多模态视频大模型Aria在Docker部署
多模态视频大模型Aria在Docker部署
契机
⚙ 闲逛HuggingFace的时候发现一个25.3B的多模态大模型,支持图片和视频。刚好我有H20的GPU所以部署来看看效果,因为我的宿主机是cuda-12.1所以为了防止环境污染采用docker部署,通过一系列的披荆斩棘比如Segmentation fault (core dumped)异常,最终成功运行在单卡h20服务器上,python3.10,cuda12.4,ubuntu20.04,程序在推理图片的时候占用50g显存,推理5s视频20fps的时候占用60g左右显存。
项目简介
rhymes-ai/Aria · Hugging Face
https://github.com/rhymes-ai/Aria
线上demo尝试

线上demo响应很快,并且描述得很详细,并且可以描述什么时间发生了啥,介绍里面说的是:Cutting a long video by scene transitions with timestamps.(通过带有时间戳的场景过渡来剪切长视频。),这不是自动剪分镜吗,我有一个好想法先写完这篇再说
环境
docker环境
宿主机cuda是12.4以上的可以忽略,宿主机可以随便升降级cuda的也可以忽略要不然会出现以下异常:ImportError: /usr/local/lib/python3.10/dist-packages/torch/lib/…/…/nvidia/cusparse/lib/libcusparse.so.12: undefined symbol: __nvJitLinkComplete_12_4, version libnvJitLink.so.12
#安装docker前置
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \&& curl -fsSL https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \&& curl -fsSL https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list#安装docker和nvidia-docker
sudo apt-get update
sudo apt-get docker.io
sudo apt-get install -y nvidia-docker2
sudo systemctl start docker
docker --version#配置加速
#data-root为容器目录,我这里指定只是根目录磁盘满了,你磁盘多的可以不指定
vim /etc/docker/daemon.json
{"log-driver": "json-file","log-opts": {"max-file": "3","max-size": "10m"},"registry-mirrors" :["https://hub.rat.dev","https://docker.1panel.live","https://docker.rainbond.cc","https://mirror.ccs.tencentyun.com","http://registry.docker-cn.com","http://docker.mirrors.ustc.edu.cn","http://hub-mirror.c.163.com"],"data-root": "/home/docker"
}#重启
sudo systemctl daemon-reload
sudo systemctl restart docker#运行cuda:12.4.1容器,指定使用哪块gpu,指定挂载路径
#cuda:12.4.1-devel-ubuntu20.04。这个镜像包含了 nvcc 和其他开发工具。
docker run -d \
--name aria \
--gpus '"device=3"' \
-v /home:/home \
nvidia/cuda:12.4.1-devel-ubuntu20.04 \
tail -f /dev/null#进入docker
docker exec -it aria bash#安装常见工具
apt install vim
apt install wget
apt install git
#迁移docker容器目录
#这只是我的磁盘满了,需要搞到其他盘,我自己记录一下,你不用运行sudo rsync -aP /var/lib/docker/ /home/docker
docker info | grep "Docker Root Dir"
Conda环境
#下载conda,有些云厂商不支持tsinghua,所以任意选一个就行
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh#安装conda,配置环境变量,如果选择了自动配置环境可以不修改bashrc
sh Miniconda3-latest-Linux-x86_64.sh#添加conda
vim ~/.bashrc # >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/xxx/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; theneval "$__conda_setup"
elseif [ -f "/xxx/miniconda3/etc/profile.d/conda.sh" ]; then. "/xxx/miniconda3/etc/profile.d/conda.sh"elseexport PATH="/xxx/miniconda3/bin:$PATH"fi
fi
unset __conda_setup
# <<< conda initialize <<<#激活
source ~/.bashrc 代码环境
#建立conda环境,必须使用3.10
#ERROR: Package 'aria' requires a different Python: 3.9.20 not in '>=3.10’
conda create --name aria python=3.10#克隆代码
git clone https://github.com/rhymes-ai/Aria.git#进入Aria工程目录
conda activate aria
pip install -e . -i https://mirrors.aliyun.com/pypi/simple
pip install grouped_gemm -i https://mirrors.aliyun.com/pypi/simple
pip install flash-attn --no-build-isolation -i https://mirrors.aliyun.com/pypi/simple
下载模型
本来测试代码可以自动下载,我喜欢放在指定目录,所以搞了个脚本下载
import argparse
import time
import logging
from huggingface_hub import snapshot_download# Configure logging
logging.basicConfig(level=logging.INFO)def download_model(model_name, local_name, max_retries=15, retry_interval=2):for attempt in range(1, max_retries + 1):try:snapshot_download(repo_id=model_name,ignore_patterns=["*.bin"],local_dir=local_name,force_download=False)logging.info("Download successful")returnexcept Exception as e:logging.error(f"Attempt {attempt} failed: {e}")if attempt < max_retries:time.sleep(retry_interval)else:logging.critical("Download failed, exceeded maximum retry attempts")def main():parser = argparse.ArgumentParser(description="Download a model from Hugging Face Hub")parser.add_argument("--model_name", required=True, help="Name of the model to download")parser.add_argument("--local_name", required=True, help="Local directory to save the model")args = parser.parse_args()download_model(args.model_name, args.local_name)if __name__ == "__main__":main()#设置国内下载加速
export HF_ENDPOINT=https://hf-mirror.com #命令行直接运行,如果缺少依赖手动装下就行
python download_model.py \
--model_name rhymes-ai/Aria \
--local_name /home/models/huggingface/rhymes-ai/Aria#建议使用nohup
export HF_ENDPOINT=https://hf-mirror.com && nohup xxxxx >> dowload.log 2>&1 &
图片测试
代码
import requests
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor#这里为下载好模型本地地址
model_id_or_path = "/home/models/huggingface/rhymes-ai/Aria"model = AutoModelForCausalLM.from_pretrained(model_id_or_path, device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)processor = AutoProcessor.from_pretrained(model_id_or_path, trust_remote_code=True)#你自己搞一个你图片
image_path = "https://m207605830-1.jpg"image = Image.open(requests.get(image_path, stream=True).raw)messages = [{"role": "user","content": [{"text": None, "type": "image"},{"text": "what is the image?", "type": "text"},],}
]text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=text, images=image, return_tensors="pt")
inputs["pixel_values"] = inputs["pixel_values"].to(model.dtype)
inputs = {k: v.to(model.device) for k, v in inputs.items()}with torch.inference_mode(), torch.cuda.amp.autocast(dtype=torch.bfloat16):output = model.generate(**inputs,max_new_tokens=500,stop_strings=["<|im_end|>"],tokenizer=processor.tokenizer,do_sample=True,temperature=0.9,)output_ids = output[0][inputs["input_ids"].shape[1]:]result = processor.decode(output_ids, skip_special_tokens=True)print(result)
结果

视频测试
代码
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import time
import requests
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessormodel_id_or_path = "/home/models/huggingface/rhymes-ai/Aria"
model = AutoModelForCausalLM.from_pretrained(model_id_or_path, device_map="auto", torch_dtype=torch.bfloat16,trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_id_or_path, trust_remote_code=True)#这个一定放在模型加载下面,要不然要报错Segmentation fault (core dumped)
from decord import VideoReader
from tqdm import tqdm
from typing import Listdef load_video(video_file, num_frames=128, cache_dir="/home/lzy/cached_video_frames", verbosity="DEBUG"):# Create cache directory if it doesn't existos.makedirs(cache_dir, exist_ok=True)video_basename = os.path.basename(video_file)cache_subdir = os.path.join(cache_dir, f"{video_basename}_{num_frames}")os.makedirs(cache_subdir, exist_ok=True)cached_frames = []missing_frames = []frame_indices = []for i in range(num_frames):frame_path = os.path.join(cache_subdir, f"frame_{i}.jpg")if os.path.exists(frame_path):cached_frames.append(frame_path)else:missing_frames.append(i)frame_indices.append(i)vr = VideoReader(video_file)duration = len(vr)fps = vr.get_avg_fps()frame_timestamps = [int(duration / num_frames * (i + 0.5)) / fps for i in range(num_frames)]if verbosity == "DEBUG":print("Already cached {}/{} frames for video {}, enjoy speed!".format(len(cached_frames), num_frames, video_file))# If all frames are cached, load them directlyif not missing_frames:return [Image.open(frame_path).convert("RGB") for frame_path in cached_frames], frame_timestampsactual_frame_indices = [int(duration / num_frames * (i + 0.5)) for i in missing_frames]missing_frames_data = vr.get_batch(actual_frame_indices).asnumpy()for idx, frame_index in enumerate(tqdm(missing_frames, desc="Caching rest frames")):img = Image.fromarray(missing_frames_data[idx]).convert("RGB")frame_path = os.path.join(cache_subdir, f"frame_{frame_index}.jpg")img.save(frame_path)cached_frames.append(frame_path)cached_frames.sort(key=lambda x: int(os.path.basename(x).split('_')[1].split('.')[0]))return [Image.open(frame_path).convert("RGB") for frame_path in cached_frames], frame_timestampsdef get_placeholders_for_videos(frames: List, timestamps=[]):contents = []if not timestamps:for i, _ in enumerate(frames):contents.append({"text": None, "type": "image"})contents.append({"text": "\n", "type": "text"})else:for i, (_, ts) in enumerate(zip(frames, timestamps)):contents.extend([{"text": f"[{int(ts) // 60:02d}:{int(ts) % 60:02d}]", "type": "text"},{"text": None, "type": "image"},{"text": "\n", "type": "text"}])return contentsvideo_extensions = ('.mp4', '.avi', '.mov')
for root, _, files in os.walk("/home/"):for file in files:if file.endswith(video_extensions):video_path = os.path.join(root, file)frames, frame_timestamps = load_video(video_path, num_frames=20)### If you want to insert timestamps for Aria Inputscontents = get_placeholders_for_videos(frames, frame_timestamps)### If you DO NOT want to insert frame timestamps for Aria Inputs# contents = get_placeholders_for_videos(frames)start = time.time()messages = [{"role": "user","content": [*contents,{"text": "描述视频","type": "text"},],}]text = processor.apply_chat_template(messages, add_generation_prompt=True)inputs = processor(text=text, images=frames, return_tensors="pt", max_image_size=980)inputs["pixel_values"] = inputs["pixel_values"].to(model.dtype)inputs = {k: v.to(model.device) for k, v in inputs.items()}with torch.inference_mode(), torch.cuda.amp.autocast(dtype=torch.bfloat16):output = model.generate(**inputs,max_new_tokens=2048,stop_strings=["<|im_end|>"],tokenizer=processor.tokenizer,do_sample=False,)output_ids = output[0][inputs["input_ids"].shape[1]:]result = processor.decode(output_ids, skip_special_tokens=True)print(result)print(time.time() - start)- 我是分析/home/下面的所有视频,你要分析单个改改就行
- max_image_size可改成490
- num_frames你根据自己视频来选,我的5秒视频,分析20fps,相当于一秒4fps
结果

总结
- aria显存占用还可以,60g左右,好像默认使用的是attn_implementation=“flash_attention_2”
- 对比qwen和cpm来说,可以做到:通过带有时间戳的场景过渡来剪切长视频
- core dumped调整下import就行
写到最后

相关文章:
多模态视频大模型Aria在Docker部署
多模态视频大模型Aria在Docker部署 契机 ⚙ 闲逛HuggingFace的时候发现一个25.3B的多模态大模型,支持图片和视频。刚好我有H20的GPU所以部署来看看效果,因为我的宿主机是cuda-12.1所以为了防止环境污染采用docker部署,通过一系列的披荆斩棘…...

Ant-Design-Vue 全屏下拉日期框无法显示,能显示后小屏又位置错乱
问题1:在全屏后 日期选择器的下拉框无法显示。 解决:在Ant-Design-Vue的文档中,很多含下拉框的组件都有一个属性 getPopupContainer可以用来指定弹出层的挂载节点。 在该组件上加上 getPopupContainer 属性,给挂载到最外层盒子上。 <temp…...

AMR移动机器人赋能制造业仓储自动化升级
在当今制造业的激烈竞争中,智能化、数字化已成为企业转型升级的关键路径。一家制造业巨头,凭借其庞大的生产体系和多个仓库资源,正以前所未有的决心和行动力,在制造业智能化浪潮中勇立潮头,开启了降本增效的新篇章。这…...
【PHP项目实战】活动报名系统
目录 项目介绍 开发语言 后端 前端 项目截图(部分) 首页 列表 详情 个人中心 后台管理 项目演示 项目介绍 本项目是一款基于手机浏览器的活动报名系统。它提供了一个方便快捷的活动报名解决方案,无需下载和安装任何APP,…...
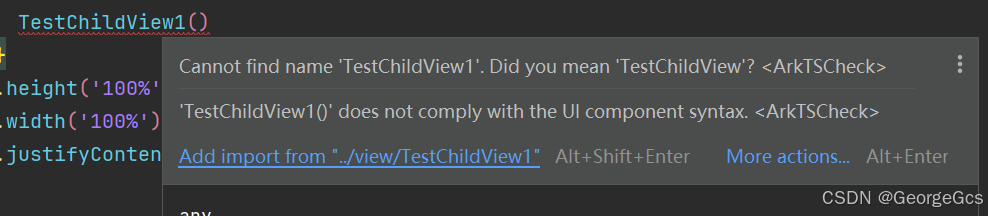
【HarmonyOS】Component组件引入报错 does not meet UI component syntax.
【HarmonyOS】Component组件引入报错 一、问题背景 有时会碰到引入组件时,无法import引入组件,导致引入的组件报错。 或者提示does not meet UI component syntax. (不符合UI组件语法。) 如下图所示,在引入组件时&a…...
vue3项目最新eslint9+prettier+husky+stylelint+vscode配置
一、eslint9和prettier通用配置 安装必装插件 ESlint9.x pnpm add eslintlatest -DESlint配置 vue 规则 , typescript解析器 pnpm add eslint-plugin-vue typescript-eslint -DESlint配置 JavaScript 规则 pnpm add eslint/js -D配置所有全局变量 globals pnpm add globa…...
)
备赛蓝桥杯--算法题目(3)
1. 2的幂 231. 2 的幂 - 力扣(LeetCode) class Solution { public:bool isPowerOfTwo(int n) {return n>0&&n(n&(-n));} }; 2. 3的幂 326. 3 的幂 - 力扣(LeetCode) class Solution { public:bool isPowerOfT…...

CSS中要注意的样式效果
1. 应用过渡效果 transition: var(--aa); 2.告诉浏览器元素可能会发生变换,从而优化性能。 will-change: transform; 3.使元素不响应鼠标事件。 pointer-events: none; 4.隐藏水平方向上的溢出内容 overflow-x: hidden; 5.定义一个元素的宽度和高度之间的比…...

【NIPS2024】Unique3D:从单张图像高效生成高质量的3D网格
背景(现有方法的不足): 基于Score Distillation Sampling (SDS)的方法:从大型二维扩散模型中提取3D知识,生成多样化的3D结果,但存在每个案例长时间优化问题/不一致问题。 目前通过微…...
使用Kubernetes部署Spring Boot项目
目录 前提条件 新建Spring Boot项目并编写一个接口 新建Maven工程 导入 Spring Boot 相关的依赖 启动项目 编写Controller 测试接口 构建镜像 打jar包 新建Dockerfile文件 Linux目录准备 上传Dockerfile和target目录到Linux 制作镜像 查看镜像 测试镜像 上传镜…...

基于VTX356语音识别合成芯片的智能语音交互闹钟方案
一、方案概述 本方案旨在利用VTX356语音识别合成芯片强大的语音处理能力,结合蓝牙功能、APP或小程序,打造一款功能全面且智能化程度高的闹钟产品。除了基本的时钟显示和闹钟提醒功能外,还拥有正计时、倒计时、日程安排、重要日提醒以及番茄钟…...
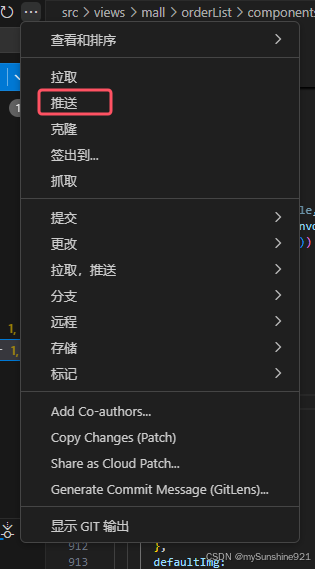
git将一个项目的文件放到另一个项目的文件夹下
现有productA与productB项目,现将productA、productB放到productC下的mall-web文件下,目前只能实现保留productA的提交记录,暂不能实现保留两个的提交记录 一.克隆最新的productC的库,这里指mall-web 二.将productA复制到mall-we…...

Cannon.js 从入门到精通
开发领域:前端开发 | AI 应用 | Web3D | 元宇宙 技术栈:JavaScript、React、ThreeJs、WebGL、Go 经验经验:6 年 前端开发经验,专注于图形渲染和 AI 技术 开源项目:智简未来、数字孪生引擎 github 大家好!我…...

深入理解 TCP 标志位(TCP Flags)
深入理解 TCP 标志位(TCP Flags) 1. 简介 在网络安全和网络分析领域,TCP标志位(TCP Flags)是理解网络行为和流量模式的关键概念。特别是在使用工具如Nmap进行端口扫描时,理解这些标志位的意义和用法至关重…...

K8S,StatefulSet
有状态应用 Deployment实际上并不足以覆盖所有的应用编排问题? 分布式应用,它的多个实例之间,往往有依赖关系,比如:主从关系、主备关系。 还有就是数据存储类应用,它的多个实例,往往都会在本地…...

JavaScript动态网络爬取:深入解析与实践指南
引言 随着互联网技术的发展,越来越多的网站采用动态加载技术来提供丰富的用户体验。这些动态内容的加载依赖于JavaScript,给传统的网络爬虫带来了挑战。JavaScript动态网络爬取技术应运而生,它允许开发者模拟用户行为,获取动态加…...
MySql:Centos7安装MySql
目录 安装之前,清除MySql残留文件 下载MySql的官方yum源 安装MySql 服务 MySql配置 常见问题 本次安装基于Centos7,平台为云服务器,由XShell软件演示。 注意,请将用户切换为Root用户。 安装之前,清除MySql残留文…...
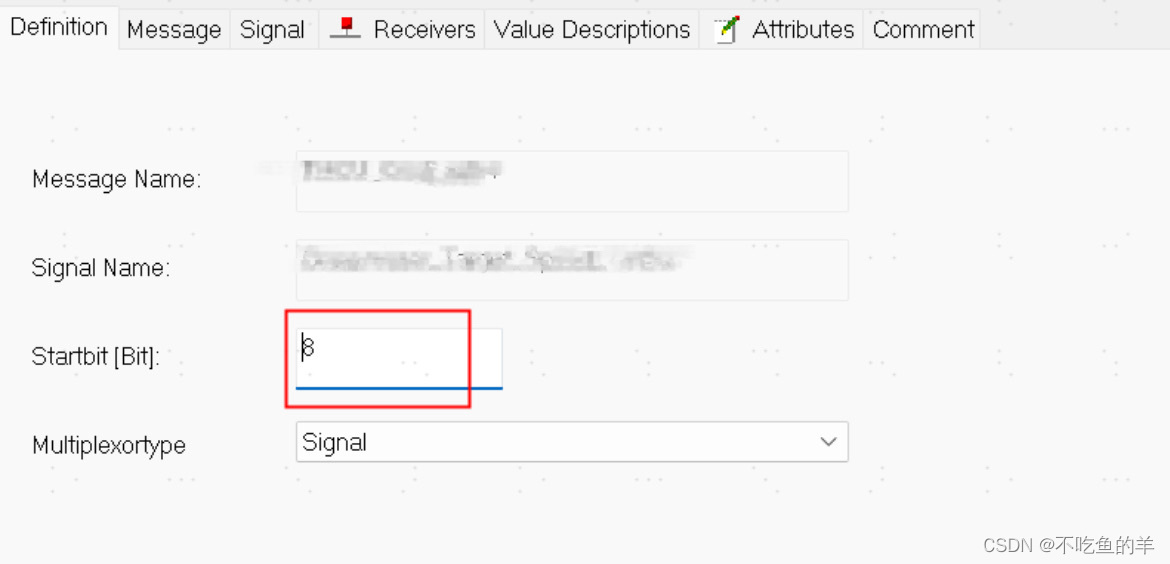
Vector软件CANdb++的信号起始位Bug
问题现象 前几天导入DBC文件发现不对劲,怎么生成代码的起始地址都怪怪的,检查下工程里面的配置,还真的是这样,一路查到输入文件——DBC文件,发现是DBC文件就有错误:一些CAN报文之后8字节长度,也…...

elasticsearch-7.14.0集群部署+kibana
1、修改系统参数 用户对软件的内存和硬盘使用权限 vim /etc/security/limits.conf * soft nproc 655350 * soft nofile 655350 * hard nproc 655350 * hard nofile 655350修改最大线程数 vim /etc/sysctl.conf vm.max_map_count262144配置用户最大的线程数 vim /etc/security/…...

如何给GitHub的开源项目贡献PR
🎯导读:本文详细介绍了如何向开源项目“代码随想录”贡献自己的题解。首先,需要Fork原项目的仓库至个人GitHub账户,然后解决克隆仓库时可能遇到的SSH密钥问题。接着,按照标准流程对本地仓库进行代码或文档的修改&#…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...