深入解析 Loss 减少方式:mean和sum的区别及其在大语言模型中的应用 (中英双语)
深入解析 Loss 减少方式:mean 和 sum 的区别及其在大语言模型中的应用
在训练大语言模型(Large Language Models, LLM)时,损失函数(Loss Function)的处理方式对模型的性能和优化过程有显著影响。本文以 reduce_loss 参数为例,详细探讨 mean 和 sum 两种方式的定义、适用场景及其对对话模型性能的潜在提升原因,并通过代码实例加深理解。
1. 什么是 reduce_loss?
reduce_loss 决定了在每个 batch 中,如何对 token-level 的损失进行归一化或累加处理。常见的选项是:
mean: 取每个 token 损失的平均值。sum: 将每个 token 损失直接累加。
参数定义示例(在代码中通过 dataclass 定义):参考来源:https://github.com/allenai/open-instruct
from dataclasses import dataclass, field@dataclass
class TrainingArguments:reduce_loss: str = field(default="mean",metadata={"help": ("How to reduce loss over tokens. Options are 'mean' or 'sum'.""Using 'sum' can improve chat model performance.")},)
2. mean 和 sum 的定义
2.1 mean 模式
- 定义:将 batch 中所有 token 的损失值取平均。
- 公式:
Loss mean = ∑ i = 1 N Loss i N \text{Loss}_{\text{mean}} = \frac{\sum_{i=1}^{N} \text{Loss}_i}{N} Lossmean=N∑i=1NLossi
其中 ( N N N) 是当前 batch 中的 token 总数。 - 特性:每个 token 的损失对最终的 loss 贡献相等,损失值与 batch 中的 token 数无关。
2.2 sum 模式
- 定义:将 batch 中所有 token 的损失值直接累加。
- 公式:
Loss sum = ∑ i = 1 N Loss i \text{Loss}_{\text{sum}} = \sum_{i=1}^{N} \text{Loss}_i Losssum=i=1∑NLossi - 特性:长序列(更多 token)的损失对总 loss 的贡献更大,损失值直接与 token 数成正比。
3. mean 和 sum 的区别
| 模式 | 特点 | 优点 | 缺点 |
|---|---|---|---|
mean | 损失对 token 数归一化,独立于 batch size。 | 稳定性强,适用于 token 数差异大的批次。 | 长序列与短序列对损失的贡献相同,可能弱化长序列的重要性。 |
sum | 损失值与 token 总数成正比,长序列贡献更大。 | 在注重长序列表现的任务中效果更好(如对话生成)。 | 损失值随 batch size 变化波动,需要动态调整学习率。 |
4. 适用场景分析
4.1 mean
- 适用任务:大多数语言建模任务,如 GPT 或 BERT 的预训练。
- 适用场景:当训练数据中序列长度差异较大时,
mean可以避免因长序列的损失值过大而导致梯度更新不均衡。
4.2 sum
- 适用任务:对长序列表现要求较高的任务,如对话生成(Chat Models)和长文本生成。
- 适用场景:长序列的损失占比更高,从而使优化过程更加关注全局上下文的建模。
5. 为什么 sum 能提升对话模型性能?
对话模型(Chat Models)的训练中,长序列往往包含丰富的上下文信息,而短序列则可能无法体现模型的上下文理解能力。在 sum 模式下:
- 长序列的重要性增加:长序列的损失对总损失的贡献更大,这促使模型更关注上下文的建模。
- 对全局一致性更敏感:
sum模式下,模型的优化方向更倾向于全序列的一致性,特别适合需要长距离依赖的任务。
示例:
假设一个 batch 包含以下两个样本:
- 样本 A: 长度为 10,损失总和为 5。
- 样本 B: 长度为 50,损失总和为 25。
计算损失贡献:
mean模式:
Loss mean = 5 + 25 10 + 50 = 0.5 \text{Loss}_{\text{mean}} = \frac{5 + 25}{10 + 50} = 0.5 Lossmean=10+505+25=0.5
样本 A 和 B 的贡献权重相同。sum模式:
Loss sum = 5 + 25 = 30 \text{Loss}_{\text{sum}} = 5 + 25 = 30 Losssum=5+25=30
样本 B 的贡献权重显著增加,优化更关注长序列。
6. 实战代码
以下是一个完整的训练脚本,展示如何在 Hugging Face 的 transformers 框架中使用 reduce_loss 参数。
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from torch.utils.data import DataLoader
import torch# 模型和数据集
model_name = "meta-llama/Llama-3.1-8B"
dataset_name = "allenai/tulu-3-sft-mixture"model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)dataset = load_dataset(dataset_name)
tokenized_dataset = dataset.map(lambda x: tokenizer(x['text'], truncation=True, padding="max_length"), batched=True)
train_loader = DataLoader(tokenized_dataset["train"], batch_size=2, shuffle=True)# 训练设置
reduce_loss = "sum" # 改为 "mean" 可对比效果
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-6)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 训练循环
for epoch in range(2):for batch in train_loader:inputs = torch.tensor(batch["input_ids"]).to(device)labels = inputs.clone()outputs = model(inputs, labels=labels)if reduce_loss == "sum":loss = outputs.loss.sum()else: # 默认 "mean"loss = outputs.loss.mean()loss.backward()optimizer.step()optimizer.zero_grad()print(f"Epoch: {epoch}, Loss: {loss.item()}")
7. 注意事项与优化建议
-
动态调整学习率:
- 使用
sum时,由于损失值放大,建议适配学习率,如降低到mean模式的 ( 1 / N 1/N 1/N )。 - 配合学习率调度器(如
linear)优化训练。
- 使用
-
对长短序列的平衡:
- 若长序列权重过大导致模型性能退化,可结合 curriculum learning 或混合训练策略(如对长短序列按比例采样)。
-
性能评估:
- 在验证集上,关注长序列和短序列的生成性能对比。
8. 总结
reduce_loss 的选择对模型性能有直接影响:
mean更通用,适合大多数语言建模任务。sum在对话生成等长序列敏感任务中表现更优。
希望本文能为 LLM 研究人员提供思路和参考,在具体任务中灵活选择合适的损失归一化方式,从而提升模型性能。
Understanding the Difference Between mean and sum Loss Reduction in LLM Training
When training large language models (LLMs), the way token-level loss is reduced across a batch can significantly impact optimization and model performance. This article delves into the reduce_loss parameter, exploring the differences between mean and sum reduction modes, their definitions, use cases, and why sum might improve the performance of chat-oriented models. Practical code examples are also provided for clarity.
1. What is reduce_loss?
The reduce_loss parameter determines how the token-level loss values in a batch are aggregated. The two most common options are:
mean: Averages the loss over all tokens in a batch.sum: Sums the loss of all tokens in a batch.
Example definition (from the codebase using Python dataclass):
from dataclasses import dataclass, field@dataclass
class TrainingArguments:reduce_loss: str = field(default="mean",metadata={"help": ("How to reduce loss over tokens. Options are 'mean' or 'sum'.""Using 'sum' can improve chat model performance.")},)
2. Definitions of mean and sum
2.1 mean
- Definition: Averages the loss across all tokens in a batch.
- Formula:
Loss mean = ∑ i = 1 N Loss i N \text{Loss}_{\text{mean}} = \frac{\sum_{i=1}^{N} \text{Loss}_i}{N} Lossmean=N∑i=1NLossi
where ( N N N ) is the total number of tokens in the batch. - Characteristics: The contribution of each token to the final loss is normalized, making the loss independent of the batch’s token count.
2.2 sum
- Definition: Sums up the loss across all tokens in a batch.
- Formula:
Loss sum = ∑ i = 1 N Loss i \text{Loss}_{\text{sum}} = \sum_{i=1}^{N} \text{Loss}_i Losssum=i=1∑NLossi - Characteristics: The total loss is proportional to the number of tokens, giving longer sequences more weight in the optimization process.
3. Key Differences Between mean and sum
| Reduction Mode | Characteristics | Advantages | Disadvantages |
|---|---|---|---|
mean | Normalizes the loss by token count. | Stable and robust for datasets with variable-length sequences. | Long sequences are underweighted relative to short ones. |
sum | Loss scales with the number of tokens. | Places greater emphasis on longer sequences, improving performance in tasks requiring context modeling. | Loss values vary with batch size, necessitating dynamic learning rate adjustment. |
4. Use Cases for mean and sum
4.1 mean
- Best Suited For: Pretraining or general language modeling tasks like GPT or BERT.
- Scenario: When the dataset contains sequences of widely varying lengths,
meanensures that longer sequences do not disproportionately influence gradient updates.
4.2 sum
- Best Suited For: Tasks requiring high performance on long sequences, such as dialogue generation or document-level text generation.
- Scenario: Encourages the model to prioritize sequences with richer contexts, as their loss contributes more to the overall optimization.
5. Why Does sum Improve Chat Model Performance?
In chat-oriented models, sequences are typically longer and require the model to understand and generate coherent responses over extended contexts. Using sum mode:
- Enhances Long Sequence Weighting: Longer sequences contribute more to the total loss, emphasizing the importance of context modeling.
- Encourages Global Consistency: By assigning more weight to longer contexts, the model better captures dependencies across the entire sequence.
- Balances Token Importance: Since chat models are often evaluated on dialogue-level coherence,
sumensures that tokens from the context and the response are proportionally weighted.
Example:
Consider a batch with two samples:
- Sample A: Sequence length = 10, loss = 5.
- Sample B: Sequence length = 50, loss = 25.
Loss calculations:
meanmode:
Loss mean = 5 + 25 10 + 50 = 0.5 \text{Loss}_{\text{mean}} = \frac{5 + 25}{10 + 50} = 0.5 Lossmean=10+505+25=0.5
Both samples contribute equally to the loss.summode:
Loss sum = 5 + 25 = 30 \text{Loss}_{\text{sum}} = 5 + 25 = 30 Losssum=5+25=30
Sample B contributes much more to the total loss, focusing the optimization on longer contexts.
6. Practical Implementation
Here’s a practical training script that demonstrates the use of reduce_loss in both modes.
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from torch.utils.data import DataLoader
import torch# Model and dataset
model_name = "meta-llama/Llama-3.1-8B"
dataset_name = "allenai/tulu-3-sft-mixture"model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)dataset = load_dataset(dataset_name)
tokenized_dataset = dataset.map(lambda x: tokenizer(x['text'], truncation=True, padding="max_length"), batched=True)
train_loader = DataLoader(tokenized_dataset["train"], batch_size=2, shuffle=True)# Training setup
reduce_loss = "sum" # Change to "mean" to compare effects
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-6)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# Training loop
for epoch in range(2):for batch in train_loader:inputs = torch.tensor(batch["input_ids"]).to(device)labels = inputs.clone()outputs = model(inputs, labels=labels)if reduce_loss == "sum":loss = outputs.loss.sum()else: # Default: "mean"loss = outputs.loss.mean()loss.backward()optimizer.step()optimizer.zero_grad()print(f"Epoch: {epoch}, Loss: {loss.item()}")
7. Practical Considerations
-
Learning Rate Adjustment:
- When using
sum, the loss magnitude increases with batch size, so you may need to adjust the learning rate (e.g., scale it down by ( 1 / N 1/N 1/N )).
- When using
-
Balancing Long and Short Sequences:
- Overweighting long sequences can sometimes harm generalization. Using curriculum learning or sampling strategies (e.g., proportional sampling) can help mitigate this.
-
Validation:
- Evaluate model performance on both short and long sequences to confirm improvements in the intended metrics.
8. Conclusion
The choice between mean and sum loss reduction modes depends on the specific task and dataset:
- Use
meanfor general-purpose language modeling tasks where sequence lengths vary significantly. - Use
sumfor tasks that prioritize long-sequence performance, such as chat models or long-text generation.
Understanding and experimenting with these settings can lead to better-optimized models, particularly in the nuanced field of LLM fine-tuning.
后记
2024年12月3日16点04分于上海,在GPT4o大模型辅助下完成。
相关文章:
)
深入解析 Loss 减少方式:mean和sum的区别及其在大语言模型中的应用 (中英双语)
深入解析 Loss 减少方式:mean 和 sum 的区别及其在大语言模型中的应用 在训练大语言模型(Large Language Models, LLM)时,损失函数(Loss Function)的处理方式对模型的性能和优化过程有显著影响。本文以 re…...

c++ auto
在C中,auto 是一种类型推导关键字,它允许编译器根据初始化表达式的类型自动推导变量的类型。自 C11 标准引入以来,auto 使得代码更加简洁,并且可以减少冗长的类型声明,尤其是在类型名称非常复杂或难以立即确定的情况下…...

python中的列表、元组、字典的介绍与使用
目录 一、区别介绍 1.使用场景以及区别图 2.详细介绍 列表 元组 字典 二、例子操作 (一)列表list 1.定义和初始化 2.访问元素(下标) 3.修改元素(下标) 4.添加元素(append、下标insert) 5.删除…...

深入浅出:PHP中的表单处理全解析
引言 在Web开发的世界里,表单是用户与服务器之间交互的重要桥梁。它们允许用户提交信息,并通过后端语言(如PHP)进行处理。本文将带你深入了解PHP中的表单处理,从基础的创建和提交到高级的安全措施和实用技巧ÿ…...

双绞线直连两台电脑的方法及遇到的问题
文章目录 前言一、步骤二、问题总结:问题1:遇到ping不通的问题。问题2:访问其他电脑上的共享文件时提示输入网络凭证问题3:局域网共享文件时提示“没有权限访问,请与网络管理员联系请求访问权限” 前言 办公室里有两台电脑,一台装了显卡用于…...

2024年认证杯SPSSPRO杯数学建模D题(第一阶段)AI绘画带来的挑战解题全过程文档及程序
2024年认证杯SPSSPRO杯数学建模 D题 AI绘画带来的挑战 原题再现: 2023 年开年,ChatGPT 作为一款聊天型AI工具,成为了超越疫情的热门词条;而在AI的另一个分支——绘图领域,一款名为Midjourney(MJÿ…...

Qt 设置QLineEdit控件placeholderText颜色
Qt 会根据QLineEdit控件显示文本的颜色自动设置placeholderText颜色,如果想自定义placeholderText颜色,可以通过以下方法。 在样式文件中增加以下设置: QLineEdit#lineEdit_userName, QLineEdit#lineEdit_password{border: none;padding: 6…...
离线安装 docker 和 docker-compose)
麒麟 V10 系统(arm64/aarch64)离线安装 docker 和 docker-compose
前期准备 查看操作系统版本,跟本文标题核对一下 uname -a查看操作系统架构 uname -m下载离线包 下载 docker 离线包 地址:https://download.docker.com/linux/static/stable/ 选择系统架构对应的文件目录:aarch64,我目前使用…...

Windows基线自动化检查脚本
本批处理脚本的主要目的是对Windows系统进行安全性检查。检查了多个安全参数和设置,以确保系统符合特定的安全标准。当然也可能有些检查项不是很准确,需要根据实际环境再调试一下,以下是该脚本的详细描述和功能分析: 1. 脚本初始…...

离谱的梯形滤波器——增加过渡点
增加过渡点 频率采样法(Frequency Sampling Method)是一种设计FIR滤波器的方法,通过在频域中指定希望的频率响应,然后利用逆离散傅里叶变换(IDFT)来获得滤波器的脉冲响应。然而,这种方法容易导…...

tauri下的两个常用rust web框架:Leptos和Trunk
tauri下有两个常用rust web框架,就是Leptos和Trunk Leptos Leptos 是一个基于 Rust 的 Web 框架。您可以在他们的官方网站上了解更多关于 Leptos 的信息。本指南适用于 Leptos 的 0.6 版本。 Leptos Leptos 是一个用 Rust 编写的现代、高效且安全的 Web 框架。它…...

pubmed关键词搜索技能1:待更新
1,白话变为领域内学术词: 例如,我想要做蛋白质糖基化修饰以功能,这个领域课题,则 第一性原理,首先是拆分词汇:糖基化(一般比蛋白质、修饰、功能要在title中更常见,或者是…...

【技巧】Mac上如何显示键盘和鼠标操作
在制作视频教程时,将键盘和鼠标的操作在屏幕上显示出来,会帮助观众更容易地理解。 推荐Mac上两款开源的小软件。 1. KeyCastr 这款工具从2009年至今一直在更新中。 https://github.com/keycastr/keycastr 安装的话,可以从Github上下载最…...
在多核MCU的TPU上功能安全ASILB与ASILD有什么区别)
ISO26262-(Timing Monitoring)在多核MCU的TPU上功能安全ASILB与ASILD有什么区别
在多核微控制器(MCU)的时间保护方面,针对功能安全ASIL B与ASILD等级的设计和实施存在显著差异,这些差异主要体现在系统对时间关键性操作的保障程度、故障检测能力、以及系统响应的严格性上。 ASIL B 级别: 时间关键性:在ASIL B等级,系统设计注重于识别并处理大部分可能…...

图像处理插件:让小程序焕发视觉新生的秘密武器
在小程序开发中,图像处理是一个重要的环节,它涉及到图片的加载、显示、裁剪、压缩等多个方面。为了简化这一复杂过程,开发者通常会使用图像处理插件。这些插件不仅提供了丰富的图像处理功能,还封装了底层的图像操作逻辑࿰…...

项目代码第2讲:从0实现LoginController.cs,UsersController.cs、User相关的后端接口对应的前端界面
一、User 1、使用数据注解设置主键和外键 设置主键:在User类的U_uid属性上使用[Key]注解。 设置外键:在Order类中,创建一个表示外键的属性(例如UserU_uid),并使用[ForeignKey]注解指定它引用User类的哪个…...

【linux 查看网卡设备信息命令记录】
查看设备信息命令 查看网卡芯片相关platform类型网卡(gmac网卡为例)PCI网卡(rtl8125为例) 查看网卡芯片相关 platform类型网卡(gmac网卡为例) gmac 属于CPU资源的一部分,属于平台设备。下面以FT2004 的CPU为例,自带GMAC0和GMAC1。 1、通过平台设备查看…...

springboot事务手动回滚报错
捕捉异常之后手动标记回滚事务 TransactionAspectSupport.currentTransactionStatus().setRollbackOnly(); 没有嵌套事务,还是报Transaction rolled back because it has been marked as rollback-only异常错误 查看错误堆栈,service调用的方法外层还套…...

SQL 算术运算符:加法、减法、乘法、除法和取模的用法
什么是存储过程? 存储过程是一段预先编写好的 SQL 代码,可以保存在数据库中以供反复使用。它允许将一系列 SQL 语句组合成一个逻辑单元,并为其分配一个名称,以便在需要时调用执行。存储过程可以接受参数,使其更加灵活…...

C#是Unity 3D的默认语言,Unity 3D是一种领先的游戏引擎
C#或C-Sharp是一种比C更现代和灵活的编程语言,它也在游戏开发中广受欢迎。C#是Unity 3D的默认语言,Unity 3D是一种领先的游戏引擎,它为各种游戏提供动力,例如《口袋妖怪围棋》、《超级马里奥跑》和《神庙跑》。 Unity 3D也在虚拟…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...
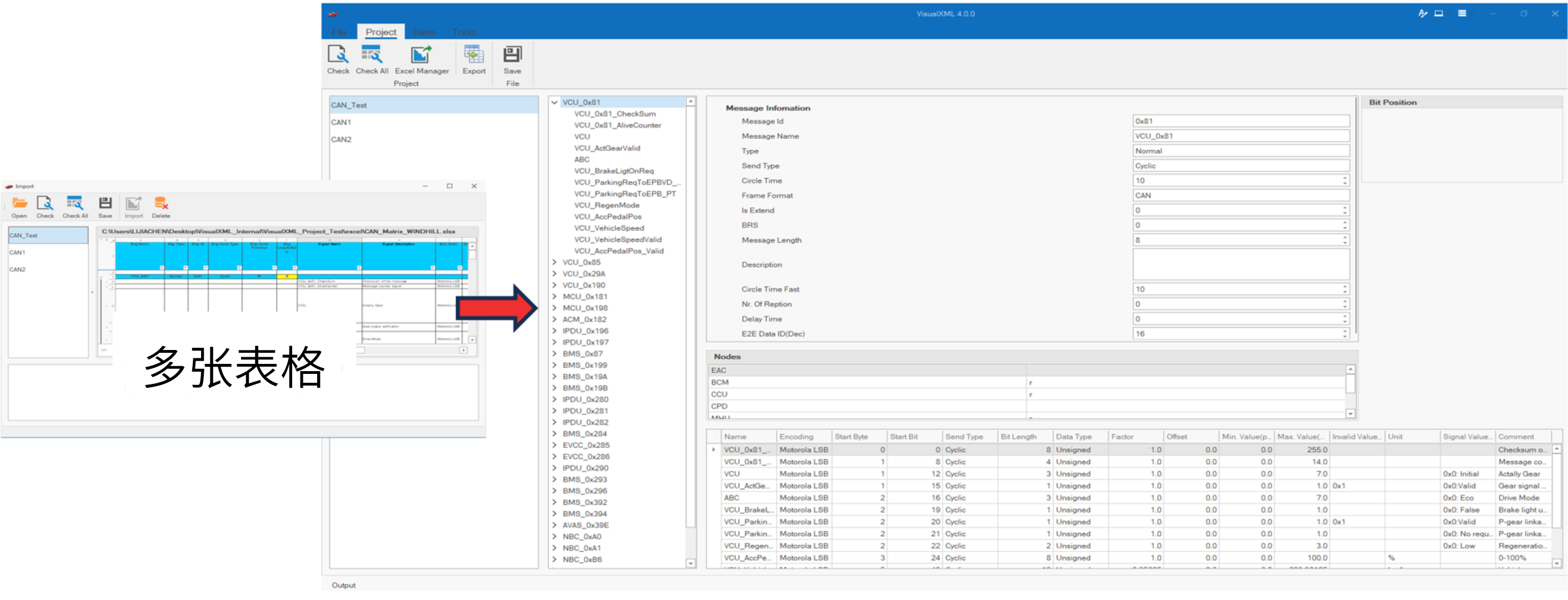
VisualXML全新升级 | 新增数据库编辑功能
VisualXML是一个功能强大的网络总线设计工具,专注于简化汽车电子系统中复杂的网络数据设计操作。它支持多种主流总线网络格式的数据编辑(如DBC、LDF、ARXML、HEX等),并能够基于Excel表格的方式生成和转换多种数据库文件。由此&…...