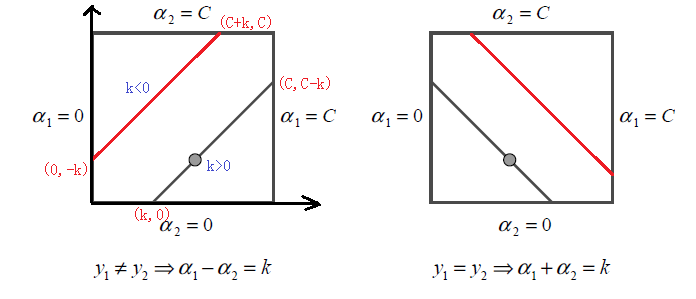
SMO算法-核方法支持向量机
我们现在的问题是要优化目标函数,同时求出参数向量 α \alpha α P m i n ⏟ α 1 2 ∑ i 1 , j 1 m α i α j y i y j K ( x i , x j ) − ∑ i 1 m α i s . t . ∑ i 1 m α i y i 0 0 ≤ α i ≤ C P\underbrace{ min }_{\alpha} \frac{1}{2}\sum\li…...

Java项目实战II基于微信小程序的科创微应用平台(开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。获取源码联系方式请查看文末 一、前言 随着科技的…...

HTTP代理是什么,有什么用?
在互联网的世界里,数据采集已经成为许多企业和个人获取信息的重要手段。而在这个过程中,HTTP代理则是一个不可或缺的工具。那么,HTTP代理究竟是什么?它在数据采集中又有什么用呢?今天,我们就来深入探讨一下…...

Postman之newman
Postman之newman 1.基础环境node安装1.1.配置环境变量1.2.安装newman和html报告组件 2.newman运行 newman可以理解为,没有命令行的postman,把写好的测试脚本直接在命令行中运行,newman依赖于node环境,因此,需要先安装好…...

数据库查询表结构和数据量以及占用空间
数据库查询表结构和数据量以及占用空间 数据库查询表结构 mysql SELECT COLUMN_NAME 列名, COLUMN_TYPE 数据类型, DATA_TYPE 字段类型, CHARACTER_MAXIMUM_LENGTH 长度, IS_NULLABLE 是否为空, COLUMN_DEFAULT 默认值, COLUMN_COMMENT 备注 FROM INFORMATION_SC…...

android 性能分析工具(03)Android Studio Profiler及常见性能图表解读
说明:主要解读Android Studio Profiler 和 常见性能图表。 Android Studio的Profiler工具是一套功能强大的性能分析工具集,它可以帮助开发者实时监控和分析应用的性能,包括CPU使用率、内存使用、网络活动和能耗等多个方面。以下是对Android …...

vscode 执行 vue 命令无效/禁止运行
在cmd使用命令可以创建vue项目但是在vscode上面使用命令却不行 一、问题描述 在 cmd 中已确认vue、node、npm命令可以识别运行,但是在 vscode 编辑器中 vue 命令被禁止,详细报错为:vue : 无法加载文件 D:\Software\nodejs\node_global\vue.…...

C++语言系列-STL容器和算法
C语言系列-STL容器 容器类 本文将对C语言中的标准模板库STL容器进行简单介绍,重点在于如何使用。 容器类 STL中的容器包括以下类别: vector: 动态数组,底层基于数组来实现,在容量不足的时候能够自动进行扩容。list: 链表stack: …...

【Web前端】Promise的使用
Promise是异步编程的核心概念之一。代表一个可能尚未完成的操作,并提供了一种机制来处理该操作最终的成功或失败。具体来说,Promise是由异步函数返回的对象,能够指示该操作当前所处的状态。 当Promise被创建时,它会处于“待定”&a…...

TDK推出第二代用于汽车安全应用的6轴IMU
近日,据外媒报道,TDK株式会社推出用于汽车安全应用的第二代6轴 IMU,即为TDK InvenSense SmartAutomotive MEMS传感器系列增加了IAM-20685HP和IAM-20689,为决策算法提供可靠的运动数据,并实时准确地检测车辆动态。这对于…...
免费S3客户端工具大赏
首发地址(欢迎大家访问):S3免费客户端工具大赏 1. S3 GUI GitHub地址:https://github.com/aminalaee/s3gui 简介:S3 GUI 是一款基于 Flutter 构建的免费开源 S3 桌面客户端,支持桌面、移动和网络平台。 特…...

前端访问后端实现跨域
背景:前端在抖音里做了一个插件然后访问我们的后端。显然在抖音访问其他域名肯定会跨域。 解决办法: 1、使用比较简单的jsonp JSONP 优点:JSONP 是通过动态创建 <script> 标签的方式加载外部数据,属于跨域数据请求的一种…...

TCP和UDP通信基础
目录 1. 套接字 (Socket) 2. 基于TCP通信的流程 服务器端 客户端 1. TCP通信API 1.1 创建套接字描述符socket 1.2 绑定IP和端口号bind 1.3 设置监听状态 listen 1.4 接受连接请求 accept 1.5 发送数据 send 1.6 接收数据 recv 2. TCP服务器代码示例 代码解释&…...

微服务中的技术使用与搭配:如何选择合适的工具构建高效的微服务架构
一、微服务架构中的关键技术 微服务架构涉及的技术非常广泛,涵盖了开发、部署、监控、安全等各个方面。以下是微服务架构中常用的一些技术及其作用: 1. 服务注册与发现 微服务架构的一个重要特性是各个服务是独立部署的,因此它们的地址&am…...

找出字符串第一个匹配项的下标
找出字符串第一个匹配项的下标 题目描述: 题解思路: 图上所示,利用字符滑动,如果匹配就字符开始移动;如果不匹配成功,则停止移动,并回到字符串刚开始匹配的字符下标前一个,为下一次…...

Cursor 的 .cursorrules 终极配置指南:写出让 AI 秒懂项目的规则文件
分类:前端工具 | 标签:Cursor、cursorrules、AI编程、前端开发、效率提升 作为前端工程师,用好 Cursor 能显著提升开发效率。而 .cursorrules(以及新版 .cursor/rules/)就是让 AI 真正「懂」你项目的关键。本文从概念、语法、到 Vue3/React/小程序等不同技术栈的配置,再到…...

黑丝空姐-造相Z-Turbo在网络安全领域的模拟应用:生成测试用例图像
黑丝空姐-造相Z-Turbo在网络安全领域的模拟应用:生成测试用例图像 最近和几个做安全测试的朋友聊天,他们都在抱怨同一个问题:做系统健壮性测试,尤其是人脸识别或者界面安全测试的时候,找合适的测试数据太麻烦了。要么…...

3个革命性技术让旧显卡焕发新生:开源性能加速工具OptiScaler全面解析
3个革命性技术让旧显卡焕发新生:开源性能加速工具OptiScaler全面解析 【免费下载链接】OptiScaler DLSS replacement for AMD/Intel/Nvidia cards with multiple upscalers (XeSS/FSR2/DLSS) 项目地址: https://gitcode.com/GitHub_Trending/op/OptiScaler 面…...

HY-MT1.5-1.8B翻译模型部署实战:从环境搭建到API调用
HY-MT1.5-1.8B翻译模型部署实战:从环境搭建到API调用 1. 引言 1.1 为什么选择HY-MT1.5-1.8B翻译模型 在全球化交流日益频繁的今天,高效准确的机器翻译已成为企业和个人不可或缺的工具。HY-MT1.5-1.8B作为腾讯混元团队推出的轻量级翻译模型,…...

Gemma-3-12B-IT入门教程:从Gemma-1到Gemma-3演进,12B-IT为何更懂人类指令
Gemma-3-12B-IT入门教程:从Gemma-1到Gemma-3演进,12B-IT为何更懂人类指令 1. 引言:为什么你需要关注Gemma-3-12B-IT? 如果你正在寻找一个既强大又容易上手的AI助手,那么今天要聊的Gemma-3-12B-IT绝对值得你花时间了解…...

【鸿蒙PC命令行移植适配】rsync 三方库鸿蒙化适配后在鸿蒙PC运行的完整实践
欢迎加入 开源鸿蒙跨平台开发者社区,与大家一起共建鸿蒙化 C/C 三方库生态。 1. 前言 本教程面向 C/C 开发者,带你完成 rsync 三方库的鸿蒙平台适配,并能够在鸿蒙PC上进行验证。 通过本教程,你将掌握: 使用 lycium…...

比话降AI的售后有多靠谱?真实退款经历分享
比话降AI的售后有多靠谱?真实退款经历分享 写这篇文章不是为了给比话打广告。是因为我在找降AI工具的过程中踩了不少坑,最后在比话这里的体验确实让我觉得值得记录一下。特别是关于售后这块——大部分人选降AI工具只看价格和效果,但等到出了问…...

Qwen3-32B-Chat私有化部署案例:金融研报摘要生成服务API封装
Qwen3-32B-Chat私有化部署案例:金融研报摘要生成服务API封装 1. 项目背景与价值 在金融行业,每天都会产生大量研究报告,分析师需要花费大量时间阅读和提炼关键信息。传统的人工摘要方式效率低下,且难以保证一致性。Qwen3-32B作为…...
)
避开这3个坑!微信小程序引导关注公众号的最佳实践(附PHP代码)
微信小程序与公众号用户体系深度整合实战指南 在移动互联网生态中,微信小程序和公众号作为两大核心产品形态,各自具备独特的优势。小程序以轻量便捷著称,公众号则以内容沉淀和用户触达见长。本文将深入探讨如何通过技术手段实现两者的无缝衔接…...

基于 PLC 的罐装控制系统开发之旅
基于plc的罐装控制系统,S7-1200称重包装采用西门子博途编程,wincc组态仿真,包括IO表,电气原理图,接线图,程序。 组态,仿真,报告 博途V13sp1编程,高版本都可以打开在工业自…...