从繁琐到优雅:用 PyTorch Lightning 简化深度学习项目开发
从繁琐到优雅:用 PyTorch Lightning 简化深度学习项目开发
在深度学习开发中,尤其是使用 PyTorch 时,我们常常需要编写大量样板代码来管理训练循环、验证流程和模型保存等任务。PyTorch Lightning 作为 PyTorch 的高级封装库,帮助开发者专注于研究核心逻辑,极大地提升开发效率和代码的可维护性。
本篇博客将详细介绍 PyTorch Lightning 的核心功能,并通过示例代码帮助你快速上手。
PyTorch Lightning 是什么?
PyTorch Lightning 是一个开源库,旨在简化 PyTorch 代码结构,同时提供强大的训练工具。它解决了以下问题:
- 规范化代码结构
- 自动化模型训练、验证和测试
- 简化多 GPU 训练
- 无缝集成日志和超参数管理
安装 PyTorch Lightning
确保你的环境中安装了 PyTorch 和 PyTorch Lightning:
pip install pytorch-lightning
核心模块介绍
PyTorch Lightning 的设计核心是将训练流程拆分成以下几个模块:
- LightningModule:用于定义模型、优化器和训练逻辑。
- DataModule:管理数据加载。
- Trainer:自动化训练、验证和测试过程。
1. 定义一个 LightningModule
LightningModule 是 PyTorch Lightning 的核心,用于封装模型和训练逻辑。
import pytorch_lightning as pl
import torch
from torch import nn
from torch.optim import Adamclass LitModel(pl.LightningModule):def __init__(self, input_dim, output_dim):super().__init__()self.model = nn.Sequential(nn.Linear(input_dim, 128),nn.ReLU(),nn.Linear(128, output_dim))self.criterion = nn.CrossEntropyLoss()def forward(self, x):return self.model(x)def training_step(self, batch, batch_idx):x, y = batchpreds = self(x)loss = self.criterion(preds, y)self.log("train_loss", loss)return lossdef configure_optimizers(self):return Adam(self.parameters(), lr=0.001)
2. 使用 DataModule 管理数据
DataModule 提供了数据加载的统一接口,支持训练、验证和测试数据集的分离。
from torch.utils.data import DataLoader, random_split, TensorDatasetclass LitDataModule(pl.LightningDataModule):def __init__(self, dataset, batch_size=32):super().__init__()self.dataset = datasetself.batch_size = batch_sizedef setup(self, stage=None):# 划分数据集train_size = int(0.8 * len(self.dataset))val_size = len(self.dataset) - train_sizeself.train_dataset, self.val_dataset = random_split(self.dataset, [train_size, val_size])def train_dataloader(self):return DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)def val_dataloader(self):return DataLoader(self.val_dataset, batch_size=self.batch_size)
3. 使用 Trainer 训练模型
Trainer 是 PyTorch Lightning 的核心工具,自动化训练和验证。
import torch
from torch.utils.data import TensorDataset# 准备数据
X = torch.rand(1000, 10) # 输入特征
y = torch.randint(0, 2, (1000,)) # 二分类标签
dataset = TensorDataset(X, y)# 初始化 DataModule 和 LightningModule
data_module = LitDataModule(dataset)
model = LitModel(input_dim=10, output_dim=2)# 训练模型
trainer = pl.Trainer(max_epochs=10)
trainer.fit(model, datamodule=data_module)
4. 增强功能:多 GPU 和日志集成
多 GPU 支持
PyTorch Lightning 的 Trainer 支持多 GPU 训练,无需额外代码。
trainer = pl.Trainer(max_epochs=10, gpus=2) # 使用 2 块 GPU
trainer.fit(model, datamodule=data_module)
日志集成
集成日志工具(如 TensorBoard 或 WandB)只需几行代码。
pip install tensorboard
然后:
from pytorch_lightning.loggers import TensorBoardLoggerlogger = TensorBoardLogger("logs", name="my_model")
trainer = pl.Trainer(logger=logger, max_epochs=10)
trainer.fit(model, datamodule=data_module)
5. 自定义 Callback
你可以通过回调函数自定义训练流程。例如,在每个 epoch 结束时打印一条消息:
from pytorch_lightning.callbacks import Callbackclass CustomCallback(Callback):def on_epoch_end(self, trainer, pl_module):print(f"Epoch {trainer.current_epoch}结束!")trainer = pl.Trainer(callbacks=[CustomCallback()], max_epochs=10)
trainer.fit(model, datamodule=data_module)
6. 模型保存和加载
PyTorch Lightning 会自动保存最佳模型,但你也可以手动保存和加载:
# 保存模型
trainer.save_checkpoint("model.ckpt")# 加载模型
model = LitModel.load_from_checkpoint("model.ckpt")
PyTorch Lightning 的实战案例:从零到部署
为了更好地展示 PyTorch Lightning 的优势,我们以一个实际案例为例:构建一个用于分类任务的深度学习模型,包括数据预处理、训练模型和最终的测试部署。
案例介绍
我们将使用一个简单的 Tabular 数据集(如 Titanic 数据集),目标是根据乘客的特征预测其是否生还。我们分为以下步骤:
- 数据预处理与特征工程
- 定义 DataModule 和 LightningModule
- 模型训练与验证
- 模型测试与部署
1. 数据预处理与特征工程
import pandas as pd
import torch
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 读取 Titanic 数据集
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
data = pd.read_csv(url)# 选择部分特征并进行简单预处理
data = data[["Pclass", "Sex", "Age", "Fare", "Survived"]].dropna()
data["Sex"] = data["Sex"].map({"male": 0, "female": 1}) # 将性别转为数值
X = data[["Pclass", "Sex", "Age", "Fare"]].values
y = data["Survived"].values# 数据划分与标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)# 转为 PyTorch 数据集
train_dataset = torch.utils.data.TensorDataset(torch.tensor(X_train, dtype=torch.float32), torch.tensor(y_train))
val_dataset = torch.utils.data.TensorDataset(torch.tensor(X_val, dtype=torch.float32), torch.tensor(y_val))
2. 定义 DataModule 和 LightningModule
DataModule
from torch.utils.data import DataLoader
import pytorch_lightning as plclass TitanicDataModule(pl.LightningDataModule):def __init__(self, train_dataset, val_dataset, batch_size=32):super().__init__()self.train_dataset = train_datasetself.val_dataset = val_datasetself.batch_size = batch_sizedef train_dataloader(self):return DataLoader(self.train_dataset, batch_size=self.batch_size, shuffle=True)def val_dataloader(self):return DataLoader(self.val_dataset, batch_size=self.batch_size)
LightningModule
import torch.nn.functional as F
from torch.optim import Adamclass TitanicClassifier(pl.LightningModule):def __init__(self, input_dim):super().__init__()self.model = torch.nn.Sequential(torch.nn.Linear(input_dim, 64),torch.nn.ReLU(),torch.nn.Linear(64, 32),torch.nn.ReLU(),torch.nn.Linear(32, 1),torch.nn.Sigmoid())def forward(self, x):return self.model(x)def training_step(self, batch, batch_idx):x, y = batchy_hat = self(x).squeeze()loss = F.binary_cross_entropy(y_hat, y.float())self.log("train_loss", loss)return lossdef validation_step(self, batch, batch_idx):x, y = batchy_hat = self(x).squeeze()loss = F.binary_cross_entropy(y_hat, y.float())self.log("val_loss", loss)def configure_optimizers(self):return Adam(self.parameters(), lr=0.001)
3. 模型训练与验证
# 初始化 DataModule 和 LightningModule
data_module = TitanicDataModule(train_dataset, val_dataset)
model = TitanicClassifier(input_dim=4)# 使用 Trainer 进行训练
trainer = pl.Trainer(max_epochs=20, gpus=0, progress_bar_refresh_rate=20)
trainer.fit(model, datamodule=data_module)
训练时,PyTorch Lightning 会自动管理训练循环和日志。
4. 模型测试与部署
在训练完成后,我们可以轻松测试模型并将其部署到实际系统中。
测试模型
# 测试数据
X_test = torch.tensor(X_val, dtype=torch.float32)
y_test = torch.tensor(y_val)# 推理
model.eval()
with torch.no_grad():predictions = (model(X_test).squeeze() > 0.5).int()# 计算准确率
accuracy = (predictions == y_test).sum().item() / len(y_test)
print(f"测试集准确率: {accuracy:.2f}")
保存与加载模型
# 保存模型
trainer.save_checkpoint("titanic_model.ckpt")# 加载模型
loaded_model = TitanicClassifier.load_from_checkpoint("titanic_model.ckpt")
loaded_model.eval()
扩展与优化
加入早停机制
通过回调功能,可以在验证损失不再下降时停止训练:
from pytorch_lightning.callbacks import EarlyStoppingearly_stop_callback = EarlyStopping(monitor="val_loss", patience=3, mode="min")
trainer = pl.Trainer(callbacks=[early_stop_callback], max_epochs=50)
trainer.fit(model, datamodule=data_module)
超参数调优
结合工具如 Optuna 可以实现超参数优化:
pip install optuna
然后通过 Lightning 的集成工具快速进行实验。
总结:PyTorch Lightning 在项目开发中的优势
- 开发效率提升:通过 LightningModule 和 DataModule,减少了重复代码。
- 模块化设计:清晰分离模型、数据和训练流程,便于维护和扩展。
- 生产级支持:方便集成分布式训练、日志管理和模型部署。
通过本案例,你可以感受到 PyTorch Lightning 的强大能力。不论是个人研究还是生产环境,它都能成为深度学习项目的得力助手。
立即行动
尝试用 PyTorch Lightning 重构你现有的 PyTorch 项目,体验优雅代码带来的效率提升吧! 🚀
相关文章:

从繁琐到优雅:用 PyTorch Lightning 简化深度学习项目开发
从繁琐到优雅:用 PyTorch Lightning 简化深度学习项目开发 在深度学习开发中,尤其是使用 PyTorch 时,我们常常需要编写大量样板代码来管理训练循环、验证流程和模型保存等任务。PyTorch Lightning 作为 PyTorch 的高级封装库,帮助…...

UE5 第一人称射击项目学习(完结)
这个项目几乎完结了。 也算我上手的第一个纯蓝图小项目。 现在只剩下缝缝补补了。 之前把子弹设计为蓝图,这里要引入C的面向对象思想,建立成员函数。 首先双击打开子弹的蓝图 这边就可以构造成员函数 写一个print your name 在这里生成成员函数后&am…...

Banana Pi BPI-CanMV-K230D-Zero 采用嘉楠科技 K230D RISC-V芯片设计
概述 Banana Pi BPI-CanMV-K230D-Zero 采用嘉楠科技 K230D RISC-V芯片设计,探索 RISC-V Vector1.0 的前沿技术,选择嘉楠科技的 Canmv K230D Zero 开发板。这款创新的开发板是由嘉楠科技与香蕉派开源社区联合设计研发,搭载了先进的勘智 K230D 芯片。 K230…...

【vim】使用 gn 组合命令实现搜索选中功能
gn是Vim 7.4新增的一个操作(motion),作用是跳到并选中下一个搜索匹配项。 具体说,Vim里执行搜索后,执行n操作只会跳转到下一个匹配项,而不选中它。但是我们往往需要对匹配项执行一些修改操作,例…...

【Python刷题】广度优先搜索相关问题
题目描述 小A与小B 算法思路 小A一次移动一步,但有八个方向,小B一次移动两步,只有四个方向,要求小A和小B最早的相遇时间。用两个队列分别记录下小A和小B每一步可以走到的位置,通过一个简单的bfs就能找到这些位置并…...

竞赛思享会 | 2024年第十届数维杯国际数学建模挑战赛D题【代码+演示】
Hello,这里是Easy数模!以下idea仅供参考,无偿分享! 题目背景 本题旨在通过对中国特定城市的房产、人口、经济、服务设施等数据进行分析,评估其在应对人口老龄化、负增长趋势和极端气候事件中的韧性与可持续发展能力。…...
早期超大规模语言模型的尝试——BLOOM模型论文解读,附使用MindSpore和MindNLP的模型和实验复现
背景 预训练语言模型已经成为了现代自然语言处理pipeline中的基石,因为其在少量的标注数据上产生更好的结果。随着ELMo、ULMFiT、GPT和BERT的开发,使用预训练模型在下游任务上微调的范式被广泛使用。随后发现预训练语言模型在没有任何额外训练的情况下任…...

二分查找题目:有序数组中的单一元素
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法一思路和算法代码复杂度分析 解法二思路和算法代码复杂度分析 题目 标题和出处 标题:有序数组中的单一元素 出处:540. 有序数组中的单一元素 难度 4 级 题目描述 要求 给定一个仅由整数…...

springboot基于Android的华蓥山旅游导航系统
摘 要 华蓥山旅游导航系统是一款专为华蓥山景区设计的智能导览应用,旨在为用户提供便捷的旅游信息服务。该系统通过整合华蓥山的地理信息、景点介绍、交通状况等数据,实现了对景区的全面覆盖。用户可以通过该系统获取实时的旅游资讯、交流论坛、地图等。…...

面向对象编程(OOP)深度解析:思想、原则与应用
🚀 作者 :“码上有前” 🚀 文章简介 :Java 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 面向对象编程(OOP)深度解析:思想、原则与应用 一、面向对象编程的基本…...

iPhone 17 Air看点汇总:薄至6mm 刷新苹果轻薄纪录
我们姑且将这款iPhone 17序列的超薄SKU称为“iPhone 17 Air”,Jeff Pu在报告中提到,我同意最近关于 iPhone 17超薄机型采用6 毫米厚度超薄设计的传言。 如果这一测量结果被证明是准确的,那么将有几个值得注意的方面。 首先,iPhone…...

「OpenCV交叉编译」ubuntu to arm64
Ubuntu x86_64 交叉编译OpenCV 为 arm64OpenCV4.5.5、cmake version 3.16.3交叉编译器 gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu 可在arm或linaro官网下载所需版本,本文的交叉编译器可点击链接跳转下载 Downloads | GNU-A Downloads – Arm Developer L…...
Stable Diffusion的解读(二)
Stable Diffusion的解读(二) 文章目录 Stable Diffusion的解读(二)摘要Abstract一、机器学习部分1. 算法梳理1.1 LDM采样算法1.2 U-Net结构组成 2. Stable Diffusion 官方 GitHub 仓库2.1 安装2.2 主函数2.3 DDIM采样器2.4 Unet 3…...

amd显卡和nVidia显卡哪个好 amd和英伟达的区别介绍
AMD和英伟达是目前市场上最主要的两大显卡品牌,它们各有自己的特点和优势,也有不同的适用场景和用户群体。那么,AMD显卡和英伟达显卡到底哪个好?它们之间有什么区别?我们又该如何选择呢?本文将从以下几个方…...

软件测试—— Selenium 常用函数(一)
前一篇文章:软件测试 —— 自动化基础-CSDN博客 目录 前言 一、窗口 1.屏幕截图 2.切换窗口 3.窗口设置大小 4.关闭窗口 二、等待 1.等待意义 2.强制等待 3.隐式等待 4.显式等待 总结 前言 在前一篇文章中,我们介绍了自动化的一些基础知识&a…...

为什么verilog中递归函数需要定义为automatic?
直接上代码 module automatic_tb;reg [7:0] value;initial begin #0 value < 8d5;#10 $display("result of automatic: %0d", factor_automatic(value));$display("result of static: %0d", factor_static(value));#50 $stop; endfunction reg[7:0] fa…...

23种设计模式-状态(State)设计模式
文章目录 一.什么是状态模式?二.状态模式的结构三.状态模式的应用场景四.状态模式的优缺点五.状态模式的C实现六.状态模式的JAVA实现七.代码解释八.总结 类图: 状态设计模式类图 一.什么是状态模式? 状态模式(State Pattern&…...

EventListener与EventBus
EventListener JDK JDK1.1开始就提供EventListener,一个标记接口,源码如下: /*** A tagging interface that all event listener interfaces must extend.*/ public interface EventListener { }JDK提供的java.util.EventObject࿱…...

Facebook为什么注册失败了?该怎么解决?
有时候用户在尝试注册Facebook账号时可能会遇到各种问题,导致注册失败或遇到困难。小编会为大家分析Facebook注册失败的可能原因,并提供解决方法,帮助大家顺利完成注册流程。 一、Facebook注册失败的可能原因 1. 账号信息问题: …...

前端数据可视化思路及实现案例
目录 一、前端数据可视化思路 (一)明确数据与目标 (二)选择合适的可视化图表类型 (三)数据与图表的绑定及交互设计 (四)页面布局与样式设计 二、具体案例:使用 Ech…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...
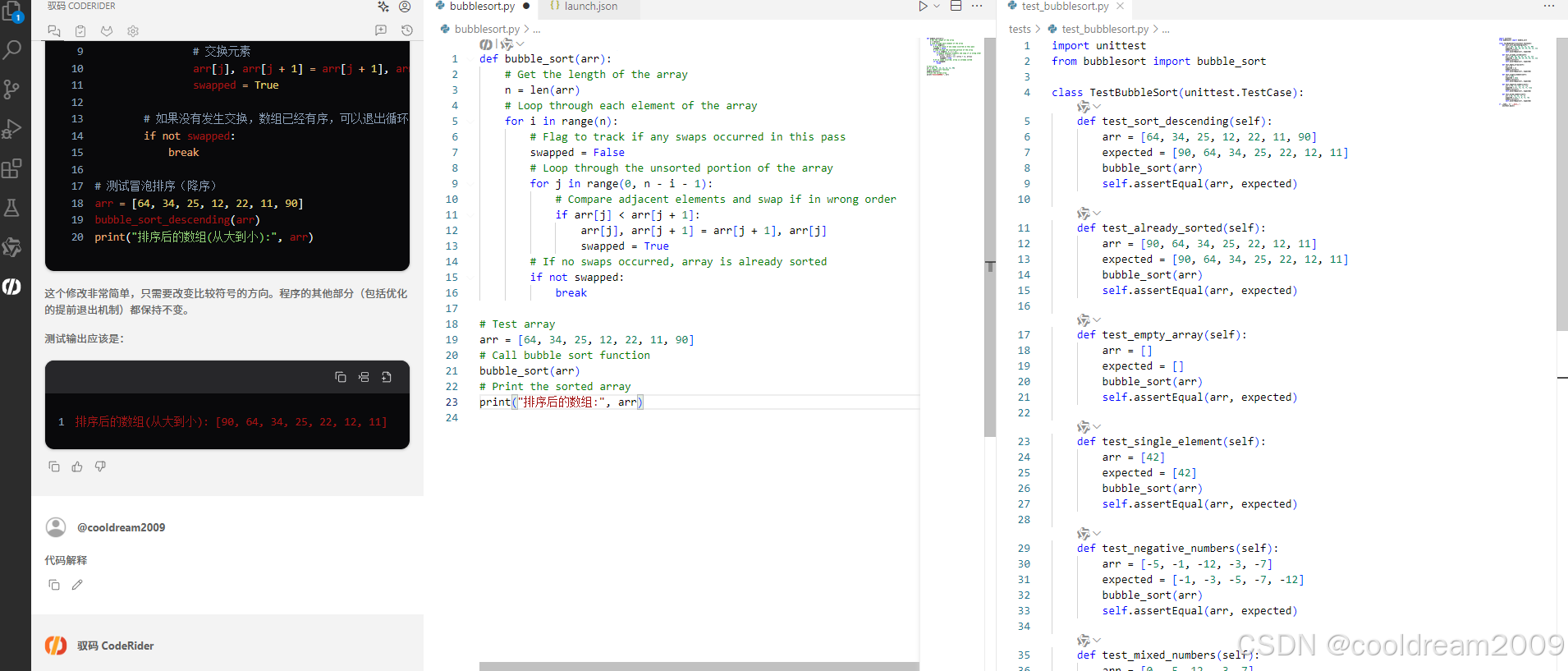
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...

电脑桌面太单调,用Python写一个桌面小宠物应用。
下面是一个使用Python创建的简单桌面小宠物应用。这个小宠物会在桌面上游荡,可以响应鼠标点击,并且有简单的动画效果。 import tkinter as tk import random import time from PIL import Image, ImageTk import os import sysclass DesktopPet:def __i…...

Python异步编程:深入理解协程的原理与实践指南
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 持续学习,不断…...
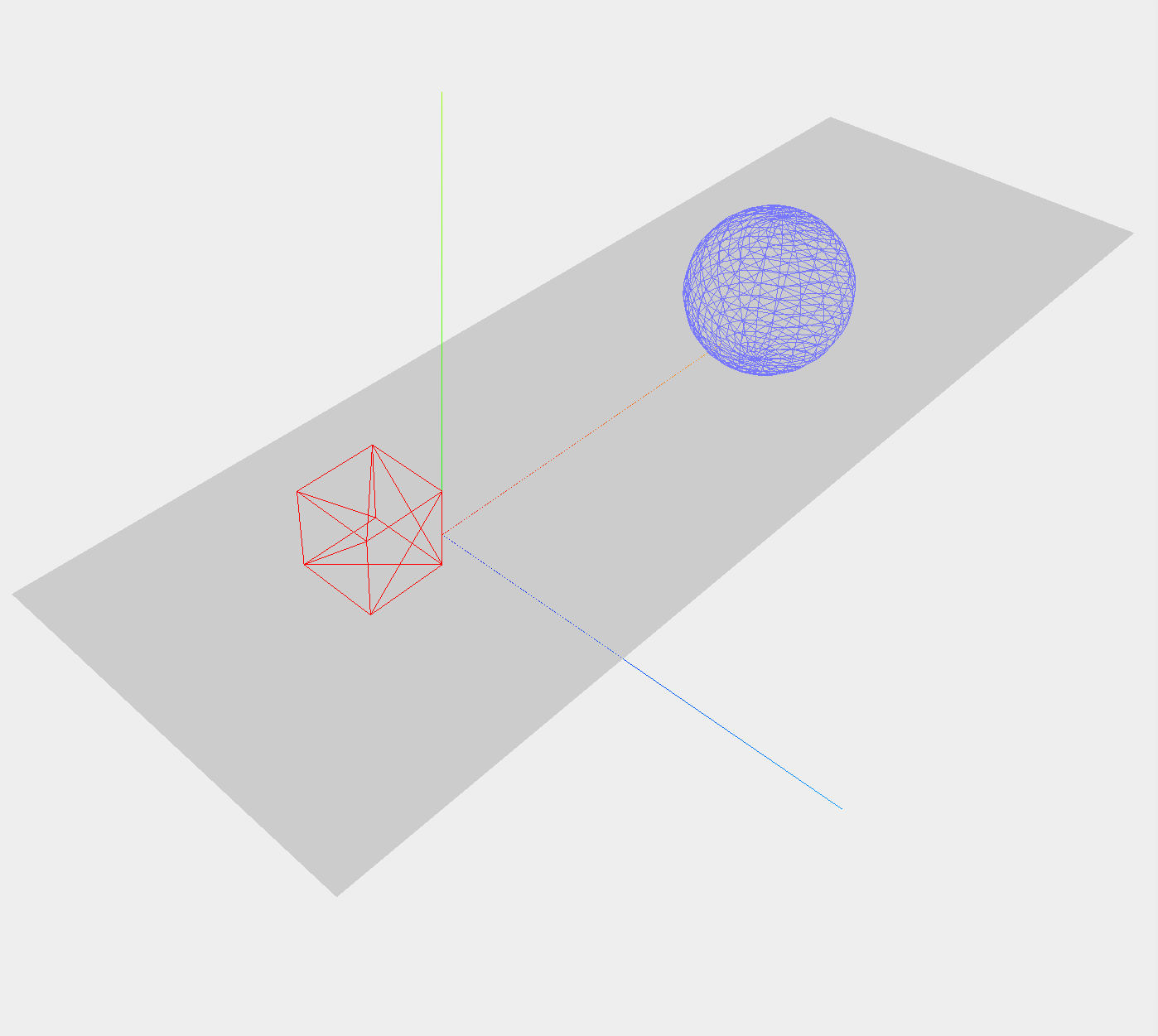
【threejs】每天一个小案例讲解:创建基本的3D场景
代码仓 GitHub - TiffanyHoo/three_practices: Learning three.js together! 可自行clone,无需安装依赖,直接liver-server运行/直接打开chapter01中的html文件 运行效果图 知识要点 核心三要素 场景(Scene) 使用 THREE.Scene(…...
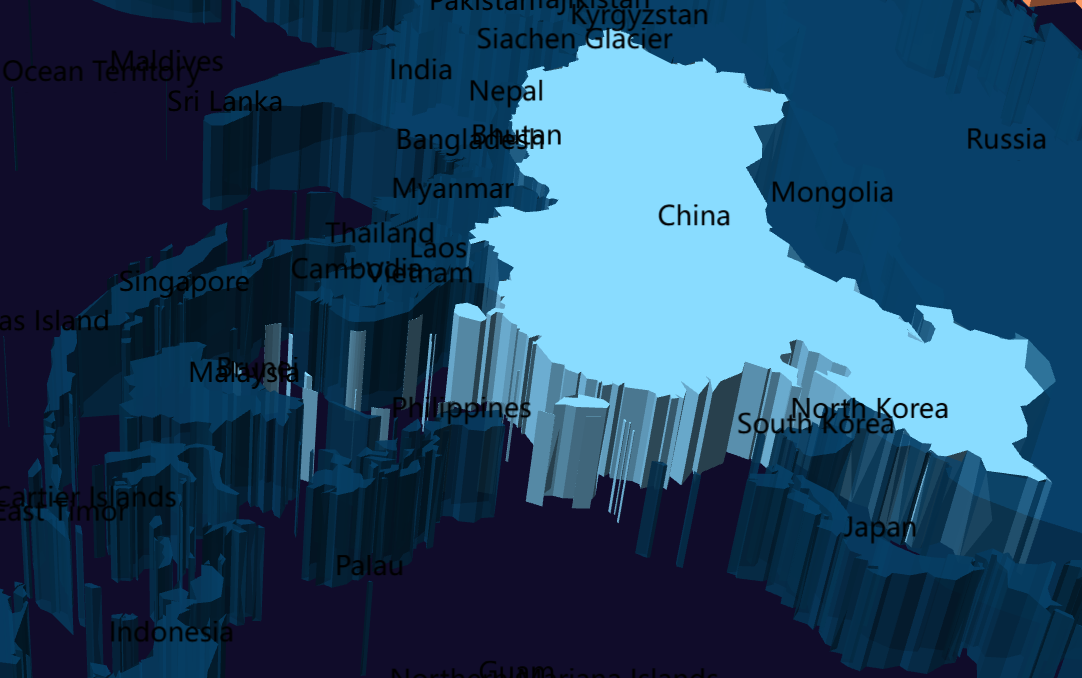
数据可视化交互
目录 【实验目的】 【实验原理】 【实验环境】 【实验步骤】 一、安装 pyecharts 二、下载数据 三、实验任务 实验 1:AQI 横向对比条形图 代码说明: 运行结果: 实验 2:AQI 等级分布饼图 实验 3:多城市 AQI…...