竞赛思享会 | 2024年第十届数维杯国际数学建模挑战赛D题【代码+演示】
Hello,这里是Easy数模!以下idea仅供参考,无偿分享!
题目背景
本题旨在通过对中国特定城市的房产、人口、经济、服务设施等数据进行分析,评估其在应对人口老龄化、负增长趋势和极端气候事件中的韧性与可持续发展能力。主要目标包括未来房价和房屋存量预测、服务水平量化分析、韧性与可持续发展能力评估,以及根据分析结果为城市未来发展提供规划建议。
问题总览
这四个问题可以按不同类型的分析任务进行概括,具体如下:
1. 问题 (1):未来房价预测与房屋存量估计
类型:预测与估计问题
该问题涉及未来趋势的预测(如房价)和当前状态的估计(如房屋存量),可以通过时间序列分析、回归模型等方法进行解决。它关注对未来市场的预测,为后续的城市发展和政策制定提供参考。
2. 问题 (2):服务水平量化分析
类型:聚类分析与特征提取
该问题关注对现有服务水平的聚类以及特征的提取。它主要是一个数据聚类和特征分析问题,涉及到对不同服务设施的覆盖度、密度等指标的计算,并提取城市服务的共性和个性,找到城市在各方面的优势和劣势。
3. 问题 (3):城市韧性和可持续发展能力评估
类型:评估与优化问题
该问题关注城市在极端气候和紧急事件中的韧性表现,以及在可持续发展方面的能力。它属于评估问题,同时包含一定的优化成分(在预算限制下制定投资计划),可通过构建指标体系、建立资源分配模型等方式来量化并优化城市的韧性与可持续发展能力。
4. 问题 (4):未来发展规划
类型:规划与决策问题
该问题要求制定一个未来发展的具体规划,属于决策与规划问题。它基于前面问题的分析结果,进一步明确投资方向、预算和预期成效,为城市的长远发展提供指导性建议。
总结
- 问题 (1):预测与估计
- 问题 (2):聚类分析与特征提取
- 问题 (3):评估与优化
- 问题 (4):规划与决策
题目解析及解题思路
问题 (1):房价预测与房屋存量估计(预测问题)
目标:预测未来房价走势,估算当前房屋存量。
数据来源:
- 已提供的City 1和City 2的房产销售信息数据(附件1和2)
- 可收集的互联网数据(如人口、GDP等)
数据总览
附件1和附件2(两个城市的房产信息):
- 字段:
- Community Number:小区编号
- Price (USD):房价(美元)
- Total number of households:总住户数
- Greening rate:绿化率
- Floor area ratio:容积率
- Building type:建筑类型(多层、中层、高层等)
- Parking space:停车位信息(总数和车位比)
- Property management fee(/m²/month USD):物业管理费
- above-ground/underground parking fee(/month USD):地上/地下停车费
- property type:房产类型
- citycode 和 adcode:城市代码和地区代码
- lon 和 lat:经纬度
- X 和 Y:坐标转换值
数据特征:
- 包含房价、住户数、绿化率、容积率等多维度的房产和小区信息,有助于进行房价预测、服务水平评估以及后续韧性与可持续发展能力分析。
解题思路:
- 数据预处理:清洗并结构化房产数据,提取关键特征如区域、房价、面积等。
- 特征选取:引入人口、GDP、收入水平、城镇化率等影响房价的宏观经济特征。
- 预测模型:
- 时间序列模型:如ARIMA模型,用于预测房价的时间变化趋势。
- 机器学习模型:如多元回归、随机森林或XGBoost模型,通过房产和经济特征变量预测未来房价。
- 房屋存量估计:
- 使用房产销售信息估算当前房屋市场的供给量。
- 结合人口密度和住宅用地面积数据,估算当前房屋存量。
- 如果可以获得历年住房数据,还可基于住房建成率和出售率进行时间动态估算。
可行性挑战:
- 需要补充人口、经济等数据并进行清洗,以保证预测准确性。
- 需要调整模型参数以适应城市不同的区域特征,避免“一刀切”模式。
1. 数据探索性分析
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns# Load the data
file_path_1 = '/content/Appendix 1.xlsx'
data_1 = pd.read_excel(file_path_1)# Display basic information about the data
print("Data Overview:")
print(data_1.info())# Display basic statistics
print("\nBasic Statistical Information:")
print(data_1.describe())# Check for missing values
print("\nMissing Values:")
print(data_1.isnull().sum())# Distribution of 'Price (USD)'
plt.figure(figsize=(10, 6))
sns.histplot(data_1['Price (USD)'].dropna(), kde=True)
plt.title('Distribution of Price (USD)')
plt.xlabel('Price (USD)')
plt.ylabel('Frequency')
plt.show()# Distribution of 'Total number of households'
plt.figure(figsize=(10, 6))
sns.histplot(data_1['Total number of households'].dropna(), kde=True)
plt.title('Distribution of Total Number of Households')
plt.xlabel('Total number of households')
plt.ylabel('Frequency')
plt.show()# Distribution of 'Greening rate'
plt.figure(figsize=(10, 6))
sns.histplot(data_1['Greening rate'].dropna(), kde=True)
plt.title('Distribution of Greening Rate')
plt.xlabel('Greening rate')
plt.ylabel('Frequency')
plt.show()# Relationship between 'Building type' and 'Price (USD)'
plt.figure(figsize=(12, 8))
sns.boxplot(x='Building type', y='Price (USD)', data=data_1)
plt.xticks(rotation=45)
plt.title('Price (USD) Distribution by Building Type')
plt.xlabel('Building type')
plt.ylabel('Price (USD)')
plt.show()# Relationship between 'Floor area ratio' and 'Price (USD)'
plt.figure(figsize=(10, 6))
sns.scatterplot(x='Floor area ratio', y='Price (USD)', data=data_1)
plt.title('Relationship between Floor Area Ratio and Price (USD)')
plt.xlabel('Floor area ratio')
plt.ylabel('Price (USD)')
plt.show()# Calculate and visualize the correlation matrix for numeric columns only
plt.figure(figsize=(12, 8))
numeric_data = data_1.select_dtypes(include=['float64', 'int64']) # Select only numeric columns
correlation_matrix = numeric_data.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', square=True)
plt.title('Correlation Matrix of Numeric Variables')
plt.show()






以下是对附件1数据的详细探索性分析结果:
- 房价分布:
- 从房价的分布图中可以看出,房价呈现右偏分布,大部分房价集中在10,000美元以下。这意味着大部分房产的价格处于较为实惠的范围内,但也有少部分房产价格较高(达到30,000美元甚至更高),拉高了整体的价格范围。
- 这种右偏的价格分布表明,在某些区域可能存在少量高端房产,这些房产的价格远高于平均水平。高价房产可能位于市中心、学区房、或是配套设施更完善的区域,从而推高了价格。
- 总体来看,大多数房产的价格集中在5,000至15,000美元之间,可能代表了市场的主流房价水平。
- 总住户数量分布:
- 总住户数量的分布也呈现出右偏,绝大多数小区的住户数较少,主要集中在1,000户以下,但也有少量小区住户数超过4,000户甚至达到7,000户以上。
- 小区住户数量的分布情况可能反映了城市中不同类型住宅区的存在:低住户数的小区可能是小型或低密度住宅区,如独栋住宅、别墅区等,而高住户数的小区可能是大型高密度住宅开发区,如公寓楼群或住宅综合体。
- 这种差异说明该城市的住宅类型多样化,可能存在不同的人群定位和住宅需求。
- 绿化率分布:
- 从绿化率的分布可以看到,大多数房产的绿化率集中在0.2到0.3之间,这可能是由城市规划的标准所决定的,确保住宅区有一定的绿色空间。
- 另外,绿化率在0.5及以上的房产相对较少。这类高绿化率的房产可能集中在生态住宅区、豪华小区或是高端住宅区中,通常这些区域会有更好的绿色环境以提升居住质量。
- 总体来看,绿化率较高的小区可能有更高的市场吸引力,因为绿色空间通常与生活质量的提升相关联。
- 建筑类型与房价的关系:
- 从箱线图中可以看出,不同建筑类型的房价分布差异显著。例如,“超高层”建筑的房价范围最广,价格波动较大,这可能是因为超高层建筑中的楼层位置和景观差异会影响价格,顶层或高层的价格往往较高。
- “多层”和“中层”建筑的房价较为集中且相对较低,表明这些建筑类型可能是普通居民住宅的主流选择,价格较为亲民且较为稳定。
- 此外,建筑类型的多样性也说明了不同人群的需求,例如,家庭可能更倾向于选择低层或中层的多层建筑,而年轻专业人士可能更青睐配套设施更齐全的高层或超高层公寓。
- 容积率与房价的关系:
- 从散点图可以看出,容积率与房价之间存在一定的负相关关系,即容积率越高的房产,房价往往越低。这种关系可以理解为,容积率高的区域往往意味着更高的建筑密度和更少的开放空间,通常与中低端住宅区相关。
- 容积率低的房产通常价格较高,可能是因为低容积率的开发项目往往具有更多的绿色空间、开放视野和更高的生活质量,例如低密度的高档住宅区或别墅区。
- 因此,容积率可以作为房产定位的一个重要参考因素,低容积率的房产可能更适合定位为高端市场,而高容积率的房产适合满足中低收入人群的居住需求。
- 相关性矩阵分析:
- 相关性矩阵显示出各变量之间的关系。以下是一些值得注意的相关性:
- 总住户数与地上停车费之间存在一定的正相关性,这表明在住户数较多的小区,停车需求也较大,从而影响停车费用。
- 绿化率与容积率之间存在一定的负相关性,这表明高密度的住宅区往往绿化率较低,而低密度的住宅区有更大的空间用于绿色环境。
- **地理坐标(经纬度)**显示出一些集群性,表明数据中不同房产可能位于不同的地理区域,可以进一步探索其地理位置与房价的关系。
总结
这些探索性分析结果提供了房产市场的整体概况,可以总结出:
- 房价和总住户数量呈现明显的右偏分布。
- 不同建筑类型和容积率对房价有显著影响,反映出不同住宅的市场定位。
- 绿化率和容积率之间的关系揭示了城市规划和住宅质量的关联。
这些见解可以为后续的建模和预测提供基础,尤其是在考虑不同区域、建筑类型和容积率等特征对房价的影响时。
2.数据预处理
- 填充了数值和类别变量的缺失值。
- 提取并转换了停车位信息。
- 转换并填充了物业管理费用。
- 删除了缺失率较高的列。
- 进行了One-Hot编码以便后续建模。
import pandas as pd
import numpy as np# Load data
file_path_1 = '/content/Appendix 1.xlsx'
data_1 = pd.read_excel(file_path_1)# Fill missing values
data_1['Price (USD)'].fillna(data_1['Price (USD)'].median(), inplace=True)
data_1['Total number of households'].fillna(data_1['Total number of households'].median(), inplace=True)
data_1['Greening rate'].fillna(data_1['Greening rate'].median(), inplace=True)
data_1['Floor area ratio'].fillna(data_1['Floor area ratio'].median(), inplace=True)
data_1['Building type'].fillna(data_1['Building type'].mode()[0], inplace=True)
data_1['property type'].fillna(data_1['property type'].mode()[0], inplace=True)# Handle 'parking space' by extracting total spaces and ratio
data_1['Total parking spaces'] = data_1['parking space'].str.extract(r'(\d+)', expand=False).astype(float)
data_1['Parking space ratio'] = data_1['parking space'].str.extract(r'\((1:\d+.\d+)\)', expand=False)
data_1.drop(columns=['parking space'], inplace=True) # Drop the original column# Handle 'Property management fee(/m²/month USD)' by converting ranges to median
data_1['Property management fee(/m²/month USD)'] = data_1['Property management fee(/m²/month USD)'].apply(lambda x: np.mean([float(i) for i in str(x).split('-')]) if isinstance(x, str) and '-' in x else x
)
data_1['Property management fee(/m²/month USD)'] = data_1['Property management fee(/m²/month USD)'].astype(float)
data_1['Property management fee(/m²/month USD)'].fillna(data_1['Property management fee(/m²/month USD)'].median(), inplace=True)# Drop columns with high missing values if necessary
data_1.drop(columns=['underground parking fee(/month USD)'], inplace=True)# One-Hot Encode categorical variables
data_1 = pd.get_dummies(data_1, columns=['Building type', 'property type'], drop_first=True)# Check final data
print("Processed Data Types:")
print(data_1.dtypes)
print("\nMissing Values After Processing:")
print(data_1.isnull().sum())# Convert 'Parking space ratio' to numerical format
data_1['Parking space ratio'] = data_1['Parking space ratio'].str.extract(r'1:(\d+\.\d+)', expand=False).astype(float)# Fill missing values for remaining columns
data_1['above-ground parking fee(/month USD)'].fillna(data_1['above-ground parking fee(/month USD)'].median(), inplace=True)
data_1['Total parking spaces'].fillna(data_1['Total parking spaces'].median(), inplace=True)
data_1['Parking space ratio'].fillna(data_1['Parking space ratio'].median(), inplace=True)# Final check for missing values
print("\nFinal Missing Values After Processing:")
print(data_1.isnull().sum())
3.特征工程筛选
进行特征重要性分析和SHAP分析有助于理解各个特征对房价的影响。我们可以使用随机森林回归模型来评估特征重要性,因为随机森林可以自然地输出每个特征对预测结果的重要性。这里将可视化每个特征的重要性。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split# 分离特征和目标变量
X = data_1.drop(columns=['Price (USD)'])
y = data_1['Price (USD)']# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练随机森林模型
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)# 获取特征重要性
feature_importances = model.feature_importances_
features = X.columns# 可视化特征重要性
plt.figure(figsize=(10, 8))
plt.barh(features, feature_importances)
plt.xlabel("Feature Importance")
plt.ylabel("Features")
plt.title("Feature Importance Analysis using Random Forest")
plt.show()

根据特征重要性图,我们可以看到一些特征的重要性接近于零或很低,因此可以考虑排除这些对房价预测影响不大的特征,以简化模型,提升计算效率。以下特征可以考虑排除:
- 建筑类型中的许多组合:例如 Building type_super high-rise、Building type_multi-story | mid-rise | super high-rise 等等,这些类别的特征重要性非常低。
- 物业类型中的部分类别:例如 property type_other、property type_hotel、property type_self-built 等类别对预测影响较小。
- 其他类别变量:citycode、adcode,这些特征对预测的影响也非常小,可以考虑排除。
排除这些变量后,我们可以重新进行SHAP分析,聚焦于对房价预测有显著影响的特征,以便更清晰地理解特征对预测的影响。
import pandas as pd
import numpy as np
import shap
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split# 重新筛选特征,排除不重要的特征
selected_features = data_1.drop(columns=['Building type_super high-rise', 'Building type_multi-story | mid-rise | super high-rise','Building type_multi-story | mid-rise | high-rise', 'Building type_multi-story | high-rise | super high-rise','property type_other', 'property type_hotel', 'property type_self-built','citycode', 'adcode'
])# 分离特征和目标变量
X_selected = selected_features.drop(columns=['Price (USD)'])
y_selected = selected_features['Price (USD)']# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X_selected, y_selected, test_size=0.2, random_state=42)# 训练随机森林模型
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)# 使用已经训练好的模型进行SHAP值分析
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)# 可视化SHAP值的整体影响(特征重要性)
plt.figure(figsize=(10, 8))
shap.summary_plot(shap_values, X_test, plot_type="bar")# 可视化SHAP值的分布(每个特征对预测的影响)
shap.summary_plot(shap_values, X_test)

4.预测模型(准备采用之前推文的模型)
等待更新,不早了,先睡了!
问题 (2):服务水平量化分析 (聚类分析)
目标:量化City 1和City 2各行业的服务水平,提取城市的共性和个性特征,分析各自的优势与劣势。
数据来源:
- 附件3和4提供的基本服务POI(Point of Interest)数据。
解题思路:
- POI数据处理:
- 按照POI数据的行业分类(如医疗、教育、公共设施等)进行整理,提取出服务设施的地理分布和数量。
- 服务水平量化指标:
- 设施密度:每个行业的服务设施在特定区域内的密度,反映服务的覆盖率。
- 可达性:基于设施的分布和人口分布,评估居民到达这些服务设施的便捷性(可以使用GIS工具计算)。
- 服务多样性:统计不同类型服务设施的多样性,反映服务的全面性。
- 共性与个性分析:
- 通过聚类分析或主成分分析,对服务设施特征进行降维,识别两城市在服务水平上的共性与差异。
- 优势与劣势:
- 利用得分模型,对比两城市在不同服务领域的表现,找到各自的优势(如教育资源丰富、医疗设施充足)和不足(如缺乏公共娱乐设施等)。
可行性挑战:
- POI数据的完整性和精度会影响分析结果,需确保数据准确性。
- 地理分布分析涉及GIS工具操作,需较强的空间数据处理能力。
问题 (3):城市韧性与可持续发展能力评估(评价问题)
目标:评估两个城市应对极端天气和紧急事件的韧性,量化可持续发展能力,识别具体的弱点及未来投资重点。
数据来源:
- 附件3和4中的POI数据,以及在互联网上获取的有关城市基础设施和气候风险的数据。
解题思路:
- 韧性评估指标:
- 应急响应设施:包括医院、消防站、避难所等数量与分布。
- 基础设施耐久性:评估关键基础设施(如交通、电力、水利设施)的抗风险能力。
- 社会支持网络:例如社区中心、志愿者组织等的数量与活跃度,增强居民在灾害中的自助能力。
- 可持续发展能力量化:
- 建立一套综合指标体系,包括经济、社会和环境维度。
- 计算每个指标的得分,得分越高代表该城市在该指标上的表现越优。
- 短期与长期投资计划:
- 短期投资:主要聚焦在提升基础设施韧性、加强应急响应设施,如增加消防站数量、加强社区防灾教育等。
- 长期投资:关注环境治理、可持续能源和智慧城市建设,制定绿地扩展、公共交通优化等长期规划。
- 财务约束下的优化:
- 使用线性规划或资源分配模型,以“有限资金下最大化韧性与可持续性得分”为目标,合理分配预算。
可行性挑战:
- 需找到适合的韧性评估框架,并调整适应城市实际情况。
- 需要结合外部环境(如经济压力、政策支持),对投资回报进行合理预估。
问题 (4):未来发展规划(规划与决策问题)
目标:根据上述分析结果,制定City 1和City 2的未来发展规划,明确投资方向、金额和预期的智能城市发展提升效果。
解题思路:
- 发展规划框架:
- 将规划分为“基础设施”、“社会服务”、“环境可持续性”、“智能城市建设”四大类,每类明确未来发展方向。
- 投资预算:
- 对各个领域设定具体的投资金额及用途,例如智能交通系统、绿色建筑、智慧医疗设备等。
- 发展效果预测:
- 使用量化指标预测投资后的成效,如基础设施完备度、应急响应时间缩短、服务水平提升等。
- 撰写规划报告:
- 简洁明了地阐述发展规划,确保内容不超过两页,包括城市建设的主要方向、每个领域的投资重点以及对应的预期效果。
可行性挑战:
- 需精简规划内容,确保报告简明扼要。
- 需要合理量化预期效果,便于未来评估成效。
相关文章:
竞赛思享会 | 2024年第十届数维杯国际数学建模挑战赛D题【代码+演示】
Hello,这里是Easy数模!以下idea仅供参考,无偿分享! 题目背景 本题旨在通过对中国特定城市的房产、人口、经济、服务设施等数据进行分析,评估其在应对人口老龄化、负增长趋势和极端气候事件中的韧性与可持续发展能力。…...
早期超大规模语言模型的尝试——BLOOM模型论文解读,附使用MindSpore和MindNLP的模型和实验复现
背景 预训练语言模型已经成为了现代自然语言处理pipeline中的基石,因为其在少量的标注数据上产生更好的结果。随着ELMo、ULMFiT、GPT和BERT的开发,使用预训练模型在下游任务上微调的范式被广泛使用。随后发现预训练语言模型在没有任何额外训练的情况下任…...

二分查找题目:有序数组中的单一元素
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法一思路和算法代码复杂度分析 解法二思路和算法代码复杂度分析 题目 标题和出处 标题:有序数组中的单一元素 出处:540. 有序数组中的单一元素 难度 4 级 题目描述 要求 给定一个仅由整数…...

springboot基于Android的华蓥山旅游导航系统
摘 要 华蓥山旅游导航系统是一款专为华蓥山景区设计的智能导览应用,旨在为用户提供便捷的旅游信息服务。该系统通过整合华蓥山的地理信息、景点介绍、交通状况等数据,实现了对景区的全面覆盖。用户可以通过该系统获取实时的旅游资讯、交流论坛、地图等。…...

面向对象编程(OOP)深度解析:思想、原则与应用
🚀 作者 :“码上有前” 🚀 文章简介 :Java 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 面向对象编程(OOP)深度解析:思想、原则与应用 一、面向对象编程的基本…...

iPhone 17 Air看点汇总:薄至6mm 刷新苹果轻薄纪录
我们姑且将这款iPhone 17序列的超薄SKU称为“iPhone 17 Air”,Jeff Pu在报告中提到,我同意最近关于 iPhone 17超薄机型采用6 毫米厚度超薄设计的传言。 如果这一测量结果被证明是准确的,那么将有几个值得注意的方面。 首先,iPhone…...

「OpenCV交叉编译」ubuntu to arm64
Ubuntu x86_64 交叉编译OpenCV 为 arm64OpenCV4.5.5、cmake version 3.16.3交叉编译器 gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu 可在arm或linaro官网下载所需版本,本文的交叉编译器可点击链接跳转下载 Downloads | GNU-A Downloads – Arm Developer L…...
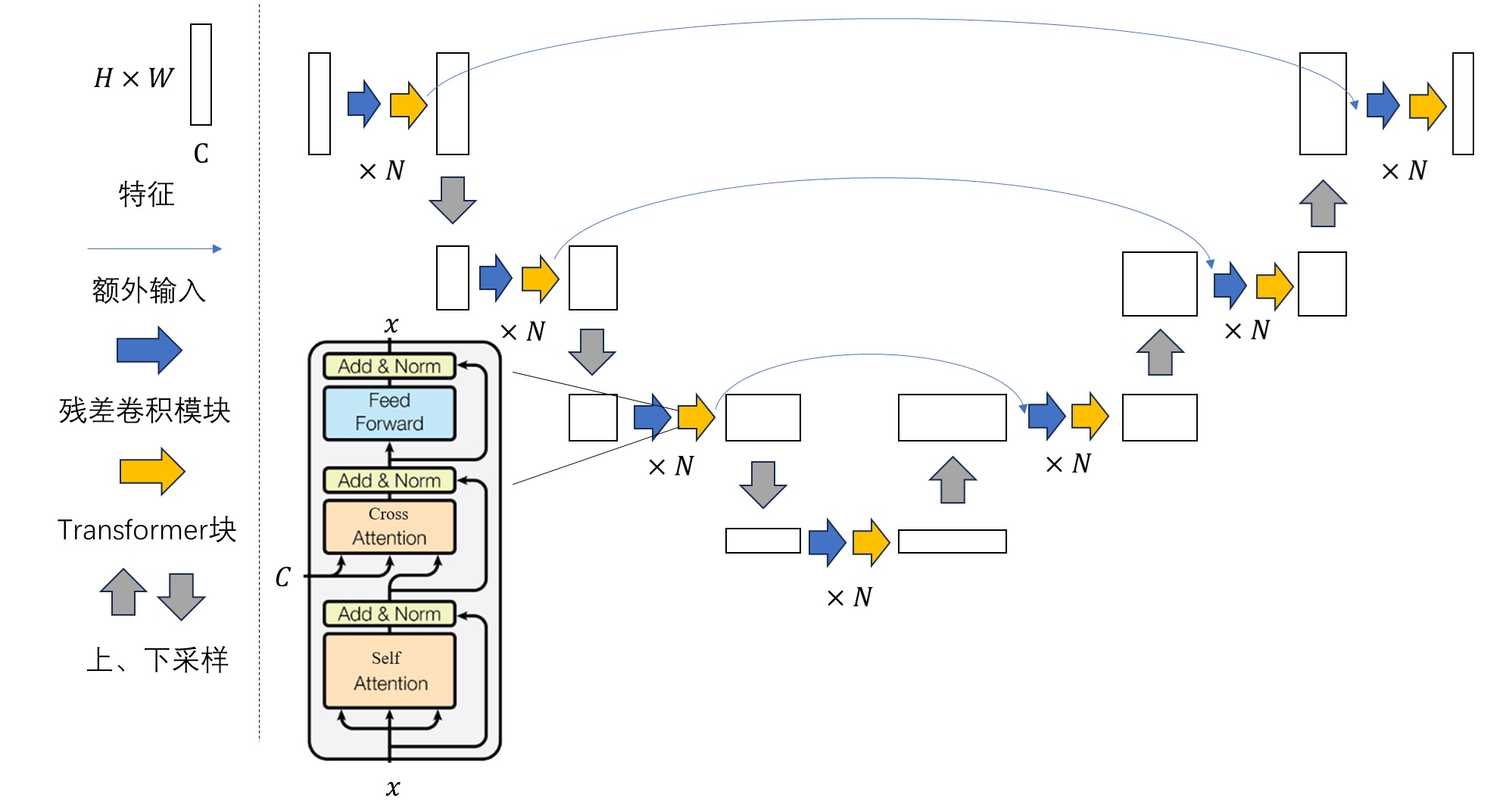
Stable Diffusion的解读(二)
Stable Diffusion的解读(二) 文章目录 Stable Diffusion的解读(二)摘要Abstract一、机器学习部分1. 算法梳理1.1 LDM采样算法1.2 U-Net结构组成 2. Stable Diffusion 官方 GitHub 仓库2.1 安装2.2 主函数2.3 DDIM采样器2.4 Unet 3…...

amd显卡和nVidia显卡哪个好 amd和英伟达的区别介绍
AMD和英伟达是目前市场上最主要的两大显卡品牌,它们各有自己的特点和优势,也有不同的适用场景和用户群体。那么,AMD显卡和英伟达显卡到底哪个好?它们之间有什么区别?我们又该如何选择呢?本文将从以下几个方…...

软件测试—— Selenium 常用函数(一)
前一篇文章:软件测试 —— 自动化基础-CSDN博客 目录 前言 一、窗口 1.屏幕截图 2.切换窗口 3.窗口设置大小 4.关闭窗口 二、等待 1.等待意义 2.强制等待 3.隐式等待 4.显式等待 总结 前言 在前一篇文章中,我们介绍了自动化的一些基础知识&a…...

为什么verilog中递归函数需要定义为automatic?
直接上代码 module automatic_tb;reg [7:0] value;initial begin #0 value < 8d5;#10 $display("result of automatic: %0d", factor_automatic(value));$display("result of static: %0d", factor_static(value));#50 $stop; endfunction reg[7:0] fa…...

23种设计模式-状态(State)设计模式
文章目录 一.什么是状态模式?二.状态模式的结构三.状态模式的应用场景四.状态模式的优缺点五.状态模式的C实现六.状态模式的JAVA实现七.代码解释八.总结 类图: 状态设计模式类图 一.什么是状态模式? 状态模式(State Pattern&…...

EventListener与EventBus
EventListener JDK JDK1.1开始就提供EventListener,一个标记接口,源码如下: /*** A tagging interface that all event listener interfaces must extend.*/ public interface EventListener { }JDK提供的java.util.EventObject࿱…...

Facebook为什么注册失败了?该怎么解决?
有时候用户在尝试注册Facebook账号时可能会遇到各种问题,导致注册失败或遇到困难。小编会为大家分析Facebook注册失败的可能原因,并提供解决方法,帮助大家顺利完成注册流程。 一、Facebook注册失败的可能原因 1. 账号信息问题: …...

前端数据可视化思路及实现案例
目录 一、前端数据可视化思路 (一)明确数据与目标 (二)选择合适的可视化图表类型 (三)数据与图表的绑定及交互设计 (四)页面布局与样式设计 二、具体案例:使用 Ech…...
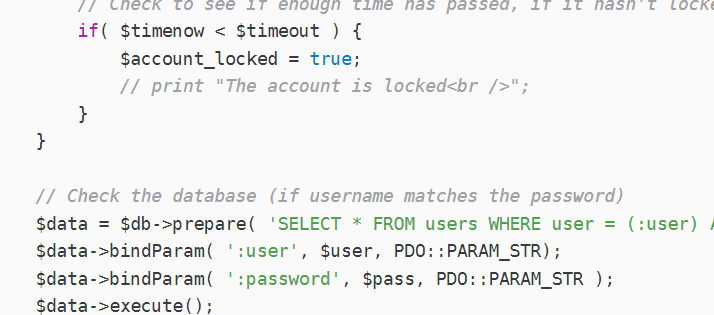
【DVWA】Brute Force暴力破解实战
问尔辈 何等样人 自摸心头 再来求我;若汝能 克存忠孝 持身正直 不拜何妨 1.Brute Force(Low) 相关的代码分析 if( isset( $_GET[ Login ] ) ) {// Get username$user $_GET[ username ];// Check the database$query "SELECT * FROM users WHERE user $…...

23种设计模式速记法
前言 在软件开发的过程中,设计模式作为解决常见问题的通用模板,一直是开发者的重要工具。尤其是在面临复杂系统架构和需求变化时,设计模式不仅能够提升代码的可复用性和扩展性,还能大大提高团队之间的协作效率。然而,…...

第7章硬件测试-7.3 功能测试
7.3 功能测试 7.3.1 整机规格测试7.3.2 整机试装测试7.3.3 DFX测试 功能测试包括整机规格、整机试装和整机功能测试,是整机结构和业务相关的测试。 7.3.1 整机规格测试 整机规格测试包括尺寸、重量、温度、功耗等数据。这些测试数据与设计规格进行比对和校验&…...

动态规划子数组系列一>等差数列划分
题目: 解析: 代码: public int numberOfArithmeticSlices(int[] nums) {int n nums.length;int[] dp new int[n];int ret 0;for(int i 2; i < n; i){dp[i] nums[i] - nums[i-1] nums[i-1] - nums[i-2] ? dp[i-1]1 : 0;ret dp[i…...

《Python浪漫的烟花表白特效》
一、背景介绍 烟花象征着浪漫与激情,将它与表白结合在一起,会创造出别具一格的惊喜效果。使用Python的turtle模块,我们可以轻松绘制出动态的烟花特效,再配合文字表白,打造一段专属的浪漫体验。 接下来,让…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

Oracle11g安装包
Oracle 11g安装包 适用于windows系统,64位 下载路径 oracle 11g 安装包...