Elasticsearch retrievers 通常与 Elasticsearch 8.16.0 一起正式发布!
作者:来自 Elastic Panagiotis Bailis

Elasticsearch 检索器经过了重大改进,现在可供所有人使用。了解其架构和用例。
在这篇博文中,我们将再次深入探讨检索器(retrievers)。我们已经在之前的博文中讨论过它们,从介绍到使用检索器进行语义重新排序。现在,我们很高兴地宣布,检索器已随 Elasticsearch 8.16.0 已正式发布,在这篇博文中,我们将从技术角度介绍如何实现它们,并有机会讨论新推出的功能!
检索器 - retrievers
检索器(retriever)的主要概念与最初版本相同;检索器是一个框架,它提供可以分层堆叠的基本构建块,以构建多阶段复杂检索和排名管道。例如,一个简单的 standard 检索器,它只返回所有文档:
GET retrievers_example/_search
{"retriever": {"standard": {"query": {"match_all": {}}}}
}非常简单,对吧?除了 standard 检索器(本质上只是 standard query 搜索 API 元素的包装器)之外,我们还支持以下类型:
- knn - 从 kNN(k 最近邻)搜索中返回排名靠前的文档
- rrf - 根据 RRF(倒数排名融合)排名公式组合来自不同检索器的结果
- text_similarity_reranker - 使用 rerank 类型推断端点对嵌套检索器的排名靠前结果进行重新排名
还可以在 Elasticsearch 文档中找到更多详细信息以及每个检索器的特定参数。
让我们首先简要介绍一些技术细节,这将有助于我们了解架构、发生了什么变化以及为什么所有这些以前的限制现在都已解除!
技术深入研究
我们想要解决的最重要的(也是要求的)问题之一是能够在任何嵌套级别使用任何检索器。无论这意味着将 2 个或更多 text_similarity_reranker 堆叠在一起,还是将 rrf 检索器与 text_similarity_reranker 一起在另一个 rrf 之上运行,或者你能想到的任何组合和嵌套,我们都希望确保这是可以用检索器表达的东西!
为了解决这个问题,我们对检索器执行计划进行了一些重大更改。到目前为止,检索器是作为 standard 搜索执行流程的一部分进行评估的,其中(在简化的场景中为了说明目的)我们两次接触分片(shard):
- 一次用于查询分片并从每个分片中带回 from + size 文档,
- 一次用于获取所有字段数据并执行任何其他操作(例如突出显示/highlighting)以获得真正的顶级 [from, from+size] 结果。
这是一个不错的线性执行流程,(相对)容易遵循,但如果我们想要执行多个查询、对不同的结果集进行操作等,就会引入一些重大限制。为了解决这个问题,我们在查询执行的早期阶段就转向了对检索器管道的所有子检索器进行急切评估。这意味着,如果需要,我们会以递归方式将任何检索器查询重写为更简单的形式,具体形式取决于检索器类型。
- 对于非复合检索器(non-compound retrievers),我们重写的方式与在 standard 查询中类似,因为它们仍然可以遵循线性执行计划。
- 对于复合检索器(compound retrievers),即在其他检索器之上操作的检索器,我们将它们展平为单个 rank_window_size 结果集,它本质上是一个 <doc, shard> 元组列表,表示此检索器的排名靠前的文档。
让我们通过以下(相当复杂的)检索器请求来看看它实际上是什么样子:
{"retriever": {"rrf": { [1]"retrievers": [{"knn": { [2]"field": "emb1","query_vector_builder": {"text_embedding": {"model_id": "my-text-embedding-model","model_text": "LLM applications in information retrieval"}}}},{"standard": { [3]"query": {"term": {"topic": "science"}}}},{"rrf": { [4]"retrievers": [{"standard": { [5]"query": {"range": {"year": {"gte": 2020}}}}},{"knn": { [6]"field": "emb2","query_vector_builder": {"text_embedding": {"model_id": "my-text-embedding-model","model_text": "Vector scale on production systems"}}}}],"rank_window_size": 100,"rank_constant": 10}}],"rank_window_size": 10,"rank_constant": 1}}
}上面的 rrf 检索器是一个复合检索器,因为它对其他一些检索器的结果进行操作,因此我们将尝试将其重写为更简单、扁平的 <doc, shard> 元组列表,其中每个元组指定一个文档和它所在的分片。此重写还将强制执行严格的排名,因此当前不支持不同的排序选项。
现在让我们继续识别所有组件并描述如何评估它的过程:
- [1] 顶级 rrf 检索器;这是所有子检索器的父级,它将最后被重写和评估,因为我们首先需要知道每个子检索器的前 10 个结果(基于 rank_window_size)。
- [2] 这个 knn 检索器是顶级 rrf 检索器的第一个子级,并使用嵌入服务(my-text-embedding-model)来计算将使用的实际查询向量。这将通过向嵌入服务发出异步请求来计算给定 model_text 的向量,从而将其重写为通常的 knn 查询。
- [3] standard 检索器,也是顶级 rrf 检索器的子项的一部分,它返回与主题匹配的所有文档:science。
- [4] 顶级 rrf 检索器的最后一个子项,也是需要展平的 rrf 检索器。
- [5] [6] 与 [2] 和 [3] 类似,这些检索器是 rrf 检索器的直接子项,我们将为每个检索器获取前 100 个结果(基于 rrf 检索器的 rank_window_size [4]),使用 rrf 公式将它们组合起来,然后重写为真正的前 100 个结果的展平 <doc, shard> 列表。
检索器的更新执行流程现在如下:
- 我们将从重写所有我们可以重写的叶子开始。这意味着我们将重写 knn 检索器 [2] 和 [6] 来计算查询向量,一旦我们有了它,我们就可以在树中向上移动一层。
- 在下一个重写步骤中,我们现在准备评估嵌套的 rrf 检索器 [4],我们最终会将其重写为扁平化的 RankDocsQuery 查询(即 <doc, shard> 元组的列表)。
- 最后,顶级 rrf 检索器 [1] 的所有内部重写步骤都将完成,因此我们应该准备好按照要求合并和排名真正的前 10 个结果。即使是这个顶级 rrf 检索器也会将自身重写为扁平化的 RankDocsQuery,稍后将用于继续执行 standard 线性搜索执行流程。
将以上所有内容可视化,我们有:

查看上面的示例,我们可以看到如何将分层检索器树异步重写为简单的 RankDocsQuery。这种简化为我们带来了良好的(也是我们想要的!)副作用,即最终执行具有明确排名的正常请求,除此之外,我们还可以执行我们选择的任何补充操作。
玩转(golden)检索器!
正如我们上面简要提到的,有了这一重构,我们现在可以支持大量额外的搜索功能!在本节中,我们将介绍一些示例和使用场景,但更多内容也可以在文档中找到。
我们从最受欢迎的功能 —— 组合性开始,也就是说,在检索器树的任何级别都可以使用任意检索器的选项。
组合性 - composabilty
在以下示例中,我们想执行一个语义查询(使用像 ELSER 这样的嵌入服务),然后结合这些结果与 knn 查询,使用 rrf 进行合并。最后,我们希望使用 text_similarity_reranker 检索器进行重新排名。表达上述操作的检索器如下所示:
GET /retrievers_example/_search
{"retriever": {"text_similarity_retriever": {"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"semantic": {"field": "inference_field","query": "Can I use generative AI to identify user intent and improve search relevance?"}}}},{"knn": {"field": "vector","query_vector": [0.23,0.67,0.89],"k": 3,"num_candidates": 5}}],"rank_window_size": 10,"rank_constant": 1}},"field": "text","inference_text": "LLM applications on production search applications","inference_id": "my-reranker-model","rank_window_size": 10}},"_source": ["text","topic"]
}聚合 - aggregation
回想一下,在我们讨论的重做中,我们将复合检索器重写为 RankDocsQuery(即扁平的显式排名结果列表)。然而,这并不妨碍我们计算聚合,因为我们还会跟踪复合检索器中的源查询。这意味着我们可以回退到下面的嵌套 standard 检索器,以根据两个嵌套检索器结果的并集正确计算 topic 字段的聚合。
GET retrievers_example/_search
{"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"range": {"year": {"gt": 2023}}}}},{"standard": {"query": {"term": {"topic": "elastic"}}}}],"rank_window_size": 10,"rank_constant": 1}},"_source": ["text","topic"],"aggs": {"topics": {"terms": {"field": "topic"}}}
}因此,在上面的例子中,我们将计算 topic 字段的术语聚合,其中年份字段大于 2023,或者文档具有与之关联的主题 elastic。
折叠 - collapsing
除了我们上面讨论的聚合选项之外,我们现在还可以折叠结果,就像我们对 standard 查询请求所做的那样。在下面的示例中,我们计算 rrf 检索器的前 10 个结果,然后将它们折叠在 year 字段下。与 standard 搜索的主要区别在于,这里我们只折叠排名靠前的结果,而不是嵌套检索器中的结果。
GET /retrievers_example/_search
{"retriever": {"rrf": {"retrievers": [{"text_similarity_reranker": {"retriever": {"standard": {"query": {"term": {"topic": "ai"}}}},"field": "text","inference_text": "Can I use generative AI to identify user intent and improve search relevance?","rank_window_size": 10,"inference_id": "my-reranker-model"}},{"knn": {"field": "vector","query_vector":[0.23,0.67,0.89],"k": 3,"num_candidates": 5}}],"rank_window_size": 10,"rank_constant": 1}},"collapse": {"field": "year","inner_hits": {"name": "year_results","_source": ["text","year"]}},"_source": ["text","topic"]
}分页 - pagination
正如文档中所述,复合检索器也支持分页。与 standard 查询相比,复合检索器有一个显著的区别,与上面的折叠类似,rank_window_size 参数是我们可以执行导航的整个结果集。这意味着,如果 from + size > rank_window_size,那么我们将不会返回任何结果(但我们仍会返回聚合)。
GET /retrievers_example/_search
{"retriever": {"rrf": {"retrievers": [{"standard": {"query": {"term": {"topic": "elastic"}}}},{"knn": {"field": "vector","query_vector":[0.23,0.67,0.89],"k": 3,"num_candidates": 5}}],"rank_window_size": 10,"rank_constant": 1}},"from": 2,"size": 2"_source": ["text","topic"]
}在上面的例子中,我们将从两个嵌套检索器(standard 和 knn)的组合中计算前 10 个结果(如 rrf 的 rank_window_size 中定义),然后我们将通过查阅 from 和 size 参数来执行分页。因此,在这种情况下,我们将跳过前 2 个结果(from)并选择接下来的 2 个结果(size)。
现在考虑一个不同的场景,在上面的相同查询中,我们将改为使用 from:10 和 size:2。假设 rank_window_size 为 10,并且这些将是我们可以分页的所有结果,在跳过前 10 个结果后请求获取 2 个结果将超出可导航结果集,因此我们将返回空结果。在 rrf 检索器的文档中还可以找到其他示例和更详细的细分。
解释 - explain
我们知道能力越大,责任越大。鉴于我们现在可以任意组合检索器,因此可能很难理解为什么最终会首先返回某个结果,以及如何优化我们的检索策略。出于这个非常具体的原因,我们努力确保检索器请求的解释输出(即通过指定 explain: true)将传达所有子检索器的所有必要信息,以便我们能够正确理解导致结果最终排名的所有因素。以 Collapsing 部分中相当复杂的查询为例,第一个结果的解释如下所示:
{"_explanation":{"value": 0.8333334,"description": "sum of:","details": [{"value": 0.8333334,"description": "rrf score: [0.8333334] computed for initial ranks [2, 1] with rankConstant: [1] as sum of [1 / (rank + rankConstant)] for each query","details": [{"value": 2,"description": "rrf score: [0.33333334], for rank [2] in query at index [0] computed as [1 / (2 + 1)], for matching query with score","details": [{"value": 0.0011925492,"description": "text_similarity_reranker match using inference endpoint: [my-awesome-rerank-model] on document field: [text] matching on source query ","details": [{"value": 0.3844723,"description": "weight(topic:ai in 1) [PerFieldSimilarity], result of:","details":[...]}]}]},{"value": 1,"description": "rrf score: [0.5], for rank [1] in query at index [1] computed as [1 / (1 + 1)], for matching query with score","details":[{"value": 1,"description": "doc [1] with an original score of [1.0] is at rank [1] from the following source queries.","details":[{"value": 1,"description": "found vector with calculated similarity: 1.0","details":[]}]}]}]}]}
}仍然有点冗长,但它传达了有关文档为何位于特定位置的所有必要信息。对于顶级 rrf 检索器,我们指定了 2 个details 信息,每个嵌套检索器一个。第一个是 text_similarity_reranker 检索器,我们可以在其中看到重新排序操作的权重,第二个是 knn 查询,告知我们文档与查询向量的计算相似性。可能需要一点时间才能熟悉,但每个检索器都会确保输出你可能需要评估和优化搜索场景的所有信息!
结论
现在就这些了!我们希望您一直关注我们,并且喜欢这个主题!我们对 retriever 框架的发布以及我们现在可以支持的所有新用例感到非常兴奋!检索器是为了支持从非常简单的搜索到高级 RAG 和混合搜索场景而构建的!如上所述,请关注此空间,更多功能即将推出!
Elasticsearch 包含新功能,可帮助您为你的用例构建最佳搜索解决方案。立即开始免费云试用或在你的本地机器上试用 Elastic。
原文:Elasticsearch retrievers are generally available with Elasticsearch 8.16.0! - Search Labs
相关文章:
Elasticsearch retrievers 通常与 Elasticsearch 8.16.0 一起正式发布!
作者:来自 Elastic Panagiotis Bailis Elasticsearch 检索器经过了重大改进,现在可供所有人使用。了解其架构和用例。 在这篇博文中,我们将再次深入探讨检索器(retrievers)。我们已经在之前的博文中讨论过它们…...

【并发模式】Go 常见并发模式实现Runner、Pool、Work
通过并发编程在 Go 程序中实现的3种常见的并发模式。 参考:https://cloud.tencent.com/developer/article/1720733 1、Runner 定时任务 Runner 模式有代表性,能把(任务队列,超时,系统中断信号)等结合起来…...

【前端知识】Javascript前端框架Vue入门
前端框架VUE入门 概述基础语法介绍组件特性组件注册Props 属性声明事件组件 v-model(双向绑定)插槽Slots内容与出口 组件生命周期样式文件使用1. 直接在<style>标签中写CSS2. 引入外部CSS文件3. 使用CSS预处理器4. 在main.js中全局引入CSS文件5. 使用CSS Modules6. 使用P…...

Springboot3.3.5 启动流程之 Bean创建流程
在文章Springboot3.3.5 启动流程(源码分析)中我们只是粗略的介绍了bean 的装配(Bean的定义)流程和实例化流程分别开始于 finishBeanFactoryInitialization 和 preInstantiateSingletons. 其实,在Spring boot中,Bean 的装配是多阶段的…...

golang反射函数注册
package main import ( “fmt” “reflect” ) type Job interface { New([]interface{}) interface{} Run() (interface{}, error) } type DetEd struct { Name string Age int } // 为什么这样设计 // 这样就避免了 在创建新的实例的之后 结构体的方法中接受者为指针类型…...

【Spring】Bean
Spring 将管理对象称为 Bean。 Spring 可以看作是一个大型工厂,用于生产和管理 Spring 容器中的 Bean。如果要使用 Spring 生产和管理 Bean,那么就需要将 Bean 配置在 Spring 的配置文件中。Spring 框架支持 XML 和 Properties 两种格式的配置文件&#…...

深入解析TK技术下视频音频不同步的成因与解决方案
随着互联网和数字视频技术的飞速发展,音视频同步问题逐渐成为网络视频播放、直播、编辑等过程中不可忽视的技术难题。尤其是在采用TK(Transmission Keying)技术进行视频传输时,由于其特殊的时序同步要求,音视频不同步现…...

为什么要使用Ansible实现Linux管理自动化?
自动化和Linux系统管理 多年来,大多数系统管理和基础架构管理都依赖于通过图形或命令行用户界面执行的手动任务。系统管理员通常使用清单、其他文档或记忆的例程来执行标准任务。 这种方法容易出错。系统管理员很容易跳过某个步骤或在某个步骤上犯错误。验证这些步…...

Android:任意层级树形控件(有效果图和Demo示例)
先上效果图: 1.创建treeview文件夹 2.treeview -> adapter -> SimpleTreeAdapter.java import android.content.Context; import android.view.View; import android.view.ViewGroup; import android.widget.ImageView; import android.widget.ListView; i…...

C++ 容器全面剖析:掌握 STL 的奥秘,从入门到高效编程
引言 C 标准模板库(STL)提供了一组功能强大的容器类,用于存储和操作数据集合。不同的容器具有独特的特性和应用场景,因此选择合适的容器对于程序的性能和代码的可读性至关重要。对于刚接触 C 的开发者来说,了解这些容…...

C++---类型转换
文章目录 C的类型转换C的4种强制类型转换RTTI C的类型转换 类型转换 内置类型之间的转换 // a、内置类型之间 // 1、隐式类型转换 整形之间/整形和浮点数之间 // 2、显示类型的转换 指针和整形、指针之间 int main() {int i 1;// 隐式类型转换double d i;printf("%d…...

CSS基础学习练习题
编程题 1.为下面这段文字定义字体样式,要求字体类型指定多种、大小为14px、粗细为粗体、颜色为蓝色。 “有规划的人生叫蓝图,没规划的人生叫拼图。” 代码: <!DOCTYPE html> <html lang"en"> <head><me…...

TypeScript知识点总结和案例使用
TypeScript 是一种由微软开发的开源编程语言,它是 JavaScript 的超集,提供了静态类型检查和其他一些增强功能。以下是一些 TypeScript 的重要知识点总结: 1. 基本类型 TypeScript 支持多种基本数据类型,包括: numbe…...

解决BUG: Since 17.0, the “attrs“ and “states“ attributes are no longer used.
从Odoo 17.0开始,attrs和states属性不再使用,取而代之的是使用depends和domain属性来控制字段的可见性和其他行为。如果您想要在选择国家之后继续选择州,并且希望在选择了国家之后才显示州字段,您可以使用depends属性来实现这一点…...

单片机GPIO中断+定时器 实现模拟串口接收
单片机GPIO中断定时器 实现模拟串口接收 解决思路代码示例 解决思路 串口波特率9600bps,每个bit约为1000000us/9600104.16us; 定时器第一次定时时间设为52us即半个bit的时间,其目的是偏移半个bit时间,之后的每104us采样并读取1bit数据。使得…...
《深入理解 Spring MVC 工作流程》
一、Spring MVC 架构概述 Spring MVC 是一个基于 Java 的轻量级 Web 应用框架,它遵循了经典的 MVC(Model-View-Controller)设计模式,将请求、响应和业务逻辑分离,从而构建出灵活可维护的 Web 应用程序。 在 Spring MV…...

HTML简介
知识点一 HTML 什么是HTML? 超文本标记语言(HyperTextMarkup Language,简称HTML) 怎么学HTML? HTML 是一门标记语言,标记语言由一套标记标签组成,学习 HTML,其实就是学习标签 开发工具 编辑器: Pycha…...

Linux系统Centos设置开机默认root用户
目录 一. 教程 二. 部分第三方工具配置也无效 一. 教程 使用 Linux 安装Centos系统的小伙伴大概都知道,我们进入系统后,通常都是自己设置的普通用户身份,而不是 root 超级管理员用户,导致我们在操作文件夹时往往爆出没有权限&am…...

【网络安全 | 甲方建设】双/多因素认证、TOTP原理及实现
未经许可,不得转载。 文章目录 背景双因素、多因素认证双因素认证(2FA)多因素认证(MFA)TOTP实现TOTP生成流程TOTP算法TOTP代码示例(JS)Google Authenticator总结背景 在传统的在线银行系统中,用户通常只需输入用户名和密码就可以访问自己的账户。然而,如果密码不慎泄…...

Nuxt3 动态路由URL不更改的前提下参数更新,NuxtLink不刷新不跳转,生命周期无响应解决方案
Nuxt3 动态路由URL不更改的前提下参数更新,NuxtLink不刷新不跳转,生命周期无响应解决方案 首先说明一点,Nuxt3 的动态路由响应机制是根据 URL 是否更改,参数的更改并不会触发 Router 去更新页面,这在 Vue3 上同样存在…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...

Python实现简单音频数据压缩与解压算法
Python实现简单音频数据压缩与解压算法 引言 在音频数据处理中,压缩算法是降低存储成本和传输效率的关键技术。Python作为一门灵活且功能强大的编程语言,提供了丰富的库和工具来实现音频数据的压缩与解压。本文将通过一个简单的音频数据压缩与解压算法…...
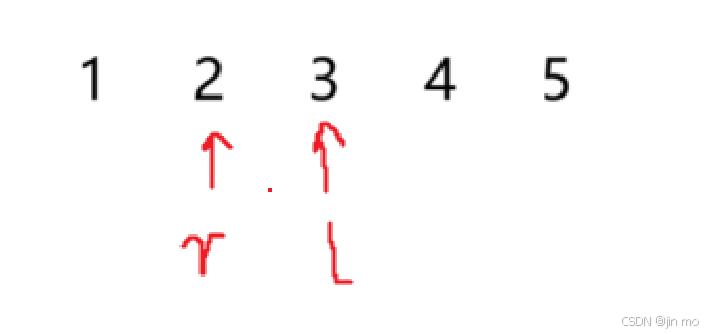
leetcode_69.x的平方根
题目如下 : 看到题 ,我们最原始的想法就是暴力解决: for(long long i 0;i<INT_MAX;i){if(i*ix){return i;}else if((i*i>x)&&((i-1)*(i-1)<x)){return i-1;}}我们直接开始遍历,我们是整数的平方根,所以我们分两…...
【笔记】AI Agent 项目 SUNA 部署 之 Docker 构建记录
#工作记录 构建过程记录 Microsoft Windows [Version 10.0.27871.1000] (c) Microsoft Corporation. All rights reserved.(suna-py3.12) F:\PythonProjects\suna>python setup.py --admin███████╗██╗ ██╗███╗ ██╗ █████╗ ██╔════╝…...