Python3 爬虫 Scrapy的使用
安装完成Scrapy以后,可以使用Scrapy自带的命令来创建一个工程模板。
一、创建项目
使用Scrapy创建工程的命令为:
scrapy startproject <工程名>例如,创建一个抓取百度的Scrapy项目,可以将命令写为:
scrapy startproject baidu工程名可以使用英文字母和数字的组合,但是绝对不能使用“scrapy”(小写)作为工程名,否则爬虫无法运行。也不要使用任何已经安装的Python第三方库的名称作为工程名,否则可能会出现奇怪的错误。这是由于Python在导入库的时候,会优先从当前工程文件夹中寻找满足条件的文件或者文件夹,如果工程的名称本身就为scrapy,那么Python就无法找到正常的Scrapy库的文件。
创建完成工程以后,Scrapy有以下的提示:
you can start your first spider with:cd baidu scrapy genspider example example.com这个提示的意思是说,可以通过下面的两条命令来创建第一个爬虫。根据它的说明来执行命令:
cd baiduscrapy genspider example baidu.com在Scrapy genspider命令中,有两个参数,“example”和“baidu.com”。其中,第1个参数“example”是爬虫的名字,这个名字可以取英文和数字的组合,但是绝对不能为“scrapy”或者工程的名字。在现在这个例子中,爬虫的工程名为“baidu”,所以这里的第1个参数也不能为“baidu”。
第2个参数“baidu.com”是需要爬取的网址。开发工程师可以修改为任何需要爬取的网址。
需要注意的是,在这个例子中,“baidu.com”没有加“www”,这是因为在浏览器中直接输入“baidu.com”就可以打开百度的首页。如果有一些网址需要添加二级域名才能访问,那么这里也必须要把二级域名加上。例如:
scrapy genspider news news.163.com现在已经把爬虫创建好了,在PyCharm中打开Scrapy的工程,可以看到在spiders文件夹下面有一个example.py 。

这个由Scrapy自动生成的爬虫运行以后是不会报错的,但是它不会输出有用的信息。
现在,将第11行:
pass修改为:
print(response.body.decode())修改完成以后,通过Windows或者Mac、Linux的终端进入爬虫的工程根目录,使用以下命令运行爬虫:
scrapy crawl <爬虫名>这里,启动百度首页爬虫的命令为:
scrapy crawl example需要特别强调的是,Scrapy的爬虫绝对不能通过Python直接运行example.py来运行。
上面的代码运行以后,可以看到并没有百度首页上面的任何文字出。

这是由于Scrapy的爬虫默认是遵守robots.txt协议的,而百度的首页在robots.txt协议中是禁止爬虫爬取的。
要让Scrapy不遵守robots.txt协议,需要修改一个配置。在爬虫的工程文件夹下面找到并打开settings.py文件,可以在里面找到下面的一行代码。
# Obey robots.txt rulesROBOTSTXT_OBEY = True
将True修改为False:
# Obey robots.txt rulesROBOTSTXT_OBEY = False再一次运行爬虫,可以正常获取到百度的首页。
Scrapy的爬虫与普通的Python文件普通爬虫的不同之处在于,Scrapy的爬虫需要在CMD或者终端中输入命令来运行,不能直接运行spiders文件夹下面的爬虫文件。那么如何使用PyCharm来运行或者调试Scrapy的爬虫呢?为了实现这个目的,需要创建另外一个Python文件。文件名可以取任意合法的文件名。这里以“main.py”为例。
main.py文件内容如下:
from scrapy import cmdlinecmdline.execute("scrapy crawl example".split()将main.py文件放在工程的根目录下,这样,PyCharm可以通过运行main.py来运行Scrapy的爬虫。
二、在Scrapy中使用XPath
由于可以从response.body.decode()中得到网页的源代码,那么就可以使用正则表达式从源代码里面提取出需要的信息。但是如果可以使用XPath,则效率将会大大提高。好消息是,Scrapy完全支持XPath。
1. ScrapyXPath语法说明
Scrapy与lxml使用XPath的唯一不同之处在于,Scrapy的XPath语句后面需要用.extract()这个方法。
“extract”这个单词在英语中有“提取”的意思,所以这个.extract()方法的作用正是把获取到的字符串“提取”出来。在Scrapy中,如果不使用.extract()方法,那么XPath获得的结果是保存在一个SelectorList中的,直到调用了.extract()方法,才会将结果以列表的形式生成出来。
这个SelectorList非常有意思,它本身很像一个列表。可以直接使用下标读取里面的每一个元素,也可以像列表一样使用for循环展开,然后对每一个元素使用.extract()方法。同时,又可以先执行SelectorList的.extract()方法,得到的结果是一个列表,接下来既可以用下标来获取每一个元素,也可以使用for循环展开。
2. Scrapy的工程结构
scrapy.cfgtutorial/__init__.pyitems.pypipelines.pysettings.pyspiders/__init__.py...其中对于开发Scrapy爬虫来说,需要关心的内容如下。
(1)spiders文件夹:存放爬虫文件的文件夹。
(2)items.py:定义需要抓取的数据。
(3)pipelines.py:负责数据抓取以后的处理工作。
(4)settings.py:爬虫的各种配置信息。
在有spiders和settings.py这两项的情况下,就已经可以写出爬虫并保存数据了。
但是为什么还有items.py和pipelines.py这两个文件呢?这是由于Scrapy的理念是将数据爬取和数据处理分开。
items.py文件用于定义需要爬取哪些内容。每个内容都是一个Field。
pipelines.py文件用于对数据做初步的处理,包括但不限于初步清洗数据、存储数据等。
--------------------------------------
没有自由的秩序和没有秩序的自由,同样具有破坏性。

相关文章:
Python3 爬虫 Scrapy的使用
安装完成Scrapy以后,可以使用Scrapy自带的命令来创建一个工程模板。 一、创建项目 使用Scrapy创建工程的命令为: scrapy startproject <工程名> 例如,创建一个抓取百度的Scrapy项目,可以将命令写为: scrapy s…...

多线程篇-4--重点概念1(volatile,Synchronized,内存屏障,MESI协议)
一、volatile (1)、简述 volatile是java提供的一个关键字,英文意思为不稳定的。 可以保障被声明对象的可见性和一定程度上的有序性,但不能保证操作的原子性。 当一个变量被声明为volatile时,意味着该变量的值会直接从…...

本地学习axios源码-如何在本地打印axios里面的信息
1. 下载axios到本地 git clone https://github.com/axios/axios.git 2. 下载react项目, 用vite按照提示命令配置一下vite react ts项目 npm create vite my-vue-app --template react 3. 下载koa, 搭建一个axios请求地址的服务端 a.初始化package.json mkdir koa-server…...

1、SpringBoo中Mybatis多数据源动态切换
我们以一个实例来详细说明一下如何在SpringBoot中动态切换MyBatis的数据源。 一、需求 1、用户可以界面新增数据源相关信息,提交后,保存到数据库 2、保存后的数据源需要动态生效,并且可以由用户动态切换选择使用哪个数据源 3、数据库保存了多个数据源的相关记录后,要求…...

【浏览器】缓存与存储
我是目录 浏览器缓存为什么需要浏览器缓存?对浏览器的缓存机制的理解协商缓存和强缓存的区别强缓存协商缓存 点击刷新按钮或者按 F5、按 CtrlF5 (强制刷新)、地址栏回车有什么区别? 浏览器本地存储前端储存的方式有哪些࿱…...

积鼎科技携手西北工业大学动力与能源学院共建复杂多相流仿真联合实验室
11月26日,复杂多相流仿真联合实验室揭牌仪式及技术研讨活动在西北工业大学动力与能源学院成功举办。复杂多相流仿真联合实验室是由西北工业大学动力与能源学院牵头,携手上海积鼎信息科技有限公司与三航铸剑(西安)科技发展有限公司…...

5. langgraph实现高级RAG (Adaptive RAG)
1. 数据准备 from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import Chromaurls ["https://lilianweng.github.io/posts/2023-06-23-age…...

Postman设置接口关联,实现参数化
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 postman设置接口关联 在实际的接口测试中,后一个接口经常需要用到前一个接口返回的结果, 从而让后一个接口能正常执行,这…...
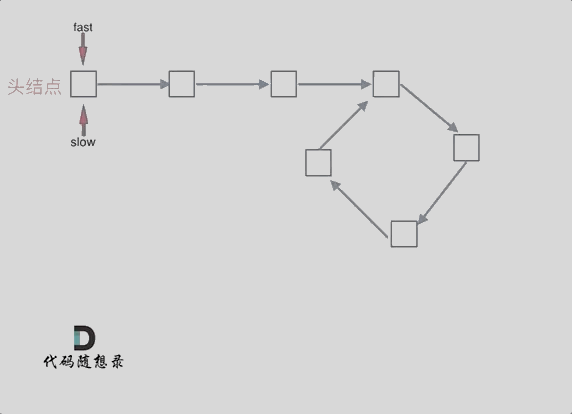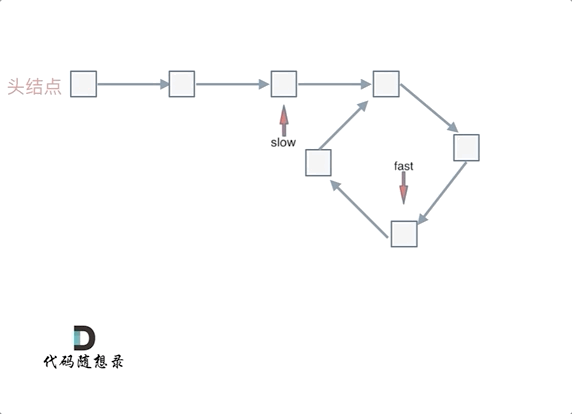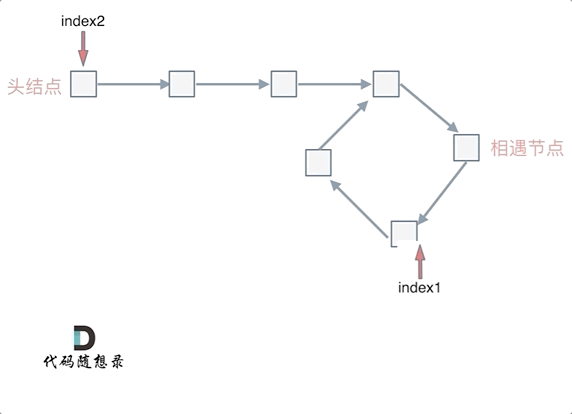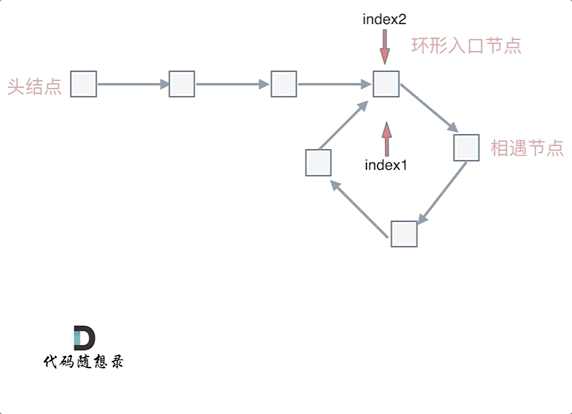
代码随想录day02--链表
移除链表元素 题目 地址:https://leetcode.cn/problems/remove-linked-list-elements/description/ 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 思路是使用虚拟节点的…...

杰发科技AC7803——不同晶振频率时钟的配置
计算公式 PLL_POSDIV [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62] PLL_PREDIV_1 1 2 4 USE_XTAL 24M SYSCLK_FREQ 64M SYSCLK_DIVIDER 1 VCO USE_XTAL*…...

ArcGIS栅格影像裁剪工具
1、前言 在最近的栅格转矢量处理过程中,发现二值化栅格规模太大,3601*3601,并且其中的面元太过细碎,通过arcgis直接栅格转面有将近几十万的要素,拿这样的栅格数据直接运行代码,发现速度很慢还难以执行出来结…...

【查询目录】.NET开源 ORM 框架 SqlSugar 系列
.NET开源 ORM 框架 SqlSugar 系列 【开篇】.NET开源 ORM 框架 SqlSugar 系列【入门必看】.NET开源 ORM 框架 SqlSugar 系列【实体配置】.NET开源 ORM 框架 SqlSugar 系列【Db First】.NET开源 ORM 框架 SqlSugar 系列【Code First】.NET开源 ORM 框架 SqlSugar 系列【数据事务…...

docker快速安装zookeeper
一、拉取镜像 docker pull zookeeper:3.9.3 二、启动zookeeper docker run --restartalways -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime zookeeper:3.9.3 如果需要挂载zookeeper文件及目录,则参数增加: -v /mydata/zookeeper/d…...

MySQL中如何减少回表
在MySQL中,回表是指在使用非聚集索引进行查询时,如果需要获取的数据不在索引页中,就需要根据索引页中的指针返回到数据表中查找实际数据行的过程。这个过程会增加额外的磁盘I/O操作,降低查询性能,特别是在查询大量数据…...

初始Python篇(7)—— 正则表达式
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏: Python 目录 正则表达式的概念 正则表达式的组成 元字符 限定符 其他字符 正则表达式的使用 正则表达式的常见操作方法 match方法的…...

洛谷P1443 马的遍历
简单的bfs 题目链接 P1443 马的遍历 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目描述 有一个 nm 的棋盘,在某个点(x,y) 上有一个马,要求你计算出马到达棋盘上任意一个点最少要走几步。 输入格式 输入只有一行四个整数,分别为 n…...
代理IP地址的含义与设置指南
在数字化时代,互联网已经成为我们日常生活不可或缺的一部分。然而,在享受互联网带来的便利的同时,我们也面临着隐私泄露、访问限制等问题。代理IP地址作为一种有效的网络工具,能够帮助我们解决这些问题。本文将详细介绍代理IP地址…...
)
Vue--------导航守卫(全局,组件,路由独享)
全局导航守卫 beforeEach 全局前置守卫 afterEach 全局后置守卫 路由独享守卫 beforeEnter 路由独享守卫 组件导航守卫 beforeRouteEnter 进入组件前 beforeRouteUpdate 路由改变但是组件复调用 beforeRouteLeave 离开组件之前 执行顺…...

ElasticSearch7.x入门教程之全文搜索(七)
文章目录 前言一、多条件查询:bool query二、更加精准查询:dis_max query总结 前言 这里再接着上一篇文章继续记录。非常感谢江南一点雨松哥的文章。 欢迎大家去查看,地址:http://www.javaboy.org 一、多条件查询:boo…...

Adversarial Learning forSemi-Supervised Semantic Segmentation
首先来了解一下对抗学习: 对抗样本:将真实的样本添加扰动而合成的新样本,是由深度神经网络的输入的数据和人工精心设计好的噪声合成得到的,但它不会被人类视觉系统识别错误。然而在对抗数据面前,深度神经网络却是脆弱…...

【Java】通过Mybatis Plus自带的方式,实现公共字段自动填充。
通过Mybatis Plus自带的方式,实现公共字段自动填充。 第一步,创建一个公共字段类,加上对应注解。 Data public class BaseEntity implements Serializable {Serialprivate static final long serialVersionUID 1L;TableField(value "c…...

千问3.5-9B+OpenClaw成本对比:自建模型VS商业API
千问3.5-9BOpenClaw成本对比:自建模型VS商业API 1. 为什么需要关注OpenClaw的token消耗 去年冬天,当我第一次用OpenClaw自动整理全年会议纪要时,看着控制台不断刷新的token消耗记录,手指不自觉地敲起了桌子——这个看似简单的任…...

Linux I/O 演进史:从管道到零拷贝,一篇串起个服务端核心原语倍
前言 在使用 kubectl get $KIND -o yaml 查看 k8s 资源时,输出结果中包含大量由集群自动生成的元数据(如 managedFields、resourceVersion、uid 等)。这些信息在实际复用 yaml 清单时需要手动清理,增加了额外的工作量。 使用 kube…...
)
【国家级数字农场认证标准】:PHP可视化配置合规性检查清单(含GDPR+农业农村部2024新规适配)
第一章:国家级数字农场认证标准的农业数字化背景与合规性演进农业正经历从机械化、自动化向数字化、智能化的历史性跃迁。国家层面推动“数字乡村”战略与“智慧农业三年行动计划”,将数据要素深度融入耕、种、管、收全链条,催生对可验证、可…...

GetQzonehistory:5分钟学会如何永久备份你的QQ空间历史说说
GetQzonehistory:5分钟学会如何永久备份你的QQ空间历史说说 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾担心那些记录着青春时光的QQ空间说说会随着时间流逝而消…...

幕连投屏电脑版
链接:https://pan.quark.cn/s/81fb3b0bcdee幕连投屏电脑版,通过各平台和设备间的屏幕同屏技术,让人们可以更轻松地分享屏幕,使会议教学更直观,家庭生活更精彩,让同屏不再只是冰冷的技术,而拥有了…...

第16章 Mosquitto客户端开发实战
第16章 客户端开发实战 16.1 Python客户端 安装 pip install paho-mqtt基础示例 import paho.mqtt.client as mqttdef on_connect(client, userdata, flags, rc):print(f"Connected: {rc}")client.subscribe("sensor/#")def on_message(client, userdata, …...

BetterNCM-Installer技术指南:从部署到定制的全方位解决方案
BetterNCM-Installer技术指南:从部署到定制的全方位解决方案 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 核心功能解析 1.1 插件架构概览 痛点:用户常因不…...

3分钟搞定APA第7版:微软Word参考文献格式终极配置指南
3分钟搞定APA第7版:微软Word参考文献格式终极配置指南 【免费下载链接】APA-7th-Edition Microsoft Word XSD for generating APA 7th edition references 项目地址: https://gitcode.com/gh_mirrors/ap/APA-7th-Edition 你是否在为学术论文的参考文献格式而…...

我让 Claude 和 Codex 同时审计 个模块,它们只在 个上达成共识犊
整体排查思路 我们的目标是验证以下三个环节是否正常: 登录成功时:服务器是否正确生成了Session并返回了包含正确 JSESSIONID的Cookie给浏览器。 浏览器端:浏览器是否成功接收并存储了该Cookie。 后续请求:浏览器在执行查询等操作…...