基于python的机器学习(三)—— 关联规则与推荐算法
目录
一、关联规则挖掘
1.1 基本概念
1.2 Apriori算法
1.2.1 Apriori算法的原理
1.2.2 Apriori算法的实例
1.2.3 Apriori算法的程序实现(efficient-apriori模块)
1.3 FP-Growth算法
1.3.1 FP-Growth算法的原理
1.3.2 FP-Growth算法的实例
二、推荐系统及算法
2.1 协调过滤推荐算法
2.1.1 两种协调过滤推荐算法
2.1.2 协同过滤推荐算法的优缺点
2.1.3 协同过滤推荐算法实例
一、关联规则挖掘
关联规则挖掘(Association Rule Mining)是一种常用的数据挖掘技术,用于发现数据集中项集之间的关联关系。关联规则通常用于市场篮子分析,可以发现在消费者购买商品时,某些项集的购买行为之间的相关性。
关联规则由两个部分组成:前项和后项。前项表示规则的前提条件,后项表示规则的结论。关联规则的形式如下:
X → Y其中,X和Y分别表示项集,用{item1, item2, ...}表示,箭头表示两个项集之间的关联关系。
1.1 基本概念
在关联规则挖掘中,常用的指标有支持度和置信度。支持度衡量一个规则在数据集中出现的频率,置信度衡量一个规则在给定前项的条件下出现的概率。
关联规则挖掘的算法包括Apriori算法和FP-growth算法。Apriori算法通过迭代方式生成候选项集,并利用剪枝策略来减少计算量。FP-growth算法通过构建频繁模式树来高效地发现频繁项集。
关联规则中的基本概念如下:
- 项与项集:数据库中不可分割的最小信息单位(即记录)称为项(或项目),用符号 i 表示,项的集合称为项集。设集合 I = { i1,i2,...,ik }为项集,I 中项的个数为 k,则集合 I 称为 k-项集。例如,集合 {啤酒,尿布,奶粉}是一个 3-项集,而奶粉就是一个项。
- 事务:每一个事务都是一个项集。设 I = { i1,i2,...,ik } 是由数据库中所有项构成的全集,则每一个事务 ti 对应的项集都是 I 的子集。事务数据库 T = { t1,t2,...,tk } 是由一系列具有唯一标识的事务组成的集合。例如,如果把超市中的所有商品看成 I ,则每个顾客每张小票中的商品集合就是一个事务,很多顾客的购物小票就构成一个事务数据库。
- 项集的频数:包含某个项集的事务在事务数据库中出现的次数称为项集的频数。例如,事务数据库中有且仅有 3 个事务 t1 = { 啤酒,奶粉 } 、t2 = { 啤酒,尿布,奶粉,面包} 、t3 = { 啤酒,尿布,奶粉} ,它们都包含了项集 I1 = {啤酒,奶粉} ,则称项集 I1 的频数为 3 ,项集的频数代表了支持度计数。
- 关联规则:关联规则由两部分组成:前项(Antecedent)和后项(Consequent)。前项是规则的条件部分,后项是规则的结果部分。关联规则的形式通常为A -> B,表示当某个事物或事件发生时,会伴随着另一个事物或事件的发生。
- 支持度:支持度(support)是指某一规则在数据集中出现的频率。支持度越高,表示该规则在数据集中出现的频率越高,反之则表示规则的出现频率较低。支持度可以通过以下公式计算: 支持度 = (规则出现次数) / (总记录数)
- 置信度:置信度是衡量规则强度的指标之一,表示在前提条件成立的情况下,后续事件发生的概率。置信度的计算公式为: 置信度 = 支持度(前提条件和后续事件同时发生的次数)/ 支持度(前提条件发生的次数)。
- 最小支持度与最小置信度:
- 最小支持度(Minimum Support)是指在关联规则挖掘中,一个频繁项集中的项出现的最小次数或比例。支持度是指项集在所有交易中出现的频率,通常用百分比来表示。最小支持度用来筛选出频繁项集,即在所有交易中出现次数超过最小支持度的项集。
- 最小置信度(Minimum Confidence)是指在关联规则挖掘中,一个关联规则的可信度不低于的最小值。置信度是指关联规则的条件项和结论项同时出现的频率与条件项出现的频率之比。最小置信度用来筛选出具有一定可信度的关联规则。
- 强关联规则:一条关联规则可以表示为A -> B,其中A和B分别称为前项(Antecedent)和后项(Consequent),表示两个项集之间的关联关系。置信度是指在前项出现的情况下,后项也出现的概率,可以表示为P(B|A)。如果置信度高于设定的阈值,那么这条关联规则就被认为是强关联规则。
- 频繁项集:频繁项集是指在一个数据集中,经常同时出现的一组项目的集合。频繁项集可以用于发现数据集中的潜在关联规则。确定一个项集是否是频繁项集,需要计算它在整个数据集中的支持度。
1.2 Apriori算法
Apriori算法是一种用于挖掘频繁项集和关联规则的算法。它是由Agrawal和Srikant于1994年提出的。
1.2.1 Apriori算法的原理
Apriori算法的基本原理是利用频繁项集的性质,通过迭代的方式逐渐生成更大的频繁项集,然后再使用这些频繁项集来发现关联规则。

Apriori算法的执行过程如下:
-
扫描事务数据库,统计每个项的支持度,并根据设定的最小支持度阈值找出所有的频繁1项集。
-
根据频繁1项集,生成候选2项集,即由两个频繁1项集组合而成的项集。再次扫描事务数据库,统计候选2项集的支持度,并根据设定的最小支持度阈值找出所有的频繁2项集。
-
以此类推,根据频繁k-1项集,生成候选k项集,并找出所有的频繁k项集,直到无法再生成更大的频繁项集为止。
-
根据频繁项集,生成关联规则。对于频繁项集中的每个项,将其拆分成左部和右部,然后计算关联规则的置信度。筛选出满足设定的最小置信度阈值的关联规则。
Apriori算法具有以下优点和缺点:
优点:
- 简单易懂,容易实现。
- 通过剪枝操作,减少了候选项集的生成和计数的数量,提高了算法的效率。
缺点:
- 需要多次扫描事务数据库,对于大规模数据集,性能较差。
- 生成大量的候选项集,会占用大量的内存空间。
1.2.2 Apriori算法的实例
我们想要利用Apriori算法找出频繁项集。假设我们的销售记录如下:
Transaction 1: {牛奶, 尿布, 面包, 鸡蛋}
Transaction 2: {牛奶, 啤酒, 尿布}
Transaction 3: {牛奶, 面包, 啤酒, 尿布}
Transaction 4: {牛奶, 面包, 可乐, 啤酒}
Transaction 5: {尿布, 面包, 可乐}现在我们来使用Apriori算法找出频繁项集。
1.2.3 Apriori算法的程序实现(efficient-apriori模块)
efficient-apriori是一个python模块,用于频繁项集挖掘和关联规则生成。它实现了Apriori算法的高效版本,能够快速地从大规模数据集中找出频繁项集,并根据设置的最小置信度生成关联规则。
使用efficient-apriori模块可以实现以下功能:
- 从给定的数据集中找出频繁项集
- 根据最小置信度生成关联规则
- 设置最小支持度和最小置信度的阈值
- 控制最大项集大小
- 支持多线程运算,加快处理速度
安装efficient-apriori模块: 在终端或命令行中运行以下命令安装:
pip install efficient-apriori使用efficient-apriori模块示例代码:
from efficient_apriori import apriori# 定义数据集
data = [('牛奶', '面包', '尿布'),('可乐', '面包', '尿布', '啤酒'),('牛奶', '尿布', '啤酒', '鸡蛋'),('可乐', '面包', '牛奶', '尿布'),('面包', '牛奶', '尿布', '啤酒')]# 执行Apriori算法
itemsets, rules = apriori(data, min_support=0.5, min_confidence=0.7)# 输出频繁项集
print(itemsets)# 输出关联规则
for rule in rules:print(rule)
运行结果:

更多详细信息和用法示例可以参考efficient-apriori的官方文档:efficient-apriori · PyPI
1.3 FP-Growth算法
FP-Growth算法是一种用于频繁项集挖掘的算法。它通过构建一种称为FP树的数据结构,来高效地发现数据集中的频繁项集。
FP-Growth算法的优点:
- FP-Growth算法采用了基于频繁项集的数据结构FP树来高效地挖掘频繁项集,相对于传统的Apriori算法,可以大大减少扫描数据库的次数,提高了算法的效率。
- FP-Growth算法将数据集转化为FP树的过程只需要两次扫描数据库,因此对于大规模的数据集来说,可以减少I/O操作,进一步提升了算法的效率。
- FP-Growth算法可以发现所有的频繁项集,不仅能够挖掘出频繁项集,还可以挖掘出关联规则。
- FP-Growth算法具有很强的可扩展性,可以应用于大规模的数据挖掘任务。
FP-Growth算法的缺点:
- FP-Growth算法在构建FP树的过程中需要使用大量的内存来存储FP树,因此对于较大的数据集来说,可能会导致内存不足的问题。
- FP-Growth算法在构建FP树的过程中需要进行多次遍历数据集,因此对于处理大规模数据集来说,可能会占用较长的时间。
- FP-Growth算法只能用于处理离散型数据,对于连续型数据需要进行离散化处理才能使用。
- FP-Growth算法在某些情况下可能会产生过多的频繁项集,导致关联规则过多和冗余,需要进行进一步的剪枝操作。
1.3.1 FP-Growth算法的原理
FP-Growth算法的流程如下:
- 构建频繁模式树:首先扫描数据库,统计每个项的支持计数。然后,根据支持计数对项进行排序,并且移除不满足最小支持阈值的项。接下来,根据数据集的频繁项集顺序,构建频繁模式树。
- 构建条件模式基:通过对每个频繁项的条件模式基进行递归,构建条件模式树。条件模式基是指给定频繁项的前缀路径。
- 递归地挖掘频繁项集:从频繁模式树的叶节点开始,逐层遍历树的节点,生成频繁项集。
在FP-Growth算法中,频繁模式树是一种紧凑的数据结构,能够有效地存储和处理大规模数据集。它的每个节点都表示一个频繁项,节点的链接指向具有相同项的下一个节点。通过频繁模式树的构建和频繁项集的递归挖掘,FP-Growth算法能够高效地发现频繁项集。
1.3.2 FP-Growth算法的实例
下面是一个使用 FP-Growth 算法的实例:
假设有一个交易数据库,包含了多个交易记录,每个交易记录是一个物品集合。我们想要寻找频繁模式,即经常一起出现的物品集合。
交易数据库如下所示:
Transaction 1: {A, B, C, D}
Transaction 2: {A, B, D}
Transaction 3: {B, C}
Transaction 4: {A, E}
首先,我们统计每个物品的频率,得到以下频繁项集:
A: 3
B: 3
C: 2
D: 2
E: 1
然后,根据频率对物品进行排序,得到排序后的频繁项集:
[A, B, C, D, E]
接着,我们构建 FP 树:
- 创建一个空的根节点。
- 对每个事务记录进行处理:
- 对于每个物品,按照频率排序后的顺序添加到树中。
- 如果物品已经存在于树中的某个节点的子节点中,则增加该节点的计数。
- 否则,创建一个新节点,并将其添加为当前节点的子节点。
- 删除树中的非频繁项,得到以下 FP 树:
null |A/ | \B C E/ \ D F
接下来,我们利用 FP 树来寻找频繁模式:
- 从频繁项集中选择一项作为条件模式基,以该项为后缀的路径构成一个条件模式基。
- 对于每个条件模式基,构建条件 FP 树。
- 在条件 FP 树上递归应用 FP-Growth 算法,直到找到所有的频繁项集。
在上述例子中,以频繁项集 [A] 为条件模式基,可以得到以下条件 FP 树:
null |B/ \ D F
然后,从条件 FP 树中寻找频繁项集,得到以下频繁项集:
[A, B]: 2
[A, B, D]: 1
同样地,以频繁项集 [B] 为条件模式基,可以得到以下条件 FP 树:
null |D
从条件 FP 树中寻找频繁项集,得到以下频繁项集:
[B, D]: 1
最后,我们可以得到所有的频繁模式:
[A]: 3
[B]: 3
[C]: 2
[D]: 2
[E]: 1
[A, B]: 2
[A, B, D]: 1
[B, D]: 1
或

二、推荐系统及算法
推荐系统是一种根据用户的兴趣和行为,向用户推荐他们可能感兴趣的内容或产品的技术。推荐系统广泛应用于电子商务、社交媒体、新闻媒体和音乐流媒体等领域。
推荐系统的算法可以分为以下几种:
-
基于内容的推荐算法:根据用户对物品的历史行为和对物品的内容特征进行推荐。例如,根据用户对电影的历史评分记录和电影的类型、导演等内容特征,推荐给用户可能喜欢的电影。
-
协同过滤算法:基于用户与物品的相似性来推荐物品。分为两种类型,一种是基于用户的协同过滤算法,根据用户之间的行为相似性来推荐物品;另一种是基于物品的协同过滤算法,根据物品之间的相似性来推荐物品。
-
矩阵分解算法:将用户和物品的关系表示为一个矩阵,通过对矩阵进行分解,得到用户和物品的低维度表示,从而进行推荐。
-
深度学习算法:使用神经网络等深度学习模型来进行推荐。深度学习算法可以学习到更复杂的用户和物品的表示,从而提高推荐的准确性。
-
基于规则的推荐算法:根据预先定义的规则或规则库,来推荐物品。例如,根据用户的购买历史和用户的个人信息等规则,来推荐商品。
2.1 协调过滤推荐算法
协调过滤推荐算法(Collaborative Filtering Recommendation Algorithm)是一种基于用户行为数据的推荐算法,它通过分析用户历史行为数据,比如购买记录、评分数据、浏览记录等,找到与当前用户兴趣相似的其他用户或物品,并根据这些相似性来预测用户对未知物品的喜好程度。
2.1.1 两种协调过滤推荐算法
下面介绍两种常见的协调过滤推荐算法:
-
基于用户的协调过滤推荐算法(User-based Collaborative Filtering): 基于用户的协调过滤推荐算法通过计算用户之间的相似度来进行推荐。算法的步骤如下:
- 计算用户之间的相似度:可以使用余弦相似度或皮尔森相似度等方法来计算用户之间的相似度。
- 根据相似度找到相似用户:对于目标用户,找到与其相似度最高的用户。
- 推荐给目标用户未曾观看过的物品:根据相似用户的行为,推荐目标用户未曾观看过的物品。
-
基于物品的协调过滤推荐算法(Item-based Collaborative Filtering): 基于物品的协调过滤推荐算法通过计算物品之间的相似度来进行推荐。算法的步骤如下:
- 计算物品之间的相似度:可以使用余弦相似度或皮尔森相似度等方法来计算物品之间的相似度。
- 根据相似度找到相似物品:对于用户历史行为中的某个物品,找到与之相似度最高的物品。
- 推荐与用户历史行为中的物品相似度较高的其他物品:根据用户历史行为中的物品,推荐与之相似度较高的其他物品给用户。
2.1.2 协同过滤推荐算法的优缺点
协同过滤推荐算法的优点:
- 算法简单、直观,实现容易。
- 不依赖商品内容和属性,适用于各种类型的商品推荐。
- 可以发现用户的偏好和兴趣,从而提供个性化的推荐结果。
- 可以发现潜在的兴趣和相关性,引导用户发现新的商品。
- 可以利用用户对商品的评分和行为进行推荐,更能刻画用户的兴趣。
协同过滤推荐算法的缺点:
- 算法在大规模数据集上的计算复杂度较高,处理效率较低。
- 对于新用户和新商品,缺乏足够的历史数据进行准确的推荐。
- 没有考虑商品的内容和属性信息,可能导致推荐结果的多样性不够。
- 用户间的兴趣相似度难以准确度量,容易受到冷启动问题的影响。
2.1.3 协同过滤推荐算法实例
MovieLens数据集包含许多用户对很多部电影的评分数据,也包括电影元数据信息和用户属性信息。这个数据集经常用来做推荐系统、机器学习算法的测试数据集。根据这些电影评分数据,就可计算出电影的相似度或用户的相似度,然后根据相似度推荐相似电影给用户。
该数据集的下载地址为:http://files.grouplens.org/datasets/movielens/![]() http://files.grouplens.org/datasets/movielens/
http://files.grouplens.org/datasets/movielens/
使用两种协同过滤推荐算法进行电影推荐并评估两种算法的推荐结果:
提醒:ratings.csv数据集380万+行,完全使用需运行内存40G+,根据自身情况删减。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics.pairwise import cosine_similarity# 读取MovieLens数据集
ratings_data = pd.read_csv('ratings.csv')
# movies_data = pd.read_csv('movies.csv')# 获取用户对电影的评分矩阵
ratings_matrix = ratings_data.pivot(index='userId', columns='movieId', values='rating').fillna(0)# 使用train_test_split函数将数据集划分为训练集和测试集
train_data, test_data = train_test_split(ratings_matrix.values, test_size=0.2, random_state=42)# 使用余弦相似度计算用户相似度矩阵
user_similarity = cosine_similarity(train_data)# 使用余弦相似度计算电影相似度矩阵
movie_similarity = cosine_similarity(train_data.T)# 定义基于用户的协同过滤推荐算法
def user_based_recommendation(user_index, top_n=5):user_ratings = train_data[user_index]similar_users_indices = np.argsort(user_similarity[user_index])[::-1]recommended_movies = []for similar_user_index in similar_users_indices:similar_user_ratings = train_data[similar_user_index]non_rated_movies_indices = np.where(user_ratings == 0)[0]sorted_indices = np.argsort(similar_user_ratings[non_rated_movies_indices])[::-1]top_movie_indices = non_rated_movies_indices[sorted_indices][:top_n]recommended_movies.extend(top_movie_indices)if len(recommended_movies) >= top_n:breakreturn recommended_movies# 定义基于物品的协同过滤推荐算法
def item_based_recommendation(user_index, top_n=5):user_ratings = train_data[user_index]similar_movies_indices = np.argsort(movie_similarity[user_index])[::-1]recommended_movies = []for similar_movie_index in similar_movies_indices:if user_ratings[similar_movie_index] == 0:recommended_movies.append(similar_movie_index)if len(recommended_movies) >= top_n:breakreturn recommended_movies# 评估基于用户的协同过滤推荐算法
def evaluate_user_based_recommendation(test_data, top_n=5):num_users = test_data.shape[0]total_precision = 0total_recall = 0for user_index in range(num_users):true_movies_indices = np.where(test_data[user_index] > 0)[0]recommended_movies_indices = user_based_recommendation(user_index, top_n)num_true_movies = len(true_movies_indices)num_recommended_movies = len(recommended_movies_indices)num_common_movies = len(set(true_movies_indices).intersection(set(recommended_movies_indices)))precision = num_common_movies / num_recommended_moviesrecall = num_common_movies / num_true_moviestotal_precision += precisiontotal_recall += recallavg_precision = total_precision / num_usersavg_recall = total_recall / num_usersreturn avg_precision, avg_recall# 评估基于物品的协同过滤推荐算法
def evaluate_item_based_recommendation(test_data, top_n=5):num_users = test_data.shape[0]total_precision = 0total_recall = 0for user_index in range(num_users):true_movies_indices = np.where(test_data[user_index] > 0)[0]recommended_movies_indices = item_based_recommendation(user_index, top_n)num_true_movies = len(true_movies_indices)num_recommended_movies = len(recommended_movies_indices)num_common_movies = len(set(true_movies_indices).intersection(set(recommended_movies_indices)))precision = num_common_movies / num_recommended_moviesrecall = num_common_movies / num_true_moviestotal_precision += precisiontotal_recall += recallavg_precision = total_precision / num_usersavg_recall = total_recall / num_usersreturn avg_precision, avg_recall# 测试基于用户的协同过滤推荐算法
precision, recall = evaluate_user_based_recommendation(test_data)
print("User-based Collaborative Filtering:")
print("Precision:", precision)
print("Recall:", recall)# 测试基于物品的协同过滤推荐算法
precision, recall = evaluate_item_based_recommendation(test_data)
print("Item-based Collaborative Filtering:")
print("Precision:", precision)
print("Recall:", recall)
运行结果:

注意:
上面的代码中假设Ratings数据保存在名为ratings.csv的CSV文件中。此外,代码中使用了sklearn库的函数进行数据集划分和余弦相似度计算。
相关文章:
基于python的机器学习(三)—— 关联规则与推荐算法
目录 一、关联规则挖掘 1.1 基本概念 1.2 Apriori算法 1.2.1 Apriori算法的原理 1.2.2 Apriori算法的实例 1.2.3 Apriori算法的程序实现(efficient-apriori模块) 1.3 FP-Growth算法 1.3.1 FP-Growth算法的原理 1.3.2 FP-Growth算法的实例 二、…...

【大模型】LLaMA: Open and Efficient Foundation Language Models
链接:https://arxiv.org/pdf/2302.13971 论文:LLaMA: Open and Efficient Foundation Language Models Introduction 规模和效果 7B to 65B,LLaMA-13B 超过 GPT-3 (175B)Motivation 如何最好地缩放特定训练计算预算的数据集和模型大小&…...

模拟器多开限制ip,如何设置单窗口单ip,每个窗口ip不同
很多手游多开玩家都是利用安卓模拟器实现手游多开,但是很多手游会限制ip,导致多开之后封号等问题,模拟器本身没有更换IP的功能,就需要通过第三方软件来实现 安卓模拟器概述 雷电模拟器、夜神模拟器、mum模拟器等都是目前市场上比较…...

hive的存储格式
1) 四种存储格式 hive的存储格式分为两大类:一类纯文本文件,一类是二进制文件存储。 Hive支持的存储数据的格式主要有:TEXTFILE、SEQUENCEFILE、ORC、PARQUET 第一类:纯文本文件存储 textfile: 纯文本文件存储格式…...
)
鸿蒙学习高效开发与测试-应用程序框架(3)
文章目录 1、应用程序框架1、规范化后台进程管理2、原生支持分布式3、支持多设备的统一窗口管理4、 组件共享及面向对象5、逻辑与界面解耦6、灵活扩展机制2、HarmonyOS SDK1、 开放能力 Kit2、开放能力的检索和使用3、 方舟工具链4、前端编译器架构1、应用程序框架 应 用 程 序…...

什么命令可以查看数据库中表的结构
1. MySQL 查看表结构 sql 复制代码 DESCRIBE 表名; 或者: sql 复制代码 SHOW COLUMNS FROM 表名; 更详细的表信息 sql 复制代码 SHOW CREATE TABLE 表名; 2. PostgreSQL 查看表结构 sql 复制代码 \d 表名 列出表的字段及类型 sql 复制代码 SELECT column_name, da…...

django基于python 语言的酒店推荐系统
摘 要 酒店推荐系统旨在提供一个全面酒店推荐在线平台,该系统允许用户浏览不同的客房类型,并根据个人偏好和需求推荐合适的酒店客房。用户可以便捷地进行客房预订,并在抵达后简化入住登记流程。为了确保连续的住宿体验,系统还提供…...

【深度学习|onnx】往onnx中写入训练的超参或者类别等信息,并在推理时读取
1、往onnx中写入 在训练完毕之后,我们先使用torch.onnx.export() 导出onnx模型,然后我们再使用以下代码来往metadata中写入信息: # Metadatad {# stride: int(max(model.stride)),names: model.names,mean : [0,0,0],std : [1,1,1],normali…...

WebSocket详解、WebSocket入门案例
目录 1.1 WebSocket介绍 http协议: webSocket协议: 1.2WebSocket协议: 1.3客户端(浏览器)实现 1.3.2 WebSocket对象的相关事宜: 1.3.3 WebSOcket方法 1.4 服务端实现 服务端如何接收客户端发送的请…...

05_Spring JdbcTemplate
在继续了解Spring的核心知识前,我们先看看Spring的一个模板类JdbcTemplate,它是一个JDBC的模板类,用来简化JDBC的操作。 接下来以实际来进行说明 一、实例环境准备 数据库及表准备 我们在本地mysql中新增一个数据库test,并新增一张数据表:user create database if not…...

Bug:引入Feign后触发了2次、4次ContextRefreshedEvent
Bug:引入Feign后发现监控onApplication中ContextRefreshedEvent事件触发了2次或者4次。 【原理】在Spring的文档注释中提示到: Event raised when an {code ApplicationContext} gets initialized or refreshed.即当 ApplicationContext 进行初始化或者刷…...
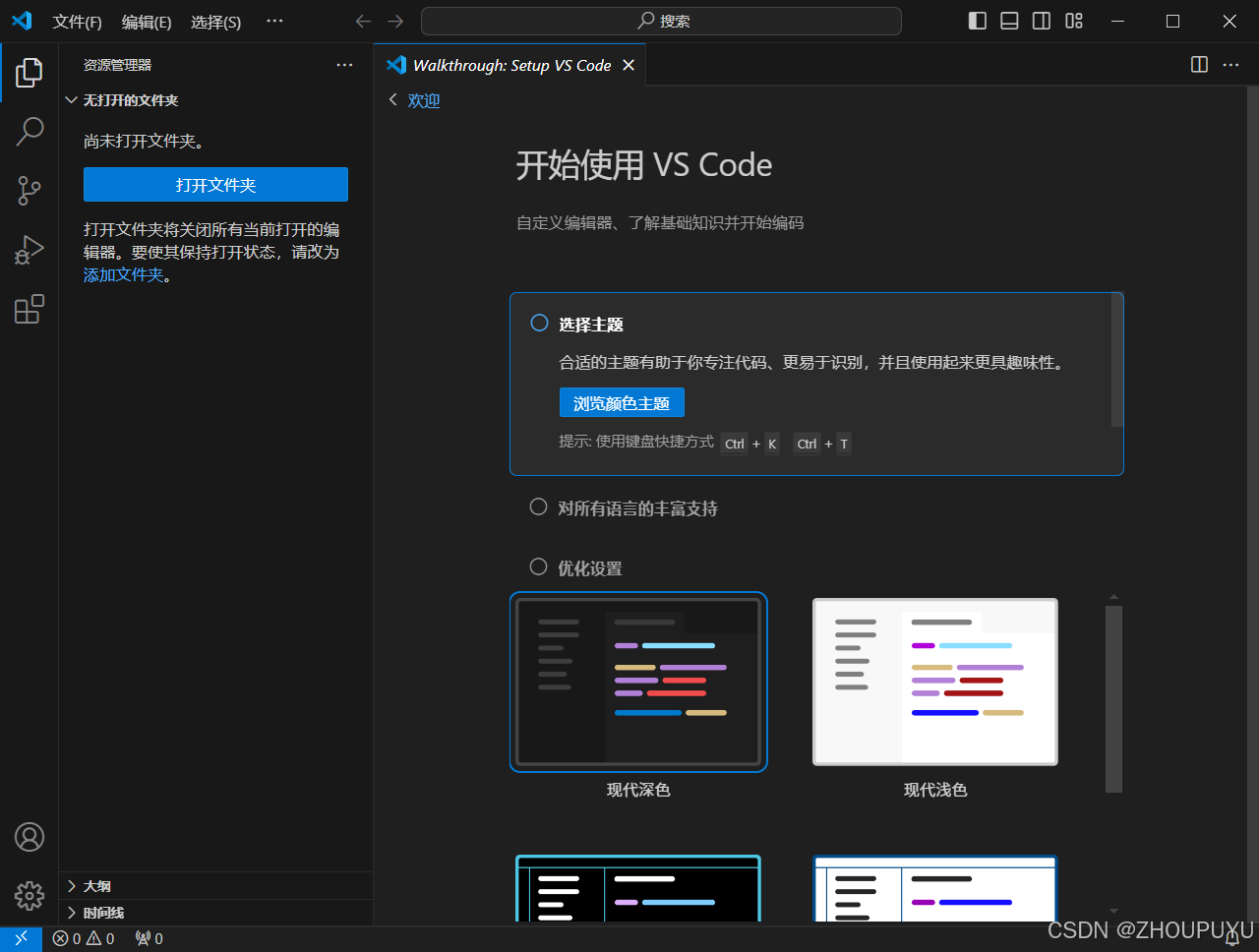
最新VSCode保姆级安装教程(附安装包)
文章目录 一、VSCode介绍 二、VSCode下载 下载链接:https://pan.quark.cn/s/19a303ff81fc 三、VSCode安装 1.解压安装文件:双击打开并安装VSCode 2.勾选我同意协议:然后点击下一步 3.选择目标位置:点击浏览 4.选择D盘安装&…...

layui 表格点击编辑感觉很好用,实现方法如下
1. 在 HTML 页面中引入 layui 的相关资源文件:html <link rel"stylesheet" href"https://cdn.staticfile.org/layui/2.5.6/css/layui.css"> <script src"https://cdn.staticfile.org/layui/2.5.6/layui.js"></script&…...
三十一、构建完善微服务——API 网关
一、API 网关基础 系统拆分为微服务后,内部的微服务之间是互联互通的,相互之间的访问都是点对点的。如果外部系统想调用系统的某个功能,也采取点对点的方式,则外部系统会非常“头大”。因为在外部系统看来,它不需要也没…...

非对称之美(贪心)
非对称之美(贪心) import java.util.*; public class Main{public static void main(String[] arg) {Scanner in new Scanner(System.in);char[] ch in.next().toCharArray(); int n ch.length; int flag 1;for(int i 1; i < n; i) {if(ch[i] ! ch[0]) {flag …...

详细教程-Linux上安装单机版的Hadoop
1、上传Hadoop安装包至linux并解压 tar -zxvf hadoop-2.6.0-cdh5.15.2.tar.gz 安装包: 链接:https://pan.baidu.com/s/1u59OLTJctKmm9YVWr_F-Cg 提取码:0pfj 2、配置免密码登录 生成秘钥: ssh-keygen -t rsa -P 将秘钥写入认…...

C#桌面应用制作计算器进阶版01
基于C#桌面应用制作计算器做出了少量改动,其主要改动为新增加了一个label控件,使其每一步运算结果由label2展示出来,而当点击“”时,最终运算结果将由label1展示出来,此时label清空。 修改后运行效果 修改后全篇代码 …...
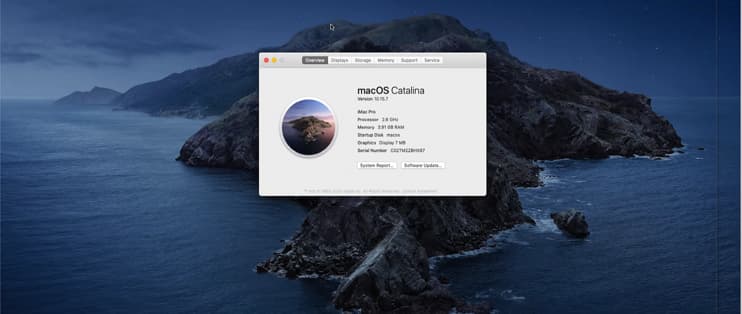
[开源] 告别黑苹果!用docker安装MacOS体验苹果系统
没用过苹果电脑的朋友可能会对苹果系统好奇,有人甚至会为了尝鲜MacOS去折腾黑苹果。如果你只是想体验一下MacOS,这里有个更简单更优雅的解决方案,用docker安装MacOS来体验苹果系统。 一、项目简介 项目描述 Docker 容器内的 OSX(…...

多模态大模型(4)--InstructBLIP
BLIP-2通过冻结的指令调优LLM以理解视觉输入,展示了在图像到文本生成中遵循指令的初步能力。然而,由于额外的视觉输入由于输入分布和任务多样性,构建通用视觉语言模型面临很大的挑战。因而,在视觉领域,指令调优技术仍未…...
)
【Linux】基于 Busybox 构建嵌入式 Linux(未完成)
嵌入式 Linux 1.需要 Toolchain 2.需要 Bootloader 3.需要嵌入式 Linux 基本组件: Linux kernelDTBRoot filesystem InitShellDaemonShared librariesConfiguration fileDevice nodeproc and sysKernel Module 基于 Busybox 构建 1.编译 Linux kernel 2.编译 …...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

排序算法总结(C++)
目录 一、稳定性二、排序算法选择、冒泡、插入排序归并排序随机快速排序堆排序基数排序计数排序 三、总结 一、稳定性 排序算法的稳定性是指:同样大小的样本 **(同样大小的数据)**在排序之后不会改变原始的相对次序。 稳定性对基础类型对象…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...