【大模型】深度解析 NLP 模型5大评估指标及 应用案例:从 BLEU、ROUGE、PPL 到METEOR、BERTScore
在自然语言处理(NLP)领域,无论是机器翻译、文本生成,还是问答系统开发,模型性能评估指标始终是开发者绕不开的工具。BLEU、ROUGE、PPL(困惑度)、METEOR 和 BERTScore 是五个最具代表性的指标,然而,它们的计算方式、优缺点和适用场景却大不相同。
本文将通过公式推导、代码实现、行业场景分析以及实践案例,深度解析这五大评估指标的特点和应用,帮助你在实际项目中合理选择适合的指标。
1. 引言:行业背景与问题引入
近年来,语言模型如 ChatGPT 和 BERT 已席卷 NLP 领域。然而,如何科学评估这些模型的性能,始终是一个关键问题。例如:
• OpenAI 使用 PPL 衡量 GPT 系列模型的生成流畅度。
• 机器翻译模型 通常以 BLEU 为优化目标。
• 文本摘要 和 问答生成 更偏好使用 ROUGE 评估覆盖内容。
核心问题:
1. 不同 NLP 任务适合哪些评估指标?
2. 这些指标在实际应用中是如何工作的?
接下来,我们将从 BLEU 到 BERTScore,深度解析五大指标的核心原理、计算方法及行业应用。
2. 深度解析五大指标
2.1 BLEU:翻译任务中的黄金标准
定义:
BLEU 是一种评估生成文本与参考文本相似性的指标,主要用于机器翻译任务。它通过计算生成文本与参考文本之间的 n-gram 匹配率 来衡量翻译质量。得分越高,生成的文本越接近参考文本。
公式推导:
BLEU 的计算包括以下步骤:
1. n-gram 精确率(Precision):统计候选文本中的 n-gram,与参考文本匹配的比例。

2. 加权几何平均(Weighted Geometric Mean):
- • 计算不同长度的 n-gram 匹配率的加权几何平均,公式为:
 • 通常
• 通常 均为
,表示每种 n-gram 的权重相等。
3. 惩罚机制(BP, Brevity Penalty):
用于防止生成的文本长度明显短于参考文本时获得高分。公式如下:

4. 最终公式
综合上述步骤,BLEU 的计算公式为:

其中:

案例解析
假设:
• 候选文本:it is a nice day
• 参考文本:today is a nice day
步骤 1:计算 n-gram 匹配率
1. 1-gram 精确率:
• 候选文本的 1-grams 为:{it, is, a, nice, day}
• 参考文本的 1-grams 为:{today, is, a, nice, day}
• 匹配项:{is, a, nice, day}
• 匹配率:

2. 2-gram 精确率:
• 候选文本的 2-grams 为:{it is, is a, a nice, nice day}
• 参考文本的 2-grams 为:{today is, is a, a nice, nice day}
• 匹配项:{is a, a nice, nice day}
• 匹配率:
3. 3-gram 精确率:
• 候选文本的 3-grams 为:{it is a, is a nice, a nice day}
• 参考文本的 3-grams 为:{today is a, is a nice, a nice day}
• 匹配项:{a nice day}
• 匹配率:
4. 4-gram 精确率:
• 候选文本的 4-grams 为:{it is a nice, is a nice day}
• 参考文本的 4-grams 为:{today is a nice day}
• 匹配项:无
• 匹配率:
步骤 2:加权几何平均
• 取每种 n-gram 的匹配率的对数平均值:
ps: 默认是均匀平均,可以手动修改权重的。因此这里平均1/4

步骤 3:计算 BP
• 假设候选文本长度为 5 ,参考文本长度为 6 :

步骤 4:计算最终 BLEU 分数

最终 BLEU 分数(假设几何平均值为 0.55)为:
实战代码
以下是用 Python 实现 BLEU 的完整示例:
# 导入 nltk 库中用于计算 BLEU 分数的两个函数:sentence_bleu 和 corpus_bleu
from nltk.translate.bleu_score import sentence_bleu, corpus_bleu# 示例句子
candidate = ['it', 'is', 'a', 'nice', 'day'] # 候选文本,通常由模型生成的句子分词后得到
reference = [['today', 'is', 'a', 'nice', 'day']] # 参考文本,人工生成的正确句子,外层列表允许包含多个参考句# 计算单句 BLEU
# weights 指定使用的 n-gram 权重,默认是均匀分布 (0.25, 0.25, 0.25, 0.25) 对应 BLEU-1, BLEU-2, BLEU-3, BLEU-4
score = sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25))# 打印结果
# 输出的是单句 BLEU 分数,范围在 0 到 1 之间
print(f"Sentence BLEU Score: {score}")# 示例数据:多句子的 BLEU 计算
# candidates 是一个包含多个候选句的列表,每个句子都已经分词
candidates = [['it', 'is', 'a', 'nice', 'day'], # 第一个候选句['what', 'a', 'great', 'day'] # 第二个候选句
]# references 是一个包含参考句子的列表,每个参考句子可以包含多个参考文本
references = [[['today', 'is', 'a', 'nice', 'day']], # 第一个候选句对应的参考句子列表[['what', 'a', 'wonderful', 'day']] # 第二个候选句对应的参考句子列表
]# 使用 corpus_bleu 计算整个语料库的 BLEU 分数
# 该函数会将多个候选句和对应的参考句作为整体进行评估
corpus_score = corpus_bleu(references, candidates)# 打印结果
# 输出的是语料库级别的 BLEU 分数,范围在 0 到 1 之间
print(f"Corpus BLEU Score: {corpus_score}")
输出:

运行结果解释应用场景
• 单句 BLEU:
• 测试单个句子的生成质量。
• 多句 BLEU:
• 比较模型在整个数据集上的翻译或生成能力。
2.2 ROUGE:文本摘要的评估利器
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 详解
定义:
ROUGE是基于召回率的评估指标,特别适用于 文本摘要、问答生成 和 机器翻译 等任务。其核心思想是通过对生成文本和参考文本的 n-gram 或 子序列 匹配程度进行评估。
常见变体
1. ROUGE-N:基于 n-gram 匹配的召回率。
核心:基于 n-gram 的匹配
• 什么意思?
• 将文本分成连续的 n 个单词的组合(称为 n-gram)。
**适用场景:**机器翻译、摘要生成等。
• 计算生成文本和参考文本之间 匹配的 n-gram 占参考文本所有 n-gram 的比例。

• 示例:
• 生成文本:it is a nice day
• 参考文本:today is a nice day
• 1-gram 匹配:{is, a, nice, day},召回率为 。
• 2-gram 匹配:{is a, a nice, nice day},召回率为 。
2. ROUGE-L:基于最长公共子序列(LCS)的匹配。
核心:基于最长公共子序列(LCS)
• 什么意思?
• 找出生成文本和参考文本之间的 最长连续子序列(Longest Common Subsequence, LCS)。
• 子序列可以跳过部分单词,但保持顺序。
• 特点:
• 能够捕捉生成文本与参考文本在 顺序和语义上的相似性。
• 更适合自然语言任务,因为它允许跳跃。
• **适用场景:**自动摘要、对话生成等。

• 示例:
• 生成文本:it is a nice day
• 参考文本:today is a nice day
• LCS 为 is a nice day,长度为 4。
• 参考文本长度为 5,召回率为 。
3. ROUGE-S:允许跳跃匹配的 n-gram。
核心:基于跳跃 n-gram 匹配(Skip-Bigram)
• 什么意思?
• 考虑生成文本和参考文本中 不连续但有顺序的单词对。
• Skip-Bigram 是指两个单词之间可以跳过其他单词,但顺序必须一致。
• 特点:
• 跳跃匹配可以捕捉生成文本与参考文本在 长距离依赖上的相似性。
• 对单词顺序有一定要求,但允许灵活性。
• **适用场景:**多文档摘要、长文本生成等。

• 示例:
• 生成文本:it is a nice day
• 参考文本:today is a nice day
• Skip-Bigram 匹配:{is nice, a day}。
4. ROUGE-W
核心:加权最长公共子序列
• 什么意思?
• 和 ROUGE-L 类似,但 更强调连续匹配的部分。
• 给连续匹配的子序列更高的权重,以鼓励生成文本和参考文本在内容上更连贯。
• 特点:
• 更加重视生成文本的 连贯性 和 流畅性。
• 连续匹配的权重越高,得分越高。
• **适用场景:**对流畅性要求高的任务,例如文档摘要。



案例解析
候选文本:it is a nice day
参考文本:today is a nice day
计算结果:
• ROUGE-1(1-gram 匹配):召回率 = 。
• ROUGE-2(2-gram 匹配):召回率 = 。
• ROUGE-L(LCS 匹配):is a nice day,召回率 = 。
实战代码
from rouge import Rouge # 导入 ROUGE 库,用于计算文本的 ROUGE 指标。# 候选文本
candidate = "It is a nice day today"
# 候选文本是模型生成的文本(Candidate Text),用于与参考文本进行比较。# 参考文本
reference = "Today is a nice day"
# 参考文本是人工生成的标准答案(Reference Text),通常用作评估基准。# 初始化 ROUGE 计算器
rouge = Rouge()
# 创建一个 Rouge 对象,提供计算多种 ROUGE 指标的方法。# 计算 ROUGE 分数
scores = rouge.get_scores(candidate, reference)
# 调用 get_scores 方法,计算候选文本与参考文本之间的 ROUGE 分数。
# 返回值是一个字典,其中包含 ROUGE-1、ROUGE-2 和 ROUGE-L 的精确率(Precision)、召回率(Recall)和 F1 分数。# 打印结果
print("ROUGE-1:", scores[0]["rouge-1"])
# 打印 ROUGE-1 指标的得分。ROUGE-1 表示基于 1-gram(单词级别)的匹配。print("ROUGE-2:", scores[0]["rouge-2"])
# 打印 ROUGE-2 指标的得分。ROUGE-2 表示基于 2-gram(连续两个单词)的匹配。print("ROUGE-L:", scores[0]["rouge-l"])
# 打印 ROUGE-L 指标的得分。ROUGE-L 表示基于最长公共子序列(LCS)的匹配。输出:
{
"rouge-1": {"p": 0.8, "r": 0.6667, "f": 0.7273},
"rouge-2": {"p": 0.75, "r": 0.6, "f": 0.6667},
"rouge-l": {"p": 0.8333, "r": 0.6667, "f": 0.7407}
}
结果解释:
ROUGE-1:
• 精确率(p)= 0.8:候选文本的单词中有 80% 在参考文本中出现。
• 召回率(r)= 0.6667:参考文本的单词中有 66.67% 被候选文本覆盖。
• F1 分数(f)= 0.7273:精确率和召回率的综合衡量值。
• ROUGE-2:
• 精确率(p)= 0.75:候选文本的二元组中有 75% 在参考文本中匹配。
• 召回率(r)= 0.6:参考文本的二元组中有 60% 被候选文本覆盖。
• F1 分数(f)= 0.6667:综合衡量候选文本与参考文本在短语级别的相似性。
• ROUGE-L:
• 精确率(p)= 0.8333:候选文本与参考文本的最长公共子序列(LCS)长度占候选文本的比例。
• 召回率(r)= 0.6667:LCS 长度占参考文本的比例。
• F1 分数(f)= 0.7407:衡量候选文本与参考文本的顺序和内容相似度。
2.3 PPL(困惑度):语言模型的试金石
定义:
PPL(Perplexity)衡量语言模型预测测试文本的能力,值越低,表示模型预测能力越强。
公式:

其中:
• W :表示测试文本。
• :表示文本中的第 i 个单词。
• :表示模型预测第 i 个单词的概率。
• N :测试文本的总单词数。
直观解释:
1. PPL 衡量模型的不确定性:
• PPL 值越低:表示模型对文本的预测更准确。
• PPL 值越高:表示模型对文本的预测越不确定。
2. PPL 的意义:
• 如果模型的 PPL 为 k ,可以理解为模型在预测每个单词时,平均有 k 个候选单词需要考虑。
2. PPL 的计算步骤
(1) 句子概率
语言模型会为测试句子分配一个生成概率 P(W) ,通过以下公式计算:
• 其中, 是根据语言模型计算的条件概率。
(2) 对数化处理
为了防止概率连乘导致的数值下溢问题(概率值非常小),对概率取对数:
(3) 平均对数概率
计算单词的平均对数概率(归一化到每个单词):
(4) 指数化
将对数均值通过指数化恢复到概率空间:
3. PPL 的意义
(1) 理想情况
• 当 PPL = 1 :模型对测试文本的预测完全准确,没有任何不确定性。
• 例如,一个完美的语言模型能精准地预测所有单词的出现。
(2) 一般情况
• 当 PPL > 1 :模型对测试文本存在一定的不确定性。
• PPL 值越高,模型的预测质量越差。
(3) 实际意义
• PPL 反映了语言模型对测试数据的 “困惑” 程度。
• 低 PPL 表示模型更擅长预测文本中的单词。
案例解析
测试句子:I have a pen
假设概率分布:{'I': 0.1, 'have': 0.1, 'a': 0.4, 'pen': 0.1}
步骤 1:计算句子概率
根据 Unigram 模型的假设,句子的概率是各单词概率的乘积:

将每个单词的概率代入:

步骤 2:对数化处理
为避免数值下溢,对概率取对数,并累加:

计算每个单词的对数概率(保留两位小数):

累加结果:

步骤 3:归一化处理
将对数概率归一化为平均对数概率:

步骤 4:指数化处理
通过对平均对数概率指数化,得到困惑度:

结果
最终困惑度为:
PPL = 7.07
1. 困惑度含义:
• PPL 表示模型在预测句子时的平均不确定性。
• PPL = 7.07 表示模型平均需要考虑约 7 个候选单词。
2. 结果解读:
• 如果困惑度较低,说明模型对句子的预测更准确。
• 本案例中,困惑度值适中,说明模型对该句子的预测尚有提升空间。
实战代码:
import math # 导入数学模块,用于对数计算# 定义测试句子
sentence = ['I', 'have', 'a', 'pen'] # 测试句子:'I have a pen'# 定义 Unigram 模型的单词概率分布
unigram_probs = {'I': 0.1, # 单词 'I' 的概率为 0.1'have': 0.1, # 单词 'have' 的概率为 0.1'a': 0.4, # 单词 'a' 的概率为 0.4'pen': 0.1 # 单词 'pen' 的概率为 0.1
}# 初始化句子概率
sentence_prob = 1 # 初始值设为 1,因为要用乘法累计每个单词的概率# 遍历句子中的每个单词,计算句子概率
for word in sentence:sentence_prob *= unigram_probs[word] # 将句子中每个单词的概率相乘# 对句子概率取以 2 为底的对数,并取负号
log_prob = -math.log2(sentence_prob)# 计算平均对数概率(归一化到单词级别)
avg_log_prob = log_prob / len(sentence)# 通过指数化计算困惑度 PPL
ppl = 2 ** avg_log_prob# 打印结果
print(f"句子概率: {sentence_prob}") # 打印整个句子的生成概率
print(f"平均对数概率: {avg_log_prob}") # 打印平均对数概率
print(f"困惑度 PPL: {ppl:.2f}") # 打印困惑度(保留两位小数)输出:
句子概率: 0.0004000000000000001
平均对数概率: 2.8228756555322954
困惑度 PPL: 7.07
2.4 METEOR 与 BERTScore:现代 NLP 的新方向
METEOR
• 核心特点:
• 支持 同义词匹配(如 run 和 running)。
• 结合精确率与召回率,更注重语义相关性。
from nltk.translate.meteor_score import meteor_score# 候选文本
candidate = "The cat is sleeping on the mat"# 参考文本
reference = "A cat sleeps on the mat"# 计算 METEOR 分数
score = meteor_score([reference], candidate)# 输出结果
print(f"METEOR Score: {score:.4f}")METEOR Score: 0.6444
BERTScore
• 核心特点:
• 使用预训练模型(如 BERT)生成上下文词向量。
• 通过余弦相似度计算生成文本与参考文本的语义相似性。
实战代码
from bert_score import score# 候选文本
candidate = ["The cat is sleeping on the mat"]# 参考文本
reference = ["A cat sleeps on the mat"]# 计算 BERTScore
P, R, F1 = score(candidate, reference, lang="en", verbose=True)# 输出结果
print(f"BERTScore Precision: {P[0]:.4f}")
print(f"BERTScore Recall: {R[0]:.4f}")
print(f"BERTScore F1 Score: {F1[0]:.4f}")输出:
BERTScore Precision: 0.9786
BERTScore Recall: 0.9815
BERTScore F1 Score: 0.9801

• METEOR 适合对 翻译质量 和 文本生成 的基本评估,尤其是需要考虑词形变化和同义词匹配的场景。
• BERTScore 在需要 深度语义匹配 的任务中表现更强,如对长文本或复杂语境进行评价。
3. 指标对比与选择指南

4. 实战案例
• 案例 1:BLEU 对比两种翻译模型性能。
• 案例 2:ROUGE 评估文本摘要质量。
案例 1:使用 BLEU 对比两种翻译模型性能
背景
• 任务: 比较两种机器翻译模型的性能。
• 指标: 使用 BLEU 分数衡量生成的翻译文本与参考翻译的相似性。
• 数据: 假设有一个句子和两种翻译模型的输出结果,以及参考翻译。
代码
from rouge import Rouge# 参考摘要
reference_summary = "The cat is on the mat. It is sleeping."# 机器生成的摘要
generated_summary = "The cat is sleeping on the mat."# 初始化 ROUGE 计算器
rouge = Rouge()# 计算 ROUGE 分数
scores = rouge.get_scores(generated_summary, reference_summary)# 打印结果
print("ROUGE-1:", scores[0]["rouge-1"])
print("ROUGE-2:", scores[0]["rouge-2"])
print("ROUGE-L:", scores[0]["rouge-l"])输出示例
Model 1 BLEU Score: 1.0000
Model 2 BLEU Score: 0.5170
分析
• 模型 1 的 BLEU 分数为 1.0,表示与参考翻译完全一致。
• 模型 2 的 BLEU 分数为 0.5170,说明翻译不完全准确(a 和 mat 的翻译质量较低)。
• BLEU 分数帮助我们量化两种翻译模型的性能。
案例 2:使用 ROUGE 评估文本摘要质量
背景
• 任务: 评估机器生成的摘要与参考摘要的质量。
• 指标: 使用 ROUGE 分数衡量摘要的覆盖率。
• 数据: 假设有一个参考摘要和一个机器生成的摘要。
代码
from rouge import Rouge# 参考摘要
reference_summary = "The cat is on the mat. It is sleeping."# 机器生成的摘要
generated_summary = "The cat is sleeping on the mat."# 初始化 ROUGE 计算器
rouge = Rouge()# 计算 ROUGE 分数
scores = rouge.get_scores(generated_summary, reference_summary)# 打印结果
print("ROUGE-1:", scores[0]["rouge-1"])
print("ROUGE-2:", scores[0]["rouge-2"])
print("ROUGE-L:", scores[0]["rouge-l"])输出示例
ROUGE-1: {'r': 0.8333, 'p': 0.8333, 'f': 0.8333}
ROUGE-2: {'r': 0.7500, 'p': 0.7500, 'f': 0.7500}
ROUGE-L: {'r': 0.8333, 'p': 0.8333, 'f': 0.8333}分析
• ROUGE-1: 单词级别的匹配分数。
• 召回率(r)、精确率(p)、F1 分数(f)均为 0.8333,表示生成摘要覆盖了大部分参考摘要的内容。
• ROUGE-2: 二元组(bigram)的匹配分数为 0.7500,说明生成摘要对短语的结构较好,但略有缺失。
• ROUGE-L: 基于最长公共子序列的分数为 0.8333,表明生成摘要较连贯。
总结
• 案例 1 通过 BLEU 分数对比两种翻译模型的性能,量化翻译质量。
• 案例 2 使用 ROUGE 分数评估机器摘要与参考摘要的覆盖率和连贯性。
• 这两种方法是 NLP 任务中常用的评估方式,可以帮助开发者改进模型性能。
5. 总结与展望
• 经典指标:BLEU 和 ROUGE 是传统任务的首选。
• 现代指标:METEOR 和 BERTScore 更关注语义,适合复杂任务。
• 未来方向:多模态任务评估指标将成为研究重点。
通过本文,希望你能深入理解 NLP 模型评估的五大核心指标,并灵活应用于实际任务中!
shud
相关文章:
【大模型】深度解析 NLP 模型5大评估指标及 应用案例:从 BLEU、ROUGE、PPL 到METEOR、BERTScore
在自然语言处理(NLP)领域,无论是机器翻译、文本生成,还是问答系统开发,模型性能评估指标始终是开发者绕不开的工具。BLEU、ROUGE、PPL(困惑度)、METEOR 和 BERTScore 是五个最具代表性的指标&am…...

LinuxC高级
gdb调试工具 gdb调试的作用 gdb用于调试代码中逻辑错误,而非语法错误 gdb调试流程 生成可以使用gdb调试的执行文件 gcc -g xxx.c ---> 生成的文件可以使用gdb调试 进入gdb工具 gdb 可执行文件 ---> 使用gdb工具开始调试可执行文件 r/run:运行代码 …...

实现PDF文档加密,访问需要密码
01. 背景 今天下午老板神秘兮兮的来问我,能不能做个文档加密功能,就是那种用户下载打开需要密码才能打开的那种效果。boss都发话了,那必须可以。 需求:将pdf文档经过加密处理,客户下载pdf文档,打开文档需要…...

LangChain——加载知识库文本文档 PDF文档
文档加载 这涵盖了如何加载目录中的所有文档。 在底层,默认情况下使用 UnstructedLoader。需要安装依赖 pip install unstructuredpython导入方式 from langchain_community.document_loaders import DirectoryLoader我们可以使用 glob 参数来控制加载特定类型文…...

深度学习2:从零开始掌握PyTorch:数据操作不再是难题
文章目录 一、导读二、张量的定义与基本操作三、广播机制四、索引与切片五、内存管理六、与其他Python对象的转换本文是经过严格查阅相关权威文献和资料,形成的专业的可靠的内容。全文数据都有据可依,可回溯。特别申明:数据和资料已获得授权。本文内容,不涉及任何偏颇观点,…...

MyBatis的if标签的基本使用
在MyBatis框架中,if标签用于在构建SQL语句时,根据参数条件判断的结果,动态地选择加入或不加where条件中。 一 常见使用 在使用MyBatis处理查询逻辑的时候,常用的是判断一些参数是否为空,列举常用的几种情况展示 1.1…...

【Azure Cache for Redis】Redis的导出页面无法配置Storage SAS时通过az cli来完成
问题描述 在Azure Redis的导出页面,突然不能配置Storage Account的SAS作为授权方式。 image.png 那么是否可以通过AZ CLI或者是Powershell来实现SAS的配置呢? 问题解答 可以的。使用 az redis export 可以实现 az redis export --container --prefix[--a…...

【微服务】Nacos
一、安装 1、官网地址:https://nacos.io/download/nacos-server/ 2、启动:找到bin目录下的startup.cmd双击启动,或者打开一个命令窗口输入: startup.cmd -m standalone双击启动后如下:可以访问控制台地址 访问后的…...

5、定义与调用函数
大家好,欢迎来到Python函数入门课程! 在编程中,函数就像一个可以重复使用的代码块,它接受输入(参数),执行特定的任务,并可能返回一个结果。想象一下,函数就像一个厨房里的搅拌机,你放入水果(参数),按下按钮(调用函数),它就会帮你制作出美味的果汁(返回值)。…...

Linux 网络编程之TCP套接字
前言 上一期我们对UDP套接字进行了介绍并实现了简单的UDP网络程序,本期我们来介绍TCP套接字,以及实现简单的TCP网络程序! 🎉目录 前言 1、TCP 套接字API详解 1.1 socket 1.2 bind 1.3 listen 1.4 accept 1.5 connect 2、…...

前海湾地铁的腾通数码大厦背后的临时免费停车点探寻
临时免费停车点:前海湾地铁的腾通数码大厦背后的桂湾大街,目前看不仅整条桂湾大街停了车,而且还有工地餐点。可能是这个区域还是半工地状态,故暂时还不会有罚单的情况出现。 中建三局腾讯数码大厦项目部A栋 广东省深圳市南山…...
鱼眼镜头立体校正的函数stereoRectify()的使用)
OpenCV相机标定与3D重建(7)鱼眼镜头立体校正的函数stereoRectify()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::fisheye::stereoRectify 是 OpenCV 中用于鱼眼镜头立体校正的函数。该函数计算两个相机之间的校正变换,使得从两个相机拍摄的图像…...

前端如何获取unpkg的资源链接
在现代前端开发中,快速获取和使用npm包是一个常见需求。unpkg是一个全球性的CDN服务,它为npm上的每个包提供了快速访问。通过unpkg,你可以轻松地通过URL获取任何npm包的文件。本文将介绍如何获取unpkg的资源链接。 unpkg简介 unpkg是一个快…...

Flink 离线计算
文章目录 一、样例一:读 csv 文件生成 csv 文件二、样例二:读 starrocks 写 starrocks三、样例三:DataSet、Table Sql 处理后写入 StarRocks四、遇到的坑 <dependency><groupId>org.apache.flink</groupId><artifactId&…...

Git | 理解团队合作中Git分支的合并操作
合并操作 团队合作中Git分支的合并操作分支合并过程1.创建feature/A分支的过程2. 创建分支feature/A-COPY3.合并分支查看代码是否改变 团队合作中Git分支的合并操作 需求 假设团队项目中的主分支是main,团队成员A基于主分支main创建了feature/A,而我又在团队成员A创…...

C++多态的实现原理
【欢迎关注编码小哥,学习更多实用的编程方法和技巧】 1、类的继承 子类对象在创建时会首先调用父类的构造函数 父类构造函数执行结束后,执行子类的构造函数 当父类的构造函数有参数时,需要在子类的初始化列表中显式调用 Child(int i) : …...

[极客大挑战 2019]PHP--详细解析
信息搜集 想查看页面源代码,但是右键没有这个选项。 我们可以ctrlu或者在url前面加view-source:查看: 没什么有用信息。根据页面的hint,我们考虑扫一下目录看看能不能扫出一些文件. 扫到了备份文件www.zip,解压一下查看网站源代码…...

map用于leetcode
//第一种map方法 function groupAnagrams(strs) {let map new Map()for (let str of strs) {let key str ? : str.split().sort().join()if (!map.has(key)) {map.set(key, [])}map.get(key).push(str)} //此时map为Map(3) {aet > [ eat, tea, ate ],ant > [ tan,…...

CommonJS 和 ES Modules 的 区别
CommonJS 和 ES Modules 的 区别 1. CommonJS 和 ES Modules 区别?1.1 语法差异CommonJS:ES Modules: 1.2. 加载机制CommonJS:ES Modules: 1.3. 运行时行为CommonJS:ES Modules: 1.4. 兼容性和使用场景Com…...

科技为翼 助残向新 高德地图无障碍导航规划突破1.5亿次
今年12月03日是第33个国际残疾人日。在当下科技发展日新月异的时代,如何让残障人士共享科技红利、平等地参与社会生活,成为当前社会关注的热点。 中国有超过8500万残障人士,其中超过2400万为肢残人群,视力障碍残疾人数超过1700万…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...
篇章二 论坛系统——系统设计
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...
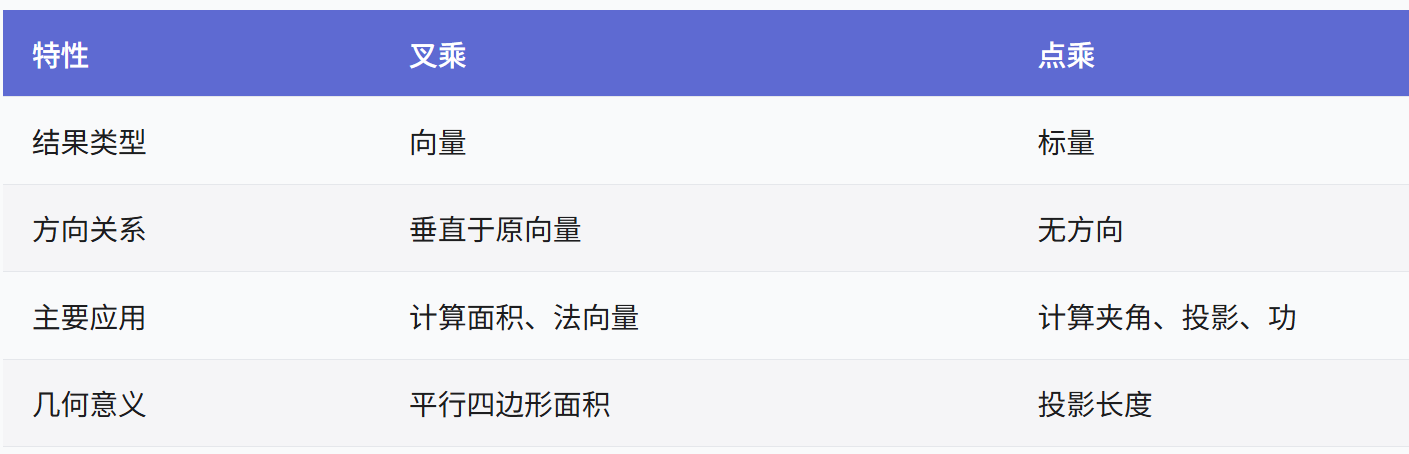
向量几何的二元性:叉乘模长与内积投影的深层联系
在数学与物理的空间世界中,向量运算构成了理解几何结构的基石。叉乘(外积)与点积(内积)作为向量代数的两大支柱,表面上呈现出截然不同的几何意义与代数形式,却在深层次上揭示了向量间相互作用的…...

js 设置3秒后执行
如何在JavaScript中延迟3秒执行操作 在JavaScript中,要设置一个操作在指定延迟后(例如3秒)执行,可以使用 setTimeout 函数。setTimeout 是JavaScript的核心计时器方法,它接受两个参数: 要执行的函数&…...

13.10 LangGraph多轮对话系统实战:Ollama私有部署+情感识别优化全解析
LangGraph多轮对话系统实战:Ollama私有部署+情感识别优化全解析 LanguageMentor 对话式训练系统架构与实现 关键词:多轮对话系统设计、场景化提示工程、情感识别优化、LangGraph 状态管理、Ollama 私有化部署 1. 对话训练系统技术架构 采用四层架构实现高扩展性的对话训练…...