51c自动驾驶~合集39
我自己的原文哦~ https://blog.51cto.com/whaosoft/12707676
#DiffusionDrive
大幅超越所有SOTA!地平线DiffusionDrive:生成式方案或将重塑端到端格局?
近年来,由于感知模型的性能持续进步,端到端自动驾驶受到了来自工业界和学术界的广泛关注,端到端自动驾驶算法直接从原始传感器采集到的信息输入中学习驾驶策略。这种基于数据驱动的方法为传统的基于规则的运动规划提供了一种可扩展且强大的替代方案,而传统的基于规则的运动规划通常难以推广到复杂的现实世界驾驶环境。为了有效地从数据中学习驾驶过程,主流的端到端规划器通常从自车查询中回归出单模轨迹,如下图所示。

然而,这种回归单模轨迹的框架模式并没有考虑到驾驶行为中固有的不确定性和多模式的性质。最近,提出的端到端自动驾驶算法VADv2引入了大量固定的锚点轨迹vocabulary。然后,根据预测的评分从这些锚点中进行采样。然而,这种大型固定vocabulary范式从根本上受到锚点轨迹数量和质量的限制,在vocabulary不足的情况下经常会失败。此外,管理大量锚点对实时的自动驾驶应用来说带来了巨大的计算挑战。
与离散化动作空间不同,扩散模型已被证明是机器人领域一种强大的生成决策策略,它可以通过迭代去噪过程的方式直接从高斯分布中采样多模式物理上合理的动作。这激励我们将机器人领域的扩散模型的成功经验复制到端到端自动驾驶领域当中。
我们将原始机器人扩散策略应用于单模回归方法Transfuser。与普通扩散策略不同,人类驾驶员遵循既定的驾驶模式,并根据实时交通状况进行动态调整。这一认识促使我们将这些先前的驾驶模式嵌入到扩散策略中,具体方法是将高斯分布划分为以先前锚点为中心的多个子高斯分布,称为anchored Gaussian分布。它是通过截断diffusion schedule来实现的,从而在先前的锚点周围引入一小部分高斯噪声,如下图所示。

为了增强与条件场景上下文的交互,我们提出了一种基于Transformer的扩散解码器,它不仅与感知模块的结构化查询交互,还通过稀疏可变形注意机制与鸟瞰图 和透视图特征交互。此外,我们引入了一种级联机制,在每个去噪步骤中迭代细化扩散解码器内的轨迹重建。
最终,我们提出了一种实时端到端自动驾驶的扩散模型,称之为DiffusionDrive。我们在NAVSIM数据集上对我们的方法进行闭环评估的基准测试。相关的实验结果表明,DiffusionDrive实现了88.1的PDMS,显著超过了之前的SOTA算法。此外,我们通过开环评估进一步验证了DiffusionDrive在nuScenes数据集上的性能, 相关的实验结果表明提出的DiffusionDrive实现了SOTA的表现结果。
论文链接:https://arxiv.org/pdf/2411.15139
算法模型网络结构&技术细节梳理
调研工作
如前文所述,我们先从非常具有代表性的端到端规划算法Transfuser开始,通过简单地将回归MLP层替换为遵循扩散策略的条件扩散模型 UNet,将其转变为生成模型。在评估过程中,我们采样随机噪声并通过20个step逐步对其进行细化,相关的实验结果如下表所示。

为了进一步研究扩散策略在驾驶中的多模式特性,我们从高斯分布中采样了20个随机噪声,并使用20个step对其进行去噪。如下图所示。

不同的随机噪声在去噪后会收敛到相似的轨迹。为了定量分析模式坍塌现象,我们定义了一个模式多样性得分,根据每条去噪轨迹与所有去噪轨迹的并集之间的平均交并比计算得到:

相关的实验结果如下表所示。通过表格中的结果可以看出,mIoU 越高,表示去噪轨迹的多样性越低。通过可视化的结果可以看出类似的效果。此外,通过下表的实验结果还可以看出,DDIM扩散策略需要20个去噪step才能将随机噪声转换为可行轨迹,这会带来大量计算开销。这使得它对于实时在线驾驶应用来说不切实际。

截断扩散
人类的驾驶行为遵循着固定模式,不同于普通扩散策略中的随机噪声去噪。受此启发,我们提出了一种截断扩散策略,该策略从锚定高斯分布而不是从标准高斯分布开始进行去噪过程。为了使模型能够学习从锚定高斯分布到所需的驾驶策略进行去噪,我们在训练期间进一步截断扩散计划,只向锚点添加少量高斯噪声。
训练过程:我们首先通过向训练集上由K-Means 聚类的锚点添加高斯噪声来构建扩散过程。我们通过截断扩散噪声方案来将锚点扩散到锚定高斯分布,相关的计算公式如下。
![]()
在训练期间,扩散解码器将噪声轨迹作为输入,并预测分类分数和去噪轨迹,相关公式如下。
![]()
我们将最接近真实轨迹的锚点周围的噪声轨迹指定为正样本,其他轨迹指定为负样本。训练目标结合了轨迹重建和分类,计算公式如下所示。

推理过程:我们使用截断去噪过程,从锚定高斯分布中采样的噪声轨迹开始,并逐步对其进行去噪,直至完成最终预测。在每个去噪时间戳中,上一步估计的轨迹被传递给扩散解码器,该解码器预测分类分数和坐标。在获得当前时间戳的预测后,我们将 DDIM 更新规则应用于下一个时间戳的样本轨迹。
推理灵活性:我们提出的自动驾驶DiffusionDrive算法的一个关键优势在于其推理的灵活性。虽然模型是用轨迹进行训练的,但其推理过程可以容纳任意数量的轨迹样本,并可以根据计算资源或应用要求进行动态的调整。
DiffusionDrive算法整体框架图
如下图所示,展示了我们提出的算法模型DiffusionDrive的网络结构。

DiffusionDrive算法模型可以集成之前端到端规划器中使用的各种现有感知的模块,并接受不同的传感器信息作为输入。设计的扩散解码器专为复杂且具有挑战性的驾驶应用而量身定制,增强了与条件场景环境的交互。
Diffusion Decoder:给定一组从锚定高斯分布中采样的噪声轨迹,我们首先应用可变形空间交叉注意力来与基于轨迹坐标的鸟瞰图 (BEV) 或透视图 (PV) 特征进行交互。随后,在轨迹特征和从感知模块派生的代理/地图查询之间执行交叉注意力,然后接一个FFN网络。为了对扩散时间戳信息进行编码,我们使用Timestep Modulation Layer,然后是多层感知机网络,用于预测置信度得分和相对于初始噪声轨迹坐标的偏移量。该Timestep Modulation Layer的输出用作后续级联扩散解码器层的输入。DiffusionDrive 进一步重用级联扩散解码器在推理过程中迭代地对轨迹进行去噪,并在不同的去噪时间步长之间共享参数。选择置信度得分最高的最终轨迹作为输出。
实验结果&评价指标
整体性能比较
下表展现了将DiffusionDrive与NAVSIM数据集上最先进的算法模型进行比较的实验结果汇总。

使用相同的 ResNet-34主干网络,DiffusionDrive 获得了 88.1 PDMS 分数,与之前基于学习的方法相比,其性能有显著的提高。与 VADv2自动驾驶算法相比, DiffusionDrive 超越了它 7.2 PDMS,同时将锚点数量从 8192 个减少到 20 个,减少了 400 倍。DiffusionDrive 还优于遵循 VADv2 的vocabulary采样范式的 HydraMDP算法模型,PDMS相比于提高了 5.1。即使与性能更强的算法模型相比,DiffusionDrive 仍然比它高出 3.5 个 EP 和 1.6 个整体 PDMS,完全依赖于直接向人类学习的方法,没有任何的后处理操作步骤。与 Transfuser算法模型的基线相比,我们仅在规划模块上有所不同,DiffusionDrive 实现了显着的 4.1 PDMS 改进,在所有子分数中均优于它。
此外,如下表所示,使用扩散策略将Transfuser算法模型转换为生成式,可将PDMS 得分提高 0.6,并提高模式多样性得分11%。然而,它也显著增加了规划模块的开销,需要 20 倍以上的去噪step和 32 倍的时间,导致运行时开销总共增加了 650 倍。

通过采用所提出的截断扩散策略,将去噪step的数量从 20 减少到 2,同时实现了 PDMS 增加 1.1,模式多样性提高 59%。通过进一步结合所提出的扩散解码器,最终 DiffusionDrive 模型达到了 88.1 PDMS 和 74% 的模式多样性得分。相比于,DiffusionDrive实现了3.5 PDMS 和 64% 模式多样性的改进, 以及去噪step减少了10倍,从而使 FPS 速度提高了 6 倍。这可以实现实时、高质量的多模式规划。
消融实验分析
下表显示了我们在扩散解码器中的设计选择的有效性。通过比较 ID-6 和 ID-1,我们可以看到所提出的扩散解码器减少了 39% 的参数,并将规划质量显著提高了 2.4 PDMS。由于缺乏与环境的丰富和层次化交互,ID-2 表现出严重的性能下降。通过比较 ID-2 和 ID-3,我们可以看到空间交叉注意对于准确规划至关重要。ID-5 表明所提出的级联机制是有效的,并且可以进一步提高性能。

下表的实验结果表明,由于起始点的选择比较合理,DiffusionDrive仅需1步即可达到良好的规划质量。进一步增加去噪步长可以提高规划质量,并使其在复杂的环境下具有灵活的推理能力。

通过下表的实验结果可以看出,消除了级联阶段数的影响。增加阶段数可以提高规划质量,但在 4 个阶段就会饱和,并且每一步都会花费更多的参数和推理时间。

由于在上文中已经有所提到,DiffusionDrive 只需从锚定高斯分布中采样可变数量的噪声即可生成不同的轨迹。下表的相关实验结果可以看出,10 个采样噪声已经可以实现不错的规划质量。通过采样更多噪声,DiffusionDrive 可以覆盖潜在的规划动作空间并提高规划质量。

由于 PDMS 规划指标基于得分最高的轨迹进行计算,而我们提出的分数评估模式多样性,因此仅凭这些指标无法完全捕捉多样化轨迹的质量。为了进一步验证多模式轨迹的质量,我们在 NAVSIM数据集上的具有挑战性的场景中可视化了 Transfuser、和 DiffusionDrive 的规划结果,如下图所示。

通过可视化的结果可以看出,DiffusionDrive 生成的多模式轨迹不仅多样性,而且质量较高。在上图的a图展示的结果可以看出,DiffusionDrive 算法模型生成的得分最高的前 10 条轨迹与真实轨迹非常相似,而突出显示的前 10 条得分轨迹出人意料地试图执行高质量的车道变换。上图的b图展示的结果可以看出,突出显示的前 10 条得分轨迹也执行车道变换,相邻的低得分轨迹进一步与周围的代理交互以有效避免了碰撞的发生。
nuScenes 数据集是之前流行的端到端规划基准。由于 nuScenes 的主要场景都是简单而琐碎的情况,因此我们仅进行相关结果的比较,如下表所示。

我们根据 SparseDrive 的训练和推理方案,使用 ST-P3中提出的开环指标,在 SparseDrive之上实现了 DiffusionDrive算法模型。我们堆叠了 2 个级联扩散解码器层,并应用了具有 18 个聚类锚点的截断扩散策略。通过上表的实验结果可以看出,DiffusionDrive 将 SparseDrive 的平均 L2 误差降低了 0.04m,与之前最先进的方法相比,实现了最低的 L2 误差和平均碰撞率。同时 DiffusionDrive 算法模型也非常高效,运行速度比 VAD 快 1.8 倍,L2 误差降低了 20.8%,碰撞率降低了 63.6%。
结论
在本文中,我们提出了一种新颖的生成式驾驶决策模型 DiffusionDrive,该模型结合了所提出的截断扩散策略和高效的级联扩散解码器,用于端到端自动驾驶。全面的实验和定性比较验证了 DiffusionDrive 在规划质量、运行效率和模式多样性方面的优越性。
#机器人甚至可以在火锅店中无痛部署!
Data Scaling Law
想象一下,你正在火锅店涮肉,一位“人美声靓”的服务员悄然从你身边走过,不仅及时地为你把菜送到身边,还帮你把菜端到桌子上并摆放整齐。正在酣畅淋漓涮肉的你正想夸一下这家店的服务真不错,猛一抬头发现,居然是个机器人!
咨询了店长才知道,这是昨天刚到的一批“服务员”。内心更加震惊:居然这么快就上岗工作了!都不用培训?即插即用?!
这大概就是Scaling law的魔力了吧。
现如今大模型已发展得如火如荼,然而为什么还没有实现真正的落地?也就是说,为了让AI渗透到生活的每个角落,实现边缘化部署,还需要做什么?有一点亟需研究清楚,即模型性如何能随数据集、模型大小和训练计算量的增加而提升?这就是Data Scaling Law,也可称为数据缩放定律。如何在保留数据集关键信息的同时,尽可能减少数据量,而不牺牲模型的性能?如何在不增加计算资源的情况下,尽量降低模型的错误率?
早在2020年,OpenAI就提出了对Neural Language Models的Scaling law(Kaplan et al.,https://arxiv.org/pdf/2001.08361),说明了模型性能随着模型参数量、数据量和用于训练的计算量的指数级增加而平稳提高。对于计算量(C),模型参数量(P)和数据大小(D),当不受其他两个因素制约时,模型性能与每个因素都呈现幂律关系。2022年DeepMind团队(Hoffmann et al., https://arxiv.org/pdf/2203.15556)发现不应该将大模型训练至最低的可能loss来获得计算最优,模型规模和训练tokens的数量应按相同比例扩展。2023年Hugging Face团队(Colin Raffel et al., https://arxiv.org/pdf/2305.16264)发现在量化在数据受限的情况下,通过增加训练epoch和增加模型参数可以以次优计算利用率为代价提取更多的信息。
通过适当的数据缩放,单任务策略可以很好地泛化到任何新环境以及同一类别中的任何新对象。值得注意的是,机器人甚至可以在火锅店中进行零样本部署!
,时长00:38
视频来源:https://data-scaling-laws.github.io/
文章表明,当前机器人策略缺乏零样本泛化能力,文章旨在研究机器人操作中数据缩放规律,为构建大规模机器人数据集提供指导。文章探讨了机器人操作模仿学习中的数据缩放规律,通过实验揭示了策略泛化性能与训练环境、对象及演示数量的关系,提出了高效的数据收集策略。
DATA SCALING LAWS IN IMITATION LEARNING FOR ROBOTIC MANIPULATION
https://data-scaling-laws.github.io/https://data-scaling-laws.github.io/paper.pdf
论文通过 Pour Water(倒水)和 Mouse Arrangement(鼠标放置)两项任务进行大量实验以得出数据缩放规律,并在 Fold Towels(叠毛巾)和 Unplug Charger(拔充电器)等其他任务上进一步验证这些发现。文章的发现如下:
- 简单幂律:策略对新对象、新环境或两者的泛化能力分别大致与训练对象、训练环境或训练环境 - 对象对的数量呈幂律关系。
- 多样性就是关键:增加环境和对象的多样性远比增加每个环境或对象的演示绝对数量更有效。
- 泛化比预期更容易:在尽可能多的环境(例如 32 个环境)中收集数据,每个环境有一个独特的操作对象和 50 次演示,就能够训练出一个对任何新环境和新对象都能很好泛化(90% 成功率)的策略。
相关工作
那么,有哪些已有研究工作与机器人操作数据缩放定律相关呢?
- 缩放规律:缩放规律最初在神经语言模型中被发现,揭示了数据集大小(或模型大小、计算量)与交叉熵损失之间的幂律关系。
- 机器人操作中的数据缩放:机器人操作领域也有数据规模扩大的趋势,但部署仍需微调。本文关注训练可直接在新环境和未见对象中部署的策略,同时也有研究探索提高数据缩放效率以增强泛化能力。
- 机器人操作中的泛化:包括对新对象实例、新环境的泛化以及遵循新任务指令的泛化。本文专注于前两个维度,即创建能在任何环境中操作同一类别内几乎任何对象的单任务策略。
研究方法
- 概括维度:考虑环境(对未见环境的泛化)和对象(对同一类别新对象的泛化)两个维度,通过收集不同环境和对象的人类演示数据,使用行为克隆(BC)训练单任务策略。
- 数据缩放规律公式化:在M个环境和N个同一类别的操作对象中收集演示数据,每个环境 - 对象对收集K个演示,评估策略在未见环境和对象上的性能,以揭示泛化能力与变量M、N、K的关系。
- 评估:通过在未见环境或对象中测试评估策略泛化性能,使用测试者分配的分数作为主要评估指标(计算归一化分数),同时最小化测试者主观偏差,确保结果可靠。
实验结果与分析
实验结果如下。以Pour Water和Mouse Arrangement任务为例,增加训练对象数量可提高策略对未见对象的性能,对象泛化相对容易实现,且训练对象增多时,每个对象所需演示减少。
用相同操作对象在不同环境收集数据,增加训练环境数量可提升策略在未见环境的泛化性能,但每个环境中演示数量增加对性能提升的作用会快速减弱,且环境泛化比对象泛化更具挑战性。
在环境和对象同时变化的设置中,增加训练环境 - 对象对数量可增强策略泛化性能,且同时改变环境和对象比单独改变更能增加数据多样性,使策略学习更高效。
实验结果遵循幂律缩放规律,策略对新对象、新环境或两者的泛化能力分别与训练对象、环境或环境 - 对象对数量呈幂律关系;当环境和对象数量固定时,演示数量与策略泛化性能无明显幂律关系。
为了实现高效的数据收集策略,文章建议在尽可能多的不同环境中收集数据,每个环境使用一个独特对象;当环境 - 对象对总数达到32时,通常足以训练出在新环境中操作未见对象的策略。
实验表明,超过一定数量的演示收益甚微,对于类似难度任务,建议每个环境 - 对象对收集50个演示,更具挑战性的灵巧操作任务可能需要更多演示。
为了验证上述策略的合理性,将数据收集策略应用于Fold Towels和Unplug Charger新任务,四个任务(包括之前的Pour Water和Mouse Arrangement)的策略成功率约达90%,凸显了数据收集策略的高效性。
模型大小和训练策略:研究Diffusion Policy中视觉编码器的训练策略和参数缩放影响,发现预训练和全量微调对视觉编码器至关重要,增加其大小可提升性能,但缩放动作扩散U - Net未带来性能提升。
文章还强调数据缩放应注重数据质量,本文揭示了环境和对象多样性在模仿学习中的重要价值。但本文仍存在一些局限性,比如当前工作专注于单任务策略的数据缩放,未探索任务级泛化;仅研究了模仿学习中的数据缩放,强化学习或可进一步增强策略能力;UMI收集数据存在小误差且仅用Diffusion Policy算法建模,未来可研究数据质量和算法对数据缩放规律的影响;资源限制下仅在四个任务上探索和验证数据缩放规律,期望未来在更多复杂任务上验证结论。
#生成模型 | 去噪扩散模型 DDPM 半小时理论扫盲
本文希望先跳过很多不熟悉的名词和定理,找出我认为适合初学者理解的部分,下一篇文章 [生成模型 2] 整流流 Rectified Flow 理论简介
有个完整理解后,再看 ewrfcas:由浅入深了解Diffusion Model 就不会觉得害怕
本文大量参考了网上文献和使用 跃问 辅助,如有纰漏求指正
主要参考的是苏神的 生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼 和 生成扩散模型漫谈(二):DDPM = 自回归式VAE,DDPM 论文
假设读者记得一些概率论的基本知识,如果忘了可以移步 Deja vu:一文带你看懂DDPM和DDIM(含原理简易推导,pytorch代码) 看前置知识
核心价值 以能量模型为抓手,将得分匹配下沉到朗之万方程的动态轨迹,打通马尔可夫链底层逻辑,发力变分推断引爆点,形成去噪过程递归闭环,拉通前向-反向全链路,卡位生成模型赛道,造势图像生成风口,布局多模态蓝海,沉淀噪声调度护城河,赋能潜在空间表征,倒逼模型优化,输出高质量样本反馈,升华生成建模格局,重塑数据生成认知矩阵,击穿传统生成模型研究员心智,打出一套组合拳。
生成扩散模型介绍
从 2019 BigGAN 可以生成 ImageNet 某一类别的 128p 图片,2022-2023 的 DALLE-2/3 又是新的里程碑
用卷积神经网络做图像任务,模型性能随着模型参数 / 训练数据量增加,其实经常是边际收益递减的
我理解 transformer 流行的一个原因是在模型放大时能有不错的边际收益,而生成扩散模型则找到了一种可以在推理时使用非常大算力来提升效果的范式,这两者实现它们和卷积神经网络的差异化
分步扩散和生成
我们的目标是一个生成模型,它从随机噪声 z 变成数据样本 x

如果我们能把中间扩散的每一步的逆过程 生成 建模出来,得到一个生成函数:=()(2)
然后从随机噪声 z 开始,生成 T 步就得到了 x
CV+DL 白话:训练的时候,随机采样数据 x 和步数 t,学到的变换模型,推理的时候,从一个随机高斯噪声递归调用 T 步学出来的模型得到生成结果
具体来说,DDPM 的扩散过程是

其一般形式来自 Variational Diffusion ModelsVariational Diffusion Models

之后推导中可以把系数看作是我们选的常数项




这里可以看到可训练参数是噪声项的下标,表示我们实际上是在预测第 t 步添加到数据样本中的噪声(实现上就是一个输入 xt 和 t 的神经网络)
代入损失函数有
推导中把 xt 变成了 x0 的加噪形式 (4)

小结:到这里我们已经了解很多了,我们知道了一个单步的具体优化过程,其中只有一个关键步骤是高斯噪声叠加过程的理解
接下来这个小节是为了把两个通过一些技巧变成一个,使得我们采样时方差变小,优化更简单
损失函数优化(可以跳过)


参数选取

在实践中,DDPM 设置生成步数 T=1000,后续有很多工作讨论加速和优化


另一方面据苏神解释,在图像上用欧式距离时,当两张图片非常接近时才好度量,所以不管是选取大的 T,还是单调递减的,都是希望在靠近图片一侧的扩散过程的每一步都走的不太远,而在靠近噪声一侧走得远一点也无妨
我感觉就算选取了更好的度量,我们仍然会希望把更多的推理开销花在靠近图片的一侧而不是最初叠加噪声的过程
小结:以上其实就是完整推导,后面是从 VAE 的角度再解释一遍,大部分推导技巧是一致的
VAE 角度理解
稍微介绍几句 VAE,做过一段神经网络的朋友应该都知道编解码结构,z = g(x), x' = f(z)
用一张图 x 和 f(g(x)) 计算欧式距离就可以训练这样一对网络
如果我们抛弃掉 g,随便采样一个 z,解码 f(z) 出来会发现基本上是噪声
这是因为 z 的先验分布 q(z) 没有建模,f 对随机的 z 是不鲁棒的
VAE 会将条件分布 p(z|x)(编码)和 q(x|z)(解码)以及 q(z) 建模为高斯分布
但是这种一步到位的做法并不能提供足够强的表达能力


做生成模型的目标是希望生成模型的联合分布 q 尽可能接近真实数据的联合分布 p,可以通过最小化 KL 散度实现
联系到 DDPM
在 DDPM 中,模型每一步的编码过程 p (3),是不含可训练参数的,所以标红的 p 是常数项
所以 (16) 就是
对比一下就是把 log 下面的分母变出前面负号,然后写成求和形式
这里的先验分布q()一般取标准高斯分布, 所以取 log 是常数项
看求和中的第 t 步
(18)


其实就是 (8) 多了权重和常数项,往后推的结果和 (11) 也只是有权重系数区别
这个系列为了督促自己补齐相关知识,希望能持续写一段时间
#xxx
#xxx
#xxx
#xxx
#xxx
#xxx
#xxx
相关文章:
51c自动驾驶~合集39
我自己的原文哦~ https://blog.51cto.com/whaosoft/12707676 #DiffusionDrive 大幅超越所有SOTA!地平线DiffusionDrive:生成式方案或将重塑端到端格局? 近年来,由于感知模型的性能持续进步,端到端自动驾驶受到了来…...

单链表基础操作
文章目录 abstract定义结点结构初始化链表遍历链表求表长查找结点根据序号查找结点根据值查找结点 插入结点首尾位置插入一般位置插入(通用插入)找到尾元素|尾指针相关操作 删除结点 abstract 单链表是一种简单的动态数据结构,它由一系列结点组成,每个结…...
,用命令代码)
Asp.net MVC在VSCore中的页面的增删改查(以Blog项目为例),用命令代码
在VSCore中的页面的增删改查(以Blog项目为例) 1.创建项目(无解决方案)复杂项目才需要 dotnet new mvc -o Blog2.控制器 BlogsController.cs 控制器(Controller)名字和视图(View)中的文件名要一模一样 u…...

【Leecode】Leecode刷题之路第66天之加一
题目出处 66-加一-题目出处 题目描述 个人解法 思路: todo代码示例:(Java) todo复杂度分析 todo官方解法 66-加一-官方解法 方法1:找出最长的后缀9 思路: 代码示例:(Java&#…...

使用 VLC 在本地搭建流媒体服务器 (详细版)
提示:详细流程 避坑指南 Hi~!欢迎来到碧波空间,平时喜欢用博客记录学习的点滴,欢迎大家前来指正,欢迎欢迎~~ ✨✨ 主页:碧波 📚 📚 专栏:音视频 目录 借助VLC media pl…...

Ubuntu 常用解压与压缩命令
.zip文件 unzip FileName.zip # 解压 zip DirName.zip DirName # 将DirName本身压缩 zip -r DirName.zip DirName # 压缩,递归处理,将指定目录下的所有文件和子目录一起压缩 zip DirName.zip DirName 行为: 只压缩 DirName 目录本身ÿ…...

【深度学习】四大图像分类网络之AlexNet
AlexNet是由Alex Krizhevsky、Ilya Sutskever(均为Hinton的学生)和Geoffrey Hinton(被誉为”人工智能教父“,首先将反向传播用于多层神经网络)在2012年ImageNet图像分类竞赛中提出的一种经典的卷积神经网络。AlexNet在…...

Day1——GitHub项目共同开发
MarkDowm解释 Markdown是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档,然后转换成结构化的HTML代码。Markdown的目的是让文档的编写和阅读变得更加容易,同时也不失HTML的强大功能。以下是Markdown的一些基本概念和用法&a…...

基于PHP的香水销售系统的设计与实现
摘 要 时代科技高速发展的背后,也带动了经济的增加,人们对生活质量的要求也不断提高。香水作为一款在人际交往过程中,给对方留下良好地第一印象的产品,在生活中也可以独自享受其为生活带来的点缀。目前香水市场体量庞大ÿ…...

A-star算法
算法简介 A*(A-star)算法是一种用于图形搜索和路径规划的启发式搜索算法,它结合了最佳优先搜索(Best-First Search)和Dijkstra算法的思想,能够有效地寻找从起点到目标点的最短路径。A*算法广泛应用于导航、…...

前端用原生js下载File对象文件,多用于上传附件时,提交之前进行点击预览,或打开本地已经选择待上传的附件列表
用于如上图场景,已经点击选择了将要上传的文件,在附件列表里面用户希望点击下载文件,以核实自己是否选中了需要上传的文件,此刻就需要 用到下面的方法: // 下载File对象文件 downloadByFileObject(file, { fileName }…...

服务器记录所有用户docker操作,监控删除容器/镜像的人
文章目录 使用场景安装auditd添加docker审计规则设置监控日志大小与定期清除查询 Docker 操作日志查看所有用户,所有操作日志查看特定用户的 Docker 操作查看所有用户删除容器/镜像日志过滤特定时间范围内日志 使用场景 多人使用的服务器,使用的docker …...

关于使用天地图、leaflet、ENVI、Vue工具实现 前端地图上覆盖上处理的农业地块图层任务
1.项目框架搭建 项目地址:Webgis: 一个关于webgis、天地图、Leaflet、Vue、数据库的学习框架。 ①git到本地,vscode打开。 ② 配置后端 搜索下载MySQL插件(前提:电脑中装有MySQL才可应用)。 连接数据库。 配置基本…...

基于yolov4深度学习网络的排队人数统计系统matlab仿真,带GUI界面
目录 1.算法仿真效果 2.算法涉及理论知识概要 3.MATLAB核心程序 4.完整算法代码文件获得 1.算法仿真效果 matlab2022a仿真结果如下(完整代码运行后无水印): 仿真操作步骤可参考程序配套的操作视频。 2.算法涉及理论知识概要 在现代社会…...

用 React 编写一个笔记应用程序
这篇文章会教大家用 React 编写一个笔记应用程序。用户可以创建、编辑、和切换 Markdown 笔记。 1. nanoid nanoid 是一个轻量级和安全的唯一字符串ID生成器,常用于JavaScript环境中生成随机、唯一的字符串ID,如数据库主键、会话ID、文件名等场景。 …...

如何离线安装dockerio
如何离线安装dockerio 一、下载Docker离线安装包二、上传离线安装包三、解压安装包四、复制文件到系统目录五、配置Docker服务六、设置文件权限并重新加载配置七、启动Docker服务八、设置开机自启动九、验证安装Docker是一个开源的容器化平台,用于开发、发布和运行应用程序。离…...

LocalDateTime序列化(跟redis有关)
使用过 没成功,序列化后是[2024 11 10 17 22 20]差不多是这样, 反序列化后就是: [ 2024 11 10.... ] 可能是我漏了什么 这是序列化后的: 反序列化后: 方法(加序列化和反序列化注解)&…...

【redis】如何跑
在 Windows 上配置 Redis 需要一些额外的步骤,因为 Redis 官方并没有为 Windows 提供原生支持。不过,可以通过以下方法来安装和配置 Redis。 方法一:使用 Windows 版 Redis(非官方版本) 下载 Redis for Windows Redis…...

Scala学习记录,全文单词统计
package test32 import java.io.PrintWriter import scala.io.Source //知识点 // 字符串.split("分隔符":把字符串用指定的分隔符,拆分成多个部分,保存在数组中) object test {def main(args: Array[String]): Unit {//从文件1.t…...

【MyBatis】验证多级缓存及 Cache Aside 模式的应用
文章目录 前言1. 多级缓存的概念1.1 CPU 多级缓存1.2 MyBatis 多级缓存 2. MyBatis 本地缓存3. MyBatis 全局缓存3.1 MyBatis 全局缓存过期算法3.2 CacheAside 模式 后记MyBatis 提供了缓存切口, 采用 Redis 会引入什么问题?万一遇到需强一致场景&#x…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...
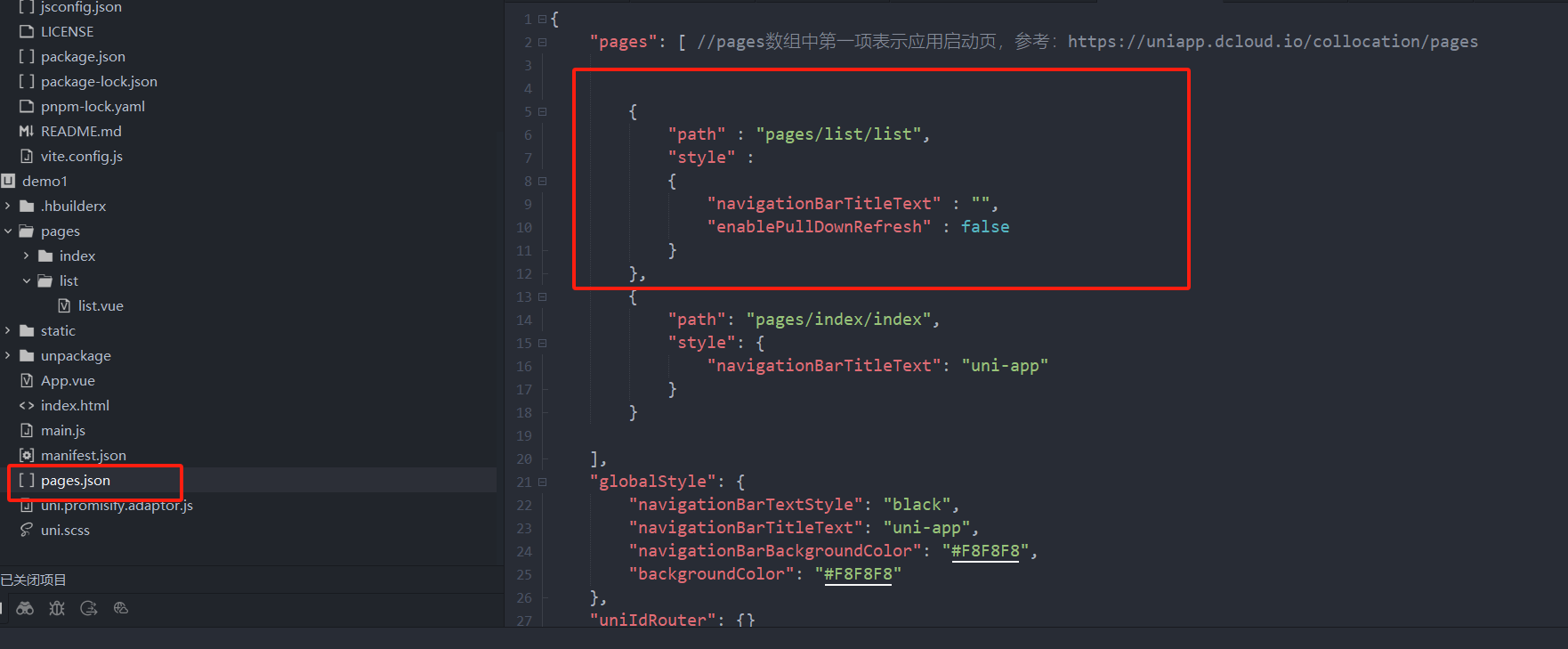
uniapp 小程序 学习(一)
利用Hbuilder 创建项目 运行到内置浏览器看效果 下载微信小程序 安装到Hbuilder 下载地址 :开发者工具默认安装 设置服务端口号 在Hbuilder中设置微信小程序 配置 找到运行设置,将微信开发者工具放入到Hbuilder中, 打开后出现 如下 bug 解…...

flow_controllers
关键点: 流控制器类型: 同步(Sync):发布操作会阻塞,直到数据被确认发送。异步(Async):发布操作非阻塞,数据发送由后台线程处理。纯同步(PureSync…...

Netty自定义协议解析
目录 自定义协议设计 实现消息解码器 实现消息编码器 自定义消息对象 配置ChannelPipeline Netty提供了强大的编解码器抽象基类,这些基类能够帮助开发者快速实现自定义协议的解析。 自定义协议设计 在实现自定义协议解析之前,需要明确协议的具体格式。例如,一个简单的…...