说说Elasticsearch拼写纠错是如何实现的?
大家好,我是锋哥。今天分享关于【说说Elasticsearch拼写纠错是如何实现的?】面试题。希望对大家有帮助;

说说Elasticsearch拼写纠错是如何实现的?
1000道 互联网大厂Java工程师 精选面试题-Java资源分享网
在 Elasticsearch 中,拼写纠错(也叫做 自动纠错 或 拼写建议)可以通过几种不同的技术来实现。主要的两种实现方法是 fuzzy 查询 和 suggest 功能。下面是几种常用的实现方法及其原理。
1. Fuzzy 查询
fuzzy 查询是一种通过匹配“模糊”文本的查询方法,用于容忍拼写错误和输入的不精确。它基于 编辑距离(Levenshtein Distance)算法,编辑距离衡量将一个单词转换为另一个单词所需的最小操作次数(插入、删除或替换字符)。
通过 fuzzy 查询,Elasticsearch 可以容忍一定数量的拼写错误,甚至对于不完全匹配的词也能找到最接近的匹配项。
示例:
{"query": {"match": {"title": {"query": "elasticsearchh", // 错误拼写"fuzziness": "AUTO" // 自动计算模糊度}}}
}
-
fuzziness: 定义了允许的最大编辑距离(模糊度)。可以是一个整数值(例如1或2),或者使用"AUTO",让 Elasticsearch 自动计算。 -
prefix_length: 指定前缀的最小长度,前缀部分不能模糊匹配。
Elasticsearch 会根据模糊匹配算法,寻找与 "elasticsearchh" 最接近的文档。如果模糊度设置为 "AUTO",系统会根据查询的长度自动选择最合适的编辑距离。
2. Completion Suggester(完成建议器)
completion suggester 是 Elasticsearch 中专门用于提供自动完成建议和拼写纠错的功能。它通常用于前端实现输入提示、自动补全或纠错。
完成建议器会基于一个索引进行实时查询,提供高效的搜索建议,常用于输入框中的建议列表,能根据用户输入的部分内容提供候选词。
- 创建一个
completion类型字段:
PUT /my_index/_mapping
{"properties": {"suggest": {"type": "completion"}}
}
- 插入数据:
POST /my_index/_doc/1
{"suggest": {"input": ["elasticsearch", "search engine", "search"]}
}
- 查询建议:
POST /my_index/_search
{"suggest": {"text": "elast","completion": {"field": "suggest","size": 3}}
}
在上面的例子中,用户输入 "elast" 时,Elasticsearch 会返回与 "elasticsearch" 最接近的词作为建议。
3. Term Vectors + Custom Script
另一种拼写纠错的方式是使用 Term Vectors,它存储了每个文档中各个词项的统计信息(如词频、位置等)。你可以通过这些信息结合 自定义脚本,手动实现拼写纠错机制。
这种方式通常需要额外的计算来分析词频和拼写误差,但它提供了很大的灵活性,可以根据实际需求调整拼写纠错的规则和逻辑。
4. Edgengram 或 Ngram Tokenizer
为了实现拼写纠错和自动完成功能,可以使用 Edge Ngram 或 Ngram 分词器,它们在分词时会从单词的不同位置生成子串,这些子串在用户输入部分匹配时会提供更好的候选词。
- Edge Ngram 会从词的前缀开始生成子串。常用于前缀自动补全(例如输入框自动补全)。
- Ngram 会从词的各个位置生成子串,适用于全词匹配,但可能会产生更多的倒排索引。
示例:
PUT /my_index
{"settings": {"analysis": {"tokenizer": {"edge_ngram_tokenizer": {"type": "edge_ngram","min_gram": 1,"max_gram": 25}},"filter": {"lowercase": {"type": "lowercase"}},"analyzer": {"edge_ngram_analyzer": {"type": "custom","tokenizer": "edge_ngram_tokenizer","filter": ["lowercase"]}}}},"mappings": {"properties": {"suggest": {"type": "text","analyzer": "edge_ngram_analyzer"}}}
}
上述配置会基于用户输入的前缀(例如“elas”)生成“e”,“el”,“ela”,“elas”等多个子串,进而实现高效的拼写纠错和自动完成功能。
5. Spellcheck(拼写检查)
虽然 Elasticsearch 本身并没有内建的专门拼写检查功能(像某些传统拼写检查工具一样),但你可以使用上述 fuzzy 查询、completion suggester 或结合外部拼写检查库(例如 Hunspell)来补充拼写纠错的功能。你可以通过编写定制化的插件来整合外部拼写检查引擎。
总结
Elasticsearch 的拼写纠错通常通过以下方式实现:
- Fuzzy 查询:通过模糊匹配容忍拼写错误,基于编辑距离来进行查询。
- Completion Suggester:为自动完成和拼写建议提供快速的候选项查询,适用于搜索建议和实时补全。
- Edge Ngram 或 Ngram 分词器:生成词的前缀或子串,支持拼写纠错和自动完成。
- Term Vectors 和自定义脚本:结合文档的词频和位置统计信息,手动实现拼写纠错。
这些技术可以单独使用,也可以组合使用,以实现高效、准确的拼写纠错和搜索建议功能。
相关文章:
说说Elasticsearch拼写纠错是如何实现的?
大家好,我是锋哥。今天分享关于【说说Elasticsearch拼写纠错是如何实现的?】面试题。希望对大家有帮助; 说说Elasticsearch拼写纠错是如何实现的? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 Elasticsearch 中&…...

Ubuntu20.04运行R-VIO2
目录 1.环境配置2.构建项目3. 运行 VIO 模式4.结果图 1.环境配置 CMakeLists.txt中 C 使用 14、opencv使用4 2.构建项目 克隆代码库: 在终端中执行以下命令克隆项目:git clone https://github.com/rpng/R-VIO2.git编译项目: 使用 catkin_m…...

【软件项目测试文档大全】软件测试方案,验收测试计划,验收测试报告,测试用例,集成测试,测试规程和指南,等保测试(Word原件)
1. 引言 1.1. 编写目的 1.2. 项目背景 1.3. 读者对象 1.4. 参考资料 1.5. 术语与缩略语 2. 测试策略 2.1. 测试完成标准 2.2. 测试类型 2.2.1. 功能测试 2.2.2. 性能测试 2.2.3. 安全性与访问控制测试 2.3. 测试工具 3. 测试技术 4. 测试资源 4.1. 人员安排 4.…...
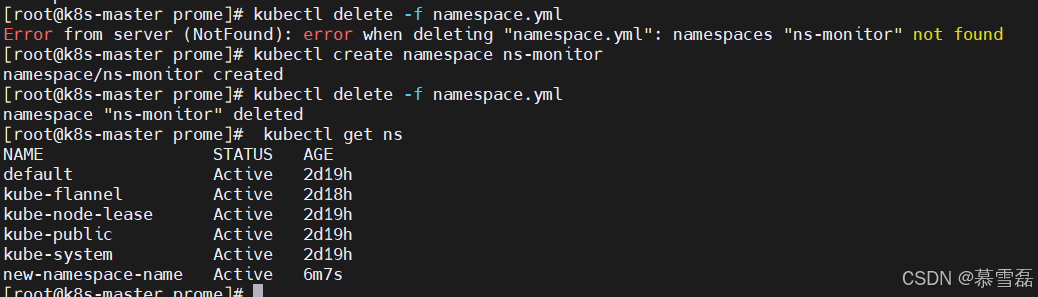
Kubernetes集群操作
查看集群信息: kubectl get nodes 删除节点 (⽆效且显示的也可以删除) 后期如果 要删除某个节点,为了不增加其他节点的访问压力,先增加一个节点,再删除要删除的节点 语法 :kubect delete…...

分布式事务调研
目录 需求背景: 本地事务 分布式基本理论 1、CAP 定理 2、BASE理论 分布式事务方案 #2PC #1. 运行过程 #1.1 准备阶段 #1.2 提交阶段 #2. 存在的问题 #2.1 同步阻塞 #2.2 单点问题 #2.3 数据不一致 #2.4 太过保守 3PC #本地消息表 TCC TCC原理 …...

Webpack 的构建流程
Webpack 的构建流程可以概括为以下几个步骤: 1. 初始化: Webpack 读取配置文件(webpack.config.js),合并默认配置和命令行参数,初始化Compiler对象。 2. 构建依赖图: 从入口文件开始递归地分…...

Cesium 当前位置矩阵的获取
Cesium 位置矩阵的获取 在 3D 图形和地理信息系统(GIS)中,位置矩阵是将地理坐标(如经纬度)转换为世界坐标系的一种重要工具。Cesium 是一个强大的开源 JavaScript 库,用于创建 3D 地球和地图应用。在 Cesi…...

ubuntu24.04 python环境
ubuntu24.04 python环境 0.引言1.使用整理 0.引言 新系统安装依赖库时报错: pip3installrequirements.txterror:externally−managed−environmentThisenvironmentisexternallymanaged╰–>ToinstallPythonpackagessystem−wide,tryaptinstallpython3−xyz,whe…...

YOLO系列论文综述(从YOLOv1到YOLOv11)【第9篇:YOLOv7——跨尺度特征融合】
YOLOv7 1 摘要2 网络架构3 改进点4 和YOLOv4及YOLOR的对比 YOLO系列博文: 【第1篇:概述物体检测算法发展史、YOLO应用领域、评价指标和NMS】【第2篇:YOLO系列论文、代码和主要优缺点汇总】【第3篇:YOLOv1——YOLO的开山之作】【第…...

Elasticearch索引mapping写入、查看、修改
作者:京东物流 陈晓娟 一、ES Elasticsearch是一个流行的开源搜索引擎,它可以将大量数据快速存储和检索。Elasticsearch还提供了强大的实时分析和聚合查询功能,数据模式更加灵活。它不需要预先定义固定的数据结构,可以随时添加或修…...

【大模型微调】一些观点的总结和记录
垂直领域大部分不用保持通用能力的,没必要跟淘宝客服聊天气预报,但是主要还是领导让你保持 微调方法没有大变数了,只能在数据上下功夫,我能想到的只有提高微调数据质量。 sft微调的越多,遗忘的越多. 不过对于小任务,rank比较低(例如8,16)的任务,影响还是有有限的。一…...

Vue 3 Hooks 教程
Vue 3 Hooks 教程 1. 什么是 Hooks? 在 Vue 3 中,Hooks 是一种组织和复用组件逻辑的强大方式。它们允许您将组件的状态逻辑提取到可重用的函数中,从而简化代码并提高代码的可维护性。 2. 基本 Hooks 介绍 2.1 ref 和 reactive 这两个函数…...

pandas数据处理及其数据可视化的全流程
Pandas数据处理及其可视化的全流程是一个复杂且多步骤的过程,涉及数据的导入、清洗、转换、分析、可视化等多个环节。以下是一个详细的指南,涵盖了从数据准备到最终的可视化展示的全过程。请注意,这个指南将超过4000字,因此请耐心…...
docker 在ubuntu系统安装,以及常用命令,配置阿里云镜像仓库,搭建本地仓库等
1.docker安装 1.1 先检查ubuntu系统有没有安装过docker 使用 docker -v 命令 如果有请先卸载旧版本,如果没有直接安装命令如下: 1.1.0 首先,确保你的系统包是最新的: 如果是root 权限下面命令的sudo可以去掉 sudo apt-get upda…...

torch.maximum函数介绍
torch.maximum 函数介绍 定义:torch.maximum(input, other) 返回两个张量的逐元素最大值。 输入参数: input: 张量,表示第一个输入。other: 张量或标量,表示第二个输入。若为张量,其形状需要能与 input 广播。输出&a…...

Java面试之多线程并发篇(9)
前言 本来想着给自己放松一下,刷刷博客,突然被几道面试题难倒!引用类型有哪些?有什么区别?说说你对JMM内存模型的理解?为什么需要JMM?多线程有什么用?似乎有点模糊了,那…...

Java全栈:超市购物系统实现
项目介绍 本文将介绍如何使用Java全栈技术开发一个简单的超市购物系统。该系统包含以下主要功能: 商品管理用户管理购物车订单处理库存管理技术栈 后端 Spring Boot 2.7.0Spring SecurityMyBatis PlusMySQL 8.0Redis前端 Vue.js 3Element PlusAxiosVuex系统架构 整体架构 …...

1.1 数据结构的基本概念
1.1.1 基本概念和术语 一、数据、数据对象、数据元素和数据项的概念和关系 数据:是客观事物的符号表示,是所有能输入到计算机中并被计算机程序处理的符号的总称。 数据是计算机程序加工的原料。 数据对象:是具有相同性质的数据元素的集合&…...

深度学习:GPT-2的MindSpore实践
GPT-2简介 GPT-2是一个由OpenAI于2019年提出的自回归语言模型。与GPT-1相比,仍基于Transformer Decoder架构,但是做出了一定改进。 模型规格上: GPT-1有117M参数,为下游微调任务提供预训练模型。 GPT-2显著增加了模型规模&…...

【Oracle11g SQL详解】ORDER BY 子句的排序规则与应用
ORDER BY 子句的排序规则与应用 在 Oracle 11g 中,ORDER BY 子句用于对查询结果进行排序。通过使用 ORDER BY,可以使返回的数据按照指定的列或表达式以升序或降序排列,便于数据的分析和呈现。本文将详细讲解 ORDER BY 子句的规则及其常见应用…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

Unity UGUI Button事件流程
场景结构 测试代码 public class TestBtn : MonoBehaviour {void Start(){var btn GetComponent<Button>();btn.onClick.AddListener(OnClick);}private void OnClick(){Debug.Log("666");}}当添加事件时 // 实例化一个ButtonClickedEvent的事件 [Formerl…...
AI语音助手的Python实现
引言 语音助手(如小爱同学、Siri)通过语音识别、自然语言处理(NLP)和语音合成技术,为用户提供直观、高效的交互体验。随着人工智能的普及,Python开发者可以利用开源库和AI模型,快速构建自定义语音助手。本文由浅入深,详细介绍如何使用Python开发AI语音助手,涵盖基础功…...