51c自动驾驶~合集30
我自己的原文哦~ https://blog.51cto.com/whaosoft/12086789
#跨越微小陷阱,行动更加稳健
目前四足机器人的全球市场上,市场份额最大的是哪个国家的企业?A.美国 B.中国 C.其他

波士顿动力四足机器人

云深处 绝影X30 四足机器人
🎉答案选B,是中国!各位具身人选对了么?
冷知识:中国的宇树科技以一己之力,已经占到全球四足机器人市场的销量份额约69%,已超过美国的波士顿动力!此外,而另一家以四足机器人见长的企业--云深处科技在四足机器人的全球市场上规模仅次于宇树机器人和波士顿动力,位列第三。
四足机器人,也常被称为四足机器人或四足行走机器人,是一种模仿动物四足行走方式的机器人。它们通常具有四个可移动的腿,能够在多种地形上行走,包括不平坦的地面、楼梯、斜坡等,能够执行复杂的动态动作,如跳跃、奔跑和快速转向。这使得它们在搜索救援、探索未知环境、以及在人类难以到达的地方执行任务时非常有用。同时,四足机器人也会搭载传感器和智能算法,能够实现一定程度的自主导航和决策。
宇树科技 Go2 四足机器人 图源:https://www.xiaohongshu.com/discovery/item/66e5cfbf00000000270071ca?source=webshare&xsec_token=ABhXNEtdRFD8RjMgqyf-_pu-0WhKu5XUccd64ANGQ_A1M=&xsec_source=pc_share
四足机器人日渐成熟的今天,仍有一些场景有待突破。来自清华大学交叉信息研究院赵行老师团队的新成果,一作是Shaoting Zhu。研究的内容很有趣:四足机器人如何越过微小障碍?文章信息如下:
Robust Robot Walker: Learning Agile Locomotion over Tiny Traps https://arxiv.org/html/2409.07409v2 Corresponding author. E-mail: zhaohang0124@gmail.com
人类和动物能在复杂环境中稳健行走,依靠本体感觉来避开各种障碍物,如绳子、杆子和地面坑洞。然而,这些挑战对机器人来说却极为困难。在现实场景中,看似微小的陷阱也会对机器人的移动性产生严重影响。如图2所示,许多这样的障碍物都很小或位于机器人下方或后方,使得它们很难被深度摄像头等外部传感设备探测到。窄条或杆子之类的小物体在深度图像中往往会产生不可靠的数据,表现为间歇性的噪声或零距离处的密集区域,使其与其他障碍物的边缘噪声难以区分。
此外,由于真实RGB图像无法在模拟中准确呈现,因此在实际应用中会受到仿真到现实差距的限制。这引发了开发控制策略的需求,使机器人能够不依赖额外的传感设备就能克服此类陷阱型障碍物。
为了解决使用本体感觉在微小陷阱上学习敏捷运动的挑战,文章提出了一种具有几个关键贡献的新颖解决方案。
首先,文章引入了一个完全依赖于本体感觉的两阶段训练框架,可以在模拟和真实世界环境中成功通过微小的陷阱。
其次,文章开发了一种显式-隐式双态估计范式,利用接触编码器来估计不同机器人链接上的接触力,并利用分类头来增强接触表示的学习。
第三,文章将任务重新定义为目标跟踪,而不是速度跟踪,并纳入了精心设计的密集奖励函数和假目标命令。这种方法无需在现实世界中使用动作捕捉或其他定位技术即可实现近似的全向运动,显著提高了训练的稳定性和跨环境的适应性。
最后,文章为微小的陷阱任务引入了一个新的基准,并在模拟和真实场景中进行了广泛的实验,证明了文章方法的稳健性和有效性。
任务定义
该任务被定义为穿过一系列微小的陷阱,机载摄像头通常无法检测到此类陷阱。这些陷阱主要分为三种类型:横杆、坑洞和立杆,如图4所示。横杆是指位于四足机器人头部高度以下的平面上的水平细杆。坑洞是两个平面之间的小凹陷,可能导致机器人腿部打滑,并且从正常的前视图看不到。立杆是直立在平面上的细杆。在遇到这些陷阱时,机器人会接收到恒定的控制命令,并必须自主调整速度以通过它们。
奖励函数
该奖励函数由三个主要部分组成:任务奖励(Task Reward)、正则化奖励(Regularization Reward)和风格奖励(Style Reward)。总奖励是三项之和。
任务奖励:包括目标奖励(鼓励机器人朝向目标移动,随机器人当前位置与目标位置之间的距离减小而增大)、朝向奖励(确保机器人在接近目标时能够正确地对准目标方向,目的是确保机器人在水平或向后方向上遇到陷阱时,以直线或小角度偏移通过陷阱)、完成奖励(当机器人接近目标时,鼓励机器人保持静止)。
正则化奖励:用于优化机器人的性能,防止训练过程中出现的各种问题(如抖动、不稳定等),包括惩罚不必要的停止、速度限制、保持平衡等。
风格奖励:使用对抗性运动先验 (AMP) 风格的奖励,旨在使机器人的运动更加自然和高效。
如何训练和部署
- 训练:采用了两阶段概率退火选择 (PAS) 框架,而不是传统的师生模仿学习方法。第一阶段学习并优化在完全信息下的控制策略,第二阶段使策略适应在部分信息下的工作情况,并减少因信息缺失导致的性能下降。
- 第一阶段使用显式-隐式双态学习机制,通过接触编码器将接触力编码为隐式潜变量,并与显式特权状态一起构成双态。引入分类头来指导策略学习接触力分布与陷阱类别之间的联系,这有助于策略理解不同陷阱的特性。目标是训练一个高性能的“Oracle”策略,该策略在完全信息下能够有效处理各种陷阱。
- 第二阶段通过概率退火选择(PAS)机制,逐步减少策略对特权状态信息的依赖,同时保持策略性能。
- 部署:
- 生成假目标命令:通过遥操作生成假的目标命令,包括恒定的 ΔG 和 Δt 值。这些命令用于指导机器人在环境中的运动方向。
- 使用估计器和低层Actor RNN:利用在第一阶段和第二阶段训练好的估计器模块和低层Actor RNN,结合来自机器人传感器的proprioception信息,预测双态并生成控制动作。
- 实现近似全向移动:由于精心设计的任务奖励函数及其比例,策略学会了基于距离到目标的不同移动策略(如大距离时先原地旋转面向目标,中等距离时同时转向和前进,小距离时直接移动)。这种能力使得机器人能够在没有运动捕捉或其他辅助定位技术的情况下,实现近似全向移动。
- 执行任务:机器人开始从左侧出发,通过小型陷阱(如Bar、Pit、Pole),最终到达右侧的目标位置,完成任务。
让四足机器人跨越小型陷阱的实验开展模拟实验
文章首先进行了一个模拟实验,设计了一个 Tiny Trap Benchmark:有一个 5m ×60m 的跑道,三种类型的陷阱沿路径均匀分布。陷阱包括 10 个高度从 0.05 米到 0.2 米不等的杆子、50 个随机放置的杆子和 10 个宽度从 0.05 米到 0.2 米不等的坑。对于每个实验,都会部署 1000 个机器人,从跑道左侧开始,穿过所有陷阱到达右侧。文章将其称为 “Mix” 基准测试(包括 “Bar”、“Pit” 和 “Pole” 三种陷阱)。此外,还有单独的 “Bar”、“Pit” 和 “Pole” 基准测试,每个基准测试都专注于一种特定类型的 Trap,但 Trap 的数量增加了三倍。
该基准测试使用三个指标:Success Rate(成功率)、Average Pass Time(平均通过时间)和 Average Travel Distance(平均行驶距离)。如果机器人在 300 秒内到达目标点的 0.2m 范围内,则认为机器人成功,此时文章记录其通过时间。故障情况包括从跑道上掉下来、卡住或翻车。对于失败的情况,通过时间设置为最长 300 秒。然后,文章计算总体成功率和平均通过时间。在评估结束时,文章平均所有机器人的横向移动距离。在评估过程中,文章使用与实际部署中相同的假目标命令来指导机器人保持在中心。
各种训练方法如下:
• Ours(w/o goal command):使用传统的速度指令,但仅训练向陷阱前进的动作。
• Ours w/ Boolean:不使用编码器,直接将布尔值的碰撞状态输入到低级RNN中。其他设置与我们的方法相同。
其余为参考文献中的其他方法:
• RMA:在师生训练框架中,一维卷积神经网络(1D-CNN)作为异步适应模块。
• MoB:“学习一种单一策略,该策略编码一系列结构化的运动策略,以不同的方式解决训练任务。”
• HIMLoco:“HIM仅通过对比学习明确估计速度,并隐式地将系统响应模拟为隐式潜在嵌入。
如表1所示,文章的方法在所有指标上都优于其他方法。如表2所示,在消融实验中,利用所有关节链接的策略在 “Mix” 上表现最好,在其他基准测试中表现相对较好。这证明了每个关节的接触力有助于提高策略性能。
真实实验
可视化结果如图 7 所示。1) 杠铃:机器人在接触杠铃后学会了前腿后退。即使后腿被故意困住,机器人仍然可以检测到碰撞并将其后腿抬过横杆。2) 坑:当一条腿踏入虚空时,机器人学会用其他三条腿支撑自己的身体,将悬空的腿抬出坑。此外,机器人还学会了在多条腿卡在坑中时用力踢腿爬出。3) 杆:机器人在与杆子碰撞后学会向左或向右回避,避开杆子一定距离后再向前移动。
对于每项测试,重复进行 20 次试验并计算成功率。图6显示了成功率随着各种尺度的陷阱的变化。与其他基线相比,文章的方法获得了最佳性能。使用 velocity 命令的方法也很好。这是因为在训练中只采用前向速度命令,而不是传统的全向速度,这大大提高了性能。
我们还表明,当布尔值碰撞状态直接被发送到低级Actor RNN时(Ours w/ Boolean),机器人在部署时会面临严重的模拟到现实的差距(sim-to-real gap),如摩擦和电机阻尼。当差距出现时,潜在空间将产生一些噪声。布尔值状态的潜在空间非常稀疏,如图11所示,这将导致策略更容易误判当前状态并操作不规则。如图9所示,当机器人在平面上向前移动并突然停止一小段时间时,差距出现,估计的碰撞状态上升到较大值。如果我们此时让机器人后退,机器人会认为它撞到了陷阱。由于实际上没有陷阱,机器人可能会碰到地面甚至摔倒。在引入接触力和接触编码器后,模拟到现实的差距得到缓解。机器人可以更好地识别陷阱并更稳定地操作。
其他实验
此外,作者还做了其他模拟实验,证明了作者提出的方法在不同方面的有效性,包括假目标命令对性能的影响、不同运动模式的生成、策略对障碍的识别和响应能力,以及状态空间中不同输入的重要性。
(1) 不同Δt(完成任务所需的剩余时间)的假目标命令对性能的影响:实验测试了通过一个0.2米高的障碍时,恒定的Δt在[3,5]范围内可以获得最佳性能。过大或过小的Δt值会降低性能,可能是由于在中间范围内的样本较少。
(2) 不同ΔG(ΔG=(Δx,Δy,Δz)=(dis⋅cosθ,dis⋅sinθ,0),目标位置相对于当前位置的距离)的假目标命令如何导致不同的运动模式:θ为表示目标位置相对于当前位置的方位的角度。
(3) 使用t-SNE方法可视化了通过每个障碍时估计的双状态。如图11,结果显示,作者发现使用分类头和接触力的方法能够在可视化中清晰地区分不同类型的陷阱和接触状态(不同颜色的点区分为不同区域),具有更可分和连续的编码,这表明了该方法能够有效地编码和区分不同的环境特征。
(4) 通过计算雅可比矩阵并归一化结果,分析了状态空间中每个输入的重要性。结果显示,接触力估计和每个关节链接的重要性被突出显示,其中基座链接最为关键,而其他链接显示出相似的重要性。这些结果强调了接触力估计的关键作用以及每个关节链接的重要性。
可以看到,文章通过将机器人链接上的接触力引入模型架构,并将学习任务定义为目标跟踪,已经很大程度上使机器人跨越微小陷阱时行动更为稳健。目前对于四组机器人,开发能够适应各种复杂地形和动态环境的高效运动控制算法、处理机器人的多体动力学和平衡问题仍然是一个挑战。此外,提高机器人的感知、认知和自主决策能力、在复杂环境中进行更精确的自主导航和避障、提高能源效率、以及改善人机交互也是四足机器人的未来发展方向。
#面向感知的决策规划介绍
我觉的来看这篇文章的人应该是相关从业人员,所以决策规划是什么以及为什么要做决策规划就先不做赘述。
- 组织架构
- 从入门到放弃
视频学习顺序:
- https://space.bilibili.com/631671239/channel/collectiondetail?sid=992923
- https://space.bilibili.com/287989852?spm_id_from=333.337.search-card.all.click
- https://space.bilibili.com/325034144?spm_id_from=333.337.0.0
2.1 坐标系
FreeNet与笛卡尔
FreeNet优劣势
优势:
- 在弗莱纳坐标系下做运动规划的好处在于借助于指引线做运动分解,将高维度的规划问题,转换成了多个低维度的规划问题,极大的降低了规划的难度。
- 另外一个好处在于方便理解场景,无论道路在地图坐标系下的形状与否,我们都能够很好的理解道路上物体的运动关系。相较直接使用地图坐标系下的坐标做分析,使用弗莱纳坐标,能够直观的体现道路上不同物体的运动关系。
劣势:
XY坐标系下的规划器能力:为什么是xy,freenet的投影问题:
- 投影有误差
- 变量没有实际物理意义,算出来的cost有问题,
- nudge场景:sl投影nudge膨胀,导致求解失败,xy最原始,贴合实际场景可以求解,
- 大曲率弯道,SL曲率有误差会影响车辆居中甚至会碰撞RB
对于轨迹生成,我认为在XY坐标系下,基于车辆运动学或再加动力学得到轨迹的方法更优。通过减少求解信息,达到减少耗时,提高限定时间内成功求解的概率;减少坐标系转换带来的损失。
Frenet高精度坐标转化需要使用优化算法,否则就可能存在厘米级误差,这会被城市场景中的决策判断放大。在Frenet下的障碍物筛选也没有XY下精度高,为了安全,只能提高冗余量,牺牲决策判断。
kd tree查点
笛卡尔:车道宽度,横向都可以解决
横向规划和纵向规划
速度规划的 s沿着轨迹的方向,路径规划的 s沿着参考线的方向。
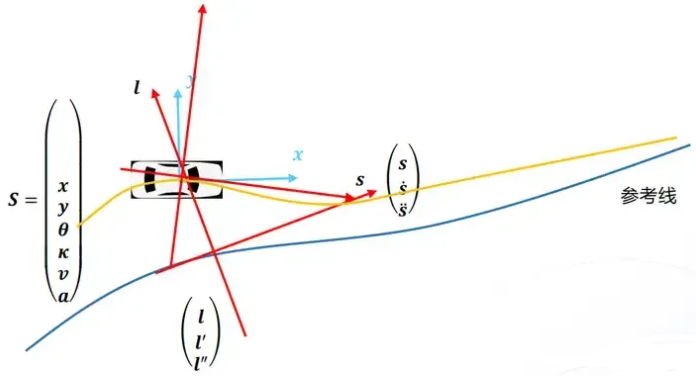
左手坐标系和右手坐标系
左右顺时针为正,右手逆时针为正,注意0轴的定义
https://blog.csdn.net/zhouqiping/article/details/124522367
3. 预测3.1 方案
DenseTNT需要四五十ms,改进后8ms。vectornet前半部分+denseTNT的轨迹输出部分
当前位置到目标位置:通过BFS搜索路径
3.2 现有问题
- 点的概率会有问题
- argoverse数据集偏高速,导致实际场景的点的位置比较远
- 原有数据集没有的场景轨迹预测结果会较差,比如T型路口等
4. 环境模型4.1 routing
- 比较稳定,A*
- 车道级导航算法开发(非高精地图):采用AStar算法搜索2km路径,用于少变多选道、导航变道和路口选道。目前保定100km,北京泛化超过2000Km,选道成功率和导航变道触发率均在95%以上。
不同供应商的数据格式定义可能不同:



4.2 pnc map (lane graph)4.2.1 Perception lane
- 无高精地图路口建模功能:
最大的问题还是强依赖与车道线平行假设。
基于SDPro地图进行路口建模,目前直行路口和少变多场景采用三次曲线、左右转采用五段式曲线(直线段、螺旋线、圆弧、螺旋线、直线段)
a. SD PRO vs HDMap:1m内,道路中心点dot_point,车道属性,有几个车道,宽度,得到拓扑map
b. routing:道路级导航,车道级导航(高德)1.映射到SDPro;2.车道级,起点是当前车道,终点无须指定,最早变道点,最晚变道点(点+buffer),右边有车卡会减速变道 road->segment->;
c. 左右转采用五段式曲线,如何保证分检点连续:转弯半径不变
d. 成功率:根据kappa是否满足最小转弯半径,R500m是个坎
- 输入:感知车道线,sd pro
- 输出:1.变道,2.laneid, 2变3,routing选用cost:车道中心线heading
- 红绿灯控车和红绿灯绑路:
红绿灯也是bbox,通过距离去匹配,匈牙利匹配。难点在于2匹1或者1匹2等存在感知或者地图丢失的情况。
主要根据灯箱的航向区分看哪组灯箱,以及根据车道箭头信息进行子灯颜色分类。根据灯的颜色进行决策,在上游稳定的情况下,控车成功率达到95%以上。
- 普通道路跟踪策略:
- 利用车道线平行假设,利用消失点计算pitch。为什么不用高精度定位的pitch?
- 对观测到的散点进行关键点BA优化,
- 对c0\1\2\3,width宽度进行滤波跟踪
- 多变少\少变多:
一般是车道线偏右,此时关键是要识别出远处(10-40m)的新增车道线,以进行点到点的连接。看不见新增的线(感知对线段起点有近距离要求?),会先往右打再往左打。
虚拟车道生成(无SDPro地图)应对场景:直行路口、道路分流合流场景(少变多、多变少)以及拥堵场景。主要分为跟车和跟线。
- 输入:感知车道线和障碍物
- 输出:local车道线
a. 跟车模式和跟线切换:看和线的距离
- 视觉感知车道线与EHR的融合:增减车道;高精地图的类型滞后;heading补偿(通常是0.3);
4.2.2 HDMap
1 问题比较多,建议与视觉感知做融合
- 弯道点不够密
- 匝道处和曲率大弯道定位不准
- 匝道的时候,定位不准,单点rtk,依赖视觉线
- heading偏差一般是两个原因:1.标定,定位装置/天线和车辆的标定 2.坐标系转换,wgs84转UTM坐标系存在畸变误差
- 定位的heading问题排查方法:画出车辆历史轨迹,然后和heading的线对比
- 怎么消除wgs84转utm时的误差 heading问题通过set_origin解决
- 匝道合入主路时地图要给全,防止左后方的车辆
- 定位偏还是控制偏:看时间戳,谁先震荡的,定位可以通过planning确认
- 怎么识别汇入口、分叉口:pre succ 所有车道的拓扑关系,难点在于哪些可换道,哪些不可以换道:通过图商给的host/subhost、 merge_left/right 、split_left/right
- merge点不准;导航变道不准;参考线偏;
- DR要退出系统,但是不要轻易进入DR
2.1.1 限速问题
2.1.2 虚实线问题
2.1.3 施工问题
2.1.4 匝道问题
2.1.5 隧道桥下树下等遮挡场景
xx只能DR5s(递推)
2.1.6 heading偏
- 标定误差:走直线标定
- 坐标转换误差:set_oring
2.1.7 方向乱晃yaw不准
检查惯导、RTK等硬件
2.2 地图质检模块的
专门需要修复层fix layer:十个图层,拓扑关系,lane、road;中心线起点终点的连续性;交通灯的判断生成停止墙
前后继点对不上的问题是由于可以允许1mm的误差:点连续性是因为utm 转换后有畸变造成,把阈值从0改为1mm就可以了;
offset个别会出现超过10(之前设置的是10);还有一个是脚本错误码14写错了
新的检测脚本做了如下改动:1. offset 10->20, 2. 允许前后继节存在1mm误差,做出以上调整按理说错误信息多应该消失了
策略点:指引线平滑程度以及指引线的偏移策略点,比如最右的车道往左偏,避免频繁减速
黑名单:奇怪的位置,尽量不去偏远的地方,不去某些lane_id;
哪里的指引线,以及怎么偏移:最右侧,容易减速
2.3特殊点处理
贝塞尔曲线的链接,
消亡车道的处理
merge/split处理
2.4用到的数据结构:
center line,左右boundary,拓扑类型,后继车道,form/to_path_id,
3.SDmap
十字路口的重建:利用dot点,五次多项式螺旋曲线拟合
3.1 打断的规则
分界有几个原因:1.车道数目发生变化 2.车道拓扑关系发生变化 3.车道边界属性发生变化 4.限速 5.类型和颜色
就是保证了每个打断内的每根线属性不会变化
4.3 参考线生成
一些参考:
https://blog.csdn.net/sinat_52032317/article/details/128386386
https://blog.csdn.net/weixin_65089713/article/details/128855681
https://blog.csdn.net/ChenGuiGan/article/details/124633387
https://github.com/YannZyl/Apollo-Note/blob/master/docs/planning/reference_line_provider.md
4.3.1 多参考线生成
该项目对于车道行驶过程中除了当前车道参考线外,给出了(可能的)左右两条车道参考线。并且,每条参考线给出了换道类型、换道距离等信息,并将地图元素(汇入口、分叉口、公交车道等)绑定到参考线中。其目的在于帮助下游决策模块实现扩大行驶范围,扩大借道范围,避免急刹和碰撞风险等功能。在实际运营过程中,参考线数量增多至原先的1.8倍。
绑定hdmap元素,overlap属性位置等, sl坐标,l怎么确认:地图给
4.3.2 参考线平滑:
参考线平滑是有必要的,如果使用优化算法来光滑,个人感觉大材小用(不排除后续path求解强耦合很平滑的参考线,此处没有量化分析过)。个人感觉参考线平滑使用拟合就够了。
https://zhuanlan.zhihu.com/p/371585754
https://zhuanlan.zhihu.com/p/565854845
- knots分段与二次规划进行参考线平滑:osqp不等式约束条件,cost,在已知box内优化,特殊点的平滑
1.1 预处理
通过第一阶段路径点采样与轨迹点矫正,可以得到这条路径的anchor_point集合,将anchor_point分成n组(n+1个knot节点),每组用一个多项式函数去拟合,可以得到n个多项式函数
默认5m一个anchor,每段qp_spline(knot)是25m,
1.2 设置约束条件
- 需要拟合的多项式函数数量为2*num_spline个,每两个knots之间会拟合x和y两个多项式
- 多项式最高阶数为5(qp_spline.spline_order: 5),所以每个多项式共6个参数,参数总和:(spline_order+1)2num_spline
- 使用每个段内的anchor point去拟合多项式函数,自变量范围[0,1],应变量相对于第一个anchor point的相对坐标。所以最后拟合出来的函数f和g的结果是相对于第一个anchor point的相对坐标。
那么在拟合过程中还需要满足一些约束,包括等式约束和不等式约束,例如:
- 预测的x'和y'需要保证在真实x和y的L轴lateral_bound、F轴longitudinal_bound领域内
- 第一个anchor point的heading和函数的一阶导方向需要一致,大小可以不一致,但是方向必需一致!
- x和y的n段函数之间,两两接壤部分应该是平滑的,两个函数值(位置)、一阶导(速度)、二阶导(加速度)必须一致。
1.3 cost函数计算
平滑度,长度,相对原始点偏离度
平滑度:FemPosSmooth相对不精准,但是只需用二次规划能快速求解
- CosThetaSmooth相对精准,但是需要非线性规划,计算量大
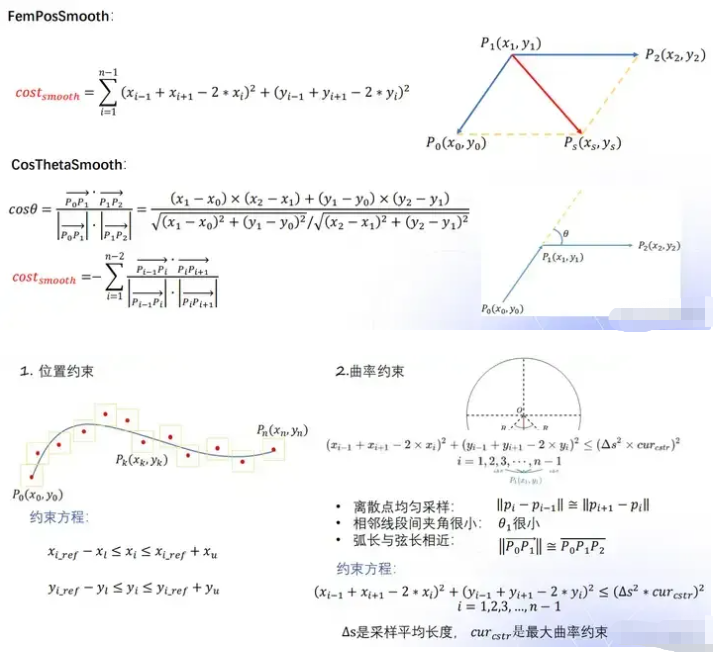
Qk·Rk是点乘
1.4优化求解系数
求解完这个QP问题就可以得到系数矩阵,也变相得到了x和y的这n段平滑曲线,最后的工作就是包装秤一条ReferenceLine,,一共500个点
1.5平滑参考线校验
对平滑参考线SmoothReferenceLine上的点(可以采样,比如累积距离每10m采样),投影到原始参考线RawReferenceLine的距离为l,l不能太大(阈值是6m),否则两条参考线有较大的偏移。
2,平滑参考线的拼接
复用、拼接、收缩
https://github.com/YannZyl/Apollo-Note/blob/master/docs/planning/reference_line_provider.md
5. 决策5.1 EUDM:
用dcp-tree语义动作减少减少动作搜索空间,并通过串联动作长时间决策能力弥补MPDP不足
cfb确定周围车辆的语义意图,选出具有风险的周车意图。
belief update体现在哪?
所以POMDP方法相当于没有用现有的求解器?但感觉思路差不多呀,相当于进行了行动空间和状态空间的改进。
初始信念和更新信念在EUDM和EPSILON中如何体现的?信念更新说的一个是基于规则一个基于学习,那初始信念怎么确定?下图啥意思?
- 参考IGP2我们考虑短期机动意图和长期预测意图
- 我们用现有存在的POMDP求解器去求解POMDP问题(EUDM中相当于用自己的方法去求解,和POMCP的区别是信念更新和MCTS?)
- 优化动作机动和长期意图序列,可以参考之前做博弈时的一些资料?EUDM中考虑的意图只是那三个?
5.2 POMDP
Michael Zhou:behavior planning 行为规划(一POMDP)
Michael Zhou:马尔可夫决策过程5.3 Bayesian+MDP+Probabilistic Risk(Constrained)
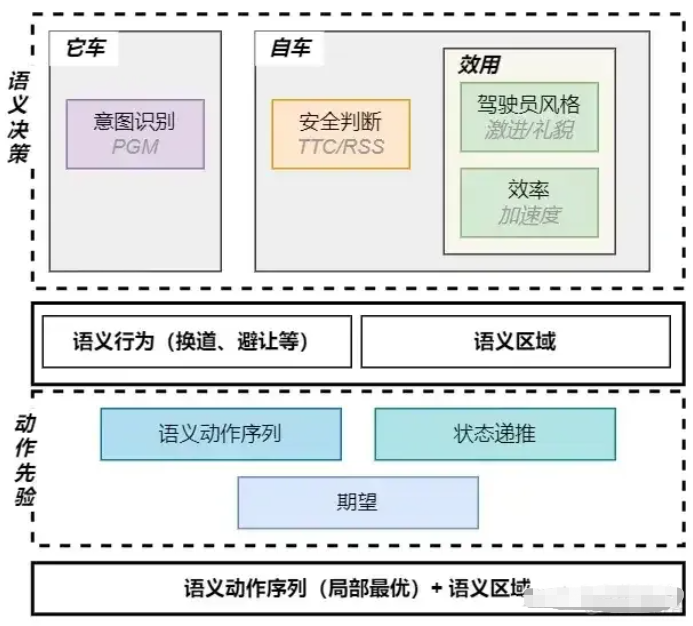
(这段引用自卓荦锋芒:对自动驾驶中决策算法的思考)自动驾驶的决策算法的最优解是**Bayesian+MDP+Probabilistic Risk(Constrained)**。简要说明下理由,
Bayesian:基于数据得到先验(Prior)概率,然后使用后验(Posterior)概率,保证整个算法的拟人性和可解释性。实际上PGM的模型包括三层:因果层、意图层和观测层。
MDP:非常适合做交互决策,又能保证局部最优性。
**Probabilistic Risk(Constrained)**:就功能安全而言,风险的定义包括了风险的发生概率和风险的危害程度。在城市场景下,若自动驾驶做到全路段的话,需要在有约束的概率风险下的做决策。
导航变道,施工变道,超车变道(最适合cost):变道类型不同,
大框架是使用MDP做交互,核心是MDP要素的处理,
状态S:采用语义化行为。致使该算法是基于行为的,而不是场景的,泛化能力更强。
自车的状态转移T:采用数据学习(非DNN)+车辆运动学模型的方法,模拟学习自车的规划性能。保证最终的结果符合规划的性能,又避免采用决策+规划的耦合方式的低泛化能力。
它车的状态转移T:采用Bayesian的方法学习和推断它车行为。根据它车的历史信息,使用先验和后验计算状态的转移及对应的概率。根据先验计算状态的转移及概率,避免深度学习、强化学习的不可解释性、低泛化性。
**可违背风险的行为(R,A)**:基于风险概率选择最优的动作序列。保证拥堵场景的通勤效率。
整体设计的思想遵循:交互性、准确性、合理性。
缺点:耗时,他车意图不确定,
根据最近的研究,再结合自身的积累储备,发现一条可行的算法方向:MDP+LinearProgram+HomotopyClass+Interpolation(2D)。从理论上来说,该算法能够保证最优性和连续性,设计来源于十字路口的无保护转向场景;从可行性来讲,因为有过基于网格插值的MDP开发和凸优化的基础,所以不存在算法开发的堵塞点。
6. 横向规划1 LaneChangeDecider产生是否换道的决策,更新换道状态:产生换道的状态,之后将结果保存在injector中

首先判断是否产生多条参考线,若只有一条参考线,则保持直行。若有多条参考线,则根据一些条件(主车的前方和后方一定距离内是否有障碍物,旁边车道在一定距离内是否有障碍物)进行判断是否换道,当所有条件都满足时,则进行换道决策。
// 纵向安全距离 2*adc_l + 1.2 * adc_v
const double common_safety_distance = config_.safety_distance_l_weight() * adc_l + config_.safety_distance_v_weight() * adc_v;
// input
Process(Frame* frame)
std::list<ReferenceLineInfo>* reference_line_info =frame->mutable_reference_line_info();
std::map<planning::ReferenceLineType, ReferenceLineInfo*>* reference_line_info_map =frame->mutable_reference_line_info_map();
// output
auto* prev_status = injector_->planning_context()->mutable_planning_status()->mutable_change_lane();
prev_status->set_is_clear_to_change_lane(is_clear_to_change_lane);
prev_status->set_left_lane_boundary_dist(left_lane_boundary_dist);
prev_status->set_right_lane_boundary_dist(right_lane_boundary_dist);换道决策决定ADC是否进行换道。目前Apollo的体系是当有多条参考线时即进行换道。
- 如果不换道,在PathBoundsDecider中会将l ll的边界限制在本车道内(如果不借道);
- 如果换道,在PathBoundsDecider中会将l ll的边界向目标车道一侧进行拓展;
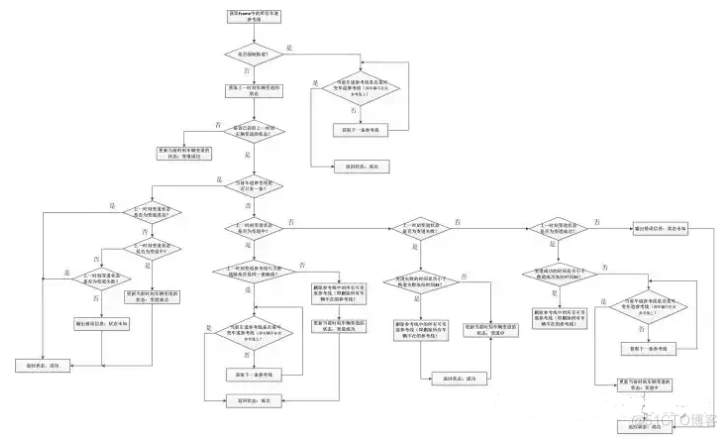
1.process()
LaneChangeDecider 的主要决策逻辑在Process() 方法中
根据reference line的数量判断是否处于变道场景中,size() > 1则处于变道过程中,需要判断变道的状态
只有一条reference line,没有进行变道
有多条reference line,说明处在变道中
如果上一时刻处在变道中,根据上一时刻自车所处道路ID与当前时刻所处道路ID对比,来确认变道状态
// 1. 换道参考线选择决策,输出选择的ReferenceLineType
// 2. 安全空间判断以及对应换道参考线上是否有危险的障碍物// 此处判断传进来的referenceLineinfo是否是变道参考线,如果是则通过// IsClearToChangeLane()检查该参考线是否满足变道条件,// IsClearToChangeLane只考虑传入的参考线上的动态障碍物,不考虑虚的和静态的障碍物。疑点:为什么只/考虑动态障碍物?
// 3. 删除其它参考线
// 4. 换道状态机// 头次进入task,车道换道状态应该为空,默认设置为换道结束状态2.PrioritizeChangeLane()
在调整参考线的顺序时,使用了PrioritizeChangeLane() 函数,它的调整参考线顺序的功能,需要配置enable_prioritize_change_lane为True,这个函数的完整代码及注释如下:
void LaneChangeDecider::PrioritizeChangeLane(
const bool is_prioritize_change_lane,
std::list<ReferenceLineInfo>* reference_line_info) const {
if (reference_line_info->empty()) {
AERROR << "Reference line info empty";return;
}
const auto& lane_change_decider_config = config_.lane_change_decider_config();
// TODO(SHU): disable the reference line order change for now// 如果没有配置变道优先,则退出该函数if (!lane_change_decider_config.enable_prioritize_change_lane()) {return;}auto iter = reference_line_info->begin();while (iter != reference_line_info->end()) {ADEBUG << "iter->IsChangeLanePath(): " << iter->IsChangeLanePath();/* is_prioritize_change_lane == true: prioritize change_lane_reference_lineis_prioritize_change_lane == false: prioritizenon_change_lane_reference_line */// 0、is_prioritize_change_lane 根据参考线数量置位True 或 False// 1、如果is_prioritize_change_lane为True// 首先获取第一条参考线的迭代器,然后遍历所有的参考线,// 如果当前的参考线为允许变道参考线,则将第一条参考线更换为当前迭代器所指向的参考线,// 注意,可变车道为按迭代器的顺序求取,一旦发现可变车道,即推出循环。//// 2、如果is_prioritize_change_lane 为False,// 找到第一条不可变道的参考线,将第一条参考线更新为当前不可变道的参考线if ((is_prioritize_change_lane && iter->IsChangeLanePath())||(!is_prioritize_change_lane && !iter->IsChangeLanePath())) {ADEBUG << "is_prioritize_change_lane: " << is_prioritize_change_lane;ADEBUG << "iter->IsChangeLanePath(): " << iter->IsChangeLanePath();break;}++iter;}reference_line_info->splice(reference_line_info->begin(),*reference_line_info, iter);ADEBUG << "reference_line_info->IsChangeLanePath(): "<< reference_line_info->begin()->IsChangeLanePath();
}3.IsClearToChangeLane() 判断当前的参考线是否变道安全
sClearToChangeLane() 遍历了当前参考线上所有目标,并根据目标的行驶方向设置安全距离,通过安全距离判断是否变道安全,代码及注释如下:
bool LaneChangeDecider::IsClearToChangeLane(ReferenceLineInfo* reference_line_info) {// 或得当前参考线的s坐标的最大最小值,以及自车速度double ego_start_s = reference_line_info->AdcSlBoundary().start_s();double ego_end_s = reference_line_info->AdcSlBoundary().end_s();double ego_v =std::abs(reference_line_info->vehicle_state().linear_velocity());// 遍历每个目标for (const auto* obstacle :reference_line_info->path_decision()->obstacles().Items()) {// 跳过静止与虚拟目标if (obstacle->IsVirtual() || obstacle->IsStatic()) {ADEBUG << "skip one virtual or static obstacle";continue;}// 初始化double start_s = std::numeric_limits<double>::max();double end_s = -std::numeric_limits<double>::max();double start_l = std::numeric_limits<double>::max();double end_l = -std::numeric_limits<double>::max();// 遍历当前目标的预测轨迹点集,或得预测轨迹的边界点for (const auto& p : obstacle->PerceptionPolygon().points()) {SLPoint sl_point;reference_line_info->reference_line().XYToSL(p, &sl_point);start_s = std::fmin(start_s, sl_point.s());end_s = std::fmax(end_s, sl_point.s());start_l = std::fmin(start_l, sl_point.l());end_l = std::fmax(end_l, sl_point.l());}// 如果目标距离当前参考线距离太远, 则跳过该目标if (reference_line_info->IsChangeLanePath()) {static constexpr double kLateralShift = 2.5;if (end_l < -kLateralShift || start_l > kLateralShift) {continue;}}// Raw estimation on whether same direction with ADC or not based on// prediction trajectory// 判断车与障碍物是否同一方向行驶,同时设置安全距离。之后判断距离障碍物距离是否安全// 根据航向角判断是否为相同方向bool same_direction = true;if (obstacle->HasTrajectory()) {double obstacle_moving_direction =obstacle->Trajectory().trajectory_point(0).path_point().theta();const auto& vehicle_state = reference_line_info->vehicle_state();double vehicle_moving_direction = vehicle_state.heading();if (vehicle_state.gear() == canbus::Chassis::GEAR_REVERSE) {vehicle_moving_direction =common::math::NormalizeAngle(vehicle_moving_direction + M_PI);}double heading_difference = std::abs(common::math::NormalizeAngle(obstacle_moving_direction - vehicle_moving_direction));same_direction = heading_difference < (M_PI / 2.0);}// TODO(All) move to confsstatic constexpr double kSafeTimeOnSameDirection = 3.0;static constexpr double kSafeTimeOnOppositeDirection = 5.0;static constexpr double kForwardMinSafeDistanceOnSameDirection = 10.0;static constexpr double kBackwardMinSafeDistanceOnSameDirection = 10.0;static constexpr double kForwardMinSafeDistanceOnOppositeDirection = 50.0;static constexpr double kBackwardMinSafeDistanceOnOppositeDirection = 1.0;static constexpr double kDistanceBuffer = 0.5;double kForwardSafeDistance = 0.0;double kBackwardSafeDistance = 0.0;// 根据方向设置安全距离if (same_direction) {kForwardSafeDistance =std::fmax(kForwardMinSafeDistanceOnSameDirection,(ego_v - obstacle->speed()) * kSafeTimeOnSameDirection);kBackwardSafeDistance =std::fmax(kBackwardMinSafeDistanceOnSameDirection,(obstacle->speed() - ego_v) * kSafeTimeOnSameDirection);} else {kForwardSafeDistance =std::fmax(kForwardMinSafeDistanceOnOppositeDirection,(ego_v + obstacle->speed()) * kSafeTimeOnOppositeDirection);kBackwardSafeDistance = kBackwardMinSafeDistanceOnOppositeDirection;}// 判断障碍物是否满足安全距离if (HysteresisFilter(ego_start_s - end_s, kBackwardSafeDistance,kDistanceBuffer, obstacle->IsLaneChangeBlocking()) &&HysteresisFilter(start_s - ego_end_s, kForwardSafeDistance,kDistanceBuffer, obstacle->IsLaneChangeBlocking())) {reference_line_info->path_decision()->Find(obstacle->Id())->SetLaneChangeBlocking(true);ADEBUG << "Lane Change is blocked by obstacle" << obstacle->Id();return false;} else {reference_line_info->path_decision()->Find(obstacle->Id())->SetLaneChangeBlocking(false);}}return true;
}2 PathReuseDecider路径是否可重用,提高帧间平顺性

主要判断是否可以重用上一帧规划的路径。若上一帧的路径未与障碍物发生碰撞,则可以重用,提高稳定性,节省计算量。若上一帧的规划出的路径发生碰撞,则重新规划路径。

1.PathReuseDecider 是第二个task,作用是
根据横纵向跟踪偏差,来决策是否需要重新规划轨迹
如果横纵向跟踪偏差,则根据上一时刻的轨迹生成当前周期的轨迹,以尽量保持轨迹的一致性
scenario_type: LANE_FOLLOW
stage_type: LANE_FOLLOW_DEFAULT_STAGE
stage_config: {stage_type: LANE_FOLLOW_DEFAULT_STAGEenabled: truetask_type: LANE_CHANGE_DECIDERtask_type: PATH_REUSE_DECIDERtask_type: PATH_LANE_BORROW_DECIDERtask_type: PATH_BOUNDS_DECIDERtask_type: PIECEWISE_JERK_PATH_OPTIMIZERtask_type: PATH_ASSESSMENT_DECIDERtask_type: PATH_DECIDERtask_type: RULE_BASED_STOP_DECIDERtask_type: ST_BOUNDS_DECIDERtask_type: SPEED_BOUNDS_PRIORI_DECIDERtask_type: SPEED_HEURISTIC_OPTIMIZERtask_type: SPEED_DECIDERtask_type: SPEED_BOUNDS_FINAL_DECIDER
task_type: PIECEWISE_JERK_SPEED_OPTIMIZERtask_type: PIECEWISE_JERK_NONLINEAR_SPEED_OPTIMIZERtask_type: RSS_DECIDER
}PublicRoadPlanner 的 LaneFollowStage 配置了以下几个task 来实现具体的规划逻辑,判断上一帧轨迹是否与障碍物碰撞
2.使用path_reuse的好处:
黑色轨迹为采用path_reuse,可以看到整个换道过程,轨迹完全一致; 红色、黄色轨迹为重新规划轨迹并采用trajectory_stitcher 拼接。速度和位置都会有问题。https://zhuanlan.zhihu.com/p/524300384 可以看到在轨迹拼接处以及整体轨迹可能出现不连贯不平滑的情况,可能会影响控制的平顺性:

时为了保证轨迹的连续性,当前拍的规划起点应该选在last_traj离pos_cur最近的投影点上(一般情况下需要增加dt的向前预测量)。得到该投影点的信息后,即可规划出蓝色cur_traj曲线。即使当前位置不在轨迹上,但我们规划出来的轨迹与上一拍规划轨迹完全重合。从而保证了轨迹的连续性,使得控制连贯,不会产生跳变的情况。
值得注意的是,这里需要设定pos_cur和投影点的偏差阈值,若两者距离太大,说明控制无法跟上规划的轨迹。此时,应该考虑实际位置做进一步的规划(比如设定阈值30cm,自车位置离轨迹线35cm,此时可以设定起点为离投影点20cm的地方作为规划的起点,而不是继续拿投影点作为起点继续规划。主要是因为此时偏差较大,继续使用投影点规划会导致控制的超调,从而引起更大的画龙。)。
3.PathReuseDecider 只对外暴露了Process() 一个接口,它的主要逻辑如下:
(1)当前处于非LaneFollow_Scenario场景,置位false
(2)当前未处于IN_CHANGE_LANE状态,置位false;
(3)如果存在可变车道,且已经完成换道轨迹生成,则置位false;
(4)前一时刻采用path_reuse, 若轨迹重规划、轨迹与静态障碍物发生碰撞、轨迹长度过短以及纵向求解失败,则置位false;
(5)只有前方静止障碍物走开(或大于阈值)、纵向求解成功、未与静态障碍物发生碰撞且轨迹长度大于阈值,才可置位true;
4.当path_reusable置位后,后续的task会跳过处理的过程
// skip path_lane_borrow_decider if reused pathif (FLAGS_enable_skip_path_tasks && reference_line_info->path_reusable()) {// for debugAINFO << "skip due to reusing path";return Status::OK();}5.一旦path_reusable置位,则使用上一周期轨迹生成当前周期的规划轨迹
6.在判断是否 path_reusable时,会调用IsCollisionFree 判断静态目标是否安全
3 PathLaneBorrowDecider
产生是否借道的决策:当产生阶导决策时,会将相应标志位置true。同时,在进行借道决策时,会对左右借道进行判断。借道的状态保存在injetor里。

该决策有以下的判断条件:• 是否只有一条车道• 是否存在阻塞道路的障碍物• 阻塞障碍物是否远离路口• 阻塞障碍物长期存在• 旁边车道是实线还是虚线 当所有判断条件都满足时,会产生借道决策。
ADC在借道工况中:判断本车道可通过性,如果在连续n nn(参数配置)帧规划中本车道可以通行,则取消借道。
Process(Frame* const frame, ReferenceLineInfo* const reference_line_info)
// input
*frame
// output
reference_line_info->set_is_path_lane_borrow(ADC不在借道工况中:ADC需要同时满足以下条件才可以进入借道工况:
- 必须只有一条参考线;(是否只有一个障碍物)
- 规划起点的速度不能过高(参数配置);
- 不能在SIGNAL、STOP_SIGN 和Junction附近;
- 不能在终点附近;
- Block Obstacle在ADC一定范围内,并且堵塞原因不是Traffic Flow;
- 地图车道线线型(虚线)允许借道;(实线还是虚线)
- 如果借道,在PathBoundsDecider中会将l ll的边界借道方向一侧进行拓展。
- 是否长期存在
作用主要是换道时:
- 已处于借道场景下判断是否退出避让;
- 未处于借道场景下判断是否具备借道能力。
1.PathLaneBorrowDecider只是判断是否满足借道条件
具体的轨迹是否借道,是由后面的task决定
2.Process()
借道决策器的主要功能为判断当前车辆是否具备借道能力,其实现在类PathLaneBorrowDecider的成员函数process()中。process()函数的功能一共分为三部分:检查输入、如果路径复用则跳过借道决策、判断当前街道状态。
2.1判断是否借道IsNecessaryToBorrowLane()
借道判断主要通过核心函数IsNecessaryToBorrowLane()判断是否借道,主要涉及一些rules,包括距离信号交叉口的距离,与静态障碍物的距离,是否是单行道,是否所在车道左右车道线是虚线等规则。主要有两个功能:
(1)已处于借道场景下判断是否退出避让;
(2)未处于借道场景下判断是否具备借道能力。
需要满足下面条件才能判断是否可以借道:
- 只有一条参考线,才能借道
- 起点速度小于最大借道允许速度
- 阻塞障碍物必须远离路口
- 阻塞障碍物会一直存在
- 阻塞障碍物与终点位置满足要求
- 为可侧面通过的障碍物
2.2CheckLaneBorrow()
主要根据前方道路的线型判断是否可以借道;在此函数中2m间隔一个点遍历车前100m参考线或全部参考线,如果车道线类型为黄实线、白实线则不借道。
2.3IsNonmovableObstacle()
IsNonmovableObstacle() 中主要对前方障碍物进行判断,利用预测以及参考线的信息来进行判断:
- 目标太远不借道
- 目标停止借道
- 目标
3.结果
PathLaneBorrowDecider 的输出结果存在mutable_path_decider_status当中,
4 PathBoundsDecider
产生路径边界:根据现有决策在参考线上进行采样,获得每个点在l ll的边界。有四种边界决策:GenerateRegularPathBound(自车道行驶)、GenerateFallbackPathBound(失败回退)、GenerateLaneChangePathBound、GeneratePullOverPathBound。最后将边界保存在SetCandidatePathBoundaries中,供下一步使用。

利用前几个决策器,根据相应条件,产生相应的SL边界。这里说明以下Nudge障碍物的概念——主车旁边的障碍物未完全阻挡主车,主车可以通过绕行避过障碍物(注意图中的边界)。它的作用主要是:
- 根据借道信息、道路宽度生成FallbackPathBound
- 根据借道信息、道路宽度生成、障碍物边界生成PullOverPathBound、LaneChangePathBound、RegularPathBound中的一种
PathBoundsDecider会根据换道决策和借道决策生成相应的l ll的边界。
FallbackBound+PullOverBound;
FallbackBound+LaneChangeBound;
FallbackBound+NoBorrow/LeftBorrow/RightBorrow;
不管在何种决策下,PathBoundsDecider都会生成一条FallbackBound,其与NoBorrow的区别是,不会删除Block Obstacle后道路边界。
// intput// Initialization.InitPathBoundsDecider(*frame, *reference_line_info);
// output
PathBound fallback_path_bound;
PathBound lanechange_path_bound;
PathBound regular_path_bound;
PathBound -> PathBoundary -> candidate_path_boundaries.emplace_back(regular_path_boundary);
reference_line_info->SetCandidatePathBoundaries(std::move(candidate_path_boundaries));1.计算path 的boundary
PathBoundsDecider根据lane borrow决策器的输出、本车道以及相邻车道的宽度、障碍物的左右边界,来计算path 的boundary,从而将path 搜索的边界缩小,将复杂问题转化为凸空间的搜索问题,方便后续使用QP算法求解
2.输出是对纵向s等间距采样,横向s对应的左右边界
PathBoundsDecider计算path上可行使区域边界,其输出是对纵向s等间距采样,横向s对应的左右边界,以此来作为下一步路径搜索的边界约束;与其他task一样,PathBoundsDecider的主要逻辑在Process() 方法中。
在Process() 方法中分四种情况对pathBound进行计算,按照处理顺序分别是fallback、pullover、lanechange、regular,不同的boundary对应不同的应用场景,其中fallback对应的path bound一定会生成,其余3个只有一个被激活,即按照顺序一旦有有效的boundary生成,就结束该task。
3.关于ADC_bound 与lane_bound的计算
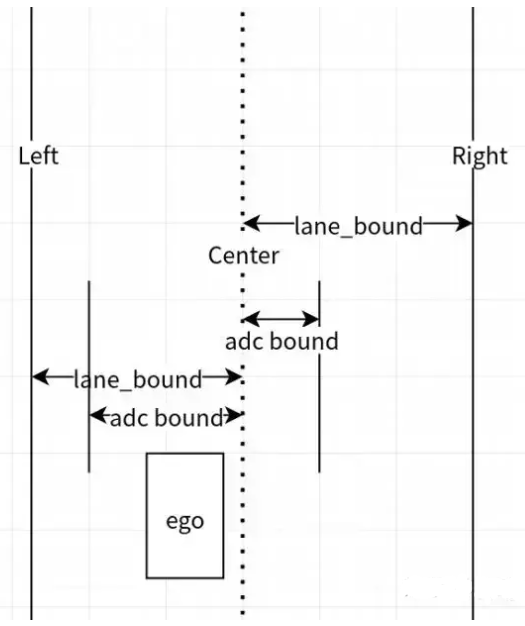
(1)根据车道生成左右的lane_bound,从地图中获得;根据自车状态生成adc_bound, adc_bound = adc_l_to_lane_center_ + ADC_speed_buffer + adc_half_width + ADC_buffer
上式中的各项:
adc_l_to_lane_center_ - 自车
adc_half_width - 车宽
adc_buffer - 0.5
ADCSpeedBuffer表示横向的瞬时位移, 公式如下:

其中kMaxLatAcc = 1.5
(2)根据ADC_bound 与lane_bound 生成基本的bound
左侧当前s对应的bound取MAX(left_lane_bound,left_adc_bound), 即取最左边的
右侧当前s对应的bound取MIN(right_lane_bound,right_adc_bound),即取最右边的
4.InitPathBoundsDecider()
在Process()过程中,首先会初始化bounds,用规划起始点自车道的lane width去初始化 path boundary,如果无法获取规划起始点的道路宽度,则用默认值目前是5m,来初始化。
path_bounds由一系列采样点组成,数据结构如下,这组数据里共有0~199个200个采样点,每两个点的间隔是0.5m;每个点由3个变量组成,分别是根据参考线建立的s-l坐标系的s坐标,右边界的l取值,左边界的s取值:
5.GenerateFallbackPathBound()
无论当前处于何种场景,都会调用GenerateFallbackPathBound() 来生成备用的path bound,在计算FallbackPathBound时不考虑障碍物边界,仅使用道路边界,并考虑借道信息来进行计算。
// Generate the fallback path boundary.
// 生成fallback_path_bound,无论何种场景都会生成fallback_path_bound
// 生成fallback_path_bound时,会考虑借道场景,向哪个方向借道,对应方向的path_bound会叠加这个方向相邻车道宽度
PathBound fallback_path_bound;Status ret =// 生成fallback_path_bound,
// 首先计算当前位置到本车道两侧车道线的距离;
// 然后判断是否借道,并根据借道方向叠加相邻车道的车道宽度
// 带有adc的变量表示与自车相关的信息
GenerateFallbackPathBound(*reference_line_info, &fallback_path_bound);if (!ret.ok()) {ADEBUG << "Cannot generate a fallback path bound.";return
Status(ErrorCode::PLANNING_ERROR, ret.error_message());}if
(fallback_path_bound.empty()) {const std::string msg = "Failed to get a valid fallback path boundary";AERROR << msg;return Status(ErrorCode::PLANNING_ERROR, msg);}if (!fallback_path_bound.empty()) {CHECK_LE(adc_frenet_l_, std::get<2>
(fallback_path_bound[0]));CHECK_GE(adc_frenet_l_, std::get<1>
(fallback_path_bound[0]));}// Update the fallback path boundary into the reference_line_info.
// 将fallback_path_bound存入到candidate_path_boundaries
std::vector<std::pair<double, double>> fallback_path_bound_pair;for (size_t i = 0; i < fallback_path_bound.size(); ++i) {fallback_path_bound_pair.emplace_back(std::get<1>
(fallback_path_bound[i]),std::get<2>
(fallback_path_bound[i]));}candidate_path_boundaries.emplace_back(std::get<0>
(fallback_path_bound[0]),kPathBoundsDeciderResolution,fallback_path_bound_pair);candidate_path_boundaries.back().set_label("fallback");
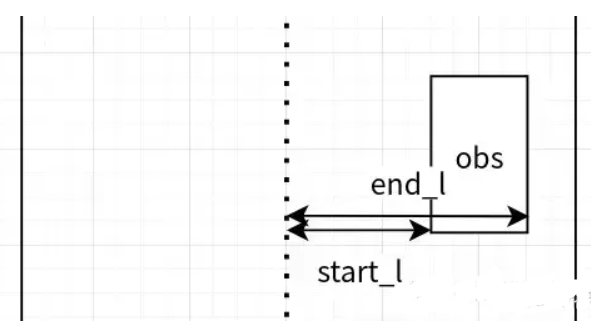
6.障碍物边界生成
(1)首先筛选障碍物,障碍物筛选规则如下,需要符合以下所有的条件,才加到obs_list中:
- 不是虚拟障碍物
- 不是可忽略的障碍物(其他decider中添加的ignore decision)
- 静态障碍物或速度小于FLAGS_static_obstacle_speed_threshold(0.5m/s)
- 在自车的前方
(2)将每个障碍物分解成两个ObstacleEdge,起点一个终点一个,记录下s,start_l,end_l,最后按s排序
7.根据场景生成另外一条path_bound依次判断是否处于pull_over、lane_change、regular;当处于其中一个场景,计算对应的path_bound并返回结果;即以上3种场景,只会选一种生成对应的根据场景生成另外一条path_bound。
这3种path bound均考虑了障碍物的边界,用障碍物的边界来修正path bound:
- 首先根据借道与否,用道路宽度来生成基本的path bound
- 然后遍历path上的每个点,并且判断这个点上的障碍物,利用障碍物的边界来修正path bound
- 如果目标在左边将left_bound 设置为目标右边界
- 如果目标在右边,将right_bound设置为目标的左边界
Status PathBoundsDecider::GenerateLaneChangePathBound(const ReferenceLineInfo& reference_line_info,std::vector<std::tuple<double, double, double>>* const path_bound) {// 1. Initialize the path boundaries to be an indefinitely large area.// 1、用numeric 的最大最小值初始化path boundif (!InitPathBoundary(reference_line_info, path_bound)) {const std::string msg = "Failed to initialize path boundaries.";AERROR << msg;return Status(ErrorCode::PLANNING_ERROR, msg);}// PathBoundsDebugString(*path_bound);// 2、用当前车道宽度计算path bound,同时考虑lane borrow,如果借道将目标车道的宽度叠加// 2. Decide a rough boundary based on lane info and ADC's positionstd::string dummy_borrow_lane_type;if (!GetBoundaryFromLanesAndADC(reference_line_info,LaneBorrowInfo::NO_BORROW, 0.1, path_bound,&dummy_borrow_lane_type, true)) {const std::string msg ="Failed to decide a rough boundary based on ""road information.";AERROR << msg;return Status(ErrorCode::PLANNING_ERROR, msg);}// PathBoundsDebugString(*path_bound);// 3、在换道结束前,用ADC坐标到目标道路边界的距离,修正path bound// 3. Remove the S-length of target lane out of the path-bound.GetBoundaryFromLaneChangeForbiddenZone(reference_line_info, path_bound);PathBound temp_path_bound = *path_bound;std::string blocking_obstacle_id;// 根据path上的障碍物修正path_bound,遍历path上每个点,并在每个点上遍历障碍物;// 如果目标在左边将left_bound 设置为目标右边界// 如果目标在右边,将right_bound设置为目标的左边界if (!GetBoundaryFromStaticObstacles(reference_line_info.path_decision(),path_bound, &blocking_obstacle_id)) {const std::string msg ="Failed to decide fine tune the boundaries after ""taking into consideration all static obstacles.";AERROR << msg;return Status(ErrorCode::PLANNING_ERROR, msg);}// Append some extra path bound points to avoid zero-length path data.int counter = 0;while (!blocking_obstacle_id.empty() &&path_bound->size() < temp_path_bound.size() &&counter < kNumExtraTailBoundPoint) {path_bound->push_back(temp_path_bound[path_bound->size()]);counter++;}ADEBUG << "Completed generating path boundaries.";return Status::OK();
}5 PiecewiseJerkPathOptimizer
PiecewiseJerkPathOptimizer 是lanefollow 场景下,所调用的第 5 个 task,属于task中的optimizer类别
基于二次规划算法,对每个边界规划出最优路径.调用piecewise_jerk_problem类进行求解,会设置一些权重以及一些约束,利用Optimize函数进行求解。
reference_line_info_->GetCandidatePathBoundaries();保存候选路径。
// input
auto &reference_line = reference_line_info->reference_line();
auto &init_point = frame->PlanningStartPoint();
const auto& path_boundaries = reference_line_info->GetCandidatePathBoundaries();
PathData path_data = *reference_line_info->mutable_path_data();
const double lat_acc_bound =std::tan(veh_param.max_steer_angle() / veh_param.steer_ratio()) /veh_param.wheel_base();// output
问题点:
- 约束设计时,曲率模型做了近似,假设太理想,
特点(1) 平滑程度高,cost_fuc中加入了目标轨迹与QP输出轨迹的贴切程度
(2) 复杂度问题,为了保证安全性,QP中的约束条件Piecewise也几乎都需要使用,一般通过第三方osqp开源库进行解算,解算耗时有较大波动
(3) 舒适度,差分考虑加加速度,对舒适性指标进行平滑
(4) 拓展性,cost_fuc可自定义
1.它的作用主要是:
- 1、根据之前decider决策的reference line和 path bound,以及横向约束,将最优路径求解问题转化为二次型规划问题;
- 2、调用osqp库求解最优路径;

2.数学模型
https://www.chuxin911.com/osqp-introduction_20210715/2.1二次规划标准型
https://blog.csdn.net/sinat_52032317/article/details/128406586


2.2定义优化变量
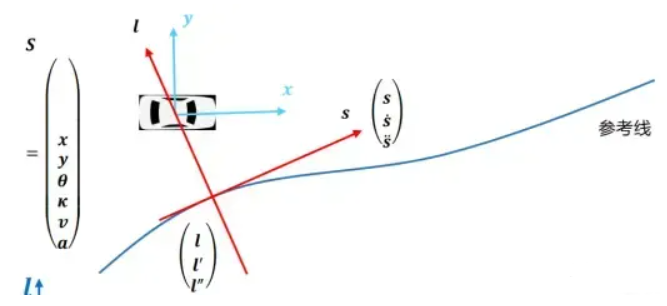
路径规划一般是在Frenet坐标系中进行的。s为沿着参考线的方向,l为垂直于坐标系的方向。


- 根据导引线和障碍物生成路径边界
- 将导引线在s方向等间隔采样
- 对每个s方向的离散点迭代的优化 , ', '' 。
一些设置
delta s : --path_bounds_decider_resolutinotallow=0.5
最大迭代次数:(15会掉帧)6
dl error 最大是0.02满足
2.3 设计目标函数


l的三阶导数,dddl可通过二阶导差分的方式获取。

piecewise-jerk method
横向位置的l三阶导数如下图所示,

图:dddl的表达式
另外,为考虑path的连续性下方的l,l',l''等式约束需要考虑到约束条件中,如下图,

图:l,dl,ddl的等式约束
整个过程的路径规划的目标函数为:

路径优化的目标函数
可变的道路边界对车辆运行学约束,道路曲率的等式约束如下,kr,kr_dot为当前点的曲率参数,△θ为车辆的航向角与当前点曲率的差值。

道路曲率与车辆的关系

QP问题的表达形式:

将bound转为qp格式
bound主要由三部分组成:
- 在path bound decider中获取的上下边界
- l' l'' l'''的约束
- 起点约束
- 数学约束,上述的l,l',l'',l'''的数学关系
所以需要将目标函数J 以及边界bound的约束条件改为QP 问题的形式,这里Python代码在考虑约束时忽略了车辆运动学的约束,在Apollo 的算法中还考虑了车辆运动学的约束。
将路径优化问题转化为QP问题的方法如下:
(1)用path上每个采样点的横向坐标,横向一阶导、二阶导构建X 矩阵:
(2)通过展开多项式推导后,按下列公式构建P、q矩阵:

(3)根据上下边界的约束,构建A 矩阵:
(4)根据path bound的约束,构建l、u矩阵:
整个formulate problem的过程,通过以上步骤完成了P,q,A,LB,UB五个矩阵,接下来使用osqp求解器进行求解需要满足半正定(https://www.cnblogs.com/icathianrain/p/14407626.html)
2.4构建约束
曲率约束:根据坐标系转换,kappa(xy) = kappa(frent) + kappa(refenrence) 。代码里优化的是kappa(frenet)。但是在曲率比较大的地方,前面的等式不成立,导致这个约束并不准确。所以业界才考虑在xy坐标下做规划。

2.4.1约束总结

3.流程
(1) 初始化
获取障碍物信息(SL图)、Frenet坐标信息、车辆信息(位姿、车辆自身几何约束)、QP后的轨迹
(2) 纵向离散化
对于每一个离散点,计算其纵向通行区域(lmin,lmax)

(3) 选择优化变量
对于第2步中的横向偏移量,求解一阶导和二阶导,表征车辆靠近与偏离指引线的趋势 同时,对相邻离散点,通过差分计算三阶导数
量化表示: 离散点i,横向偏移li,一二三阶导数分别为li',li'',li'''


(4) 优化目标设定
(1) 车辆贴近参考线
(2) 一二三阶导数尽可能小,控制横向加速度,保证舒适性

备注: 可以根据需求,选择性的加入与边界距离的优化目标,使车辆与障碍物保持适当距离
4.求解
求解器:考虑曲率才用的是非线性的osqp,如果不加曲率约束的话就用QP,不用迭代。
6 PathAssessmentDecider
路径评价,选出最优路径。调用ComparePathData函数,对路径进行两两比较。 依据以下规则,进行评价。路径是否和障碍物碰撞路径长度路径是否会停在对向车道路径离自车远近哪个路径更早回自车道…

路径两两进行对比,选出最优的路径。
PathAssessmentDecider 是lanefollow 场景下,所调用的第 6 个 task,属于task中的decider 类别它的作用主要是:
- 选出之前规划的备选路径中排序最靠前的路径;
- 添加一些必要信息到路径中

PathAssessmentDecider会依据设计好的规则筛选处最终的path,并在规划路径上的采样点添加标签(IN_LANE、OUT_ON_FORWARD_LANE、OUT_ON_REVERSE_LANE等),作为路径筛选的依据,并为速度规划提供限制。
路径筛选的规则是:
- 不能偏离参考线和Road太远;
- 不能和Static Obstacle相撞;
- 不能停止在对向车道上;
- 选择优先级最高的Path,排序规则:
- Regular path优先于fallback path;
- 如果两条路径至少有一条是self_lane,并且两条路径长度的差大于15m,选择路径长的;
- 如果两条路径至少有一条是self_lane,并且两条路径长度的差小于5m,是self_lane的;
- 如果两条路径都不是self_lane,并且两条路径长度的差大于25m,选择路径长的;
- 选择占据反向车道更少的路径;
- 是否停到对向车道
- 如果有block obstacle,选择占据空间少的方向的路径;
- 如果没有block obstacle,选择ADC靠近方向的路径,使车辆少打方向盘;
- 选择返回本车道更早的路径;
- 在上述情况无法区分的情况下选择左侧的路径;
7. PathDecider
根据选出的路径给出对障碍物的决策

若是绕行的路径,则产生绕行的决策;若前方有障碍物阻塞,则产生停止的决策。
PathDecider 是lanefollow 场景下,所调用的第 7 个 task,属于task中的decider 类别它的作用主要是:
在上一个任务中获得了最优的路径,PathDecider的功能是根据静态障碍物做出自车的决策,对于前方的静态障碍物是忽略、stop还是nudge

遍历每个障碍物, 根据规则判断前面优化并筛选出来的path生成对应的decisions(GNORE, STOP, LEFT NUDGE, RIGHT NUDGE等)。
- 对以有IGNORE/STOP/KEEP_CLEAR决策的obstacle不做处理;
- 如果是block obstacle,并且不是借道工况,设为STOP决策;
- 不在path纵向范围内的障碍物设为IGNORE决策;
- 对于碰撞的obstacle,设为STOP决策;
- 根据位置关系设置LEFT NUDGE或者RIGHT NUDGE的决策;
8 RuleBasedStopDecider
RuleBasedStopDecider 是lanefollow 场景下,所调用的第 8 个 task,属于task中的decider 类别它的作用主要是:
- 根据一些规则来设置停止标志。

横向输出
message PathPoint {// coordinatesoptional double x = 1;optional double y = 2;optional double z = 3;// direction on the x-y planeoptional double theta = 4;// curvature on the x-y planningoptional double kappa = 5;// accumulated distance from beginning of the pathoptional double s = 6;// derivative of kappa w.r.t s.optional double dkappa = 7;// derivative of derivative of kappa w.r.t s.optional double ddkappa = 8;// The lane ID where the path point is onoptional string lane_id = 9;// derivative of x and y w.r.t parametric parameter t in CosThetareferencelineoptional double x_derivative = 10;optional double y_derivative = 11;// Ali-XLab-Begin motai.yy 2019-10-11optional double slope_angle = 12 [default = 0.0]; // [rad]// Ali-XLab-End
}纵向输出
message SpeedPoint {optional double s = 1;optional double t = 2;// speed (m/s)optional double v = 3;// acceleration (m/s^2)optional double a = 4;// jerk (m/s^3)optional double da = 5;
}纵向:
https://blog.csdn.net/weixin_56492465/article/details/128870540?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-128870540-blog-122009754.pc_relevant_multi_platform_whitelistv3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-128870540-blog-122009754.pc_relevant_multi_platform_whitelistv3&utm_relevant_index=2https://blog.csdn.net/mpt0816/article/details/122009754
优化模型离散方式
在处理最优化问题时,一般会转化成离散形式,将轨迹s ( t ) s(t)s(t)按照某参数离散,并计算离散点处的约束和c o s t costcost。不同的离散方式会构建不同的优化模型。对于速度规划问题,一般可以按照等间距离散(Spatial Parameter Discretization)和等时间离散(Temporal Parameter Discretization)。
1.1.1 Spatial Parameter Discretization
使用纵向距离s ss作为离散采样参数,假设第一个采样点s = 0 s=0s=0,连续采样离散点之间等间隔Δ s \Delta sΔs离散,那么优化问题的决策变量为每个离散点的s ˙ , s ¨ 和相邻采样点之间的时间间隔Δ t \Delta tΔt。

优点:
参考线或者规划路径的曲率κ \kappaκ是纵向距离s ss的函数,因此向心加速度约束是容易处理的;
地图限速等速度约束是和纵向距离s ss相关的,那么优化问题的s ˙ 约束容易计算;
缺点:
优化问题的目标函数难以建模。Apollo规划算法用来优化纵向冲击度最小,冲击度使用相邻两个离散点的差分计算,如果采用Δ s \Delta sΔs离散会使决策变量之间有除法运算,形成非凸优化问题;
难以施加安全约束。障碍物一般投影在ST Graph中,会得到每个时刻下的安全行驶范围( s m i n , s m a x ) ),即可行驶区域s f r e e ( t ) (t)是时间t tt的函数。
1.1.2 Temporal Parameter Discretization
使用时间t tt作为离散采样参数,假设第一个采样点t = 0 t=0t=0,连续采样离散点之间等间隔Δ t \Delta tΔt离散,那么优化问题的决策变量为每个离散点的s , s ˙ , s ¨ cost funtion

使用等时间间隔离散的方式,和使用等距离离散方式的优缺点恰好相反。
优点:
优化模型可以保持凸包性质,冲击度的计算仍然是线性形式;
障碍物的安全约束容易施加在优化模型中;
缺点:
由于曲率是s ss的函数,因此向心加速度约束难以处理;
速度约束难以处理;
最小任务完成时间的优化目标难以处理;
处理方法:
使用规划路径的最大曲率计算向心加速度限制;
将离散点处的位置s ss与DP得到纵向位置s ss的差作为目标函数的一部分,使用DP结果在采样时刻t处的s处对应的速度限值;
将离散采样点处的速度s ˙ 与目标速度(reference speed)的差作为目标函数的一部分。以保证完成任务花费的时间最少;
此外,Apollo还设计了非线性速度规划来处理以上问题。
const funtion

约束
等式约束

不等式约束
7.纵向规划
7.1 STBoundsDecider
百度已经关掉此task,区间过于宽泛。
作用
- 生成DrivableSTBoundary 供dp搜索的时候用
- 对不影响纵向规划的障碍物设置IGNORE属性;
// 输入:
const PathData &path_data = reference_line_info->path_data();
PathDecision *path_decision = reference_line_info->path_decision();
// 输出:
regular_st_bound, regular_vt_bound
RecordSTGraphDebug(st_boundaries, regular_st_bound, st_guide_line,&st_graph_debug);
// 1.Initialize the related helper classes
InitSTBoundsDecider(*frame, reference_line_info);
// 1.1st_driving_limits_初始化
st_obstacles_processor_.MapObstaclesToSTBoundaries(path_decision);
st_driving_limits_.Init(max_acc, max_dec, max_v,frame.PlanningStartPoint().v());
// 2.GenerateRegularSTBound,Sweep the t-axis, and determine the s-boundaries step by step
// 2.1依据运动学driving_limits更新s_lower, s_upper
auto driving_limits_bound = st_driving_limits_.GetVehicleDynamicsLimits(t);
// 2.2.依据自车运动学约束,剔除不可达的障碍物decisionSTBoundsDecider是来计算ST Graph中st_drivable_boundary_。由三个模块的计算组成:
- 依据障碍物st_boundary约束,更新可通行s_bounds以及对应的决策(
GetBoundsFromDecisions),对于同一障碍物的st_boundary可能存在多个决策,比如overtake或yield,见GetSBoundsFromDecisions函数;
本模块障碍物的ST图计算耗时也较高,但st_boundary精度较低;同理最终生成的st_drivable_boundary_边界精度也较低。
如果在下游gridded_path_time_graph模块中FLAGS_use_st_drivable_boundary不置位时,则无需使用该模块输出的st_drivable_boundary;因此可结合实际项目需求,来精简该模块的冗余计算。
7.2 SPEED_BOUNDS_PRIORI_DECIDER
作用:
得到ST Graph中的st_boundaries
产生速度可行驶边界

所形成的区域是非凸的,不能用之前
凸优化的方法去做,需要用动态规划的方法去做。
(1)将规划路径上障碍物的st bounds 加载到路径对应的st 图上
(2)计算并生成路径上的限速信息
// 输入:
// retrieve data from frame and reference_line_info
const PathData &path_data = reference_line_info->path_data();
const TrajectoryPoint &init_point = frame->PlanningStartPoint();
const ReferenceLine &reference_line = reference_line_info->reference_line();
PathDecision *const path_decision = reference_line_info->path_decision();
// 输出:
boundaries, min_s_on_st_boundaries, speed_limit
st_graph_data->LoadData(boundaries, min_s_on_st_boundaries, init_point,speed_limit, reference_line_info->GetCruiseSpeed(),path_data_length, total_time_by_conf);SpeedBoundsPrioriDecider对应的Decider或者说class是SpeedBoundsDecider,是计算每个障碍物的STBoundary得到ST Graph中的st_boundaries_和speed_limit_(SpeedLimit)。其中每个障碍物的STBoundary的计算其实是根据遍历规划时间内障碍物和规划路径的碰撞关系来计算的,并且会根据是否对障碍物做过纵向决策以及决策类型设置其STBoundary的
characteristic_length。
speed_limit_(SpeedLimit)则是根据三个方面计算的:
- 地图限速;
double speed_limit_from_reference_line =reference_line_.GetSpeedLimitFromS(reference_line_s);- 向心加速度限制;sqrt(a/kappa) a= 2
const double speed_limit_from_centripetal_acc =std::sqrt(speed_bounds_config_.max_centric_acceleration_limit() /std::fmax(std::fabs(discretized_path.at(i).kappa()),speed_bounds_config_.minimal_kappa()));- 对于近距离nudge障碍物的减速避让;
//1.先判断是否左/右靠太近
//2.然后根据动静态障碍物设置限速比例
speed_limit_from_nearby_obstacles =nudge_speed_ratio * speed_limit_from_reference_line;7.3 PathTimeHeuristicOptimizer
非凸变凸 -> DP
动态规划
动态规划——通过把原问题分解为相对简单的子问题,再根据子问题的解来求解出原问题解的方法
状态转移方程

1.目标:产生粗糙速度规划曲线

PathTimeHeuristicOptimizer是速度规划的DP过程。速度规划需要在凸空间内求解,然而由于障碍物等原因会使求解空间变成非凸的,因此需要DP算法得到对不同障碍物的决策,从而得到一个凸空间。另一方面,最优化问题一般都仅有局部寻优能力,可能会收敛到某个局部最优解。为了保障优化问题的求解质量,使用全局“视野”的DP算法快速生成粗糙的初始解,并从该初始解的领域开展局部优化可以使最优化问题收敛到全局近似解。

SPEED_HEURISTIC_OPTIMIZER 是lanefollow 场景下,所调用的第 11个 task,属于task中的optimizer 类别,它的作用主要是:
- apollo中使用动态规划的思路来进行速度规划,其实更类似于使用动态规划的思路进行速度决策;
- 首先将st图进行网格化,然后使用动态规划求解一条最优路径,作为后续进一步速度规划的输入,将问题的求解空间转化为凸空间
// 输入:
init_point, path_data
// 输出
(使用speed_bounds_decider的reference_line_info_->st_graph_data())
speed_data(s, t, v)2. 流程
- 基于动态规划的速度规划的流程如下:
- 对路程和时间进行采样2.搜索出粗略的可行路线3.选出代价最小的一条

速度规划在ST图进行采样,在t 的方向上以固定的间隔进行采样,在s方向上以先密后疏的方式进行采样(离主车越近(10m),所需规划的精度就需更高;离主车越远,牺牲采样精度,提升采样效率)
// 时间采样的一般参数设置
unit_t: 1.0 //采样时间
dense_dimension_s: 101 // 采样密集区域的点数
dense_unit_s: 0.1 //采样密集区域的间隔
sparse_unit_s: 1.0 //采样系数区域的间隔代码总流程如下:
- 1、遍历每个障碍物的boundry,判度是否有碰撞风险,如果有碰撞风险使用fallback速度规划;
- 2、初始化cost table
- 3、按照纵向采样点的s,查询各个位置处的限速
- 4、搜索可到达位置
- 5、计算可到达位置的cost
- 6、搜索最优路径
2.1采样:
如上
2.2状态转移方程
一个点的total_cost由四部分构成:
- obstacle_cost:障碍物cost
- spatial_potential_cost:空间位置cost,于终点s的差值
- 前一个点的total_cost
- EdgeCost:边界约束由三部分构成Speedcost、AccelCost、JerkCost
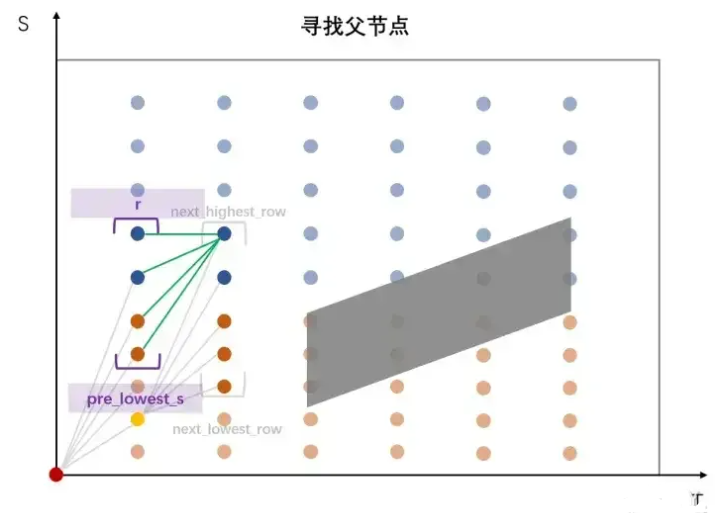
在更新父节点时同样有一个剪枝操作,使用限速信息FLAGS_planning_upper_speed_limit得到pre_lowest_s,进而将寻找范围限制在[r_low, r],其中r为当前行号,因为EM Planner主要是前进场景,不会考虑倒车情况,那么S值是递增或不变,不会下降,所以r最大也就当前行号
2.2.2.1 障碍物cost计算

S_safe_overtake超车的安全距离S_safe_follow跟车的安全距离 在设计状态转移方程时,要求不能与障碍物发生碰撞以及和障碍物不发生碰撞。于是可以得到以下方程:

如果在障碍物距离之内,则cost设为无穷;如果在安全距离之外,则cost设为0;如果在安全距离与障碍物之间,则按按之间的距离计算。
2.2.2.2 距离cost计算
目的是更快的到达目的地

距离cost计算方式如下:

2.2.2.3 状态转移cost计算
状态转移cost计算分为三个部分:


越靠近0,代价值越小;越靠近目标值,代价值越大,满足舒适性与平滑性。

加加速度的计算方式如下:

7.4 SpeedDecider
产生速度决策

根据粗规划出的速度曲线,依据曲线在障碍物的上方还是下方,采取不同的决策。
// 输入:
init_point_, adc_sl_boundary_, reference_line_,
MakeObjectDecision(reference_line_info->speed_data(),reference_line_info->path_decision())
// 输出:
mutable_obstacle->AddLongitudinalDecision()SpeedDecider 是lanefollow 场景下,Apollo Planning算法所调用的第12个 task,属于task中的decider 类别它的作用主要是:
- 1、对每个目标进行遍历,分别对每个目标进行决策
- 2、或得mutable_obstacle->path_st_boundary()
- 3、根据障碍物st_boundary的时间与位置的分布,判断是否要忽略
- 4、对于虚拟目标 Virtual obstacle,如果不在referenceline的车道上,则跳过
- 5、如果是行人则决策结果置为stop
- 6、SpeedDecider::GetSTLocation() 获取障碍物在st图上与自车路径的位置关系
- 7、根据不同的STLocation,来对障碍物进行决策
- 8、如果没有纵向决策结果,则置位ignore_decision;
SpeedDecider根据DP算法生成的速度曲线s ( t ) s(t)s(t)和障碍物的STBoundary的位置关系生成Ignore、Stop、Follow、Yield、Overtake的纵向决策。
Ignore:
障碍物的STBoundary在ST Graph的范围内;
已经有纵向决策的障碍物;
类型是禁停区的obstacle的STBoundary位于速度曲线的下方;
Stop:
前方是行人的停车决策;
类型是禁停区的obstacle的STBoundary位于速度曲线的上方;
在ADC前方低速行驶的堵塞道路的障碍物;
STBoundary和速度曲线相交的障碍物;
Follow:
STBoundary位于速度曲线上方,且不需要Stop的障碍物;
Yield:
STBoundary位于速度曲线上方,且不需要Stop和Follow的障碍物;
Overtake:
STBoundary位于速度曲线下方的障碍物;
**13 SPEED_BOUNDS_FINAL_DECIDER **产生速度规划边界


在障碍物的上方或下方确定可行使区域。
SpeedBoundsFinalDecider对应的Decider同样是SpeedBoundsDecider,和SpeedBoundsPrioriDecider不同的是配置参数,从Apollo中的默认配置参数来看,
7.5 SpeedBoundsFinalDecider
会根据DP过程生成的决策结果和更小的boundary_buffer生成更加精确的STBoundary。
// 输入:
const PathData &path_data = reference_line_info->path_data();
const TrajectoryPoint &init_point = frame->PlanningStartPoint();
const ReferenceLine &reference_line = reference_line_info->reference_line();
PathDecision *const path_decision = reference_line_info->path_decision();
// 输出:
std::vector<const StBoundary *> boundaries,const double min_s_on_st_boundaries,
SpeedLimit speed_limit,
st_graph_data->LoadData(boundaries, min_s_on_st_boundaries, init_point,speed_limit, reference_line_info->GetCruiseSpeed(),path_data_length, total_time_by_conf);配置
// 1. Map obstacles into st graph
// 2. Create speed limit along path
// 3. Get path_length as s axis search bound in st graph
// 4. Get time duration as t axis search bound in st graph
SPEED_BOUNDS_FINAL_DECIDER 是lanefollow 场景下,所调用的第 13 个 task,属于task中的decider 类别它的作用主要是:
- (1)将规划路径上障碍物的st bounds 加载到路径对应的st 图上(并且根据障碍物决策生成boundary类型)
- (2)计算并生成路径上的限速信息
7.5 PiecewiseJerkSpeedOptimizer
产生平滑速度规划曲线

根据ST图的可行驶区域,优化出一条平滑的速度曲线。满足一阶导、二阶导平滑(速度加速度平滑);满足道路限速;满足车辆动力学约束。
PIECEWISE_JERK_SPEED_OPTIMIZER 基于二次规划的速度规划
PIECEWISE_JERK_NONLINEAR_SPEED_OPTIMIZER 基于非线性规划的速度规划
两者二选一即可
速度规划的优化求解即是按照上述的算法原理实现的。
可以看到,在此会依据纵向决策结果生成纵向位移的约束边界,将每个时刻和cruise speed的误差作为优化目标的一部分,并且根据DP结果在每个时刻处位移的速度约束作为优化问题的速度约束边界,因此将每个时刻的位移和DP的位置之差作为了优化目标的一部分,但是这样只能实现速度的软约束。
PiecewiseJerkSpeedOptimizer 是lanefollow 场景下,所调用的第 14个 task,属于task中的decider 类别它的作用主要是:
- 1、根据之前decider决策的speed decider和 speed bound,以及纵向约束,将最优速度求解问题转化为二次型规划问题;
- 2、调用osqp库求解最优路径;
//输入:
PathData& path_data(get 曲率),
common::TrajectoryPoint& init_point,
SpeedData* const speed_data
//优化变量x dx ddx
//目标函数set_x_ref,set_dx_ref,set_weight_ddx,set_weight_dddx
//构建约束set_x_bounds,set_penalty_dx,set_dx_bounds,set_ddx_bounds,set_dddx_bound
//优化器求解piecewise_jerk_problem.Optimize()
penalty_dx.push_back(std::fabs(path_point.kappa()) *config.kappa_penalty_weight());
piecewise_jerk_problem.set_penalty_dx(penalty_dx); //输出:s ds dds
// Update STBoundary by boundary_type影响s上下边界
speed_data->AppendSpeedPoint(s[i], delta_t * i, ds[i], dds[i],(dds[i] - dds[i - 1]) / delta_t);
配置
default_task_config: {task_type: PIECEWISE_JERK_SPEED_OPTIMIZERtask_process_type: ON_REFERENCE_LINEpiecewise_jerk_speed_optimizer_config {acc_weight: 1.0 # ddxjerk_weight: 3.0 # dddxkappa_penalty_weight: 2000.0 # kappa penalty_dxref_s_weight: 10.0 # xref_v_weight: 10.0 # dx}
}
default_task_config: {task_type: PIECEWISE_JERK_NONLINEAR_SPEED_OPTIMIZERtask_process_type: ON_REFERENCE_LINEpiecewise_jerk_nonlinear_speed_optimizer_config {acc_weight: 2.0 # ddxjerk_weight: 3.0 # dddxlat_acc_weight: 1000.0 # kappas_potential_weight: 0.05 # addref_v_weight: 5.0 # dxref_s_weight: 100.0 # xsoft_s_bound_weight: 1e6 # adduse_warm_start: true # add}
}
动态规划得到的轨迹还比较粗糙,需要用优化的方法对轨迹进行进一步的平滑。基于二次规划的速度规划的方法与路径规划基本一致。
- 确定优化变量
- 设计目标函数
- 设计约束
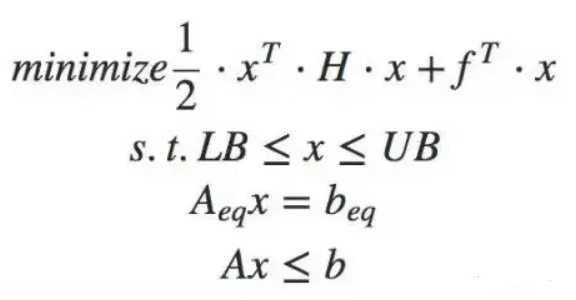
二次规划
- 这些成员函数之间的相互依赖关系见下图,其中Optimize( )是入口
- 调用FormulateProblem( )完成二次规划问题的建模,针对二次规划问题CalculateKerne( )完成目标函数中的H矩阵计算,CalculateOffset( )完成目标函数中的g矩阵计算,CalculateAffineConstraint( )完成约束条件中的A矩阵计算
- 最后借用osqp求解器完成求解
1.1.确定优化变量

1.2设计目标函数
对于目标函数的设计,我们需要明确以下目标:

1.3.要满足的约束条件

1.4.转化为二次规划问题求解

代入OSQP求解器进行求解,输出一条平稳、舒适、能安全避开障碍物并且尽快到达目的地的速度分配曲线。
二次规划速度规划算法的问题

基于二次规划的速度规划中,p i 是曲率关于时间t tt的函数,但实际上路径的曲率是与s 相关的。二次规划在原先动态规划出来的粗糙ST曲线上将关于s 的曲率惩罚转化为关于t 的曲率惩罚,如此,当二次规划曲线与动态规划曲线差别不大,规划出来基本一致;若规划差别大,则会差别很大。就如图所示,规划出来的区间差别较大。限速/曲率的函数是关于s 的函数,而s 是我们要求的优化量,只能通过动态规划进行转化,如此就会使得二次规划的速度约束不精确。
二次规划与非线性的选择:
二次规划在dp的ST曲线基础上将关于s的曲率惩罚转化为关于t的曲率惩罚,导致对于道路限速的反应不准确,如下图,sv图,绿线是地图实际限速,蓝线为二次规划求解所得。但是求解效率高。
非线性优化主要考虑曲率的约束,惩罚是关于s的函数,对于限速和曲率是更加准确和严格的;二次规划是关于t的函数,从dp的st图转化过来的,是对t的约束

非线性优化
// 输入:
scont PathData& path_data,const common::TrajectoryPoint& init_point SpeedData* const speed_dataconst auto problem_setups_status = SetUpStatesAndBounds(path_data, *speed_data);
const auto qp_smooth_status = OptimizeByQP(speed_data, &distance, &velocity, &acceleration, st_graph_data->mutable_st_graph_debug());
const auto speed_limit_smooth_status = SmoothSpeedLimit();
const auto nlp_smooth_status =OptimizeByNLP(&distance, &velocity, &acceleration);// 输出:
x,dx,ddx
speed_data->AppendSpeedPoint(distance[i], delta_t_ * i, velocity[i], acceleration[i],(acceleration[i] - acceleration[i - 1]) / delta_t_);2.1优化变量
基于非线性规划的速度规划步骤与之前规划步骤基本一致。

采样方式:等间隔的时间采样。s l o w e r s_{lower}与 s_{upper}为松弛变量,防止求解失败。2.2目标函数


2.3制定约束


将所有的限速函数相加,得到下图的限速函数,很明显,该函数既不连续也不可导,所以需要对其进行平滑处理。

对于限速曲线的平滑,Apollo采样分段多项式进行平滑,之后采样二次规划的方式进行求解。限速曲线的目标函数如下:

如此,我们就有了连续且可导的限速曲线。 再回到约束中,为了避免求解的失败,二次规划中对位置的硬约束,在非线性规划中转为了对位置的软约束。提升求解的精度。

同时还需满足基本的物理学原理

2.4求解器求解
最后代入Ipopt中进行非线性规划的求解。 Ipopt(Interior Point Optimizer)是一个用于大规模非线性优化的开源软件包。它可用于解决如下形式的非线性规划问题:
- CombinePathAndSpeedProfile
将SL曲线、ST曲线合成为完整轨迹,之后作为Planning的输出。

8.1 trajectory plan
更好的位形组成在上面的3个变量基础上加入车辆的即时转向曲率κ:如果车辆的导向轮保持一定的角度,车辆会做圆周运动。这个圆周运动的半径就是即时转向曲率 κ。加入κ,有助于控制模块获得更准确的控制反馈,设计更为精细平稳的控制器。
轨迹规划的正式定义,计算一个以时间t为参数的函数S,对于定义域内([0, t_max])的每一个t,都有满足条件的状态 s:满足目标车辆的运动学约束,碰撞约束,以及车辆的物理极限。

https://www.cnblogs.com/liuzubing/p/11051390.html
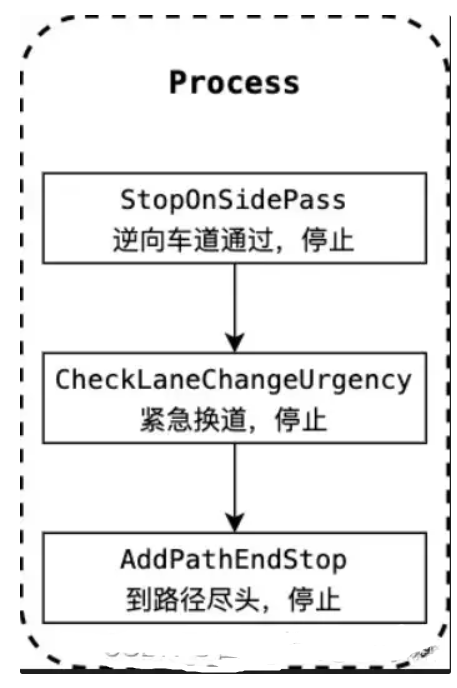
8.2 FallBack
GenerateFallbackPathBound
fallback是其他3种场景计算PathBound失败时的备选,只考虑自车信息和静态道路信息,不考虑静态障碍物。因此,speed decider负责让自车在障碍物前停车。
Status PathBoundsDecider::GenerateFallbackPathBound(const ReferenceLineInfo& reference_line_info, PathBound* const path_bound) {// 1. Initialize the path boundaries to be an indefinitely large area.if (!InitPathBoundary(reference_line_info, path_bound)) { ... }// 2. Decide a rough boundary based on lane info and ADC's positionstd::string dummy_borrow_lane_type;if (!GetBoundaryFromLanesAndADC(reference_line_info,LaneBorrowInfo::NO_BORROW, 0.5, path_bound,&dummy_borrow_lane_type)) { ... }return Status::OK();
}GenerateFallbackSpeed
SpeedData SpeedProfileGenerator::GenerateFallbackSpeed( const EgoInfo* ego_info, const double stop_distance) // s的最大范围应该符合车辆动力学,即车辆按照最大a和da进行刹车时,车辆在此范围内可以停下来,否则会造成优化问题无解 // 对于乘用车来说100m的刹车距离是足够了
#RT-DETRv3
真正的实时端到端目标检测算法,完爆YOLOv10~
真正的实时目标检测!百度超进化RT-DETRv3:一骑绝尘的端到端目标检测算法,性能&耗时完爆YOLOv10
写在前面 & 笔者的个人理解
RT-DETR是第一个基于实时端到端Transformer的目标检测器。其效率来源于框架设计和匈牙利匹配。然而与YOLO系列等密集的监督检测器相比,匈牙利匹配提供了更稀疏的监督,导致模型训练不足,难以达到最佳结果。为了解决这些问题,本文提出了一种基于RT-DETR的分层密集正监督方法,称为RT-DETRv3。首先引入了一个基于CNN的辅助分支,该分支提供密集的监督,与原始解码器协同工作,以增强编码器的特征表示。其次为了解决解码器训练不足的问题,进一步提出了一种涉及self-att扰动的新学习策略。该策略使多个查询组中阳性样本的标签分配多样化,从而丰富了阳例。此外引入了一个共享权重解编码器分支,用于密集的正向监督,以确保更多高质量的查询与GT匹配。值得注意的是,上述所有模块都只是训练策略。我们进行了广泛的实验,以证明我们的方法对COCOval2017的有效性。RT-DETRv3的性能明显优于现有的实时检测器,包括RT-DETR系列和YOLO系列。例如,与RT-DETR-R18/RT-DETRv2-R18相比,RT-DETRv3-R18实现了48.1%的AP(+1.6%/+1.4%),同时保持了相同的耗时。同时它只需要一半的时间就可以达到类似的性能。此外,RT-DETRv3-R101以54.6%的AP性能超越YOLOv10-X。

总结来说,本文的主要贡献如下:
引入了一种基于CNN的一对多标签分配辅助头,它与原始检测分支协作进行优化,进一步增强了编码器的表示能力。
提出了一种具有self-att扰动的学习策略,旨在通过在多个查询组中分散标签分配来增强对解码器的监督。此外引入了一个共享权重解码器分支,用于密集的正向监督,以确保更多高质量的查询与每个基本事实相匹配。这些方法显著提高了模型的性能,并在没有额外推理耗时的情况下加速了收敛。
在COCO数据集上进行的广泛实验彻底验证了我们提出的方法的有效性。如图1所示,RT-DETRv3明显优于其他实时检测器,包括RT-DETR系列和YOLO系列。例如,与RT-DETR-R18相比,RT-DETRv3-R18实现了48.1%的AP(+1.6%),同时保持了相同的延迟。此外RT-DETRv3-R50的AP比YOLOv9-C高0.9%,即使耗时减少了1.3ms。
相关工作回顾基于CNN的实时目标检测算法
目前基于CNN的实时目标探测器主要是YOLO系列。YOLOv4和YOLOv5优化了网络架构(例如,通过采用CSPNet和PAN),同时还利用了Mosaic数据增强。YOLOv6进一步优化了结构,包括RepVGG骨干、解耦头、SimSPPF和更有效的训练策略(例如SimOTA等)。YOLOv7引入了E-ELAN注意力模块,以更好地整合不同层次的特征,并采用自适应锚机制来提高小目标检测。YOLOv8提出了一个C2f模块,用于有效的特征提取和融合。YOLOv9提出了一种新的GELAN架构,并设计了一个PGI来增强训练过程。PP-YOLO系列是基于百度提出的飞桨框架的实时目标检测解决方案。该系列算法在YOLO系列的基础上进行了优化和改进,旨在提高检测精度和速度,以满足实际应用场景的需求。
基于Transformer的实时目标检测算法
RT-DETR是第一个实时端到端目标检测器。该方法设计了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合来有效地处理多尺度特征,并提出了IoU感知查询选择,通过向解码器提供更高质量的初始目标查询来进一步提高性能。其精度和速度均优于同期YOLO系列,受到了广泛关注。RT-DETRv2进一步优化了训练策略,包括动态数据增强和优化采样算子以便于部署,从而进一步提高了其模型性能。然而由于它们一对一的稀疏监督,收敛速度和最终效果有限。因此引入一对多标签分配策略可以进一步提高模型的性能。
辅助训练策略
Co-DETR提出了多个并行的一对多标签分配辅助头部训练策略(例如ATSS和Faster RCNN),可以很容易地增强端到端检测器中编码器的学习能力。例如,ViT-CoMer与Co-DETR的集成在COCO检测任务上取得了最先进的性能。DAC-DETR、MS-DETR和GroupDETR主要通过向模型的解码器添加一对多监督信息来加速模型的收敛。上述方法通过在模型的不同位置添加额外的辅助分支来加速收敛或提高模型的性能,但它们不是实时目标检测器。受此启发,我们在RT-DETR的编码器和解码器中引入了多个一对多辅助密集监控模块。这些模块提高了收敛速度,改善了RT-DETR的整体性能。由于这些模块仅在训练阶段参与,因此它们不会影响RT-DETR的推理耗时。
详解RT-DETRv3方法概览
RT-DETRv3的整体结构如图2所示。我们保留了RT-DETR的整体框架(以黄色突出显示),并额外引入了我们提出的分层解耦密集监督方法(以绿色突出显示)。最初,输入图像通过CNN骨干网(例如ResNet)和特征融合模块(称为高效混合编码器)进行处理,以获得多尺度特征{C3、C4和C5}。然后,这些特征被并行馈送到基于CNN的一对多辅助分支和基于变压器的解码器分支中。对于基于CNN的一对多辅助分支,我们直接采用现有的最先进的密集监督方法,如PP-YOLOE,来协同监督编码器的表示学习。在基于Transformer的解码器分支中,首先对多尺度特征进行展平和级联。然后,我们使用查询选择模块从中选择前k个特征来生成目标查询。在解码器中引入了一个掩码生成器,可以生成多组随机掩码。这些掩码应用于自我关注模块,影响查询之间的相关性,从而区分正向查询的分配。每组随机掩码都与相应的查询配对,如图2中的所示。此外,为了确保有更多高质量的查询与每个gt相匹配,我们在解码器中加入了一对多标签分配分支。以下部分详细描述了本工作中提出的模块。

Overview of RT-DETR
RT-DETR是一个为目标检测任务设计的实时检测框架。它集成了DETR的端到端预测的优点,同时优化了推理速度和检测精度。为了实现实时性能,编码器模块被一个轻量级的CNN骨干网和一个为高效特征融合而设计的高效混合编码器模块所取代。RT-DETR提出了一种不确定性最小查询选择模块,用于选择高置信度特征作为目标查询,降低了查询优化的难度。随后,解码器的多层通过自关注、交叉注意力和前馈网络(FFN)模块增强这些查询,并由MLP层产生预测结果。在训练优化过程中,RT-DETR采用匈牙利语匹配进行一对一分配。对于损失计算,它使用L1损失和GIoU损失来监督盒回归,并使用可变焦点损失(VFL)来监督分类任务的学习。
基于此CNN的One-to-Many辅助分支
为了缓解解码器的一对一集匹配方案导致的编码器输出稀疏监督问题,我们引入了一种具有一对多分配的辅助检测头,如PP-YOLOE。该策略可以有效地加强对编码器的监督,使其具有足够的表示能力来加速模型的收敛。具体来说,我们直接将编码器的输出特征{C3、C4和C5}集成到PP-YOLOE头中。对于一对多匹配算法,我们遵循PP-YOLOE头的配置,在训练的早期使用ATSS匹配算法,然后切换到TaskAlign匹配算法。为了学习分类和定位任务,分别选择了VFL和分布式聚焦损失(DFL)。其中,VFL使用IoU分数作为阳性样本的目标,这使得IoU较高的阳性样本对损失的贡献相对较大。这也使得模型在训练过程中更关注高质量的样本,而不是低质量的样本。具体来说,解码器头还使用VFL损失来确保任务定义的一致性。我们将CNN辅助分支的总损失表示为Laux,相应的损失重量表示为α。
基于变压器的多组自注意力扰动分支
解码器由一系列变压器块组成,每个块都包含一个自注意力、cross-att和FFN(前馈网络)模块。最初,查询通过自注意力模块相互交互,以增强或减少它们的特征表示。随后,每个查询通过交叉注意力模块从编码器的输出特征中检索信息来更新自身。最后,FFN预测与每个查询对应的目标的类和边界框坐标。然而,在RT-DETR中采用一对一的集合匹配会导致监督信息稀疏,最终损害模型的性能。
为了确保与同一目标相关的多个相关查询有机会参与正样本学习,我们提出了基于掩码自注意的多个自注意扰动模块。这个扰动模块的实现细节如图2所示。首先,我们通过查询选择模块生成多组目标查询,表示为OQi(i=1…N,其中N是集合的数量)。相应地,我们使用掩模生成器为每组OQi生成随机扰动掩模Mi。OQi和Mi都被输入到面具自注意模块中,从而产生扰动和融合的特征。

Mask Self-Attention模块的详细实现如图3所示,首先线性投影OQi以获得Qi、Ki和Vi。然后,将Qi和Ki相乘以计算注意力权重,再将注意力权重乘以Mi,并通过softmax函数得到扰动注意力权重。最后,将该扰动注意力权重乘以Vi,得到融合结果。该过程可以表示为:

引入多组随机扰动使查询的特征多样化,允许与同一目标相关的多个相关查询有机会被分配为正样本查询,从而丰富了监督信息。在训练过程中,多组目标查询被连接并馈入单个解码器分支,从而实现了参数共享并提高了训练效率。损失计算和标签分配方案与RT-DETR保持一致。我们将第i个集的损失表示为损失,N个扰动集的总损失计算如下:

基于变压器的一对多密集监督分支
为了使多组自关注扰动分支的收益最大化,我们在解码器中引入了一个具有共享权重的额外密集监督分支。这确保了更多高质量的查询与每个基本事实相匹配。具体来说,我们使用查询选择模块来生成一组唯一的目标查询。在样本匹配阶段,通过将训练标签复制因子m来生成增强目标集,默认值为4。随后,将此增强集与查询的预测进行匹配。损失计算与原始检测损失保持一致,我们将指定为该分支的损失函数,损失权重为。
整体损失如下所示:

实验结果
推理速度和算法性能。基于变压器架构的实时目标检测器主要由RT-DETR系列表示。表1显示了我们的方法和RT-DETR系列之间的比较结果。我们的方法在各种骨干上都优于RT-DETR和RT-DETRv2。具体而言,与RT-DETR相比,采用6倍训练计划,我们的方法显示R18、R34、R50和R101主干分别提高了1.6%、1.0%、0.3%和0.3%。与RT-DETRv2相比,我们在6x/10x训练计划下评估了R18和R34骨干,我们的方法分别提高了1.4%/0.8%和0.9%/0.2%。此外,由于我们提出的辅助密集监督分支仅用于训练,因此我们的方法保持了与RT-DETR和RT-DETRv2相同的推理速度。

收敛速度。我们的方法基于RT-DETR框架,通过结合基于CNN和基于Transformer的一对多密集监督,不仅提高了模型性能,还加快了收敛速度。我们进行了广泛的实验来验证我们方法的有效性。表1显示了不同训练计划下RT-DETRv3、RT-DETR和RT-DETRv2的比较分析。它清楚地表明,在任何调度中,我们的方法在收敛速度方面都优于它们,只需要一半的训练周期就可以达到类似的性能。

过拟合分析。如图4所示,我们注意到,随着模型大小的增加,RT-DETRv3往往表现出过拟合。我们认为这可能是由于训练数据集的大小与模型大小不匹配造成的。我们进行了几个实验,如表3所示,当我们添加额外的训练数据时,RT-DETRv3的性能随着训练周期的增加而持续提高,并且在相同的周期内,它的性能优于没有额外数据的模型。

与基于CNN的实时目标检测器的比较
推理速度和算法性能。我们将RT-DETRv3的端到端速度和准确性与当前先进的基于CNN的实时目标检测方法进行了比较。我们根据推理速度将模型分为小、中、大三个尺度。在类似的推理性能条件下,我们将RT-DETRv3与其他最先进的算法进行了比较,如YOLOv6-3.0、Gold-YOLO、YOLO-MS、YOLOv8、YOLOv0和YOLOv10。如表2所示,对于小规模模型,RT-DETRv3-R18方法的性能分别优于YOLOv6-3.0-S、Gold-YOLO-S、YOLO-MS-S、YOLOv8-S、YOLOv9-S和YOLOv10-S 4.4%、3.3%、2.5%、2.5%、2.0%和2.4%。对于中尺度模型,RT-DETRv3的性能也优于YOLOv6-3.0-M、Gold-YOLO-M、YOLO-MS-M、YOLOv8-M、YOLOv9-M和YOLOv10-M。对于大尺度模型,我们的方法始终优于基于CNN的实时目标检测器。例如,我们的RT-DETRv3-R101可以实现54.6个AP,这比YOLOv10-X要好。但是,由于我们还没有针对轻量级部署优化RT-DETRv3检测器的整体框架,因此RT-DETLv3的推理效率仍有进一步提高的空间。
收敛速度。如表2所示,我们很高兴地发现,与基于CNN的实时检测器相比,我们的RT-DETRv3在实现卓越性能的同时,可以将训练时间减少到60%甚至更少。

消融结果如下:

结论
本文提出了一种基于Transformer的实时目标检测算法RT-DETRv3。该算法在RT-DETR的基础上,引入了多个密集正样本辅助监督模块。这些模块将一对多目标监督应用于RT-DETR中编码器和解码器的特定特征,从而加速算法的收敛并提高其性能。值得注意的是,这些模块仅用于训练。我们在COCO目标检测基准上验证了我们算法的有效性,实验表明:与其他实时目标检测器相比,我们的算法取得了更好的结果。
#汽车居然也要用开源软件?
开源生态是推动软件技术创新的重要引擎,可以说现在世界上很多伟大的软件和OS都靠着开源,走向繁荣。
在自动驾驶平台领域,也有着许多开源平台,其中属Autoware最为著名,可以说,它在自动驾驶界的地位不亚于“Linux”。当然,不能把它理解成OS,它实际上是一套软件库和工具,可以帮助用户快速建立机器人应用程序。
作为汽车领域的工程师必知必会的平台之一、自动驾驶入门最有价值软件框架,最近一段时间,其热度正在不断攀升。
世界第一个自动驾驶开源软件
你有没有发现最近几年自动驾驶走得特别快?除了芯片本身发展较快外,开源平台也是加快自动驾驶脚步的重要因素之一。
自动驾驶平台开源的历史并没有多久,Autoware就是世界上第一个用于自动驾驶汽车的“All-in-One”(多合一)开源软件,现在国内热度很高的百度Apollo都是它的“小老弟”。它基于ROS(Robot Operating System,机器人操作系统),并在Apache2.0许可下使用,支持在各种车辆和应用中进行自动驾驶的商业部署。

Autoware的开源算法最初是由名古屋大学的客座副教授、东京大学的副教授加藤真平在2015年8月首次提出。2015年12月下旬,加藤伸平教授创立了Tier IV,以维护Autoware并将其应用于真正的自动驾驶汽车。
而后,开源自动驾驶平台就像雨后春笋一样,不断浮现:
- 百度Apollo:2017年4月推出,包括一整套硬件、软件和云服务解决方案,可以帮助开发者快速构建各种类型和规模的自动驾驶系统,从3.5版放弃传统的ROS,转用自己开发的CyberRT,Apollo推荐64位x86指令集的CPU加英伟达GPU架构;
- 英伟达DriveWorks:英伟达不仅抛弃了ROS,连Ubuntu也抛弃了,使用了微内核的QNX来代替Ubuntu。虽然说软件本身是开源的,但必须在使用英伟达GPU前提下使用,而且DriveWorks实际只是其中的最上层,关键的底层DriveOS,英伟达并未开源,因为DriveOS有相当多QNX的贡献,而QNX肯定是要收费的;
- 大陆汽车子公司Elektrobit的EB robinsand Predictor:VECTOR、博世旗下的ETAS和大陆旗下的EB并称AUTOSAR中间件三巨头,其EB robins完全没考虑非车规级的底层系统,它高度依赖Autosar,其评估套件是运行 EB robinos e-Horizon Provider (ADASIS) 的 Raspberry Pi 设备,所以主要支持Arm架构;
- comma.ai的OpenPilot:与上面的产品不同,OpenPilot专注于提供高级驾驶辅助系统(ADAS)功能,如自适应巡航控制和自动转向,OpenPolit的cereal中间件主打轻量化、高性能,并保持服务协议的全局一致性
- CARLA:它是一个开源的自动驾驶仿真平台,提供了真实的交通环境模拟,可以用于测试和验证自动驾驶算法,可以与Autoware耦合使用。
从上面主要厂商来看,软件计算框架可以主要分为ROS派生自动驾驶平台、专研自动驾驶平台(如Cyber RT)、面向工业界开发的软件框架Autosar三种技术路线。刚开始,厂商都和Autoware一样,基于ROS,后来慢慢改变了自己的路线,Autoware则一直保持本心,基于ROS。
从指令集架构来看,Autoware支推荐Arm指令集架构,但也支持Arm。历史上,Autoware刚开始被Arm鼎力支持,而后AMD也成为了Autoware基金会的白金会员之一。此外,Autoware的白金会员还包括华为、AWS、富士康、TIER IV等。
随着时间的流逝,Autoware已成为公认的开源项目。
看懂Autoware的里子
Autoware的优势很多。一是模块化架构,作为一个多合一平台,其集成了自动驾驶所需的所有功能,并采用模块化架构设计,具有清晰定义的接口和API;二是可扩展性,不仅能哦股扩展更多功能,还能联动别的软件;三是不断进化,其最新版本已经开始基于ROS 2.0进行重新设计:四是支持多种自动驾驶的应用场景,如出租车、公交车、货运、物流、农业、建筑、采矿等。
更重要的是,Autoware自动驾驶平台的ROS 2采用了代码优先的方法,使为此类系统开发新应用程序变得尽可能简单,代码可重复性高,学习起来比其它平台更容易上手,适合初学者,代码在Github(https://github.com/autowarefoundation/autoware)上面为全开源状态,可以直接安装使用。此外,Autoware自动驾驶平台考虑了更多的嵌入式系统。
传感器部分,Autoware支持多种传感器,包括相机、激光雷达(LiDAR)、惯导(IMU)和GPS等,提供了多种传感器的驱动和融合算法,主要功能包括感知、定位、规划与控制等。在Autoware中,每个相机分开管理,以便执行不同任务,如物体检测和交通信号灯识别等。此外,Autoware自动驾驶平台不支持将不同相机图像合成一个图像;在Autoware中,可以组合使用多台雷达扫描仪,提供丰富的融合点云数据,实现更精准的目标检测、跟踪和定位;GPS/GNSS接收器通常会通过串行接口生成符合NMEA标准的文本字符串。目前,几乎所有的GPS/GNSS产品都将与Autoware自动驾驶平台现有的nmea2tfpose节点兼容;不过,Autoware还没有独立的IMU模块适配,因为在不使用IMU情况下,通过基于SLAM算法的3D地图和里程计定位已经足够可靠。但是,由于IMU在某些场景中仍然有用,因此Autoware自动驾驶平台支持将IMU驱动程序和数据集成到本地模块中。
算法部分,包括感知、决策和路径规划三大功能。其中,感知功能由定位、检测和预测三个模块组成;决策功能跨越感知和路径规划功能,根据感知的结果,Autoware决定当前的驾驶行为,从而可以选择合适的规划函数;路径规划功能作用是根据感知和决策的结果制定全局运动方案与局部运动方案,路径规划功能由任务和运动两个模块组成。
驱动部分,算法部分的输出结果是一组速度、角速度、车轮角度和曲率,这些信息将作为命令通过车辆接口发送到线控控制器,线控控制器负责方向角度和油门的改变。

特别是现在的Autoware.Universe(开发者版本)和Autoware.core(稳定版本)版本,内容十分丰富,功能和性能相较Autoware.Ai和Autoware.Auto两个前期版本有了质的飞跃,由Sensing、Map、Localization、Perception、Planning、Control、Vehicle Interface七大模块组成。
不过,Autoware也不是万能的。虽然从ROS 1升级到了ROS 2,解决了实时性、master节点、跑不了嵌入式等问题,但车规方面建设并不很多。此外,自动驾驶开源项目商业模式不明确,很难形成有效的开发团队。在汽车行业内,也没有开源项目可以直接用于产品上,严格的测试认证需要较大资金投入。
对比Apollo,有什么异同
Apollo同属于开源自动驾驶平台这一赛道,也拥有很好的人气,行业对于二者的讨论也很多。
工程师普遍认为追求快速落地和生态圈,Autoware更好。ROS作为世界上最丰富的机器人操作系统,积累了大量的经验,避免了开发者重复的开发工作,提高了开发效率。但成也ROS,“败”也ROS,毕竟ROS更多针对机器人,原本并非针对汽车领域。同时,由于Linux是极其开放的开发环境,内核调度器对于算法业务逻辑并不清晰,只能保证公平的分配资源。所以,ROS Node运行顺序并无任何逻辑。当然随着进入新版本,Autoware也已经逐渐填补了这些缺点。
追求一些特殊场景的性能,选择Apollo。Apollo没有调度,无算法运算逻辑,同时增加了Component组件,组件之间通过Cyber channel通信。不过,Cyber RT用户经验少,同时资源也没有ROS全面。
当然,现在市场上也有一些双系统的选项,即Autoware(ROS 2)和Apollo相结合。也有一些厂商,比如Apex.AI开始尝试将Autoware(ROS 2)和Autosar相结合。反正都是开源的,结合起来也没啥毛病。

Autosar和ROS在Apex.AI产品中统一,来源:Apex.AI
总而言之,Autoware本身的人气在工程师群体内很高,是对这个行业有兴趣的人必知必会的平台之一。为了让广大工程师更好的学习Autoware,汽车开发圈也曾经放出一些学习资料,未来汽车开发圈还会继续为广大工程师提供更多资料。
#国内高校的具身智能实验室汇总
本期具身智能之心整理了国内高校的具身智能实验室,供大家参考。排名不分先后!!篇幅有限,欢迎大家补充。一起来看看吧~
清华MARS多模态学习实验室
主页:https://group.iiis.tsinghua.edu.cn/~marslab/#/
MARS Lab多模态学习实验室,是清华大学交叉信息院下的交叉学科人工智能实验室,由赵行教授组建和指导。当前MARS Lab特别感兴趣如何让机器像人一样的能够通过多种感知输入进行学习、推理和交互。MARS Lab的研究涵盖了多模态学习的基础问题及其应用:(1)多媒体计算, (2)自动驾驶, (3)机器人, (4)多传感器。
导师:赵行
研究成果:
图注:来源:https://www.bilibili.com/video/BV1h1421C7KQ/?vd_source=60762b2741beebb14f0eaac7c46cc65f
图注:论文《Robot Parkour Learning》成果展示 来源:https://robot-parkour.github.io/
代表性论文:
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models, https://arxiv.org/abs/2402.12289
A Universal Semantic-Geometric Representation for Robotic Manipulation, https://openreview.net/pdf?id=AIgm8ZE_DlD
Occ3D: A Large-Scale 3D Occupancy Prediction Benchmark for Autonomous Driving, https://arxiv.org/abs/2304.14365
Robot Parkour Learning, https://robot-parkour.github.io/resources/Robot_Parkour_Learning.pdf
IWIN-FINS实验室(智能无线网络与协同控制中心)
主页:https://iwin-fins.com/
简介:专注于为移动机器人、机器学习、控制和优化开发分布式、安全智能系统。
导师:何建平副教授
研究项目:(1)智能机器人控制系统:实验室构建了一个自主设计的多机器人平台,该平台上的机器人能够进行全方位、高精度控制和可靠通信。此外,这些机器人还非常便于嵌入其他先进的车载设备,以满足各种实际应用需求。(2)安全的数据驱动协作:每当收集、存储、使用或展示可识别个人身份的信息时,都会引发隐私和安全问题。实验室致力于研究保护隐私的信息交换机制和可靠的控制设计,以确保系统合作的安全性。(3)协调充电系统:作为无轨电车的储能装置,超级电容器在高功率充电系统中存在故障数据和输出偏差等问题,实验室希望制定可靠且安全的充电策略,以确保充电性能。(4)多智能体学习系统:专注于多智能体系统的一些前沿课题,以克服实现高级智能和安全性能所面临的挑战,包括智能感知、决策制定、协同控制、攻防理论及其在环境监测、目标搜索与跟踪等工业领域的应用。
研究成果:
图注:论文《Observation-based Optimal Control Law Learning with LQR Reconstruction》实验展示
图注:来源于论文《Unidentifiability of System Dynamics: Conditions and Controller Design》
代表性论文:
- Unidentifiability of System Dynamics: Conditions and Controller Design https://arxiv.org/abs/2308.15493
- Observation-based Optimal Control Law Learning with LQR Reconstruction https://arxiv.org/abs/2312.16572
- Multi-Robot Stochastic Patrolling via Graph Partitioning, Weizhen Wang https://ieeexplore.ieee.org/document/10683971
清华大学智能产业研究院(AIR)
主页:https://air.tsinghua.edu.cn/
导师:张亚勤、马维英、赵峰等人
简介:清华大学智能产业研究院(Institute for AI Industry Research, Tsinghua University,英文简称AIR,THU)是面向第四次工业革命的国际化、智能化、产业化的研究机构。研究院建立了智慧交通、智慧物联、智慧医疗、大数据智能和智能机器 人等5个科研团队,面向世界科技前沿、经济主战场、国家重大 需求、人民生命健康开展前沿研究,推动技术落地。
研究方向:智慧物联、智慧交通、智慧医疗、大数据智能、智能机器人
研究成果:
图注:清华大学万国数据教授、智能产业研究院(AIR)执行院长刘洋教授课题组在基于知识迁移的增量学习方面取得新进展,相关研究成果“基于知识迁移的多语言神经机器翻译增量学习方法”(英文名称Knowledge Transfer in Incremental Learning for Multilingual Neural Machine Translation)于北京时间2023年7月11日获得人工智能领域重要国际会议ACL 2023颁发的杰出论文奖(Outstanding Paper Award)。
代表性论文:
- DecisionNCE:Embodied Multimodal Representations via Implicit Preference https://arxiv.org/abs/2402.18137
- Instruction-Guided Visual Masking https://arxiv.org/abs/2405.19783
- Evolution of Future Medical AI Models — From Task-Specific, Disease-Centric to Universal Health https://ai.nejm.org/doi/full/10.1056/AIp2400289
- ESM All-Atom: Multi-Scale Protein Language Model for Unified Molecular Modeling https://arxiv.org/abs/2403.12995
清华大学智能系统与机器人实验室(ISR Lab)
主页:https://group.iiis.tsinghua.edu.cn/~isrlab/
导师:陈建宇
简介:智能系统与机器人实验室,简称ISRLab,是由陈建宇教授创立的一个前沿科研机构。该实验室隶属于清华大学跨学科信息科学研究所(IIIS, Institute for Interdisciplinary Information Sciences)及上海期智研究院。ISRLab的核心目标是研发高性能、高智能的先进机器人系统。ISRLab在机器人硬件设计、运动控制、感知与识别、人机交互等方面展开深入研究,旨在提升机器人的环境适应能力、任务执行效率和智能化水平。除此以外,ISRLab也在强化学习算法、策略优化、仿真环境构建等方面积极探索,旨在让机器人能够通过不断试错和学习来优化自身行为,实现更复杂的任务执行。ISRLab也开始关注大型语言模型在机器人领域的应用。通过集成先进的语言理解能力,机器人可以更好地理解人类指令、进行对话交流,并在一定程度上实现语义推理和决策制定。
研究方向:机器人技术、强化学习、大型语言模型
研究成果:
图注:论文《DoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment》成果展示
图注:论文《Decentralized Motor Skill Learning for Complex Robotic Systems》成果展示
图注:论文《Asking Before Acting: Gather Information in Embodied Decision Making with Language》成果展示
代表性论文:
- DoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment https://arxiv.org/abs/2307.00329
- Decentralized Motor Skill Learning for Complex Robotic Systems https://arxiv.org/abs/2306.17411
- Asking Before Acting: Gather Information in Embodied Decision Making with Language Models https://arxiv.org/abs/2305.15695
- Learning Robust, Agile, Natural Legged Locomotion Skills in the Wild https://arxiv.org/abs/2304.10888
具身感知与交互实验室(Embodied Perception and InteraCtion (EPIC) Lab)
主页:https://hughw19.github.io/
简介:EPIC实验室由北京大学前沿计算研究中心的助理教授王鹤博士创立并领导。实验室的研究目标是通过发展具身技能及具身多模态大模型,推进通用具身智能的实现。这包括在三维复杂环境中,使机器人具备感知、决策和执行的能力。实验室重点关注具身机器人在三维复杂环境中的感知和交互问题,研究内容涵盖物体抓取、功能性操控、灵巧操作及寻物导航等。此外,实验室提出了本体层、技能层和大模型层构成的三层级具身多模态大模型系统,旨在实现通用机器人。
研究方向:三维视觉感知与机器人学,具身多模态大模型
研究成果:
图注:论文《Task-Oriented Dexterous Grasp Synthesis via Differentiable Grasp Wrench Boundary Estimator》结果展示
图注:IROS 2024 Oral presentation 成果展示《Open6DOR: Benchmarking Open-instruction 6-DoF Object Rearrangement and A VLM-based Approach》
图注:论文《MaskClustering: View Consensus based Mask Graph Clustering for Open-Vocabulary 3D Instance Segmentation》成果展示
代表性论文:
- Task-Oriented Dexterous Grasp Synthesis via Differentiable Grasp Wrench Boundary Estimator https://arxiv.org/abs/2309.13586
- NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation https://arxiv.org/abs/2402.15852
- MaskClustering: View Consensus based Mask Graph Clustering for Open-Vocabulary 3D Instance Segmentation https://arxiv.org/abs/2401.07745
智能机器人与机器视觉(IRMV)实验室
主页:https://irmv.sjtu.edu.cn/cn
简介:智能机器人与机器视觉(IRMV)实验室旨在在具有挑战性的非结构化环境下通过视觉感知实现通用机器人自动化和机器智能。IRMV 实验室属于上海交通大学自动化系,自主机器人实验室。实验室的研究目标是为具有挑战性的非结构化环境下的自主机器人和人工智能智能开发强大的机器视觉算法。为此,围绕视觉伺服、自动驾驶、软体机器人、无人机、医疗机器人、强化学习控制、多机器人控制和大规模调度 和 机器视觉项目等课题进行探索和研究。
导师:王贺升、刘哲、徐璠等人
研究成果:
图注:基于规划的视觉伺服:设计了一种基于二次规划的局部规划器(控制器),其能够在视觉伺服过程中处理视野、关节(位置、速度/力矩)极限并缓解奇异现象的出现,结合基于采样的全局规划框架,能够以高效率处理大部分受约束视觉伺服问题(T-MECH 2024 Under Review)
图注:无人送货机器人:与唯品会合作,提出了一种基于多传感器融合的无人系统,具有自主导航、定位、规划和控制算法,以解决物流园区的最后一英里交付问题。
代表性论文:
- Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Applications https://ieeexplore.ieee.org/document/10657322
- DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement https://ieeexplore.ieee.org/document/10655787
- 3DSFLabelling: Boosting 3D Scene Flow Estimation by Pseudo Auto-Labelling https://ieeexplore.ieee.org/document/10656074
- Cognitive Navigation for Intelligent Mobile Robots: A Learning-Based Approach with Topological Memory Configuration https://ieeexplore.ieee.org/document/10551318
数字媒体与计算机视觉实验室 商汤科技 – 上海交大深度学习与计算机视觉联合实验室
主页:https://dmcv.sjtu.edu.cn/
简介:数字媒体与计算机视觉实验室(DMCV),隶属于上海交通大学,是一个致力于计算机视觉、人工智能与计算机图形学领域前沿研究的科研团队。实验室得到了国家自然科学基金委员会(NSFC)及上海市科学技术委员会的大力支持,并与腾讯、商汤科技等行业领军企业建立了深度的合作关系。
研究方向:计算机视觉、数字图像处理、计算机图形、虚拟现实
导师:马利庄,卢策吾,盛斌,肖双九等人
研究成果:
图注:论文《TransVOD: End-to-End Video Object Detection with Spatial-Temporal Transformers》成果展示
图注:论文《Understanding Pixel-Level 2D Image Semantics With 3D Keypoint Knowledge Engine》成果展示
代表性论文:
- Qianyu Zhou, Xiangtai Li, Lu He, Yibo Yang, Guangliang Cheng, Yunhai Tong, Lizhuang Ma, Dacheng Tao. TransVOD: End-to-End Video Object Detection with Spatial-Temporal Transformers[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence (IEEE TPAMI), 2022. https://arxiv.org/abs/2201.05047
- Xin Tan, Jiaying Lin, Ke Xu, Pan Chen, Lizhuang Ma, and Rynson Lau. Mirror Detection with the Visual Chirality Cue[J]. EEE Trans. on Pattern Analysis and Machine Intelligence (IEEE TPAMI), 2022. https://ieeexplore.ieee.org/document/9793716
- Yang You, Chengkun Li, Yujing Lou, Zhoujun Cheng, Liangwei Li, Lizhuang Ma, Weiming Wang, Cewu Lu: Understanding Pixel-Level 2D Image Semantics With 3D Keypoint Knowledge Engine [J]. IEEE Trans. on Pattern Analysis and Machine Intelligence (IEEE TPAMI), 2022. https://arxiv.org/abs/2111.10817
上海交通大学赵波老师实验室
主页:https://www.bozhao.me/
简介:赵波老师是上海交通大学人工智能学院的副教授(终身教职轨道)。在加入上海交通大学之前,他曾在北京人工智能研究院(BAAI)担任首席研究员,领导数据中心人工智能(DCAI)团队。赵波老师拥有爱丁堡大学博士学位和北京大学工学硕士学位。他在Snap Inc.和商汤科技担任过研究实习生。他和他的团队开发了轻量级多模态大语言模型——Bunny-3B/4B/8B,并计划共同组织在CVPR'24和ECCV'24上的数据集蒸馏研讨会和挑战赛,并邀请学术界和工业界提交相关论文。
研究方向:多模态大语言模型(MLLM)、6D 物体姿态估计和姿态跟踪、具身人工智能(Embodied AI)和机器学习等领域。
研究成果:
图注:赵波老师和他的团队开发的轻量级多模态大语言模型——Bunny-3B/4B/8B,来源:https://github.com/BAAI-DCAI/Bunny
图注:论文《Omni6DPose: A Benchmark and Model for Universal 6D Object Pose Estimation and Tracking》成果展示。来源:https://jiyao06.github.io/Omni6DPose/
代表性论文:
- Efficient Multimodal Learning from Data-centric Perspective https://arxiv.org/abs/2402.11530
- Omni6DPose: A Benchmark and Model for Universal 6D Object Pose Estimation and Tracking. https://arxiv.org/pdf/2406.04316
- VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval. https://arxiv.org/pdf/2406.04292
复旦大学智能人机交互实验室(MemX)
主页:https://www.memx.life/#/
简介:在通用人工智能(AGI)时代,实验室定义了大语言模型与智能可穿戴技术相融合的人机交互新范式。实验室开发了MemX,是世界上首个智能眼镜与大语言模型(LLM)相结合的可穿戴AGI。实验室致力于实现以人为中心的通用智能可穿戴系统,研究重点包括移动端视觉-语言模型、个性化AGI、低功耗深度学习技术、智能可穿戴设备设计等。同时,实验室希望开发Q智能体,一款先进的基于LLM与多智能体技术的通用人工智能系统,执行不同任务的同时能够自我学习和适应,不断提升智能水平。
研究方向:可穿戴AGI、Q-智能体、具身智能
导师:尚笠、Robert P. Dick、杨帆、常玉虎、黄将历等人
成果展示:
代表性论文:
- Zhenyu Xu, Hailin Xu, Zhouyang Lu, Yingying Zhao, Rui Zhu, Yujiang Wang, Mingzhi Dong, Yuhu Chang, Qin Lv, Robert P. Dick, Fan Yang, Tun Lu, Ning Gu, and Li Shang, “Can Large Language Models Be Good Companions? An LLM-Based Eyewear System with Conversational Common Ground,” ACM Interactive Mobile Wearable & Ubiquitous Technologies (IMWUT), Vol. 8, No. 2, pp. 1-41, June 2024. (Accepted)
- Yubin Shi, Yixuan Chen, Mingzhi Dong, Xiaochen Yang, Dongsheng Li, Yujiang Wang, Robert Dick, Qin Lv, Yingying Zhao, Fan Yang, Tun Lu, Ning Gu, and Li Shang, “Train Faster, Perform Better: Modular Adaptive Training in Over-Parameterized Models,” in Proceedings Conference on Neural Information Processing Systems (NeurIPS), December 2023.
- Maya Okawa, Ekdeep S. Lubana, Robert P. Dick, and Hidenori Tanaka, “Compositional abilities emerge multiplicatively: Exploring diffusion models on a synthetic task,” in Proceedings Conference on Neural Information Processing Systems (NeurIPS), December 2023.
复旦智能感知与无人系统实验室
主页:https://ipass.fudan.edu.cn/
简介:复旦智能感知与无人系统实验室近年来在机器直觉、人机物三元融合智能等新一代人工智能理论、智能感知与人机交互、计算机视觉与行为分析、数字孪生与虚拟仿真、智能计算与智能芯片、智能驾驶与智慧医疗等领域开展创新研究。
导师:张立华、康晓洋、董志岩、陈迟晓、曹凯、王哲、翟鹏等人
科研项目:
- “新一代人工智能”重大项目:“标准化儿童患者模型关键技术与应用”
- “人机物三元协同行为与群智涌现”
- 三元空间群智智能基础理论与关键技术前瞻性研究
- 肝癌智能化精准外科的共性关键技术体系的建立
研究成果:
图注:《医工结合项目捷报 |复旦大学工研院发展脑机解码新方法,实现超低延迟的运动想象脑电解码》图1 所提出的解码系统框架。(a)传导模型生成,使用ICBM152模型的MRI数据建立三层头部模型。(b)基于Desikan Killiany图谱选择感兴趣区域,并生成感兴趣区域的源信号。(c)特征提取和分类。FBCSP算法用于训练空间滤波器内核,以生成相应的频带时间序列特征。采用带空间-时间自注意机制的神经网络完成特征分类。通过将测试数据直接与滤波器核相乘来获得特征,最后通过分类获得预测结果。来源:https://ipass.fudan.edu.cn/3f/89/c38382a475017/page.htm
图注:存算融合人工智能芯片“COMB-MCM”及其多芯粒集成封装。来源《克服冯诺依曼瓶颈:工研院张立华课题组参与合作研发的人工智能芯片亮相ISSCC 2022》https://ipass.fudan.edu.cn/f1/a3/c38382a455075/page.htm
代表性论文:
- Robust Adaptive Ensemble Adversary Reinforcement Learning https://ieeexplore.ieee.org/document/9942298
- COMB-MCM: Computing-on-Memory-Boundary NN Processor with Bipolar Bitwise Sparsity Optimization for Scalable Multi-Chiplet-Module Edge Machine Learning https://ieeexplore.ieee.org/document/9731657
- Comparison of MI-EEG Decoding in Source to Sensor Domain https://ieeexplore.ieee.org/abstract/document/9871186
- N170 component analysis of single-trial EEG based on electrophysiological source imaging https://ieeexplore.ieee.org/document/9871791
鹏城实验室多智能体与具身智能研究所
主页:https://imaei.github.io/
简介:多智能体与具身智能研究所隶属于鹏城实验室网络智能研究部,所长为林倞教授,成员包括数十名在人工智能、多模态大数据分析、嵌入式系统及机器人领域取得显著成果的青年科学家。研究所以人工智能前沿技术探索、以及原创技术引领产业发展为导向,重点突破智能体视角下的多模态感知与生成、智能体任务生成与规划、多智能体的通讯协作与联合决策、具身智能体的控制与人机共融、智能体评测机制与体系等几大方向开展研究。相关课题将涵盖从基础理论到实际应用的全方位内容,旨在通过领域合作研究,解决现实世界中的复杂智能体问题,支撑智能制造、工业物联网、无人自主系统、机器人系统在内的多个场景的规模化产业应用。
代表性成果(1):携手国内知名高校及科创企业共同打造国内首个大规模、多模态,并且涵盖多个场景、技能、任务、平台类型的具身智能数据集ARIO(All Robots In One)。链接:https://openi.pcl.ac.cn/ARIO/ARIO
代表性成果(2):深度参与具身智能技术国家标准和国际标准制定工作,牵头《具身智能虚实融合训练系统设计规范》、《具身智能多模态感规控开源数据结构规范》等标准制定工作,参与《人工智能人形机器人成熟度分级》、《人工智能具身智能系统技术规范》、《具身智能数据采集规范》等多项国家标准制定工作。
代表性成果(3):初步建立了基于Gazebo、Mujoco、Isaac等开源工具的具身智能虚实融合训练系统,并在该类工具中对松灵机器人、Aloha机器人等实体设备和虚拟模型进行虚实融合交互控制、采集数据,下一步将开展虚实融合模型训练和模型验证等工作,实现城市级的具身智能虚实融合训练平台。
图注:论文《Affordances-Oriented Planning using Foundation Models for Continuous Vision-Language Navigation》成果展示
图注:论文《NavCoT: Boosting LLM-Based Vision-and-Language Navigation via Learning Disentangled Reasoning》成果展示
代表性论文:
- Affordances-Oriented Planning using Foundation Models for Continuous Vision-Language Navigation https://arxiv.org/abs/2407.05890
- NavCoT: Boosting LLM-Based Vision-and-Language Navigation via Learning Disentangled Reasoning https://arxiv.org/abs/2403.07376
- MapGPT: Map-Guided Prompting with Adaptive Path Planning for Vision-and-Language Navigation https://arxiv.org/abs/2401.07314
- Surfer: Progressive Reasoning with World Models for Robotic Manipulation https://arxiv.org/abs/2306.11335
中山大学人机物智能融合实验室(HCP)
主页:https://www.sysu-hcp.net/home/
简介:中山大学人机物智能融合实验室围绕“人工智能前沿技术与产业化”布局研究方向与课题,并深入应用场景打造产品原型,输出大量原创技术及孵化创业团队。在多模态认知计算、机器人与嵌入式系统、元宇宙与数字人、可控内容生成等领域开展体系化研究,以“攀学术高峰、踏应用实地”为工作理念。
成果展示:
图注:来源:论文《CorNav: Autonomous Agent with Self-Corrected Planning for Zero-Shot Vision-and-Language Navigation》针对视觉语言导航,提出CorNav 框架:利用大型语言模型进行决策,包含两个关键组件。一是纳入环境反馈以改进未来计划并调整行动;二是多个领域专家用于解析指令、理解场景和改进预测行动。
图注:论文《TIP-Editor: An Accurate 3D Editor Following Both Text-Prompts And Image-Prompts》成果展示。TIP-Editor 框架:接受文本和图像提示以及 3D 包围框来指定编辑区域。图像提示可让用户方便地指定目标内容的详细外观 / 风格,补充文本描述,从而实现对外观的准确控制。
图注:《多模态大模型:新一代人工智能技术范式》本书以深入浅出的方式全面地介绍了多模态大模型的核心技术与典型应用,并围绕新一代人工智能技术范式,详细阐述了因果推理、世界模型、超级智能体与具身智能等前沿技术。希望本书能够为学术界和工业界提供一个清晰的视角,以帮助人工智能科研工作者更全面地了解多模态大模型的技术和新一代人工智能的发展方向。
代表性论文:
- CorNav: Autonomous Agent with Self-Corrected Planning for Zero-Shot Vision-and-Language Navigation https://arxiv.org/abs/2306.10322
- NeRF-HuGS: Improved Neural Radiance Fields in Non-static Scenes Using Heuristics-Guided Segmentation https://arxiv.org/abs/2403.17537
- OVER-NAV: Elevating Iterative Vision-and-Language Navigation with Open-Vocabulary Detection and StructurEd Representation https://arxiv.org/abs/2403.17334
#DrivingForward
专为驾驶场景而生!上交&华师,珠联璧合拿下SOTA~
目前,具备智驾技术的自动驾驶汽车都会配备环视相机来捕捉周围的3D环境。3D场景重建对于自动驾驶系统理解驾驶场景至关重要,此外,从稀疏的车载摄像头实时准确地重建驾驶场景有助于自动驾驶中的各种下游任务,包括在线建图、BEV感知和3D目标检测。
然而,各类下游任务所需的实时计算和稀疏的周围视图对驾驶场景重建提出了挑战。从目前来看,NeRF和3DGS显著推动了3D场景重建任务的发展,但目前最新的相关技术通常需要较多的图像以及比较长时间的计算时间才能重建出一个场景,导致这些重建方法并不适用于自动驾驶中的实时下游任务,从而限制了它们的实用性。
考虑到上述提到的相关问题,我们的目标是从稀疏的环视视图中实现在线、可泛化的3D驾驶场景重建。考虑到在线和可泛化的3D驾驶场景重建面临的挑战包括实时处理、稀疏的周围视图和最小重叠以及输入帧数量的可变性,我们提出了一种新颖的前馈3DGS算法模型,可以从灵活稀疏的环视图像中实时重建驾驶场景,该算法称之为DrivingForward。
在nuScenes数据集上进行的大量实验结果表明,我们提出的DrivingForward算法模型在各种输入下的新视图合成方面优于其他前馈算法模型。与具有相同输入的场景优化方法相比,DrivingForward算法还实现了更高的重建质量。下图展示了我们提出的DrivingForward与最新相关算法的表现性能比较。

将我们提出的DrivingForward算法模型与其他相关算法进行对比
论文链接:https://arxiv.org/pdf/2409.12753v1;
网络模型的整体架构&细节梳理
在详细介绍本文提出的DrivingForward算法模型之前,下图展示了我们提出的DrivingForward算法的整体网络结构。

提出的DrivingForward算法模型的整体流程图
通过上图可以看出,整体而言,我们选择个稀疏相机图像作为输入,最终得到3D场景重建结果。DrivingForward算法模型在训练过程中从大规模驾驶场景数据集中学习强大的先验知识,并在推理阶段从稀疏的车载摄像头以前馈的方式实现实时驾驶场景重建。
具体而言,一个位姿网络和深度估计网络从输入图片中预测车辆的运动以及像素的深度信息。我们将每个像素分配给一个高斯基元,并通过估计的深度定位位置。高斯基元的其他参数由高斯网络预测。我们将所有视图中的高斯基元投影到3D场景空间中,以可区分的方式将它们渲染到目标视图上,并端到端联合训练整个算法模型。在推理阶段,深度估计网络和高斯网络用于前馈重建。由于尺度感知定位和其他参数的预测不依赖于其他帧,我们可以在推理过程中灵活地输入不同数量的环视帧数据信息。
尺度感知定位
原始的3DGS重建算法显式地使用一组高斯基元来建模场景。该算法使用来自运动的结构来初始化高斯位置,并通过基于splat的光栅化渲染对其进行优化。相反,为了实现无需测试时优化的前馈推理,我们直接从输入图像以像素为单位预测高斯基元,并将每个像素分配给一个基元。 这样,准确定位高斯基元的位置是高质量重建的关键,因为它决定了基元的中心。 然而,在驾驶场景中,稀疏摄像机之间的有限重叠限制了从多个视图获得的几何关系。 我们改为估计单帧的深度图,而不依赖于其他帧。为了获得多帧一致的深度,我们提出了一种受自监督环视深度估计启发的尺度感知定位,它在训练期间从多帧环视中学习尺度感知深度,并在推理期间从周围视图的不同帧中独立预测真实尺度的深度,从而实现一致的尺度感知高斯定位。
具体而言,我们在尺度感知定位中引入了位姿网络以及深度网络。在训练阶段,我们从稀疏的车载摄像头输入多帧环视图像。姿态网络预测车辆运动,深度网络估计深度图,用公式表述如下。
其中,代表在时间戳时刻的相机的图像,是从时间戳到时间戳的映射矩阵。
为了以自监督的方式从输入图像中学习相机运动和尺度感知深度图,我们对多帧周围视图应用了光度损失。光度损失用于最小化目标图像 和从源图像扭曲的合成图像之间的投影损失,并且通常从立体对或单目视频中获得。
其中是结构相似性度量。Warp操作可以表示为如下的形式。其中,和是相机和的内参,是的深度图,是到的相机变换矩阵。
在具有多帧周围视图的驾驶场景中,我们将不同的输入作为源图像来计算光度损失。首先,我们使用来自同一相机的不同帧的图像,表示为时间上下文。然后,我们使用来自同一帧的相邻相机的图像,表示为空间上下文。我们还结合了这两种方式,使用来自不同帧的相邻相机的图像,表示为时空上下文。关键是利用空间和时间相邻图像之间的小重叠进行匹配,这提供了尺度信息并能够在训练期间学习尺度感知的相机运动和深度图。
假设和是两个相邻的相机,和是在时间戳时刻的图像数据,则上述的相关数据可以通过下面的公式来进行计算。


其中,和是从相机坐标系到车辆坐标系的变换矩阵。需要注意的是,此相机到车辆的变换矩阵在所有时刻中对于每个相机都是固定的,并且在实际中相对容易获得,而一般的世界到相机外部参数在每个时刻都会发生变化,因此收集成本很高。利用固定的相机到车辆变换矩阵和姿势网络预测的相机运动,我们在训练期间不需要世界到相机外部参数,从而凸显我们算法的优越性。
单张图像的高斯参数预测
在我们提出的DrivingForward算法中,每个高斯基元都根据原始3DGS通过属性进行参数化,其中协方差矩阵能够被分解为缩放因子和旋转四元数。我们通过尺度感知定位获得,然后我们需要预测其他参数,包括缩放因子,旋转四元数,不透明度以及颜色。基于此,我们提出了一个高斯网络来独立地从每幅图像中预测这些参数,并聚合所有图像中的高斯基元,这更适合稀疏车载摄像头之间重叠较小的驾驶场景。为了确保预测的高斯参数在所有输入视图中保持一致,我们利用深度网络中先前的尺度感知深度和图像特征作为高斯网络的输入。由于先前的深度网络从空间和时间上下文图像中学习尺度信息,我们认为尺度感知深度和图像特征可以增强剩余高斯参数的多视图一致性。
高斯网络包含有一个深度编码器,一个特征融合解码器以及用于尺度缩放因子,旋转四元数,不透明度以及色彩的预测头,,,。给定每张输入图像的输出预测深度图,高斯网络的深度编码器提取深度特征。
然后,融合编码器结合了以及来自深度网络编码器的图像特征。
其中,代表特征级别的合并操作,是高斯参数预测的融合特征。预测头仅由两个卷积组成,可以有效地从融合特征中预测参数。由于高斯网络无需依赖其他帧,仅从一帧环视图像预测高斯参数,因此基于单帧的预测支持灵活的单帧或多帧环视输入,而不局限于两帧相邻帧的成对图像等固定输入。
联合训练策略
通过对每个输入视图应用尺度感知定位和高斯参数预测,我们获得所有图像的高斯基元。然后将这些基元聚合到3D空间中以形成3D表达。通过3DGS中基于splat的光栅化渲染可以实现新颖的视图合成。
我们联合训练整个模型,包括深度网络、位姿网络和高斯网络。对于深度和位姿网络的warp操作,我们使用spatial transformer网络从源图像中采样合成图像。为了在3D空间中获得高斯基元后渲染新颖的视图,基于splat的光栅化渲染也是完全可微的。这两个操作以及其他可微分部分使端到端的联合训练成为可能。我们将来自深度网络的图像特征融合到高斯网络中。此共享特征将尺度感知位置与其他高斯参数的预测联系起来,使高斯网络能够利用来自时间和空间上下文的尺度信息。此外,它还促进了整个模型的收敛。
通过联合训练策略,我们在一个阶段实现了尺度感知定位和高斯参数预测,并支持灵活的多帧输入,因为预测独立地依赖于周围视图的每一帧数据信息。
实验结果&评价指标
由于我们的方法是最早探索实时重建驾驶场景的方法之一,目前尚无可用的基准。因此,我们定义了两种新颖的视图合成模式,以适应不同的比较方法。第一种方法是单帧模式(Single Frame,SF),即给定时间戳,目标是在时间戳时刻合成下一帧的周围环视图像。另外一种是多帧模式(Multi Frame,MF),即给定两个间隔帧的环视图像,即时间戳和时刻的环视图像,目标是合成时间戳时刻的中间环视图像。使用两种新颖的视图合成模式,我们将我们的方法与前馈和场景优化重建方法进行了比较,相关的实验结果汇总在如下的表格当中。

通过上图的实验结果可以看出,尽管我们调整了方法以适应baseline的不同设置,但我们在相应配置下的所有指标上都优于它们。此外,为了更加直观的展示我们提出的算法模型的优越性,我们也将相关的结果进行了可视化。

不同算法模型的可视化结果

不同算法模型的可视化结果比较
通过可视化的结果可以看出,我们的DrivingForward算法模型取得了最高质量的效果,即使是对于具有挑战性的细节,例如左前视图中的交通标志和右后视图中带有文字的纪念碑。其他方法在这些区域中显示出明显的伪影,而我们的方法合成了清晰的新颖视图而没有此类伪影。
我们将我们的前馈方法与代表场景优化方法的原始3DGS进行了比较。在SF模式下,我们训练模型并从验证集中选择前三个场景。然后,我们针对每个场景分别优化3DGS模型,并将3DGS模型渲染的新视图图像与我们的进行比较。下表展示了三个场景的平均测试时间和指标。3DGS需要几分钟来合成场景的新视图。相比之下,我们的前馈方法在半秒内完成此操作,并且无需过多的测试时间优化即可实现更高的重建质量。

此外,我们也比较了不同算法之间的运行时间和内存消耗,统计结果如下表所示。

通过统计结果也可以明显的看出,我们在运行时间和内存消耗等方面都更有优势。
结论
在本文中,我们提出了一个前馈Gaussian Splatting算法模型,用于在输入环视图像的情况下实现实时的驾驶场景重建,该算法称之为DrivingForward。此外,我们提出的DrivingForward算法模型不需要深度真值信息,并且在训练过程中不受外部因素的影响。相关的实验结果表明,在推理阶段,与现有的前馈和场景优化重建方法相比,我们提出的算法模型比其他方法更快,并且对驾驶场景实现了更高的重建质量。
#MA2T
北航出品MA2T:基于端到端驾驶模型的对抗训练新方法!
在自动驾驶系统当中包括感知、预测以及规控在内的各个功能模块。传统的解决方案主要是侧重于独立的解决单个子任务,但是这可能导致诸如模块间信息丢失、错误累积和特征错位等问题。因此,学术界和工业界为了应对这些挑战,提出了端到端的自动驾驶算法模型,这类算法模型将从感知到规划的所有组件统一起来,以提供更全面的解决方案并实现最先进的表现性能。
虽然目前提出的各类基于深度学习的自动驾驶模型具有良好的表现性能,但它在对抗性攻击,细微的扰动都会显著降低模型性能。先前的相关研究工作已经广泛评估了自动驾驶系统在各种子任务,比如目标检测、轨迹预测以及端到端算法模型中的对抗鲁棒性。但是,端到端的自动驾驶模型受到的关注相对较少。这种研究的稀疏性对端到端自动驾驶的安全性构成了严重风险,增加了其受到攻击的脆弱性。
因此基于上述提到的相关问题,本文提出了研究端到端自动驾驶背景下的对抗训练,但是由于学习范式不同,简单地将现有的对抗性训练基线扩展到端到端自动驾驶任务上存在两点挑战。
多样化的训练目标:由于整个端到端流程中每个模块的训练目标并不同,因此设计有效的对抗性训练目标具有很大的挑战性
不同模块的贡献:不同的模块对模型最终决策的稳健性有不同的影响和贡献程度
因此,基于上述提到的端到端自动驾驶的背景以及相关的挑战,本文提出了基于模块化的自适应对抗训练算法。为了验证提出算法模型的有效性,我们在nuScenes数据集上进行了大量的实验,实验涉及多个端到端自动驾驶模型。同时面对白盒和黑盒攻击,我们提出的方法相比其他基线方法表现更加优异。此外,我们通过CARLA模拟环境中的闭环评估验证了我们防御的稳健性,结果表明,即使面对自然破坏,我们的防御能力也得到了提升。
论文链接如下:https://arxiv.org/pdf/2409.07321v1
网络模型的整体架构&细节梳理
在详细介绍本文提出的算法模型之前,下图展示了我们提出的算法模型的整体思路,包含了基于模块化的噪声注入以及动态权重累计适应。
以UniAD为例说明提出的算法模型
具体而言,针对模块间训练目标不同的问题,我们设计了模块化的噪声注入,以总体目标而非各个独立模块损失来训练模型。这种方法确保噪声的生成具有模型的整体性,使用总体损失进行反向传播,而不是关注可能相互矛盾并对整体决策鲁棒性产生负面影响的单个模块损失。为了管理训练过程中模块的不同贡献,我们引入了动态权重累积自适应,它根据噪声注入期间模块的贡献自适应地调整每个模块的损失权重以适应总体目标。具体而言,该方法结合了权重累积因子来调整下降率以保持平衡的训练过程,可以自适应地控制每个模块的权重并防止任何模块在训练期间的急剧下降。
基于模块化的噪声注入
为了应对多样化训练目标带来的挑战,我们设计了模块化的噪声注入方法。我们将噪声直接注入算法模型的每个模块的输入中,以确保对所有模块进行全面的训练。虽然之前的相关方法针对每个模块的损失,但这可能会导致对模型产生不一致的影响。为了缓解这种情况,我们采用统一的目标来指导模型的训练过程。
具体而言,我们在每个模块的输入引入了噪声来实现模块化的噪声注入,具体流程如下公式所示。
其中代表在感知、预测和规划模块中对第个图像应用特定的对抗性扰动。在常规的训练过程中,总损失是通过汇总每个模块的损失来计算的。具体来说,它是感知模块损失,预测模块损失以及规划模块损失的总和。
其中,我们引入了来表达所有模块的总损失和。对于生成的每个,我们使用总损失作为攻击目标。对抗模型的目标是最大化对抗条件下的总损失,公式如下所示。
这种策略可以保证在产生噪声时,攻击的目标是总损失。这里我们以UniAD算法模型为例,我们可以将噪声注入到五个不同的模块当中。噪声注入管道的位置有:数据输入、数据传播、损失反向传播、噪声注入以及提供噪声生成的梯度。
动态权重累计适应
我们通过引入了动态权重累计适应思想来解决不同模块的贡献的挑战,通过合并累积权重变化自适应地调整每个模块的损失权重。这种方法利用模块的贡献来确保更好的平衡和更稳健的训练。前向传播过程中每个模块的损失可以用来描述。受到多任务学习中动态加权累计思路的启发,将多任务的概念扩展到多个模块,每个模块在当前时间戳的损失相对于其前一个值的比值计算方式如下:
其中,比例捕获两个时间步长之间模块损失的相对变化。在此基础上,我们引入了一个缩放因子来表达损失率变化相对于所有模块平均变化的重要性。该因子的定义方式如下
其中,是在所有时间戳上所有模块比率的平均值,代表的是标准差。考虑到仅依赖最后两个损失会导致不稳定和次优解决方案。为了缓解这种情况,我们引入了一个时间衰减因子来考虑损失的时间变化率。通过将时间衰减因子应用于前一个权重并合并新计算的权重,可以更新下一个时间戳中每个模块的权重
最终在时间戳时模型的总损失函数通过对所有模块的加权损失函数求和来计算,计算方式如下
通过上述的方式,确保权重能够随时间动态适应每个模块的性能,从而提高稳定性并改善整体性能。这种指数调整允许模型在保持整体稳定性的同时优先考虑性能变化显著的模块。
整体训练
由于模型训练时间较长,我们采用微调的方法。该过程从预先训练的模型开始,该模型已经学习了标准驾驶任务,允许专注于对抗性微调以有效增强鲁棒性。在微调过程中,对抗性噪声被策略性地引入到各个模块中,模块级噪声注入的集成可确保每个模块都暴露于对抗性条件,从而促进整个模型的全面训练。训练过程遵循最小-最大优化框架,旨在最大限度地减少对抗条件下的最坏情况损失,确保微调模型在面对最具挑战性的攻击时仍能保持稳健。
实验结果&评价指标
在实验部分中,我们选取两个具有代表性的端到端自动驾驶模型UniAD和VAD来验证我们提出算法模型的有效性,并且在白盒和黑盒的设置下进行实验。
下表展示了我们使用UniAD在nuScenes上的白盒设置下的实验结果。
通过上述的实验结果,我们可以发现在白盒场景的防御扰动时,的表现始终优于其他方法,在所有五个任务中实现了超过10%的绝对改进。这凸显了在增强端到端模型抵御各种扰动的稳健性方面的有效性。对于至关重要的规划任务,在抵御各类攻击方面表现出了显著的提升,在规划的平均误差UniAD减少了0.64米,VAD减少了0.58米,在真实驾驶场景中提供了实质性的安全保障。
此外,我们使用训练的UniAD和VAD作为受害者模型,其带有三类攻击模型:分别是具有相同架构的vanilla模型、传统对抗训练模型和具有不同架构的vanilla模型。相关的实验结果如下表所示。
通过上述的实验结果,我们可以发现在黑盒设置下,两种模型的性能下降幅度均小于白盒设置,但还提供了防御攻击的能力,即使面对未知攻击,也能实现平均7.2%的性能提升,超过其他方法的6.0%。此外,传统对抗训练模型进行的转移攻击是三种设置中最强的,但还也可以发挥防御作用,UniAD的规划误差减少了0.2m,VAD减少了0.1m。不同模型架构产生的攻击最弱,相应的防御提升也相对较小,这仍然证明了在防御来自不同领域的噪声方面的有效性。
此外,我们也验证了我们提出的模块化噪声注入的有效性。作为的核心组件,模块式噪声注入对于增强对抗性防御至关重要。我们尝试了五种不同类型的噪音。默认设置包括注入所有五种类型,并且我们探索在对抗训练期间仅去除或保留一种噪音的设置,以衡量其效果。
考虑到不同训练阶段的结果存在差异,我们对每个设置进行了多次重复实验,并用小提琴图可视化了平均L2误差,如下图所示。总体而言,结果表明,当注入所有类型的噪声时,防御效果最有效。此外,随着注入噪声的模块数量的增加,防御效果显著提高。具体来说,我们发现,当只注入一个噪声时,来自Track-Motion分支的噪声对模型的稳健性贡献最大,而当只丢弃一个噪声时,丢弃Track-Motion分支的噪声后,规划误差最大化。这意味着Track-Motion接口的关键和脆弱特性。
此外,我们也进一步验证了动态权重累计自适应的效果,相关的实验结果汇总在下图中。
通过上图可以看出,使用动态权重累计自适应时,模型的损失在6,000个Batch时几乎收敛,而没有动态权重累计自适应时,损失持续下降直到8,000个Batch,并且规划模块早在4,000个Batch时就接近收敛。这些发现证实了动态权重累计自适应在加速减少损失、平衡模块间损失分配和提高整体模型性能方面的有效性。
除此之外,我们使用了CARLA模拟器进行闭环评估,同时集成了最先进的UniAD和VAD算法模型,我们将图像作为感知数据直接输入模型,以评估其在现实驾驶场景中的决策性能。为了验证我们的在现实世界中的有效性,我们进行了黑盒攻击实验。
为了验证对抗训练模型的稳健性,我们通过将生成的噪声应用于输入图像,在CARLA上测试了训练模型。下图显示了在干净条件下的vanilla模型、攻击后的vanilla模型和攻击后的训练模型之间的性能比较。
同时,我们也将相关的详细实验结果指标汇总在下表当中。
通过实验结果可以看出,在黑盒攻击下,UniAD和VAD模型的性能显著下降。例如,VAD的驾驶得分从37.72%下降到25.64%,UniAD的驾驶得分从39.42%下降到37.91%。任务特定性能也受到影响。例如,UniAD的合并成功率从4.11%下降到1.25%。显著提高了模型对这些攻击的鲁棒性。经过训练后,UniAD的驾驶得分提高到38.86%,VAD的驾驶得分提高到26.87%。这些结果表明方法在减轻对抗性攻击的影响方面非常有效,几乎恢复了模型的原始性能水平。
此外,我们也将几种关键场景下的模型表现性能进行了可视化,如下图所示。通过可视化的结果可以看出,在应用之后,模型准确预测了周围车辆的未来运动状态,与没有受到攻击的情景非常相似。
结论
在本文我们引入了一种专门设计用于增强端到端自动驾驶模型抵御各种对抗性攻击的稳健性的新方法,称之为模块化自适应对抗训练方法。在nuScenes数据集和CARLA模拟器的闭环评估实验验证了我们算法模型的有效性。
#LSSInst
LSS再次登顶!浙大&中科大:BEV和稀疏表示优势互补,3D检测暴涨5个点!
作为自动驾驶感知系统的重要组成部分,3D目标检测可应用于自动驾驶、机器人等各个领域。尽管基于激光雷达的3D目标检测算法已被证实具有卓越的3D感知性能,但基于相机传感器的3D目标检测的研究也受到越来越多的关注。其收到关注的原因不仅在于基于相机的感知算法部署成本较低,而且还在于远距离和视觉道路元素的识别带来的诸多优势。然而,与提供直接和准确的目标深度信息和几何结构信息的激光雷达传感器不同,仅基于相机传感器实现3D目标的检测是一项重大的挑战。因此,如何利用多视图图像建立有效的特征表示已成为当前一个关键的问题。
最近,利用BEV的方法取得了重大进展,其视图变换主要可分为以LSS为代表的前向类型和基于可学习BEV Query的后向类型。由于后向类型通过不可解释的Query进行纯粹隐式的聚合,因此其性能和扩展性较低,这使得基于LSS算法的前向类型成为目前仅使用相机图像的 3D 检测的主流范式。基于 LSS 假设以及场景中大多数物体靠近地面的事实,基于 LSS 的 BEV 感知算法在观察整个物体时提供了视差模糊和信息丢失最小的视角。BEV 特征受益于其整体表示和密集特征空间,使其非常适合捕获场景的结构和数据分布。然而,BEV 表示的几何压缩性质(例如分辨率和高度轴的减少)本质上限制了它提供物体的精确 3D 位置描述或充分利用详细特征进行目标匹配的能力,特别是在需要准确预测 3D 物体边界框的 3D 检测任务中。
在比较不同算法模型实验结果中不同类别的AP指标时,我们发现了一些有趣的现象,如下表所示。
值得注意的是,同一组中所选方法的整体 mAP 值之间的差异严格小于0.5%,这代表同组间不同类方法的检测效果是类似的。我们可以观察到,各个类别之间存在相同的AP趋势。具体来说,BEV 表示似乎更关注场景中具有不同运动或共同位置的常规物体(汽车、公共汽车、卡车、障碍物),而对具有不确定轨迹或分散位置的物体(行人、自行车、交通锥)相对不敏感,这进一步证明了其拟合数据分布更倾向于场景级的理解。
基于上述的实验结果的相关启发,在本文中,为了增强BEV表示和稀疏表示之间的互补协同作用,弥补当前基于 LSS 的 BEV 感知表示中缺失的细节,并利用多视图几何约束,我们提出了LSSInst算法,结合基于场景级表示的稀疏实例级表示,通过几何匹配来回顾更详细的特征。相关的实验结果表明,我们提出的LSSInst算法在nuScenes数据集上超过了现有的基于LSS的其他算法。
论文链接:https://arxiv.org/pdf/2411.06173;
算法模型网络结构&技术细节梳理
在详细介绍本文提出的网络架构之前,下图展示了我们提出的LSSInst算法模型的网络结构图。
通过上图的整体网络结构可以看出,LSSInst算法模型主要由三个子部分构成,分别是BEV Branch、Instance Adaptor、Instance Branch。接下来,我们就详细的介绍一下这三个部分的具体实现细节。
BEV Branch: Looking around for scene-level representation
我们首先将前T帧的多视角图像序列输入到2D 图像主干网络进行图像特征的提取。然后,BEV分支将多尺度的图像特征信息转换到场景级的BEV特征空间中。
具体而言,BEV分支包括时序特征共享的视角变换模块将多尺度的特征信息转换为时序的BEV特征信息,然后时序的BEV特征信息经过时间戳对齐之后,利用BEV时序编码器模块得到最终的BEV特征。在这里,使用的编码器是非常轻量化的残差网络,仅仅用于实现降维的目的。
Instance Adaptor: Scene-to-instance adaptation
为了保持 BEV 和实例表示之间连贯且牢固的语义一致性,我们提出了Instance Adaptor来消除位置描述和空间差异中的差距。由于 BEV 特征是围绕自车的场景级表示,因此在对实例级特征进行建模时存在冗余和不灵活性。
为此,所提出的适配器模块首先对通过 BEV Proposal头获得的提议框坐标进行重新投影,返回到 BEV 识别的位置以重新采样与目标相关的特征。这里代表的是BEV Proposal的数量。给定BEV点云的范围,对应的体素大小是,上采样因子是,我们建模这种2D映射坐标如下:

此外,由于 BEV 中的过度拟合偏差,聚焦区域可能会偏离实际物体位置。受可变形注意力的启发,adaptor模块通过探索更多语义感知区域,结合基于原始聚焦特征的可学习偏移量来进行错位补偿,其补偿方式如下。
如上所述,BEV 编码空间与回顾图像特征的 3D 稀疏空间之间仍然存在固有的空间差异。因此,我们首先引入一个非常浅的卷积特征转换器来重新参数化聚合特征以进行空间叙述。同时,即使基于 BEV 注意力特征进行广泛的聚合和增强,由于 BEV 对规则物体的过度拟合和相对粗糙的感知粒度,一部分不规则或分离的物体无法被检测到,因此我们引入了额外的独立于BEV Proposal的可学习query和参考框,称为潜在 3D 实例和3D框,旨在捕获潜在的 BEV 不敏感目标并学习与 BEV 无关的 3D 空间先验信息。因此,我们可以得到相应的稀疏特征如下。

Instance Branch: Looking back for instancelevel representation
给定来自图像主干网络的顺序图像特征和来自Instance Adaptor的具有相应3D框的稀疏实例特征,实例分支将根据参考框坐标在空间和时间上回顾图像特征,并迭代提取丰富但更细粒度的表示以更新预特征。该分支可以粗略地看作是一个用于3D检测的多层Transformer-decoder类模块,简单分为两部分:box-level offset和embedding,以及时空采样和融合。
- Box-level Offset and Embedding:与之前类似 DETR的3D方法仅通过3D坐标偏移回归进行迭代细化不同,实例分支采用基于的框级偏移回归。具体来说,我们首先根据框的维度的元素语义将分为四类,分别是位置、尺度、速度以及方向。然后,我们引入了五个独立的线性投影进行综合编码,其中前四个将每个类别局部嵌入,最后一个将每个类别全局嵌入。最终的Box Embedding可以表述如下。
- Spatiotemporal Sampling and Fusion:稀疏特征和box embedding将通过空间和时间采样进行更新,并被输入到多头自注意力模块中。在空间方面,为了访问目标区域,我们对原始特征进行采样,以中间回归从到目标的现有偏移量。为了扩大搜索广度,我们类比扩展采样点,并用权重扩大残差添加的比例。
另一方面,随着时间的推移,自动驾驶场景中存在自车运动和物体运动,需要在采样前进行补偿。考虑到这种稀疏时间立体中的短期运动,我们将物体运动近似为均匀的直线运动。因此,我们首先用当前速度补偿,然后通过全局世界坐标系转换,将其作为每个历史时间变换到到每个坐标系中。
然后,我们将多帧特征输入到稀疏时间编码器(一个三层多层感知机)中,进行时序的迭代融合。
实验结果&评价指标
为了证明我们提出的算法模型LSSInst的有效性,我们在 nuScenes 验证集和测试集上将我们的方法与基于 LSS 和两阶段的最先进的方法进行了比较。主要结果分别列于下面两个表格当中。
在验证集上,我们评估了 LSSInst 与具有相同设置且没有 CBGS 策略和未来帧使用的其他模型的性能。结果清楚地展示了 LSSInst 的优越性,因为它的表现优于当前基于 LSS 的 SOTA,SOLOFusion,在 mAP 上领先 1.6%,在 NDS 上领先 1.7%,并且优于当前的两阶段 SOTA,BEVFormerv2,在 mAP 上领先 3.4%,在 NDS 上领先 1.6%。
在测试集上,我们的LSSInst在没有任何额外增强的情况下实现了 54.6% 的 mAP 和 62.9% 的 NDS,优于所有基于 LSS 的方法。这些改进证明了我们的 LSSInst 在改进基于 LSS 的 BEV 感知方面的有效性。
为了证明我们的 LSSInst 方法的泛化能力,我们选择了基于 LSS 的相关方法作为 LSSInst 的 BEV 分支。结果如下表所示。
与独立的 BEV 检测器相比,我们的 LSSInst 在 mAP 和 NDS 方面取得了显着的改进,而成本却很小。尽管检测增强了 2-5% 的 mAP 和 NDS,但相应的成本增加了可接受的幅度。特别是在所有方法中,mATE、mASE 和 mAOE 都有显着的改进,这表明 LSSInst 可以利用细粒度的像素级特征,并更好地增强平移、缩放和方向方面的感知能力。
为了更加直观的展现出本文提出算法模型的有效性,我们展示了 LSSInst、真值和当前 SOTA 方法 SOLOFusion 的 3D 物体检测可视化比较结果,如下图所示。
通过可视化结果可以看出,LSSInst 具有更高的召回率,可以检测到更多不明显和被遮挡的物体。例如,我们的模型成功地在CAM FRONT LEFT 和 CAM FRONT RIGHT 视图中检测到远处的汽车和卡车,尤其是被树木遮挡的车辆和与背景高度相似的深色不明显汽车。此外,我们的方法在每个视图中都能产生与真值标注更一致的方向和框比例。相比之下,例如,在 CAM FRONT 和 CAM FRONT LEFT 视图中,公交车都存在严重的旋转偏移(红色弯曲箭头),并且在 CAM FRONT RIGHT 视图中,那些正在通过左侧交通信号灯的汽车之间存在框错位。上述观察充分证明了缺失细节的改善,无论是更广的感知宽度还是更精细的属性。
尽管我们已经在 nuScenes 数据集上验证了 提出的LSSInst算法模型的高性能,即使是大规模的自动驾驶数据集,当传感器大量收集数据时,获得的外部参数中也不可避免地会包含干扰。在实际的自动驾驶场景中,要求检测器能够抵抗由微小测量误差引起的干扰噪声。因此,我们在这里添加了一组随机旋转噪声,其比例与外部参数成比例增加,探索 LSSInst 在外部参数不准确的情况下的稳健性。这里的基线是具有4帧的 BEVDepth4D。实验结果如下表所示,我们证明 LSSInst 保持了良好的稳健性,表现出更高的性能和更小的整体衰减。
为了进一步研究多重Query对算法模型感知性能的影响,相关的实验结果如下表所示。我们探索了两种场景:仅使用Proposal Query或可学习的潜在Query以及合并两种Query。这里我们遵循Query最大数量默认为 900 的经典设置。
通过实验结果我们可以观察到,一方面,仅依靠潜在Query不能发挥主要作用,即使使用所有 900 个Query也会产生平庸的性能,这表明由于初始化语义分散而没有上述来自 BEV 的场景级信息基础,收敛速度很慢。另一方面,虽然单独使用来自 BEV 的Proposal Query可以取得整体良好的结果,但添加更多Query并不能取得更好的改进,这证明了其对场景的过度拟合特性以及对场景中缺失物体的检测被忽视的事实。然而,当结合两种Query时,性能进一步提高并达到了一个新的水平。可以得出结论,这两类Query发挥着各自独特的作用,它们密不可分、相辅相成的协同作用使得模型能够从全局场景级别到局部实例级别有全面的理解。
此外,我们也进行了相关实验来证明BEV与实例的语义一致性。相关实验结果如下表所示。根据与真值的结果相比,观察到我们提出额LSSInst算法模型比 LSS 基线具有更好的语义保持,这表明对场景中额外的 BEV 不敏感对象的感知能力有所提高。
结论
在本文中,我们提出了LSSInst感知算法模型,LSSInst是一种两阶段的3D目标检测器。它通过实例表示改进了 BEV 感知的几何建模结构。在nuScenes数据集上的大量实验结果表明,我们提出的算法框架在目前已有的基于LSS的BEV感知算法中具有很强的泛化能力和出色的感知性能,超越了目前最先进的3D目标检测算法。
#布局具身智能?
前十年自动驾驶,后十年具身智能,一位资深自动驾驶从业者这样和我们说。这不仅仅是对具身智能的看好,更是未来近10年的发展趋势。
具身智能不再是一句空话...
具身智能广义上是指具有物理身体的智能体,能够与环境进行互动,感知周围世界,自主学习、决策并执行任务。说到这里,像人形机器人、四足机器人、机械臂系统、自动驾驶系统算广义上的具身智能,能够感知周围环境并作出反应或执行。GPT这类大模型从狭义上理解,当然也可以算。如果再来看工业界的产品落地,扫地机也是,只是没有那么智能罢了!

无论是特斯拉的擎天柱,抑或波士顿动力的大狗or大牛,都在解决一个事情,那就是通用人工智能。行业期望双足机器人能够类人工作劳动,比如产线机器人、陪伴机器人、服务机器人等;期望多足机器人能够完成搬运、巡检、救援等工作,将人类从无趣或危险的场景中解救出来,减少人力成本。
具身智能开始备受青睐
依托于AI技术的快速发展,以及各类芯片的算力提升。硬件、数据和算法相比于之前纯机器人时代已经有着大幅度提升,更多智能的技术可以快速应用到具身领域,比如自动驾驶领域的端到端、感知、规划等,大模型技术、SLAM这类建图定位、位姿估计、机械臂动力学等等。
如何将多类领先的技术和物理实体结合,是很多顶尖科研机构和机器人AI公司一直在突破的。国外有波士顿动力、特斯拉擎天柱这类具有代表性的四足和人形机器人;国内像宇树科技、云深处、智元机器人、还有各大厂的机器人实验室都在不断攻克难关,期望能够推动社会的生产变革。

软件算法与硬件都具备较高的感知和实时能力,资本自然也非常看好,可以说具身的市场绝不亚于那时的自动驾驶,相关的融资事件与岗位招募逐渐拉升,前景满满,也促使了相当多的从业者转向具身智能。
具身智能知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,也是目前该领域最大的知识付费社区,已经近600人啦!创建的出发点是给大家提供一个具身相关的技术交流平台。星球内部主要关注具身智能相关的数据集、开源项目、 具身仿真平台、大模型、视觉语言模型、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略 学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。
我们为大家汇总了近40+开源项目、近60+具身智能相关数据集、行业主流具身仿真平台、强化学习全栈学习路线、具身智能感知学习路线、具身智能交互学习路线、视觉语言导航学习路线、触觉感知学习路线、多模态大模型学理解学习路线、多模态大模型学生成学习路线、大模型与机器人应用、机械臂抓取位姿估计学习路线、机械臂的策略学习路线、双足与四足机器人开源方案、具身智能与大模型部署等方向,涉及当前具身所有主流方向。
为了促进行业的发展,我们前期希望更多优秀的人加入我们,邀请各位在未来5-10年和我们一起输出相关技术与行业最新干货。
加入星球有哪些福利?
- 第一时间掌握具身智能相关的学术进展、工业落地应用;
- 和行业大佬一起交流工作与求职相关的问题;
- 优良的学习交流环境,能结识更多同行业的伙伴;
- 具身智能相关工作岗位推荐,第一时间对接企业;
- 行业机会挖掘,投资与项目对接
星球内容一览0)国内外具身智能高校汇总
星球内部为大家汇总了具身智能多个研究方向的国内外知名实验室,供大家后期读研、申博、博后参考。
1)国内外具身智能公司汇总
星球内部为大家汇总了各类国内外各类具身相关机器人公司,涉及教育、宠物、工业、救援、物流、交互、医疗等方向。

2)具身智能研报汇总
星球内部为大家汇总了大模型、人形机器人等行业相关的研报,第一时间了解行业的发展与工业的落地情况。

3)机器人相关书籍汇总
星球内部汇总了机器人导航、概率机器人、机器人动力学与运动学、路径规划、机器人视觉控制等多个方向的PDF书籍,供大家做基础学习。

4)具身智能零部件品牌汇总
我们内部为大家汇总了机器人行业知名的零部件制造厂商,涉及芯片、激光雷达、相机、IMU、底盘等。

5)开源项目汇总
星球内部针对机器人仿真项目、机器人抓取、机器人控制、具身交互、具身感知等多个领域的开源项目进行了汇总,助力快速上手。

6)具身智能数据集
针对具身感知、触觉感知、导航、问答、大模型、视觉语言模型、端到端、机械臂抓取、控制规划多个领域的开源数据集进行了汇总,再也不用担心找不到可用的数据集了。

7)具身智能仿真平台汇总
星球内部针对通用机器人仿真平台和真实场景仿真平台进行了汇总,机器人仿真这里全都有!

8)强化学习路线汇总
我们为大家汇总了基于LLM的强化学习、可解释强化学习、深度强化学习主流方案,一览各个子领域的应用训练。

9)具身智能感知学习路线
内部针对主动视觉感知、3D视觉感知定位、视觉语言导航、触觉感知等多个任务进行了汇总,具身感知路线,一网打尽。

10)具身智能交互
星球内部为大家汇总了具身智能与环境交互相关工作,涉及抓取、检测、视觉语言模型、具身问答、gaussian splatting等多块内容。

11)视觉语言导航
针对视觉语言导航、规划等多个应用内容,星球内部进行了详细的汇总,关注自动驾驶与机器人应用。

12)触觉感知
我们汇总了触觉感知最新综述、传感器应用、多模态算法集成、数据集等多项内容,让大家对这一前沿应用有着深刻了解。

13)多模态大模型理解
星球内部汇总了大量多模态大模型理解相关内容, 包括但不限于Image+Text到Text、 Video+Text到Text、 Audio+Text到Text、 3D+Text到Text、Many到Text等。

14)多模态大模型生成
除了多模态大模型理解,星球内部也汇总了大量多模态大模型生成相关内容,包括Image+Text到Image+Text、Video+Text到Video+Text、 Audio/Speech+Text到Audio/Speech+Text、Many到Image+Text、Many到Many等。

15)视觉-语言-动作
内部为大家汇总了主流的VLA模型相关内容,一览最新视觉-语言-动作相关进展。

16)大模型微调与量化推理

17)大模型部署相关
针对大模型部署框架、大模型轻量化方法等进行了汇总,助力落地。

18)机械臂抓取
针对机械臂抓取、任务数据表示、位姿估计、策略学习多个部分展开了汇总。

19)双足与四足机器人
星球内部对开源的双足与四足机器人项目、仿真、源码、硬件等部分进行了详细的汇总,助力从零搭建你的机器人。

20)四足/轮式+机械臂
针对常用的移动+执行硬件方案进行了汇总,助力大家快速搭建属于自己的系统。

#End-to-End Navigation with Vision-Language Models
加州大学 | 基于视觉语言模型的端到端导航:零样本,无需数据训练!
原标题:End-to-End Navigation with Vision-Language Models: Transforming Spatial Reasoning into Question-Answering
论文链接:https://jirl-upenn.github.io/VLMnav/static/VLMnav.pdf
项目链接:https://jirl-upenn.github.io/VLMnav/
作者单位:UC Berkeley 宾夕法尼亚大学
出发点&VLMnav的概览
VLMnav是一种将视觉语言模型(VLM)转化为端到端导航策略的具身框架。与以往研究不同,VLMnav不依赖感知、规划和控制的分离,而是通过VLM一步直接选择动作。令人惊讶的是,我们发现VLM可以作为端到端策略进行零样本导航,即无需任何微调或导航数据的训练。这使得方法具有开放性和广泛的下游导航任务的泛化能力。我们进行了广泛的研究,以评估该方法相较于基线提示方法的性能。此外还进行了设计分析,以理解最具影响力的设计决策。
内容出自国内首个具身智能全栈学习社区:具身智能之心知识星球,这里包含所有你想要的。
VLMnav的设计
在环境中有效导航以实现目标的能力是物理智能的标志。空间记忆以及更高级的空间认知形式,被认为在早期陆生动物和高级脊椎动物的进化历史中开始发展,可能始于4亿至2亿年前。由于这一能力经历了如此漫长的进化历程,因此对于人类而言,这种能力几乎显得本能且理所当然。然而,导航实际上是一个高度复杂的问题。它需要协调低层次的规划以避开障碍,同时还需进行高层次的推理,以理解环境的语义,并探索最有可能让智能体实现其目标的方向。
导航问题的很大一部分似乎涉及与回答长上下文图像和视频问题类似的认知过程,而这是当代视觉语言模型(VLMs)擅长的领域。然而,当这些模型直接应用于导航任务时,却面临明显的局限性。具体而言,当给出任务描述并将其与观察-动作历史拼接后,VLMs 往往难以生成精细的空间输出以避开障碍,且无法有效利用其长上下文推理能力来支持有效的导航。
为了解决这些挑战,先前的研究将VLMs作为模块化系统的组成部分,用于执行高层次的推理和识别任务。此类系统通常包含一个显式的3Dmapping模块和一个规划器,以处理任务中更具具身性的部分,例如运动和探索。尽管模块化设计的优势在于可以将每个组件用于其擅长的子任务,但其缺点在于系统的复杂性增加,并且任务专用性较强。
在本研究中,我们展示了一种现成的VLM可以作为零样本的端到端语言条件导航策略使用。实现这一目标的关键在于将导航问题转化为VLM擅长的任务:回答关于图像的问题。
为此,开发了一种新颖的提示策略,使VLM能够明确考虑探索和避障问题。该提示具有通用性,可用于任何基于视觉的导航任务。
与以往的方法相比,我们不使用特定模态的专家模型,不训练任何特定领域的模型,也不假设可以访问模型生成的概率。
我们在具身导航的既定基准上评估了本文的方法,结果证实,与现有的提示方法相比,本文的方法显著提升了导航性能。最后,本文通过对具身VLM框架的多个组件进行消融实验,得出了设计上的见解。
图1:VLMnav的完整动作提示由三部分组成:系统提示用于描述具身性,动作提示用于描述任务、可能的动作和输出指令,以及图像提示显示当前观察到的场景和标注的动作。
图2:方法:本文的方法由四个关键组件组成:(i) 可导航性,确定智能体可以实际移动的位置,并相应地更新体素地图。地图更新步骤的示例显示新区域标记为已探索(灰色)或未探索(绿色)。(ii) 动作提议器,根据间距和探索情况优化一组最终动作。(iii) 投影,视觉上在图像中标注动作。(iv) 提示,构建详细的思维链提示以选择动作。
VLMnav是一种导航系统,以目标作为输入,目标可以通过语言或图像指定,还包括RGB-D图像、姿态,并输出动作。动作空间由绕偏航轴的旋转和沿机器人框架前轴的位移组成,使得所有动作可以用极坐标表示。由于已知VLM在连续坐标推理上存在困难,本文将导航问题转化为从离散选项集中选择动作。本文的核心思想是选择这些动作选项,以避免碰撞障碍并促进探索。
图2总结了本文的方法。首先,本文通过深度图像估计与障碍物的距离,以确定局部区域的可导航性。本文使用深度图像和位置信息来维护场景的自上而下体素地图,并显著地将体素标记为已探索或未探索。该地图由动作提议器使用,以确定一组避开障碍并促进探索的动作。接着,本文将这一组可能的动作通过投影模块映射到第一人称视角的RGB图像中。最后,VLM将该图像和精心设计的提示作为输入,选择一个动作供智能体执行。为确定回合终止,本文使用一个单独的VLM调用。
图3:可导航性子程序的示例步骤。可导航性掩码显示为蓝色,构成初始动作集
图4:用于确定回合终止的独立提示
VLMnav的实验验证
图5:基线方法:在示例图像上比较四种不同方法。本文的方法包含指向可导航位置的箭头,PIVOT方法的箭头从随机二维高斯分布中采样,本文的无导航版本显示均匀分布的箭头(注意箭头3和5指向墙壁),仅提示方法则仅显示原始RGB图像。
图6:传感器视场角(FOV)的影响。本文评估了四种不同视场角传感器的性能,发现更宽的视场角始终带来更高的性能。
表1:ObjectNav结果。本文在ObjectNav基准上评估了四种不同的提示策略,结果显示本文的方法在准确性(SR)和效率(SPL)方面均达到了最高性能。消融“允许滑动”参数表明本文的方法依赖于滑过障碍物的能力。
表2:GOAT结果。在更具挑战性的导航任务GOAT基准上对提示策略进行比较。在三种不同的目标模态下,本文的方法均显著优于基线方法。
表3:直接与其他方法对比,本文发现专用系统仍然具有更高的性能。本文还注意到,这些其他方法使用了更窄的视场角(FOV)、更低的图像分辨率以及不同的动作空间,这可能解释了部分性能差异。
表4:添加上下文历史的影响。本文将保持过去0、5、10和15个观测和动作的不同方案与本文的方法进行比较。结果显示,添加上下文历史并未提升本文方法的性能。
表5:深度消融实验。本文评估了仅需RGB的两种替代方法。结果显示,语义分割的性能接近于使用真实深度数据,而估计深度值会导致性能显著下降。
总结
在本研究中,我们提出了VLMnav,这是一种新颖的视觉提示工程方法,使现成的VLM能够作为端到端导航策略工作。该方法的核心思想是精心选择动作提议并将其投影到图像上,从而有效地将导航问题转化为问答问题。通过在ObjectNav和GOAT基准上的评估,本文观察到相较于迭代基线PIVOT(之前在视觉导航提示工程中的最新方法)有显著的性能提升。我们的设计研究进一步突出了宽视场的重要性,并展示了使用最小传感的可能性,即仅依赖RGB图像来实现该方法的部署。
本文的方法也存在一些局限性。禁用“允许滑动”参数后性能急剧下降,表明存在多次与障碍物碰撞的情况,这在实际部署中可能会带来问题。此外,本文发现一些专用系统的性能优于本文的方法。然而,随着VLM能力的不断提升,本文推测该方法可以帮助未来的VLM在具身任务上达到或超越专用系统的表现。
相关文章:
51c自动驾驶~合集30
我自己的原文哦~ https://blog.51cto.com/whaosoft/12086789 #跨越微小陷阱,行动更加稳健 目前四足机器人的全球市场上,市场份额最大的是哪个国家的企业?A.美国 B.中国 C.其他 波士顿动力四足机器人 云深处 绝影X30 四足机器人 …...

Python Tutor网站调试利器
概述 本文主要是推荐一个网站:Python Tutor. 网站首页写道: Online Compiler, Visual Debugger, and AI Tutor for Python, Java, C, C++, and JavaScript Python Tutor helps you do programming homework assignments in Python, Java, C, C++, and JavaScript. It contai…...

h5小游戏实现获取本机图片
h5小游戏实现获取本机图片 本文使用cocos引擎 1.1 需求 用户通过文件选择框选择图片。将图片内容转换为Cocos Creator的纹理 (cc.Texture2D),将纹理设置到 cc.SpriteFrame 并显示到节点中。 1.2 实现步骤 创建文件输入框用于获取文件 let input document.createElement(&quo…...

前端 javascript a++和++a的区别
前端 javascript a和a的区别 a 是先执行表达式后再自增,执行表达式时使用的是a的原值。a是先自增再执行表达示,执行表达式时使用的是自增后的a。 var a0 console.log(a); // 输出0 console.log(a); // 输出1var a0 console.log(a); // 输出1 console.l…...

OceanBase V4.x应用实践:如何排查表被锁问题
DBA在日常工作中常常会面临以下两种常见情况: 业务人员会提出问题:“表被锁了,导致业务受阻,请帮忙解决。” 业务人员还会反馈:“某个程序通常几秒内就能执行完毕,但现在却运行了好几分钟,不清楚…...
ctfshow-web入门-SSRF(web351-web360)
目录 1、web351 2、web352 3、web353 4、web354 5、web355 6、web356 7、web357 8、web358 9、web359 10、web360 1、web351 看到 curl_exec 函数,很典型的 SSRF 尝试使用 file 协议读文件: urlfile:///etc/passwd 成功读取到 /etc/passwd 同…...

【日常记录-Git】如何为post-checkout脚本传递参数
1. 简介 在Git中,post-checkout 钩子是一个在git checkout 或git switch命令成功执行后自动调用的脚本。该脚本不接受任何来自Git命令的直接参数,因为Git设计该钩子是为了在特定的版本控制操作后执行一些预定义的任务,而不是作为一个通用的脚…...

《机器人控制器设计与编程》考试试卷**********大学2024~2025学年第(1)学期
消除误解,课程资料逐步公开。 复习资料: Arduino-ESP32机器人控制器设计练习题汇总_arduino编程语言 题-CSDN博客 试卷样卷: 开卷考试,时间: 2024年11月16日 001 002 003 004 005 ……………………装………………………...
后台管理系统(开箱即用)
很久没有更新博客了,给大家带上一波福利吧,大佬勿扰 现在市面上流行的后台管理模板很多,若依,芋道等,可是这些框架对我们来说可能会有点重,所以我自己从0到1写了一个后台管理模板,你们使用时候可扩展性也会更高 项目主要功能: 成员管理,部门管理&#…...

5G CPE与4G CPE的主要区别有哪些
什么是CPE? CPE是Customer Premise Equipment(客户前置设备)的缩写,也可称为Customer-side Equipment、End-user Equipment或On-premises Equipment。CPE通常指的是位于用户或客户处的网络设备或终端设备,用于连接用户…...
实现)
量化交易系统开发-实时行情自动化交易-4.1.3.A股平均趋向指数(ADX)实现
19年创业做过一年的量化交易但没有成功,作为交易系统的开发人员积累了一些经验,最近想重新研究交易系统,一边整理一边写出来一些思考供大家参考,也希望跟做量化的朋友有更多的交流和合作。 接下来继续说说A股平均趋向指数实现。 …...

tcp的网络惊群问题
1. SO_REUSEPORT 可以解决epoll的惊群问题 但是,现在的 TCP Server,一般都是 多进程多路IO复用(epoll) 的并发模型,比如我们常用的 nginx 。如果使用 epoll 去监听 accept socket fd 的读事件,当有新连接建立时,所有进…...

云原生之运维监控实践-使用Prometheus与Grafana实现对Nginx和Nacos服务的监测
背景 如果你要为应用程序构建规范或用户故事,那么务必先把应用程序每个组件的监控指标考虑进来,千万不要等到项目结束或部署之前再做这件事情。——《Prometheus监控实战》 去年写了一篇在Docker环境下部署若依微服务ruoyi-cloud项目的文章,当…...

软考教材重点内容 信息安全工程师 第 4 章 网络安全体系与网络安全模型
4,1 网络安全体系的主要特征: (1)整体性。网络安全体系从全局、长远的角度实现安全保障,网络安全单元按照一定的规则,相互依赖、相互约束、相互作用而形成人机物一体化的网络安全保护方式。 (2)协同性。网络安全体系依赖于多种安全机制,通过各…...

机器学习——期末复习 重点题归纳
第一题 问题描述 现有如下数据样本: 编号色泽敲声甜度好瓜1乌黑浊响高是2浅白沉闷低否3青绿清脆中是4浅白浊响低否 (1)根据上表,给出属于对应假设空间的3个不同假设。若某种算法的归纳偏好为“适应情形尽可能少”,…...

MYSQL——数据更新
一、插入数据 1.插入完整的数据记录 在MYSQL中,使用SQL语句INSERT插入一条完整的记录,语法如下: INSERT INTO 表名 [(字段名1[,...字段名n])] VALUES (值1[...,值n]); 表名——用于指定要插入的数据的表名 字段名——用于指定需要插入数据…...

Vite 基础理解及应用
文章目录 概要Vite基础知识点1. 快速启动和热更新热更新原理 2. 基于ES模块的构建3. 对不同前端框架的支持 vite.config.js配置实例1. 基本结构2. 服务器相关配置3. 输入输出路径配置4. 打包优化配置 项目构建一、项目初始化二、项目结构理解三、CSS处理四、静态资源处理五、构…...

[JAVA]用MyBatis框架实现一个简单的数据查询操作
基于在前面几章我们已经学习了对MyBatis进行环境配置,并利用SqlSessionFactory核心接口生成了sqlSession对象对数据库进行交互,执行增删改查操作。这里我们就先来学习如何对数据进行查询的操作,具体查询操作有以下几个步骤 创建实体类创建Ma…...

CSS 样式的优先级?
在CSS中,样式的优先级决定了当多个样式规则应用于同一个元素时,哪个样式会被最终使用。以下是一些决定CSS样式优先级的规则: 就近原则: 最后应用在元素上的样式具有最高优先级。这意味着如果两个选择器都应用了相同的样式…...

Linux驱动开发快速入门——字符设备驱动(直接操作寄存器设备树版)
Linux驱动开发快速入门——字符设备驱动 前言 笔者使用开发板型号:正点原子的IMX6ULL-alpha开发板。ubuntu版本为:20.04。写此文也是以备忘为目的。 字符设备驱动 本小结将以直接操作寄存器的方式控制一个LED灯,可以通过read系统调用可以…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...