Nature Methods | 人工智能在生物与医学研究中的应用
Nature Methods | 人工智能在生物与医学研究中的应用
生物研究中的深度学习
随着人工智能(AI)技术的迅速发展,尤其是深度学习和大规模预训练模型的出现,AI在生物学研究中的应用正在经历一场革命。从基因组学、单细胞组学到癌症生物学,AI的引入不仅加速了数据处理和分析的速度,还为揭示生物学复杂性提供了新的视角。
▲ 在Pubmed 中检索"artificial intelligence" + disease,相关文章近几年呈现爆发式增长。
就在今年8月9号,顶级杂志 Nature Methods [IF: 36.1] 发表了 14 篇总结性文章,列出了深度学习与 AI 在生物学中的各种应用场景,可以说是腹泻式产出。小编简单将这些文章排列如下:
-
基础模型
-
- 生物学语言模型入门指南
- Transformers 在单细胞组学中的应用
- 基础模型学习细胞和基因表征
- 生物图像中的多模态大语言模型
-
AI的不同应用
-
- 生物影像中的解释性
- 空间组学
- 蛋白组学
- 癌症生物学
- 免疫系统
- 神经连接组学
- 基因组到功能调控
- 生物分子相互作用预测
- 生物重编程
-
社区伦理与呼吁
-
- 人工智能中的生物伦理
基础模型
为生物研究设计的语言模型:入门
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02354-y
**本篇论文介绍了语言模型(Language Models, LMs)在生物学研究中的应用,特别是自然语言和生物学序列基础的语言模型。**语言模型是一种AI模型,能够学习序列中的复杂模式,比如句子中的词汇或蛋白质中的氨基酸序列。它们的应用不仅限于文本生成,还可以解决多种生物信息学问题,如基因序列分析、蛋白质结构预测等。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ 生物研究中的语言模型可以处理自然语言(如英语)或生物语言(如单细胞数据中的基因或蛋白质序列),将输入分解为词块(如单词或氨基酸)进行处理。语言模型在生物研究中的应用主要包括三种方式:迁移学习方法,通过对预训练模型进行微调解决特定任务;直接预测方法,模型直接根据输入数据进行预测(如预测句子中的下一个单词);以及嵌入分析方法,通过计算输入的表示(嵌入)进行降维和聚类等分析。
Transformers 在单细胞组学中的应用
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02353-z
**本篇论文探讨了Transformer模型在单细胞组学中的应用,重点讨论了这一先进AI模型如何帮助解析细胞异质性和生物学动态。**单细胞组学为研究细胞类型、细胞状态变化以及疾病进程提供了深入的视角,但现有的分析方法无法充分挖掘这些数据的潜力。Transformer模型可以在单细胞组学的研究中发挥关键作用,解决现有分析方法无法解决的问题。与传统模型相比,Transformer具有处理异质数据集的优势,能够捕捉细胞间复杂的相互作用和生物学动态。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ Transformers最初设计用于处理顺序数据,如自然语言、DNA和蛋白质序列,但在处理非顺序的单细胞组学数据时面临挑战。为使这类数据适应变换器,研究者开发了不同的方法,将其嵌入为模型可处理的格式。这些方法通过逐元素求和,将单个细胞的RNA计数转换为嵌入表示,图中展示了常见的方法,包括基因嵌入、位置编码、值分箱和数据投影等。这些方法通过编码细胞的转录组特征,使变换器能够处理这些数据,其中位置编码反映了基因表达顺序或空间信息。特殊标记也被用于编码附加信息,如基因扰动或物种特定数据。
基础模型学习细胞和基因表征
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02367-7
本篇论文讨论了利用基础模型(foundation models),特别是生成预训练变换器(GPT)等大规模机器学习模型,在单细胞数据分析中的应用。随着单细胞组学数据的快速增长,AI模型被广泛应用于细胞类型标注、基因功能预测等任务。论文介绍了新的单细胞基础模型(scGPT和scFoundation),以及如何利用GPT-4这样的语言模型来增强单细胞数据的注释和分析。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ 训练一个单细胞基础模型的示意过程,单细胞转录组数据来自多个器官和供体(a)经过标记化处理,转化为一系列基因嵌入和可学习的细胞嵌入(b),并输入到变换器架构中进行预训练。经过大规模预训练后,基因嵌入(c)和细胞嵌入(d)会被更新,这些嵌入可以用于下游分析和微调任务。
生物图像中的多模态大语言模型
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02334-2
**本篇论文讨论了多模态大语言模型(Multimodal Large Language Models,MLLMs)在生物图像分析中的应用潜力。**随着成像技术和分析方法的迅速进展,生物学研究面临着前所未有的数据复杂性和体量挑战。MLLMs结合图像、文本等多种数据形式,展示了强大的理解、推理和概括能力,为生物图像分析提供了新的智能助手。这些模型通过整合来自多个模态的数据,能够在多个尺度上深入探究生物学世界,进而推动新型计算框架的发展。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ 用于生物影像分析的多模态大语言模型(MLLM)的架构。该架构由多个编码器组成,使用“专家混合”(MoE)模块进行来自不同模态的数据融合,从而使大语言模型(LLM)能够解码混合特征(左图)。为了在不增加额外训练的情况下高效提升MLLM的能力,可以通过使用RAG方法或将MLLM作为代理进行调整;当需要训练时,PEFT方法提供了一种高效的方式,将新知识融入MLLM中(右图)
AI的不同应用
生物影像中的解释性
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02322-6
**本篇论文探讨了解释性人工智能(XAI)在生物成像中的应用,重点关注深度学习(DL)模型的可视化解释性。**尽管深度学习在生物图像分析中取得了巨大成功,但其“黑箱”性质使得生物学意义的解释变得困难。作者回顾了XAI在生物成像中的现状,特别是视觉可解释性的潜力,讨论了其在假设生成和数据驱动发现中的应用前景。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ 图中展示了基于显著性图(右下)与基于反事实(上)的解释。显著性方法突出了对深度学习模型决策最重要的图像区域;而反事实方法则生成具有夸张分类驱动表型的人工现实图像,从而改变模型的预测。此示例中的夸张表型包括颜色、大小和深色斑点的数量。最常见的视觉可解释性方法大致可以分为基于显著性图和基于反事实的两类。基于显著性的方法(也称为“特征归因”)通过为每个像素分配网络内部层的激活值或梯度,生成图像区域的“注意力图”,以显示对个体预测贡献最大的区域。显著性方法适用于局部(实例)解释,当视觉解释在图像中是局部化的且不需要进一步训练时,特别适用于将注意力图与对应的亚细胞结构关联,或利用从细胞轨迹数据中衍生的注意力图来解释邻近细胞对给定细胞运动的相对影响。基于反事实的解释使用生成模型人工改变图像,以保持图像的真实性并改变模型的预测,它们在理解图像细微差异方面表现出色,尤其是在对人类直觉较为陌生的领域,如生物影像学。
空间组学
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02363-x
**本篇论文探讨了人工智能(AI)如何增强空间组学技术,进而推动生物医学研究的发展。**空间组学技术使我们能够以前所未有的分辨率分析组织的分子特征,并揭示细胞之间的空间结构与功能。然而,尽管这些技术取得了显著进展,如何有效整合不同类型的数据以充分挖掘其潜力仍然是一个挑战。AI的应用被认为是克服这些挑战的关键,能够帮助将复杂的数据集整合起来,从而发现新的生物医学见解。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ 人工智能如何整合不同层次和类型的生物医学数据。左图展示了细胞/Spot级数据、组织级数据和患者级数据作为人工智能模型输入的不同形式和分辨率。经过处理后,右图显示了丰富的输出,如单细胞和转录组全覆盖、集成的空间多组学数据以及三维分子组织体积,这些都能促进疾病预测和精准医疗的高级分析。
蛋白组学
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02324-4
**本篇论文探讨了人工智能(AI)如何辅助解释蛋白质组学研究中的数据,特别是在质谱分析的背景下。**尽管质谱技术已经能够提供广泛的定量检测,且其结果大多以蛋白质列表的形式呈现,AI方法的应用能够整合已有的文献知识,协调碎片化的数据集,从而推动蛋白质组学实验的机制性与功能性解释。AI的参与使得蛋白质组学不仅限于技术数据的展示,更能够深入挖掘生物学意义。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ 未来人工智能方法如何解读蛋白质组学实验。未来的人工智能方法将通过协调互不关联的先验知识库、创建跨异构数据集的互操作层,以及将这些信息整合到新一代模型中,产生可操作的假设并指导后续实验,从而推动系统生物学方法的全面扩展至整个蛋白质组。
癌症生物学
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02364-w
**本篇论文探讨了人工智能(AI)和多模态基因组学在癌症生物学中的应用,重点分析了AI如何帮助揭示肿瘤微环境(TME)的动态和功能。**随着AI技术和基因组学的进步,研究人员能够从肿瘤进展、免疫逃逸机制等多个角度深入了解癌症。AI和机器学习方法的结合可以有效处理和整合来自不同组学的数据,从而为癌症治疗的个性化和新型免疫疗法的发展提供数据支持。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ 利用机器学习深入了解 TME 的概述
免疫系统
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02351-1
**本篇论文探讨了人工智能(AI)如何帮助解锁人类免疫系统的复杂性,尤其是在免疫学研究中的应用。**免疫系统是一个多尺度、适应性强的网络,涉及细胞、分子和环境的相互作用。传统的统计学和机器学习方法虽然有助于分析免疫学数据,但仍面临着如何全面捕捉免疫系统复杂性的挑战。AI技术,特别是基础模型,能够处理大规模生物数据并提供新的研究思路,推动免疫学研究的突破。
神经连接组学
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02336-0
**本篇论文探讨了新一代人工智能(AI)技术,特别是基础模型和合成数据生成技术,在神经系统突触分辨率图谱(连接组学)生成中的应用。**作者分析了这些技术如何帮助突破当前的计算瓶颈,推动整个哺乳动物大脑连接组图谱的自动化生成,并减少生产连接组学图谱所需的成本和劳动力。
基因组到功能调控
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02331-5
**本篇论文探讨了利用序列到功能的模型(sequence-to-function models)解锁基因调控的潜力,特别是结合了深度学习与大规模功能基因组数据。**这些模型通过学习DNA序列与其多层次基因调控功能之间的关系,能够揭示细胞生物学的机制性关系。这将有助于转变我们对基因调控的理解,并为发现疾病机制开辟新的途径。
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ 基因型与表型关系的复杂性。左图解释了个人基因组的解读需要对不同层次的基因调控机制有深入理解,如何通过遗传变异影响中间过程(如染色质组织、表观基因组修饰、转录调控、转录后调控等)。右图展示了两种基因组解读方法:统计关联方法和细胞类型特异的序列到功能(S2F)模型。S2F模型通过输入基因组DNA并预测其功能属性(如基因表达),以细胞类型和状态为依赖变量,预测任意遗传变异的影响,并揭示决定上下文依赖基因调控的序列语法。
生物分子相互作用预测
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02350-2
**本篇论文讨论了人工智能在生物分子相互作用预测中的应用,特别是如何利用AI方法预测更广泛的生物分子相互作用,包括蛋白质、核酸和小分子。**论文回顾了AlphaFold和RoseTTAFold等AI模型在蛋白质三级和四级结构预测中的成就,并探讨了将AI方法扩展到其他生物分子相互作用的潜力及面临的挑战,尤其是如何克服数据稀缺和模型的专用性问题。
生物重编程
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
▲ DOI: 10.1038/s41592-024-02338-y
**本篇论文讨论了人工智能(AI)在生物学中的应用,特别是在分子和细胞工程方面的潜力。**通过AI技术,生物学不仅能够帮助揭示生命过程的奥秘,还能促进生物学的“编程”,从而操控分子、蛋白质和细胞等层面的功能。随着AI与基因组学、单细胞测序等技术的发展,生物学的可编程性已经迎来了新的革命,推动了新的治疗策略和工具的出现。
相关文章:

Nature Methods | 人工智能在生物与医学研究中的应用
Nature Methods | 人工智能在生物与医学研究中的应用 生物研究中的深度学习 随着人工智能(AI)技术的迅速发展,尤其是深度学习和大规模预训练模型的出现,AI在生物学研究中的应用正在经历一场革命。从基因组学、单细胞组学到癌症生…...

Axure PR 9 随机函数 设计交互
大家好,我是大明同学。 这期内容,我们将深入探讨Axure中随机函数的用法。 随机函数 创建随机函数所需的元件 1.打开一个新的 RP 文件并在画布上打开 Page 1。 2.在元件库中拖出一个矩形元件。 3.选中矩形元件,样式窗格中,将…...

【人工智能基础05】决策树模型
文章目录 一. 基础内容1. 决策树基本原理1.1. 定义1.2. 表示成条件概率 2. 决策树的训练算法2.1. 划分选择的算法信息增益(ID3 算法)信息增益比(C4.5 算法)基尼指数(CART 算法)举例说明:计算各个…...

【人工智能基础03】机器学习(练习题)
文章目录 课本习题监督学习的例子过拟合和欠拟合常见损失函数,判断一个损失函数的好坏无监督分类:kmeans无监督分类,Kmeans 三分类问题变换距离函数选择不同的起始点 重点回顾1. 监督学习、半监督学习和无监督学习的定义2. 判断学习场景3. 监…...
性能优化之状态管理最佳实践)
HarmonyOS(60)性能优化之状态管理最佳实践
状态管理最佳实践 1、避免在循环中访问状态变量1.1 反例1.2 正例 2、避免不必要的状态变量的使用3、建议使用临时变量替换状态变量3.1 反例3.2 正例 4、参考资料 1、避免在循环中访问状态变量 在应用开发中,应避免在循环逻辑中频繁读取状态变量,而是应该…...

数据库课程设计报告 超市会员管理系统
一、系统简介 1.1设计背景 受到科学技术的推动,全球计算机的软硬件技术迅速发展,以计算机为基础支撑的信息化如今已成为现代企业的一个重要标志与衡量企业综合实力的重要标准,并且正在悄无声息的影响与改变着国内外广泛的中小型企业的运营模…...

C++算法练习-day54——39.组合总和
题目来源:. - 力扣(LeetCode) 题目思路分析 题目:给定一个整数数组 candidates 和一个目标数 target,找出所有独特的组合,这些组合中的数字之和等于 target。每个数字在每个组合中只能使用一次。 思路&a…...

计算机毕业设计PySpark+Hadoop中国城市交通分析与预测 Python交通预测 Python交通可视化 客流量预测 交通大数据 机器学习 深度学习
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...

Linux的文件系统
这里写目录标题 一.文件系统的基本组成索引节点目录项文件数据的存储扇区三个存储区域 二.虚拟文件系统文件系统分类进程文件表读写过程 三.文件的存储连续空间存放方式缺点 非连续空间存放方式链表方式隐式链表缺点显示链接 索引数据库缺陷索引的方式优点:多级索引…...

【Vue3】从零开始创建一个VUE项目
【Vue3】从零开始创建一个VUE项目 手动创建VUE项目附录 package.json文件报错处理: Failed to get response from https://registry.npmjs.org/vue-cli-version-marker 相关链接: 【VUE3】【Naive UI】<NCard> 标签 【VUE3】【Naive UI】&…...
语法分析:半倒装和全倒装)
9)语法分析:半倒装和全倒装
在英语中,倒装是一种特殊的句子结构,其中主语和谓语(或助动词)的位置被颠倒。倒装分为部分倒装和全倒装两种类型,它们的主要区别在于倒装的程度和使用的场合。 1. 部分倒装 (Partial Inversion) 部分倒装是指将助动词…...

Scala关于成绩的常规操作
score.txt中的数据: 姓名,语文,数学,英语 张伟,87,92,88 李娜,90,85,95 王强,78,90,82 赵敏,92,8…...

使用Java实现度分秒坐标转十进制度的实践
目录 前言 一、度分秒的使用场景 1、表示方法 2、两者的转换方法 3、区别及使用场景 二、Java代码转换的实现 1、确定计算值的符号 2、数值的清洗 3、度分秒转换 4、转换实例 三、总结 前言 在地理信息系统(GIS)、导航、测绘等领域,…...

根据后台数据结构,构建搜索目录树
效果图: 数据源 const data [{"categoryidf": "761525000288210944","categoryids": "766314364226637824","menunamef": "经济运行","menunames": "经济运行总览","tempn…...

食品计算—FoodSAM: Any Food Segmentation
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

2411rust,1.83
原文 1.83.0稳定版 新的常能力 此版本包括几个说明在常环境中运行代码可干的活的大型扩展.这是指编译器在编译时必须计算的所有代码:常和静项的初值,数组长度,枚举判定值,常模板参数及可从(constfn)此类环境调用的函数. 引用静.当前,除了静项的初化器式外,禁止常环境引用静…...

tomcat加载三方包顺序
共享库 tomcat支持多个webapp共享一个三方库,而不需要每个webapp都引入该三方库 tomcat加载类顺序 bootstrap:加载jvm提供的类system:加载$CATALINA_HOME/bin下的bootstrap.jar,commons-daemon.jar,tomcat-juli.jar三个包//加载$CLASSPATH…...

计算机的错误计算(一百七十一)
摘要 探讨 MATLAB 中秦九韶(Horner)多项式的错误计算。 例1. 用秦九韶(Horner)算法计算(一百零七)例1中多项式 直接贴图吧: 这样,MATLAB 给出的仍然是错误结果,因为准…...

js对于json的序列化、反序列化有哪几种方法
在JavaScript中,对JSON(JavaScript Object Notation)进行序列化(将对象转换为JSON字符串)和反序列化(将JSON字符串转换为对象)是常见的操作。以下是一些常用的方法: 序列化…...

Linux——基础命令(2) 文件内容操作
目录 编辑 文件内容操作 1.Vim (1)移动光标 (2)复制 (3)剪切 (4)删除 (5)粘贴 (6)替换,撤销,查找 (7ÿ…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...
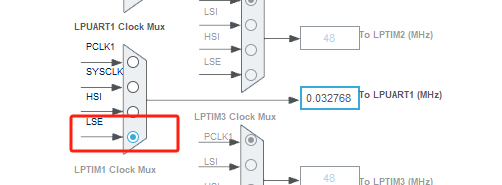
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...
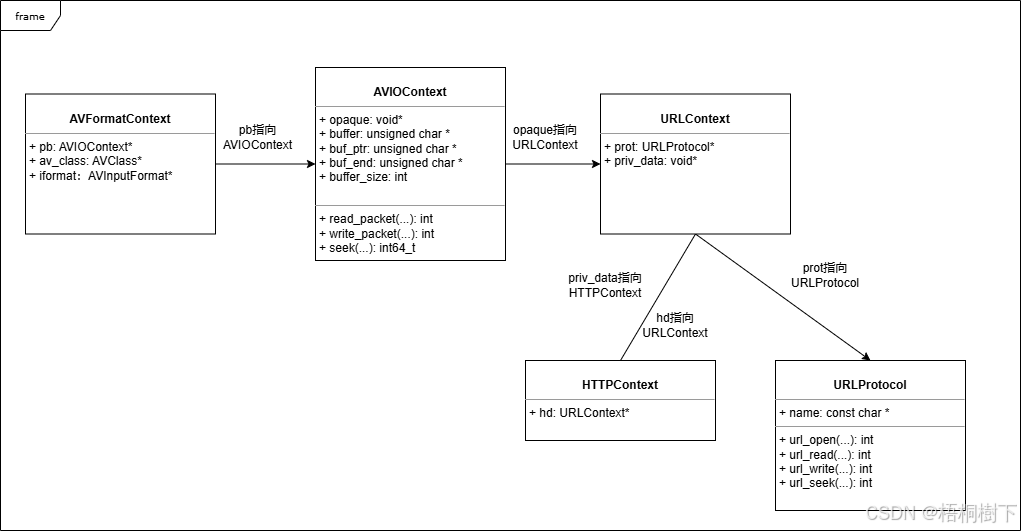
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...