Prometheus结合K8s(二)使用
上一篇介绍了如何搭建 Prometheus结合K8s(一)搭建-CSDN博客,这章介绍使用
页面访问
kubectl get svc -n prom 看promeheus和granfana的端口访问页面
Prometheus

点击status—target,可以看到metrics的数据来源,即各exporter,点击相应exporter上的链接可查看这个exporter提供的metrics明细。

查看指标能否正常输出
访问grafana,添加prometheus数据源: 默认管理账号密码为admin admin

添加数据源,由于都在集群内,所以Prometheusip写cluster ip和端口即可,因为grafana和Prometheus都在集群内,也可以写servicename(五段式)然后import模板,也可以从网上找现成的模板

可以导入监控模板

编辑具体的监控项

这些语句查的是Prometheus里面的监控项,在上方的Prometheus面板graph里面都能查到指标数据
监控项

直接从grafana的官网下载json文件,导入即可
315 用于监控 Kubernetes 集群和 Pods。
057用于监控 MySQL 的查询、连接、缓存等指标。
kubernetes
sum (container_memory_working_set_bytes{id="/",kubernetes_io_hostname=~"^$Node$"}) / sum (machine_memory_bytes{kubernetes_io_hostname=~"^$Node$"}) * 100
这个 PromQL 查询表达式计算了指定 Kubernetes 节点的容器内存使用率百分比,其分解如下:
-
sum(container_memory_working_set_bytes{id="/",kubernetes_io_hostname=~"^$Node$"}):
-
这个部分用于计算指定节点上所有容器的实际使用内存总量,container_memory_working_set_bytes 表示各个容器当前的工作集内存,即容器实际消耗的内存,不包含缓存的内存。通过 {id="/"} 过滤出根目录的内存使用量。
-
标签 kubernetes_io_hostname=~"^$Node$" 用于匹配特定节点的主机名,其中 $Node$ 是目标节点的占位符。
-
-
sum(machine_memory_bytes{kubernetes_io_hostname=~"^$Node$"}):
-
此部分用于获取目标节点的总内存量,通过 machine_memory_bytes 指标得出节点的物理内存总量。
-
同样使用 kubernetes_io_hostname=~"^$Node$" 来锁定节点。
-
-
最终表达式:(工作集内存 / 总内存) * 100
-
将两个部分相除并乘以 100,得到该节点的容器内存使用率百分比。此表达式可以帮助管理员了解容器内存的利用率,识别内存过载风险。
-
sum (rate (container_cpu_usage_seconds_total{id="/",kubernetes_io_hostname=~"^$Node$"}[$interval])) / sum (machine_cpu_cores{kubernetes_io_hostname=~"^$Node$"}) * 100
这个 PromQL 查询用于计算指定 Kubernetes 节点的 CPU 使用率百分比,其结构分解如下:
-
sum(rate(container_cpu_usage_seconds_total{id="/",kubernetes_io_hostname=~"^$Node$"}[$interval])):
-
这个部分计算在指定时间窗口内($interval)每个容器的 CPU 使用率。container_cpu_usage_seconds_total 指标表示容器使用 CPU 的总时间(以秒为单位)。rate() 函数计算该指标在时间范围内的变化率,从而得到每秒的 CPU 使用量。
-
标签 id="/" 通常用于选择容器根路径的指标,而 kubernetes_io_hostname=~"^$Node$" 则用于指定要监控的节点。
-
-
sum(machine_cpu_cores{kubernetes_io_hostname=~"^$Node$"}):
-
此部分获取目标节点的总 CPU 核心数。machine_cpu_cores 指标表示物理机的 CPU 核心数量,通过相同的标签过滤来确保只选择特定节点的数据。
-
-
最终表达式:(CPU 使用总量 / 总核心数) * 100
-
将容器的 CPU 使用率与总 CPU 核心数相除,并乘以 100,得到该节点的 CPU 使用率百分比。
-
sum (container_fs_usage_bytes{device=~"$device",id="/",kubernetes_io_hostname=~"^$Node$"}) / sum (container_fs_limit_bytes{device=~"$device",id="/",kubernetes_io_hostname=~"^$Node$"}) * 100
sum(container_fs_usage_bytes{device=~"$device",id="/",kubernetes_io_hostname=~"^$Node$"}):
-
这一部分计算指定节点上所有容器在指定文件系统设备($device)上的实际使用字节数。container_fs_usage_bytes 指标表示容器文件系统的实际使用空间。
-
标签 id="/" 通常指根文件系统,而 kubernetes_io_hostname=~"^$Node$" 用于匹配特定的节点。
sum(container_fs_limit_bytes{device=~"$device",id="/",kubernetes_io_hostname=~"^$Node$"}):
-
此部分获取指定文件系统设备的总限制字节数,container_fs_limit_bytes 指标表示容器文件系统的大小限制。
-
同样使用 device=~"$device" 和 kubernetes_io_hostname=~"^$Node$" 标签进行过滤。
最终表达式:(文件系统使用字节数 / 文件系统限制字节数) * 100
-
将容器的文件系统使用字节数与总限制字节数相除,结果乘以 100,得到该节点文件系统的使用率百分比。
sum (rate (container_cpu_usage_seconds_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^$Node$"}[$interval])) by (pod_name)
这个 PromQL 查询用于计算 Kubernetes 中每个 Pod 的 CPU 使用率,其结构分析如下:
-
sum(rate(container_cpu_usage_seconds_total{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^$Node$"}[$interval])):
-
container_cpu_usage_seconds_total:此指标表示容器使用 CPU 的总时间(以秒为单位)。
-
rate() 函数用于计算指定时间窗口内($interval)的 CPU 使用速率,即每秒的 CPU 使用量。
-
{image!=""}:此过滤条件确保只计算有图像标签的容器。
-
name=~"^k8s_.*":此过滤条件匹配名称以 k8s_ 开头的容器,通常表示这些容器是由 Kubernetes 管理的。
-
kubernetes_io_hostname=~"^$Node$":此过滤条件用于匹配特定节点,$Node$ 是目标节点的占位符。
-
-
by (pod_name):
-
这部分指示 Prometheus 按 Pod 名称对结果进行分组,以便每个 Pod 的 CPU 使用率可以单独计算和显示。
-
sum (container_memory_working_set_bytes{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^$Node$"}) by (pod_name)
这个 PromQL 查询计算每个 Pod 的内存实际使用量(工作集内存),具体结构如下:
-
sum(container_memory_working_set_bytes{image!="",name=~"^k8s_.*",kubernetes_io_hostname=~"^$Node$"}):
-
container_memory_working_set_bytes 指标表示容器正在使用的实际内存量,不包括缓存内存(即工作集内存)。
-
image!="":过滤掉没有关联镜像的容器,确保仅包含实际正在运行的应用。
-
name=~"^k8s_.*":匹配名称以 k8s_ 开头的容器,通常表示由 Kubernetes 管理的容器。
-
kubernetes_io_hostname=~"^$Node$":匹配特定节点,$Node$ 是目标节点的占位符。
-
-
by (pod_name):
-
该部分按 Pod 名称分组,确保每个 Pod 的工作集内存独立显示。
-
Mysql
mysql_global_status_uptime
用于监控 MySQL 实例的运行时长。具体说明如下:
-
mysql_global_status_uptime:这是 MySQL 的 Uptime 指标,表示 MySQL 实例自上次启动以来的总运行时间(单位为秒)。此指标可以帮助判断 MySQL 实例的稳定性和重启频率。如果 uptime 较短且频繁重启,可能表明存在系统故障或资源问题。
rate(mysql_global_status_queries[$__interval])
用于计算 MySQL 实例在特定时间间隔内的查询速率,具体分析如下:
-
mysql_global_status_queries:此指标代表 MySQL 实例自启动以来处理的查询总数,包括 SELECT、INSERT、UPDATE、DELETE 等操作。该计数指标会随着时间累积增加。
-
rate() 函数:rate() 用于计算特定时间窗口($__interval)内的查询速率,即每秒查询次数。这个速率可以揭示 MySQL 数据库的负载情况,特别是在不同时间段的查询量变化。例如,可以帮助识别高峰时段的查询负载,以便优化资源分配。
mysql_global_variables_innodb_buffer_pool_size
提供了 MySQL 实例的 innodb_buffer_pool_size 配置值,具体解释如下:
-
mysql_global_variables_innodb_buffer_pool_size:该指标表示 InnoDB 缓冲池的大小(以字节为单位),这是 MySQL 用于缓存数据和索引的内存区域。InnoDB 缓冲池的大小对数据库的性能有直接影响,尤其是当数据库的大部分数据都能缓存到缓冲池时,会显著减少磁盘 I/O,提升查询性能。
connections
sum(max_over_time(mysql_global_status_threads_connected{[$__interval]))
用于监控在给定时间窗口内 MySQL 实例的最大连接数具体分解如下:
-
mysql_global_status_threads_connected:该指标表示当前连接到 MySQL 实例的线程数。这个数值会随着时间动态变化,反映当前有多少客户端连接处于活跃状态。
-
max_over_time():该函数用于计算指定时间窗口($interval)内的最大连接数。例如,如果 $interval 为 5 分钟,max_over_time 会返回在过去 5 分钟内连接数的峰值。通过观察此数值,可以了解 MySQL 在特定时间段内的最大连接负载。
-
sum():最外层的 sum() 作用是将多个实例的最大连接数相加,计算整个 MySQL 集群的连接负载总量。
sum(mysql_global_status_max_used_connections)
用于监控 MySQL 实例在历史上达到的最大连接数,具体说明如下:
-
mysql_global_status_max_used_connections:该指标表示 MySQL 自启动以来所记录的最大并发连接数,即历史上出现的最高连接数峰值。此指标可以帮助了解 MySQL 实例连接的最高负载情况,确保最大连接数限制合理。如果此数值接近或超过 max_connections 设置,则可能出现连接拒绝或性能下降的问题。
-
sum():外层的 sum() 用于将符合过滤条件的各实例的最大连接数相加。这样可以在多实例环境中汇总各 MySQL 实例的最大连接数,得出整个 MySQL 集群的最大历史连接负载。
sum(mysql_global_variables_max_connections)
用于获取 MySQL 配置中允许的最大连接数总和。该查询提供了所有符合过滤条件的 MySQL 实例中配置的 max_connections 值的总和。
-
mysql_global_variables_max_connections:此指标表示 MySQL 实例配置的 max_connections 参数值,它定义了允许的最大并发连接数。设置适当的 max_connections 值对于避免连接过载至关重要。
-
sum():最外层的 sum() 会将符合条件的所有实例的最大连接数汇总,以提供一个整体视图,了解 MySQL 集群中所有实例所允许的总连接容量。
sum(max_over_time(mysql_global_status_threads_connected[$__interval]))
用于在给定时间窗口内计算 MySQL 实例的最大连接数。其作用和结构解析如下:
-
mysql_global_status_threads_connected:此指标表示当前连接到 MySQL 的线程数量,反映了实时的连接数负载。这个值随时间变化,表示有多少客户端线程正在连接 MySQL 实例。
-
max_over_time() 函数:此函数用于在指定时间窗口($interval)内计算连接数的最大值。例如,如果 $interval 设置为 5 分钟,则 max_over_time() 会返回过去 5 分钟中连接数的峰值。此峰值帮助了解 MySQL 实例在高负载期的最大连接数。
-
sum() 函数:sum() 汇总所有符合查询条件的 MySQL 实例的最大连接数。在多实例环境中,这个函数可以计算整个 MySQL 集群的峰值连接负载,从而提供一个整体视图。
table locks
Questions
rate(mysql_global_status_questions[$__interval])
用于计算 MySQL 实例在特定时间窗口内执行的 SQL 查询速率。此查询可以帮助数据库管理员评估 MySQL 的查询负载情况,尤其适用于监控 MySQL 在不同时段的查询波动情况。以下是详细说明:
-
mysql_global_status_questions:该指标表示 MySQL 实例自启动以来执行的总查询数量,包含所有 SQL 请求(如 SELECT、INSERT、UPDATE、DELETE 等)。它是一个累积计数指标,随着时间不断增加。
-
rate() 函数:rate() 函数计算指定时间窗口($interval)内的平均速率。对于 mysql_global_status_questions 指标,rate() 会返回在给定的时间间隔内每秒执行的查询数量,能够准确捕捉到 MySQL 的查询速率波动。例如,如果 $interval 为 5 分钟,则 rate() 会返回过去 5 分钟的每秒查询平均数量。
thread cache
sum(mysql_global_variables_thread_cache_size)
用于监控 MySQL 实例的线程缓存大小。以下是对该查询的详细解析:
-
mysql_global_variables_thread_cache_size:此指标表示 MySQL 配置的线程缓存大小(以线程数为单位)。线程缓存用于存储线程的复用,能够减少创建和销毁线程的开销。当有新的客户端连接时,如果缓存中有可用线程,则可以快速响应,从而提升性能。
-
sum() 函数:此函数用于将多个 MySQL 实例的线程缓存大小进行汇总,提供整个 MySQL 集群中线程缓存的总配置。这对于评估集群整体的线程管理能力非常重要。
sum(mysql_global_status_threads_cached)
用于监控 MySQL 实例的缓存线程数量。以下是对该查询的详细分析:
-
mysql_global_status_threads_cached:此指标表示当前从线程缓存中获取的线程数量。线程缓存用于存储已创建的线程,以便在新连接请求到来时快速复用,从而提高性能。此值表示在连接期间实际使用了多少线程缓存。
-
sum() 函数:这个函数会将所有符合条件的 MySQL 实例中的线程缓存数量进行求和,提供整个 MySQL 集群的线程缓存使用情况。这对于了解集群的线程利用效率和性能调优非常重要。
监控 threads_cached 的数量可以帮助数据库管理员评估线程缓存的有效性。如果线程缓存的使用量较高,这可能意味着数据库在连接管理方面表现良好;反之,如果缓存利用率低,则可能需要调整 thread_cache_size 参数,以提升性能。此查询对于容量规划和资源优化尤其有用。
tenproary Object
tenporary
sum(rate(mysql_global_status_created_tmp_tables [$__interval]))
用于监控 MySQL 实例在特定时间窗口内创建的临时表的速率。以下是对该查询的详细分析:
-
mysql_global_status_created_tmp_tables:该指标表示 MySQL 自启动以来创建的临时表的总数。临时表通常在执行某些 SQL 查询(如 GROUP BY 和 ORDER BY)时使用,能够有效地处理中间结果。
-
rate() 函数:rate() 函数计算在指定时间窗口($interval)内的平均速率。它会返回在该时间段内每秒创建的临时表数量。例如,如果 $interval 为 5 分钟,rate() 会计算过去 5 分钟内每秒创建的临时表的平均数量。这个速率可以帮助监控系统在处理复杂查询时的性能表现。
-
sum() 函数:sum() 用于将符合条件的所有 MySQL 实例的临时表创建速率进行汇总,适用于多实例环境,能够提供整体视图。
sum(rate(mysql_global_status_created_tmp_disk_tables [$__interval]))
用于监控 MySQL 实例在特定时间窗口内创建的临时磁盘表的速率。以下是对该查询的详细分析:
-
mysql_global_status_created_tmp_disk_tables:该指标表示 MySQL 自启动以来创建的临时磁盘表的总数。临时磁盘表通常在处理复杂查询时生成,尤其是当内存中的临时表无法满足要求时,MySQL 会将其写入磁盘以存储中间结果。
-
rate() 函数:rate() 计算在指定时间窗口($interval)内的平均速率。它返回在该时间段内每秒创建的临时磁盘表数量。例如,如果 $interval 为 5 分钟,则 rate() 会计算过去 5 分钟内每秒创建的临时磁盘表的平均数量。这对于了解系统的查询性能和资源利用情况非常重要。
-
sum() 函数:sum() 用于汇总所有符合条件的 MySQL 实例中的临时磁盘表创建速率,适合多实例环境,为管理员提供整体视图。
监控临时磁盘表的创建速率可以帮助数据库管理员识别潜在的性能问题。频繁创建临时磁盘表可能表明 SQL 查询的设计不当、缺乏适当的索引或内存配置不足。这可能导致性能下降,因为磁盘 I/O 通常比内存访问慢。
Select types
sum(rate(mysql_global_status_select_full_join[$__interval]))
用于监控 MySQL 实例在特定时间窗口内执行的全连接查询的速率。以下是对该查询的详细分析:
-
mysql_global_status_select_full_join:此指标表示自 MySQL 启动以来执行的全连接查询的总数。全连接(Full Join)是指在两个表中返回所有行的连接,不论它们是否匹配。此查询通常在没有合适索引的情况下执行,可能导致性能问题。
-
rate() 函数:rate() 函数用于计算在指定时间窗口($interval)内的平均速率,返回在该时间段内每秒执行的全连接查询数量。例如,如果 $interval 为 5 分钟,则 rate() 会计算过去 5 分钟内每秒执行的全连接查询的平均数量。
-
sum() 函数:此函数用于将符合条件的所有 MySQL 实例的全连接查询速率进行汇总,以提供整体视图,特别适合于多实例环境。
监控全连接查询的执行速率对于数据库管理员来说非常重要,因为全连接通常会导致性能下降。频繁的全连接查询可能表明查询设计不佳或缺乏适当的索引。通过监控此指标,管理员可以识别潜在的性能问题并进行优化,例如优化 SQL 查询、增加索引或调整数据库设计。
sum(rate(mysql_global_status_select_range [$__interval]))
用于监控 MySQL 实例在特定时间窗口内执行的范围查询(Range Queries)的速率。以下是对该查询的详细分析:
-
mysql_global_status_select_range:此指标表示自 MySQL 启动以来执行的范围查询的总数。范围查询通常是指通过使用条件限制返回结果集的一部分,例如 WHERE 子句中的条件。在查询中使用索引可以提高范围查询的性能。
-
rate() 函数:rate() 函数计算在指定时间窗口($interval)内的平均速率,返回在该时间段内每秒执行的范围查询数量。例如,如果 $interval 为 5 分钟,则 rate() 会计算过去 5 分钟内每秒执行的范围查询的平均数量。
-
sum() 函数:此函数用于汇总所有符合条件的 MySQL 实例的范围查询速率,适合多实例环境,能够提供整体视图。
sum(rate(mysql_global_status_select_scan[$__interval]))
用于监控 MySQL 实例在特定时间窗口内执行的扫描查询(Scan Queries)的速率。以下是对该查询的详细分析:
-
mysql_global_status_select_scan:该指标表示自 MySQL 启动以来执行的扫描查询的总数。扫描查询通常是指没有使用索引,而是通过全表扫描来返回结果。全表扫描可能会导致性能下降,特别是在数据量较大的表中。
-
rate() 函数:rate() 函数计算在指定时间窗口($interval)内的平均速率,返回在该时间段内每秒执行的扫描查询数量。例如,如果 $interval 为 5 分钟,则 rate() 会计算过去 5 分钟内每秒执行的扫描查询的平均数量。
-
sum() 函数:该函数用于汇总所有符合条件的 MySQL 实例中的扫描查询速率,适合多实例环境,提供整体视图。
sorts
mysql sorts
sum(rate(mysql_global_status_sort_rows [$__interval]))
用于监控 MySQL 实例在特定时间窗口内排序的行数的速率。以下是对该查询的详细分析:
-
mysql_global_status_sort_rows:该指标表示自 MySQL 启动以来用于排序操作的行数总计。排序操作通常在执行查询时需要处理 ORDER BY 子句,或者在某些情况下使用 GROUP BY,涉及对大量数据的排序。
-
rate() 函数:rate() 函数计算在指定时间窗口($interval)内的平均排序行数的速率,返回在该时间段内每秒进行排序的行数。例如,如果 $interval 为 5 分钟,则 rate() 会计算过去 5 分钟内每秒进行排序的行数的平均数量。
-
sum() 函数:此函数用于汇总所有符合条件的 MySQL 实例中的排序行数的速率,适合多实例环境,提供整体视图。
-
mysql_global_status_sort_rows:
-
含义:表示自 MySQL 启动以来处理的排序行数总数。这反映了执行的排序操作的复杂性。
-
-
mysql_global_status_sort_scan:
-
含义:表示自 MySQL 启动以来执行的扫描排序的总次数。扫描排序发生在没有使用索引的情况下,通常会导致性能下降。
-
-
mysql_global_status_sort_range:
-
含义:表示自 MySQL 启动以来执行的范围排序的总次数。范围排序通常是指使用了范围条件的排序操作。
-
-
mysql_global_status_sort_merge_passes:
-
含义:表示自 MySQL 启动以来进行的合并排序操作的总次数。合并排序用于将多个结果集合并成一个最终结果,通常在处理大量数据时会发生。
-
-
排序性能:高的 sort_rows 和 sort_scan 数量可能表明查询没有有效利用索引,从而导致性能下降。
-
内存使用:高的 sort_merge_passes 表示 MySQL 在合并结果时可能需要更多的内存和计算资源。
-
查询优化:结合这些指标,数据库管理员可以识别需要优化的查询,确保使用适当的索引来减少不必要的扫描和排序操作。
slow queries
sum(rate(mysql_global_status_slow_queries[$__interval]))
用于监控特定时间窗口内慢查询的速率。以下是对该查询的详细分析:
-
mysql_global_status_slow_queries:此指标表示自 MySQL 启动以来执行的慢查询的总数。慢查询是指执行时间超过设定阈值的查询,这通常是在 MySQL 配置中指定的 long_query_time。
-
rate() 函数:该函数用于计算在指定时间窗口($interval)内每秒的慢查询速率。例如,如果 $interval 是 5 分钟,那么 rate() 会计算过去 5 分钟内每秒的慢查询平均数量。
aborted
connection
sum(rate(mysql_global_status_aborted_connects [$__interval]))
sum(rate(mysql_global_status_aborted_clients [$__interval]))
-
mysql_global_status_aborted_connects:
-
含义:表示自 MySQL 启动以来中止的连接总数。这通常是由于身份验证失败、用户未提供所需的参数或连接超时等原因引起的。
-
监控目的:高数量的中止连接可能表明存在安全问题(例如密码错误)或应用程序设计不当,可能需要优化连接池或身份验证机制。
-
-
mysql_global_status_aborted_clients:
-
含义:表示自 MySQL 启动以来中止的客户端总数。这通常是由于客户端在没有发送完整请求的情况下关闭连接引起的。
-
监控目的:高数量的中止客户端可能指示应用程序异常或用户操作不当,可能导致资源浪费。
-
table locks
sum(rate(mysql_global_status_table_locks_immediate [$__interval]))
sum(rate(mysql_global_status_table_locks_waited [$__interval]))
用于衡量表级锁的使用情况。以下是对这两个指标的详细分析及其在 Prometheus 中的查询。
-
mysql_global_status_table_locks_waited:
-
含义:表示自 MySQL 启动以来等待表锁的总次数。表锁用于防止多个事务对同一表的数据进行冲突性操作。
-
监控目的:高数量的等待表锁可能表明存在锁竞争,导致性能下降。这通常发生在高并发情况下,多个事务同时尝试访问同一表。
-
-
mysql_global_status_table_locks_immediate:
-
含义:表示自 MySQL 启动以来立即获取表锁的总次数。此指标表明在没有等待的情况下成功获取锁的情况。
-
监控目的:这个值与 table_locks_waited 结合使用,可以帮助评估锁的效率和事务的并发性。
-
network
mysql_global_status_bytes_received:
-
含义:表示自 MySQL 启动以来接收到的字节总数。此指标包括客户端发送给 MySQL 的所有查询和数据。
-
监控目的:可以帮助管理员评估流入 MySQL 数据库的数据量,了解应用程序与数据库之间的交互频率和数据传输量。
mysql_global_status_bytes_sent:
-
含义:表示自 MySQL 启动以来发送给客户端的字节总数。此指标包括 MySQL 返回给客户端的结果集和状态信息。
-
监控目的:可以帮助管理员了解 MySQL 向客户端传输数据的量,反映查询的复杂度和结果集的大小。
memory
通过计算总的 InnoDB 数据页大小,数据库管理员可以:
-
评估缓冲池的使用效率:了解当前使用的内存量与设定的缓冲池大小的比例。
-
监测性能瓶颈:如果数据页数量过多而缓冲池大小不够,可能导致性能下降,这时可能需要调整缓冲池大小或优化查询。
command,handlers
command
topk(5,rate(mysql_global_status_commands_total[$__interval])>0)
用于获取执行 MySQL 命令的速率,并返回速率最高的前五个命令
rate(...):计算 mysql_global_status_commands_total 指标在给定时间间隔($__interval)内的速率。此指标表示自 MySQL 启动以来已执行的命令总数。
{job=~"$job", instance=~"$instance"}:使用正则表达式匹配特定的作业和实例,以便从监控数据中筛选出相应的指标。
> 0:过滤条件,只返回执行次数大于零的命令。
topk(5, ...):从计算出的速率中返回前五个最大值。即找出最活跃的五个 MySQL 命令。
handlers
rate(mysql_global_status_handlers_total{handler!~"commit|rollback|savepoint.|prepare"}[$__interval]) or irate(mysql_global_status_handlers_total{handler!~"commit|rollback|savepoint.|prepare"}[5m])
该 Prometheus 查询用于监控 MySQL 的处理器指标,重点关注与事务无关的处理器(如提交、回滚、保存点和准备的处理器)
rate(...):计算在给定时间窗口($__interval)内的速率,表示每秒的处理器调用次数。这是一个用于计算时间序列数据变化率的函数,适合监控指标。
mysql_global_status_handlers_total:这是一个表示自 MySQL 启动以来各种处理器调用总数的指标。处理器通常指不同类型的查询或操作的统计。
{instance=~"$host", handler!~"commit|rollback|savepoint.*|prepare"}:
-
instance=~"$host":通过正则表达式匹配特定的 MySQL 实例。
-
handler!~"commit|rollback|savepoint.*|prepare":过滤掉与事务相关的处理器。这意味着只关注非事务性操作的处理器。
or:表示如果第一个 rate 查询没有返回结果,将使用 irate 查询的结果。
irate(...):计算在过去 5 分钟内的即时速率,适用于更短时间内的快速变化监测。适合捕捉突发事件。
相关文章:
Prometheus结合K8s(二)使用
上一篇介绍了如何搭建 Prometheus结合K8s(一)搭建-CSDN博客,这章介绍使用 页面访问 kubectl get svc -n prom 看promeheus和granfana的端口访问页面 Prometheus 点击status—target,可以看到metrics的数据来源,即各…...

【虚幻引擎】UE5数字人开发实战教程
本套课程将会交大家如何去开发属于自己的数字人,包含大模型接入,流式输出,语音识别,语音合成,口型驱动,动画蓝图,语音唤醒等功能。 课程介绍视频如下: 【虚幻引擎】UE5 历时一个多月…...

深入分析:固定参考框架在RViz中的作用与对数据可视化的影响 ros ubuntu20.04
深入分析:固定参考框架在RViz中的作用与对数据可视化的影响 RViz (Robot Visualization) 是 ROS (Robot Operating System) 中一种重要的三维可视化工具,主要用于实时观察和分析传感器数据、机器人状态信息以及环境模型。RViz的核心功能之一是固定参考框…...

Android:时间选择器(最下面有效果图)
1.创建DateUtil类 /*** Created by wangshuai on 2024/11/19.*/ public class DateUtil {public final static String PATTERN_ALL"yyyy-MM-dd HH:mm:ss";public final static String PATTERN_DEFAULT"yyyy-MM-dd";/*** 获取当前时间* return yyyy-MM-dd*…...
-c++/c)
第十六届蓝桥杯模拟赛(第一期)-c++/c
c/c蓝桥杯模拟赛题解,非常详细 质因数 1、填空题 【问题描述】 如果一个数 p 是个质数,同时又是整数 a 的约数,则 p 称为 a 的一个质因数。 请问 2024 有多少个质因数。 【答案提交】 这是一道结果填空的题,你只需要算出结果后提…...

如何挑选路由器?需要看哪些参数?
挑选路由器时,选择合适的型号和参数对于确保家庭或办公网络的速度、稳定性和覆盖范围至关重要。以下是挑选路由器时需要考虑的关键参数和因素: 1. 无线标准 (Wi-Fi标准) 无线标准是衡量路由器性能的核心指标。不同的无线标准提供不同的速率、范围和技术…...

mysql-备份(二)
前章介绍了MySQL的内部数据结构btree,这章讲述mysql的备份 1:环境 ubuntu22.04 LST mysql5.7.42 or win10 mysql5.7.44 (这里图简单直接windows部署) download:https://downloads.mysql.com/archives/community/ 2:install 1> unzip mysql-5.7.44-w…...

Tailwind CSS 和 UnoCSS简单比较
UnoCSS 和 Tailwind CSS 都是流行的原子化 CSS 框架,但它们在设计理念、性能和使用方式上有一些重要的区别。下面是对它们的详细对比: 1. 概述 Tailwind CSS:Tailwind 是一个原子化的 CSS 框架,提供了大量的预定义类(…...

unity3d————范围检测
目录 知识点一:什么是范围检测 知识点二:如何进行范围检测 问题: Physics.queriesHitTriggers 怎么查看是不是true? QueryTriggerInteraction.UseGlobal 参数意味着是否检测触发器将依据全局设置 Physics.queriesHitTrigge…...

修改this.$confirm的按钮位置、图标、文字及标题
在Vue.js项目中,this.$confirm 通常是基于某些UI库(如Element UI或Ant Design Vue)的对话框确认方法。 以下是基于Element UI的this.$confirm的用法示例。 在此之前,你的项目要已经安装了Element UI,如果没安装话就打…...
 函数详解)
SQL MID() 函数详解
SQL MID() 函数详解 SQL 中的 MID() 函数是一个非常有用的字符串处理工具,它允许用户从字符串中提取特定位置的子字符串。这个函数在数据库查询和报告中特别有用,尤其是在需要从较长的文本字段中提取特定信息时。本文将详细介绍 MID() 函数的用法、参数…...
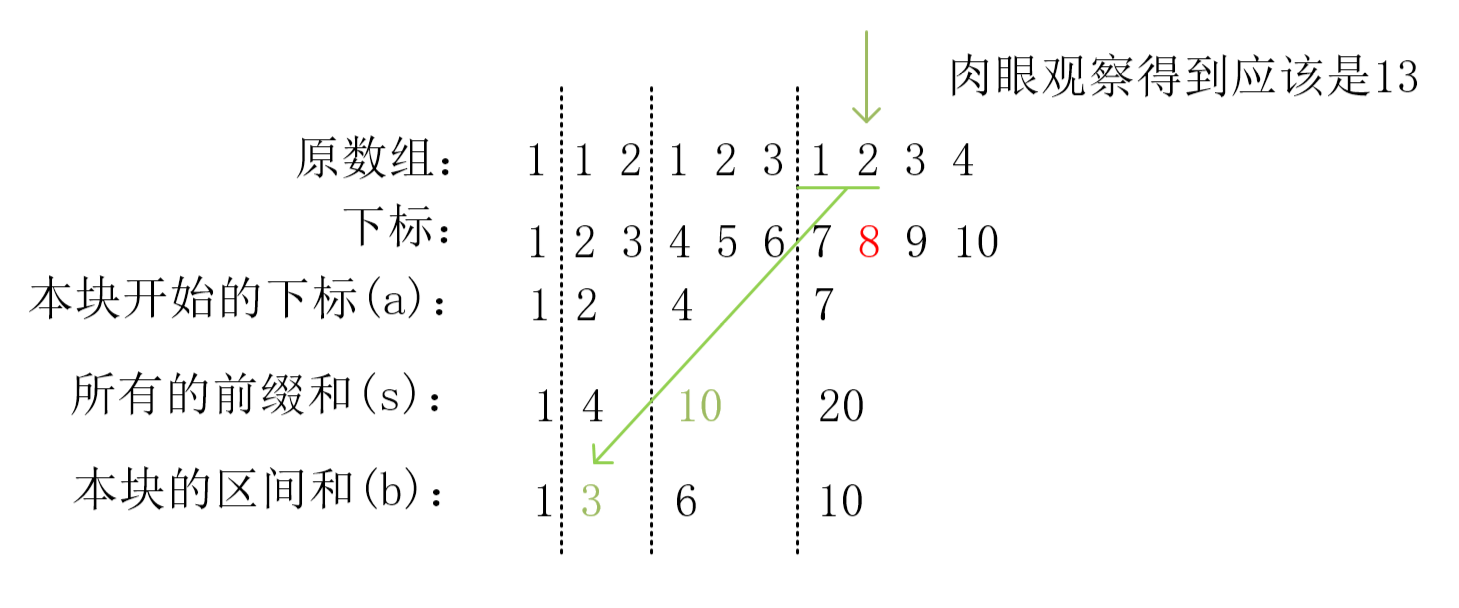
【蓝桥杯备赛】123(前缀和的复杂应用)
5. 前缀和的复杂应用 5.1. 123(4 星) 5.1.1. 题目解析 这道题仍然是求一段区间的和,很容易能够想到前缀和找规律: 1------------------1 号块 1 2----------------2 号块 1 2 3--------------3 号块 1 2 3 4------------4 号…...

MINES
MINES (m)6A (I)dentification Using (N)anopor(E) (S)equencing Tombo(v1.4) 命令在 MINES 之前执行: (仅在 fast5 文件中尚未包含 fastq 时需要) tombo preprocess annotate_raw_with_fastqs --fast5-basedir /fast5_dir/ --fastq-file…...

H.265流媒体播放器EasyPlayer.js H5流媒体播放器关于如何查看手机端的日志信息并保存下来
现今流媒体播放器的发展趋势将更加多元化和个性化。人工智能的应用将深入内容创作、用户体验优化等多个方面,带来前所未有的个性化体验。 EasyPlayer.js H.265流媒体播放器属于一款高效、精炼、稳定且免费的流媒体播放器,可支持多种流媒体协议播放&#…...
uni-app快速入门(十一)--常用JS API(上)
在前面学习了uni-app的布局、组件、路由等知识点以后,还要掌握uni-app的JS API ,也可以理解为基于uni-app的java script。本节介绍uni-app的request请求、文件上传、数据缓存、获取位置、获取系统信息、获取手机的网络状态、拨打电话API。 一、request请求 使用uni…...

Flink任务提交到yarn上slot数量为0的问题
现象:Flink提交到yarn上slot数量为0的问题 解决方法: 参考论坛上的方案,修改flink-conf.yaml文件都不管用 最终解决方法: $FLINK_HOME/lib 路径下有2个非.jar结尾的文件,把这几个文件移走之后,再启就可…...

vue3怎么根据字符串获取组件实例
例子: 我在使用vue2开发的时候,定义了一个方法 handler(strRef){ this.$refs[strRef].innerText hello world }, 我在点击某个按钮的时候,调用了方法handler,传递了一个参数是字符串 condition,然后方法…...

ISUP协议视频平台EasyCVR私有化视频平台新能源汽车充电停车管理方案的创新与实践
在环保意识提升和能源转型的大背景下,新能源汽车作为低碳出行的选择,正在全球迅速推广。但这种快速增长也引发了充电基础设施短缺和停车秩序混乱等挑战,特别是在城市中心和人口密集的居住区,这些问题更加明显。因此,开…...

智领未来: 宏集物联网HMI驱动食品与包装行业迈向智能化新高度
行业现状与挑战 食品与包装行业对设备的自动化、智能化水平要求日益提高,特别是瓶装和灌装生产线需要实现高速、高效的生产。此外,该行业还需遵循严格的卫生标准和安全规范,以保证产品质量符合消费者需求。在提高生产效率的同时,…...

redis-击穿、穿透、雪崩
击穿、穿透、雪崩经常听人说吧? 那他到底是啥呢?无非就是在有缓存层的情况下,对各种绕过缓存层从而直接落到了DB上的情况进行的分类。 概念性的东西大概如下,我是记不住,后期具体使用与规避这些问题才是大事ÿ…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...
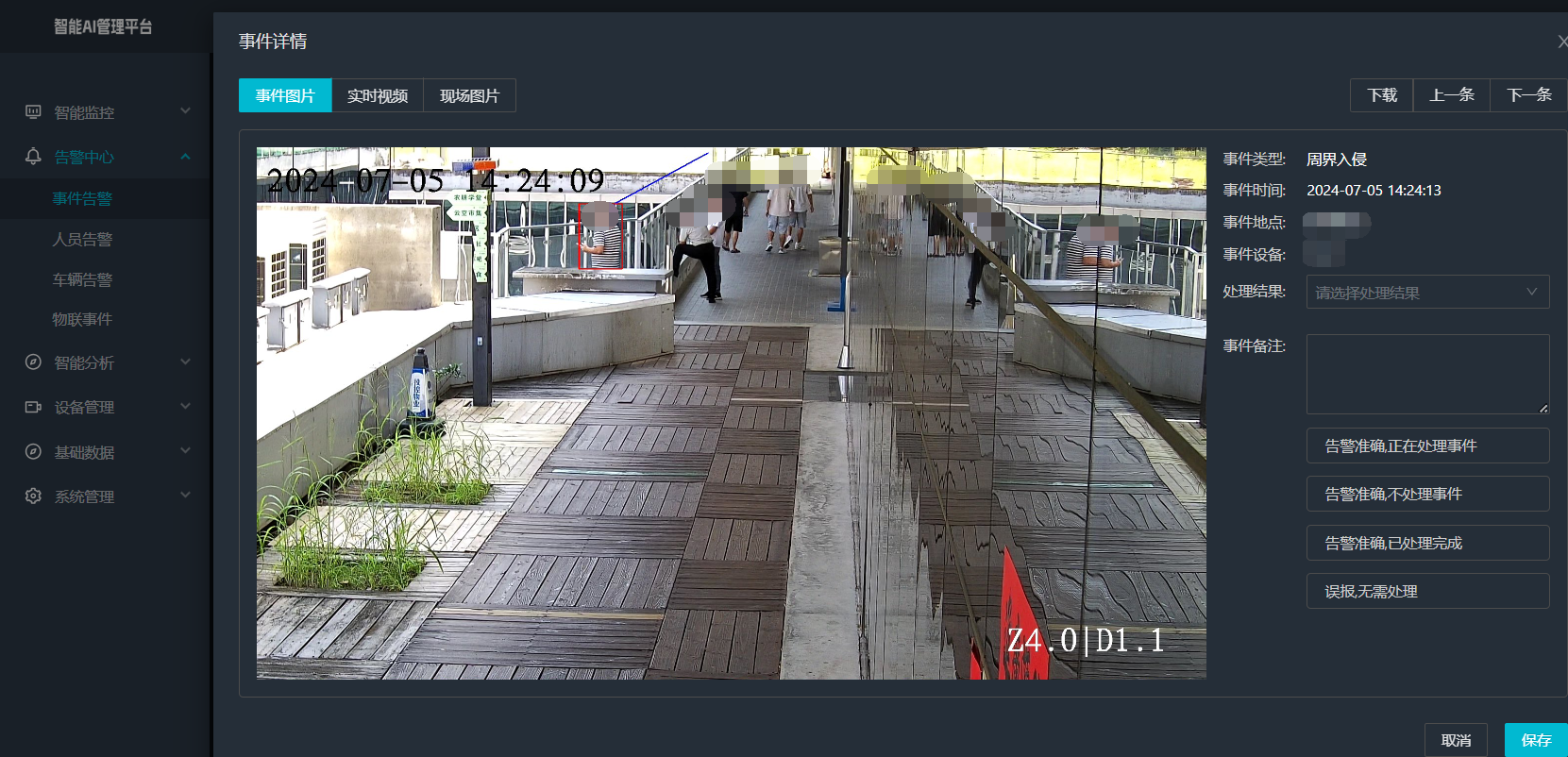
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...