【论文复现】融入模糊规则的宽度神经网络结构

📝个人主页🌹:Eternity._
🌹🌹期待您的关注 🌹🌹


❀ 融入模糊规则的宽度神经网络结构
- 论文概述
- 创新点及贡献
- 算法流程讲解
- 核心代码复现
- main.py文件
- FBLS.py文件
- 使用方法
- 测试结果
- 示例:使用公开数据集进行本地训练
- 准备数据
- 定义数据转换(预处理)
- 下载并加载训练数据集
- 下载并加载测试数据集
- 将每张图片展平并检查加载的数据
- 将每张图片展平
- 将整个训练集展平
- 将整个测试集展平
- 将数据转换为DataFrame并保存为CSV文件
- 数据输入模型进行训练
- 实验结果
- 环境配置
论文概述
今天来给大家讲解一篇发表在中科院一区顶级期刊上《IEEE Transactions on Cybernetics》的有关于目前人工智能计算机视觉新方向(宽度学习)的文章。作者在这篇文章中基于宽度神经网络提出了一种改进的新模型,融入了模糊规则来提高模型对特殊特征的分辨能力。由于模糊规则的复杂性,本博客用了比较多的博客来讲述,如果大家觉得太难,可以直接下载附件代码先跑起来,从代码入手再回来看数学公式会更直接一点。
该论文的作者团队介绍了一种创新的神经模糊模型,即模糊宽度学习系统(简称BLS),这一系统是通过将Takagi-Sugeno(TS)模糊逻辑融入BLS架构中而创建的。在模糊BLS中,传统的BLS特征节点被一系列TS模糊子系统所取代,这些子系统各自负责处理输入数据。不同于直接将各个模糊子系统生成的模糊规则输出简单汇总为一个结果,模糊BLS选择将它们全部传输至一个增强层,进行更深层次的非线性处理,以此来保持输入数据的特性。最终,模糊子系统的去模糊化输出与增强层的输出相结合,共同决定了模型的输出结果。模糊子系统前件部分所使用的高斯隶属函数的中心以及模糊规则的数量,均通过k-means聚类方法来确定。在模糊BLS中,需要计算的参数主要包括连接增强层输出与模型输出的权重,以及模糊子系统后件部分多项式的随机初始化系数,这些参数都可以通过直接求解的方法得到。因此,模糊BLS依然保持了BLS在处理速度上的优势。
该模糊BLS通过一些流行的回归和分类基准进行评估,并与一些最先进的非模糊和神经模糊方法进行比较。结果表明,模糊BLS在性能上优于其他模型。此外,模糊BLS在模糊规则数量和训练时间方面也优于神经模糊模型,在一定程度上缓解了规则爆炸的问题。
本文所涉及的所有资源的获取方式:这里
创新点及贡献
为了建立一个名为模糊BLS的新神经模糊模型,他们用Takagi-Sugeno(TS)模糊子系统代替BLS左部的特征节点。模糊BLS的显著特征与其他神经模糊方法不同,其创新点如下。
模糊BLS构建于一组一阶TS模糊子系统之上,每个子系统均负责处理输入数据。该系统的独特之处在于,所有模糊子系统均参与构建模糊BLS的最终输出,从而充分利用了这种“集体智慧”架构的优势。
我们采用k均值算法对输入数据进行聚类,并据此为每个模糊子系统确定模糊规则的数量以及前件部分高斯隶属函数的中心。得益于k均值算法的特性,每个模糊子系统都能从训练数据中提取出不同的中心,确保产生多样化的结果,从而尽可能全面地捕捉输入数据的信息。
在模糊BLS中,模糊规则产生的输出并不会被立即汇总。相反,所有模糊子系统生成的中间值会被整合成一个向量,并直接传递给增强节点进行非线性转换。随后,结合增强层的输出以及模糊子系统的去模糊化输出,共同生成模型的最终输出。
模糊BLS的参数设定包括连接增强层输出到最终输出层的权重,以及每个模糊子系统中模糊规则后件部分的系数。这些参数可以通过高效的伪逆计算快速得出,从而确保模糊BLS在保持BLS快速计算特性的同时,也能实现精确的输出。
算法流程讲解
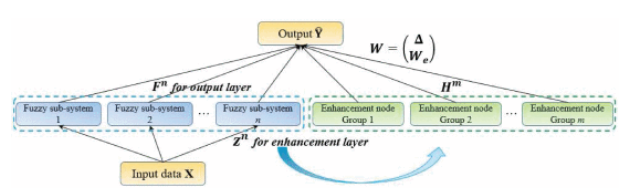
模糊广义学习系统(FBLS)基于随机向量功能链接神经网络和伪逆理论的架构。该设计使系统能够快速且渐进地学习,并且在无需重新训练的情况下重新建模。FBLS模型如图3所示,包含输入层、模糊子系统层、增强节点复合层和输出层。在复合层中,使用模糊规则从输入数据生成多个模糊子系统。这些模糊子系统随后被增强为增强节点,每个节点具有不同的随机权重。通过将所有特征和增强节点连接到输出层来计算输出。
模糊广义学习系统的主要概念是将输入数据映射到一组模糊规则中,然后利用BLS算法学习和优化这些规则的权重和参数。这些模糊规则由模糊集及其对应的隶属函数组成,这些函数描述了输入和输出之间的模糊关系。通过采用模糊逻辑推理,系统可以基于输入数据的模糊表示进行预测和分类。
FBLS是一种结合了随机向量功能链接神经网络和伪逆理论的神经网络模型。该设计允许系统快速学习和适应,无需重新训练。如图3所示,该模型由输入层、模糊子系统层、增强层和输出层组成。在模糊子系统层,使用模糊规则从输入数据生成多个模糊子系统。这些模糊子系统随后使用随机权重转换为增强节点。通过将所有模糊子系统和增强节点连接到输出层来计算输出。





核心代码复现
本人在复现时用三个文件来完成本次项目,分别是main.py文件作为顶层文件调用所有函数和方法;utils.py文件作为工具文件,封装了一些所需要用到的方法;FBLS.py文件中实现了Fuzzy规则和BLS结合的新型宽度神经网络模型——FBLS,下面我们将分别给出他们的伪代码来进一步帮大家理解。
main.py文件
开始
|
|---> 导入 numpy 和 scipy.io 中的 loadmat 和 savemat 函数
|---> 导入 random 和 FBLS 模块中的 bls_train 函数
|
|---> 定义主函数 main():
| |
| |---> 从 MATLAB 文件 'wbc.mat' 中加载数据
| | data = loadmat('wbc.mat')
| | train_x = data['train_x']
| | train_y = data['train_y']
| | test_x = data['test_x']
| | test_y = data['test_y']
| |
| |---> 转换测试集
| | n = 随机生成一个置换数组,长度为 test_x.shape[0]
| | 使用置换数组 n 的前 140 行来更新 test_x 和 test_y,并将它们转换为 np.float64 类型
| | train_y 和 test_y 转换为二元标签 (-1, +1)
| |
| |---> 初始化常数和变量
| | C = 2 ** -30
| | s = 0.8
| | best = 0.72
| | result = 空列表
| |
| | NumRule = 2
| | NumFuzz = 6
| | NumEnhan = 20
| |
| |---> 设置随机种子为 1,生成 Alpha 和 WeightEnhan
| | Alpha = 空列表
| | 对于 i 从 0 到 NumFuzz-1:
| | 生成大小为 (train_x.shape[1], NumRule) 的随机数组 alpha
| | 将 alpha 添加到 Alpha
| |
| | 生成大小为 (NumFuzz * NumRule + 1, NumEnhan) 的随机数组 WeightEnhan
| |
| |---> 打印模糊规则数、模糊系统数和增强器数
| | 打印字符串 'Fuzzy rule No.= {NumRule}, Fuzzy system No. ={NumFuzz}, Enhan. No. = {NumEnhan}'
| |
| |---> 调用 bls_train 函数进行模型训练和测试
| | 调用 bls_train(train_x, train_y, test_x, test_y, Alpha, WeightEnhan, s, C, NumRule, NumFuzz)
| | 返回 NetoutTest, Training_time, Testing_time, TrainingAccuracy, TestingAccuracy
| |
| |---> 计算总时间,并将结果保存到 result 列表中
| | total_time = Training_time + Testing_time
| | 将 [NumRule, NumFuzz, NumEnhan, TrainingAccuracy, TestingAccuracy] 添加到 result 列表
| |
| |---> 如果 TestingAccuracy 比 best 大,则更新 best,并将结果保存到 'optimal.mat' 文件中
| | 如果 best < TestingAccuracy:
| | 更新 best 为 TestingAccuracy
| | 将 {'TrainingAccuracy': TrainingAccuracy, 'TestingAccuracy': TestingAccuracy,
| | 'NumRule': NumRule, 'NumFuzz': NumFuzz, 'NumEnhan': NumEnhan, 'time': total_time}
| | 保存到 'optimal.mat'
| |
| |---> 将 result 列表保存到 'result.mat' 文件中
| | 将 {'result': np.array(result)} 保存到 'result.mat'
| |
| |---> 打印字符串 'Results saved!'
|
|---> 如果运行在主模块下:
| 调用主函数 main()
|
结束
在main.py文件中,我们将FBLS模型封装在bls_train函数中,加载好数据集之后输入模型中进行训练,并编写代码对输出的结果进行测试,打印出评价指标。
FBLS.py文件
开始
|
| 返回 2 / (1 + exp(-2 * x)) - 1
|
|---> 函数 result_tra(output):
| 返回 argmax(output, axis=1)
|
|---> 函数 bls_train(train_x, train_y, test_x, test_y, Alpha, WeightEnhan, s, C, NumRule, NumFuzz):
| |
| |---> std = 1
| |---> 记录开始时间
| |
| |---> 设置 H1 为 train_x
| |---> 初始化 y 为大小 (train_x.shape[0], NumFuzz * NumRule) 的零矩阵
| |---> 初始化 CENTER 为一个空列表
| |---> 初始化 ps 为一个空列表
| |
| |---> 循环 i 从 0 到 NumFuzz-1:
| | |
| | |---> 设置 b1 为 Alpha[i]
| | |---> 初始化 t_y 为大小 (train_x.shape[0], NumRule) 的零矩阵
| | |---> 使用 NumRule 个聚类对 train_x 进行 KMeans 聚类,并将中心设置为聚类中心
| | |
| | |---> 循环 j 从 0 到 train_x.shape[0]-1:
| | | |
| | | |---> 计算 MF 为 exp(-sum((train_x[j, :] - center) ** 2) / std)
| | | |---> 将 MF 归一化
| | | |---> 设置 t_y[j, :] 为 MF * (train_x[j, :].dot(b1))
| | |
| | |---> 将 center 添加到 CENTER
| | |---> 初始化 scaler 为范围 (0, 1) 的 MinMaxScaler
| | |---> 使用 scaler 对 t_y 进行拟合和变换,并将结果设置为 T1
| | |---> 将 scaler 添加到 ps
| | |---> 设置 y[:, NumRule * i:NumRule * (i + 1)] 为 T1
| |
| |---> 将 y 与一个全为 0.1 的列连接起来形成 H2
| |---> 计算 T2 为 H2 dot WeightEnhan
| |---> 设置 l2 为 s / max(T2)
| |---> 对 T2 乘以 l2 应用 tansig
| |---> 将 y 与 T2 连接起来形成 T3
| |
| |---> 计算 beta 为 inverse(T3.T dot T3 + eye(T3.shape[1]) * C) dot T3.T dot train_y
| |---> 记录训练时间
| |---> 打印 'Training has been finished!' 和训练时间
| |---> 计算 NetoutTrain 为 T3 dot beta
| |
| |---> 设置 yy 为 result_tra(NetoutTrain)
| |---> 设置 train_yy 为 result_tra(train_y)
| |---> 计算 TrainingAccuracy 为 mean(yy == train_yy)
| |---> 打印训练准确率
| |
| |---> 记录开始时间
| |
| |---> 设置 HH1 为 test_x
| |---> 初始化 yy1 为大小 (test_x.shape[0], NumFuzz * NumRule) 的零矩阵
| |
| |---> 循环 i 从 0 到 NumFuzz-1:
| | |
| | |---> 设置 b1 为 Alpha[i]
| | |---> 初始化 t_y 为大小 (test_x.shape[0], NumRule) 的零矩阵
| | |---> 设置 center 为 CENTER[i]
| | |
| | |---> 循环 j 从 0 到 test_x.shape[0]-1:
| | | |
| | | |---> 计算 MF 为 exp(-sum((test_x[j, :] - center) ** 2) / std)
| | | |---> 将 MF 归一化
| | | |---> 设置 t_y[j, :] 为 MF * (test_x[j, :].dot(b1))
| | |
| | |---> 设置 scaler 为 ps[i]
| | |---> 使用 scaler 变换 t_y 并将结果设置为 TT1
| | |---> 设置 yy1[:, NumRule * i:NumRule * (i + 1)] 为 TT1
| |
| |---> 将 yy1 与一个全为 0.1 的列连接起来形成 HH2
| |---> 对 HH2 dot WeightEnhan 乘以 l2 应用 tansig
| |---> 将 yy1 与 TT2 连接起来形成 TT3
| |
| |---> 计算 NetoutTest 为 TT3 dot beta
| |---> 设置 y 为 result_tra(NetoutTest)
| |---> 设置 test_yy 为 result_tra(test_y)
| |---> 计算 TestingAccuracy 为 mean(y == test_yy)
| |---> 记录测试时间
| |---> 打印 'Testing has been finished!' 和测试时间
| |---> 打印测试准确率
| |
| |---> 返回 NetoutTest, Training_time, Testing_time, TrainingAccuracy, TestingAccuracy
|
结束
在FBLS.py文件中,我们完整地复现了FBLS模型的代码,依照上面提到的算法流程一比一实现了FBLS从输入数据到输出测试结果的过程。
使用方法
在FBLS.py文件中我们已经封装好了结果,因此我们可以直接在main.py文件中调用我们想要的数据集并进行训练。
首先,我们需要把本地的数据集放入到当前目录中然后修改数据集名称为大家本地的数据集名称,或者给出它的绝对路径:data=loadmat(‘文件名的绝对路径’)
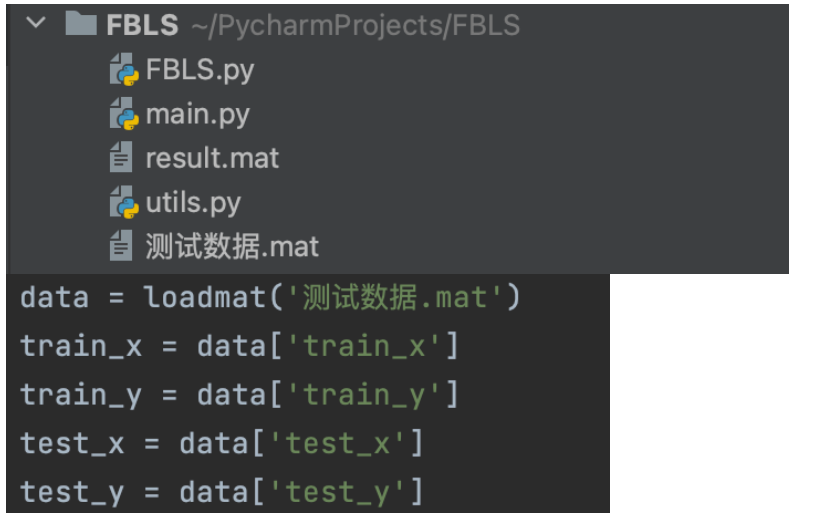
这里我们的数据集中有四个变量:train_x,train_y,test_x,test_y,分别存储的训练集的数据、标签和测试集的数据、标签,标签采用独热编码。
然后在这里,我们可以修改模型的超参数(模糊规则数、模糊节点数和增强层数量)来使我们的模型拟合到最优结果

接下来就可以得到我们输出的结果啦,训练精度、测试精度、训练时间、测试时间都会被打印出来,大家如果想多使用一些评价指标,也可以自行添加需要的指标,具体方法可以参考我之前的博客。
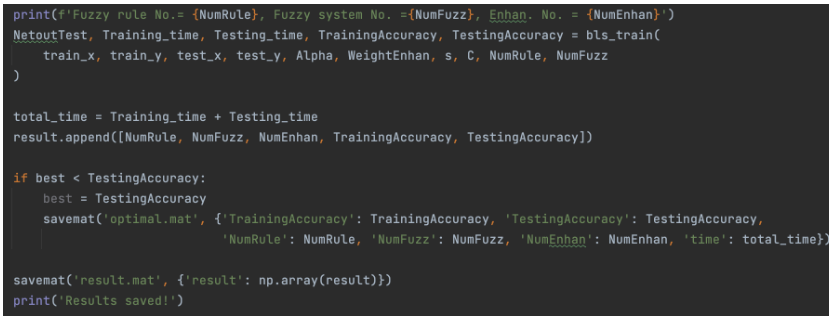
测试结果
在一次训练测试结束后,我们可以看到最后的结果,训练精度和测试精度都可以达到97%。
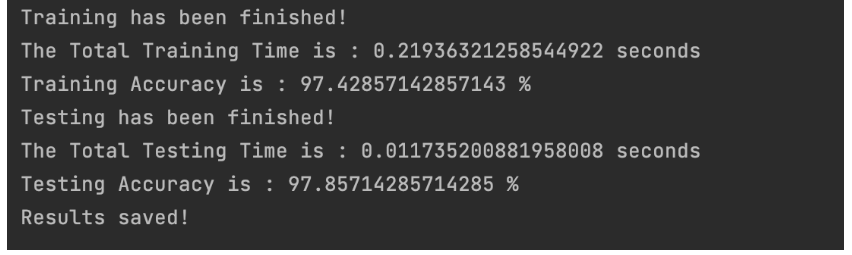
我们可以修改一下超参数,让 NumRule = 10,NumFuzz = 20,NumEnhan = 100
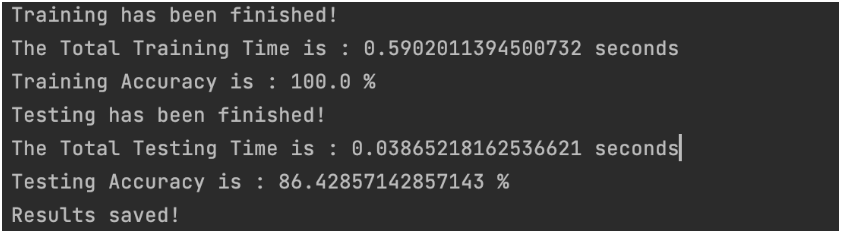
可以看到现在模型训练精度虽然达到了100%,但是测试精度出现了下降,这就说明我们参数调的太大让模型出现了过拟合现象,具体的调参大家可以根据自己的数据集来调整。
示例:使用公开数据集进行本地训练
有了复现代码之后,大家肯定很感兴趣我们应该怎么利用这个复现好的模型来在公开数据集上进行本地训练呢,这样才能推进我们的研究。这里我就以MNIST数据集为例教大家如何利用这份代码来进行在公开数据集上的训练
准备数据
首先我们需要将想要用到的数据集导入到本地环境中,
import ssl import torch from torchvision import datasets, transforms from torch.utils.data import DataLoader import pandas as pd
ssl._create_default_https_context = ssl._create_unverified_context
定义数据转换(预处理)
transform = transforms.Compose([ transforms.Resize((10, 10)), transforms.ToTensor(), # 转换为Tensor # transforms.Normalize((0.1307,), (0.3081,)) # 归一化 ])
下载并加载训练数据集
train_dataset = datasets.MNIST(root=‘./data’, train=True, download=True, transform=transform) train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
下载并加载测试数据集
test_dataset = datasets.MNIST(root=‘./data’, train=False, download=True, transform=transform) test_loader = DataLoader(dataset=test_dataset, batch_size=1000, shuffle=False)
现在很多公开数据集都提供了第三方库的内置接口,如上面的代码,我们可以很方便地直接使用代码将数据导入到本地环境中。这份MNIST公开数据集中包含70000张首先数字签名的图片,其中60000张被用作训练集,10000张被用作测试集。这里为了适应我们的模型,我们需要对图像数据做一些处理,我们将图像调整为10*10的大小,并将其按照像素点进行展平,将展平后的像素点作为每一个样本的特征,也就是说我们最后会得到训练数据格式为(60000,100),测试数据格式为(10000,100)的数据集用于实验。
将每张图片展平并检查加载的数据
examples = enumerate(train_loader) batch_idx, (example_data, example_targets) = next(examples)
将每张图片展平
flat_example_data = example_data.view(example_data.size(0), -1)
print(flat_example_data.shape) # 应该输出 (64, 784) print(example_targets.shape) # 应该输出 (64,)
将整个训练集展平
all_flat_train_data = [] all_train_targets = []
for batch_idx, (data, targets) in enumerate(train_loader): flat_data = data.view(data.size(0), -1) all_flat_train_data.append(flat_data) all_train_targets.append(targets)
all_flat_train_data = torch.cat(all_flat_train_data) all_train_targets = torch.cat(all_train_targets)
print(all_flat_train_data.shape) print(all_train_targets.shape) # 应该输出 (60000,)
将整个测试集展平
all_flat_test_data = [] all_test_targets = []
for batch_idx, (data, targets) in enumerate(test_loader): flat_data = data.view(data.size(0), -1) all_flat_test_data.append(flat_data) all_test_targets.append(targets)
all_flat_test_data = torch.cat(all_flat_test_data) all_test_targets = torch.cat(all_test_targets)
print(all_flat_test_data.shape) print(all_test_targets.shape) # 应该输出 (10000,)
将数据转换为DataFrame并保存为CSV文件
train_df = pd.DataFrame(all_flat_train_data.numpy()) train_df[‘label’] = all_train_targets.numpy() train_df.to_csv(‘mnist_train_flattened.csv’, index=False)
test_df = pd.DataFrame(all_flat_test_data.numpy()) test_df[‘label’] = all_test_targets.numpy() test_df.to_csv(‘mnist_test_flattened.csv’, index=False)
print(“数据已成功保存到CSV文件中。”)
数据输入模型进行训练
接下来我们可以选择多种方式将数据输入到模型中进行训练,我这里选择的是先将处理好的数据保存到csv文件中,然后输入的时候将其读出来导入环境中。 保存:
将数据转换为DataFrame并保存为CSV文件 train_df = pd.DataFrame(all_flat_train_data.numpy()) train_df[‘label’] = all_train_targets.numpy() train_df.to_csv(‘mnist_train_flattened.csv’, index=False) test_df = pd.DataFrame(all_flat_test_data.numpy()) test_df[‘label’] = all_test_targets.numpy() test_df.to_csv(‘mnist_test_flattened.csv’, index=False)
导入:
train_data = pd.read_csv(‘mnist_train_flattened.csv’) test_data = pd.read_csv(‘mnist_test_flattened.csv’) train_x = train_data.drop(‘label’, axis=1).values train_y = convert_onehot(train_data[‘label’].values).astype(int) test_x = test_data.drop(‘label’, axis=1).values test_y = convert_onehot(test_data[‘label’].values).astype(int)
接下来的步骤就如跟上述使用测试数据的逻辑一样
实验结果
接下来我们来看看使用FBLS进行MNIST数据集分类的效果,本次我主要测试了随着各个节点数的上升,FBLS的效果会有什么变化,结果如下图:
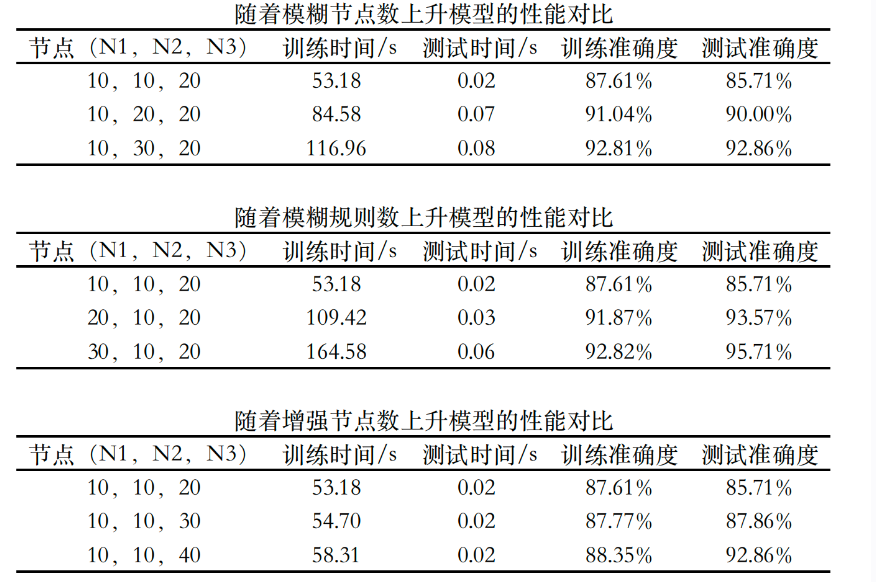
模型的分类准确率基本在90%左右,可以看到固定其他变量不变,模糊节点数、模糊规则数和增强节点数的增加都会带来模型性能的提升,但相应的训练时间也会一定程度的增加。
需要注意的是上表可以看作是对FBLS三个关键性参数的敏感性测试,FBLS的参数调节比较粗略,其分类最优值其实可以达到更优,目前我手调能达到的值已经到了97%,大家也可以多多尝试更广泛的参数看看是否可以收敛的更好,对MNIST数据集进行实验的代码我也一并放在了附件代码中,大家可以下载下来好好研究。
环境配置
- 本次使用的python版本最好为python3.8及以上- 使用的库函数包括numpy、scipy、sklearn和random
成功的路上没有捷径,只有不断的努力与坚持。如果你和我一样,坚信努力会带来回报,请关注我,点个赞,一起迎接更加美好的明天!你的支持是我继续前行的动力!"
“每一次创作都是一次学习的过程,文章中若有不足之处,还请大家多多包容。你的关注和点赞是对我最大的支持,也欢迎大家提出宝贵的意见和建议,让我不断进步。”
编程未来,从这里启航!解锁无限创意,让每一行代码都成为你通往成功的阶梯,帮助更多人欣赏与学习!
更多内容详见:这里
相关文章:
【论文复现】融入模糊规则的宽度神经网络结构
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ 融入模糊规则的宽度神经网络结构 论文概述创新点及贡献 算法流程讲解核心代码复现main.py文件FBLS.py文件 使用方法测试结果示例:…...

sql server 获取当前日期的时间戳
SQL Server 获取当前日期的时间戳 在 SQL Server 中,可以使用 GETDATE() 函数获取当前日期和时间。如果想要获取当前日期的时间戳,可以将日期转换为 UNIX 时间戳格式。本文将介绍如何在 SQL Server 中获取当前日期的时间戳,并提供示例代码。 …...

LLM PPT Translator
LLM PPT Translator 引言Github 地址UI PreviewTranslated Result Samples 引言 周末开发了1个PowerPoint文档翻译工具,上传PowerPoint文档,指定想翻译的目标语言,通过LLM的能力将文档翻译成目标语言的文档。 Github 地址 https://github.…...

铲屎官进,2024年宠物空气净化器十大排行,看看哪款吸毛最佳?
不知道最近换毛季,铲屎官们还承受的住吗?我家猫咪每天都在表演“天女散花”,家里没有一块干净的地方,空气中也都是堆积的浮毛,幸好有宠物空气净化器这种清理好物。宠物空气净化器针对宠物浮毛设计,可以有效…...

python 中常用的定积分求解方法
【例1】 解:本例题使用 Scipy 科学计算库的 quad 函数,它的一般形式是 scipy.integrate.quad(f,a,b),其中 f 是积分的函数名称,a和b分别是下线和上线。 【代码如下】: import numpy as np from scipy.integrate impo…...

音视频相关的一些基本概念
音视频相关的一些基本概念 文章目录 音视频相关的一些基本概念RTTH264profile & levelI帧 vs IDRMP4 封装格式AAC封装格式TS封装格式Reference RTT TCP中的RTT指的是“往返时延”(Round-Trip Time),即从发送方发送数据开始,到…...
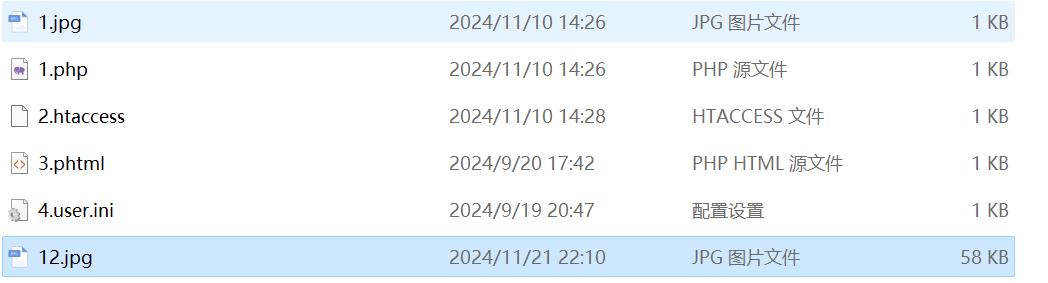
pikachu文件上传漏洞通关详解
声明:文章只是起演示作用,所有涉及的网站和内容,仅供大家学习交流,如有任何违法行为,均和本人无关,切勿触碰法律底线 目录 概念:什么是文件上传漏洞一、客户端check二、MIME type三、getimagesi…...

【拥抱AI】向量数据库有哪些常见的检索算法?
在信息检索领域,有许多常见的算法用于帮助用户从大量数据中找到相关的信息。以下是一些常见的检索算法: 布尔模型示例(文本操作) 在文本操作中,布尔模型可以通过编写一个简单的脚本来实现。例如,你可以创…...

Webpack前端工程化进阶系列(二) —— HMR热模块更新(图文+代码)
前言 之前更新过一篇Webpack文章:Webpack入门只看这一篇就够了(图文代码),没想到颇受好评,很快就阅读量就破万了hhh,应读者私信的要求,决定继续更新Webpack进阶系列的文章! 进入今天的主题 —— HMR 热模块替换(HotM…...

【RAG 项目实战 07】替换 ConversationalRetrievalChain(单轮问答)
【RAG 项目实战 07】替换 ConversationalRetrievalChain(单轮问答) NLP Github 项目: NLP 项目实践:fasterai/nlp-project-practice 介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大…...

godot游戏引擎_瓦片集和瓦片地图介绍
在 Godot 中,TileSet 和 TileMap 是用于处理瓦片地图的两个关键概念,它们的作用和用途有明显的区别。以下是两者的详细对比: 1. TileSet(瓦片集) TileSet 是资源,定义瓦片的内容和属性。 特点:…...

7、深入剖析PyTorch nn.Module源码
文章目录 1. 重要类2. add_modules3. Apply(fn)4. register_buffer5. nn.Parametersister_parameters6. 后续测试 1. 重要类 nn.module --> 所有神经网络的父类,自定义神经网络需要继承此类,并且自定义__init__,forward函数即可: #!/usr…...

如何提升编程能力第二篇
如何提升编程能力2 1. 引言2. 掌握理论基础2.1 理解编程语言的核心2.2 数据结构与算法2.3 计算机基础与系统设计3.1 多写代码3.2 参与开源项目3.3 开发自己的项目 4. 提高代码质量4.1 代码风格与可读性4.2 测试驱动开发 1. 引言 编程是推动现代科技发展的核心技能,…...

问:SpringBoot核心配置文件都有啥,怎么配?
在SpringBoot的开发过程中,核心配置文件扮演着至关重要的角色。这些文件用于配置应用程序的各种属性和环境设置,使得开发者能够灵活地定制和管理应用程序的行为。本文将探讨SpringBoot的核心配置文件,包括它们的作用、区别,并通过…...

RHCSA作业
课后练习 将整个 /etc 目录下的文件全部打包并用 gzip 压缩成/back/etcback.tar.gz [rootlocalhost ~]# tar -czvf /back/etcback.tar.gz -C / etc 使当前用户永久生效的命令别名:写一个命令命为hello,实现的功能为每输入一次hello命令,就有hello&#…...
——SoftwareTimer)
ESP32学习笔记_FreeRTOS(3)——SoftwareTimer
摘要(From AI): 这篇笔记全面介绍了 FreeRTOS 软件定时器的核心概念和使用方法,包括定时器的创建、管理、常用 API 和辅助函数,并通过示例代码演示了如何启动、重置和更改定时器的周期。它强调了软件定时器的灵活性、平台无关性以及与硬件定时器的对比 …...

文心一言与千帆大模型平台的区别:探索百度AI生态的双子星
随着人工智能技术的迅猛发展,越来越多的公司开始投入资源开发自己的AI解决方案。在中国,百度作为互联网巨头之一,不仅在搜索引擎领域占据重要位置,还在AI领域取得了显著成就。其中,“文心一言”和“千帆大模型平台”便…...

【c语言】文件操作详解 - 从打开到关闭
文章目录 1. 为什么使用文件?2. 什么是文件?3. 如何标识文件?4. 二进制文件和文本文件?5. 文件的打开和关闭5.1 流和标准流5.1.1 流5.1.2 标准流 5.2 文件指针5.3 文件的打开和关闭 6. 文件的读写顺序6.1 顺序读写函数6.2 对比一组…...

Flink Sink的使用
经过一系列Transformation转换操作后,最后一定要调用Sink操作,才会形成一个完整的DataFlow拓扑。只有调用了Sink操作,才会产生最终的计算结果,这些数据可以写入到的文件、输出到指定的网络端口、消息中间件、外部的文件系统或者是…...

pcl::PointCloud<PointType>::Ptr extractedCloud; 尖括号里的值表示什么含义?
在C中,pcl::PointCloud<PointType>::Ptr是一种智能指针,它是Point Cloud Library (PCL)中用于管理pcl::PointCloud对象的智能指针类型。这里的<pcl::PointCloud<PointType>::Ptr>尖括号里的值表示智能指针所指向的对象类型。 让我们分…...
)
RK3568安卓11系统定制指南:如何快速修改设备名、型号和时区(附常见问题解决)
RK3568安卓11系统深度定制:从设备标识到时区配置的实战手册 每次接手一个新的RK3568项目,总免不了要重新折腾一遍设备信息的配置。明明上次在某个mk文件里改过设备名,这次却要花半小时翻遍整个device/rockchip目录;好不容易编译完…...

Qwen2.5-VL-7B-Instruct效果对比:不同分辨率输入对图文理解精度影响实测
Qwen2.5-VL-7B-Instruct效果对比:不同分辨率输入对图文理解精度影响实测 1. 测试背景与目的 Qwen2.5-VL-7B-Instruct作为新一代多模态视觉-语言模型,在图文理解任务中展现出强大能力。但在实际应用中,我们发现输入图像的分辨率会显著影响模…...

BGE Reranker-v2-m3惊艳效果:同一查询下相似文本的细微语义差异被精准识别并排序
BGE Reranker-v2-m3惊艳效果:同一查询下相似文本的细微语义差异被精准识别并排序 1. 核心能力展示:细微差异的精准捕捉 BGE Reranker-v2-m3最令人惊艳的能力在于,它能够识别同一查询下高度相似文本之间的细微语义差异,并给出精准…...

AI For Trusted Code|泛联新安:以“AI+可信”构筑智能时代基石
当前,两会正在北京隆重举行,“人工智能”与“新质生产力”再度成为全场焦点,深化AI应用、筑牢安全底座的热潮席卷各行各业。展望2026年,人工智能将从“辅助探索”全面迈向“核心重构”。AI不仅改变了内容的生产方式,更…...

机械臂关节空间的五次非均匀B样条轨迹规划:Matlab实现与应用
机械臂关节空间轨迹规划,五次非均匀B样条轨迹规划采用matlab函数编写而成,简单易用,替换自己关节值就能用。在机器人领域,机械臂的轨迹规划是至关重要的一环。今天咱们就来讲讲机械臂关节空间的五次非均匀B样条轨迹规划࿰…...

深入理解Polymer-bundler工作原理:从源码解析到bundle manifest生成
深入理解Polymer-bundler工作原理:从源码解析到bundle manifest生成 【免费下载链接】polymer-bundler Moved to Polymer/tools monorepo 项目地址: https://gitcode.com/gh_mirrors/po/polymer-bundler Polymer-bundler是一款高效的前端资源打包工具&#…...

SSHKit高级技巧:自定义输出格式化与日志管理提升部署可见性
SSHKit高级技巧:自定义输出格式化与日志管理提升部署可见性 【免费下载链接】sshkit A toolkit for deploying code and assets to servers in a repeatable, testable, reliable way. 项目地址: https://gitcode.com/gh_mirrors/ss/sshkit SSHKit是一款强大…...

X-AnyLabeling革命性评测:AI标注工具如何重塑数据标注产业格局
X-AnyLabeling革命性评测:AI标注工具如何重塑数据标注产业格局 【免费下载链接】X-AnyLabeling Effortless data labeling with AI support from Segment Anything and other awesome models. 项目地址: https://gitcode.com/gh_mirrors/xa/X-AnyLabeling 在…...

leetcode 1357. Apply Discount Every n Orders 每隔 n 个顾客打折-耗时100
Problem: 1357. Apply Discount Every n Orders 每隔 n 个顾客打折 耗时100%,用哈希表存储每种产品对应的价格prod,然后计算总和即可 Code class Cashier { public:int prod[201], nn, cnt 0;double disc;Cashier(int n, int discount, vector<int&…...
)
新手必看!VL812 USB3.0扩展坞四层板PCB设计全流程(附嘉立创EDA工程)
从零到一:基于VL812的USB 3.0扩展坞四层PCB实战设计指南 你是否曾对电脑上那永远不够用的USB接口感到烦恼?是否想过自己动手,打造一个性能稳定、外观独特的USB扩展坞?对于硬件爱好者而言,从原理图到一块沉甸甸的PCB板&…...