【大数据学习 | Spark-Core】Spark中的join原理
join是两个结果集之间的链接,需要进行数据的匹配。
演示一下join是否存在shuffle。
1. 如果两个rdd没有分区器,分区个数一致
,会发生shuffle。但分区数量不变。
scala> val arr = Array(("zhangsan",300),("lisi",400),("wangwu",350),("zhaosi",450))
arr: Array[(String, Int)] = Array((zhangsan,300), (lisi,400), (wangwu,350), (zhaosi,450))scala> val arr1 = Array(("zhangsan",22),("lisi",24),("wangwu",30),("guangkun",5))
arr1: Array[(String, Int)] = Array((zhangsan,22), (lisi,24), (wangwu,30), (guangkun,5))scala> sc.makeRDD(arr,3)
res116: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[108] at makeRDD at <console>:27scala> sc.makeRDD(arr1,3)
res117: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[109] at makeRDD at <console>:27scala> res116 join res117
res118: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[112] at join at <console>:28scala> res118.collect
res119: Array[(String, (Int, Int))] = Array((zhangsan,(300,22)), (wangwu,(350,30)), (lisi,(400,24)))

2. 如果分区个数不一致,有shuffle,且产生的rdd的分区个数以多的为主。

3. 如果分区个数一样并且分区器一样,那么是没有shuffle的
scala> sc.makeRDD(arr,3)
res128: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[118] at makeRDD at <console>:27scala> sc.makeRDD(arr1,3)
res129: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[119] at makeRDD at <console>:27scala> res128.reduceByKey(_+_)
res130: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[120] at reduceByKey at <console>:26scala> res129.reduceByKey(_+_)
res131: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[121] at reduceByKey at <console>:26scala> res130 join res131
res132: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[124] at join at <console>:28scala> res132.collect
res133: Array[(String, (Int, Int))] = Array((zhangsan,(300,22)), (wangwu,(350,30)), (lisi,(400,24)))scala> res132.partitions.size
res134: Int = 3
4. 都存在分区器但是分区个数不同,也会存在shuffle
scala> val arr = Array(("zhangsan",300),("lisi",400),("wangwu",350),("zhaosi",450))
arr: Array[(String, Int)] = Array((zhangsan,300), (lisi,400), (wangwu,350), (zhaosi,450))scala> val arr1 = Array(("zhangsan",22),("lisi",24),("wangwu",30),("guangkun",5))
arr1: Array[(String, Int)] = Array((zhangsan,22), (lisi,24), (wangwu,30), (guangkun,5))scala> sc.makeRDD(arr,3)
res0: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at makeRDD at <console>:27scala> sc.makeRDD(arr1,4)
res1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[1] at makeRDD at <console>:27scala> res0.reduceByKey(_+_)
res2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[2] at reduceByKey at <console>:26scala> res1.reduceByKey(_+_)
res3: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[3] at reduceByKey at <console>:26scala> res2 join res3
res4: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[6] at join at <console>:28scala> res4.collect
res5: Array[(String, (Int, Int))] = Array((zhangsan,(300,22)), (wangwu,(350,30)), (lisi,(400,24)))scala> res4.partitions.size
res6: Int = 4
这里为啥stage3里reduceByKey和join过程是连在一起的,因为分区多的RDD是不需要进行shuffle的,数据该在哪个分区就在哪个分区,反而是分区少的RDD要进行join,要进行数据的打散。
分区以多的为主。
5. 一个带有分区器一个没有分区器,那么以带有分区器的rdd分区数量为主,并且存在shuffle
scala> arr
res7: Array[(String, Int)] = Array((zhangsan,300), (lisi,400), (wangwu,350), (zhaosi,450))scala> arr1
res8: Array[(String, Int)] = Array((zhangsan,22), (lisi,24), (wangwu,30), (guangkun,5))scala> sc.makeRDD(arr,3)
res9: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[7] at makeRDD at <console>:27scala> sc.makeRDD(arr,4)
res10: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[8] at makeRDD at <console>:27scala> res9.reduceByKey(_+_)
res11: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[9] at reduceByKey at <console>:26scala> res10 join res11
res12: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[12] at join at <console>:28scala> res12.partitions.size
res13: Int = 3scala> res12.collect
res14: Array[(String, (Int, Int))] = Array((zhangsan,(300,300)), (wangwu,(350,350)), (lisi,(400,400)), (zhaosi,(450,450)))
同理,stage6的reduceByKey过程和join过程是连在一起的,是因为有分区器的RDD并不需要进行shuffle操作,原来的数据该在哪在哪,而没有分区器的RDD要进行join要进行数据的打散,有shuffle过程,所以有stage4到stage6的连线。
相关文章:
【大数据学习 | Spark-Core】Spark中的join原理
join是两个结果集之间的链接,需要进行数据的匹配。 演示一下join是否存在shuffle。 1. 如果两个rdd没有分区器,分区个数一致 ,会发生shuffle。但分区数量不变。 scala> val arr Array(("zhangsan",300),("lisi",…...

【代码pycharm】动手学深度学习v2-08 线性回归 + 基础优化算法
课程链接 线性回归的从零开始实现 import random import torch from d2l import torch as d2l# 人造数据集 def synthetic_data(w,b,num_examples):Xtorch.normal(0,1,(num_examples,len(w)))ytorch.matmul(X,w)bytorch.normal(0,0.01,y.shape) # 加入噪声return X,y.reshape…...

李宏毅机器学习课程知识点摘要(1-5集)
前5集 过拟合: 参数太多,导致把数据集刻画的太完整。而一旦测试集和数据集的关联不大,那么预测效果还不如模糊一点的模型 所以找的数据集的量以及准确性也会影响 由于线性函数的拟合一般般,所以用一组函数去分段来拟合 sigmoi…...

React(五)——useContecxt/Reducer/useCallback/useRef/React.memo/useMemo
文章目录 项目地址十六、useContecxt十七、useReducer十八、React.memo以及产生的问题18.1组件嵌套的渲染规律18.2 React.memo18.3 引出问题 十九、useCallback和useMemo19.1 useCallback对函数进行缓存19.2 useMemo19.2.1 基本的使用19.2.2 缓存属性数据 19.2.3 对于更新的理解…...

UE5时间轴节点及其设置
在 Unreal Engine 5 (UE5) 中,时间轴节点 (Timeline) 是一个非常有用的工具,可以在蓝图中实现时间驱动的动画和行为。它允许你在给定的时间范围内执行逐帧的动画或数值变化,广泛应用于动态动画、物体移动、颜色变化、材质变换等场景中。 1. …...

git 命令之只提交文件的部分更改
git 命令之只提交文件的部分更改 有时,我们在一个文件中进行了多个更改,但只想提交其中的一部分更改。这时可以使用 使用 git add -p 命令 Git add -p命令允许我们选择并添加文件中的特定更改。它将会显示一个交互式界面,显示出文件中的每个更…...

算法 差分修改 极简
N个气球排成一排,从左到右依次编号为1,2,3....N.每次给定2个整数a b(a < b),lele便为骑上他的“小飞鸽"牌电动车从气球a开始到气球b依次给每个气球涂一次颜色。但是N次以后lele已经忘记了第I个气球已经涂过几次颜色了,你能帮他算出每个气球被涂过…...

pcb元器件选型与焊接测试时的一些个人经验
元件选型 在嘉立创生成bom表,对照bom表买 1、买电容时有50V或者100V是它的耐压值,注意耐压值 2、在买1117等降压芯片时注意它降压后的固定输出,有那种可调降压比如如下,别买错了 贴片元件焊接 我建议先薄薄的在引脚上涂上锡膏…...

OSG开发笔记(三十三):同时观察物体不同角度的多视图从相机技术
若该文为原创文章,未经允许不得转载 本文章博客地址:https://blog.csdn.net/qq21497936/article/details/143932273 各位读者,知识无穷而人力有穷,要么改需求,要么找专业人士,要么自己研究 长沙红胖子Qt…...

模糊逻辑学习 | 模糊推理 | 模糊逻辑控制
注:本文为几位功夫博主关于 “模糊逻辑学习 / 推理 / 控制” 的相关几篇文章合辑。 初学模糊逻辑控制(Fuzzy Logic Control) ziqian__ 已于 2022-08-19 20:30:25 修改 一、前言 模糊逻辑控制(Fuzzy Logic Control)是…...

【JavaEE】Servlet:表白墙
文章目录 一、前端二、前置知识三、代码1、后端2、前端3、总结 四、存入数据库1、引入 mysql 的依赖,mysql 驱动包2、创建数据库数据表3、调整上述后端代码3.1 封装数据库操作,和数据库建立连接3.2 调整后端代码 一、前端 <!DOCTYPE html> <ht…...
)
C++特殊类设计(不能被拷贝的类、只能在堆上创建对象的类、不能被继承的类、单例模式)
C特殊类设计 在实际应用中,可能需要设计一些特殊的类对象,如不能被拷贝的类、只能在堆上创建对象的类、只能在栈上创建对象的类、不能被继承的类、只能创建一个对象的类(单例模式)。 1. 不能被拷贝的类 拷贝只会发生在两个场景…...

【小白学机器学习34】用python进行基础的数据统计 mean,var,std,median,mode ,四分位数等
目录 1 用 numpy 快速求数组的各种统计量:mean, var, std 1.1 数据准备 1.2 直接用np的公式求解 1.3 注意问题 1.4 用print() 输出内容,显示效果 2 为了验证公式的后背,下面是详细的展开公式的求法 2.1 均值mean的详细 2.2 方差var的…...
)
安装 Docker(使用国内源)
一、安装Docker-ce 1、下载阿里云的repo源 [rootlocalhost ~]# yum install yum-utils -y && yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo && yum makecache # 尝试列出 docker-ce 的版本 [rootlocalh…...

Ajax学习笔记,第一节:语法基础
Ajax学习笔记,第一节:语法基础 一、概念 1、什么是Ajax 使用浏览器的 XMLHttpRequest 对象 与服务器通信2、什么是axios Axios是一个基于Promise的JavaScript库,支持在浏览器和Node.js环境中使用。相较于Ajax,Axios提供了更多…...

《用Python画蔡徐坤:艺术与编程的结合》
简介 大家好!今天带来一篇有趣的Python编程项目,用代码画出知名偶像蔡徐坤的形象。这个项目使用了Python的turtle库,通过简单的几何图形和精心设计的代码来展示艺术与编程的结合。 以下是完整的代码和效果介绍,快来试试看吧&…...

Unity中动态生成贴图并保存成png图片实现
实现原理: 要生成长x宽y的贴图,就是生成x*y个像素填充到贴图中,如下图: 如果要改变局部颜色,就是从x1到x2(x1<x2),y1到y2(y1<y2)这个范围做处理, 或者要想做圆形就是计算距某个点(x1,y1&…...

Mac配置maven环境及在IDEA中配置Maven
Mac配置maven环境及在IDEA中配置Maven 1. 介绍 Maven是一款广泛用于Java等JVM语言项目的工具,它以项目对象模型(POM)为基础进行项目管理,通过POM文件来定义项目信息和依赖关系。同时,它也是构建自动化工具࿰…...

Reactor 模式的理论与实践
1. 引言 1.1 什么是 Reactor 模式? Reactor 模式是一种用于处理高性能 I/O 的设计模式,专注于通过非阻塞 I/O 和事件驱动机制实现高并发性能。它的核心思想是将 I/O 操作的事件分离出来,通过事件分发器(Reactor)将事…...

vim 一次注释多行 的几种方法
在 Vim 中一次注释多行是一个常见操作。可以使用以下方法根据你的具体需求选择合适的方式: 方法 1:手动插入注释符 进入正常模式: 按 Esc 确保进入正常模式。 选择需要注释的多行: 移动到第一行,按下 Ctrlv 进入可视块…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...
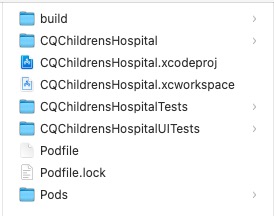
Xcode 16 集成 cocoapods 报错
基于 Xcode 16 新建工程项目,集成 cocoapods 执行 pod init 报错 ### Error RuntimeError - PBXGroup attempted to initialize an object with unknown ISA PBXFileSystemSynchronizedRootGroup from attributes: {"isa">"PBXFileSystemSynchro…...

数据结构:泰勒展开式:霍纳法则(Horner‘s Rule)
目录 🔍 若用递归计算每一项,会发生什么? Horners Rule(霍纳法则) 第一步:我们从最原始的泰勒公式出发 第二步:从形式上重新观察展开式 🌟 第三步:引出霍纳法则&…...

【java】【服务器】线程上下文丢失 是指什么
目录 ■前言 ■正文开始 线程上下文的核心组成部分 为什么会出现上下文丢失? 直观示例说明 为什么上下文如此重要? 解决上下文丢失的关键 总结 ■如果我想在servlet中使用线程,代码应该如何实现 推荐方案:使用 ManagedE…...

虚幻基础:角色旋转
能帮到你的话,就给个赞吧 😘 文章目录 移动组件使用控制器所需旋转:组件 使用 控制器旋转将旋转朝向运动:组件 使用 移动方向旋转 控制器旋转和移动旋转 缺点移动旋转:必须移动才能旋转,不移动不旋转控制器…...