5. langgraph实现高级RAG (Adaptive RAG)
1. 数据准备
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chromaurls = ["https://lilianweng.github.io/posts/2023-06-23-agent/","https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/","https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)from langchain_community.embeddings import ZhipuAIEmbeddings
embed = ZhipuAIEmbeddings(model="Embedding-3",api_key="your api key",
)# Add to vectorDB
batch_size = 10
for i in range(0, len(doc_splits), batch_size):# 确保切片不会超出数组边界batch = doc_splits[i:min(i + batch_size, len(doc_splits))]vectorstore = Chroma.from_documents(documents=batch,collection_name="rag-chroma",embedding=embed,persist_directory="./chroma_db")retriever = vectorstore.as_retriever()2. question_router llm模型
### Routerfrom typing import Literalfrom langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAIfrom pydantic import BaseModel, Field
# Data model
class RouteQuery(BaseModel):"""Route a user query to the most relevant datasource."""datasource: Literal["vectorstore", "web_search"] = Field(...,description="Given a user question choose to route it to web search or a vectorstore.",)from langchain_openai import ChatOpenAIllm = ChatOpenAI(temperature=0,model="GLM-4-plus",openai_api_key="your api key",openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
structured_llm_router = llm.with_structured_output(RouteQuery)# Prompt
system = """You are an expert at routing a user question to a vectorstore or web search.
The vectorstore contains documents related to agents, prompt engineering, and adversarial attacks.
Use the vectorstore for questions on these topics. Otherwise, use web-search."""
route_prompt = ChatPromptTemplate.from_messages([("system", system),("human", "{question}"),]
)question_router = route_prompt | structured_llm_router
print(question_router.invoke({"question": "Who will the Bears draft first in the NFL draft?"})
)
print(question_router.invoke({"question": "What are the types of agent memory?"}))
datasource='web_search'
datasource='vectorstore'
3. Retrieval Grader llm模型
# Data model
class GradeDocuments(BaseModel):"""Binary score for relevance check on retrieved documents."""binary_score: str = Field(description="Documents are relevant to the question, 'yes' or 'no'")from langchain_openai import ChatOpenAIllm = ChatOpenAI(temperature=0,model="GLM-4-plus",openai_api_key="your api key",openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
structured_llm_grader = llm.with_structured_output(GradeDocuments)# Prompt
system = """You are a grader assessing relevance of a retrieved document to a user question. \n If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \nIt does not need to be a stringent test. The goal is to filter out erroneous retrievals. \nGive a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages([("system", system),("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),]
)retrieval_grader = grade_prompt | structured_llm_grader
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "document": doc_txt}))
binary_score='yes'
4. Generate llm 模型
### Generatefrom langchain import hub
from langchain_core.output_parsers import StrOutputParser# Prompt
prompt = hub.pull("rlm/rag-prompt")from langchain_openai import ChatOpenAIllm = ChatOpenAI(temperature=0,model="GLM-4-plus",openai_api_key="your api key",openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)# Post-processing
def format_docs(docs):return "\n\n".join(doc.page_content for doc in docs)# Chain
rag_chain = prompt | llm | StrOutputParser()# Run
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)
d:\soft\anaconda\envs\langchain\Lib\site-packages\langsmith\client.py:354: LangSmithMissingAPIKeyWarning: API key must be provided when using hosted LangSmith APIwarnings.warn(In a LLM-powered autonomous agent system, memory is a crucial component. It includes various types of memory and utilizes techniques like Maximum Inner Product Search (MIPS) for efficient information retrieval. This memory system complements the LLM, which acts as the agent's brain, enabling the agent to perform complex tasks effectively.
5. Hallucination Grader
### Hallucination Grader# Data model
class GradeHallucinations(BaseModel):"""Binary score for hallucination present in generation answer."""binary_score: str = Field(description="Answer is grounded in the facts, 'yes' or 'no'")from langchain_openai import ChatOpenAIllm = ChatOpenAI(temperature=0,model="GLM-4-plus",openai_api_key="your api key",openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)# Prompt
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages([("system", system),("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),]
)hallucination_grader = hallucination_prompt | structured_llm_grader
hallucination_grader.invoke({"documents": docs, "generation": generation})
GradeHallucinations(binary_score='yes')
6. Answer Grader llm 模型
# Data model
class GradeAnswer(BaseModel):"""Binary score to assess answer addresses question."""binary_score: str = Field(description="Answer addresses the question, 'yes' or 'no'")from langchain_openai import ChatOpenAIllm = ChatOpenAI(temperature=0,model="GLM-4-plus",openai_api_key="your api key",openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
structured_llm_grader = llm.with_structured_output(GradeAnswer)# Prompt
system = """You are a grader assessing whether an answer addresses / resolves a question \n Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""
answer_prompt = ChatPromptTemplate.from_messages([("system", system),("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),]
)answer_grader = answer_prompt | structured_llm_grader
answer_grader.invoke({"question": question, "generation": generation})
GradeAnswer(binary_score='yes')
7. Question Re-writer llm 模型
# LLM
from langchain_openai import ChatOpenAIllm = ChatOpenAI(temperature=0,model="GLM-4-plus",openai_api_key="your api key",openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)# Prompt
system = """You a question re-writer that converts an input question to a better version that is optimized \n for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning."""
re_write_prompt = ChatPromptTemplate.from_messages([("system", system),("human","Here is the initial question: \n\n {question} \n Formulate an improved question.",),]
)question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})
'To optimize the initial question "agent memory" for vectorstore retrieval, we need to clarify the intent and provide more context. The term "agent memory" could refer to various concepts, such as memory in AI agents, memory management in software agents, or even human agents\' memory in certain contexts. \n\nImproved Question: "What are the key principles and mechanisms involved in memory management for AI agents?"\n\nThis version is more specific and provides clear context, making it easier for a vectorstore retrieval system to identify relevant information. It assumes the intent is to understand how memory is handled in the context of artificial intelligence agents. If the intent is different, please provide more context for further refinement.'
8. Websearch 工具
### Search
import os
from langchain_community.tools.tavily_search import TavilySearchResults
os.environ["TAVILY_API_KEY"] = "your api key"
web_search_tool = TavilySearchResults(k=3)
9. Graph中的State数据结构
from typing import Listfrom typing_extensions import TypedDictclass GraphState(TypedDict):"""Represents the state of our graph.Attributes:question: questiongeneration: LLM generationdocuments: list of documents"""question: strgeneration: strdocuments: List[str]
10. Graph中的各个节点函数
from langchain.schema import Documentdef retrieve(state):"""Retrieve documentsArgs:state (dict): The current graph stateReturns:state (dict): New key added to state, documents, that contains retrieved documents"""print("---RETRIEVE---")question = state["question"]# Retrievaldocuments = retriever.invoke(question)return {"documents": documents, "question": question}def generate(state):"""Generate answerArgs:state (dict): The current graph stateReturns:state (dict): New key added to state, generation, that contains LLM generation"""print("---GENERATE---")question = state["question"]documents = state["documents"]# RAG generationgeneration = rag_chain.invoke({"context": documents, "question": question})return {"documents": documents, "question": question, "generation": generation}def grade_documents(state):"""Determines whether the retrieved documents are relevant to the question.Args:state (dict): The current graph stateReturns:state (dict): Updates documents key with only filtered relevant documents"""print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")question = state["question"]documents = state["documents"]# Score each docfiltered_docs = []for d in documents:score = retrieval_grader.invoke({"question": question, "document": d.page_content})grade = score.binary_scoreif grade == "yes":print("---GRADE: DOCUMENT RELEVANT---")filtered_docs.append(d)else:print("---GRADE: DOCUMENT NOT RELEVANT---")continuereturn {"documents": filtered_docs, "question": question}def transform_query(state):"""Transform the query to produce a better question.Args:state (dict): The current graph stateReturns:state (dict): Updates question key with a re-phrased question"""print("---TRANSFORM QUERY---")question = state["question"]documents = state["documents"]# Re-write questionbetter_question = question_rewriter.invoke({"question": question})return {"documents": documents, "question": better_question}def web_search(state):"""Web search based on the re-phrased question.Args:state (dict): The current graph stateReturns:state (dict): Updates documents key with appended web results"""print("---WEB SEARCH---")question = state["question"]# Web searchdocs = web_search_tool.invoke({"query": question})web_results = "\n".join([d["content"] for d in docs])web_results = Document(page_content=web_results)return {"documents": web_results, "question": question}### Edges ###def route_question(state):"""Route question to web search or RAG.Args:state (dict): The current graph stateReturns:str: Next node to call"""print("---ROUTE QUESTION---")question = state["question"]source = question_router.invoke({"question": question})if source.datasource == "web_search":print("---ROUTE QUESTION TO WEB SEARCH---")return "web_search"elif source.datasource == "vectorstore":print("---ROUTE QUESTION TO RAG---")return "vectorstore"def decide_to_generate(state):"""Determines whether to generate an answer, or re-generate a question.Args:state (dict): The current graph stateReturns:str: Binary decision for next node to call"""print("---ASSESS GRADED DOCUMENTS---")state["question"]filtered_documents = state["documents"]if not filtered_documents:# All documents have been filtered check_relevance# We will re-generate a new queryprint("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---")return "transform_query"else:# We have relevant documents, so generate answerprint("---DECISION: GENERATE---")return "generate"def grade_generation_v_documents_and_question(state):"""Determines whether the generation is grounded in the document and answers question.Args:state (dict): The current graph stateReturns:str: Decision for next node to call"""print("---CHECK HALLUCINATIONS---")question = state["question"]documents = state["documents"]generation = state["generation"]score = hallucination_grader.invoke({"documents": documents, "generation": generation})grade = score.binary_score# Check hallucinationif grade == "yes":print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")# Check question-answeringprint("---GRADE GENERATION vs QUESTION---")score = answer_grader.invoke({"question": question, "generation": generation})grade = score.binary_scoreif grade == "yes":print("---DECISION: GENERATION ADDRESSES QUESTION---")return "useful"else:print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")return "not useful"else:pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")return "not supported"
11. Graph中的各条边
from langgraph.graph import END, StateGraph, STARTworkflow = StateGraph(GraphState)# Define the nodes
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query# Build graph
workflow.add_conditional_edges(START,route_question,{"web_search": "web_search","vectorstore": "retrieve",},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges("grade_documents",decide_to_generate,{"transform_query": "transform_query","generate": "generate",},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges("generate",grade_generation_v_documents_and_question,{"not supported": "generate","useful": END,"not useful": "transform_query",},
)# Compile
app = workflow.compile()
12. Graph可视化
from IPython.display import Image, displaytry:display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except Exception:# This requires some extra dependencies and is optionalpass

13. 不同实例的运行结果
第一个实例
from pprint import pprint# Run
inputs = {"question": "What player at the Bears expected to draft first in the 2024 NFL draft?"
}
for output in app.stream(inputs):for key, value in output.items():# Nodepprint(f"Node '{key}':")# Optional: print full state at each node# pprint.pprint(value["keys"], indent=2, width=80, depth=None)pprint("\n---\n")# Final generation
pprint(value["generation"])
输出:
---ROUTE QUESTION---
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
"Node 'web_search':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('The Chicago Bears were expected to draft Caleb Williams first in the 2024 ''NFL Draft. Williams, a quarterback from USC, was widely considered the top ''prospect after winning the Heisman Trophy in 2022. The Bears indeed selected ''him with the No. 1 overall pick.')
第二个实例
# Run
inputs = {"question": "What is the agent memory?"}
for output in app.stream(inputs):for key, value in output.items():# Nodepprint(f"Node '{key}':")# Optional: print full state at each node# pprint.pprint(value["keys"], indent=2, width=80, depth=None)pprint("\n---\n")# Final generation
pprint(value["generation"])
输出:
---ROUTE QUESTION---
---ROUTE QUESTION TO RAG---
---RETRIEVE---
"Node 'retrieve':"
'\n---\n'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
"Node 'grade_documents':"
'\n---\n'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
"Node 'generate':"
'\n---\n'
('The agent memory in a LLM-powered autonomous agent system is a key component '"that complements the LLM, which functions as the agent's brain. It includes "'various types of memory and utilizes techniques like Maximum Inner Product ''Search (MIPS) to enhance its functionality. This memory system aids the ''agent in retaining and retrieving information crucial for decision-making ''and task execution.')
官网中的问题是:
inputs = {"question": "What are the types of agent memory?"}
但用智谱的模型会限制死循环, 具体修改方法可以参考这篇 文章
langgraph官网链接:https://langchain-ai.github.io/langgraph/tutorials/rag/langgraph_adaptive_rag/#use-graph
如果有任何问题,欢迎在评论区提问。
相关文章:
5. langgraph实现高级RAG (Adaptive RAG)
1. 数据准备 from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.document_loaders import WebBaseLoader from langchain_community.vectorstores import Chromaurls ["https://lilianweng.github.io/posts/2023-06-23-age…...

Postman设置接口关联,实现参数化
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 postman设置接口关联 在实际的接口测试中,后一个接口经常需要用到前一个接口返回的结果, 从而让后一个接口能正常执行,这…...
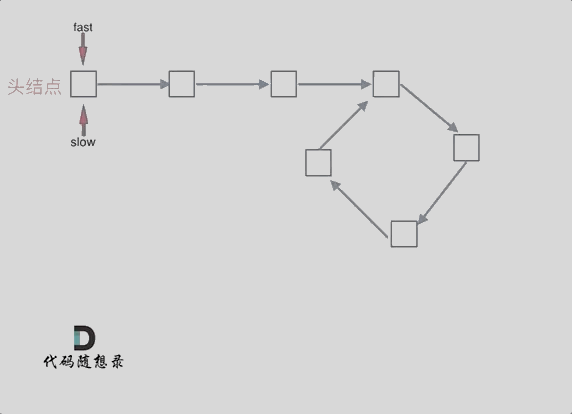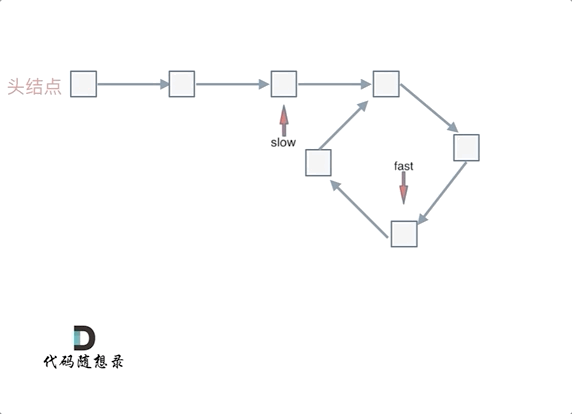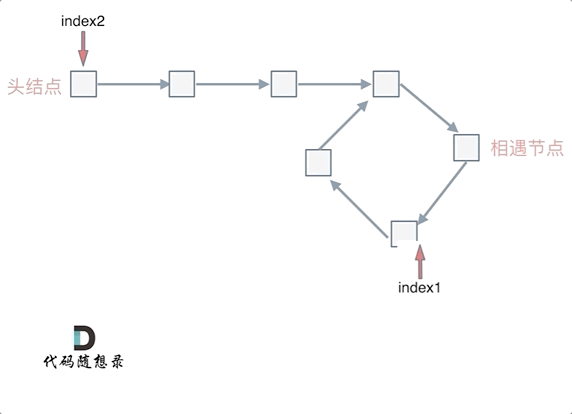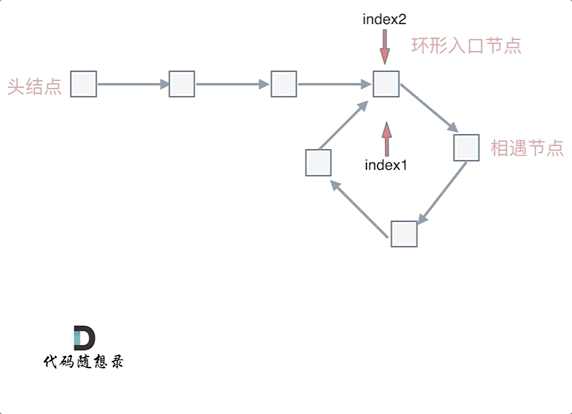
代码随想录day02--链表
移除链表元素 题目 地址:https://leetcode.cn/problems/remove-linked-list-elements/description/ 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 思路是使用虚拟节点的…...

杰发科技AC7803——不同晶振频率时钟的配置
计算公式 PLL_POSDIV [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62] PLL_PREDIV_1 1 2 4 USE_XTAL 24M SYSCLK_FREQ 64M SYSCLK_DIVIDER 1 VCO USE_XTAL*…...

ArcGIS栅格影像裁剪工具
1、前言 在最近的栅格转矢量处理过程中,发现二值化栅格规模太大,3601*3601,并且其中的面元太过细碎,通过arcgis直接栅格转面有将近几十万的要素,拿这样的栅格数据直接运行代码,发现速度很慢还难以执行出来结…...

【查询目录】.NET开源 ORM 框架 SqlSugar 系列
.NET开源 ORM 框架 SqlSugar 系列 【开篇】.NET开源 ORM 框架 SqlSugar 系列【入门必看】.NET开源 ORM 框架 SqlSugar 系列【实体配置】.NET开源 ORM 框架 SqlSugar 系列【Db First】.NET开源 ORM 框架 SqlSugar 系列【Code First】.NET开源 ORM 框架 SqlSugar 系列【数据事务…...

docker快速安装zookeeper
一、拉取镜像 docker pull zookeeper:3.9.3 二、启动zookeeper docker run --restartalways -d --name zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime zookeeper:3.9.3 如果需要挂载zookeeper文件及目录,则参数增加: -v /mydata/zookeeper/d…...

MySQL中如何减少回表
在MySQL中,回表是指在使用非聚集索引进行查询时,如果需要获取的数据不在索引页中,就需要根据索引页中的指针返回到数据表中查找实际数据行的过程。这个过程会增加额外的磁盘I/O操作,降低查询性能,特别是在查询大量数据…...

初始Python篇(7)—— 正则表达式
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏: Python 目录 正则表达式的概念 正则表达式的组成 元字符 限定符 其他字符 正则表达式的使用 正则表达式的常见操作方法 match方法的…...

洛谷P1443 马的遍历
简单的bfs 题目链接 P1443 马的遍历 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目描述 有一个 nm 的棋盘,在某个点(x,y) 上有一个马,要求你计算出马到达棋盘上任意一个点最少要走几步。 输入格式 输入只有一行四个整数,分别为 n…...
代理IP地址的含义与设置指南
在数字化时代,互联网已经成为我们日常生活不可或缺的一部分。然而,在享受互联网带来的便利的同时,我们也面临着隐私泄露、访问限制等问题。代理IP地址作为一种有效的网络工具,能够帮助我们解决这些问题。本文将详细介绍代理IP地址…...
)
Vue--------导航守卫(全局,组件,路由独享)
全局导航守卫 beforeEach 全局前置守卫 afterEach 全局后置守卫 路由独享守卫 beforeEnter 路由独享守卫 组件导航守卫 beforeRouteEnter 进入组件前 beforeRouteUpdate 路由改变但是组件复调用 beforeRouteLeave 离开组件之前 执行顺…...

ElasticSearch7.x入门教程之全文搜索(七)
文章目录 前言一、多条件查询:bool query二、更加精准查询:dis_max query总结 前言 这里再接着上一篇文章继续记录。非常感谢江南一点雨松哥的文章。 欢迎大家去查看,地址:http://www.javaboy.org 一、多条件查询:boo…...

Adversarial Learning forSemi-Supervised Semantic Segmentation
首先来了解一下对抗学习: 对抗样本:将真实的样本添加扰动而合成的新样本,是由深度神经网络的输入的数据和人工精心设计好的噪声合成得到的,但它不会被人类视觉系统识别错误。然而在对抗数据面前,深度神经网络却是脆弱…...

UCOS-II 自学笔记
摘抄于大学期间记录在QQ空间的一篇自学笔记,当前清理空间,本来想直接删除掉的,但是感觉有些舍不得,因此先搬移过来。 一、UC/OS_II体系结构 二、UC/OS_II中的任务 1、任务的基本概念 在UCOS-II中,通常把一个大型任…...

C++ - 二叉搜索树讲解
二叉搜索树概念和定义 二叉搜索树是一个二叉树,其中每个节点的值都满足以下条件: 节点的左子树只包含小于当前节点值的节点。节点的右子树只包含大于当前节点值的节点。左右子树也必须是二叉搜索树。 二叉树搜索树性质 从上面的二叉搜索树定义中可以了…...

基于开源云原生数据仓库 ByConity 体验多种数据分析场景
基于开源云原生数据仓库 ByConity 体验多种数据分析场景 业务背景什么是 ByConity上手实测环境要求测试操作远程登录 ECS 服务器windows10 自带连接工具 执行查询 ByConity 相对于 ELT 能力的优化提升并行度任务级重试并行写入简化数据链路 业务背景 大家都知道,在…...

RabbitMQ 消息确认机制
RabbitMQ 消息确认机制 本文总结了RabbitMQ消息发送过程中的一些代码片段,详细分析了回调函数和发布确认机制的实现,以提高消息传递的可靠性。 返回回调机制的代码分析 主要用途 这个代码主要用于设置RabbitMQ消息发送过程中的回调函数,即…...

Node.js:开发和生产之间的区别
Node.js 中的开发和生产没有区别,即,你无需应用任何特定设置即可使 Node.js 在生产配置中工作。但是,npm 注册表中的一些库会识别使用 NODE_ENV 变量并将其默认为 development 设置。始终在设置了 NODE_ENVproduction 的情况下运行 Node.js。…...

【QT】背景,安装和介绍
TOC 目录 背景 GUI技术 QT的安装 使用流程 QT程序介绍 main.cpp编辑 Wiget.h Widget.cpp form file .pro文件 临时文件 C作为一门比较古老的语言,在人们的认知里始终是以底层,复杂和高性能著称,所以在很多高性能需求的场景之下…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...