从Full-Text Search全文检索到RAG检索增强
从Full-Text Search全文检索到RAG检索增强
时光飞逝,转眼间六年过去了,六年前铁蛋优化单表千万级数据查询性能的场景依然历历在目,铁蛋也从最开始做CRUD转行去了大数据平台开发,混迹包装开源的业务,机缘巧合下做了实时数据集成入湖,对传统Java的栈和大数据栈以及他们之间的衔接层有了比较全面的了解。现如今大模型业务蓬勃发展,铁蛋也想乘着这波东风谋求更好的发展,最近刚开始接触这块的技术,对RAG相关的技术比较感兴趣,但是一直没有很了解这里面的关系,这玩意搞不清楚就很难受, 于是铁蛋决定袖子一撸,干他完了。

事情还得从最开始说起,第一次接触到RAG是听说大模型在回答一些领域特定知识or一些时效性的数据的时候容易出现幻觉(胡说八道)。For Example:

看到这个回答铁蛋老师都快要吐血了,你说你不知道一个有名的程序员王铁蛋也好, 别说成是铁蛋机器人呀!!!

压压上升的血压后铁蛋定睛一看原来这些知识都来源于外部知识(网页搜索),看来还是自己不够有名呀,模型本身的数据中不包含自己就算了,网上也搜不到,这个气呀!!!!
气归气,闹归闹,学习知识最重要
铁蛋仔细回忆了下,在国内问答模型发展之初,林黛玉倒拔垂杨柳的问题很生动的展示了模型的幻觉问题,它可以把两个完全不想干的事一本正经的给串联起来,返回给发问的用户, 这一次是铁蛋自己本身的遭遇。
好了,到这我们对RAG在智能问答中发挥的作用有了一丝感觉了,记住这个感觉我们继续往下探索。

铁蛋现在心里有个感觉就是RAG检索增强就是个方案,简单点就是:RAG = 搜索 + 模型总结,此时铁蛋心里就又有疑惑了,既然是搜索+总结那为什么老是听到有人说向量检索呢?这中间到底有什么不为人知的秘密?

大家再回忆下自己平时是怎么使用搜素引擎的,在一个输入框中输入一段想要搜索的内容的描述,搜索引擎返回一个一个的搜索结果列表,按照匹配的程度从高到低排序(有钱插队的忽略,广告创收的也忽略,当然现在的搜索引擎也是融合了多种搜索技术的混合搜素,大家不用太较真,能说明问题即可),然后我们自己再去一个一个甄别哪一个或者哪几个是我们需要的,在智能问答的时代,结合搜索+总结的能力,我们的搜索习惯变成了向模型发问,模型自己去搜索,然后将搜索出来的结果进行汇总整合成一个完整的逻辑来回答我们的发问,在这个过程中我们可以一直进行追问和补充描述让模型的回答更加的准确或者说更加符合我们的预期。 技术的发展带来了用户行为的改变, look like this:


铁蛋心想如果事情只是这样的话,原本自己搞过的全文检索能力,配合模型总结能力已经能够满足RAG的方案了,那这里面还有向量检索什么事?
其实谜底就在谜面里,RAG 是个方案,RAG是个方案的话那这个方案配合什么技术来实现就完全取决于要解决的问题场景,相比于全文检索向量检索肯定是有他独到之处,那到底全文检索有什么局限之处导致RAG方案中大家普遍采用向量检索的方案呢?
对啊,到底是什么原因呢???

经历一顿老程序员的疯狂Goggle之后,终于发现了一些端倪。 下面就简单对比下两者的区分。
在开始对比之前铁蛋想简单啰嗦两句,不管是全文检索还是向量检索他们都不是万能的,各有千秋或者说他们各自有各自适合的场景,今天我们的侧重点就在智能问答的场景下进行。
全文检索的原理简单理解是通过分词器 (简单理解就是把用户的输入按照对应语言的特点进行拆分成单词或者词组) 把用户的输入进行分词然后在构建的文档索引(文档也是被分词后进行存储)中进行查找召回, 最后通过文本相关性的算法对结果进行打分排序,最后得到的就是我们看到的搜索结果。
向量检索的原理简单理解是通过 Vector Embedding把用户的输入(文字,图片,视频等)进行向量化然后在向量数据库中搜索相似的向量(文档被向量化存储到向量数据库),最后根基相似度召回最相似的内容(中间涉及一些相关性排序来计算查询和文档之间的相关性来提高搜索的准确性),当然在智能问答的场景中召回的这部分结果不会直接返回,而是喂给大模型进行总结输出。
OK, 现在脑子里有个简单的概念之后我们从几个维度对比下这两种方式的的区别:
| 功能维度 | 全文检索 | 向量检索 |
|---|---|---|
| 数据类型 | 主要适用于文本类型 | 可以处理多种数据类型,如文本、图像、音频等 |
| 数据处理 | 将文本分词后存储 | 将数据转换成高维向量后存储 |
| 索引构建 | 构建倒排索引,记录每个词出现的文档及其位置 | 构建向量索引,记录每个向量及其对应的文档 |
| 查询处理 | 用户输入文本,通过分词器将其拆分成词或短语 | 用户输入数据,通过嵌入模型将其转换成向量 |
| 相似度计算 | 基于关键词匹配,使用布尔逻辑、TF-IDF等 | 基于向量相似度,使用余弦相似度、欧几里得距离等 |
| 召回方式 | 通过倒排索引快速定位包含关键词的文档 | 通过向量索引快速找到与查询向量最相似的文档 |
| 相关性排序 | 基于关键词频率、位置、文档权重等进行排序 | 基于向量相似度和高级模型(如深度学习模型)进行排序 |
| 应用场景 | 文档搜索、网站搜索、图书检索等 | 推荐系统、图像搜索、语音识别、自然语言处理等 |
| 处理速度 | 通常较快,尤其是在处理大量文本数据时 | 通常较慢,特别是在高维向量空间中进行搜索时 |
| 资源消耗 | 存储和计算资源相对较少 | 存储和计算资源较多,特别是向量索引和相似度计算 |
| 灵活性 | 较低,主要依赖关键词匹配 | 较高,可以处理复杂的数据结构和语义关系 |
| 准确性 | 对于精确匹配的查询效果较好 | 对于模糊匹配和语义相似的查询效果较好 |
| 扩展性 | 扩展性较好,可以轻松添加新的文档 | 扩展性较好,但需要更多的计算资源来处理新增数据 |
| 可解释性 | 较强,可以通过关键词和文档位置进行解释 | 较弱,向量空间的解释性较差,但可以通过可视化辅助 |
| 语义理解 | 无法捕获语义与相似性 | 支持语义相近搜索 |
咳咳!!! 哈哈铁蛋上面的表格明显作弊了哦,不过不要紧都是为了学习知识,知识最重要。
到了这里我们对全文检索和向量检索已经有了个初步的了解,全文检索铁蛋已经腻了,向量检索才是铁蛋的新欢,既然是新欢, 那必须得好好的了解一番。

向量检索向量检索,那就分向量&检索两块来看,又要回忆下铁蛋为数不多的数学知识了。
首先我们回忆下什么是向量,如图所示,在数学概念中向量是有大小有方向的量。

当然向量有多重不同的表现形式:
字母加箭头
( a ⃗ \vec{a} a )
几何表示

坐标系表示

矩阵表示
[ 1 2 3 4 5 6 7 8 9 ] \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix} \ 147258369
OR
[ 1 2 3 4 5 6 7 8 9 ] \begin{bmatrix} 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \end{bmatrix} [123456789]
这该死的数学记忆又被唤醒,铁蛋现在满脑子点线面。。。。。。。啊面什么面,牛肉面吗?

从上面可以发现以人类可以感知的形式来表示高维向量是比较困难的,三维向量我们可以在三维坐标系中表示,到了4维,甚至更高维度,我们已经没法想象了,但是我们可以通过数学的矩阵or多维数组来表示,虽然没法想象,但是能表示就有的搞。
认识了向量之后我们继续了解检索的事,想象一下,平时我们是怎么找人的,可能会有如下对话:
A:你认识铁蛋老师吗?
B:不认识,你能描述下吗?
A:就是那个长得威武霸气,英俊潇洒,坐在角落的小伙。
B:哦哦哦哦,知道了,就是那个短发,戴方框眼镜,穿着T恤的大叔是吧。
A:是的是的, 。。。。。。。。

发现没,我们会对一个人用各种特征进行描述,只要你描述的足够详细,就能够很准确的找到对应的这个人。
同理,以此类推任何数据都可以通过 特征描述(构建高维的特征空间) 去尽可能详细的去表征,这些高维特征可以通过多维数组or矩阵来表述,我们可以称之为 张量(tensor);
虽然我们没法感知到更高维的坐标系到底是什么样的,但是从一维,二维和三维空间坐标系中我们能够得出一个结论,可以通过计算两个向量之间的距离来表征这两个向量之间的相似性;
跟随铁蛋继续往下, 向量之间的距离可以表示相似,离得近代表相似, 离得远代表不相似,那到底怎么去计算呢?
高维空间向量我们比较难以想象和理解,我们从人最好理解的二维空间出发进行理解,进而推导出N维空间向量的距离计算方法。
铁蛋研究了几种常见的经典的计算方式:欧几里得距离 和、 余弦相似度、点积相似度。
- 欧几里得距离:从坐标系可以看出线段P的长度就是欧几里得距离。

很明显欧几里得距离在两个向量的长度不断延伸时会不断增大,所以欧几里得距离算法可以反应向量的绝对距离,适用于需要考虑向量长度的相似性计算;例如在推荐系统中,需要根据用户的历史行为来推荐相似的商品,这时就需要考虑用户的历史行为的数量,而不是仅仅是用户的历史行为的相似度。
- 余弦相似度:余弦相似从坐标系可以看出是在计算两个向量之间的夹角的Cos值。

总结: cos ( α ) = A ⋅ B ∣ A ∣ ∣ B ∣ \cos(\alpha) = \frac{\mathbf{A} \cdot \mathbf{B}}{|\mathbf{A}| |\mathbf{B}|} cos(α)=∣A∣∣B∣A⋅B
其中, A \mathbf{A} A 和 B \mathbf{B} B 分别表示两个向量, ⋅ \cdot ⋅ 表示向量的点积, ∣ A ∣ |\mathbf{A}| ∣A∣ 和 ∣ B ∣ |\mathbf{B}| ∣B∣ 分别表示两个向量的模长。
从图中可以看出来无论向量长度如何变化余弦相似度不受长度变化影响,只受向量方向的变化影响,因此更适用于高维向量的相似性计算,例如语义搜索和文件分类。
- 点积相似度 :向量的点积相似度是指两个向量之间的点积值, 计算公式如下
A ⋅ B = ∑ i = 1 n A i B i \mathbf{A} \cdot \mathbf{B} = \sum_{i=1}^{n}A_i B_i A⋅B=i=1∑nAiBi
其中, A \mathbf{A} A 和 B \mathbf{B} B 分别表示两个向量, n n n 表示向量的维度。

从图中可以看出,点积相似度受两个向量之间的夹角和长度两个因素影响,兼顾了向量的长度和方向。适用场景较多,例如图像识别、语义搜索和文档分类等。但点积相似度算法对向量的长度敏感,因此在计算高维向量的相似性时可能会出现问题。

铁蛋长舒一口气,终于把向量和向量之间的相似度计算方法的基本原理搞清楚了个大概,一鼓作气,继续探索下怎么检索。
原始数据被向量化存储, 用户输入的数据在检索时也被向量化成相同维度的向量跟原始数据进行相似度计算,继续回想下我们上面找人的例子。
如果铁蛋老师没啥特点,那么在你不认识的情况下想要从人群中找出他,你就需要记住更多的特征,你记住的特征越多脑容量占用越大(虽然我也不知道有没有脑容量这回事,只是简单比喻下),在把记住的特征应用到具体的人身上进行比对匹配的时候你花费的时间久越多。
铁老师敲黑板了,抓重点:空间占用大, 检索时间久
从上面推导出来的相似性算法的公式中我们也能比较直观的看出来影响检索速度的方面有两个方面:
-
减少向量的大小:减少维度或者减少向量的长度
-
缩小搜索的范围:主要是通过一些索引技术来实现,类比关系型数据库的索引,通过空间换时间。
降维稍微有点难度(需要点数学知识哈哈)柿子先挑软的捏,我们先从缩小搜索的范围这个方面下手!!
好了铁蛋老师回来了(疯狂Google了两小时),咳咳!!! 那么接下来就给大家科普下常见的几种缩小搜索范围的手段。
- K-Means聚类
做过分类任务的朋友对K-Means应该不会陌生,K-Means算法会通过划分聚类中心将一组数据分成K类,这样不管你有多少的数据量,经过聚类后搜索之前先跟聚类中心的点进行比较,先判断落到哪个分类中,然后再在这个分类中进行小范围搜索,搜索的数据范围直接缩减成原来的 1 K \frac{1}{K} K1。

上面的图简单示意了下在二维空间中将一组数据分成4类, 每类数据都有一个聚类中心点(铁蛋也仅仅知道聚类点是不断重复迭代计算出来的,具体的细节大家可以自行Google)。
上图形象的展示了数据的分布,大家可能会发现一个问题。如果某个点落在两个分类的中间,那么简单的去计算跟中心点的相似程度可能会漏掉最相似的部分(用局部【中心点】代替了全部,边缘部分的数据的特点就容易被忽略)。
另外在真实的场景中数据的分布式更加复杂的一种情况,区域跟区域之间的边界往往是相邻的,如下图所示。

假定图中q点是输入的数据, x点是某个聚类中心点,当qx之间的距离小于某个值n的时候搜索的范围就限制在当前q点落进去的区域,当qx之间的距离大于n的时候搜索的范围扩大到邻近的聚类区域。
从上面的权衡我们也能看出来,除了暴力搜索(全部对比)之外,其他的搜索算法知识在速度和质量以及内存上做的一个权衡,这些算法被称之为近似最相邻 ANN(Approximate Nearest Neighbor)。
再接再厉,继续干他!!!!
在开始之前我们先想一个问题,上面的例子中我们在二维空间中演示了对向量数据进行聚类来减少搜索的数据范围,从图中来看感觉一切都正常,但是如果把这个数据量放大, 维度放高(上千维),我们就会发现本身存储原始的向量数据已经耗费了大量的空间,除此之外我们还要额外维护聚类中心(为了搜搜效果维度越高,维护的聚类中心需要更多)以及每个向量和聚类中心的索引,造成内存占用过大,怎么解决呢? 且听铁蛋娓娓道来。
Product Quantization (PQ) 乘积量化
量化是一种解决直接进行k-means聚类产生的问题的手段,在开始之前我们先想想前面提到的问题。
高维向量在聚类的时候为了维持较好的搜索效果就需要更多的聚类中心? Why ????
网上给的大部分原因说随着维度的增加会出现维度灾难,点跟点之间的距离会出现快速增长,数据在高维空间中就分布的很稀疏(距离稀疏),而且点跟点之间的距离都趋于相等(称之为距离的均匀性),因此为了更好的分类效果需要维持更多的聚类中心。
铁蛋去网上看很多人都这样说,但是铁蛋不明白为啥?
从上面的相似度计算公式的特点中来看,余弦相似度表征的是两个向量之间夹角的余弦值,理论上受维度影响较小,那为什么大家都会有这个论调呢?
原来问题在算法上,业界常用的k-means聚类算法通常使用的是欧式距离,而欧式距离从公式上来看距离的值会随着维度的增加而增加。点跟点之间的距离趋于相等从数学的角度也能够得出, 具体细节大家可以去查, 主要也是从方差,期望这些可以反应数据离散程度的公式可以看出。
So!!! 高维空间中直接聚类需要更多的聚类中心对前面的优化检索速度的方式产生了挑战。为了解决这个问题可以通过将原本的高维度向量拆分成多段低维度向量, 多个高纬度的向量拆分的子向量组成子向量集,然后为每个子向量集通过k-means的方式生成聚类中心组成码本,最后计算码本中跟子向量中最近的点,用这个最近的点的索引来表示这个子向量,如下图所示:

在使用的时候可以通过这个编码后的新向量(码本的索引) + 码本 还原出一个近似的高维向量,举个例子:
量化: 128维的向量 ===》 拆分成8个16维的子向量 ========》对比码本生成一个包含8个码本索引的向量;
还原: 8个码本索引 ====》 查找码本找出 8 个 16 维的子向量 ======》 组成跟原始向量近似的128维向量;
我们继续探索往下看另外一种优化算法。
Hierarchical Navigable Small Worlds (HNSW)
除了聚类以外,也可以通过构建树或者构建图的方式来实现近似最近邻搜索。这种方法的基本思想是每次将向量加到数据库中的时候,就先找到与它最相邻的向量,然后将它们连接起来,这样就构成了一个图。当需要搜索的时候,就可以从图中的某个节点开始,不断的进行最相邻搜索和最短路径计算,直到找到最相似的向量。
这种算法能保证搜索的质量,但是如果图中所以的节点都以最短的路径相连,如图中最下面的一层,那么在搜索的时候,就同样需要遍历所有的节点。

解决这个问题的思路与常见的跳表算法相似,如下图要搜索跳表,从最高层开始,沿着具有最长“跳过”的边向右移动。如果发现当前节点的值大于要搜索的值-我们知道已经超过了目标,因此我们会在下一级中向前一个节点。

HNSW 继承了相同的分层格式,最高层具有更长的边缘(用于快速搜索),而较低层具有较短的边缘(用于准确搜索)。
具体来说,可以将图分为多层,每一层都是一个小世界,图中的节点都是相互连接的。而且每一层的节点都会连接到上一层的节点,当需要搜索的时候,就可以从第一层开始,因为第一层的节点之间距离很长,可以减少搜索的时间,然后再逐层向下搜索,又因为最下层相似节点之间相互关联,所以可以保证搜索的质量,能够找到最相似的向量。
HNSW 算法是一种经典的空间换时间的算法,它的搜索质量和搜索速度都比较高,但是它的内存开销也比较大,因为不仅需要将所有的向量都存储在内存中。还需要维护一个图的结构,也同样需要存储。所以这类算法需要根据实际的场景来选择。
好了,中场休息一下, 铁蛋感觉自己在长脑子了。。。。。。。

喝杯茶,休息了一会后铁蛋在脑子里一直在思考一个问题,了解完上面优化向量检索的速度的手段之后我们是不是该总结下了? 这样不停的罗列优化手段感觉脑子一直很凌乱,是不是可以从更上层的角度总结出一个纲领来指引我们继续探索。说干就干,开始Thinking。。。。。。。。。。。
铁老师在敲黑板画重点的时候就提到过, 从计算相似度的公式中我们推导出来了几个影响向量检索速度的因素, 最开始为了简单入手我们从降低检索数据量的角度出发(挑软柿子捏), 但是以铁蛋的这点知识储备,软柿子捏的也费劲啊!!!
咳咳。。。。 学习知识不能有情绪,咬咬牙忍一忍就废了, 啊呸呸呸, 就会了!!!(铁老师这嘴没把门)
从降低检索数据量的角度来看主要的手段就是量化 和 近似最相邻搜索(ANN);这里面具体的手段如下:
近似最近邻搜索(Approximate Nearest Neighbor, ANN):
- 局部敏感哈希(LSH):通过哈希函数将相似的向量映射到同一个桶中,加快检索速度。
- 树结构:如KD树、球树(Ball Tree)等,通过层次结构加速搜索。
- 图结构:如HNSW(Hierarchical Navigable Small World)等,通过图结构加速最近邻搜索。
量化和离散化:
- 乘积量化(Product Quantization, PQ):将高维向量分割成多个子向量,为每个子向量生成码本,将子向量量化为码本中的码字。
- 标量量化(Scalar Quantization):将每个维度的值量化为离散的值。
上面的实际案例中我们已经分别介绍了ANN 中的HNSW和量化中的乘积量化手段。
从降低数据维度的角度来看主要的优化手段是维度约简,具体的手段如下所示:
维度约简:
- 主成分分析(PCA):通过线性变换将数据投影到低维空间,保留主要的方差。
- 随机投影(Random Projection):通过随机矩阵将高维数据投影到低维空间,保留数据的近似距离。
- 局部线性嵌入(LLE):保留数据的局部结构,适用于非线性数据。
铁蛋的脑容量实在有限, 关于降维的实现我们这里不再展开, 后续铁老师有精力可以单独整理一下,这里大家脑子里有个概念就可以了,万变不离其宗,知道方向其他是一些工程性的或者数学理论上的知识,有兴趣可以自行了解。
在继续进行之前铁蛋的心里一直有个疑问, 乘积量化这个玩意怎么看都像是对原始高纬度的向量做了降维,但是它又不是降维, why????
128维的向量量化成8维的向量编码,缘何不是降维, 真理是什么???

终于铁蛋在遍查古籍,阅读经典之后了解到了一丝丝真理。
量化从表面上看也确实是得到了一个低维度的向量,但是从实际上来说,它只是原始向量的在码本空间中的索引,量化是将连续的数值转换成离散数值的过程,来达到降低数据存储和计算复杂度的目的。

翻译成人话就是量化过程你可以类比电报密码翻译, 发送方可以通过一个密码本(码本,稍微有点不同, 码本是根据实际的数据来生成,密码本可能是事先约定的,问题不大,能理解就行),把原始的大量的文本映射成只有少量数据的字母或者数字的密文, 接收方在收到这些密文之后可以通过密码本把原始的文本翻译出来(在电报加密发送的场景中原文是可以被完整还原,但是量化还原只能还原出来相似的向量,具体看上文)。
降维是直接对原始高维度的数据转换成低维度的数据的过程,在减少数据维度的同事保留或者增强数据的重要信息,可以减少数据的复杂度和冗余,提高数据处理效率。
直白点降维后直接对降维后的数据做处理,不需要还原。 从手段上来看降维需要通过线性或者非线性变换,或者随机投影等方法进行转换,量化只是做了近似映射。

休息下休息下, 铁蛋的脑细胞快要用完了, 再用脑头发要保不住了。。。。。。。。
茶歇时间结束 , 元气满满, 继续战斗,铁老师还能肝!!!!
那么让我们继续再想一个问题,实际上我们在检索的时候需要全量检索吗?显然是不需要的, 如果我问的是一个文学类的知识,显然是不需要到医学类的数据中尝试去检索的。
我们上面说的都是理论上的优化手段,基调就是我们要在全量的数据中进行检索,然后考虑怎么优化,但是实际情况就跟上面说的一样,检索的时候大多数时候是带有范围的,或者说具有业务or行业属性的,我们可以通过过滤缩小检索的数据范围,这就是我们下面要讨论的过滤。
过滤(Filtering)
过滤其实有两层作用,其一是提高检索的精度,其二是为了减少检索的数据量(但是增加了过滤的过程)。
在实际的业务场景中,往往不需要在整个向量数据库中进行相似性搜索,而是通过部分的业务字段进行过滤再进行查询。所以存储在数据库的向量往往还需要包含元数据,例如用户 ID、文档 ID 等信息。这样就可以在搜索的时候,根据元数据来过滤搜索结果,从而得到最终的结果。
为此,向量数据库通常维护两个索引:一个是向量索引,另一个是元数据索引。然后,在进行相似性搜索本身之前或之后执行元数据过滤,但无论哪种情况下,都存在导致查询过程变慢的困难。
前过滤:

后过滤:

过滤过程可以在向量搜索本身之前或之后执行,但每种方法都有自己的挑战,可能会影响查询性能:
Pre-filtering:在向量搜索之前进行元数据过滤。虽然这可以帮助减少搜索空间,但也可能导致系统忽略与元数据筛选标准不匹配的相关结果。
Post-filtering:在向量搜索完成后进行元数据过滤。这可以确保考虑所有相关结果,在搜索完成后将不相关的结果进行筛选。
为了优化过滤流程,向量数据库使用各种技术,例如利用先进的索引方法来处理元数据或使用并行处理来加速过滤任务。平衡搜索性能和筛选精度之间的权衡对于提供高效且相关的向量数据库查询结果至关重要。
终于终于,铁蛋把向量检索相关的入门基础了解了个七七八八,激动的心颤抖的手。。。。
回到最开始,我们是想了解RAG检索增强,在大模型时代智能问答离不开RAG的技术,从明白RAG是一个方案,全文检索和向量检索只是实现的手段我们知道了应用场景不同我们选择不同的检索技术,到最后我们把向量检索打开进行分析(其实向量检索也不是个什么新鲜玩意,很早之前就出现了,只是因为大模型的出现让更多的人知道,并且在实际工作中去使用,仔细想想铁蛋之前做的以图搜图底层其实也是基于向量检索的,图片数据被向量化,进行相似性搜索。),让我们对其有了更加深刻的认识,本文仅仅是在理论层面做了一些简单的入门总结,有些名词或者描述为了理解方便可能措辞不准确,有什么不当之处欢迎大家指正。
至此学习历程已经结束,铁蛋感觉距离自己成为专家的梦想又近了一步。

相关文章:
从Full-Text Search全文检索到RAG检索增强
从Full-Text Search全文检索到RAG检索增强 时光飞逝,转眼间六年过去了,六年前铁蛋优化单表千万级数据查询性能的场景依然历历在目,铁蛋也从最开始做CRUD转行去了大数据平台开发,混迹包装开源的业务,机缘巧合下做了实时…...

springMVC 全局异常统一处理
全局异常处理⽅式⼀: 1、配置简单异常处理器 配置 SimpleMappingExceptionResolver 对象: <!-- 配置全局异常统⼀处理的 Bean (简单异常处理器) --> <bean class"org.springframework.web.servlet.handler.SimpleMappingExceptionReso…...

qt ubuntu i386 系统
sudo ln -s cmake-3.31.0-linux-x86_64/bin/* /usr/local/bin 【Ubuntu20.4安装QT6 - CSDN App】Ubuntu20.4安装QT6_ubuntu安装qt6-CSDN博客 sudo ../configure -release -platform linux-g-64 -static -nomake examples -nomake demos -no-qt3support -no-script -no-scriptt…...

BUUCTF—Reverse—helloword(6)
一道安卓逆向的签到题 下载附件 使用JADX-gui反编译工具打开(注意配环境),找到主函数 jadx 本身就是一个开源项目,源代码已经在 Github 上开源了 官方地址:GitHub - skylot/jadx: Dex to Java decompiler 发现flag …...

深入解析下oracle date底层存储方式
之前我们介绍了varchar2和char的数据库底层存储格式,今天我们介绍下date类型的数据存储格式,并通过测试程序快速获取一个日期。 一、环境搭建 1.1,创建表 我们还是创建一个测试表t_code,并插入数据: 1.2,…...

Elasticsearch 开放推理 API 增加了对 IBM watsonx.ai Slate 嵌入模型的支持
作者:来自 Elastic Saikat Sarkar 使用 Elasticsearch 向量数据库构建搜索 AI 体验时如何使用 IBM watsonx™ Slate 文本嵌入。 Elastic 很高兴地宣布,通过集成 IBM watsonx™ Slate 嵌入模型,我们的开放推理 API 功能得以扩展,这…...

如何搭建一个小程序:从零开始的详细指南
在当今数字化时代,小程序以其轻便、无需下载安装即可使用的特点,成为了连接用户与服务的重要桥梁。无论是零售、餐饮、教育还是娱乐行业,小程序都展现了巨大的潜力。如果你正考虑搭建一个小程序,本文将为你提供一个从零开始的详细…...

NFS搭建
NFS搭建 单节点安装配置服务器安装配置启动并使NFS服务开机自启客户端挂载查看是否能发现服务器的共享文件夹创建挂载目录临时挂载自动挂载 双节点安装配置服务器安装配置服务端配置NFS服务端配置Keepalived编辑nfs_check.sh监控脚本安装部署RsyncInofity 客户端 单节点安装配置…...

RNN与LSTM,通过Tensorflow在手写体识别上实战
简介:本文从RNN与LSTM的原理讲起,在手写体识别上进行代码实战。同时列举了优化思路与优化结果,都是基于Tensorflow1.14.0的环境下,希望能给您的神经网络学习带来一定的帮助。如果您觉得我讲的还行,希望可以得到您的点赞…...

Docker部署FastAPI实战
在现代 Web 开发领域,FastAPI 作为一款高性能的 Python 框架,正逐渐崭露头角,它凭借简洁的语法、快速的执行速度以及出色的类型提示功能,深受开发者的喜爱。而 Docker 容器化技术则为 FastAPI 应用的部署提供了便捷、高效且可移植…...

【Python数据分析五十个小案例】电影评分分析:使用Pandas分析电影评分数据,探索评分的分布、热门电影、用户偏好
博客主页:小馒头学python 本文专栏: Python数据分析五十个小案例 专栏简介:分享五十个Python数据分析小案例 在现代电影行业中,数据分析已经成为提升用户体验和电影推荐的关键工具。通过分析电影评分数据,我们可以揭示出用户的…...

Vue2学习记录
前言 这篇笔记,是根据B站尚硅谷的Vue2网课学习整理的,用来学习的 如果有错误,还请大佬指正 Vue核心 Vue简介 Vue (发音为 /vjuː/,类似 view) 是一款用于构建用户界面的 JavaScript 框架。 它基于标准 HTML、CSS 和 JavaScr…...

TMS FNC UI Pack 5.4.0 for Delphi 12
TMS FNC UI Pack是适用于 Delphi 和 C Builder 的多功能 UI 控件的综合集合,提供跨 VCL、FMX、LCL 和 TMS WEB Core 等平台的强大功能。这个统一的组件集包括基本工具,如网格、规划器、树视图、功能区和丰富的编辑器,确保兼容性和简化的开发。…...

Redis主从架构
Redis(Remote Dictionary Server)是一个开源的、高性能的键值对存储系统,广泛应用于缓存、消息队列、实时分析等场景。为了提高系统的可用性、可靠性和读写性能,Redis提供了主从复制(Master-Slave Replication…...

logback动态获取nacos配置
文章目录 前言一、整体思路二、使用bootstrap.yml三、增加环境变量四、pom文件五、logback-spring.xml更改总结 前言 主要是logback动态获取nacos的配置信息,结尾完整代码 项目springcloudnacosplumelog,使用的时候、特别是部署的时候,需要改环境&#…...

KETTLE安装部署V2.0
一、前置准备工作 JDK:下载JDK (1.8),安装并配置 JAVA_HOME 环境变量,并将其下的 bin 目录追加到 PATH 环境变量中。如果你的环境中已存在,可以跳过这步。KETTLE(8.2)压缩包:LHR提供关闭防火墙…...

[RabbitMQ] 保证消息可靠性的三大机制------消息确认,持久化,发送方确认
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...
介绍和使用)
aws服务--机密数据存储AWS Secrets Manager(1)介绍和使用
一、介绍 1、简介 AWS Secrets Manager 是一个完全托管的服务,用于保护应用程序、服务和 IT 资源中的机密信息。它支持安全地存储、管理和访问应用程序所需的机密数据,比如数据库凭证、API 密钥、访问密钥等。通过 Secrets Manager,你可以轻松管理、轮换和访问这些机密信息…...

Java设计模式笔记(一)
Java设计模式笔记(一) (23种设计模式由于篇幅较大分为两篇展示) 一、设计模式介绍 1、设计模式的目的 让程序具有更好的: 代码重用性可读性可扩展性可靠性高内聚,低耦合 2、设计模式的七大原则 单一职…...

Unity3d C# 实现一个基于UGUI的自适应尺寸图片查看器(含源码)
前言 Unity3d实现的数字沙盘系统中,总有一些图片或者图片列表需要点击后弹窗显示大图,这个弹窗在不同尺寸分辨率的图片查看处理起来比较麻烦,所以,需要图片能够根据容器的大小自适应地进行缩放,兼容不太尺寸下的横竖图…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...
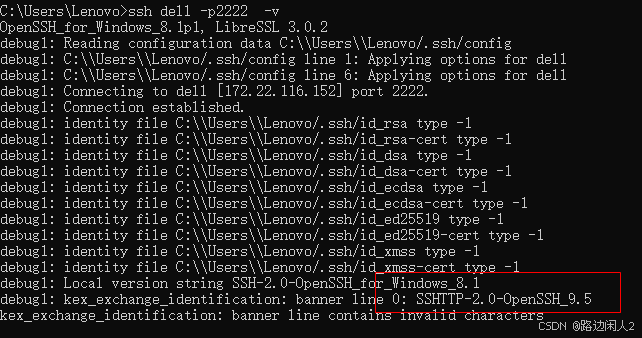
sshd代码修改banner
sshd服务连接之后会收到字符串: SSH-2.0-OpenSSH_9.5 容易被hacker识别此服务为sshd服务。 是否可以通过修改此banner达到让人无法识别此服务的目的呢? 不能。因为这是写的SSH的协议中的。 也就是协议规定了banner必须这么写。 SSH- 开头,…...

机器学习的数学基础:线性模型
线性模型 线性模型的基本形式为: f ( x ) ω T x b f\left(\boldsymbol{x}\right)\boldsymbol{\omega}^\text{T}\boldsymbol{x}b f(x)ωTxb 回归问题 利用最小二乘法,得到 ω \boldsymbol{\omega} ω和 b b b的参数估计$ \boldsymbol{\hat{\omega}}…...

【实施指南】Android客户端HTTPS双向认证实施指南
🔐 一、所需准备材料 证书文件(6类核心文件) 类型 格式 作用 Android端要求 CA根证书 .crt/.pem 验证服务器/客户端证书合法性 需预置到Android信任库 服务器证书 .crt 服务器身份证明 客户端需持有以验证服务器 客户端证书 .crt 客户端身份…...

简单介绍C++中 string与wstring
在C中,string和wstring是两种用于处理不同字符编码的字符串类型,分别基于char和wchar_t字符类型。以下是它们的详细说明和对比: 1. 基础定义 string 类型:std::string 字符类型:char(通常为8位)…...

6.9本日总结
一、英语 复习默写list11list18,订正07年第3篇阅读 二、数学 学习线代第一讲,写15讲课后题 三、408 学习计组第二章,写计组习题 四、总结 明天结束线代第一章和计组第二章 五、明日计划 英语:复习l默写sit12list17&#…...