网络爬虫——常见问题与调试技巧
在开发网络爬虫的过程中,开发者常常会遇到各种问题,例如网页加载失败、数据提取错误、反爬机制限制等。以下内容将结合实际经验和技术方案,详细介绍解决常见错误的方法,以及如何高效调试和优化爬虫代码。
1. 爬虫过程中常见的错误及解决方法
1.1 请求失败与响应异常
问题描述
- HTTP 请求失败: 如 403 Forbidden、404 Not Found、500 Internal Server Error 等。
- 超时错误: 目标网站响应速度慢,导致请求超时。
- 过频繁访问导致 IP 封禁: 服务器认为访问行为异常。
解决方法
-
模拟真实用户行为
- 使用合理的
User-Agent模拟浏览器。 - 添加 HTTP 头部信息,如
Referer和Accept-Language。
示例代码:设置请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36","Referer": "https://example.com","Accept-Language": "en-US,en;q=0.9" } response = requests.get("https://example.com", headers=headers) - 使用合理的
-
调整请求频率
- 在请求之间设置随机延迟,避免被检测为爬虫。
import time import randomtime.sleep(random.uniform(1, 3)) # 延迟 1 到 3 秒 -
使用代理 IP
- 通过代理池切换 IP,绕过封禁。
proxies = {"http": "http://proxy_ip:port","https": "http://proxy_ip:port" } response = requests.get("https://example.com", proxies=proxies)
1.2 动态加载问题
问题描述
- 页面使用 JavaScript 渲染,导致爬虫无法直接获取数据。
- 数据通过异步请求加载。
解决方法
-
捕获 Ajax 请求
- 使用浏览器开发者工具分析网络请求,找到实际加载数据的 API。
示例代码:抓取 API 数据
import requestsapi_url = "https://example.com/api/data" response = requests.get(api_url) if response.status_code == 200:data = response.json()print(data) -
Selenium 模拟用户行为
- 适用于动态渲染的复杂页面。
from selenium import webdriver from selenium.webdriver.common.by import Bydriver = webdriver.Chrome() driver.get("https://example.com") element = driver.find_element(By.CLASS_NAME, "dynamic-content") print(element.text) driver.quit() -
使用 Headless 浏览器
- 提高性能,减少资源占用。
options = webdriver.ChromeOptions() options.add_argument("--headless") driver = webdriver.Chrome(options=options)
1.3 数据提取错误
问题描述
- HTML 结构发生变化,导致爬虫无法定位目标元素。
- 数据格式不一致或字段缺失。
解决方法
-
增加容错机制
- 使用
try-except捕获异常。
from bs4 import BeautifulSouphtml = "<div class='product'>Price: $100</div>" soup = BeautifulSoup(html, "html.parser") try:price = soup.find("span", class_="price").text except AttributeError:price = "N/A" print(price) - 使用
-
动态调整 XPath 或 CSS 选择器
- 针对不同 HTML 结构设计备选方案。
-
日志记录
- 在错误发生时记录详细信息,便于排查问题。
import logginglogging.basicConfig(filename="errors.log", level=logging.ERROR) try:# 爬取逻辑 except Exception as e:logging.error(f"Error occurred: {str(e)}")
2. 如何调试并优化爬虫代码
2.1 调试技巧
-
逐步验证代码
- 在每个爬取阶段打印调试信息(如请求状态码、HTML 片段)。
- 使用
breakpoint()或交互式调试工具(如pdb)逐步检查。
import pdbresponse = requests.get("https://example.com") pdb.set_trace() # 在此处暂停执行,检查变量值 -
检查目标网站的 HTML
- 使用开发者工具查看页面结构,确认爬虫选择器的准确性。
-
模拟请求
- 利用 Postman 或 cURL 调试 API 请求。
2.2 性能优化
-
异步编程
- 使用
asyncio和aiohttp实现高并发,提高爬取效率。
示例代码:异步请求
import aiohttp import asyncioasync def fetch(session, url):async with session.get(url) as response:return await response.text()async def main():urls = ["https://example.com/page1", "https://example.com/page2"]async with aiohttp.ClientSession() as session:tasks = [fetch(session, url) for url in urls]results = await asyncio.gather(*tasks)print(results)asyncio.run(main()) - 使用
-
使用多线程或多进程
- 使用
ThreadPoolExecutor或multiprocessing并行化任务。
from concurrent.futures import ThreadPoolExecutordef crawl(url):response = requests.get(url)print(response.status_code)urls = ["https://example.com/page1", "https://example.com/page2"] with ThreadPoolExecutor(max_workers=5) as executor:executor.map(crawl, urls) - 使用
-
缓存数据
- 避免重复爬取相同内容,通过缓存减少请求次数。
import requests_cacherequests_cache.install_cache("cache", expire_after=3600) response = requests.get("https://example.com") -
调整代码结构
- 使用模块化设计,提高代码的可读性和可维护性。
-
限流机制
- 使用
RateLimiter限制每秒请求次数,防止触发反爬。
from ratelimit import limits@limits(calls=10, period=60) def fetch_data():response = requests.get("https://example.com")return response - 使用
2.3 监控与日志
-
实时监控
- 使用监控工具(如 Prometheus + Grafana)记录爬虫运行状态。
-
详细日志记录
- 记录每次请求的时间、状态码和错误信息,方便后续分析。
总结
爬虫调试和优化是确保爬虫稳定、高效运行的关键。通过正确处理常见错误、优化代码性能以及良好的日志和监控机制,开发者可以构建功能强大且可靠的网络爬虫系统。

相关文章:
网络爬虫——常见问题与调试技巧
在开发网络爬虫的过程中,开发者常常会遇到各种问题,例如网页加载失败、数据提取错误、反爬机制限制等。以下内容将结合实际经验和技术方案,详细介绍解决常见错误的方法,以及如何高效调试和优化爬虫代码。 1. 爬虫过程中常见的错误…...

【AI绘画】Midjourney进阶:色调详解(下)
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: AI绘画 | Midjourney 文章目录 💯前言💯Midjourney中的色彩控制为什么要控制色彩?为什么要在Midjourney中控制色彩? 💯色调纯色调灰色调暗色调 💯…...

springboot+redis+lua实现分布式锁
1 分布式锁 Java锁能保证一个JVM进程里多个线程交替使用资源。而分布式锁保证多个JVM进程有序交替使用资源,保证数据的完整性和一致性。 分布式锁要求 互斥。一个资源在某个时刻只能被一个线程访问。避免死锁。避免某个线程异常情况不释放资源,造成死锁…...

【Petri网导论学习笔记】Petri网导论入门学习(十一) —— 3.3 变迁发生序列与Petri网语言
目录 3.3 变迁发生序列与Petri网语言定义 3.4定义 3.5定义 3.6定理 3.5例 3.9定义 3.7例 3.10定理 3.6定理 3.7 有界Petri网泵引理推论 3.5定义 3.9定理 3.8定义 3.10定义 3.11定义 3.12定理 3.93.3 变迁发生序列与Petri网语言 对于 Petri 网进行分析的另一种方法是考察网系统…...

docker-compose文件的简介及使用
Docker Compose是Docker官方的开源项目,主要用于定义和运行多容器Docker应用。以下是对Docker Compose的详细介绍: 一、主要功能: 容器编排:Docker Compose允许用户通过一个单独的docker-compose.yml模板文件(YAML格…...

[护网杯 2018]easy_tornado
这里有一个hint点进去看看,他说md5(cookie_secretmd5(filename)),所以我们需要获得cookie_secret的value 根据题目tornado,它可能是tornado的SSTI 这里吧filehash改为NULL. 是tornado的SSTI 输入{{handler.settings}} (settings 属性是一个字典&am…...

基于STM32的智能风扇控制系统
基于STM32的智能风扇控制系统 持续更新,欢迎关注!!! ** 基于STM32的智能风扇控制系统 ** 近几年,我国电风扇市场发展迅速,产品产出持续扩张,国家产业政策鼓励电风扇产业向高技术产品方向发展,国内企业新增投资项目投…...

决策树——基于乳腺癌数据集与cpu数据集实现
决策树——乳腺癌数据实现 4.1 训练决策树模型,并计算测试集的准确率 1. 读入数据 from sklearn import datasets from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix …...
探索空间自相关:揭示地理数据中的隐藏模式
目录 一、什么是空间自相关? 类型 二、空间自相关的数学基础 空间加权矩阵 三、度量空间自相关的方法 1. 全局自相关 2. 局部自相关 四、空间自相关的实际应用 五、Python实现空间自相关分析 1. 数据准备 2. 计算莫兰指数 3. 局部自相关(LISA 分析&…...

echarts使用示例
柱状图折线图 折柱混合:https://echarts.apache.org/examples/zh/editor.html?cmix-line-bar option {title:{show: true},tooltip: {trigger: axis,axisPointer: {type: cross,crossStyle: {color: #999}}},toolbox: {feature: {dataView: { show: true, readOnl…...

Flink高可用配置(HA)
从Flink架构中我们可以看到,JobManager这个组件非常重要,是中心协调器,负责任务调度和资源管理。默认情况下,每个Flink集群只有一个JobManager实例。这会产生单点故障(SPOF):如果JobManager崩溃,则无法提交新程序,正在运行的程序也会失败。通过JobManager的高可用性,…...

如何编写出色的技术文档
目录 编辑 1. 明确文档目的和受众 目的的重要性 了解受众 2. 收集和组织信息 信息收集的技巧 组织信息 3. 规划文档结构 结构规划的重要性 结构规划的步骤 4. 编写内容 语言和风格 内容的组织 编写技巧 5. 审阅和测试 审阅的重要性 测试的必要性 6. 版本控…...

学习日记_20241126_聚类方法(谱聚类Spectral Clustering)
前言 提醒: 文章内容为方便作者自己后日复习与查阅而进行的书写与发布,其中引用内容都会使用链接表明出处(如有侵权问题,请及时联系)。 其中内容多为一次书写,缺少检查与订正,如有问题或其他拓展…...

图书系统小案例
目前就实现了分页查询,修改,删除功能 这个小案例练习到了很多技能,比如前后端交互、异步请求、三层架构思想、后端连接数据库、配置文件、基础业务crud等等 感兴趣的小伙伴可以去做一个试试 准备工作 1、使用maven构建一个web工程 打开i…...
)
目标检测之学习路线(本科版)
以下是为一名计算机科学与技术本科大四学生整理的“目标检测”学习路线,结合了从基础到高级的内容,适合初学者逐步深入。每个阶段都有明确的学习要求、学习建议和资源推荐。 阶段一:基础知识学习 学习要求: 掌握编程语言 Pytho…...

C#调用C++ DLL方法之C++/CLI(托管C++)
托管C与C/CLI前世今生 C/CLI (C/Common Language Infrastructure) 是一种用于编写托管代码的语言扩展,它是为了与 .NET Framework 进行互操作而设计的。C/CLI 是 C 的一种方言,它引入了一些新的语法和关键字,以便更好地支持 .NET 类型和垃圾…...
)
免费搭建一个属于自己的个性化博客(Hexo+Fluid+Github)
文章目录 0.简介1. 下载安装fluid主题2. 创建文章3. 添加分类及标签3.1 创建“分类”选项3.2 创建“标签”选项4. 文章中插入图片5. 添加阅读量统计6. 添加评论功能7. 显示文章更新时间8. 为hexo添加latex支持小结参考文献0.简介 通过HEXO模板和Fluid主题搭建自己的博客,预览…...

vue3 开发利器——unplugin-auto-import
这玩意儿是干啥的? 还记得 Vue 3 的组合式 API 语法吗?如果有印象,那你肯定对以下代码有着刻入 DNA 般的熟悉: 刚开始写觉得没什么,但是后来渐渐发现,这玩意儿几乎每个页面都有啊! 每次都要写…...

开发需求总结19-vue 根据后端返回一年的数据,过滤出符合条件数据
需求描述: 定义时间分界点:每月26号8点,过了26号8点则过滤出data数组中符合条件数据下个月的数据,否则过滤出当月数据 1.假如现在是2024年11月14日,那么过滤出data数组中日期都是2024-11月的数据; 2.假如…...

人工智能如何改变创新和创造力?
王琼工作室 输出的力量 有了GPT这样的人工智能平台,创新和创造力的机会在哪里? 我们是否有信心: 面对效率,超越效率。 把问题拓展为机会? 把机会拓展为价值? 让智能更好地和我们协作,走心、走…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

SQL Server 触发器调用存储过程实现发送 HTTP 请求
文章目录 需求分析解决第 1 步:前置条件,启用 OLE 自动化方式 1:使用 SQL 实现启用 OLE 自动化方式 2:Sql Server 2005启动OLE自动化方式 3:Sql Server 2008启动OLE自动化第 2 步:创建存储过程第 3 步:创建触发器扩展 - 如何调试?第 1 步:登录 SQL Server 2008第 2 步…...
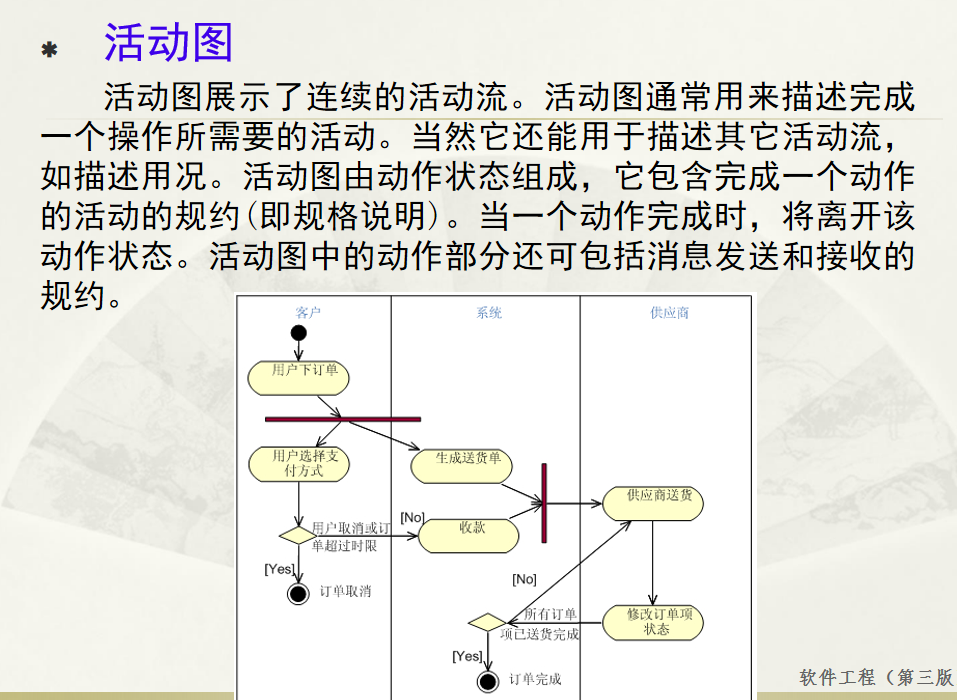
软件工程 期末复习
瀑布模型:计划 螺旋模型:风险低 原型模型: 用户反馈 喷泉模型:代码复用 高内聚 低耦合:模块内部功能紧密 模块之间依赖程度小 高内聚:指的是一个模块内部的功能应该紧密相关。换句话说,一个模块应当只实现单一的功能…...