Hive 在工作中的调优总结
总结了一下在以往工作中,对于Hive SQL调优的一些实际应用,是日常积累的一些优化技巧,如有出入,欢迎在评论区留言探讨~
EXPLAIN 查看执行计划
建表优化
分区
- 分区表基本操作,partitioned
- 二级分区
- 动态分区
分桶
- 分桶表基本操作,clustered
- 分桶表主要是抽样查询,找出具有代表性的结果
选择合适的文件格式和压缩格式
- LZO,拉兹罗
- Snappy
- 压缩速度快,压缩比高
HiveSQL语法优化
单表查询优化
-
列裁剪和分区裁剪,全表和全列扫描效率都很差,生产环境绝对不要使用
SELECT *,所谓列裁剪就是在查询时只读取需要的列,分区裁剪就是只读取需要的分区- 与列裁剪优化相关的配置项是
hive.optimize.cp,默认是true - 与分区裁剪优化相关的则是
hive.optimize.pruner,默认是true - 在
HiveSQL解析阶段对应的则是ColumnPruner逻辑优化器
- 与列裁剪优化相关的配置项是
-
Group By 配置调整,
map阶段会把同一个key发给一个reduce,当一个key过大时就倾斜了,可以开启map端预聚合,可以有效减少shuffle数据量并# 是否在map端聚合,默认为true set hive.map.aggr = true;# 在map端聚合的条数 set hive.groupby.mapaggr.checkintervel = 100000;# 在数据倾斜的时候进行均衡负载(默认是false),开启后会有 两个`mr任务`。 # 当选项设定为true时,第一个 `mr任务` 会将map输出的结果随机分配到`reduce`, # 每个`reduce`会随机分布到`reduce`上,这样的处理结果是会使相同的`group by key`分到不同的`reduce`上。 # 第二个 `mr任务` 再根据预处理的结果按`group by key`分到`reduce`上, # 保证相同`group by key`的数据分到同一个`reduce`上。# *切记!!!* # 这样能解决数据倾斜,但是不能让运行速度更快 # 在数据量小的时候,开始数据倾斜负载均衡可能反而会导致时间变长 # 配置项毕竟是死的,单纯靠它有时不能根本上解决问题 # 因此还是建议自行了解数据倾斜的细节,并优化查询语句 set hive.groupby.skewindata = true; -
Vectorization,矢量计算技术,通过设置批处理的增量大小为1024行单次来达到比单行单次更好的效率
# 开启矢量计算 set hive.vectorized.execution.enabled = true;# 在reduce阶段开始矢量计算 set hive.vectorized.execution.reduce.enabled = true; -
多重模式,一次读取多次插入,同一张表的插入操作优化成先
from table再insert -
in/exists或者join用
left semi join代替(为什么替代扩展一下~)
多表查询优化
-
CBO优化,成本优化器,代价最小的执行计划就是最好的执行计划
- join的时候表的顺序关系,前面的表都会被加载到内存中,后面的表进行磁盘扫描
- 通过
hive.cbo.enable,自动优化hivesql中多个join的执行顺序 - 可以通过查询一下参数,这些一般都是true,无需修改
set hive.cbo.enable = true; set hive.compute.query.using.stats = true; set hive.stats.fetch.column.stats = true; set hive.stats.fetch.partition.stats = true; -
谓词下推(非常关键的一个优化),将
sql语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量,
在关系型数据库如MySQL中,也有谓词下推(Predicate Pushdown,PPD)的概念,
它就是将sql语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量# 这个设置是默认开启的 # 如果关闭了但是cbo开启,那么关闭依然不会生效 # 因为cbo会自动使用更为高级的优化计划 # 与它对应的逻辑优化器是PredicatePushDown # 该优化器就是将OperatorTree中的FilterOperator向上提 set hive.optimize.pdd = true;# 举个例子 # 对forum_topic做过滤的where语句写在子查询内部,而不是外部 select a.uid,a.event_type,b.topic_id,b.title from calendar_record_log a left outer join (select uid,topic_id,title from forum_topicwhere pt_date = 20220108 and length(content) >= 100 ) b on a.uid = b.uid where a.pt_date = 20220108 and status = 0; -
Map Join,
map join是指将join操作两方中比较小的表直接分发到各个map进程的内存中,在map中进行join的操作。
map join特别适合大小表join的情况,Hive会将build table和probe table在map端直接完成join过程,消灭了reduce,减少shuffle,所以会减少开销set hive.auto.convert.join = true,配置开启,默认是true- 注意!!! 如果执行
小表join大表,小表作为主连接的主表,所有数据都要写出去,此时会走reduce阶段,mapjoin会失效 大表join小表不受影响,上一条的原因主要是因为小表join大表的时候,map阶段不知道reduce的结果其他reduce是否有,- 所以必须在最后
reduce聚合的时候再处理,就产生了reduce的开销
# 举个例子 # 在最常见的`hash join`方法中,一般总有一张相对小的表和一张相对大的表, # 小表叫`build table`,大表叫`probe table` # Hive在解析带join的SQL语句时,会默认将最后一个表作为`probe table`, # 将前面的表作为`build table`并试图将它们读进内存 # 如果表顺序写反,`probe table`在前面,引发`OOM(内存不足)`的风险就高了 # 在维度建模数据仓库中,事实表就是`probe table`,维度表就是`build table` # 假设现在要将日历记录事实表和记录项编码维度表来`join` select a.event_type,a.event_code,a.event_desc,b.upload_time from calendar_event_code a inner join (select event_type,upload_time from calendar_record_logwhere pt_date = 20220108 ) b on a.event_type = b.event_type; -
Map Join,大表和大表的
MapReduce任务,可以使用SMB Join- 直接join耗时会很长,但是根据某字段分桶后,两个大表每一个桶就是一个小文件,两个表的每个小文件的分桶字段都应该能够一一对应(hash值取模的结果)
- 总结就是分而治之,注意两个大表的分桶字段和数量都应该保持一致
set hive.optimize.bucketmapjoin = true; set hive.optimeize.bucketmapjoin.sortedmerge = true; hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat; -
多表join时key相同,这种情况会将多个
join合并为一个mr 任务来处理# 举个例子 # 如果下面两个join的条件不相同 # 比如改成a.event_code = c.event_code # 就会拆成两个MR job计算 select a.event_type,a.event_code,a.event_desc,b.upload_time from calendar_event_code a inner join (select event_type,upload_time from calendar_record_logwhere pt_date = 20220108 ) b on a.event_type = b.event_type inner join (select event_type,upload_time from calendar_record_log_2where pt_date = 20220108 ) c on a.event_type = c.event_type; -
笛卡尔积,在生产环境中严禁使用
其他查询优化
-
Sort By 代替 Order By,HiveQL中的
order by与其他sql方言中的功能一样,就是将结果按某字段全局排序,这会导致所有map端数据都进入一个reducer中,
在数据量大时可能会长时间计算不完。如果使用sort by,那么还是会视情况启动多个reducer进行排序,并且保证每个reducer内局部有序。
为了控制map端数据分配到reducer的key,往往还要配合distribute by一同使用,如果不加distribute by的话,map端数据就会随机分配到reducer# 举个例子 select uid,upload_time,event_type,record_data from calendar_record_log where pt_date >= 20220108 and pt_date <= 20220131 distribute by uid sort by upload_time desc,event_type desc; -
Group By代替Distinct,当要统计某一列的去重数时,如果数据量很大,
count(distinct)就会非常慢,原因与order by类似,
count(distinct)逻辑只会有很少的reducer来处理。但是这样写会启动两个mr任务(单纯distinct只会启动一个),
所以要确保数据量大到启动mr任务的overhead远小于计算耗时,才考虑这种方法,当数据集很小或者key的倾斜比较明显时,group by还可能会比distinct慢
数据倾斜
注意要和数据过量的情况区分开,数据倾斜是大部分任务都已经执行完毕,但是某一个任务或者少数几个任务,一直未能完成,甚至执行失败,
而数据过量,是大部分任务都执行的很慢,这种情况需要通过扩充执行资源的方式来加快速度,大数据编程不怕数据量大,就怕数据倾斜,一旦数据倾斜,严重影响效率
单表携带了 Group By 字段的查询
- 任务中存在
group by操作,同时聚合函数为count或sum,单个key导致的数据倾斜可以这样通过设置开启map端预聚合参数的方式来处理# 是否在map端聚合,默认为true set hive.map.aggr = true;# 在map端聚合的条数 set hive.groupby.mapaggr.checkintervel = 100000;# 有数据倾斜的时候开启负载均衡,这样会生成两个mr任务 set hive.groupby.skewindata = true; - 任务中存在
group by操作,同时聚合函数为count或sum,多个key导致的数据倾斜可以通过增加reduce的数量来处理- 增加分区可以减少不同分区之间的数据量差距,而且增加的分区时候不能是之前分区数量的倍数,不然会导致取模结果相同继续分在相同分区
- 第一种修改方式
# 每个reduce处理的数量 set hive.exec.reduce.bytes.per.reducer = 256000000;# 每个任务最大的reduce数量 set hive.exec.reducers.max = 1009;# 计算reducer数的公式,根据任务的需要调整每个任务最大的reduce数量 N = min(设置的最大数,总数量数/每个reduce处理的数量)- 第二种修改方式
# 在hadoop的mapred-default.xml文件中修改 set mapreduce.job.reduces = 15;
两表或多表的 join 关联时,其中一个表较小,但是 key 集中
- 设置参数增加
map数量# join的key对应记录条数超过该数量,会进行分拆 set hive.skewjoin.key = 1000;# 并设置该参数为true,默认是false set hive.optimize.skewjoin = true;# 上面的参数如果开启了会将计算数量超过阈值的key写进临时文件,再启动另外一个任务做map join # 可以通过设置这个参数,控制第二个任务的mapper数量,默认10000 set hive.skewjoin.mapjoin.map.tasks = 10000; - 使用
mapjoin,减少reduce从根本上解决数据倾斜,参考HiveSQL语法优化 -> 多表查询优化 -> Map Join,大表和大表的MapReduce任务,SMB Join
两表或多表的 join 关联时,有 Null值 或 无意义值
这种情况很常见,比如当事实表是日志类数据时,往往会有一些项没有记录到,我们视情况会将它置为null,或者空字符串、-1等,
如果缺失的项很多,在做join时这些空值就会非常集中,拖累进度,因此,若不需要空值数据,就提前写where语句过滤掉,
需要保留的话,将空值key用随机方式打散,例如将用户ID为null的记录随机改为负值:
select a.uid,a.event_type,b.nickname,b.age
from (select (case when uid is null then cast(rand()*-10240 as int) else uid end) as uid,event_type from calendar_record_logwhere pt_date >= 20220108
) a left outer join (select uid,nickname,age from user_info where status = 4
) b on a.uid = b.uid;
两表或多表的 join 关联时,数据类型不统一
比如int类型和string类型进行关联,关联时候以小类型作为分区,这里int、string会到一个reduceTask中,如果数据量多,会造成数据倾斜
# 可以通过转换为同一的类型来处理
cast(user.id as string)
单独处理倾斜key
这其实是上面处理空值方法的拓展,不过倾斜的key变成了有意义的,一般来讲倾斜的key都很少,我们可以将它们抽样出来,
对应的行单独存入临时表中,然后打上一个较小的随机数前缀(比如0~9),最后再进行聚合
Hive Job 优化
Hive Map 优化
Map数量多少的影响
- Map数过大
map阶段输出文件太小,产生大量小文件- 初始化和创建
map的开销很大
- Map数太小
- 文件处理或查询并发度小,
Job执行时间过长 - 大量作业时,容易堵塞集群
- 文件处理或查询并发度小,
控制Map数的原则
根据实际情况,控制map数量需要遵循两个原则
- 第一是使大数据量利用合适的
map数 - 第二是使单个
map任务处理合适的数据量
复杂文件适当增加Map数
- 当
input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加map数,来使得每个map处理的数据量减少,从而提高任务的执行效率 - 那么如何增加
map的数量呢?在map阶段,文件先被切分成split块,而后每一个split切片对应一个Mapper任务,
FileInputFormat这个类先对输入文件进行逻辑上的划分,以128m为单位,将原始数据从逻辑上分割成若干个split,每个split切片对应一个mapper任务,
所以说减少切片的大小就可增加map数量 - 可以依据公式计算
computeSliteSize(Math.max(minSize, Math.min(maxSize, blockSize))) = blockSize = 128m - 执行语句:
set mapreduce.input.fileinputformat.split.maxsize = 100;
小文件进行合并减少Map数
为什么要进行小文件合并?因为如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完成,
而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费,同时可执行的map数是受限的
两种方式合并小文件
- 在
Map执行前合并小文件,减少map数量// 每个Map最大输入大小(这个值决定了合并后文件的数量) set mapred.max.split.size = 256000000;// 一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并) set mapred.min.split.size.per.node = 100000000;// 一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并) set mapred.min.split.size.per.rack = 100000000;// 执行Map前进行小文件合并 set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; - 在
Map-Reduce任务执行结束时合并小文件,减少小文件输出// 设置map端输出进行合并,默认为true set hive.merge.mapfiles = true;// 设置reduce端输出进行合并,默认为false set hive.merge.mapredfiles = true;// 设置合并文件的大小,默认是256 set hive.merge.size.per.task = 256 * 1000 * 1000;// 当输出文件的平均大小小于该值时,启动一个独立的`MapReduce任务`进行文件`merge`。 set hive.merge.smallfiles.avgsize = 16000000;
Map端预聚合减少Map数量
- 相当于在
map端执行combiner,执行命令:set hive.map.aggr = true; combiners是对map端的数据进行适当的聚合,其好处是减少了从map端到reduce端的数据传输量- 其作用的本质,是将
map计算的结果进行二次聚合,使Key-Value<List>中List的数据量变小,从而达到减少数据量的目的
推测执行
- 在分布式集群环境下,因为程序Bug(包括Hadoop本身的bug),负载不均衡或者资源分布不均等原因,会造成同一个作业的多个任务之间运行速度不一致,
有些任务的运行速度可能明显慢于其他任务(比如一个作业的某个任务进度只有50%,而其他所有任务已经运行完毕),则这些任务会拖慢作业的整体执行进度 - Hadoop采用了
推测执行(Speculative Execution)机制,它根据一定的法则推测出拖后腿的任务,并为这样的任务启动一个备份任务,
让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果 - 执行命令:
set mapred.reduce.tasks.speculative.execution = true; # 默认是true - 当然,如果用户对于运行时的偏差非常敏感的话,那么可以将这些功能关闭掉,如果用户因为输入数据量很大而需要执行长时间的
map task或者reduce task的话,
那么启动推测执行造成的浪费是非常巨大的
合理控制Map数量的实际案例
假设一个SQL任务:
SELECT COUNT(1)
FROM fx67ll_alarm_count_copy
WHERE alarm_date = "2021-01-08";
该任务的输入目录inputdir是:/group/fx67ll_data/fx67ll_data_etl/date/fx67ll_alarm_count_copy/alarm_date=2021-01-08,共有194个文件,
其中很多是远远小于128m的小文件,总大小约9G,正常执行会用194个Map任务,map总共消耗的计算资源:SLOTS_MILLIS_MAPS= 610,023
通过在Map执行前合并小文件,减少Map数
# 前面三个参数确定合并文件块的大小
# 大于文件块大小128m的,按照128m来分隔
# 小于128m,大于100m的,按照100m来分隔
# 把那些小于100m的(包括小文件和分隔大文件剩下的),进行合并,最终生成了74个块
set mapred.max.split.size=100000000;
set mapred.min.split.size.per.node=100000000;
set mapred.min.split.size.per.rack=100000000;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
合并后,用了74个map任务,map消耗的计算资源:SLOTS_MILLIS_MAPS= 323,098,对于这个简单SQL任务,执行时间上可能差不多,但节省了一半的计算资源
再假设这样一个SQL任务:
SELECT data_fx67ll,
COUNT(1),
COUNT(DISTINCT id),
SUM(CASE WHEN …),
SUM(CASE WHEN …),
SUM(…)
FROM fx67ll_device_info_zs
GROUP data_fx67ll
如果表fx67ll_device_info_zs只有一个文件,大小为120m,但包含几千万的记录,如果用1个map去完成这个任务,肯定是比较耗时的,
这种情况下,我们要考虑将这一个文件合理的拆分成多个
增加Reduce数量,来增加Map数量
set mapred.reduce.tasks=10;
CREATE TABLE fx67ll_device_info_zs_temp
AS
SELECT *
FROM fx67ll_device_info_zs
DISTRIBUTE BY RAND(123);
这样会将fx67ll_device_info_zs表的记录,随机的分散到包含10个文件的fx67ll_device_info_zs_temp表中,
再用fx67ll_device_info_zs_temp代替上面sql中的fx67ll_device_info_zs表,
则会用10个map任务去完成,每个map任务处理大于12m(几百万记录)的数据,效率肯定会好很多
Hive Reduce 优化
Reduce数量多少的影响
- 同
map一样,启动和初始化reduce也会消耗时间和资源 - 另外,有多少个
reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题
控制Reduce数的原则
和map一样,控制reduce数量需要遵循两个原则
- 第一是使大数据量利用合适的
reduce数 - 第二是使单个
reduce任务处理合适的数据量
Hive自己如何确定Reduce数
reduce个数的设定极大影响任务执行效率,不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个设定:
# 每个reduce任务处理的数据量,默认为 1000^3=1G
hive.exec.reducers.bytes.per.reducer# 每个任务最大的reduce数,默认为999
hive.exec.reducers.max
计算reducer数的公式很简单N = min(参数2,总输入数据量 / 参数1)
即,如果reduce的输入(map的输出)总大小不超过1G,那么只会有一个reduce任务
举个例子:
SELECT alarm_date,COUNT(1)
FROM fx67ll_alarm_count_copy
WHERE alarm_date = "2021-01-08"
GROUP BY alarm_date;
该任务的输入目录inputdir是:/group/fx67ll_data/fx67ll_data_etl/date/fx67ll_alarm_count_copy/alarm_date=2021-01-08,
总大小为9G多,因此这句有10个reduce
如何调整Reduce数量
注意!!!实际开发中,reduce的个数一般通过程序自动推定,而不人为干涉,因为人为控制的话,如果使用不当很容易造成结果不准确,且降低执行效率
- 通过调整每个
reduce任务处理的数据量来调整reduce个数,处理的数据量少了,任务数就多了# 设置每个reduce任务处理的数据量500M,默认是1G set hive.exec.reducers.bytes.per.reducer = 500000000;SELECT alarm_date,COUNT(1) FROM fx67ll_alarm_count_copy WHERE alarm_date = "2021-01-08" GROUP BY alarm_date;这次有20个reduce - 直接调整每个
Job中的最大reduce数量,过于简单粗暴,慎用,尽量不要,虽然设置了reduce的个数看起来好像执行速度变快了,但是实际并不是这样的# 设置每个任务最大的reduce数为15个,默认为999 set mapred.reduce.tasks = 15;SELECT alarm_date,COUNT(1) FROM fx67ll_alarm_count_copy WHERE alarm_date = "2021-01-08" GROUP BY alarm_date;这次有15个reduce
推测执行
参考map优化的最后一项
什么情况下只有一个Reduce
很多时候你会发现任务中不管数据量多大,不管你有没有设置调整reduce个数的参数,任务中一直都只有一个reduce任务,
其实只有一个reduce任务的情况,除了数据量小于hive.exec.reducers.bytes.per.reducer参数值的情况外,还有以下原因:
- 没有
Group By的汇总,例如:SELECT alarm_date,COUNT(1) FROM fx67ll_alarm_count_copy WHERE alarm_date = "2021-01-08" GROUP BY alarm_date;写成SELECT COUNT(1) FROM fx67ll_alarm_count_copy WHERE alarm_date = "2021-01-08";注意避免这样情况的发生 - 用了
Order by排序,因为它会对数据进行全局排序,所以数据量特别大的时候效率非常低,尽量避免 - 有笛卡尔积,生产环境必须严格避免
Hive 任务整体优化
Fetch抓取
Fetch抓取是指Hive在某些情况的查询可以不必使用mr 任务,例如在执行一个简单的select * from XX时,我们只需要简单的进行抓取对应目录下的数据即可。
在hive-default.xml.template中,hive.fetch.task.conversion(默认是morn),老版本中默认是minimal。
该属性为morn时,在全局查找,字段查找,limit查找等都不走mr 任务
本地模式
Hive也可以不将任务提交到集群进行运算,而是直接在一台节点上处理,因为消除了提交到集群的overhead,所以比较适合数据量很小,且逻辑不复杂的任务。
设置hive.exec.mode.local.auto为true可以开启本地模式,但任务的输入数据总量必须小于hive.exec.mode.local.auto.inputbytes.max(默认值128MB),
且mapper数必须小于hive.exec.mode.local.auto.tasks.max(默认值4),reducer数必须为0或1,才会真正用本地模式执行
并行执行
Hive中互相没有依赖关系的job间是可以并行执行的,最典型的就是多个子查询union all,
在集群资源相对充足的情况下,可以开启并行执行,即将参数hive.exec.parallel设为true,
另外hive.exec.parallel.thread.number可以设定并行执行的线程数,默认为8,一般都够用。
注意!!!没资源无法并行,且数据量小时开启可能还没不开启快,所以建议数据量大时开启
严格模式
要开启严格模式,需要将参数hive.mapred.mode设为strict。
所谓严格模式,就是强制不允许用户执行3种有风险的sql语句,一旦执行会直接失败,这3种语句是:
- 查询分区表时不限定分区列的语句
- 两表join产生了笛卡尔积的语句
- 用order by来排序但没有指定limit的语句
JVM重用
- 主要用于处理小文件过多的时候
- 在
mr 任务中,默认是每执行一个task就启动一个JVM,如果task非常小而碎,那么JVM启动和关闭的耗时就会很长 - 可以通过调节参数
mapred.job.reuse.jvm.num.tasks来重用 - 例如将这个参数设成5,那么就代表同一个
mr 任务中顺序执行的5个task可以重复使用一个JVM,减少启动和关闭的开销,但它对不同mr 任务中的task无效
启用压缩
压缩job的中间结果数据和输出数据,可以用少量CPU时间节省很多空间,压缩方式一般选择Snappy,效率最高。
要启用中间压缩,需要设定hive.exec.compress.intermediate为true,
同时指定压缩方式hive.intermediate.compression.codec为org.apache.hadoop.io.compress.SnappyCodec。
另外,参数hive.intermediate.compression.type可以选择对块(BLOCK)还是记录(RECORD)压缩,BLOCK的压缩率比较高。
输出压缩的配置基本相同,打开hive.exec.compress.output即可
采用合适的存储格式
- 在Hive SQL的
create table语句中,可以使用stored as ...指定表的存储格式。
Hive表支持的存储格式有TextFile、SequenceFile、RCFile、Avro、ORC、Parquet等。
存储格式一般需要根据业务进行选择,在我们的实操中,绝大多数表都采用TextFile与Parquet两种存储格式之一。 TextFile是最简单的存储格式,它是纯文本记录,也是Hive的默认格式,虽然它的磁盘开销比较大,查询效率也低,但它更多地是作为跳板来使用。RCFile、ORC、Parquet等格式的表都不能由文件直接导入数据,必须由TextFile来做中转。Parquet和ORC都是Apache旗下的开源列式存储格式。列式存储比起传统的行式存储更适合批量OLAP查询,并且也支持更好的压缩和编码。- 我们选择
Parquet的原因主要是它支持Impala查询引擎,并且我们对update、delete和事务性操作需求很低。
Hive的小文件
什么情况下会产生小文件?
- 动态分区插入数据,产生大量的小文件,从而导致map数量剧增
- reduce数量越多,小文件也越多,有多少个reduce,就会有多少个输出文件,如果生成了很多小文件,那这些小文件作为下一次任务的输入
- 数据源本身就包含大量的小文件
小文件有什么样的危害?
- 从Hive的角度看,小文件会开很多map,一个map开一个java虚拟机jvm去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重影响性能
- 在hdfs中,每个小文件对象约占150byte,如果小文件过多会占用大量内存,这样NameNode内存容量严重制约了集群的扩展
- 每个hdfs上的文件,会消耗128字节记录其meta信息,所以大量小文件会占用大量内存
如何避免小文件带来的危害?
从小文件产生的途经就可以从源头上控制小文件数量
- 使用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件
- 减少reduce的数量(可以使用参数进行控制)
- 少用动态分区,用时记得按distribute by分区
对于已有的小文件
- 使用hadoop archive命令把小文件进行归档,采用archive命令不会减少文件存储大小,只会压缩NameNode的空间使用
- 重建表,建表时减少reduce数量
我是 fx67ll.com,如果您发现本文有什么错误,欢迎在评论区讨论指正,感谢您的阅读!
如果您喜欢这篇文章,欢迎访问我的 本文github仓库地址,为我点一颗Star,Thanks~ 😃
转发请注明参考文章地址,非常感谢!!!
相关文章:

Hive 在工作中的调优总结
总结了一下在以往工作中,对于Hive SQL调优的一些实际应用,是日常积累的一些优化技巧,如有出入,欢迎在评论区留言探讨~ EXPLAIN 查看执行计划 建表优化 分区 分区表基本操作,partitioned二级分区动态分区 分桶 分…...

每天一道大厂SQL题【Day09】充值日志SQL实战
每天一道大厂SQL题【Day09】充值日志SQL实战 大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题&#…...

MATLAB 遗传算法
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...

探讨 Java 中 valueOf 和 parseInt 的区别
前言 在编程中,遇到类型转换,好像会经常用到 parseInt 和 valueOf,当然这里只拿 Integer 类型进行陈述,其他类型也是雷同的; 想必有读者也跟我一样,经常交叉使用这两个方法,但却不知道这两者到…...
JSON学习笔记
♥课程链接:【狂神说Java】一小时掌握JSON_哔哩哔哩_bilibili配套的当然还要学习ajax不管是前端后端,感觉这部分内容是必须的,不然真的做项目的时候云里雾里。总体json的内容不多,具体就:1. 列表、对象等语法格式2. js…...
家政服务小程序实战教程07-轮播图组件
小程序中首页一般显示轮播图的功能,点击轮播图会跳转到具体的一篇文章或者是产品,本篇我们就介绍一下轮播图功能的开发 01 设计数据源 我们轮播图组件需要两个字段,一个是展示的图片,一个是跳转页面传入的参数。打开数据源&…...

MySQL之索引创建、删除、唯一索引、普通索引、及命名规则、注意事项
一、MySQL 索引 定义 索引是一个数据结构,用于加速数据库表中数据的查询。索引存储了一些数据表中的列值,以及这些列值在数据表中的位置,这样就可以通过索引来快速查找到数据表中的某一行数据。 MySQL 支持多种索引类型,包括普通…...

【C++设计模式】学习笔记(3):策略模式 Strategy
目录 简介动机(Motivation)模式定义结构(Structure)要点总结笔记结语简介 Hello! 非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出~ ଘ(੭ˊᵕˋ)੭ 昵称:海轰 标签:程序猿|C++选手|学生 简介:因C语言结识编程,随后转入计算机专业,获得过国家奖学金…...
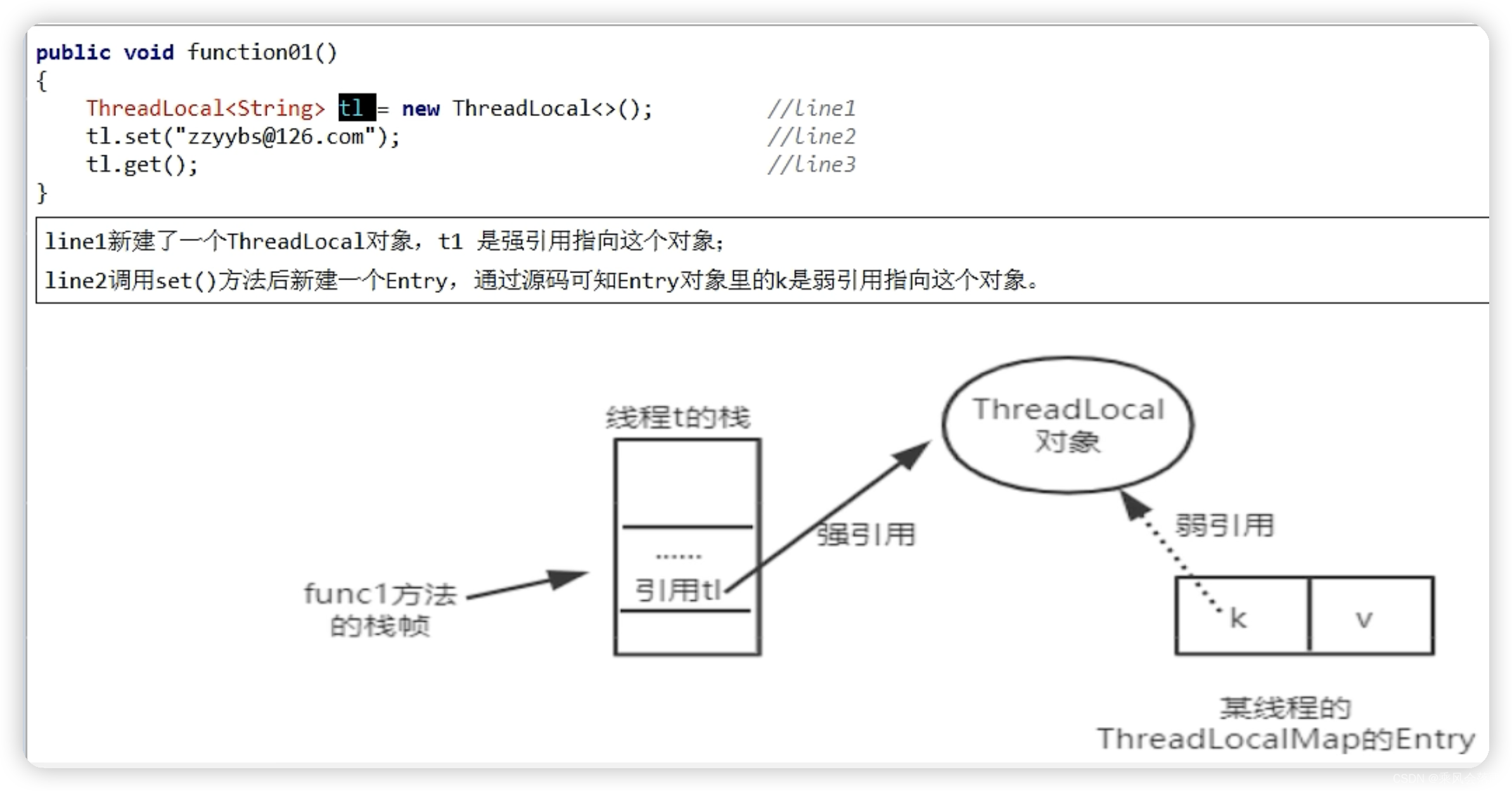
Java——聊聊JUC中的ThreadLocal
文章目录: 1.什么是ThreadLocal? 1.1 api介绍 1.2 最简单的案例认识ThreadLocal 1.3 线程池结合ThreadLocal案例 2.Thread &ThreadLocal & ThreadLocalMap 3.ThreadLocal内存泄漏问题 3.1 四大引用之强引用 3.2 四大引用之软引用 3.3 四…...
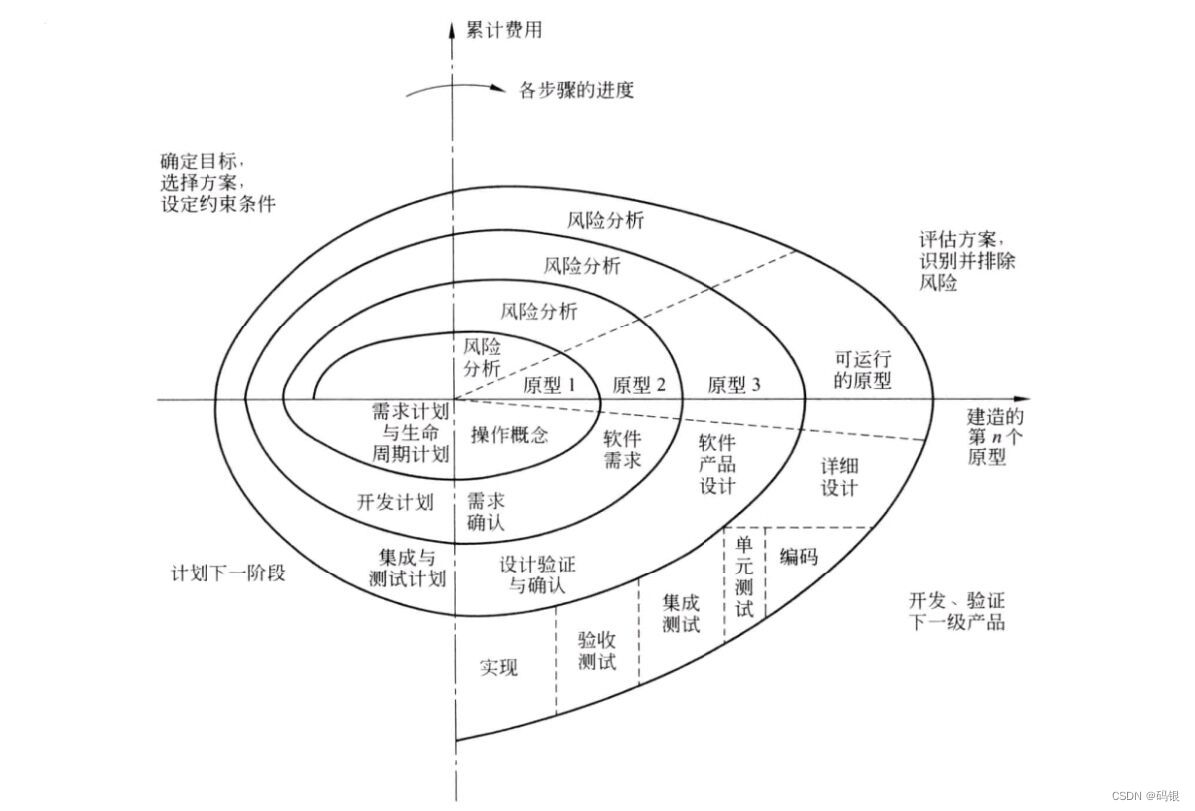
软件工程(4)--螺旋模型
前言 这是基于我所学习的软件工程课程总结的第四篇文章。 在软件开发过程中必须及时识别和分析风险,并且采取适当措施以消除或减少风险的危害。构建原型是一种能使某些类型的风险降至最低的方法。为了降低交付给用户的产品不能满足用户需要的风险,一种行…...

图解LeetCode——剑指 Offer 50. 第一个只出现一次的字符
一、题目 在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 s 只包含小写字母。 二、示例 2.1> 示例 1: 【输入】s "abaccdeff" 【输出】b 2.2> 示例 2: 【输入】s "" 【输出】 限制: 0 < s 的…...

《HTML 5与CSS 3核心技法》读书笔记
目录前言第1章 写在前面第2章 HTML 语法基础第3章 布局类元素 ,房子的楼板、柱子和大梁第4章 功能类元素,房子的门、窗、水管和电气第5章 CSS基础第6章 选择器,确定样式的作用范围选择器类型选择器的组合使用第7章 权重,样式发送冲…...

【沐风老师】3DMAX几何投影插件Geometry Projection使用详解
【几何投影插件】 描述 3DMAX几何投影插件Geometry Projection,将一个或多个对象或它的顶点选择沿全局或局部 x、y 或 z 轴投影到另一个对象上。 适用版本 3dMax2013或更高版本 安装设置 插件的安装非常简单,解压后把插件脚本 “geometry_projectio…...

面试问题整理
20200422面试题 1、有nginx为什么还要用gateway 2、factorybean和beanfactory有什么区别 https://www.cnblogs.com/leeego-123/p/12159574.html 2、aop原理 3、ioc原理 4、注解requestbody和responsebody区别。pathvireable和requestparam注解区别,feign客户端的注解…...

“区块链60人”2022赋能中国区块链创新人物名单公布
2022年11月5日,“2022第五届全国高校人工智能大数据区块链教育教学创新论坛”在京隆重召开。此次论坛公布了“区块链60人”2022赋能中国区块链创新人物评选活动获评名单。 本次评选活动通过媒体报道、第三方推荐、专家评选等环节,坚持“公开、公平、公正…...

day2324 数组
文章目录相关概念codeArrayTest08 数组拷贝相关概念 day23课堂笔记 1、数组 1.1、数组的优点和缺点,并且要理解为什么。 第一:空间存储上,内存地址是连续的。 第二:每个元素占用的空间大小相同。 第三:知道首元素的内…...

【Python实战】神仙运气—快看看你的彩票:2千多万元大奖无人领,马上就过期了,下一期的中奖者会是你吗?(纯技术交流)
前言 越努力越幸运 哈喽~我是栗子同学! 特别注意:不管是沉迷赌球,还是沉迷购彩,都是不可取的。本文纯是一个技术学习内容。 听说关注我的人会暴富哦!、 所有文章完整的素材源码都在👇👇 粉丝…...

2023年上半年软考高项信息系统项目管理师2月25日开班
信息系统项目管理师是全国计算机技术与软件专业技术资格(水平)考试(简称软考)项目之一,是由国家人力资源和社会保障部、工业和信息化部共同组织的国家级考试,既属于国家职业资格考试,又是职称资…...
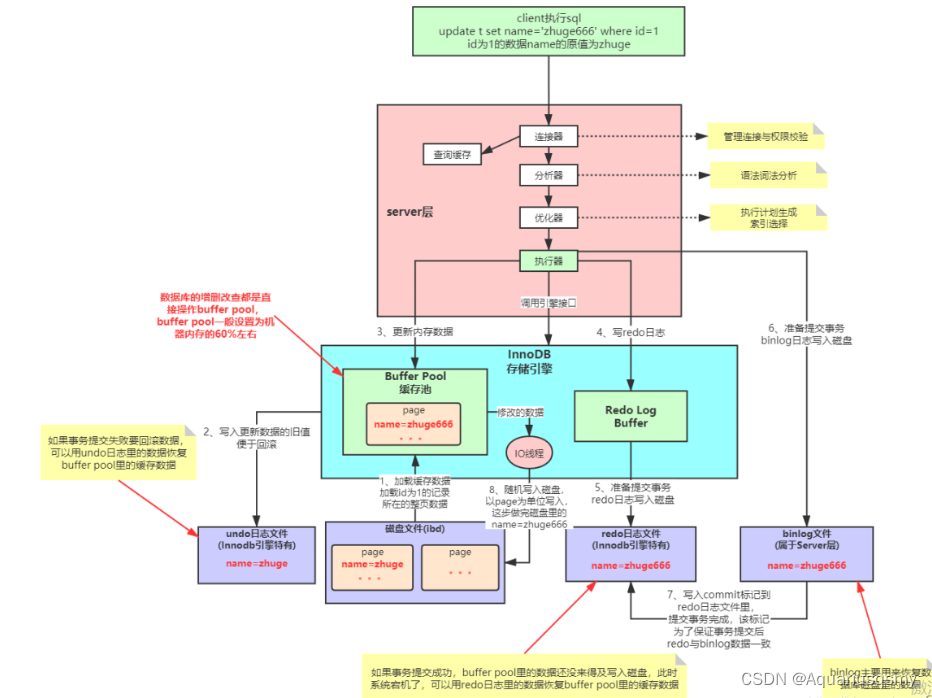
数据库(第一天)
文档信息 文档类别正式文档文档编号数据库基础课 1.2-001版本1.2-001文档名称数据库基础课编写负责人/编写时间梁昭东/2023 年 1 月 30 日审核负责人/审核时间年 月 日批准人/批准时间年 月 日 变更记录 日期版本号变更内容修订者2023.01.30v1.2版根据实际情况增删了部分内容…...

一文了解 ArrayList 的扩容机制
了解 ArrayList 在 Java 中常用集合类之间的关系如下图所示: 从图中可以看出 ArrayList 是实现了 List 接口,并是一个可扩容数组(动态数组),它的内部是基于数组实现的。它的源码定义如下: public class A…...

开源入门踩坑全实录:从PR被拒到核心贡献者的全周期避坑指南
根据中国开源软件推进联盟2025年发布的《中国开源开发者生态报告》,国内开源开发者规模已突破1200万,但入门1年内就停止贡献的开发者占比高达78.6%。换句话说,每5个尝试入门开源的新手,就有4个会在一年内彻底放弃。 作为从0起步&a…...

Ext2Read:Windows用户如何轻松读取Linux分区文件
Ext2Read:Windows用户如何轻松读取Linux分区文件 【免费下载链接】ext2read A Windows Application to read and copy Ext2/Ext3/Ext4 (With LVM) Partitions from Windows. 项目地址: https://gitcode.com/gh_mirrors/ex/ext2read 你是否遇到过这样的情况&a…...

KMS_VL_ALL_AIO:Windows与Office授权管理全场景解决方案
KMS_VL_ALL_AIO:Windows与Office授权管理全场景解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾在重要会议前遭遇Office突然提示"未授权"导致文件无法编辑…...

浪潮 NF5270M4 装 ESXi 8.0 识别不到 RAID1?这样设置一次搞定
最近很多机友遇到了核心问题:RAID1 已创建,但 ESXi 8.0U3i 只看到两块独立 SATA 盘,没识别出 RAID 逻辑盘。这是浪潮 NF5270M4 ESXi 8.0 的典型兼容性 / 驱动 / 配置问题,按下面步骤排查即可解决。一、先确认核心前提(必做)1、你…...

OpenHarmony标准系统选Linux内核,为啥首选LTS版本?聊聊4.19、5.10和6.6的适配实战
OpenHarmony标准系统选Linux内核:LTS版本决策逻辑与实战适配指南 当OpenHarmony标准系统遇上Linux内核选型,技术决策者们往往面临一个关键抉择:是追求前沿特性拥抱最新稳定版,还是坚守长期支持(LTS)版本的稳…...

Simple Form终极性能优化指南:如何实现Rails表单批量查询
Simple Form终极性能优化指南:如何实现Rails表单批量查询 【免费下载链接】simple_form Forms made easy for Rails! Its tied to a simple DSL, with no opinion on markup. 项目地址: https://gitcode.com/gh_mirrors/si/simple_form Simple Form是Rails生…...

从演唱会踩踏到交通拥堵:我们如何用无人机双光人群计数,为城市装上‘智慧之眼’?
无人机双光人群计数:城市安全管理的智能升级之路 当夜幕降临,体育场外数万观众正陆续离场,安保指挥中心的大屏上闪烁着红黄相间的热力图——这不是科幻电影的场景,而是某省会城市在明星演唱会后的真实一幕。通过部署在关键节点的1…...

NVIDIA Orin AGX开发环境搭建避坑指南:从Ubuntu 22.04到ROS2完整配置流程
NVIDIA Orin AGX开发环境搭建实战:从系统部署到ROS2深度优化 第一次拿到NVIDIA Orin AGX开发套件时,我对着这块巴掌大的计算模块发呆了十分钟——它强大的AI算力与紧凑体积形成的反差令人震撼。但很快现实给了我一盆冷水:官方文档里轻描淡写的…...
)
别再死记硬背了!用5分钟搞懂NPN和PNP三极管的电流流向(附快速判断技巧)
5分钟掌握NPN与PNP三极管的电流奥秘:从生活场景到实战技巧 记得第一次拆解收音机时,那些黑色的小方块上延伸出的金属腿让我一头雾水——它们看起来平平无奇,却能控制电流的放大与开关。直到导师用浇花的水管作比喻,三极管的秘密才…...

Audacity:音频创作者的开源瑞士军刀
Audacity:音频创作者的开源瑞士军刀 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity 在数字音频创作的世界里,专业工具往往意味着高昂的订阅费用和陡峭的学习曲线。Audacity 的出现打破了这…...