YOLOv8-ultralytics-8.2.103部分代码阅读笔记-autobatch.py
autobatch.py
ultralytics\utils\autobatch.py
目录
autobatch.py
1.所需的库和模块
2.def check_train_batch_size(model, imgsz=640, amp=True, batch=-1):
3.def autobatch(model, imgsz=640, fraction=0.60, batch_size=DEFAULT_CFG.batch):
1.所需的库和模块
# Ultralytics YOLO 🚀, AGPL-3.0 license
"""Functions for estimating the best YOLO batch size to use a fraction of the available CUDA memory in PyTorch."""
# 用于估算最佳 YOLO 批量大小的函数,以使用 PyTorch 中可用 CUDA 内存的一小部分。from copy import deepcopyimport numpy as np
import torchfrom ultralytics.utils import DEFAULT_CFG, LOGGER, colorstr
from ultralytics.utils.torch_utils import autocast, profile
2.def check_train_batch_size(model, imgsz=640, amp=True, batch=-1):
# 这段代码定义了一个名为 check_train_batch_size 的函数,它用于确定在给定图像尺寸和内存使用率下,模型训练时的最佳批量大小。
# 1.model :要评估的模型。
# 2.imgsz :输入图像的尺寸,默认为 640。
# 3.amp :布尔值,指示是否使用自动混合精度(Automatic Mixed Precision, AMP)。
# 4.batch :批量大小的分数或具体数值。如果这个值在 0.0 到 1.0 之间,它表示 CUDA 内存使用率的分数;如果是一个具体的数值,则直接表示批量大小。
def check_train_batch_size(model, imgsz=640, amp=True, batch=-1):# 使用 autobatch() 函数计算最佳 YOLO 训练批次大小。"""Compute optimal YOLO training batch size using the autobatch() function.Args:model (torch.nn.Module): YOLO model to check batch size for.imgsz (int, optional): Image size used for training.amp (bool, optional): Use automatic mixed precision if True.batch (float, optional): Fraction of GPU memory to use. If -1, use default.Returns:(int): Optimal batch size computed using the autobatch() function.Note:If 0.0 < batch < 1.0, it's used as the fraction of GPU memory to use.Otherwise, a default fraction of 0.6 is used."""# 自动混合精度上下文管理。 使用 PyTorch 的 autocast 上下文管理器来启用或禁用自动混合精度。这有助于在训练过程中减少内存使用和加速计算,同时保持模型的精度。# def autocast(enabled: bool, device: str = "cuda"):# -> 它用于创建一个上下文管理器,以便在 PyTorch 的自动混合精度(AMP)中使用。如果 PyTorch 版本是 1.13 或更高,使用 torch.amp.autocast 并指定设备类型和启用状态。如果 PyTorch 版本低于 1.13,使用 torch.cuda.amp.autocast ,这时不能指定设备类型,只能启用或禁用自动混合精度。# -> return torch.amp.autocast(device, enabled=enabled) / return torch.cuda.amp.autocast(enabled)with autocast(enabled=amp):# 调用 autobatch 函数。# 使用 deepcopy 函数创建模型的一个深拷贝,以确保不会修改原始模型。# 将模型设置为训练模式。# 调用 autobatch 函数来计算最佳批量大小。 autobatch 函数接受 模型 、 图像尺寸 和 内存使用率的分数 作为参数。# 如果 batch 参数在 0.0 到 1.0 之间,它被用作内存使用率的分数;否则,默认使用 0.6 作为内存使用率的分数。# 返回值。函数返回 autobatch 函数计算出的最佳批量大小。return autobatch(deepcopy(model).train(), imgsz, fraction=batch if 0.0 < batch < 1.0 else 0.6)
# 这个方法的目的是自动调整模型的批量大小,以便在不超过指定 CUDA 内存使用率的情况下最大化模型性能。通过这种方式,可以确保模型在有限的硬件资源下高效运行,同时避免内存溢出错误。3.def autobatch(model, imgsz=640, fraction=0.60, batch_size=DEFAULT_CFG.batch):
# 这段代码定义了一个名为 autobatch 的函数,其目的是自动计算并优化模型在给定 CUDA 内存使用率下的最佳批量大小(batch size)。
# 1.model :要评估的模型。
# 2.imgsz :输入图像的尺寸,默认为 640。
# 3.fraction :CUDA 内存使用率的分数,默认为 0.60(即 60%)。
# 4.batch_size :默认的批量大小,通常从配置中获取。
def autobatch(model, imgsz=640, fraction=0.60, batch_size=DEFAULT_CFG.batch):# 自动估计最佳 YOLO 批次大小以使用可用 CUDA 内存的一小部分。"""Automatically estimate the best YOLO batch size to use a fraction of the available CUDA memory.Args:model (torch.nn.module): YOLO model to compute batch size for.imgsz (int, optional): The image size used as input for the YOLO model. Defaults to 640.fraction (float, optional): The fraction of available CUDA memory to use. Defaults to 0.60.batch_size (int, optional): The default batch size to use if an error is detected. Defaults to 16.Returns:(int): The optimal batch size."""# Check device# 这段代码是 autobatch 函数的开头部分,它负责检查模型所在的设备是否适合执行自动批量大小调整,并验证是否满足必要的条件。# 定义前缀。 使用 colorstr 函数来定义一个前缀,用于所有日志消息,以便于识别。# def colorstr(*input):# -> 它用于生成带有ANSI转义序列的字符串,这些转义序列可以使终端中的文本显示不同的颜色和样式。# -> 函数通过遍历 args 中的每个元素(颜色或样式),从 colors 字典中获取对应的ANSI转义序列,并将其与传入的 string 字符串连接起来。最后,它还会添加一个 colors["end"] 序列,用于重置终端的颜色和样式到默认状态。# -> return "".join(colors[x] for x in args) + f"{string}" + colors["end"]prefix = colorstr("AutoBatch: ")# 记录信息。使用日志记录器 LOGGER 记录一条信息,表明正在计算给定图像尺寸 imgsz 和 CUDA 内存使用率 fraction 下的最佳批量大小。LOGGER.info(f"{prefix}Computing optimal batch size for imgsz={imgsz} at {fraction * 100}% CUDA memory utilization.") # {prefix}在 CUDA 内存利用率为 {fraction * 100}% 时,计算 imgsz={imgsz} 的最佳批量大小。# 获取模型设备。通过访问模型参数迭代器中的下一个元素来获取模型所在的设备(例如 GPU 或 CPU)。device = next(model.parameters()).device # get model device# 检查设备类型。 检查设备是否为 CPU 或 Apple Metal Performance Shaders (MPS)。如果是,说明代码不适用于这些设备,因为 autobatch 函数旨在用于 CUDA 设备(GPU)。if device.type in {"cpu", "mps"}:# 记录警告并返回默认批量大小。如果设备不是 CUDA 设备,记录一条警告信息,指出该函数仅适用于 CUDA 设备,并使用默认的批量大小。LOGGER.info(f"{prefix} ⚠️ intended for CUDA devices, using default batch-size {batch_size}") # {prefix} ⚠️适用于 CUDA 设备,使用默认批量大小 {batch_size}。# 返回默认的批量大小,并结束函数执行。return batch_size# 检查 torch.backends.cudnn.benchmark 设置。检查 PyTorch 的 cudnn.benchmark 设置是否为 True 。这个设置会影响 PyTorch 如何选择算法和卷积实现,可能会影响内存使用和性能。if torch.backends.cudnn.benchmark:LOGGER.info(f"{prefix} ⚠️ Requires torch.backends.cudnn.benchmark=False, using default batch-size {batch_size}") # {prefix} ⚠️ 需要 torch.backends.cudnn.benchmark=False,使用默认批量大小 {batch_size}。# 记录警告并返回默认批量大小。如果 cudnn.benchmark 设置为 True ,记录一条警告信息,指出需要将其设置为 False 才能正确执行自动批量大小调整,并使用默认的批量大小。返回默认的批量大小,并结束函数执行。return batch_size# 这段代码的目的是确保 autobatch 函数在正确的环境下执行,并满足所有必要的条件。如果条件不满足,函数将记录适当的警告信息,并返回默认的批量大小。# Inspect CUDA memory 检查 CUDA 内存。# 这段代码是 autobatch 函数中用于检查和记录 CUDA 设备内存状态的部分。# 定义字节到吉字节的转换。将字节转换为吉字节(GiB),因为 1 GiB 等于 2^30 字节。gb = 1 << 30 # bytes to GiB (1024 ** 3)# 获取设备名称。将设备对象转换为字符串并转换为大写,通常格式为 'CUDA:0',表示第一个 CUDA 设备。d = str(device).upper() # 'CUDA:0'# 获取设备属性。使用 PyTorch 的 torch.cuda.get_device_properties 函数获取 CUDA 设备的属性。properties = torch.cuda.get_device_properties(device) # device properties# 计算总内存、已保留内存、已分配内存和空闲内存。# 计算 CUDA 设备的总内存(以吉字节为单位)。t = properties.total_memory / gb # GiB total# 计算 CUDA 设备已保留的内存(以吉字节为单位)。r = torch.cuda.memory_reserved(device) / gb # GiB reserved# 计算 CUDA 设备已分配的内存(以吉字节为单位)。a = torch.cuda.memory_allocated(device) / gb # GiB allocated# 计算 CUDA 设备的空闲内存(以吉字节为单位)。f = t - (r + a) # GiB free# 记录 CUDA 内存状态。使用日志记录器 LOGGER 记录 CUDA 设备的内存状态,包括设备名称、总内存、已保留内存、已分配内存和空闲内存。LOGGER.info(f"{prefix}{d} ({properties.name}) {t:.2f}G total, {r:.2f}G reserved, {a:.2f}G allocated, {f:.2f}G free") # {prefix}{d} ({properties.name}) {t:.2f}G 总计, {r:.2f}G 保留, {a:.2f}G 分配, {f:.2f}G 空闲。# Profile batch sizes 配置文件批次大小。# 这段代码是 autobatch 函数的核心部分,它负责通过试验不同的批量大小并测量它们对 CUDA 内存的影响来确定最佳批量大小。# 变量定义。一个包含不同批量大小的列表,用于测试。batch_sizes = [1, 2, 4, 8, 16]# 尝试执行。尝试执行以下操作,如果出现任何异常,则执行 except 块。try:# 创建空图像张量。为每个批量大小创建一个空的图像张量,形状为 (b, 3, imgsz, imgsz) 。img = [torch.empty(b, 3, imgsz, imgsz) for b in batch_sizes]# 评估每个批量大小。使用 profile 函数评估每个批量大小的内存使用情况。 n=3 可能表示每个批量大小被评估 3 次。# def profile(input, ops, n=10, device=None): -> 它用于评估模型或操作(ops)在不同输入下的性能和资源消耗。返回包含所有性能评估结果的 results 列表。记录 参数数量 、 GFLOPs 、 内存使用 、 前向传播时间 、 反向传播时间 、 输入 和 输出的形状 。 -> return resultsresults = profile(img, model, n=3, device=device)# Fit a solution 找到解决方案。# 拟合解决方案。# 从 results 中提取每个批量大小的内存使用情况(假设内存使用是 x[2] )。y = [x[2] for x in results if x] # memory [2]# numpy.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)# np.polyfit 是 NumPy 库中的一个函数,用于拟合数据到一个多项式模型。# 参数 :# x :一个数组,包含自变量的值。# y :一个数组,包含因变量的值。# deg :一个整数,表示拟合多项式的阶数。# rcond :一个浮点数,用于确定多项式系数矩阵的条件数。如果为 None ,则使用机器精度。# full :一个布尔值,如果为 True ,则返回完整的拟合信息。# w :一个数组,包含每个数据点的权重。# cov :一个布尔值,如果为 True ,则返回系数的协方差矩阵。# 功能 :# np.polyfit 函数使用最小二乘法拟合一个 deg 阶多项式到数据点 (x, y) 。它返回多项式的系数,从最高次项到最低次项。# 返回值 :# 函数返回一个数组,包含拟合多项式的系数。# np.polyfit 是数据分析和科学计算中常用的函数,特别适用于趋势线分析和数据建模。通过拟合多项式,可以对数据进行预测或者提取数据的潜在规律。# 使用 np.polyfit 函数对批量大小和内存使用情况进行一次多项式拟合。p = np.polyfit(batch_sizes[: len(y)], y, deg=1) # first degree polynomial fit 一次多项式拟合。# 计算最佳批量大小 b ,使得 CUDA 内存使用率达到 fraction 指定的百分比。# 变量解释。# f :CUDA 设备的空闲内存(以吉字节为单位)。 fraction :期望的 CUDA 内存使用率(以小数形式表示,例如 0.6 表示 60%)。 p :一个包含多项式系数的元组,其中 p[0] 是多项式的斜率, p[1] 是 y 截距。# 公式解释。# f * fraction :计算期望使用的 CUDA 内存量(以吉字节为单位)。 p[1] :多项式 y 截距,表示在批量大小为 0 时的内存使用量。 p[0] :多项式斜率,表示批量大小每增加一个单位时内存使用的增加量。 (f * fraction - p[1]) / p[0] :计算达到期望内存使用率所需的批量大小的比率。 int(...) :将计算结果转换为整数,因为批量大小必须是整数。# 计算过程。# 首先,计算期望使用的 CUDA 内存量 : f * fraction 。 然后,从期望使用的内存量中减去多项式的 y 截距 :f * fraction - p[1] 。 接着,将结果除以多项式的斜率 :(f * fraction - p[1]) / p[0] 。 最后,将得到的比率转换为整数,得到最佳批量大小 b 。# 这个公式基于多项式拟合的结果,通过解线性方程来找到在给定内存使用率下的最佳批量大小。这种方法允许在不超过 CUDA 内存限制的情况下,最大化模型训练的批量大小,从而提高训练效率。b = int((f * fraction - p[1]) / p[0]) # y intercept (optimal batch size) y 截距(最佳批量大小)。# 处理异常情况。# 检查结果中是否包含 None。这行代码检查 results 列表中是否包含 None 值,这意味着在测试某个批量大小时出现了错误。if None in results: # some sizes failed 有些尺寸不合格。# 找到第一个失败的批量大小的索引。 如果发现 None ,则使用 index 方法找到第一个 None 值的索引 i 。i = results.index(None) # first fail index 首次失败指数。# 检查最佳批量大小是否大于或等于失败的批量大小。这行代码检查计算出的最佳批量大小 b 是否大于或等于失败的批量大小 batch_sizes[i] 。if b >= batch_sizes[i]: # y intercept above failure point y 截距高于故障点。# 选择一个安全的批量大小。 如果 b 大于或等于失败的批量大小,则选择一个安全的批量大小,即失败批量大小之前的最大的批量大小。这里使用 max(i - 1, 0) 确保索引值不会是负数。b = batch_sizes[max(i - 1, 0)] # select prior safe point 选择先前的安全点。# 如果最佳批量大小 b 在 1 到 1024 的范围之外,使用默认批量大小。if b < 1 or b > 1024: # b outside of safe range b 超出安全范围。b = batch_sizeLOGGER.info(f"{prefix}WARNING ⚠️ CUDA anomaly detected, using default batch-size {batch_size}.") # {prefix}警告⚠️检测到 CUDA 异常,使用默认批量大小 {batch_size}。# numpy.polyval(p, x)# np.polyval 是 NumPy 库中的一个函数,用于计算多项式在特定值的函数值。# 参数 :# p :一个数组,包含多项式的系数,从最高次项到常数项。# x :一个数值、数组或 poly1d 对象,表示要计算多项式值的点。# 功能 :# np.polyval 函数计算多项式 p 在点 x 处的值。如果 p 的长度为 N ,则函数返回的值按照以下公式计算 :p[0]*x**(N-1) + p[1]*x**(N-2) + ... + p[N-2]*x + p[N-1]。# 如果 x 是一个序列,则 p(x) 返回每个元素的多项式值。如果 x 是另一个多项式,则返回复合多项式 p(x(t)) 。# 返回值 :# 函数返回一个 ndarray 或 poly1d 对象,包含在 x 处计算的多项式值。# np.polyval 是一个方便的工具,用于在给定点评估多项式,常用于数据分析、科学计算和工程领域中的多项式函数计算。# 计算实际内存使用率。 使用拟合的多项式计算实际的 CUDA 内存使用率。fraction = (np.polyval(p, b) + r + a) / t # actual fraction predicted 实际分数 预测。# 记录信息并返回最佳批量大小。# 记录使用的最佳批量大小和实际的 CUDA 内存使用率。LOGGER.info(f"{prefix}Using batch-size {b} for {d} {t * fraction:.2f}G/{t:.2f}G ({fraction * 100:.0f}%) ✅") # {prefix}使用批量大小 {b} 表示 {d} {t * 分数:.2f}G/{t:.2f}G ({分数 * 100:.0f}%)✅。# 返回计算出的最佳批量大小。return b# 异常处理。# 如果在尝试过程中出现任何异常,记录警告信息并返回默认批量大小。except Exception as e:LOGGER.warning(f"{prefix}WARNING ⚠️ error detected: {e}, using default batch-size {batch_size}.") # {prefix}警告 ⚠️ 检测到错误:{e},使用默认批量大小 {batch_size}。return batch_size# 这段代码的目的是自动确定最佳批量大小,以便在不超过指定 CUDA 内存使用率的情况下最大化模型性能。通过这种方式,可以确保模型在有限的硬件资源下高效运行,同时避免内存溢出错误。
# 这个方法的目的是自动调整模型的批量大小,以便在不超过指定 CUDA 内存使用率的情况下最大化模型性能。通过这种方式,可以确保模型在有限的硬件资源下高效运行,同时避免内存溢出错误。
相关文章:

YOLOv8-ultralytics-8.2.103部分代码阅读笔记-autobatch.py
autobatch.py ultralytics\utils\autobatch.py 目录 autobatch.py 1.所需的库和模块 2.def check_train_batch_size(model, imgsz640, ampTrue, batch-1): 3.def autobatch(model, imgsz640, fraction0.60, batch_sizeDEFAULT_CFG.batch): 1.所需的库和模块 # Ultraly…...

SycoTec 4060 ER-S德国高精密主轴电机如何支持模具的自动化加工?
SycoTec 4060 ER-S高速电主轴在模具自动化加工中的支持体现在以下几个关键方面: 1.高精度与稳定性:SycoTec 4060 ER-S锥面跳动小于1微米,确保了加工过程中的极高精度,这对于模具的复杂几何形状和严格公差要求至关重要。高精度加工…...

部署 DeepSpeed以推理 defog/sqlcoder-70b-alpha 模型
部署 DeepSpeed 以推理 defog/sqlcoder-70b-alpha 这样的 70B 模型是一个复杂的过程,涉及多个关键步骤。下面是详细的步骤,涵盖了从模型加载、内存优化到加速推理的全过程。 1. 准备环境 确保你的环境配置正确,以便能够顺利部署 defog/sqlc…...

Python网络爬虫基础
Python网络爬虫是一种自动化工具,用于从互联网上抓取信息。它通过模拟人类浏览网页的行为,自动地访问网站并提取所需的数据。网络爬虫在数据挖掘、搜索引擎优化、市场研究等多个领域都有广泛的应用。以下是Python网络爬虫的一些基本概念: 1.…...

每天五分钟机器学习:支持向量机数学基础之超平面分离定理
本文重点 超平面分离定理(Separating Hyperplane Theorem)是数学和机器学习领域中的一个重要概念,特别是在凸集理论和最优化理论中有着广泛的应用。该定理表明,在特定的条件下,两个不相交的凸集总可以用一个超平面进行分离。 定义与表述 超平面分离定理(Separating Hy…...

TCP/IP网络协议栈
TCP/IP网络协议栈是一个分层的网络模型,用于在互联网和其他网络中传输数据。它由几个关键的协议层组成,每一层负责特定的功能。以下是对TCP/IP协议栈的简要介绍: TCP/IP协议模型的分层 1. 应用层(Application Layer)…...

利用编程思维做题之最小堆选出最大的前10个整数
1. 理解问题 我们需要设计一个程序,读取 80,000 个无序的整数,并将它们存储在顺序表(数组)中。然后从这些整数中选出最大的前 10 个整数,并打印它们。要求我们使用时间复杂度最低的算法。 由于数据量很大,直…...

详解MVC架构与三层架构以及DO、VO、DTO、BO、PO | SpringBoot基础概念
🙋大家好!我是毛毛张! 🌈个人首页: 神马都会亿点点的毛毛张 今天毛毛张分享的是SpeingBoot框架学习中的一些基础概念性的东西:MVC结构、三层架构、POJO、Entity、PO、VO、DO、BO、DTO、DAO 文章目录 1.架构1.1 基本…...

Unity C# 影响性能的坑点
c用的时间长了怕unity的坑忘了,记录一下。 GetComponent最好使用GetComponent<T>()的形式, 继承自Monobehaviour的函数要避免空的Awake()、Start()、Update()、FixedUpdate().这些空回调会造成性能浪费 GetComponent方法最好避免在Update当中使用…...

工作学习:切换git账号
概括 最近工作用的git账号下发下来了,需要切换一下使用的账号。因为是第一次弄,不熟悉,现在记录一下。 打开设置 路径–git—git remotes,我这里选择项是Manage Remotes,点进去就可以了。 之后会出现一个输入框&am…...
)
量化交易系统开发-实时行情自动化交易-8.量化交易服务平台(一)
19年创业做过一年的量化交易但没有成功,作为交易系统的开发人员积累了一些经验,最近想重新研究交易系统,一边整理一边写出来一些思考供大家参考,也希望跟做量化的朋友有更多的交流和合作。 接下来会对于收集整理的33个量化交易服…...

Scala习题
姓名,语文,数学,英语 张伟,87,92,88 李娜,90,85,95 王强,78,90,82 赵敏,92,88,91 孙涛,…...

结构方程模型(SEM)入门到精通:lavaan VS piecewiseSEM、全局估计/局域估计;潜变量分析、复合变量分析、贝叶斯SEM在生态学领域应用
目录 第一章 夯实基础 R/Rstudio简介及入门 第二章 结构方程模型(SEM)介绍 第三章 R语言SEM分析入门:lavaan VS piecewiseSEM 第四章 SEM全局估计(lavaan)在生态学领域高阶应用 第五章 SEM潜变量分析在生态学领域…...

OpenCV图像基础处理:通道分离与灰度转换
在计算机视觉处理中,理解图像的颜色通道和灰度表示是非常重要的基础知识。今天我们通过Python和OpenCV来探索图像的基本组成。 ## 1. 图像的基本组成 在数字图像处理中,彩色图像通常由三个基本颜色通道组成: - 蓝色(Blue&#x…...

C++ 类和对象(类型转换、static成员)
目录 一、前言 二、正文 1.隐式类型转换 1.1隐式类型转换的使用 2.static成员 2.1 static 成员的使用 2.1.1static修辞成员变量 2.1.2 static修辞成员函数 三、结语 一、前言 大家好,我们又见面了。昨天我们已经分享了初始化列表:https://blog.c…...
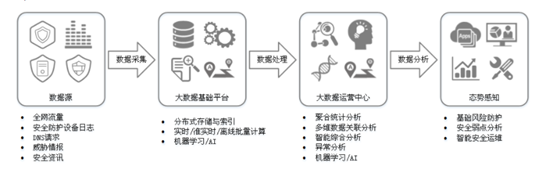
【网络安全设备系列】12、态势感知
0x00 定义: 态势感知(Situation Awareness,SA)能够检测出超过20大类的云上安全风险,包括DDoS攻击、暴力破解、Web攻击、后门木马、僵尸主机、异常行为、漏洞攻击、命令与控制等。利用大数据分析技术,态势感…...

Linux介绍与安装指南:从入门到精通
1. Linux简介 1.1 什么是Linux? Linux是一种基于Unix的操作系统,由Linus Torvalds于1991年首次发布。Linux的核心(Kernel)是开源的,允许任何人自由使用、修改和分发。Linux操作系统通常包括Linux内核、GNU工具集、图…...

BGE-M3模型结合Milvus向量数据库强强联合实现混合检索
在基于生成式人工智能的应用开发中,通过关键词或语义匹配的方式对用户提问意图进行识别是一个很重要的步骤,因为识别的精准与否会影响后续大语言模型能否检索出合适的内容作为推理的上下文信息(或选择合适的工具)以给出用户最符合…...
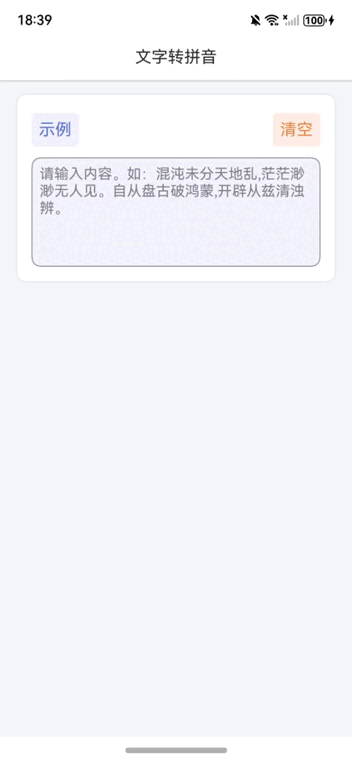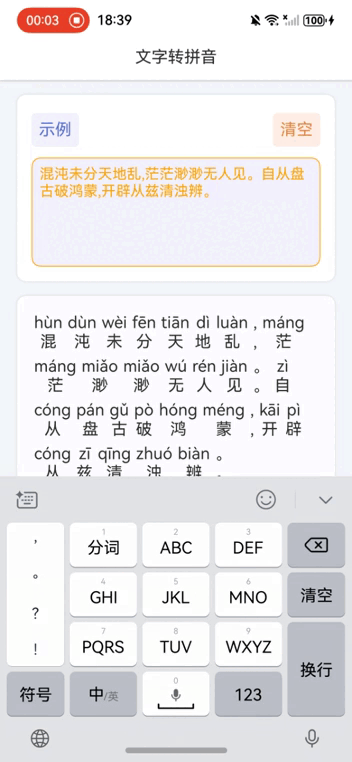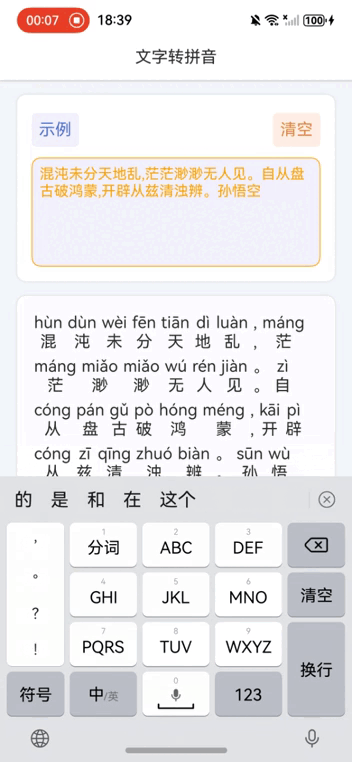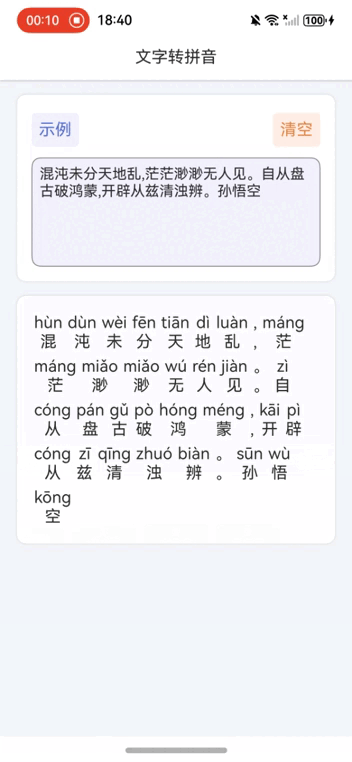
鸿蒙NEXT开发案例:文字转拼音
【引言】 在鸿蒙NEXT开发中,文字转拼音是一个常见的需求,本文将介绍如何利用鸿蒙系统和pinyin-pro库实现文字转拼音的功能。 【环境准备】 • 操作系统:Windows 10 • 开发工具:DevEco Studio NEXT Beta1 Build Version: 5.0.…...
)
CTF之密码学(栅栏加密)
栅栏密码是古典密码的一种,其原理是将一组要加密的明文划分为n个一组(n通常根据加密需求确定,且一般不会太大,以保证密码的复杂性和安全性),然后取每个组的第一个字符(有时也涉及取其他位置的字…...

保姆级避坑指南:在Ubuntu 22.04上为ROS2 Humble编译OpenCV 4.2.0和cv_bridge
深度解析:Ubuntu 22.04下ROS2 Humble与OpenCV 4.2.0的精准版本匹配实战 当视觉SLAM遇上ROS2生态,版本依赖就像一场精密的外科手术。本文将带你穿透ORB-SLAM3等视觉算法与ROS2 Humble环境整合时的核心痛点——特别是OpenCV 4.2.0与cv_bridge的版本锁定机…...
)
QT 5.14.0实战:手把手教你用QLineEdit打造一个带验证码的登录框(附完整样式代码)
QT 5.14.0实战:手把手教你用QLineEdit打造一个带验证码的登录框(附完整样式代码) 在GUI开发中,登录界面是最基础也最考验细节的组件之一。一个优秀的登录框不仅需要功能完整,还要在用户体验上下足功夫——比如实时输入…...

Phi-4-mini-reasoning 128K上下文应用创新:法律条文交叉引用推理案例
Phi-4-mini-reasoning 128K上下文应用创新:法律条文交叉引用推理案例 1. 模型简介与核心能力 Phi-4-mini-reasoning 是一个轻量级开源模型,专注于高质量推理任务。作为Phi-4模型家族成员,它通过合成数据训练和微调,特别擅长处理…...

Visual C++运行库一键修复终极指南:快速解决系统依赖问题
Visual C运行库一键修复终极指南:快速解决系统依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库是Windows系统中不可或缺的组件…...

数学动画音频同步:让几何图形随音乐起舞的技术实现
数学动画音频同步:让几何图形随音乐起舞的技术实现 【免费下载链接】manim A community-maintained Python framework for creating mathematical animations. 项目地址: https://gitcode.com/GitHub_Trending/man/manim 在数学可视化领域,Manim…...
)
JS 缓存函数(缓存函数计算结果、缓存异步函数的执行结果以及带过期时间)
JS 缓存函数 一、普通函数结果缓存(同步缓存) 实现一个通用缓存高阶函数,核心逻辑:第一次执行计算并缓存结果,后续相同参数直接读取缓存,不再重复执行。 实现代码 // 缓存高阶函数:接收一个函数…...

为什么需要虚拟摄像头?OBS-VirtualCam 3大核心价值解析
为什么需要虚拟摄像头?OBS-VirtualCam 3大核心价值解析 【免费下载链接】obs-virtual-cam obs-studio plugin to simulate a directshow webcam 项目地址: https://gitcode.com/gh_mirrors/ob/obs-virtual-cam 在视频会议和在线教学中,你是否曾希…...

基于IEEE39节点系统的风力发电机组并网改造与稳定性研究
基于IEEE39节点系统的风力发电机组并网改造与稳定性研究 摘要 随着可再生能源在电力系统中占比的不断提升,风电并网技术已成为电力系统领域的研究热点。本文针对IEEE39节点标准测试系统,将其工作频率从60Hz改造为50Hz,并将30、32、34、37号节点的同步发电机分别替换为不同…...
:渐进式任务学习框架在行人轨迹预测中的实践与优化)
轨迹预测新范式(ECCV’24):渐进式任务学习框架在行人轨迹预测中的实践与优化
1. 行人轨迹预测的挑战与渐进式学习框架的诞生 预测行人未来轨迹一直是计算机视觉和智能体交互领域的核心难题。想象一下,当你走在拥挤的商场里,大脑会不自觉地预测周围行人的移动方向——这种看似简单的行为,对AI系统来说却需要处理复杂的时…...

SoundSwitch音频配置文件深度解析:应用触发和多设备管理的完整指南
SoundSwitch音频配置文件深度解析:应用触发和多设备管理的完整指南 【免费下载链接】SoundSwitch C# application to switch default playing device. Download: https://soundswitch.aaflalo.me/ 项目地址: https://gitcode.com/gh_mirrors/so/SoundSwitch …...