SciAssess——评估大语言模型在科学文献处理中关于模型的记忆、理解和分析能力的基准
概述
大规模语言模型(如 Llama、Gemini 和 GPT-4)的最新进展因其卓越的自然语言理解和生成能力而备受关注。对这些模型进行评估对于确定其局限性和潜力以及促进进一步的技术进步非常重要。为此,人们提出了一些特定的基准来评估大规模语言模型的各种技能。这样可以完成更复杂的任务。
与此同时,大规模语言模型在科学研究中发挥着越来越重要的作用。特别是在科学文献分析方面,大规模语言模型已在文献总结和知识提取等应用中得到实际应用,提高了研究人员的工作效率。然而,现有的基准无法解决对科学文献复杂而全面的理解以及处理多模态数据的场景。这些基准无法充分复制科学文献带来的特定领域术语、复杂关系推理和多模态信息整合等挑战。要填补这一空白,需要开发能准确反映科学文献分析的复杂性和特殊性的高级基准。
以下三个关键要素被认为是评估大规模语言模型在科学文献分析中的能力所必不可少的
- 能力模型:制定基准有助于明确所需的能力,并了解如何通过建立其内在关系 模型来获得和提高这些能力。
- 范围和任务:基准应涵盖广泛的科学领域,所选任务应代表各领域的典型挑战和情景。
- 质量控制:基准数据集的质量必须保持在较高水平,并作为得出准确和可行见解的可靠依据。每个数据点都必须经过领域专家的严格验证,以确保其准确性和可靠性。
在此背景下,本文提出了一个专为科学文献分析设计的新基准–SciAssess,该基准涵盖各种任务和问题类型,旨在对大规模语言模型的能力进行更详细、更严格的评估�
SciAssess 可从记忆、理解、分析和推理三个渐进的层面评估模型的能力。这样就能提供精细而翔实的评估结果,具体指出模型的不足之处。它还涵盖了与不同科学学科相关的广泛任务,包括普通化学、有机电解质、合金材料、药物发现和生物学。为确保基准的代表性,原始数据都是从公开的科学出版物和专业数据库中精心收集的,以确保 SciAssess 全面反映科学研究的现状。此外,它们还经过严格的同行评审交叉验证,以确保准确性和可靠性。此外,为保护隐私和安全,还进行了仔细筛选,并删除或匿名化了敏感信息。这保证了 SciAssess 在法律和道德方面的完整性。
SciAssess 旨在揭示大规模语言模型在科学文献分析领域的性能,并找出其优缺点。希望这将提高大规模语言模型更有效地处理科学文献的能力,并支持各科学学科的研究进展;从 SciAssess 中获得的见解将进一步提高大规模语言模型分析科学文献的能力,并最终促进科学发现和创新的加速。希望 SciAssess 的见解将有助于加速科学发现和创新。
基准数据集
在制定科学领域大型语言模型的评估标准时,本文精心设计了三个要素:模型能力、范围和任务以及质量控制。借鉴广受认可的布鲁姆分类法,我们开发了一个专门用于科学文献分析的基准,名为 “SciAssess”。该评估涵盖三个关键能力
- 记忆(L1):指模型的广泛知识基础和准确回答有关科学常识问题的能力
- 理解(L2):准确识别和理解特定文本中关键信息和事实的能力
- 分析和推理(L3):将提取的信息与现有知识库整合起来,并利用逻辑推理和分析 得出可靠结论和预测的高级能力
如下表所示,该基准涵盖了一系列科学学科。此外,还设计了五种不同的问题形式来评估该模型,即:真/假问题、选择问题、表格提取、约束生成和自由回答生成。真/假问题、选择问题、表格提取、约束生成和自由回答生成。这些问题格式的详情和具体示例如下。

普通化学
普通化学评估集是一套综合任务,旨在评估大语言模型中与化学相关的技能,包括基础知识、应用问题解决和研究分析。这套任务包括五个不同的任务,每个任务都针对化学和学术理解的不同方面。通过这些任务,可以全面了解大型语言模型在化学学术研究及其原理的实际应用方面的能力。所有测试数据均来自 OpenAI evals 数据库。
MMLU(大规模多任务语言理解)是一个衡量模型知识的新基准,它通过评估在零拍和四拍(fourshot)设置下先前学习过程中获得的知识来衡量模型知识。这使得该基准更具挑战性,并与人类的评估方式类似:在 57 个科目中,选择高中化学和大学化学来评估知识回忆。有关提示和回答示例,请参阅下文。

Abstract2Title 测试模型使用文献摘要部分生成适当标题的能力。大型语言模型需要理解摘要部分并对其进行简明扼要的解析。生成标题的简洁程度由 GPT-4 评估,具体如下。

问题提取旨在评估大规模语言模型从科学文章摘要中识别、提取和总结关键研究问题的能力。这项任务要求大规模语言模型深入理解摘要的内容,并简明扼要地概括背景、目标、方法、结果和结论等信息。它测试您对复杂和专业语言的理解能力,从广泛而详细的信息中找出重点的能力,以及总结和重构学术内容的能力。
这不仅需要对文本进行表面处理,还需要进行深入分析,以确定研究要解决的问题、假设或议题。这项任务对于评估大规模语言模型在学术和研究环境中的实用性尤为重要。有效地理解和提取学术文章的要点有助于进行文献综述、制定研究计划以及确定研究趋势和差距。这简化了处理浩瀚且不断增长的科学文献的过程,并凸显了大规模语言模型在帮助研究人员、学者和学生方面的潜力。回答由 GPT-4 按 1 到 5 的等级进行评分,这与 Abstract2Title 任务类似。
平衡方程式旨在评估大语言模型理解和应用化学化学计量学以及质量和能量守恒定律的能力。平衡化学反应方程式包括调整反应物和生成物的系数,使反应方程式两边每种元素的原子数相等。这反映了物质守恒定律。
这项任务不仅测试大规模语言模型解释和理解化学符号语言的能力,还评估他们解决问题和基于专业知识的能力。要平衡化学反应方程式,大型语言模型需要识别反应物和生成物,理解它们之间的化学计量关系,并运用数学推理找出系数来平衡反应方程式。

合金材料
合金材料是两种或两种以上金属元素按一定比例混合而成的具有金属特性的混合物。合金广泛应用于航空航天、汽车制造、建筑和电气产品等多个领域。通过调整成分和制造工艺,可以达到特定的性能和要求。因此,从文献中提取合金成分和工艺值对合金设计非常重要。
本文还研究了大规模语言模型提取合金设计所需信息的能力。它设计了一套与文献研究相关的综合任务。这些任务包括合金成分提取、工艺值提取、工艺序列确定和样品识别。这里涉及的所有任务的标准解决方案都是从不同期刊的文献中手动提取的,并经过不同人员的验证。
从文章文本和表格中提取合金成分信息并将其结构化,可以让研究人员更有效地利用历史数据,并为后续设计提供有用的指导。本任务评估大规模语言模型从文本和表格中提取合金成分(所有元素含量)的能力。合金元素的提取位置通常分为两种情况:第一,元素含量列于表格中(见下表);第二,元素含量由合金名称表示。例如,"Fe30Co20Ni50"表示原子比为 30%的铁、20% 的钴和 50%的镍。本任务的目的是全面提取这些信息,并将结果整理成表,以计算标准答案表和提取结果表之间的一致分数。这证明了大规模语言模型在整合、提取和组织多模态信息方面的理解能力。


合金的特性还取决于其成分和加工过程(如处理和热处理)。热处理温度的提取尤为重要。本任务的目的是确定合金热处理的最高温度值。为确保准确的统计分析,提示语设计为多选题的形式。下面是一个示例。


合金处理要求每个过程都有明确的顺序。因此,确保提取热处理过程的顺序与实验顺序一致非常重要。例如,样品在固溶处理后可能会进一步进行时效处理,以释放内应力。在这项任务中,将对两种热处理之间的顺序关系进行客观分析和评估,以确定其正确与否。如果论文中没有具体的热处理名称,则视为 “错误”。本任务评估您理解从文本中确定处理顺序的大型语言模型的能力。该模型的提示包括

有机物
有机材料由碳基分子和聚合物制成,功能多样,应用广泛。与无机材料不同,有机材料在电子学、光子学、传感器和能源等领域发挥着重要作用,因为它们的特性很容易改变,而且适应性很强。利用有机化学的巨大潜力,促进技术进步。
这里的重点是有机功能材料的两个子领域:有机电解质和聚合物材料。在聚合物材料方面,我们评估了大规模语言模型从科学文献中提取与聚合物材料相关的关键属性的有效性。特别是,我们以共轭聚合物在有机太阳能电池中的应用为案例,设计了两个任务,一个是文字任务,一个是表格任务。这样,我们就能评估该模型从一系列任务中识别和鉴定这些材料信息的能力。
有机电解质是一种广泛使用的电解质,尤其是在锂离子电池中。它们含有有机溶剂、锂盐以及必要的添加剂,可促进电池内的离子转移,从而储存和释放能量。了解有机电解质的溶解度至关重要,因为它会直接影响电解过程的效率、产品选择性和设备设计。本任务研究 LLM 获取溶解度相关表格的能力。有关电解质的论文通常会选择不同方面的数据来描述系统。这就很难将多个表格整合为一个合适的格式。因此,重点在于评估模型理解含义的能力,从大量选项中选择最合适和最大的 "溶解度 "相关表格,并将其转换为指定格式。对模型的提示如下。

有机电解质的组成和性质对电池的性能、稳定性和安全性至关重要。因此,为了进一步评估模型获取电解质相关信息的能力,我们提出了有关溶液系统组成和溶解反应的物理和化学特性的多项选择题。这些问题都是根据论文表格中的信息提出的。对模型的提示如下。

功率转换效率 (PCE)、开路电压 (VOC) 和其他电子特性等重要数值都是从文献中提取的。这些特性通常以表格形式列出。使用大规模语言模型来提取这些特性,显示了人工智能界在聚合物建模方面的巨大潜力。这方面的例子包括计算机辅助筛选、目标设计和优化。源数据收集自《自然-通讯》、《先进材料》、《自然-光子学》、《自然-通讯》、《J. Phys. Chem》、《Appl. Phys. Lett.模型提示如下

药物研发
论文还研究了大规模语言模型在药物发现领域的能力。它设计了与专利和文献研究相关的综合任务,重点关注亲缘数据提取和专利覆盖范围。
亲和力数据提取任务评估大规模语言模型提取亲和力表(包括分子标签、SMILES 中不同目标的亲和力)的能力。这项评估任务测试的是大规模语言模型理解复杂的特定领域语言、分子和表格的能力。提取亲和性数据不仅需要对文本进行表面处理,还需要进行深入分析,以匹配不同的模式。作为一个具体的例子,输出结果如下表所示。

数据集是从 PubChem 生物测定中精心挑选出来的,涵盖了不同期刊和年代的文献。由于原始数据集是按生物测定编号组织的,因此根据 DOI 合并了源数据,并对其中一些数据进行了仔细抽样。这些论文涵盖了广泛的蛋白质靶标和细胞系,并以不同格式同时列出了表格。

分子确定任务评估的是模型确定文档中是否包含分子(以 SMILES 表示)的能力。大型语言模型需要识别所有标记结构式及其取代基,以确定是否涵盖了所需的分子。

生物学
MedMCQA 任务旨在评估理解和推理医疗保健相关多项选择题的能力。该任务由临床相关问题和知识评估组成,旨在衡量人工智能系统的能力。例如,将以下提示输入模型。

为了保障数据集的质量和道德标准,我们采取了严格的程序,以便
- 专家验证:为确保 SciAssess 的准确性和可靠性,所有任务均由专家进行多次交叉验证。这可确保数据集上的标签准确无误,并保持高质量标准。
- 筛选和匿名化:SciAssess 对敏感信息进行彻底筛选,并删除或匿名化所有已识别的潜在敏感数据。这确保了隐私保护和数据安全。
- 版权合规:对所有文件和数据都有严格的版权审查程序,以确保 SciAssess 不侵犯知识产权,并遵守法律标准和道德规范。
这些程序可确保数据质量、隐私保护和法律合规性。
试验
OpenAI 的 GPT-4 在文本生成和理解方面表现出色,并增强了图像处理、代码解释和信息检索能力。这使它成为一个能应对复杂科学文本的多功能工具。最新版本的 GPT-4 使用排序链(CoT)提取最终结果,因为答案可以使用代码解释器编写;CoT 提示如下。


第二个是GPT-3.5–OpenAI的GPT-3.5先于GPT-4,因其先进的语言处理能力而脱颖而出,能有效处理复杂文本;第三个是Gemini–谷歌DeepMind的Gemini模型系列是文本、多模态理解,集成了对代码、图像和音频的分析。它在 MMLU 测试中的表现尤其令人印象深刻,Gemini-1.0-Ultra 的表现超过了人类基准。不过,由于我们目前还没有收到 API,我们正在评估 Gemini-1.0-Pro。该模型在理解和综合科学文献方面表现出色,是学术研究中的先进工具,可在分析科学文献时提供见解并提高工作效率。
SciAssess 基于 openai/evals 提供的框架的改进版本(https://github.com/openai/evals)。本文还纳入了其他功能,如模型调用(如 Gemini)、自定义任务和度量、数据集和 PDF 处理模块,详细代码即将发布。
SciAssess 的主要部分侧重于学术文献,并使用不同的方法处理文献 PDF。
- GPT-4:使用基于网络的 ChatGPT4 界面,将原始 PDF 文件直接上传到聊天界面,然后利用 OpenAI 内置的 PDF 处理功能进行提问。
- GPT-3.5:使用 PyPDF2 将 PDF 转换为文本,然后将纯文本输入模型。
- Gemini:它能同时处理文本和图像,这意味着它首先使用 PyPDF2 从 PDF 中提取文本,然后使用 PyMuPDF 检索文档中的图像,按阅读顺序排列,并将文本和图像同时输入模型。
这里的重点是记忆、理解和分析能力,并在各个科学领域分析了大规模语言模型在有多模态内容和无多模态内容的任务中的表现。
下表总结了大规模语言模型在不同科学学科中的总体表现,通过比较可以看出每个模型的明显优缺点。

GPT-4 在几乎所有领域的表现都优于其他模型,并获得了最高的总平均排名。这表明 GPT-4 在理解复杂的科学文献方面具有出色的适应性;GPT-3.5 落后于 GPT-4,但在广泛的任务中表现出能力,表明其稳健性;Gemini 在总体排名中位居第三,但在特定任务中表现出优势;GPT-3.5 在总体排名中位居第三,但在特定任务中表现出优势。
在许多科学学科中,GPT-4 几乎在所有领域都表现出色,在生物学领域的排名与双子座相当。这凸显了 GPT-4 理解科学文献的卓越能力和高度适应性;双子座在总体上排名第三,但在生物学领域的表现与 GPT-4 不相上下,这表明它在某些领域具有潜在的优势。
在药物发现领域,所有模型在 "Tag2Molecule "任务中的得分都接近零分,这表明所有模型在处理高度专业化的化学内容和复杂的分子结构转换方面能力有限。这些发现凸显了每个模型在特定科学学科中的优势和局限性,并为今后改进模型提供了宝贵的启示。
记忆力(L1)表示模型回忆以前所学信息的能力。在这方面,GPT-4 的平均排名最高,证明了其优越性。例如,在 "MMLU 高中化学 "任务中,GPT-4 准确地回忆了基本的化学知识,以 0.591 的准确率领先于其他模型。GPT-4 的这一优势可能归功于其广泛的训练数据集,能够覆盖更多的科学知识领域。
理解力(L2)衡量模型理解复杂文本和提取重要信息的能力 GPT-4 在理解力方面也处于领先地位,在多项任务中表现突出。例如,在 "Abstract2Title "任务中,GPT-4 以 0.99 的模型评级得分名列前茅。这表明,GPT-4 能够深入理解文本内容,并准确生成相关标题。
分析和推理(L3)指的是模型处理复杂问题、推理和生成解决方案的能力;GPT-4 在这一能力上略胜一筹,平均排名为 1.75。这表明学生具有较高的应用知识、分析情况和得出结论的能力。例如,在 "样本区分 "任务中,GPT-4 的准确率达到 0.528,远高于 GPT-3.5 (0.177)和 Gemini(0.059)。
总结
科学评估(SciAssess)旨在严格评估大规模语言模型在分析科学文献方面的能力。该基准评估了普通化学、合金材料、有机材料、药物发现、生物学等特定科学领域的大规模语言模型的记忆、理解和分析能力。确定了每个模型的优势和需要改进的地方。这项研究为科学研究领域开发大规模语言模型提供了有力支持。
作者表示,今后他们将进一步扩大基准测试所涵盖的科学领域,并纳入更复杂的多模态数据集,从而显著提高基准的实用性和有效性。希望这将有助于大规模语言模型的使用,并为进一步的科学研究和创新提供明确的指导。
注:
源码地址:https://github.com/sci-assess/sciassess
论文地址:https://arxiv.org/abs/2403.01976
相关文章:
SciAssess——评估大语言模型在科学文献处理中关于模型的记忆、理解和分析能力的基准
概述 大规模语言模型(如 Llama、Gemini 和 GPT-4)的最新进展因其卓越的自然语言理解和生成能力而备受关注。对这些模型进行评估对于确定其局限性和潜力以及促进进一步的技术进步非常重要。为此,人们提出了一些特定的基准来评估大规模语言模型…...

SQLModel与FastAPI结合:构建用户增删改查接口
SQLModel简介 SQLModel是一个现代化的Python库,旨在简化与数据库的交互。它结合了Pydantic和SQLAlchemy的优势,使得定义数据模型、进行数据验证和与数据库交互变得更加直观和高效。SQLModel由FastAPI的创始人Sebastin Ramrez开发,专为与FastA…...

【RISC-V CPU debug 专栏 2.3 -- Run Control】
文章目录 Run ControlHart 运行控制状态位状态信号操作流程时间与实现注意事项Run Control 在 RISC-V 调试架构中,运行控制模块通过管理多个状态位来对硬件线程(harts)的执行进行调节和控制。这些状态位帮助调试器请求暂停或恢复 harts,并在 hart 复位时进行控制。以下是运…...

探索 IntelliJ IDEA 中 Spring Boot 运行配置
前言 IntelliJ IDEA 作为一款功能强大的集成开发环境(IDE),为 Spring Boot 应用提供了丰富的运行配置选项,定义了如何在 IntelliJ IDEA 中运行 Spring Boot 应用程序,当从主类文件运行应用程序时,IDE 将创建…...

三除数枚举
给你一个整数 n 。如果 n 恰好有三个正除数 ,返回 true ;否则,返回 false 。 如果存在整数 k ,满足 n k * m ,那么整数 m 就是 n 的一个 除数 。 输入:n 4 输出:true 解释:4 有三…...

【051】基于51单片机温度计【Proteus仿真+Keil程序+报告+原理图】
☆、设计硬件组成:51单片机最小系统DS18B20温度传感器LCD1602液晶显示按键设置蜂鸣器LED灯。 1、本设计采用STC89C51/52、AT89C51/52、AT89S51/52作为主控芯片; 2、采用DS18B20温度传感器测量温度,并且通过LCD1602实时显示温度;…...

[Java]微服务之服务保护
雪崩问题 微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩 雪崩问题产生的原因是什么? 微服务相互调用,服务提供者出现故障或阻塞。服务调用者没有做好异常处理,导致自身故障。调用链中的所有服…...

自动驾驶目标检测融合全貌
1、early fusion 早期融合,特点用到几何空间转换3d到2d或者2d到3d的转换,用像素找点云或者用点云找像素。 2、deep fusion 深度融合,也是特征级别融合,也叫多模态融合,如bevfusion范式 3、late fusion 晚融合&#x…...
的测试方法和测试用例)
消息框(Message Box)的测试方法和测试用例
我来帮你了解消息框(Message Box)的测试方法和测试用例的编写。 我已经创建了一个测试用例示例,让我为你解释消息框测试的主要方面: 测试维度: 功能性测试:验证消息框的基本功能是否正常样式测试:确认不同类型消息框…...

Ubuntu 包管理
APT&dpkg 查看已安装包 查看所有已经安装的包 dpkg -l 查找包 apt search <package_name>搜索软件包列表,找到与搜索关键字匹配的包 dpkg与grep结合查找特定的包 dpkg -s <package>:查看某个安装包的详细信息 安装包 apt安装命令 更新…...
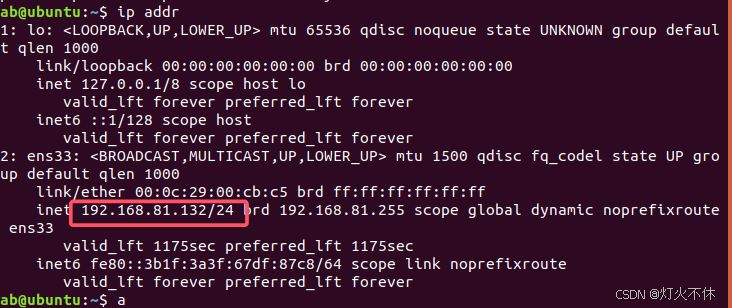
[Ubuntu] linux之Ubuntu18.04的下载及在虚拟机中详细安装过程(附有下载链接)
前言 ubuntu 链接:https://pan.quark.cn/s/283509d0d36e 提取码:dfT1 链接失效(可能被官方和谐)可评论或私信我重发 下载压缩包后解压 !!安装路径不要有中文 下载后解压得到.iso文件,不要放在…...

ffmpeg安装(windows)
ffmpeg安装-windows 前言ffmpeg安装路径安装说明 前言 ffmpeg的安装也是开箱即用的,并没有小码哥说的那么难 ffmpeg安装路径 这就下载好了! 安装说明 将上面的bin目录加入到环境变量,然后在cmd中测试一下: C:\Users\12114\Desktop\test\TaskmgrPlayer\x64\Debug>ffmpe…...

服务器数据恢复—raid6阵列硬盘被误重组为raid5阵列的数据恢复案例
服务器存储数据恢复环境: 存储中有一组由12块硬盘组建的RAID6阵列,上层linux操作系统EXT3文件系统,该存储划分3个LUN。 服务器存储故障&分析: 存储中RAID6阵列不可用。为了抢救数据,运维人员使用原始RAID中的部分…...

linux内核编译启动总结
linux kernel 编译 升级汇总 写在前面内核编译获取kernel代码开始前的准备工作 编译过程1\.解压与净化将下载好的linux内核解压至/usr/src 2\. 得到源代码后,将其净化3\. 配置要进行编译的内核4.编译内核. (15分钟)5.编译模块.方法1:方法2: 6…...

Android Studio的AI工具插件使用介绍
Android Studio的AI工具插件使用介绍 一、前言 Android Studio 的 AI 工具插件具有诸多重要作用,以下是一些常见的方面: 代码生成与自动补全 代码优化与重构 代码解读 学习与知识获取 智能搜索与资源推荐实际使用中可以添加注释,解读某段代…...

本地部署 WireGuard 无需公网 IP 实现异地组网
WireGuard 是一个高性能、极简且易于配置的开源虚拟组网协议。使用路由侠内网穿透使其相互通讯。 第一步,服务端(假设为公司电脑)和客户端(假设为公司外的电脑)安装部署 WireGuard 1,点此下载(…...

asyncio.ensure_future 与 asyncio.create_task:Python异步编程中的选择
asyncio.ensure_future 与 asyncio.create_task:Python异步编程中的选择 引言asyncio.ensure_futureasyncio.create_task两者的区别参数接受范围任务调度的保证代码可读性 哪个更好?使用asyncio.create_task使用asyncio.ensure_future 结论参考 引言 在…...
CTF之密码学(密码特征分析)
一.MD5,sha1,HMAC,NTLM 1.MD5:MD5一般由32/16位的数字(0-9)和字母(a-f)组成的字符串 2.sha1:这种加密的密文特征跟MD5差不多,只不过位数是40(sha256:64位;sha512:128位) 3.HMAC:这…...

JVM调优篇之JVM基础入门AND字节码文件解读
目录 Java程序编译class文件内容常量池附录-访问标识表附录-常量池类型列表 Java程序编译 Java文件通过编译成class文件后,通过JVM虚拟机解释字节码文件转为操作系统执行的二进制码运行。 规范 Java虚拟机有自己的一套规范,遵循这套规范,任…...
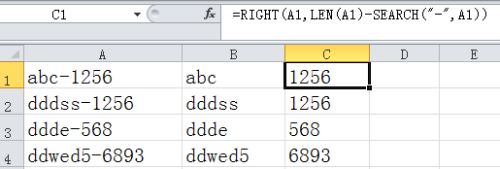
EXCEL截取某一列从第一个字符开始到特定字符结束的字符串到新的一列
使用EXCEL中的公式进行特定截取 假设列A是一组产品的编码,我们需要的数据是“-”之前的字段。 我们需要在B1单元格输入公式“LEFT(A1,SEARCH("-",A1)-1)”然后选中B1至B4单元格,按“CTRLD”向下填充,就可以得出其它几行“-”之前的…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...