2024.5 AAAiGLaM:通过邻域分区和生成子图编码对领域知识图谱对齐的大型语言模型进行微调
GLaM: Fine-Tuning Large Language Models for Domain Knowledge Graph Alignment via Neighborhood Partitioning and Generative Subgraph Encoding
问题
如何将特定领域知识图谱直接整合进大语言模型(LLM)的表示中,以提高其在图数据上自然语言问答(QA)任务中的准确性,特别是在处理复杂推理查询时,同时解决事实性幻觉问题并保留文本处理能力。
挑战
- 现有 LLM - 图整合方法主要侧重于利用 LLM 知识提升图神经网络在节点分类和链接预测等任务上的性能,而增强 LLM 对图进行推理的研究相对较少。
- 传统方法将知识库视为外部可检索存储,未将其集成到模型参数中,无法实现上下文集成符号约束来塑造中间推理。
- 实际应用中的知识图谱具有倾斜的大小分布和稀疏性等特性,给编码和处理带来困难。
创新点
提出了一种通过微调将领域特定知识图谱融入大语言模型的方法,即 Graph - aligned LAnguage Models(GLAM)框架,将知识图谱转换为带有标记问答对的替代文本表示,使模型能够基于图进行推理。
贡献
- 提出的邻域分区和编码方案能够适应现实世界图的特性,为基于成本 - 准确性权衡的 LLM 编码调整开辟了实验可能性。
- 评估了五种利用 LLM 固有总结和文本生成能力的编码方法,验证了相关方向的可行性。
- 基于两个特定图开发了新的领域问答数据集,涵盖了从链接预测到多跳推理查询的一系列评估任务,并将开源代码和数据集。
提出的方法
- 任务定义:将知识图谱转换为用于语言模型微调的文本数据集,生成需要神经图推理来回答涉及关系或多跳推理的开放域问题的(上下文,问答)对。
- 最优子图上下文生成
- 对于图中的每个节点,检索其 k - 跳邻域子图,并将其编码为文本,同时生成需要在该子图上进行推理的问答对。
- 通过引入超参数 Nmax 对邻域子图进行分区,以满足 LLM 的最大令牌限制约束,确保编码后的序列长度不超过限制。
- 邻域编码函数
- 编码通过三元组:将边数据转换为(源,关系,目标)三元组,但每个训练样本仅表示单条边,上下文大小有限。
- 编码通过邻接表 / 关系组:包括中心节点的整个邻接表或根据关系类型对邻居进行分区,以支持更复杂的推理任务。
- 编码通过总结:利用 LLM 的提示方法将上述编码重写为更连贯的表示,实现节点标签的语义对齐、减少冗余文本、引入额外知识 / 同义词,并减少过拟合。
- 编码通过节点描述符:利用 LLM 的零样本能力将 k - 跳上下文子图转换为基于文本的节点描述符,适用于处理新图数据中 LLM 不熟悉的术语。
- 生成问答对:根据从子图生成的文本上下文,通过提示生成不同任务(事实回忆、逆事实回忆、多跳问答)的问答对,并映射为开放域问答和多项选择题两种答案格式。
指标
- BERTScore:用于评估开放域问答中模型生成的回答与预期回答之间的文本相似性,报告精确率(P)、召回率(R)和 F1 分数。
- 准确率:在多项选择题设置中,用于评估模型从 5 个可能选择中识别正确答案的能力。
模型结构
论文未提及传统意义上的模型结构,主要关注如何将知识图谱编码并整合到 LLM 中,通过邻域分区和编码方案以及各种编码函数对知识图谱进行处理,以适应 LLM 的输入要求并提升其推理能力。
结论
- GLAM 在领域知识检索任务中显著优于传统 LLM,证明了将领域特定知识图谱整合进 LLM 的有效性。
- 在训练中增加节点邻域上下文可提高推理性能,从单三元组样本到包含多关系和邻域信息的训练方式改进了模型的回忆和推理能力。
- 使用 LLM 进行节点上下文总结有助于学习,能提高 GLAM 的事实回忆和多跳推理能力。
剩余挑战和未来工作
- 评估分区和编码方案在更广泛、连接分布高度不均匀的大规模图上的有效性。
- 进一步探索如何更好地利用图结构知识进行复杂推理,提升模型在处理关系方向性等方面的能力。
数据集
- UMLS(Unified Medical Language System):一个医学知识图谱,使用了经过处理的版本,包含 297,927 个概念、98 种关系类型和 1,212,586 条边,选择了捕获不同疾病、症状和药物之间关系的子图,用于 GLAM 训练,包含 “cause of”、“may cause”、“risk factor of” 和 “may treat” 4 种关系类型,共 126,149 个三元组。
- DBLP:一个从 DBLP、ACM、MAG 等来源提取的引文图数据集,包括论文引用、摘要、作者、出版年份、会议和标题等信息。用于 GLAM 训练时,聚焦于包含标题、摘要、会议和 2 个或更多作者的论文集,共 19,577 篇独特论文。
抽象
将大型语言模型(LLM)与源自特定领域数据的知识图谱集成代表了向更强大和事实推理的重要进步。随着这些模型的能力越来越强,让它们能够对真实世界的知识图谱进行多步骤推理,同时最大限度地减少幻觉至关重要。虽然大型语言模型擅长对话和文本生成,但它们对互连实体的领域专用图进行推理的能力仍然有限。例如,我们可以查询 LLM 以基于私有数据库中的关系和属性来识别专业网络中特定目标的最佳联系人吗?答案是否定的 —— 这些功能超出了当前方法的范围。然而,这个问题凸显了一个必须解决的关键技术差距。科学、安全和电子商务等领域的许多高价值应用依赖于编码独特结构、关系和逻辑约束的专有知识图谱。我们介绍了一个用于开发图对齐语言模型(GLAM)的微调框架,该框架将知识图转换为带有标记问答对的替代文本表示。我们证明了将模型建立在特定的基于图的知识中可以扩展模型基于结构的推理能力。我们的方法论利用大型语言模型的生成能力来创建数据集,并提出了检索增强生成样式方法的有效替代方法。
导言
大型语言模型(LLM)最近展示了颠覆性的潜力,它们能够以类似人类的语言能力生成文本和回答问题。然而,它们的推理仍然受到完全依赖文本训练数据的限制,缺乏与编码复杂现实世界约束和关系的结构化知识图的集成。通过将 LLM 与多关系图对齐来弥合这一鸿沟,可以实现对由图结构化数据驱动的应用程序至关重要的有根据的事实推断。
过去关于 LLM 图集成的工作主要集中在利用 LLM 知识来改进图
神经网络在节点分类和链接预测等任务上的性能(Jinet al.2023)。增加或 “微调” LLM 以推理图的替代方向仍相对未被探索。例如,现有技术仍然将知识库视为外部可检索存储(Lewis et al.2020),而不是将它们集成到模型参数中。使用 LLM 作为编码器来转换图中基于文本的节点和边缘标签,然后融合 LLM 和 GNN 派生的表示一直是各种应用的主要方法,从产品推荐(Choudhary et al.2022)到多项选择题环境中的生物医学问答(Yasunaga et al.2022)。
我们的工作是第一个通过微调将特定领域的知识图直接整合到 LLM 表示中的研究,目标是提高开放式问答(QA)的准确性,这是一项比以前工作中探索的多项选择题设置更复杂的任务。通过在生物医学存储库、推荐系统和社交网络中的专用图中编码模式和实体,我们可以增强基于现实世界约束的多跳推理。这解决了自由形式推理中事实幻觉的挑战,同时保留了多功能文本处理优势(Touvron et al.2023; Nori et al.2023)。
问题定义
我们的工作目标是图数据上的自然语言问答(QA)。我们将定义为大型语言模型的函数表示,该模型接受来自词汇表 v 的一系列高维离散标记作为输入,并产生从同一空间绘制的输出序列。给定一个自然语言问题 Q(也称为提示),将 Q 从 v 中导出成一系列标记并返回答案
接下来,我们引入一个图数据集,其中 V 是顶点集,E 是边集。重要的是,我们假设 G 不包括在的训练数据中。图 1 描述了激励这些图 QA 工作负载的真实用例,例如基于社交或专业网络的推荐或患者特定的临床假设生成。
我们的目标是引入一个新的功能uti
从 G 到回答问题 Q 的信息。形式上,。在本文中,我们系统地探索了以下三个查询类,在开放式问答和多项选择题设置中:
委托给 GNN 一种常见的方法使用图神经网络作为编码器。给定一个自然语言查询 Q,这需要从
查询和集成 GNN 和 LLM 表示。这种集成可以通过学习耦合 LLM 和 GNN 表示的联合模型来完成(Saxena、Tripath i 和 Talukdar 2020;Yasunaga 等人 2022),或者使用将 GNN 派生的向量嵌入到 LLM 提示符中的软提示方法(田等人 2023)。
1. 事实回忆:评估 GLM 回忆训练期间看到的领域事实的能力(例如回答 “糖尿病有哪些可能的治疗方法?” 在看到 “糖尿病用胰岛素和二甲双胍治疗” 后)。
检索增强生成检索增强生成(RAG)方法遵循类似的实现路径。这里的不同之处在于,不是委托给 GNN,而是查询包含节点和 / 或关系嵌入的外部图数据库(江等人 2023)或向量数据库(田等人 2023)。在这两种方法中,LLM 都被用作本地图数据库或机器学习模型的路由接口,来自适当的基于图的组件的答案被反馈给用户,LLM 作为生成层,产生最终答案。
2. 反向事实回忆:评估关系方向性的处理,最近的工作表明标准 LM 很难做到这一点(“A 是 B 并不意味着” B 是)(Berglund et al.2023)。这是以前没有为 LLM 图模型探索过的图的一个关键方面。
3. 推理链:需要适当使用图结构知识的复杂查询,例如图 1(左)。
少镜头提示在这种方法中,与 Q 相关的子图被提取并插入到带有示例的提示中(法特米、哈尔克劳和佩罗齐 2023)。虽然很有希望,但这种方法面临着潜在的缺点,需要在 LLM 提示中编码全图或对每个问题执行多跳子图检索。
技术方法及相关工作
在过去的几年里,探索大型语言模型和知识图谱的交集引起了浓厚的兴趣。我们首先概述了文献中用于回答知识图谱上复杂推理查询的关键设计范式,将图数据与大型语言模型(LLM)对齐,并向读者推荐一组优秀的调查文章,以详细概述这一新兴子领域(潘等人。2023;刘等人。2023;金等人。2023)。任何方法都必须解决两个问题: 1)如何将图 G 编码到 LLM 的知识表示中,以及 2)查询 Q 如何执行。
微调的动机不管它们有什么不同,上述所有方法都可能面临一个基本的限制 —— 它们不能在上下文中集成符号约束来塑造中间推理。仅基于初始查询检索嵌入或三元组的方法忽略了多方面的执行,其中使用混合专家的动态路由(Shazeer 等人,2017 年;周等人,2022 年)、规划(郝等人,2023 年;姚等人,2023 年)和启发式搜索(Sprueill 等人,2023 年;Sun 等人,2023 年)步骤修改每个推理中的信息需求步骤。固定检索排除了将图结构动态折叠到每个决策点中。
相比之下,微调将领域知识先验地灌输到模型参数和表示中,而不是将图视为外部附加组件。通过将约束和依赖关系直接编码到知识基础中,微调允许上下文图在建模认知的每一步产生影响。图不再充当静态查找,而是成为一个完整的推理组件 —— 以更严格、更细粒度的方式塑造复杂的推理。
我们的方法和贡献我们引入了一种算法,将每个节点周围的邻域子图迭代划分和编码为文本句子,以便对数据进行微调。这会将图形结构转换为大型语言模型可以提取和微调的格式。我们在两个图表上探索编码策略:1) UMLS - 生物医学知识库,以及 2) DBLP - 学术出版网络。
我们的工作做出了以下贡献。
- 我们的邻域分区和编码方案适应现实世界的图属性,如偏斜大小分布和稀疏性。我们的方法开辟了未来的实验可能性,通过根据成本准确性权衡设置上下文大小限制来调整 LLM 的编码。
- 我们提出并评估了利用 LLM 固有的摘要和文本生成优势的五种编码方法。例如,我们评估 LLM 生成的邻域摘要。令人鼓舞的是,我们的结果与并行工作中的类似方法(Fatemi、Halcrow 和 Perozzi 2023)一致,证实了这一方向的前景。
- 我们基于上面的两个图表开发了一个新的领域问答数据集,其中包含一套评估任务,用于捕获到多跳推理查询的链接预测。代码和数据集将在接受后作为开源发布。
方法
任务定义我们提出了将知识图谱转换为相应的基于文本的语言模型微调数据集的方法。我们的目标是产生成对的 (context, question-answer) (Ouyang et al. 2022;Wei et al. 2021),需要神经图推理来回答涉及关系或多跳推理的开放领域问题。
我们首先描述一种通用算法(算法 1),该算法通过多个运算符函数的组合将节点的 k 跳邻域编码为这样的上下文和 QA 对。我们将在本节的后半部分更详细地讨论这些运算符的实现。
子图上下文的最优生成
对于每个节点 ,我们将 v 的 k 跃点邻域转换为以下形式的一组对:

邻域编码函数
邻域编码函数的目的是将以节点 v 为中心的邻域子图 转换为可以由大型语言模型 (LLM) 有效处理的文本表示。这个过程对于使 LLM 能够执行高阶推理和回答有关图的复杂问题至关重要。
影响邻域编码函数选择的主要因素有两个:
- 将图结构和高阶推理要求传达给 LLM:编码函数应有效地捕获子图中节点之间的结构关系,以及可能存在的任何高阶逻辑依赖关系。这可以通过合并有关边缘及其类型以及多个节点之间关系的信息来实现。
- 与 LLM 的内部知识表示的语义对齐:编码应以与 LLM 存储和解释信息的方式一致的方式表示图中的节点和关系。这可能涉及对节点和边使用自然语言标签,或者在 LLM 无法识别节点标签(例如学术网络)时使用节点的邻域生成描述性标签,同时确保编码表示保留图形元素的语义含义。
通过三元组编码:邻域编码的一种简单方法是将边缘数据转换为 (source, relation, target) 三元组。这为 LLM 提供了有关节点之间关系的基本信息,但它仅限于表示每个训练样本的单个边缘,并且上下文大小有限。
通过邻接列表 / 关系组进行编码 为了使 LLM 能够执行更复杂的推理任务,我们更新了邻域编码以包含有关子图中多个节点的信息。我们尝试了两种不同的选项:包括中心节点 v,并根据邻居的关系类型将邻居划分为子集。我们观察到更复杂的方法,例如采样技术与大型邻居列表相关,但在当前工作中尚未实现。
通过摘要进行编码接下来,我们专注于语义对齐目标,并使用提示方法将上述方法的编码重写为更连贯的表示形式(图 2)。
- ・提示允许我们将笨拙的节点标签映射到人类可理解的术语:例如,LLM 将 “Insulin human, rDNA origin” 映射到 “Insulin therapy from recombinant DNA”,以便在微调过程中更好地解释。
- ・它减少了来自类似标记节点的冗余文本:“Diabetes mellitus, Type 1 diabetes mellitus, Type 2 diabetes mellitus” 映射到 “diabetes, including type 1 and type 2 diabetes”。
- ・在培训中引入额外的知识 / 同义词:“Hypoinsulinaemia” 映射到 “low insulin levels (hypoinsulinaemia)”,“rDNA” 扩展为 “recombinant DNA”。
- ・基于提示的重写还可以通过将过拟合映射到不同的短语,将过拟合减少到仅几个关系标签。在 “may treat” 关系中观察到这种过拟合的例子,其中该短语在特定模式中出现的大量次数会导致 LLM 生成的答案错误地填充了 “may treat” 短语的出现次数过多。
通过节点描述符进行编码 前面的编码步骤利用 LLM 对特定实体(例如 “rDNA”)的理解来以最大的语义对齐进行重写。但是,对新图形数据的训练可能包括 LLM 不熟悉的术语,即在初始训练中很少出现或根本不出现的单词或短语。此问题的一个常见示例涉及对标准 LLM 训练数据集中不常见的人名进行编码。此外,我们不希望根据人员的姓名来映射人员,而是考虑其配置文件属性或网络中的 k -hop 连接。我们通过利用 LLM 的零样本功能将 k 跳上下文子图 转换为一组基于文本的节点描述符来推广这一需求。通常,这是替代 implementation 将检索 GNN 表示的步骤。例如,为了扩展 DBLP 数据集中作者的信息,我们提示 LLM 提取论文摘要的主题领域,并从其论文历史中构建作者发表的主题列表。
生成问答对最后,给定一个由子图 生成的文本上下文,我们通过提示文本上下文执行不同的任务(事实回忆、逆事实回忆、多跳问答)来生成一组问答对。每个问题还映射为两种类型的答案:1) 开放域问答,以及 2) 多项选择题。例如,给定一个 (head, relation, tail) 三元组作为子图上下文,则通过包含其中一个尾部实体和图中其他节点的随机选择来生成其多项选择答案候选项,以形成一组可能的问题的答案。
实验
在本节中,我们通过实验分析解决以下研究问题 (RQ):
- RQ-1 使用图形编码进行微调是否能提高 LLM 回忆事实的能力?
- RQ-2 使用图编码对 LLM 进行微调是否通过在图域上执行多跳推理来提高其回答开放域自然语言问题的能力?
- RQ-3 哪些子图上下文编码策略产生原始 LLM 和目标图的最大语义对齐?
数据集
我们展示了在两个图数据集上训练 GLaM 的结果,DBLP(Tanget al.2008)和 UMLS(Bodenreider 2004),在 LLM 中具有不同的应用程序和覆盖率,以展示对基线语言模型的响应改进。
统一医学语言系统 1(UMLS)(Bodenreider 2004)是一个医学知识图。我们使用 Yasunaga 等人(Yasunaga 等人,2022 年)的知识图的处理版本,由 297,927 个概念组成,
98 种关系类型和 1,212,586 条边捕捉了广泛的医学概念之间的关系。对于 GLaM 培训,我们选择了一个子图来捕捉不同疾病、症状和药物之间的关系。这导致减少到 4 种不同的关系类型:“原因”、“可能导致”、“风险因素” 和 “可能治疗” 总共 126,149 倍。
DBLP2(Tanget al.2008)是从 DBLP、ACM、MAG 和其他来源提取的引文图数据集。该数据集包括论文引用、摘要、作者、出版年份、地点和标题。为了训练 GLaM,我们专注于包含标题、摘要、地点和 2 名或更多作者的集合论文,导致 19,577 篇独特的论文。
训练和推理设置
对于 UMLS 和 DBLP,提取的自然语言问题和答案被分成 70% 的训练(事实回忆)和 30% 的测试(多跳推理)。我们使用 Microsoft DeepSpeed 框架(Rasley et al.2020)进行监督提示和响应微调。使用 Llama-7bchat-hf 作为训练 GLaM 的基本模型对训练超参数进行网格搜索。1e−5 的学习率和余弦学习率调度器与 bfloat16 精度的融合 Adam 优化器一起使用。最大序列长度设置为 256,所有模型最多使用 4 个训练周期。一个由 8 个 A100 GPU 组成的集群,每个 GPU 内存为 80GB,用于训练,每个设备的批次大小为 4 个问题,导致总训练批次大小为 32 个。我们使用 7b 的 Llama2 - 聊天 - hf 和 Llama-2-13b-chat-hf(Touvron et al.2023)模型作为训练的基线模型。在 UMLS 上训练 7b 模型对于 13b 模型大约需要 9 分钟和 16 分钟。对于 DBLP,训练时间分别大约为 11 和 21 分钟。
评估任务
事实回忆:该任务相当于语言模型中的问答任务,并测试 GLaM 记住训练期间看到的领域级事实的能力。例如,给定一个训练句子,如 “糖尿病用胰岛素和二甲双胍治疗”(来自 UMLS),该模型被查询为 “糖尿病的可能治疗方法是什么?” 类似地,对于 DBLP 数据集,给定一个句子,如 “[学生以不同的方式学习 CS:来自实证研究的见解] 是由 Anders Berglund 编写的。”,该模型被查询为 “[学生以不同的方式学习 CS:来自实证研究的见解] 是由谁编写的?” 事实回忆的 UMLS 问题集包含 7710 个问题,DBLP 集包含 13,704 个问题。
反向事实回忆:该任务相当于语言模型中的反向问答任务(Berglund et al.2023),并测试 GLaM 从训练期间看到的领域级事实中推断反向关系的能力。例如,给定上述训练语句,模型是查询 “哪种疾病可以用胰岛素治疗?”UMLS 反向事实回忆问题集中有 11130 个问题,DBLP 集中有 13704 个问题。
多跳推理:该任务反映了 GNN 设置中的链接预测任务,并通过对训练期间看到的事实进行推理来测试 GLaM 推断新事实(图边)的能力。多跳推理的 UMLS 问题集包含 3347 个问题,DBLP 集包含 5873 个问题。我们为 DBLP 探索的一个常见问题类型是推荐作者与之合作。以事实回忆任务中提到的 DBLP 问题为例,一个多跳推理问题会问:“安德斯・贝里隆德想写一篇题为 [学生以不同方式学习 CS:来自实证研究的见解] 的论文,发表在《澳大利亚计算教育学报》上。他们应该与谁合作,为什么?”
多项选择题:每个评估任务:事实回忆、反向事实回忆和多跳推理,都被重新格式化为多项选择题。问题包括正确答案和分别从图表中随机选择的四个额外的不正确选项。请注意,这是一个
比开放式问答设置更容易完成,要求模型只从给定选项中选择最有可能的答案。
评估指标
为了考虑 LLM 或 GLaM 生成的答案中固有的文本可变性,我们使用 BERTScore 指标(Zhang et al.2019)进行开放式域 QA 设置和选择题的准确性。
Bert Score:比较模型生成的响应与预期响应之间的文本相似性。microsoft/deberta-xlarg-mnli 模型(He et al.2020)用于计算 BertScore,因为它在自然语言理解(NLU)任务中表现出色。我们在评估集中报告精度(P)、召回率(R)和 F1 分数。
准确度:我们使用标准准确度度量来评估模型在多项选择题设置中从 5 个可能选项中识别正确答案的能力。
结果
训练 GLaM 的结果如表 1 和表 2 所示。我们讨论了各个数据集的结果,然后提供总体结论。
表 1 给出了 UMLS 图实验结果。对于事实召回和推理,使用基于 LLM 的摘要编码重写语句在精度、召回和 F1 分数方面表现出最佳性能。然而,对于反向事实召回,使用更简单的训练方法会导致分数略有提高。所有微调 GLaM 版本都优于基线 LLM,表明即使是朴素的训练策略也比基线 LLM 提供了一些改进。虽然 Llama 的 13b 版本优于 7b 版本,但一旦经过训练,13b 和 7bGLaM 之间的差异可以忽略不计。

表 2 给出了 DBLP 引用图实验结果。具有完全邻接和基于 LLM 的摘要的 GLaM 版本在所有任务中获得了最佳结果。不出所料,由于数据集中不熟悉的名称的数量,未经训练的 LLM 在选择题任务中仅比随机猜测略好。随着邻域信息被整理到训练中,性能也有提高的总体趋势,除了添加出版物的地点没有明显影响之外,可能是因为标题足以捕获出版物上下文。GLaM 的 13b 版本比 7b 版本在事实回忆方面略有改进,但 7b 版本在反向事实回忆和事实推理任务上略优于更大的 GLaM。这与 UMLS 上的类似发现相结合,表明当针对域进行微调时,较小的 LLM 足以进行事实保留和推理。

表 3 提供了 UMLS 和 DBLP 的多项选择题结果。在所有任务中,GLaM 优于未精炼的 LLM,最小的差异是在 UMLS 的反向事实上,GLaM 明显没有学会从训练中推断逆关系。对于 UMLS 事实回忆,GLaM 在回忆训练集的答案时表现出 100% 的准确性,同样在多跳推理问题上表现非常好。我们假设,与开放式问题结果的差异相比,LLM 和 GLaM 在多项选择题结果上的更大差距来自 GLaM 学习区分好答案和差答案,即使它没有明确知道正确答案。

图对齐语言模型显着改善领域知识检索任务。大型语言模型是通用知识的非凡工具,但不能为复杂网络中建模的许多领域特定问题提供答案。GLaM 在所有领域级任务(包括简单的事实检索问题)中的表现优于 LLM 证明了这一点。
在训练期间增加节点邻域上下文可以提高推理性能。UMLS(表 1)和 DBLP(表 2)案例都表明,将多个边合并到每个训练实例中可以提高语言模型的召回和推理。这一点很明显,因为 GLaM 训练从单个三重样本发展到与多个目标的关系,并进一步包括 ad
条件邻域信息,例如作者发布的主题区域。
使用 LLM 进行节点上下文总结改进了学习。使用 LLM 重写或总结节点邻域编码产生的语句提高了 GLaM 的事实回忆和多跳推理,如表 1 所示。即使训练中存在相同的信息,UMLS 图编码的 LLM 总结版本也优于其他 GLaM 版本。我们假设单词选择的变化,将节点标签映射到更可解释的名称有助于显着改善学习过程。
结论和未来的工作我们展示了一种通过微调将特定领域的知识图集成到大型语言模型中的有效方法。经验上,这种技术在基本 LLM 的多跳推理能力方面产生了显著的收益。我们提出的微调方法通过最大限度地利用原始 LLM 的优势 —— 文本理解、常识知识和生成能力 —— 将图结构及其语义知识编码到 LLM 中。
特别是,定量实验验证了 F1 分数在事实召回方面提高了 18%,在需要在 UMLS 领域进行多跳推理的复杂推理查询方面提高了 13%,而在 DBLP 的社交网络结构上分别提高了 142% 和 141%,该结构代表了 LLM 的新信息。鉴于图中关系方向性的重要性,我们还衡量了由此产生的模型对回忆逆事实的改进。总的来说,我们的实验虽然是初步的,但证实了通过微调的集成灌输了基于包含专门实体和关系的图的更可靠的推理能力,并使结构化知识与学习到的表示更紧密地耦合。在具有高度不均匀连通性分布的更广泛的更大规模图上评估分区和编码方案的有效性是未来工作的候选对象。
金,B.;刘,G.;韩,C.;江,M.;吉,H.;韩,J.2023。图上的大型语言模型:综合调查。arxiv 预印本 arxiv:2312.02783。
in, B.; Liu, G.; Han, C.; Jiang, M.; Ji, H.; and Han, J. 2023.
Large Language Models on Graphs: A Comprehensive Sur-
vey. arXiv preprint arXiv:2312.02783
刘杰;杨昌;卢,Z。;陈杰;李,Y。;张,M。;白,T。;方,Y。;孙,L。余,P. S.;等人。2023。走向图基础模型:调查及超越。arxiv 预印本 arxiv:2310.11829。
Liu, J.; Yang, C.; Lu, Z.; Chen, J.; Li, Y.; Zhang, M.; Bai,
T.; Fang, Y.; Sun, L.; Yu, P. S.; et al. 2023. Towards graph
foundation models: A survey and beyond. arXiv preprint
arXiv:2310.11829
使用知识库嵌入改进知识图谱上的多跳问答。计算语言学协会第 58 届年会论文集,4498-4507
Saxena, A.; Tripathi, A.; and Talukdar, P. 2020. Improving
multi-hop question answering over knowledge graphs using
knowledge base embeddings. In Proceedings of the 58th
annual meeting of the association for computational linguis-
tics, 4498–4507
孙杰;徐长春;唐琳;王新春;林琳;龚宇;沈海勇;郭杰。2023。图上思考:用知识图谱进行大语言模型的深度和负责任的推理。arxiv 预印本 arxiv:2307.07697。
Sun, J.; Xu, C.; Tang, L.; Wang, S.; Lin, C.; Gong, Y.; Shum, H.-Y.; and Guo, J. 2023. Think-on-graph: Deep and responsible reasoning of large language model with knowledge graph. arXiv preprint arXiv:2307.07697.
相关文章:
2024.5 AAAiGLaM:通过邻域分区和生成子图编码对领域知识图谱对齐的大型语言模型进行微调
GLaM: Fine-Tuning Large Language Models for Domain Knowledge Graph Alignment via Neighborhood Partitioning and Generative Subgraph Encoding 问题 如何将特定领域知识图谱直接整合进大语言模型(LLM)的表示中,以提高其在图数据上自…...
)
从熟练Python到入门学习C++(record 6)
基础之基础之最后一节-结构体 1.结构体的定义 结构体相对于自定义的一种新的变量类型。 四种定义方式,推荐第一种;第四种适合大量定义,也适合查找; #include <iostream> using namespace std; #include <string.h>…...

jenkins的安装(War包安装)
Jenkins是一个开源的持续集成工具,基于Java开发,主要用于监控持续的软件版本发布和测试项目。 它提供了一个开放易用的平台,使软件项目能够实现持续集成。Jenkins的功能包括持续的软件版本发布和测试项目,以及监控外部调用执行…...

WPS 加载项开发说明wpsjs
wpsjs几个常用的CMD命令: 1.打开cmd输入命令测试版本号 npm -v 2.首次安装nodejs,npm默认国外镜像,包下载较慢时,可切换到国内镜像 //下载速度较慢时可切换国内镜像 npm config set registry https://registry.npmmirror.com …...

【Anomaly Detection论文阅读记录】PaDiM与PatchCore模型的区别与联系
PaDiM与PatchCore模型的区别与联系 背景介绍 PADIM(Pretrained Anomaly Detection via Image Matching)和 PatchCore 都是基于深度学习的异常检测方法,主要用于图像异常检测,尤其是在无监督学习设置下。 PADIM 是一种通过利用预训练的视觉模型(例如,ImageNet预训练的卷…...

uni-app Vue3语法实现微信小程序样式穿透uview-plus框架
1 问题描述 我在用 uni-app vue3 语法开发微信小程序时,在项目中使用了 uview-plus 这一开源 UI 框架。在使用 up-text 组件时,想要给它添加一些样式,之前了解到微信小程序存在样式隔离的问题,也在uview-plus官网-注意事项中找到…...

K8S基础概念和环境搭建
K8S的基础概念 1. 什么是K8S K8S的全称是Kubernetes K8S是一个开源的容器编排平台,用于自动化部署、扩缩、管理容器化应用程序。 2. 集群和节点 集群:K8S将多个机器统筹和管理起来,彼此保持通讯,这样的关系称之为集群。 节点…...

[服务器] 腾讯云服务器免费体验,成功部署网站
文章目录 概要整体架构流程概要 腾讯云服务器免费体验一个月。 整体架构流程 腾讯云服务器体验一个月, 选择预装 CentOS 7.5 首要最重要的是: 添加阿里云镜像。 不然国外源速度慢, 且容易失败。 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/li…...

vue中el-select 模糊查询下拉两种方式
第一种:先获取所有下拉数据再模糊查询,效果如下 1,页面代码:speciesList是种类列表List, speciesId 是speciesList里面对应的id,filterable是过滤查询标签 <el-form-item label"种类" prop"species…...

深入解析PostgreSQL中的PL/pgSQL语法
在数据库管理系统中,PostgreSQL因其强大的功能和稳定性而受到广泛欢迎。其中,PL/pgSQL作为PostgreSQL的过程化语言,为用户提供了更为灵活和强大的编程能力。本文将深入解析PL/pgSQL的语法,帮助读者更好地掌握这门语言,…...
Vue 3集成海康Web插件实现视频监控
🌈个人主页:前端青山 🔥系列专栏:组件封装篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来组件封装篇专栏内容:Vue 3集成海康Web插件实现视频监控 引言 最近在项目中使用了 Vue 3 结合海康Web插件来实…...

多目标优化算法:多目标蛇鹫优化算法(MOSBOA)求解DTLZ1-DTLZ9,提供完整MATLAB代码
一、蛇鹫优化算法 蛇鹫优化算法(Secretary Bird Optimization Algorithm,简称SBOA)由Youfa Fu等人于2024年4月发表在《Artificial Intelligence Review》期刊上的一种新型的元启发式算法。该算法旨在解决复杂工程优化问题,特别是…...

机器翻译基础与模型 之三:基于自注意力的模型
基于RNN和CNN的翻译模型,在处理文字序列时有个问题:它们对序列中不同位置之间的依赖关系的建模并不直接。以CNN的为例,如果要对长距离依赖进行描述,需要多层卷积操作,而且不同层之间信息传递也可能有损失,这…...

如何使用PCL处理ROS Bag文件中的点云数据并重新保存 ubuntu20.04
如何使用PCL处理ROS Bag文件中的点云数据并重新保存 要精确地处理ROS bag中的点云数据并使用PCL进行处理,再将处理后的数据保存回新的ROS bag文件,以下方案提供了详细、专业和严谨的步骤。 步骤 1: 环境设置 确保安装了ROS和PCL,并配置好环…...
)
背包问题(动态规划)
背包问题是一种组合优化的问题,它有多种变体,但最常见的两种是0/1背包问题和完全背包问题。 0/1背包问题 问题描述: 假设你有一个背包,背包的容量为W(可以是重量或者体积等度量),同时有n个物品…...

从0开始学习机器学习--Day26--聚类算法
无监督学习(Unsupervised learning and introduction) 监督学习问题的样本 无监督学习样本 如图,可以看到两者的区别在于无监督学习的样本是没有标签的,换言之就是无监督学习不会赋予主观上的判断,需要算法自己去探寻区别,第二张…...

Vue3插槽v-slot使用方式
在 Vue 3 中,v-slot 是用来定义和使用插槽的指令。插槽是 Vue 的一个功能,允许你在组件内部定义占位内容,便于在父组件中提供动态内容。以下是 v-slot 的详细使用方法: 1. 基础使用 <template><BaseComponent><te…...

Axure二级菜单下拉交互实例
1.使用boxlabe进行基础布局 2.设置鼠标悬浮和选中状态 3.转换为动态面板 选中所有二级菜单,进行按钮组转换 选中所有二级菜单,进行动态面板转换 4.给用户管理增加显示/隐藏事件 1)选择toggle代表上拉和下拉切换加载 2)勾选Bring to Front,并选择Push/Pull Widgets代表收缩时…...

华为VPN技术
1.启动设备 2.配置IP地址 [FW1]int g1/0/0 [FW1-GigabitEthernet1/0/0]ip add 192.168.1.254 24 [FW1-GigabitEthernet1/0/0]int g1/0/1 [FW1-GigabitEthernet1/0/1]ip add 100.1.1.1 24 [FW1-GigabitEthernet1/0/1]service-manage ping permit [FW2]int g1/0/0 [FW2-Gi…...

CommonsBeanutils与Shiro发序列化利用的学习
一、前言 前面的学习中,过了一遍cc1-cc7的利用链,在CC2的利用链中,学习了 java.util.PriorityQueue,它在Java中是一个优先队列,队列中每一个元素都有自己的优先级。在反序列化这个对象时,为了保证队列顺序…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...

Python实现简单音频数据压缩与解压算法
Python实现简单音频数据压缩与解压算法 引言 在音频数据处理中,压缩算法是降低存储成本和传输效率的关键技术。Python作为一门灵活且功能强大的编程语言,提供了丰富的库和工具来实现音频数据的压缩与解压。本文将通过一个简单的音频数据压缩与解压算法…...

FOPLP vs CoWoS
以下是 FOPLP(Fan-out panel-level packaging 扇出型面板级封装)与 CoWoS(Chip on Wafer on Substrate)两种先进封装技术的详细对比分析,涵盖技术原理、性能、成本、应用场景及市场趋势等维度: 一、技术原…...
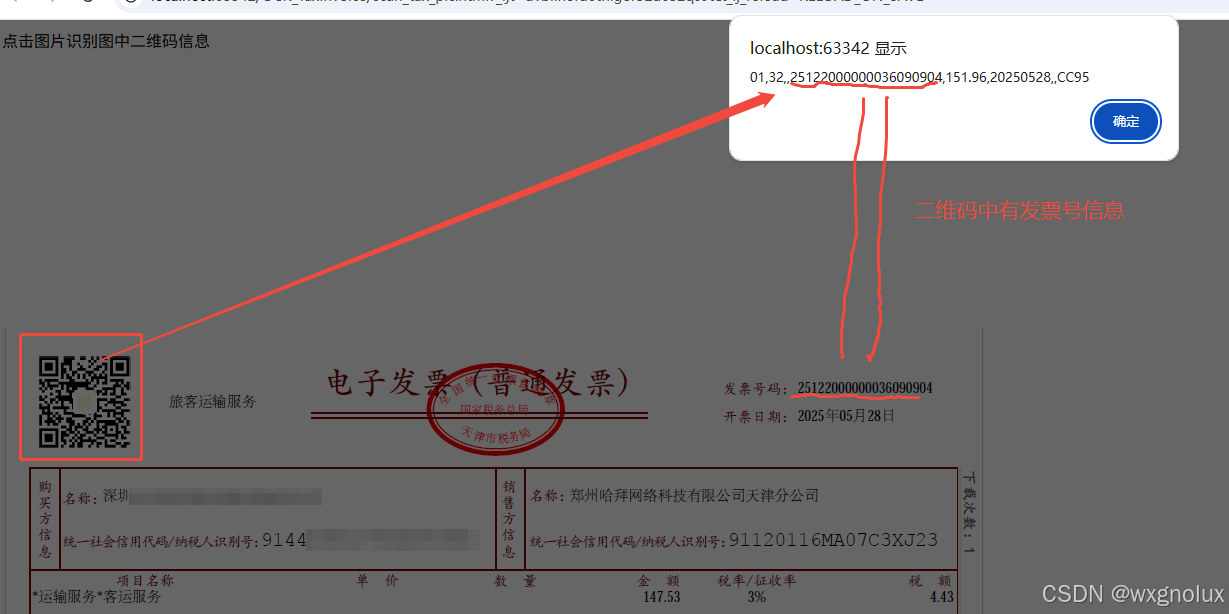
网页端 js 读取发票里的二维码信息(图片和PDF格式)
起因 为了实现在报销流程中,发票不能重用的限制,发票上传后,希望能读出发票号,并记录发票号已用,下次不再可用于报销。 基于上面的需求,研究了OCR 的方式和读PDF的方式,实际是可行的ÿ…...
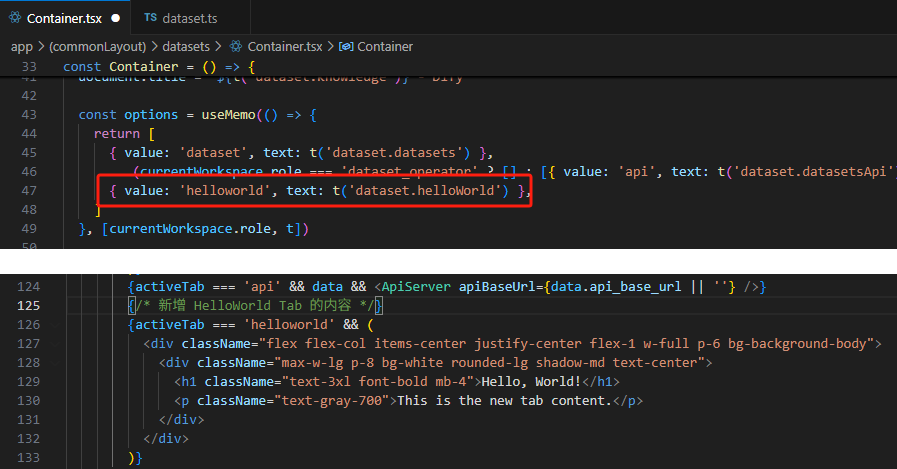
【技巧】dify前端源代码修改第一弹-增加tab页
回到目录 【技巧】dify前端源代码修改第一弹-增加tab页 尝试修改dify的前端源代码,在知识库增加一个tab页"HELLO WORLD",完成后的效果如下 [gif01] 1. 前端代码进入调试模式 参考 【部署】win10的wsl环境下启动dify的web前端服务 启动调试…...