python selenium(4+)+chromedriver最新版 定位爬取嵌套shadow-root(open)中内容
废话不多说,直接开始
本文以无界作为本文测试案例,抓取shadow-root(open)下的内容
shadow Dom in selenium:
首先先讲一下shadow Dom in selenium 版本的区别,链接指向这里
在Selenium 4+版本 以及 chrome ver 96+中,有做出一下修改。摒弃了老版本的driver.find_element_by_css_selector。这点跟版本有关系,请自行查看目前使用的版本。

使用以及安装版本:
selenium 4.27.1 + chrome(131.0.6778.86)最新版本**
selenium pip install selenium==4.27.1即可(不指定版本也可以,目前默认安装此版本)
chromedriver 最新版本下载指向https://googlechromelabs.github.io/chrome-for-testing/#stable
由于selenium ,chrome+chromedriver 版本一直在迭代,所以也许过两年情况可能不一样了。具体更新见官方。
初入shadow-root:
先看shadow Dom in selenium提供的例子:
import osimport pytest
from selenium.webdriver import Chrome
from selenium.webdriver import Firefox
from selenium.webdriver import Remote
from selenium.webdriver.chrome.options import Options as ChromeOptions
from selenium.webdriver.common.by import Bydef test_old_code_old_chrome():"""What most people use for Shadow DOM Elements.Still works for Chrome < v96, Edge < v96, Safari"""options = ChromeOptions()options.set_capability('browserVersion', '95.0')sauce_options = {'username': os.environ["SAUCE_USERNAME"],'accessKey': os.environ["SAUCE_ACCESS_KEY"]}options.set_capability('sauce:options', sauce_options)sauce_url = "https://ondemand.us-west-1.saucelabs.com/wd/hub"driver = Remote(command_executor=sauce_url, options=options)driver.get('http://watir.com/examples/shadow_dom.html')shadow_host = driver.find_element_by_css_selector('#shadow_host')shadow_root = driver.execute_script('return arguments[0].shadowRoot', shadow_host)shadow_content = shadow_root.find_element_by_css_selector('#shadow_content')assert shadow_content.text == 'some text'driver.quit()def test_old_code_new_chrome():"""Same code as above, but in Chromium 96+.Selenium 4.0 has same error as Selenium 3.Selenium 4.1 has AttributeError for using the old find_element_* method"""driver = Chrome()driver.get('http://watir.com/examples/shadow_dom.html')shadow_host = driver.find_element_by_css_selector('#shadow_host')shadow_root = driver.execute_script('return arguments[0].shadowRoot', shadow_host)with pytest.raises(AttributeError, match="'ShadowRoot' object has no attribute 'find_element_by_css_selector'"):shadow_root.find_element_by_css_selector('#shadow_content')driver.quit()def test_fix_old_code():"""Same code as above, but using the new By class for find_element()This works in Selenium 4.1."""driver = Chrome()driver.get('http://watir.com/examples/shadow_dom.html')shadow_host = driver.find_element(By.CSS_SELECTOR, '#shadow_host')shadow_root = driver.execute_script('return arguments[0].shadowRoot', shadow_host)shadow_content = shadow_root.find_element(By.CSS_SELECTOR, '#shadow_content')assert shadow_content.text == 'some text'driver.quit()def test_recommended_code():"""Please use this code."""driver = Chrome()driver.get('http://watir.com/examples/shadow_dom.html')shadow_host = driver.find_element(By.CSS_SELECTOR, '#shadow_host')shadow_root = shadow_host.shadow_rootshadow_content = shadow_root.find_element(By.CSS_SELECTOR, '#shadow_content')assert shadow_content.text == 'some text'driver.quit()def test_firefox_workaround():"""Firefox is special."""driver = Firefox()driver.get('http://watir.com/examples/shadow_dom.html')shadow_host = driver.find_element(By.CSS_SELECTOR, '#shadow_host')children = driver.execute_script('return arguments[0].shadowRoot.children', shadow_host)shadow_content = next(child for child in children if child.get_attribute('id') == 'shadow_content')assert shadow_content.text == 'some text'driver.quit()
主要看test_recommended_code这部分代码,可以发现主要抓取some text,并assert

同理于是按照官方给的示例代码,很容易抓到“nested text”
def test_recommended_code():"""Please use this code."""driver = Chrome()driver.get('http://watir.com/examples/shadow_dom.html')shadow_host = driver.find_element(By.CSS_SELECTOR, '#shadow_host')shadow_root = shadow_host.shadow_rootnest_shadow_host = shadow_root.find_element(By.CSS_SELECTOR, '#nested_shadow_host')nest_shadow_root = nest_shadow_host.shadow_rootnest_shadow_content = nest_shadow_root.find_element(By.CSS_SELECTOR, '#nested_shadow_content')assert nest_shadow_content.text == 'nested text'driver.quit()
在控制台我们能得到同样的输出结果:


测试案例:
打开本文开头指向的无界链接,进入F12。

这里主要看下,相比前一个简单例子的区别:
- 这里可以很明显看到wujie,这个词在之后抓取其他shadow-root网页会很常见。该测试案例网站也有介绍章节。
- shadow Dom内嵌<html>,同时注意到下方的script脚本,有些网站会写到是异步脚本动态加载js,该过程需要在selenium中使用 timesleep或者until 来解决动态加载问题。
如下(异步加载js):
参考前一个例子来抓取仓库地址
import time
from selenium import webdriver
from selenium.webdriver.common.by import By# 设置 Chrome options
options = webdriver.ChromeOptions()
options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36')# 初始化 WebDriver
driver = webdriver.Chrome(options=options)
# 在页面中执行自定义 JavaScript 代码try:# 打开目标网页url = "https://wujie-micro.github.io/demo-main-vue/vue3?vue3=%2Fdemo-vue3%2Fhome"driver.get(url)time.sleep(5)# 等待页面加载并找到目标元素所在的 Shadow DOM# wait = WebDriverWait(driver, 20) # 等待最多20秒# shadow_host = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "wujie-app.wujie_iframe")))shadow_host = driver.find_element(By.CSS_SELECTOR,"wujie-app.wujie_iframe")shadow_root = shadow_host.shadow_roothtml_element = shadow_root.find_element(By.CSS_SELECTOR,'html')button = html_element.find_element(By.CSS_SELECTOR,".el-button")assert button.text == '仓库地址'except Exception as e:print("Error:", e)finally:driver.quit()
恭喜你,你会收到一份报错
 尝试F12控制台js获取,复制JS路径,控制台输出,说明没问题。
尝试F12控制台js获取,复制JS路径,控制台输出,说明没问题。

尝试在python selenium运行js
#加不加return 返回都是noneresult = driver.execute_script('return document.querySelector("#app > div.content > div > wujie-app").shadowRoot.querySelector("#app > div:nth-child(2) > div.content > p:nth-child(4) > button > span")')
result返回是none

于是就开始查这个问题查了大半天,百度 csdn,stackoverflow什么的翻了个底朝天,几乎一度快放弃了。。。。到这里以为是被反爬了,但后想了一想该网站应该不是一个商用的客户网站,不涉及到用户信息,应该不会有反爬才对,所以决定再试试。
实在不行了,打算去看看chromedriver的开源代码查查到底为什么,查之前抱着试一试的态度在chromedriver的 issue中搜我的问题竟然找到了解决办法!
只能说十分感谢该老哥!链接指向
感兴趣的可以去看源码,我自己后面去看了下里面这个IsNodeReachable,这里就不贴图分析了。

问题大概是 Shadow DOM 的封装性导致节点在 Chromedriver 的验证中被误判为不可达。
所以解决思路: 通过修改 Shadow DOM 节点的行为(伪装其父节点为全局文档),绕过验证逻辑。
于是修改后代码如下:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By# 设置 Chrome options
options = webdriver.ChromeOptions()
options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36')# 初始化 WebDriver
driver = webdriver.Chrome(options=options)
# 在页面中执行自定义 JavaScript 代码try:# 打开目标网页url = "https://wujie-micro.github.io/demo-main-vue/vue3?vue3=%2Fdemo-vue3%2Fhome"driver.get(url)time.sleep(5)driver.execute_script("""Object.defineProperty(window.document.querySelector('wujie-app').shadowRoot.firstElementChild, "parentNode", {enumerable: true,configurable: true,get: () => window.document,});""")# 等待页面加载并找到目标元素所在的 Shadow DOM# wait = WebDriverWait(driver, 20) # 等待最多20秒# shadow_host = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "wujie-app.wujie_iframe")))#方法1,直接复制js路径,更简单result = driver.execute_script('return document.querySelector("#app > div.content > div > wujie-app").shadowRoot.querySelector("#app > div:nth-child(2) > div.content > p:nth-child(4) > button > span")')#方法2 一步步的,我个人感觉这样更清晰,对于初学,我建议这样层层递进,并学会# find_element(By.CSS_SELECTOR 的使用shadow_host = driver.find_element(By.CSS_SELECTOR,"wujie-app.wujie_iframe")shadow_root = shadow_host.shadow_roothtml_element = shadow_root.find_element(By.CSS_SELECTOR,'html')button = html_element.find_element(By.CSS_SELECTOR,".el-button")#方法2 Ansassert button.text == '仓库地址'#方法1 Ansassert result.text == '仓库地址'print(button.text)print(result.text)
except Exception as e:print("Error:", e)finally:driver.quit()
最后成功拿到 仓库地址(好的,现在就偷仓库东西去了)

课后作业!
试试抓取 某企鹅下的 某moba手游论坛下的用户名,日期!
实验链接:彻底疯狂!
I got it ,代码和上述大差不差

相关文章:
python selenium(4+)+chromedriver最新版 定位爬取嵌套shadow-root(open)中内容
废话不多说,直接开始 本文以无界作为本文测试案例,抓取shadow-root(open)下的内容 shadow Dom in selenium: 首先先讲一下shadow Dom in selenium 版本的区别,链接指向这里 在Selenium 4版本 以及 chrom…...
:useCallback记忆函数的使用)
React基础教程(11):useCallback记忆函数的使用
11、useCallback记忆函数 防止因为组件重新渲染,导致方法被重新创建,起到缓存作用,只有第二个参数变化了,才重新声明一次。 示例代码: import {useCallback, useState} from "react";const App = () =>...

arp-scan 移植到嵌入式 Linux 系统是一个涉及多个步骤的过程
将 arp-scan 移植到嵌入式 Linux 系统是一个涉及多个步骤的过程。arp-scan 是一个用于发送 ARP 请求以发现网络上设备的工具,它依赖于一些标准的 Linux 库和工具。以下是将 arp-scan 移植到嵌入式 Linux 系统的基本步骤: 1. 获取 arp-scan 源码 首先&a…...

【Linux】常用命令一
声明:以下内容均学习自《Linux就该这么学》一书。 Linux中的shell是一种命令行工具,它充当的作用是人与内核(硬件)之间的翻译官。 大多数Linux系统默认使用的终端是Bash解释器。 1、echo 用于在终端输出字符串或变量提取后的值。 echo "字符串…...

在鲲鹏麒麟服务器上部署MySQL主从集群
因项目需求需要部署主从MySQL集群,继续采用上次的部署的MySQL镜像arm64v8/mysql:latest,版本信息为v8.1.0。计划部署服务器192.168.31.100和192.168.31.101 部署MySQL主节点 在192.168.31.100上先创建好/data/docker/mysql/data和/data/docker/mysql/l…...
Siknhorn算法介绍
SiknHorn算法是一个快速求解离散优化问题的经典算法,特别适用于计算离散分布之间的**最优传输(Optimal Transport)**距离; 最优传输问题介绍 计算两个概率分布 P 和 Q 之间的传输成本,通常表示为: 是传输…...

群控系统服务端开发模式-应用开发-邮箱短信通道功能开发
邮箱短信通道主要是将邮箱及短信做归属的。具体见下图: 一、创建表 1、语句 CREATE TABLE cluster_control.nc_param_emailsms (id int(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 编号,email_id varchar(120) CHARACTER SET utf8 COLLATE utf8_general_ci NO…...

[docker中首次配置git环境]
11月没写东西,12月初赶紧水一篇。 刚开始搭建docker服务器时,网上找一堆指令配置好git后,再次新建容器后忘记怎么配了,,这次记录下。 一、git ssh指令法,该方法不用每次提交时输入密码 前期准备࿰…...

书生浦语·第四期作业合集
目录 1. Linux基础知识 1.1-Linux基础知识 1.在终端通过ssh 端口映射连接开发机 2. 创建helloworld.py 3.安装相关包并运行 4.端口映射并访问相关网页...

5G学习笔记之PRACH
即使是阴天,也要记得出门晒太阳哦 目录 1. 概述 2. PRACH Preamble 3. PRACH Preamble 类型 3.1 长前导码 3.2 短前导码 3.3 前导码格式与小区覆盖 4. PRACH时频资源 4.1 小区所有可用PRACH资源 4.2 SSB和RACH的关系 4.3 PRACH时频资源配置 1. 概述 随机接入…...

Ubuntu24.04配置DINO-Tracker
一、引言 记录 Ubuntu 配置的第一个代码过程 二、更改conda虚拟环境的默认安装路径 鉴于不久前由于磁盘空间不足引发的重装系统的惨痛经历,在新系统装好后当然要先更改虚拟环境的默认安装路径。 输入指令: conda info可能因为我原本就没有把 Anacod…...

抓包之查看websocket内容
写在前面 本文看下websocket抓包相关内容。 1:正文 websocket基础环境搭建参考这篇文章。 启动后,先看chrome的network抓包,这里我们直接使用is:running来过滤出websocket的请求: 可以清晰的看到发送的内容以及响应的内容。在…...

【Leetcode Top 100】21. 合并两个有序链表
问题背景 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 数据约束 两个链表的节点数目范围是 [ 0 , 50 ] [0, 50] [0,50] − 100 ≤ N o d e . v a l ≤ 100 -100 \le Node.val \le 100 −100≤Node.val≤100 l 1 l_1 …...

账本模型
05-账本模型 1 账本模型 1.1 传统线性增长模型 传统的 MySQL 等系统采用线性增长的日志模型,通过一个 Leader 和多个 Follower 进行状态同步。这种方式有单点的带宽瓶颈问题。 1.2 区块链共享账本模型 共享账本:树形增长。在去中心化网络中,…...

openwrt利用nftables在校园网环境下开启nat6 (ipv6 nat)
年初写过一篇openwrt在校园网环境下开启ipv6 nat的文章,利用ip6tables控制ipv6的流量。然而从OpenWrt22版本开始,系统内置的防火墙变为nftables,因此配置方法有所改变。本文主要参考了OpenWRT使用nftables实现IPv6 NAT 这篇文章。 友情提示 …...

24.12.02 Element
import { createApp } from vue // 引入elementPlus js库 css库 import ElementPlus from element-plus import element-plus/dist/index.css //中文语言包 import zhCn from element-plus/es/locale/lang/zh-cn //图标库 import * as ElementPlusIconsVue from element-plus/i…...
记录QT5迁移到QT6.8上的一些问题
经常看到有的同学说网上的教程都是假的,巴拉巴拉,看看人家发布时间,Qt官方的API都会有所变动,多搜索,多总结,再修改记录。 下次遇到问题多这样搜索 QT 4/5/6 xxx document,对比一下就知道…...

清理Linux/CentOS7根目录的思路
在使用Linux服务器过程中,经常会遇到磁盘空间不足的问题,好多应用默认安装在根目录下,记录一下如何找到问题所在,清理根目录(/) 1. 检查空间使用情况 1.1 查看分区占用: df -h输出࿱…...
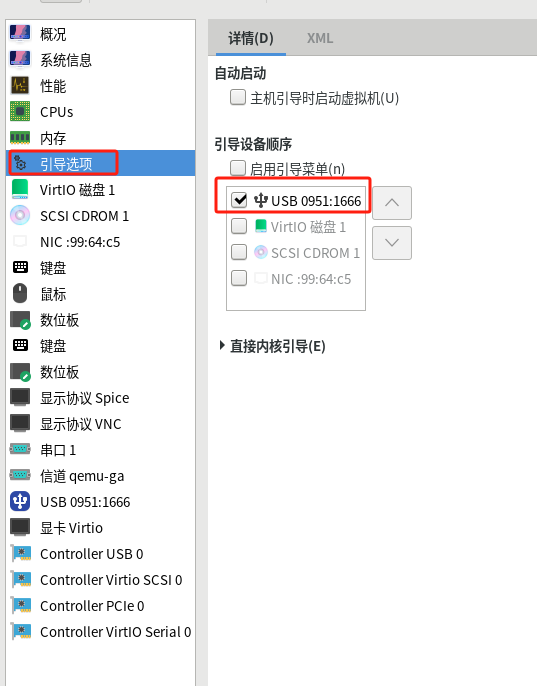
【LInux】kvm添加u盘启动引导
前提:要有一个u盘的启动盘 1、查看u盘设备信息 # lsusb ....忽略其他设备信息,查看到u盘设备 Bus 005 Device 005: ID 0951:1666 Kingston Technology DataTraveler 100 G3/G4/SE9 G2## 主要记住ID 0951:1666确认id为ID 0951:1666 2、修改配置文件 如…...
.net XSSFWorkbook 读取/写入 指定单元格的内容
方法如下: using NPOI.SS.Formula.Functions;using NPOI.SS.UserModel;using OfficeOpenXml.FormulaParsing.Excel.Functions.DateTime;using OfficeOpenXml.FormulaParsing.Excel.Functions.Numeric;/// <summary>/// 读取Excel指定单元格内容/// </summa…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...

k8s从入门到放弃之HPA控制器
k8s从入门到放弃之HPA控制器 Kubernetes中的Horizontal Pod Autoscaler (HPA)控制器是一种用于自动扩展部署、副本集或复制控制器中Pod数量的机制。它可以根据观察到的CPU利用率(或其他自定义指标)来调整这些对象的规模,从而帮助应用程序在负…...