open-instruct - 训练开放式指令跟随语言模型

文章目录
- 关于 open-instruct
- 设置
- 训练
- 微调
- 偏好调整
- RLVR
- 污染检查
- 开发中
- 仓库结构
- 致谢
关于 open-instruct
- github : https://github.com/allenai/open-instruct
这个仓库是我们对在公共数据集上对流行的预训练语言模型进行指令微调的开放努力。我们发布这个仓库,并将持续更新它,包括:
- 使用最新技术和指令数据集统一格式微调语言模型的代码。
- 在一系列基准上运行标准评估的代码,旨在针对这些语言模型的多种能力。
- 我们在探索中构建的检查点或其他有用的工件。
请参阅我们的第一篇论文
How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
关于这个项目背后的更多想法以及我们的初步发现,请参阅我们的第二篇论文。
Camels in a Changing Climate: Enhancing LM Adaptation with Tulu 2
关于使用Llama-2模型和直接偏好优化的结果。我们仍在开发更多模型。有关涉及PPO和DPO的更近期的结果,请参阅我们的第三篇论文
Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback
设置
我们的设置大部分遵循我们的
Dockerfile
, 使用 Python 3.10。注意,Open Instruct 是一个研究代码库,不保证向后兼容性。 我们提供两种安装策略:
- 本地安装:这是推荐安装 Open Instruct 的方式。您可以通过运行以下命令安装依赖项:
pip install --upgrade pip "setuptools<70.0.0" wheel
# TODO, unpin setuptools when this issue in flash attention is resolved
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu121
pip install packaging
pip install flash-attn==2.6.3 --no-build-isolation
pip install -r requirements.txt
python -m nltk.downloader punkt
pip install -e .
- Docker 安装: 您也可以使用 Dockerfile 来构建 Docker 镜像。您可以使用以下命令来构建镜像:
docker build --build-arg CUDA=12.1.0 --build-arg TARGET=cudnn8-devel --build-arg DIST=ubuntu20.04 . -t open_instruct_dev
# if you are interally at AI2, you can create an image like this:
beaker image delete $(whoami)/open_instruct_dev
beaker image create open_instruct_dev -n open_instruct_dev -w ai2/$(whoami)
如果您在 AI2 内部,您可以使用我们始终最新的自动构建镜像来启动实验:nathanl/open_instruct_auto。
训练
设置好环境后,您就可以开始一些实验了。我们在下面提供了一些示例。要了解有关如何重现Tulu 3模型的更多信息,请参阅Tulu 3自述文件。Tulu 1和Tulu 2的说明和文档在Tulu 1和2自述文件中。
微调
您可以使用以下命令开始:
# quick debugging run using 1 GPU
sh scripts/finetune_with_accelerate_config.sh 1 configs/train_configs/sft/mini.yaml
# train an 8B tulu3 model using 8 GPU
sh scripts/finetune_with_accelerate_config.sh 8 configs/train_configs/tulu3/tulu3_sft.yaml
偏好调整
# quick debugging run using 1 GPU
sh scripts/dpo_train_with_accelerate_config.sh 1 configs/train_configs/dpo/mini.yaml
# train an 8B tulu3 model using 8 GPU
sh scripts/finetune_with_accelerate_config.sh 8 configs/train_configs/tulu3/tulu3_dpo_8b.yaml
RLVR
# quick debugging run using 2 GPU (1 for inference, 1 for training)
# here we are using `HuggingFaceTB/SmolLM2-360M-Instruct`; it's prob not
# gonna work, but it's easy to test run and print stuff.
python open_instruct/ppo_vllm_thread_ray_gtrl.py \--dataset_mixer '{"ai2-adapt-dev/gsm8k_math_ifeval_ground_truth_mixed": 1.0}' \--dataset_train_splits train \--dataset_eval_mixer '{"ai2-adapt-dev/gsm8k_math_ground_truth": 1.0}' \--dataset_eval_splits test \--max_token_length 2048 \--max_prompt_token_length 2048 \--response_length 2048 \--model_name_or_path HuggingFaceTB/SmolLM2-360M-Instruct \--reward_model_path HuggingFaceTB/SmolLM2-360M-Instruct \--non_stop_penalty \--stop_token eos \--temperature 1.0 \--ground_truths_key ground_truth \--chat_template tulu \--sft_messages_key messages \--learning_rate 3e-7 \--total_episodes 10000 \--penalty_reward_value -10.0 \--deepspeed_stage 3 \--per_device_train_batch_size 2 \--local_rollout_forward_batch_size 2 \--local_mini_batch_size 32 \--local_rollout_batch_size 32 \--num_epochs 1 \--actor_num_gpus_per_node 1 \--vllm_tensor_parallel_size 1 \--beta 0.05 \--apply_verifiable_reward true \--output_dir output/rlvr_1b \--seed 3 \--num_evals 3 \--save_freq 100 \--reward_model_multiplier 0.0 \--gradient_checkpointing \--with_tracking# train an 8B tulu3 model using 8 GPU (1 for inference, 7 for training)
python open_instruct/ppo_vllm_thread_ray_gtrl.py \--dataset_mixer '{"ai2-adapt-dev/gsm8k_math_ifeval_ground_truth_mixed": 1.0}' \--dataset_train_splits train \--dataset_eval_mixer '{"ai2-adapt-dev/gsm8k_math_ground_truth": 1.0}' \--dataset_eval_splits test \--max_token_length 2048 \--max_prompt_token_length 2048 \--response_length 2048 \--model_name_or_path allenai/Llama-3.1-Tulu-3-8B-DPO \--reward_model_path allenai/Llama-3.1-Tulu-3-8B-RM \--non_stop_penalty \--stop_token eos \--temperature 1.0 \--ground_truths_key ground_truth \--chat_template tulu \--sft_messages_key messages \--learning_rate 3e-7 \--total_episodes 10000000 \--penalty_reward_value -10.0 \--deepspeed_stage 3 \--per_device_train_batch_size 2 \--local_rollout_forward_batch_size 2 \--local_mini_batch_size 32 \--local_rollout_batch_size 32 \--actor_num_gpus_per_node 7 \--vllm_tensor_parallel_size 1 \--beta 0.05 \--apply_verifiable_reward true \--output_dir output/rlvr_8b \--seed 3 \--num_evals 3 \--save_freq 100 \--reward_model_multiplier 0.0 \--gradient_checkpointing \--with_tracking
污染检查
我们发布了用于测量指令调整数据集和评估数据集之间重叠的脚本./decontamination。有关更多详细信息,请参阅自述文件。
开发中
当向此仓库提交PR时,我们使用以下方式检查open_instruct/中的核心代码样式:
make style
make quality
仓库结构
├── assets/ <- Images, licenses, etc.
├── configs/
| ├── beaker_configs/ <- AI2 Beaker configs
| ├── ds_configs/ <- DeepSpeed configs
| └── train_configs/ <- Training configs
├── decontamination/ <- Scripts for measuring train-eval overlap
├── eval/ <- Evaluation suite for fine-tuned models
├── human_eval/ <- Human evaluation interface (not maintained)
├── open_instruct/ <- Source code (flat)
├── quantize/ <- Scripts for quantization
├── scripts/ <- Core training and evaluation scripts
└── Dockerfile <- Dockerfile
致谢
Open Instruct 是一个受益于许多开源项目和库的项目。我们特别感谢以下项目:
- HuggingFace Transformers : 我们为微调脚本适配了 Hugging Face 的 Trainer。
- HuggingFace TRL 和 eric-mitchell/direct-preference-optimization : 我们的偏好调整代码改编自 TRL 和 Eric Mitchell 的 DPO 代码。
- OpenAI 的 lm-human-preferences, summarize-from-feedback, 和vwxyzjn/summarize_from_feedback_details : 我们的核心PPO代码是从OpenAI的原始RLHF代码改编而来。
Huang et al (2024)'s reproduction work 关于OpenAI的基于反馈的总结工作的内容。 - OpenRLHF : 我们将 OpenRLHF 的 Ray + vLLM 分布式代码进行了适配,以扩展 PPO RLVR 训练至 70B 规模。
相关文章:
open-instruct - 训练开放式指令跟随语言模型
文章目录 关于 open-instruct设置训练微调偏好调整RLVR 污染检查开发中仓库结构 致谢 关于 open-instruct github : https://github.com/allenai/open-instruct 这个仓库是我们对在公共数据集上对流行的预训练语言模型进行指令微调的开放努力。我们发布这个仓库,并…...

DI依赖注入详解
DI依赖注入 声明了一个成员变量(对象)之后,在该对象上面加上注解AutoWired注解,那么在程序运行时,该对象自动在IOC容器中寻找对应的bean对象,并且将其赋值给成员变量,完成依赖注入。 AutoWire…...

TDengine在debian安装
参考官网文档: 官网安装文档链接 从列表中下载获得 Deb 安装包; TDengine-server-3.3.4.3-Linux-x64.deb (61 M) 进入到安装包所在目录,执行如下的安装命令: sudo dpkg -i TDengine-server-<version>-Linux-x64.debNOTE 当…...

【C#设计模式(15)——命令模式(Command Pattern)】
前言 命令模式的关键通过将请求封装成一个对象,使命令的发送者和接收者解耦。这种方式能更方便地添加新的命令,如执行命令的排队、延迟、撤销和重做等操作。 代码 #region 基础的命令模式 //命令(抽象类) public abstract class …...

XGBoost库介绍:提升机器学习模型的性能
XGBoost库介绍:提升机器学习模型的性能 在机器学习领域,模型的准确性和训练效率是最为关注的两大因素。特别是在处理大量数据和复杂任务时,传统的机器学习算法可能无法满足高效和准确性的需求。XGBoost(eXtreme Gradient Boostin…...

网络安全构成要素
一、防火墙 组织机构内部的网络与互联网相连时,为了避免域内受到非法访问的威胁,往往会设置防火墙。 使用NAT(NAPT)的情况下,由于限定了可以从外部访问的地址,因此也能起到防火墙的作用。 二、IDS入侵检…...

SpringMVC——SSM整合
SSM整合 创建工程 在pom.xml中导入坐标 <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_…...
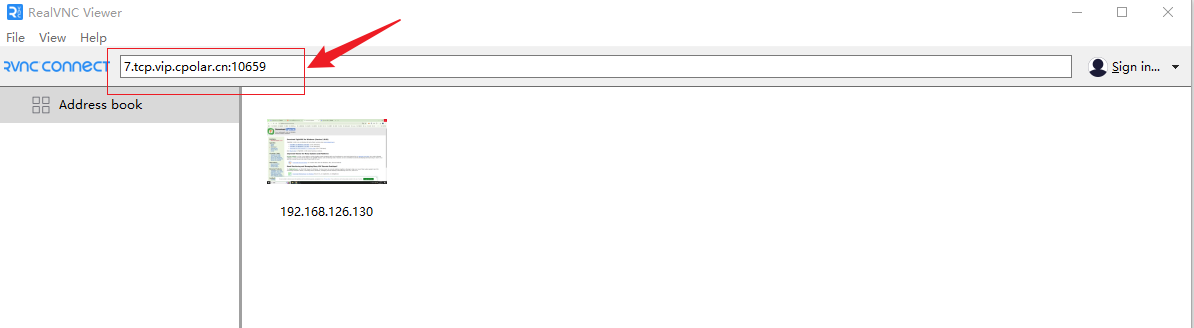
Windows系统电脑安装TightVNC服务端结合内网穿透实现异地远程桌面
文章目录 前言1. 安装TightVNC服务端2. 局域网VNC远程测试3. Win安装Cpolar工具4. 配置VNC远程地址5. VNC远程桌面连接6. 固定VNC远程地址7. 固定VNC地址测试 前言 在追求高效、便捷的数字化办公与生活的今天,远程桌面服务成为了连接不同地点、不同设备之间的重要桥…...

【ubuntu24.04】GTX4700 配置安装cuda
筛选显卡驱动显卡驱动 NVIDIA-Linux-x86_64-550.135.run 而后重启:最新的是12.6 用于ubuntu24.04 ,但是我的4700的显卡驱动要求12.4 cuda...

Spring Boot 动态数据源切换
背景 随着互联网应用的快速发展,多数据源的需求日益增多。Spring Boot 以其简洁的配置和强大的功能,成为实现动态数据源切换的理想选择。本文将通过具体的配置和代码示例,详细介绍如何在 Spring Boot 应用中实现动态数据源切换,帮…...

MySQL技巧之跨服务器数据查询:进阶篇-从A服务器的MySQ数据库复制到B服务器的SQL Server数据库的表中
MySQL技巧之跨服务器数据查询:进阶篇-从A服务器的MySQ数据库复制到B服务器的SQL Server数据库的表中 基础篇已经描述:借用微软的SQL Server ODBC 即可实现MySQL跨服务器间的数据查询。 而且还介绍了如何获得一个在MS SQL Server 可以连接指定实例的MyS…...

大语言模型LLM的微调中 QA 转换的小工具 xlsx2json.py
在训练语言模型中,需要将文件整理成规范的文档,因为文档本身会有很多不规范的地方,为了训练的正确,将文档进行规范处理。代码的功能是读取一个 Excel 文件,将其数据转换为 JSON 格式,并将 JSON 数据写入到一…...

CFD 在生物反应器放大过程中的作用
工艺工程师最常想到的一个问题是“如何将台式反应器扩大到工业规模的反应器?”。这个问题的答案并不简单,也不容易得到。例如,人们误以为工业规模的反应器的性能与台式反应器相同。因此,扩大规模的过程并不是一件容易的事。必须对…...

Axios与FastAPI结合:构建并请求用户增删改查接口
在现代Web开发中,FastAPI以其高性能和简洁的代码结构成为了构建RESTful API的热门选择。而Axios则因其基于Promise的HTTP客户端特性,成为了前端与后端交互的理想工具。本文将介绍FastAPI和Axios的结合使用,通过一个用户增删改查(C…...

美畅物联丨如何通过ffmpeg排查视频问题
在我们日常使用畅联AIoT开放云平台的过程中,摄像机视频无法播放是较为常见的故障。尤其是当碰到摄像机视频不能正常播放的状况时,哪怕重启摄像机,也仍然无法使其恢复正常的工作状态,这着实让人感到头疼。这个时候,可以…...

基于OpenCV视觉库让机械手根据视觉判断物体有无和分类抓取的例程
项目实例,在一个无人封闭的隔绝场景中,根据视觉判断物件的有无,通过机械手 进行物件分类提取,并且返回状态结果; 实际的场景是有一个类似采血的固件支架盘,上面很多采血管,采血管帽颜色可能不同…...

QChart数据可视化
目录 一、QChart基本介绍 1.1 QChart基本概念与用途 1.2 主要类的介绍 1.2.1 QChartView类 1.2.2 QChart类 1.2.3QAbstractSeries类 1.2.4 QAbstractAxis类 1.2.5 QLegendMarker 二、与图表交互 1. 动态绘制数据 2. 深入数据 3. 缩放和滚动 4. 鼠标悬停 三、主题 …...

转换的艺术:如何在JavaScript中序列化Set为Array、Object及逆向操作
先认识一下Set 概念:存储唯一值的集合,元素只能是值,没有键与之对应。Set中的每个值都是唯一的。 特性: 值的集合,值可以是任何类型。 值的唯一性,每个值只能出现一次。 保持了插入顺序。 不支持通过索引来…...

万能门店小程序管理系统存在前台任意文件上传漏洞
免责声明: 本文旨在提供有关特定漏洞的深入信息,帮助用户充分了解潜在的安全风险。发布此信息的目的在于提升网络安全意识和推动技术进步,未经授权访问系统、网络或应用程序,可能会导致法律责任或严重后果。因此,作者不对读者基于本文内容所采取的任何行为承担责任。读者在…...

详解Rust泛型用法
文章目录 基础语法泛型与结构体泛型约束泛型与生命周期泛型与枚举泛型和Vec静态泛型(const 泛型)类型别名默认类型参数Sized Trait与泛型常量函数与泛型泛型的性能 Rust是一种系统编程语言,它拥有强大的泛型支持,泛型是Rust中用于实现代码复用和类型安全…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...