Spark SQL大数据分析快速上手-完全分布模式安装
【图书介绍】《Spark SQL大数据分析快速上手》-CSDN博客
《Spark SQL大数据分析快速上手》【摘要 书评 试读】- 京东图书
大数据与数据分析_夏天又到了的博客-CSDN博客
Hadoop完全分布式环境搭建步骤-CSDN博客,前置环境安装参看此博文
完全分布模式也叫集群模式。将Spark目录文件分发到其他主机并配置workers节点,即可快速配置Spark集群(需要先安装好JDK并配置好从Master到Worker的SSH信任)。具体步骤 如下:
【免费送书活动】《Spark SQL大数据分析快速上手》-CSDN博客
步骤1: 配置计划表。
集群主机配置如表2-1所示。所有主机在相同目录下安装JDK,Spark安装到所有主机的相同目录下,如/app/。

步骤2: 准备3台Linux虚拟机搭建集群环境。
这里推荐直接使用下面链接讲解的、配置好的Hadoop完全分布式环境,稍微做些修改,即可快速搭建Spark完全分布模式环境。
Hadoop完全分布式环境搭建步骤_hadoop 开发环境搭建及hdfs初体验-CSDN博客
步骤3: 解压并配置Spark。
在server101上解压Spark:
$ tar -zxvf ~/spark-3.3.1-bin-hadoop3.tgz -C /app/$ mv spark-3.3.1-bin-hadoop3 spark-3.3.1修改spark-env.sh文件,在文件最开始添加JAVA_HOME环境变量:
$ vim /app/spark-3.3.1/sbin/spark-conf.shexport JAVA_HOME=/usr/java/jdk1.8.0-361修改worker文件,添加所有主机在worker节点上的名称:
$ vim /app/spark-3.3.1/conf/workersserver101server102server103使用scp将Spark目录分发到所有主机相同的目录下:
$ scp -r /app/spark-3.3.1 server102:/app/$ scp -r /app/spark-3.3.1 server103:/app/步骤4: 启动Spark。
在主Spark上执行start-all.sh:
$ /app/spark-3.3.1/sbin/start-all.sh
启动完成以后,查看master主机的8080端口,如图2-8所示。
步骤5: 测试。
由于已经配置了Hadoop集群,并且与Spark的worker节点在相同的主机上,因此在集群环境下,一般是访问HDFS上的文件:
$spark-shell --master spark://server101:7077scala> val rdd1 = sc.textFile(“hdfs://server101:8082/test/a.txt”);
图2-8 master主机的8080端口
将结果保存到HDFS,最后查看HDFS上的计算结果即可:
scala> rdd1.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_). saveAsTextFile("hdfs://server101:8020/out004");
相关文章:
Spark SQL大数据分析快速上手-完全分布模式安装
【图书介绍】《Spark SQL大数据分析快速上手》-CSDN博客 《Spark SQL大数据分析快速上手》【摘要 书评 试读】- 京东图书 大数据与数据分析_夏天又到了的博客-CSDN博客 Hadoop完全分布式环境搭建步骤-CSDN博客,前置环境安装参看此博文 完全分布模式也叫集群模式。将Spark目…...

Java面试题2024-Java基础
Java基础 1、 Java语言有哪些特点 1、简单易学、有丰富的类库 2、面向对象(Java最重要的特性,让程序耦合度更低,内聚性更高) 3、与平台无关性(JVM是Java跨平台使用的根本) 4、可靠安全 5、支持多线程 2、…...

局域网协同办公软件,2024安全的协同办公软件推荐
在2024年,随着数字化转型的深入和远程工作需求的增加,协同办公软件已成为企业提升工作效率、优化沟通流程的重要工具。 以下是一些值得推荐的安全的协同办公软件: 钉钉 功能全面:钉钉是一款综合性极强的企业级协同软件ÿ…...

osg、osgearth简介及学习环境准备
一、osg简介(三维场景图渲染与调度引擎) OSG是Open Scene Graphic 的缩写,OSG于1997年诞生于以为滑翔机爱好者之手,Don burns 为了对滑翔机的飞行进行模拟,对openGL的库进行了封装,osg的雏形就这样诞生了&…...

nodejs基于微信小程序的云校园的设计与实现
摘 要 相比于传统的校园管理方式,智能化的管理方式可以大幅提高校园的管理效率,实现了云校园管理的标准化、制度化、程序化的管理,有效地防止了云校园信息的不规范管理,提高了信息的处理速度和精确度,能够及时、准确地…...
uni-app快速入门(十)--常用内置组件(下)
本文介绍uni-app的textarea多行文本框组件、web-view组件、image图片组件、switch开关组件、audio音频组件、video视频组件。 一、textarea多行文本框组件 textarea组件在HTML 中相信大家非常熟悉,组件的官方介绍见: textarea | uni-app官网uni-app,un…...

golang基础
在 Go 中字符串是不可变的,例如下面的代码编译时会报错: cannot assign to s[0] 但如果真的想要修改怎么办呢?下面的代码可以实现: var s string "hello" s [ 0 ] c s : "hello" c : [] b…...

Selenium + 数据驱动测试:从入门到实战!
引言 在软件测试中,测试数据的多样性和灵活性对测试覆盖率至关重要。而数据驱动测试(Data-Driven Testing)通过将测试逻辑与数据分离,极大地提高了测试用例的可维护性和可扩展性。本文将结合Selenium这一流行的测试工具࿰…...

LLaMA与ChatGLM选用比较
目录 1. 开发背景 2. 目标与应用 3. 训练数据 4. 模型架构与规模 5. 开源与社区支持 6. 对话能力 7. 微调与应用 8. 推理速度与资源消耗 总结 LLaMA(Large Language Model Meta AI)和 ChatGLM(Chat Generative Language Model)都是强大的大型语言模型,但它们有一…...

GPTZero:高效识别AI生成文本,保障学术诚信与内容原创性
产品描述 GPTZero 是一款先进的AI文本检测工具,专为识别由大型语言模型(如ChatGPT、GPT-4、Bard等)生成的文本而设计。它通过分析文本的复杂性和一致性,判断文本是否可能由人类编写。GPTZero 已经得到了超过100家媒体机构的报道&…...

C/C++ 优化,strlen 示例
目录 C/C optimization, the strlen examplehttps://hallowed-blinker-3ca.notion.site/C-C-optimization-the-strlen-example-108719425da080338d94c79add2bb372 揭开优化的神秘面纱... 让我们来谈谈 CPU 等等,SIMD 是什么? 为什么 strlen 是一个很…...

【动手学深度学习Pytorch】1. 线性回归代码
零实现 导入所需要的包: # %matplotlib inline import random import torch from d2l import torch as d2l import matplotlib.pyplot as plt import matplotlib import os构造人造数据集:假设w[2, -3.4],b4.2,存在随机噪音&…...

深入理解PyTorch中的卷积层:工作原理、参数解析与实际应用示例
深入理解PyTorch中的卷积层:工作原理、参数解析与实际应用示例 在PyTorch中,卷积层是构建卷积神经网络(CNNs)的基本单元,广泛用于处理图像和视频中的特征提取任务。通过卷积操作,网络可以有效地学习输入数…...

DataGear 5.2.0 发布,数据可视化分析平台
DataGear 企业版 1.3.0 已发布,欢迎体验! http://datagear.tech/pro/ DataGear 5.2.0 发布,图表插件支持定义依赖库、严重 BUG 修复、功能改进、安全增强,具体更新内容如下: 重构:各模块管理功能访问路径…...

uniapp: vite配置rollup-plugin-visualizer进行小程序依赖可视化分析减少vender.js大小
一、前言 在之前文章《uniapp: 微信小程序包体积超过2M的优化方法(主包从2.7M优化到1.5M以内)》中,提到了6种优化小程序包体积的方法,但并没有涉及如何分析common/vender.js这个文件的优化,而这个文件的大小通常情况下…...

深度学习:如何复现神经网络
深度学习:如何复现神经网络 要复现图中展示的卷积神经网络(CNN),我们需详细了解和配置每层网络的功能与设计理由。以下将具体解释各层的配置以及设计选择的原因,确保网络设计的合理性与有效性。 详细的网络层配置与设…...

Spring Boot与MyBatis-Plus的高效集成
Spring Boot与MyBatis-Plus的高效集成 引言 在现代 Java 开发中,MyBatis-Plus 作为 MyBatis 的增强工具,以其简化 CRUD 操作和无需编写 XML 映射文件的特点,受到了开发者的青睐。本篇文章将带你一步步整合 Spring Boot 与 MyBatis-Plus&…...

【Unity ShaderGraph实现流体效果之Function入门】
Unity ShaderGraph实现流体效果之Node入门(一) 前言Shader Graph NodePosition NodeSplit NodeSubtract NodeBranch Node 总结 前言 Unity 提供的Shader Graph在很大程度上简化了开发者对于编写Shader的工作,只需要拖拽即可完成一个视觉效果…...

Spark RDD sortBy算子执行时进行数据 “采样”是什么意思?
一、sortBy 和 RangePartitioner sortBy 在 Spark 中会在执行排序时采用 rangePartitioner 进行分区,这会影响数据的分区方式,并且这一步骤是通过对数据进行 “采样” 来计算分区的范围。不过,重要的是,sortBy 本身仍然是一个 tr…...

React-useRef与DOM操作
#题引:我认为跟着官方文档学习不会走歪路 ref使用 组件重新渲染时,react组件函数里的代码会重新执行,返回新的JSX,当你希望组件“记住”某些信息,但又不想让这些信息触发新的渲染时,你可以使用ref&#x…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...
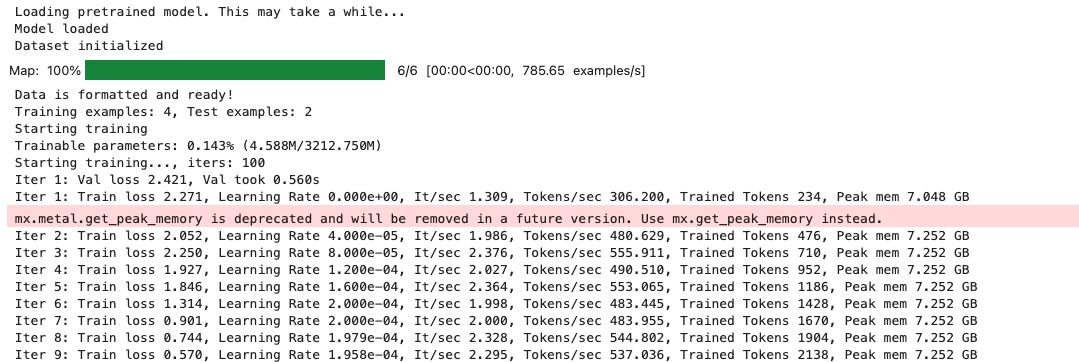
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...