利用 Jsoup 进行高效 Web 抓取与 HTML 处理
Jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 JQuery 的操作方法来取出和操作数据。
官网:https://jsoup.org/
中文文档:Jsoup 快速入门 | JAVA-TUTORIAL
1. Jsoup相关概念
1. Document
- 定义:Document 对象表示整个 HTML 文档。
- 用途:用于解析 HTML 字符串或从 URL 获取 HTML 内容。
2. Element
- 定义:Element 对象表示 HTML 中的一个标签元素。
- 用途:用于选择和操作具体的 HTML 元素。
3. Elements
- 定义:Elements 对象是一个 Element 对象的集合。
- 用途:用于存储多个匹配的元素。
4. Node
- 定义:Node 是 Element 和 Text 的基类,表示 HTML 文档中的节点。
- 用途:用于更细粒度的操作,如处理注释、文档类型声明等。
5. TextNode
- 定义:TextNode 表示 HTML 文档中的纯文本节点。
- 用途:用于处理元素内的文本内容。
6. CSS 选择器
- 定义:CSS 选择器是一种用于选择 HTML 元素的语法。
- 用途:用于精确选择文档中的特定元素。
- 常用选择器:
- #id:选择具有指定 ID 的元素。
- .class:选择具有指定类的元素。
- tag:选择指定标签的元素。
- tag[attr]:选择具有指定属性的元素。
- tag[attr=value]:选择具有指定属性值的元素。
7. 连接和请求
- 定义:Jsoup 提供了连接到 URL 并获取 HTML 文档的功能。
- 用途:用于从远程服务器获取 HTML 内容。
2. Jsoup 的优点
1. 易用性:
- 简洁的 API:Jsoup 提供了非常简洁和直观的 API,使得开发者可以快速上手。
- 链式调用:支持链式调用,使代码更加简洁和可读。
2. 强大的解析能力:
- HTML 解析:能够解析不规范的 HTML,即使 HTML 结构不完整也能正确解析。
- CSS 选择器:支持类似于 jQuery 的 CSS 选择器,方便提取和操作 HTML 元素。
3. 网络请求:
- HTTP 请求:内置了简单的 HTTP 客户端,可以方便地发送 GET 和 POST 请求。
- 自动处理重定向:支持自动处理 HTTP 重定向。
4. 安全性:
- HTML 清洗:提供了 Jsoup.clean 方法,可以清理 HTML 以防止 XSS 攻击,确保输出的安全性。
3. Jsoup 的缺点
1. 性能问题:
- 内存消耗:在处理大文件或大量数据时,Jsoup 可能会消耗较多的内存,尤其是在解析复杂的 HTML 文档时。
- 速度较慢:与一些低级别的解析库相比,Jsoup 的解析速度可能稍慢,特别是在高并发场景下。
2. 功能限制:
- 有限的 HTTP 功能:虽然内置了 HTTP 客户端,但功能相对简单,对于复杂的需求(如多线程请求、高级认证等)可能需要额外的库支持。
- 缺乏高级特性:相比于一些更专业的爬虫框架(如 Scrapy),Jsoup 缺乏一些高级特性,如分布式爬取、自动反爬机制等。
3. 依赖管理:
- 依赖项:Jsoup 本身依赖较少,但在实际项目中可能需要引入其他库来补充其功能,增加了项目的复杂性。
4. 错误处理:
- 异常处理:Jsoup 的异常处理机制较为简单,对于一些复杂的错误情况可能需要开发者自行处理。
4. 执行流程

4.1. 添加依赖
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.14.3</version>
</dependency>4.2. 获取 Document
Jsoup 类方法列表:
| 方法名称 | 是否静态 | 参数 | 返回值 | 描述 |
| parse(String html) | 是 | String html | Document | 从字符串中解析 HTML 并返回一个 Document 对象。 |
| parse(File in, String charsetName) | 是 | File in, String charsetName | Document | 从文件中解析 HTML 并返回一个 Document 对象。 |
| parse(URL url, int timeoutMillis) | 是 | URL url, int timeoutMillis | Document | 从 URL 中解析 HTML 并返回一个 Document 对象。 |
| connect(String url) | 是 | String url | Connection | 创建一个新的 Connection 对象,用于发送 HTTP 请求。 |
Connection 类方法列表:
| 方法名称 | 是否静态 | 参数 | 返回值 | 描述 |
| method(Method method) | 否 | Method method | Connection | 设置请求方法(GET、POST 等)。 |
| url(URL url) | 否 | URL url | Connection | 设置请求的 URL。 |
| requestBody(String requestBody) | 否 | String requestBody | Connection | 设置请求体内容。 |
| data(String key, String value) | 否 | String key, String value | Connection | 添加表单数据。 |
| header(String key, String value) | 否 | String key, String value | Connection | 添加请求头。 |
| userAgent(String userAgent) | 否 | String userAgent | Connection | 设置 User-Agent。 |
| referrer(String referrer) | 否 | String referrer | Connection | 设置 Referer。 |
| timeout(int millis) | 否 | int millis | Connection | 设置连接超时时间(毫秒)。 |
| followRedirects(boolean follow) | 否 | boolean follow | Connection | 设置是否自动跟随重定向。 |
| ignoreHttpErrors(boolean ignore) | 否 | boolean ignore | Connection | 设置是否忽略 HTTP 错误(如 404)。 |
| ignoreContentType(boolean ignore) | 否 | boolean ignore | Connection | 设置是否忽略内容类型检查。 |
| maxBodySize(int maxSize) | 否 | int maxSize | Connection | 设置响应体的最大大小(字节)。 |
| cookie(String key, String value) | 否 | String key, String value | Connection | 添加 Cookie。 |
| cookies(Map<String, String> cookies) | 否 | Map<String, String> cookies | Connection | 添加多个 Cookie。 |
| execute() | 否 | 无 | Connection.Response | 执行请求并返回响应对象。 |
| get() | 否 | 无 | Document | 发送 GET 请求并返回解析后的 Document 对象。 |
| post() | 否 | 无 | Document | 发送 POST 请求并返回解析后的 Document 对象。 |
Connection.Response 类方法列表:
| 方法名称 | 是否静态 | 参数 | 返回值 | 描述 |
| body() | 否 | 无 | String | 获取响应体内容。 |
| parse() | 否 | 无 | Document | 解析响应体为 Document 对象。 |
| statusCode() | 否 | 无 | int | 获取响应状态码。 |
| statusMessage() | 否 | 无 | String | 获取响应状态消息。 |
| url() | 否 | 无 | URL | 获取最终请求的 URL(可能经过重定向)。 |
| headers() | 否 | 无 | Map<String, List<String>> | 获取响应头。 |
| header(String key) | 否 | String key | String | 获取指定响应头的值。 |
| cookies() | 否 | 无 | Map<String, String> | 获取响应中的 Cookie。 |
| cookie(String key) | 否 | String key | String | 获取指定 Cookie 的值。 |
4.3. 获取Element 或 Elements 及 文本内容
Document 类方法列表:
| 方法名称 | 是否静态 | 参数 | 返回值 | 描述 |
| title() | 否 | 无 | String | 获取文档的标题。 |
| select(String cssQuery) | 否 | String cssQuery | Elements | 使用 CSS 选择器选择元素。 |
| getElementsByTag(String tagName) | 否 | String tagName | Elements | 获取指定标签名的所有元素。 |
| getElementById(String id) | 否 | String id | Element | 获取指定 ID 的元素。 |
| html() | 否 | 无 | String | 获取文档的 HTML 内容。 |
| text() | 否 | 无 | String | 获取文档的文本内容。 |
Elements 类方法列表:
| 方法名称 | 是否静态 | 参数 | 返回值 | 描述 |
| first() | 否 | 无 | Element | 获取第一个元素。 |
| last() | 否 | 无 | Element | 获取最后一个元素。 |
| size() | 否 | 无 | int | 获取元素的数量。 |
| get(int index) | 否 | int index | Element | 获取指定索引的元素。 |
| eachText() | 否 | 无 | List<String> | 获取所有元素的文本内容列表。 |
| eachAttr(String attributeKey) | 否 | String attributeKey | List<String> | 获取所有元素的指定属性值列表。 |
Element 类方法列表:
| 方法名称 | 是否静态 | 参数 | 返回值 | 描述 |
| attr(String key) | 否 | String key | String | 获取元素的属性值。 |
| removeAttr(String key) | 否 | String key | Element | 移除元素的属性。 |
| addClass(String className) | 否 | String className | Element | 添加 CSS 类。 |
| removeClass(String className) | 否 | String className | Element | 移除 CSS 类。 |
| text() | 否 | 无 | String | 获取元素的文本内容。 |
| html() | 否 | 无 | String | 获取元素的 HTML 内容。 |
| append(String html) | 否 | String html | Element | 在元素末尾追加 HTML。 |
| prepend(String html) | 否 | String html | Element | 在元素开头插入 HTML。 |
| select(String cssQuery) | 否 | String cssQuery | Elements | 使用 CSS 选择器选择子元素。 |
5. CSS 选择器
5.1. 基本选择器
1. 标签选择器
- 选择所有 <div> 标签:div
- 选择所有 <a> 标签:a
2. 类选择器
- 选择所有带有 class="example" 的元素:.example
3. ID 选择器
- 选择 ID 为 example 的元素:#example
4. 属性选择器
- 选择所有带有 href 属性的 <a> 标签:a[href]
- 选择所有 href 属性值为 http://example.com 的 <a> 标签:a[href="http://example.com"]
- 选择所有 href 属性值包含 example 的 <a> 标签:a[href*="example"]
- 选择所有 href 属性值以 http 开头的 <a> 标签:a[href^="http"]
- 选择所有 href 属性值以 .html 结尾的 <a> 标签:a[href$=".html"]
- 选择所有 src 属性值匹配正则表达式的 <img> 标签:img[src~=(?i)(png|jpe?g)]
5. 命名空间选择器
- 选择所有在 fb 命名空间中的 name 标签:fb|name
6. 通配符选择器
- 选择所有元素:*
5.2. 组合选择器
1. 后代选择器
- 选择所有在 <div> 内部的 <p> 标签:div p
2. 子选择器
- 选择所有直接在 <div> 内部的 <p> 标签:div > p
3. 相邻兄弟选择器
- 选择所有紧接在 <h1> 后面的 <p> 标签:h1 + p
4. 通用兄弟选择器
- 选择所有在 <h1> 后面的 <p> 标签:h1 ~ p
5. 元素+ID
- 选择所有带有 ID 为 logo 的 <div> 标签:div#logo
6. 元素+类
- 选择所有带有 class="title" 的 <div> 标签:div.title
7. 元素+属性
- 选择所有带有 href 属性的 <a> 标签:a[href]
8. 多个类选择器
- 选择所有同时带有 class="info" 和 class="active" 的元素:.info.active
9. 多个选择器组合
- 选择所有带有 class="highlight" 且带有 href 属性的 <a> 标签:a[href].highlight
5.3. 伪类选择器
1. 索引选择器
- 选择索引值小于 3 的 <td> 标签:td:lt(3)
- 选择索引值大于 2 的 <p> 标签:div p:gt(2)
- 选择索引值等于 1 的 <input> 标签:form input:eq(1)
2. 包含选择器
- 选择包含 <p> 标签的 <div> 标签:div:has(p)
- 选择不包含 class="logo" 的所有 <div> 标签:div:not(.logo)
3. 文本匹配选择器
- 选择包含文本 jsoup 的 <p> 标签:p:contains(jsoup)
- 选择直接包含文本 jsoup 的 <p> 标签:p:containsOwn(jsoup)
4. 正则表达式匹配选择器
- 选择文本匹配正则表达式的 <div> 标签:div:matches((?i)login)
- 选择自身包含文本匹配正则表达式的 <div> 标签:div:matchesOwn((?i)login)
6. 实战示例
以爬取 https://ssr3.scrape.center/ 这个网站为例:
1. 获取所有电影信息。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.http.HttpHeaders;import java.io.IOException;@SpringBootTest
public class JsoupTests {@Testpublic void testJsoup() throws IOException {String url = "https://ssr3.scrape.center/";Document document = Jsoup.connect(url).header(HttpHeaders.AUTHORIZATION, "Basic YWRtaW46YWRtaW4=").get();// 解析电影信息Elements movieItems = document.select(".el-card__body");for (Element item : movieItems) {// 提取电影名称和链接Element nameLink = item.select("a.name").first();if (nameLink != null) {String movieName = nameLink.select("h2").text();String movieUrl = nameLink.attr("href");// 提取电影封面URLElement coverImage = item.select("img.cover").first();String coverImageUrl = coverImage != null ? coverImage.attr("src") : "N/A";// 提取电影类别String category = item.select(".el-button.category").text();// 提取国家和片长Elements infoElements = item.select(".info");String countryAndDuration = infoElements.get(0).text();String[] parts = countryAndDuration.split(" / ");String country = parts[0];String duration = parts[1];// 提取上映日期String releaseDate = infoElements.get(1).text();// 提取评分String score = item.select(".score").text();// 提取星级评分String starRating = item.select(".el-rate").attr("aria-valuenow");// 打印提取的信息System.out.println("电影名称: " + movieName);System.out.println("电影链接: " + movieUrl);System.out.println("电影封面URL: " + coverImageUrl);System.out.println("电影类别: " + category);System.out.println("国家: " + country);System.out.println("片长: " + duration);System.out.println("上映日期: " + releaseDate);System.out.println("评分: " + score);System.out.println("星级评分: " + starRating);System.out.println("----------------------------");}}}
}测试结果为:

2. 打印所有电影的电影类别、国家和片长、上映日期、评分、星级评分、总条数及页面链接
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.http.HttpHeaders;import java.io.IOException;@SpringBootTest
public class JsoupTests {public static void main(String[] args) {String url = "https://ssr3.scrape.center/";try {// 连接并获取文档Document document = Jsoup.connect(url).header("Authorization", "Basic YWRtaW46YWRtaW4=").get();// 提取电影类别Elements categoryButtons = document.select(".el-button.category");for (Element button : categoryButtons) {System.out.println("电影类别: " + button.text());}// 提取国家和片长Elements infoDivs = document.select(".info");for (Element div : infoDivs) {System.out.println("国家和片长: " + div.text());}// 提取上映日期Elements releaseDateDivs = document.select(".info:contains(上映)");for (Element div : releaseDateDivs) {System.out.println("上映日期: " + div.text());}// 提取评分Elements scoreElements = document.select(".score");for (Element score : scoreElements) {System.out.println("评分: " + score.text());}// 提取星级评分Elements rateElements = document.select(".el-rate");for (Element rate : rateElements) {int fullStars = rate.select(".el-rate__icon.el-icon-star-on").size();int halfStar = rate.select(".el-rate__decimal.el-icon-star-on").size();double rating = fullStars + (halfStar > 0 ? 0.5 : 0);System.out.println("星级评分: " + rating);}// 提取分页信息Element pagination = document.select(".el-pagination").first();if (pagination != null) {String totalItems = pagination.select(".el-pagination__total").text();System.out.println("总条数: " + totalItems);Elements pageLinks = pagination.select(".el-pager li.number a");for (Element link : pageLinks) {System.out.println("页面链接: " + link.attr("href"));}}} catch (IOException e) {e.printStackTrace();}}
}打印结果:
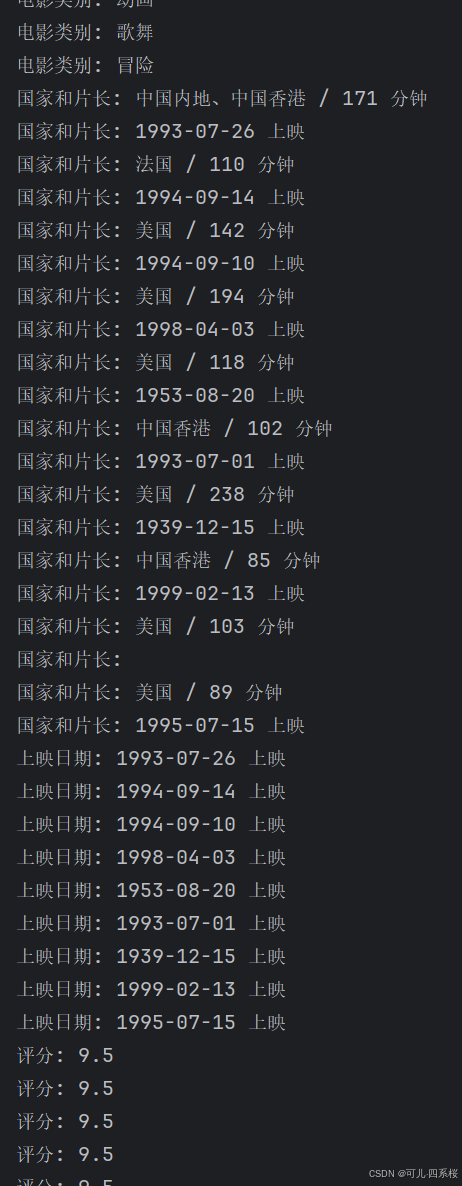
相关文章:
利用 Jsoup 进行高效 Web 抓取与 HTML 处理
Jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 JQuery 的操作方法来取出和操作数据。 官网:https://jsoup.org/ 中文文档:Jsou…...

【Java】二叉树:数据海洋中灯塔式结构探秘(上)
个人主页 🌹:喜欢做梦 二叉树中有一个树,我们可以猜到他和树有关,那我们先了解一下什么是树,在来了解一下二叉树 一🍝、树型结构 1🍨.什么是树型结构? 树是一种非线性的数据结构&…...

微信小程序 WXS 的概念与基本用法教程
微信小程序 WXS 的概念与基本用法教程 引言 在微信小程序的开发中,WXS(WeiXin Script)是一种特殊的脚本语言,旨在解决小程序在逻辑处理和数据处理上的一些限制。WXS 允许开发者在小程序的 WXML 中嵌入 JavaScript 代码,以便实现更复杂的逻辑处理。本文将深入探讨 WXS 的…...

Vue.js 中 v-bind 和 v-model 的用法与异同
简介 在 Vue.js 中,v-bind 和 v-model 是两个非常常用且强大的指令,它们分别用于动态地绑定属性和实现双向数据绑定。理解这两个指令的用法和区别对于构建 Vue.js 应用至关重要。本文将详细介绍 v-bind 和 v-model 的用法,并探讨它们的异同。…...

K8s的水平自动扩容和缩容HPA
HPA全称是Horizontal Pod Autoscaler,翻译成中文是POD水平自动伸缩,HPA可以基于CPU利用率对replication controller、deployment和replicaset中的pod数量进行自动扩缩容(除了CPU利用率也可以基于其他应程序提供的度量指标custom metrics进行自…...

【AI日记】24.11.26 聚焦 kaggle 比赛
【AI论文解读】【AI知识点】【AI小项目】【AI战略思考】【AI日记】 核心工作 1 内容:研究 kaggle 比赛时间:3 小时 核心工作 2 内容:学习 kaggle 比赛 Titanic - Machine Learning from Disaster时间:4 小时备注:这…...
大型语言模型LLM - Finetuning vs Prompting
资料来自台湾大学李宏毅教授机器学课程ML 2023 Spring,如有侵权请通知下架 台大机器学课程ML 2023 Springhttps://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.php2023/3/10 课程 機器如何生成文句 内容概要 主要探讨了大型语言模型的两种不同期待及其导致的两类…...

【IEEE独立出版 | 厦门大学主办】第四届人工智能、机器人和通信国际会议(ICAIRC 2024,12月27-29日)
第四届人工智能、机器人和通信国际会议(ICAIRC 2024) 2024 4th International Conference on Artificial Intelligence, Robotics, and Communication 重要信息 会议官网:www.icairc.net 三轮截稿时间:2024年11月30日23:59 录…...

【GPT】力量训练是什么,必要吗,有可以替代的方式吗
什么是力量训练? 力量训练是一种通过抵抗力(如重量、阻力带、自身体重等)来刺激肌肉收缩,从而提高肌肉力量、耐力和体积的运动形式。它包括以下常见形式: 自由重量训练:使用哑铃、杠铃、壶铃等。固定器械…...
【03】Selenium+Python 八种定位元素方法
操作元素,需要先查找定位到对应的元素。 查找单个元素:driver.find_element() 返回是一个web element 对象 查找多个元素:driver.find_elements() 返回是一个list对象 By 是 Selenium 中一个非常重要的类,用于定位网页元素。 使…...

笔记:jQuery追加js时会自动加“_时间戳“参数,导致百度统计失败
问题描述: $(document.createElement("script")).attr(id, baidutj).attr(src, https://hm.baidu.com/hm.js?xxx).appendTo(body); 会自动给src加_时间戳的参数? 问题解疑: 【未完待续…】 问题解决: 老老实实按它…...

【PyTorch】(基础二)---- 张量
张量 在 PyTorch 中,张量(Tensor)是核心数据结构,类似于 NumPy 中的数组,但具有更强的计算能力和对 GPU 的支持。 创建 从列表或数组创建 import torch# 从列表创建 tensor_from_list torch.tensor([1, 2, 3, 4])…...

充满智慧的埃塞俄比亚狼
非洲的青山 随着地球温度上升,贝尔山顶峰的冰川消失殆尽,许多野生动物移居到海拔3000米以上的高原上生活,其中就包括埃塞俄比亚狼。埃塞俄比亚狼是埃塞俄比亚特有的动物,总数不到500只,为“濒危”物种。 埃塞俄比亚狼…...
基于STM32设计的智能桌面暖风机(华为云IOT)
一、前言 1.1 项目开发背景 随着智能家居技术的迅猛发展,传统家用电器正逐步向智能化方向转型。暖风机作为冬季广泛使用的取暖设备,其智能化升级不仅能够提高用户的使用体验,还能通过物联网技术实现远程控制和数据监控,赋予其更…...

零基础学安全--云技术基础
目录 学习连接 前言 云技术历史 云服务 公有云服务商 云分类 基础设施即服务(IaaS) 平台即服务(PaaS) 软件即服务(SaaS) 云架构 虚拟化 容器 云架构设计 组件选择 基础设施即代码 集成部署…...

Spring Boot中配置Flink的资源管理
在 Spring Boot 中配置 Flink 的资源管理,需要遵循以下步骤: 添加 Flink 依赖项 在你的 pom.xml 文件中,添加 Flink 和 Flink-connector-kafka 的依赖项。这里以 Flink 1.14 版本为例: <!-- Flink dependencies --><de…...
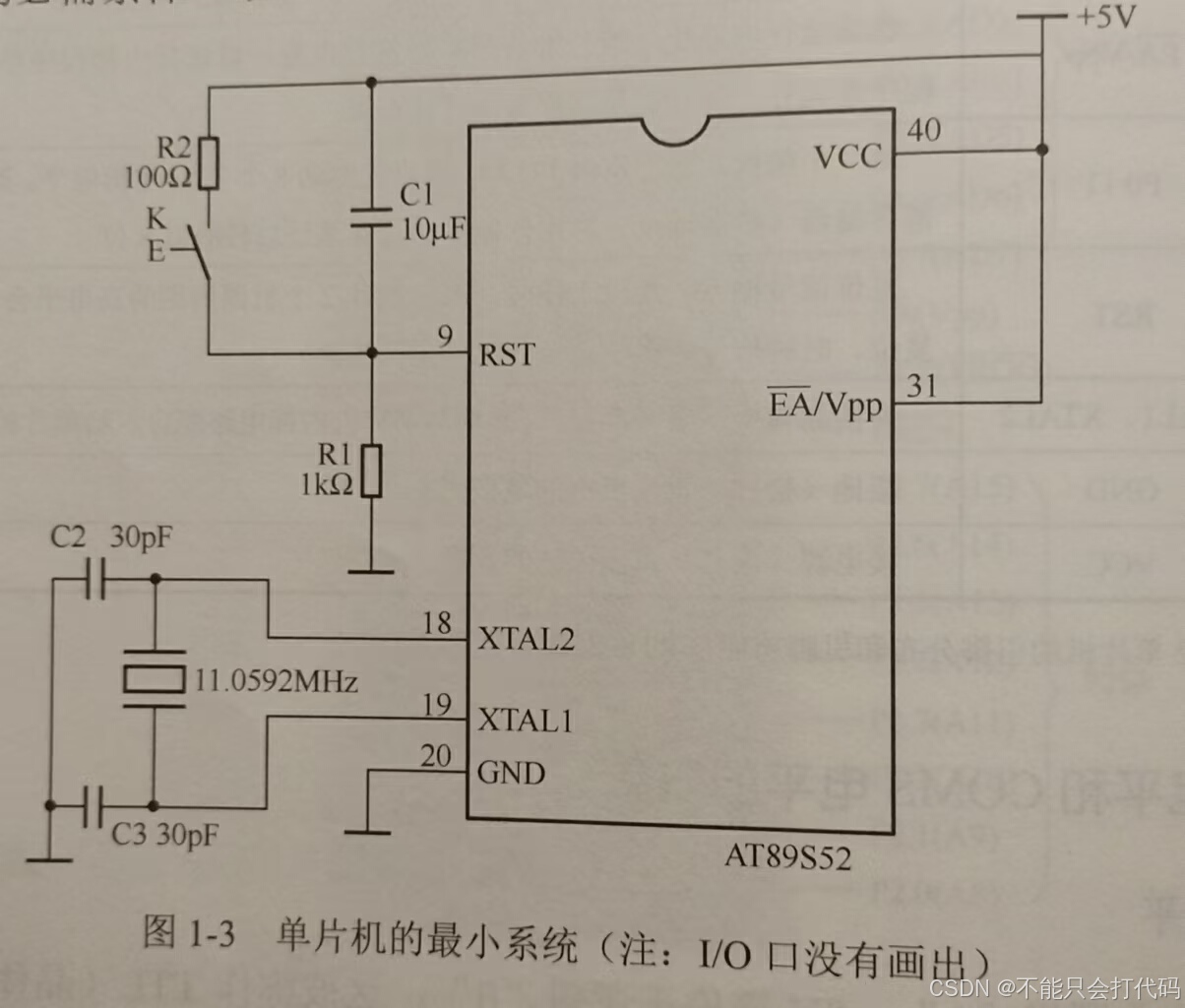
51单片机从入门到精通:理论与实践指南入门篇(二)
续51单片机从入门到精通:理论与实践指南(一)https://blog.csdn.net/speaking_me/article/details/144067372 第一篇总体给大家在(全局)总体上讲解了一下51单片机,那么接下来几天结束详细讲解,从…...
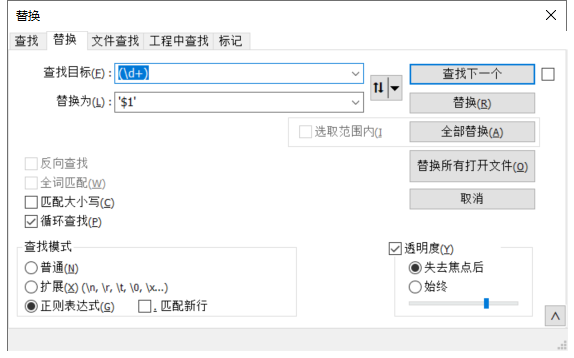
Notepad++ 替换所有数字给数字加单引号
前言 今天遇到这样一个场景: 要去更新某张表里 code1,2,3,4,5,6 的数据,把它的 name 设置为 ‘张三’ 但是 code在数据库里面的字段类型是 vachar(64),它自身携带索引 原本可以这样写 SQL: update tableA set namezhangsan where code in …...

【CANOE】【Capl】【RS232】控制串口设备
系列文章目录 内置函数,来控制传统的串口设备,比如继电器等 文章目录 系列文章目录前言一、控制串口二、自定义相关的参数RS232Configure**函数语法****函数功能****参数说明****返回值****示例代码** 三、回调函数的使用RS232OnSend**函数语法****函数…...

查找相关题目
1.顺序查找法适合于存储结构为(B )的线性表。 A.散列存储 B.顺序存储或链式存储 C.压缩存储 D.索引存储 顺序查找法的特点 2.适用于折半查找的表的存储方式及元素排列要求为(D ) 。 A.链接方式存储,元素无序 B.链接方式存储࿰…...

eSearch一站式屏幕效率工具安装指南
eSearch一站式屏幕效率工具安装指南 【免费下载链接】eSearch 截屏 离线OCR 搜索翻译 以图搜图 贴图 录屏 万向滚动截屏 屏幕翻译 Screenshot Offline OCR Search Translate Search for picture Paste the picture on the screen Screen recorder Omnidirectional scrolling sc…...

Git【多人协作一】
目前,基本上可以完成的工作如下:基本完成Git的所有本地库的相关操作,git 基本操作,分支理解,版本回退,冲突解决等等申请码云账号,将远端信息clone到本地,以及推送和力量去。但是&…...

PlotJuggler颜色映射终极指南:如何创建惊艳的数据可视化效果
PlotJuggler颜色映射终极指南:如何创建惊艳的数据可视化效果 【免费下载链接】PlotJuggler The Time Series Visualization Tool that you deserve. 项目地址: https://gitcode.com/gh_mirrors/pl/PlotJuggler PlotJuggler是一款功能强大的时间序列数据可视化…...

uni-app Android应用华为审核隐私权限提示与上架授权说明实战指南
1. uni-app Android应用华为审核隐私权限问题解析 第一次用uni-app开发Android应用准备上架华为市场时,我被审核驳回的理由整懵了——"缺少权限使用说明"。明明iOS版本在manifest.json配得好好的,怎么到Android就出问题?后来才发现…...

2026上海紧固件专业展观察:12.9级螺栓为何成为高端制造核心紧固方案?
2026第十六届上海紧固件专业展(Fastener Expo Shanghai 2026)将于6月24日至26日在上海国家会展中心举办。作为紧固件行业的重要展示窗口,本届展会将集中呈现高强度紧固件的发展趋势,其中12.9级螺栓已成为当前制造业升级的重要标志…...

RMBG-1.4开源模型解析:AI净界如何实现SOTA级Alpha通道生成
RMBG-1.4开源模型解析:AI净界如何实现SOTA级Alpha通道生成 你有没有遇到过这样的烦恼?想给产品换个背景,结果抠出来的图边缘全是锯齿;想给自己做一张透明背景的证件照,头发丝却和背景糊在一起;或者想用AI生…...

Winhance中文版深度解析:Windows系统优化的C解决方案
Winhance中文版深度解析:Windows系统优化的C#解决方案 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh…...

15 分钟上线|开源克隆网站 + 一键部署,搭建你自己的产品
把目标网站像素级克隆下来,再用部署技能把它一键部署到线上。全程主要靠自然语言对话完成,不需要命令行操作,不需要懂代码。你要做的只有一件事:把“你想复制哪个网站、要怎么上线”说清楚,其它交给 AI 去检测、拆解、…...

终极Cursor Pro解锁指南:免费体验AI编程助手的完整解决方案
终极Cursor Pro解锁指南:免费体验AI编程助手的完整解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...

终极B站界面美化指南:如何用BewlyBewly插件快速打造个性化体验
终极B站界面美化指南:如何用BewlyBewly插件快速打造个性化体验 【免费下载链接】BewlyBewly Just make a few small changes to your Bilibili homepage. (English | 简体中文 | 正體中文 | 廣東話) 项目地址: https://gitcode.com/gh_mirrors/be/BewlyBewly …...