Go 协程上下文切换的代价
在 Go 语言中,协程(Goroutine)是一种非常轻量级的并发执行单元,设计之初就是为了简化并发编程并提高性能。协程的上下文切换被认为是非常高效的,但是它的真正性能优势需要我们深入了解其背后的机制。
本文将深入探讨 Go 协程的上下文切换机制,分析它的效率和潜在的代价,同时通过代码示例帮助大家理解其工作原理和性能影响。
1. 什么是 Go 协程的上下文切换?
上下文切换(Context Switch)指的是 CPU 从一个协程(或线程)切换到另一个协程的过程。在 Go 中,协程的上下文切换相对轻量级,因为 Go 的调度器在用户空间进行协程调度,而不是依赖操作系统内核。协程的上下文切换不需要操作系统内核的干预,意味着它们的切换开销远低于传统线程的上下文切换。
1.1 协程的调度模型
Go 采用的是一种基于 M:N 的调度模型:
- M:表示操作系统中的物理线程(或者叫 P)。
- N:表示 Go 协程的数量。
Go 的调度器会将多个 Goroutine 调度到少量的操作系统线程上。每当 Goroutine 被阻塞时,调度器会尝试将其他 Goroutine 调度到相同的操作系统线程上,从而避免了线程上下文切换的代价。
1.2 协程的上下文切换的特点
Go 协程的上下文切换与操作系统线程的上下文切换有很大的不同:
- 协程是轻量级的:它们在用户空间进行调度,没有内核干预,内存占用少。
- 上下文切换快:Go 协程的上下文切换主要是保存和恢复寄存器、栈等少量的状态,开销相对较小。
- 无须操作系统线程切换:与线程相比,Go 协程的切换不需要切换内核线程,因此能显著减少调度开销。
1.3 Go 协程的调度与栈
Go 协程在创建时,内存占用较小,默认栈大小为 2KB。Go 的调度器会根据需要动态调整栈的大小(随着协程的栈深度增长),从而使得多个协程能够共享相同的操作系统线程,进一步减少了内存占用和上下文切换的代价。
2. 协程上下文切换的代价
尽管 Go 协程的上下文切换比传统线程的切换要高效,但它仍然有一些代价,特别是在高并发场景下:
2.1 上下文切换的开销
虽然 Go 协程的上下文切换开销相对较小,但它并不是零成本的。每次上下文切换时,Go 调度器需要执行以下操作:
- 保存当前协程的状态(寄存器、栈指针等)。
- 恢复下一个协程的状态。
- 更新调度器的队列和调度信息。
- 如果某个协程被阻塞(如 I/O 操作),需要将其挂起,并在适当的时候唤醒。
这些操作会消耗 CPU 时间,因此,如果协程频繁切换或存在过多的协程,可能会导致性能下降。
2.2 高并发中的挑战
在高并发场景下,协程的上下文切换开销可能会影响性能。特别是当协程的数量非常大时(比如数万甚至更多),频繁的上下文切换可能导致 CPU 资源被浪费在调度上,而不是实际的计算任务上。
- 调度压力:如果协程的数量过多,调度器的管理和切换操作可能会产生显著的开销。
- 缓存失效:频繁的上下文切换可能导致 CPU 缓存失效,因为协程间的局部性差异较大,频繁切换可能导致缓存被清空,影响性能。
3. 性能测试:协程上下文切换的开销
为了帮助理解 Go 协程上下文切换的代价,我们通过代码示例来进行一些简单的性能测试。以下是一个简单的性能测试示例,比较了在不同数量的 Goroutine 和上下文切换下的性能表现。
3.1 示例 1:测试协程上下文切换的代价
package mainimport ("fmt""sync""time"
)// 测试协程上下文切换的开销
func testGoroutineSwitching(numGoroutines int) {var wg sync.WaitGroupwg.Add(numGoroutines)start := time.Now()// 创建多个 Goroutinefor i := 0; i < numGoroutines; i++ {go func() {// 每个 Goroutine 执行简单的计算任务for j := 0; j < 1000; j++ {_ = j * j // 模拟一些计算任务}wg.Done()}()}// 等待所有 Goroutine 完成wg.Wait()duration := time.Since(start)fmt.Printf("Total time for %d goroutines: %v\n", numGoroutines, duration)
}func main() {// 测试不同数量的 Goroutinefor _, num := range []int{100, 1000, 10000, 50000} {testGoroutineSwitching(num)}
}
3.2 代码解释
- 我们创建了多个 Goroutine,每个 Goroutine 执行一个简单的计算任务(在此只是模拟一些计算操作)。
- 我们分别测试了不同数量的 Goroutine(如 100, 1000, 10000, 50000)在执行时所需要的时间。
- 通过比较不同数量的 Goroutine 执行时间,我们可以观察到随着 Goroutine 数量的增加,执行时间的变化情况,从而间接了解上下文切换的代价。
3.3 结果分析
假设我们运行了上面的代码,以下是可能的输出(实际输出可能会受到机器性能、操作系统调度等因素的影响):
Total time for 100 goroutines: 5.3ms
Total time for 1000 goroutines: 40ms
Total time for 10000 goroutines: 300ms
Total time for 50000 goroutines: 1500ms
从这个结果中我们可以看出,随着 Goroutine 数量的增加,执行时间明显增加。虽然每个 Goroutine 执行的任务非常简单,但随着 Goroutine 数量的增加,调度器的上下文切换开销也逐渐显现出来。
4. 如何优化协程上下文切换
虽然 Go 协程的上下文切换相对高效,但在高并发场景下,过多的协程仍然可能导致性能下降。为了减少上下文切换的开销,可以考虑以下几种优化方法:
4.1 限制 Goroutine 的数量
避免创建过多的 Goroutine。可以使用 工作池(Worker Pool)模式,将任务分配给固定数量的 Goroutine 进行处理,避免协程数量过多带来的调度开销。
4.2 使用通道(Channels)控制协程数量
通道(Channels)是 Go 语言中的一个重要特性,可以用于协程间的通信和同步。通过通道来控制并发数量,从而限制协程的数量和调度的频繁程度。
4.3 使用 sync.Pool 来复用对象
如果协程中处理的数据对象比较复杂,可以使用 sync.Pool 来复用对象,从而减少内存分配和垃圾回收的压力,间接减少上下文切换的代价。
4.4 优化任务分配策略
尽量避免让大量的协程争用少数的资源(如 CPU、内存等)。合理分配任务,避免过多的协程切换到同一操作系统线程上执行,从而减少资源竞争。
5. 总结
Go 协程的上下文切换相对于操作系统线程的上下文切换而言非常轻量级,但在高并发场景下,频繁的上下文切换仍然可能带来一定的性能开销。尽管如此,Go 协程的设计和调度模型使得它们在绝大多数应用场景中仍然非常高效。
提升性能的策略:
- 限制协程的数量,避免过多的协程导致调度开销过大。
- 使用工作池、通道、
sync.Pool等方式控制协程的创建和销毁。 - 在设计系统时尽量避免频
繁的上下文切换,合理安排任务和资源的分配。
相关文章:

Go 协程上下文切换的代价
在 Go 语言中,协程(Goroutine)是一种非常轻量级的并发执行单元,设计之初就是为了简化并发编程并提高性能。协程的上下文切换被认为是非常高效的,但是它的真正性能优势需要我们深入了解其背后的机制。 本文将深入探讨 …...
)
HTTP 持久连接(长连接)
HTTP 持久连接(长连接) HTTP 持久连接(HTTP Persistent Connections),也常被称作 HTTP 长连接,是 HTTP 协议中的一种重要特性,以下是关于它的详细介绍: 一、基本概念 在传统的 HTT…...
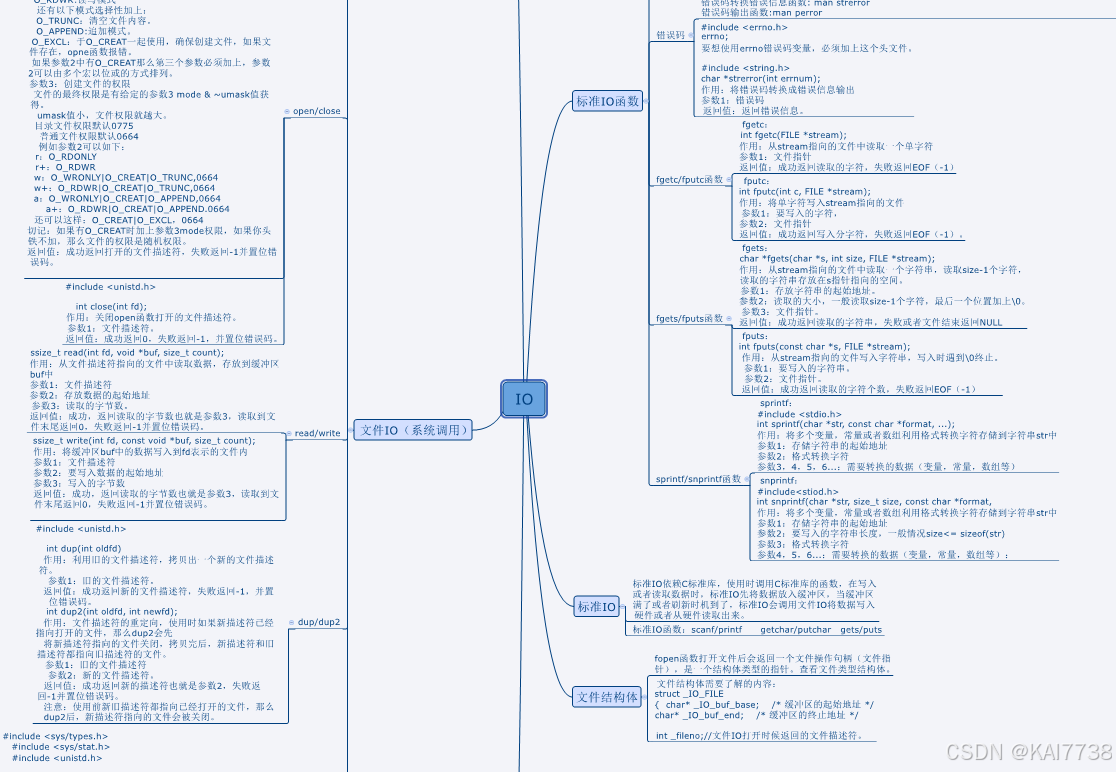
12月10日IO
作业:使用read和write实现拷贝文件,将1.txt内容前一半拷贝给2.txt后一半拷贝给3.txt #include <myhead.h>int main(int argc, const char *argv[]) {//打开三个文件int fd1,fd2,fd3;fd1open("1.txt",O_RDONLY);fd2open("2.txt&quo…...

Composite Pattern
Composite Pattern The intent of Composite pattern is to composite objects into tree structures to represent a “part-whole” hierarchy .The Composite Pattern allow clients to treat individual objects and composite objects uniformly. UML Used in Qt Exam…...

Springboot MVC
1. Springboot为MVC提供的自动配置 Spring Boot 为 Spring MVC 提供了自动配置,这在大多数应用程序中都能很好地工作。除了已经实现了 Spring MVC 的默认功能外,自动配置还提供了以下特性: 包括 ContentNegotiatingViewResolver 和 BeanNam…...

MySQL数据表记录增操作
对数据库的操作用的最最频繁的呢,总结起来就四个字:增删改查! 查是属于DQL(Data QueryLanguage ,数据查询语言)部分,而增、改、删属于DML(Data Manipulation Language, 数据操纵语言) 增:作用是往数据库的数据表里写入记录值 语…...
maven报错“找不到符号“
问题 springboot项目 maven编译打包过程,报错"找不到符号" 解决 很多网上方法都试过,都没用 换jdk,把17->21...
python进阶-05-利用Selenium来实现动态爬虫
python进阶-05-利用Selenium来实现动态爬虫 一.说明 这是python进阶部分05,我们上一篇文章学习了Scrapy来爬取网站,但是很多网站需要登录才能爬取有用的信息,或者网站的静态部分是一个空壳,内容是js动态加载的,或者人机验证&…...

P1226 【模板】快速幂
题目描述 给你三个整数 𝑎,𝑏,𝑝求 𝑎𝑏 mod 𝑝 输入格式 输入只有一行三个整数,分别代表 𝑎,𝑏,𝑝 输出格式 输出一行一个字符串 a^b mod ps…...

【C++】求第二大的数详细解析
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C 文章目录 💯前言💯题目描述💯输入描述💯解题思路分析1. 题目核心要求2. 代码实现与解析3. 核心逻辑逐步解析定义并初始化变量遍历并处理输入数据更新最大值与次大值输…...
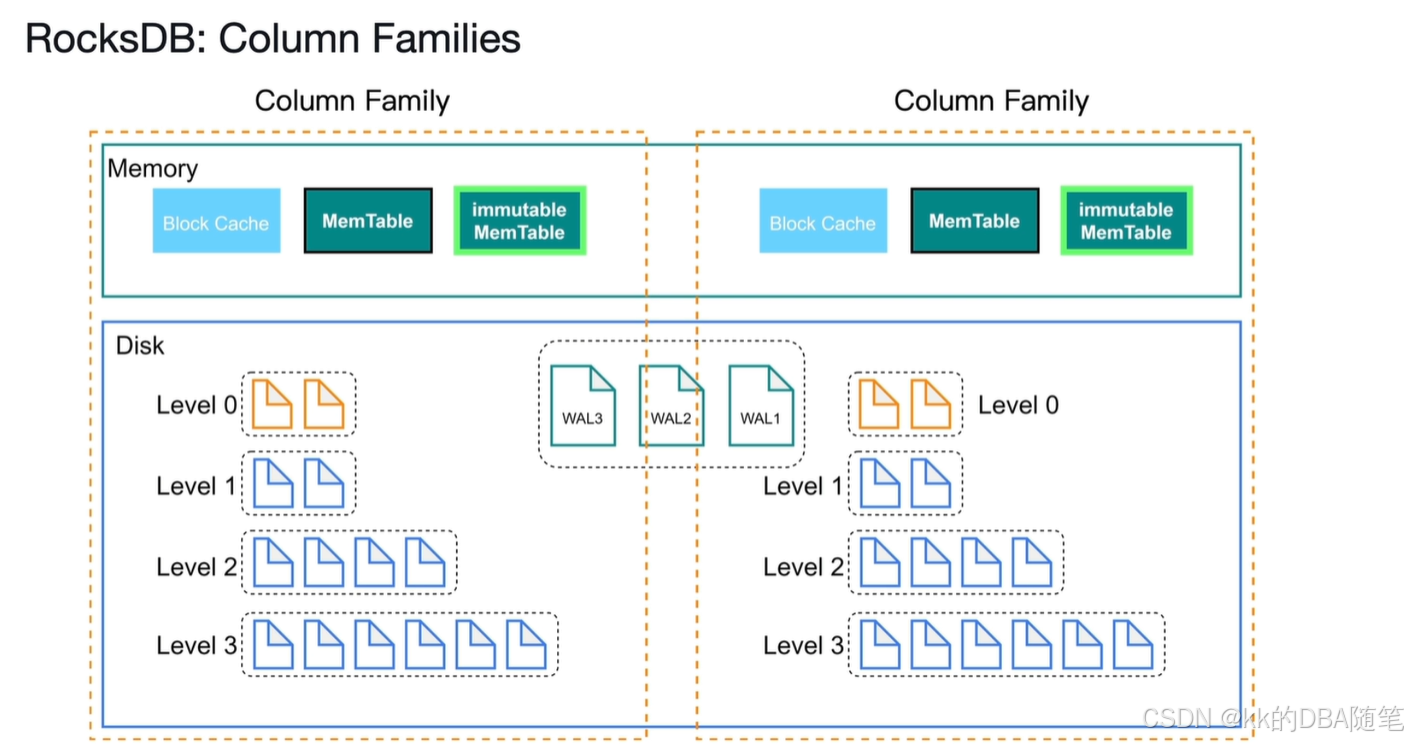
从零开始学TiDB(3)TiKV 持久化机制
如图,每个TiKV有两个rocksdb实例,rocksdbKV复制存储键值对,rocksdb raft负责存储复制的日志 。 每个region及其副本构成了raft group。这个OB的Zone其实有点类似,在OB中每个Unit及其副本构成了paxos组,在TiDB中叫raft…...

Elasticsearch+Kibana+IK分词器+拼音分词器安装
目录 ES报错 Kibanaik分词器拼音分词器 安装都比较简单,可以参考这几篇博客 ES 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch 报错 ES启动报错error downloading geoip database [GeoLite2-ASN.mmdb] Kibana KIBANA的安装教程ÿ…...
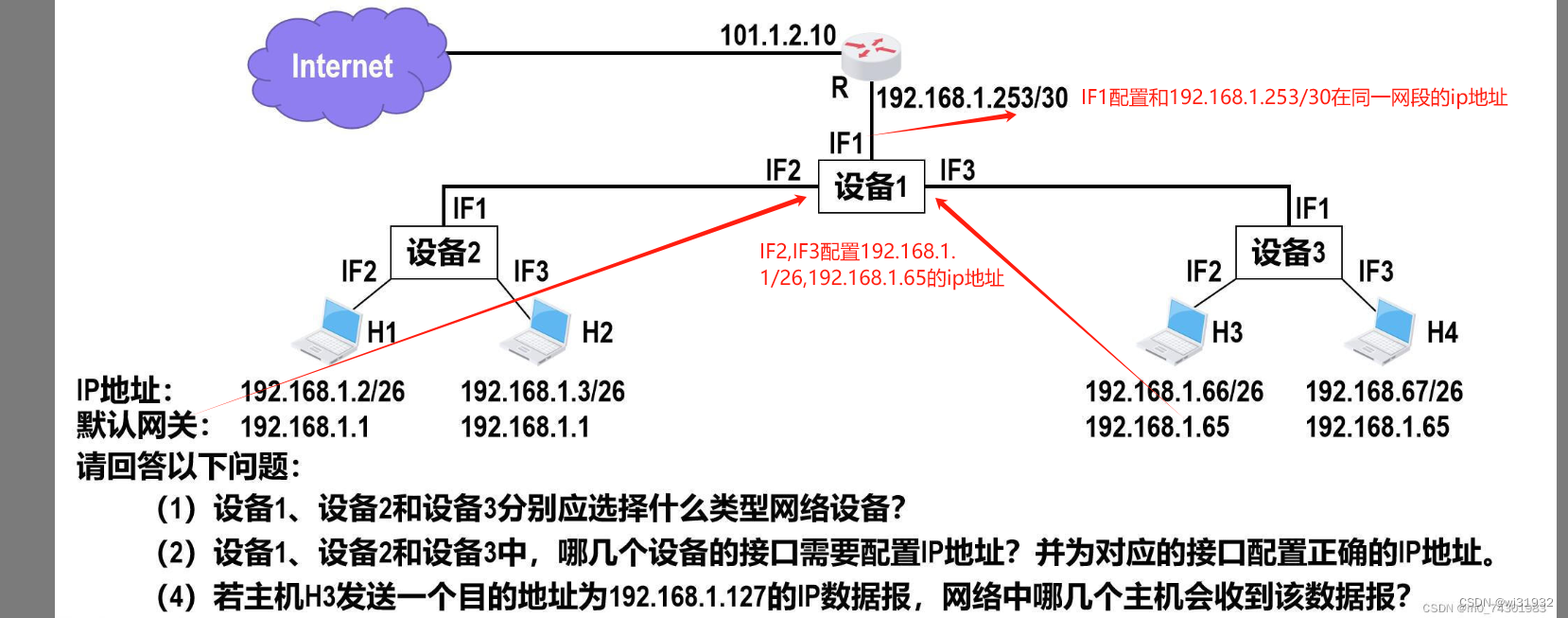
子网划分实例
看到有人问这个问题: 想了一下,这是一个子网划分的问题: 处理方法如图: 这是一个子网划分的问题 设备1用三层交换机,端口设置为路由模式,设备2和设备3为傻瓜交换机模式 设备2和设备3下挂设备都是26为掩码&…...

上海亚商投顾:创业板指震荡调整 机器人概念股再度爆发
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指昨日冲高回落,深成指、创业板指盘中跌超1%,尾盘跌幅有所收窄。机器人概念股逆势爆…...
:初始化 Initializer)
【C++ 20进阶(2):初始化 Initializer
【C 20进阶(2):初始化 Initializer】 原文:https://blog.csdn.net/weixin_44259356/article/details/144377955 引言 本篇文章为系列文章将着重介绍C20新特性,一是希望可以和大家交流分享,二是也便于自己…...

【重生之我在B站学MySQL】
MySQL笔记 文章目录 MySQL的三层结构SQL语句分类sql语句数据库操作创建数据库查看、删除数据库 表操作创建表mysql常用数据类型(列类型)查询表、插入值创建表练习创建一个员工表emp 修改表mysql约束primary key(主键)not null(非空)unique(唯一)foreign key(外键)check自增长 索…...

Python实现中国象棋
探索中国象棋 Python 代码实现:从规则逻辑到游戏呈现 中国象棋,这款源远流长的棋类游戏,承载着深厚的文化底蕴与策略智慧。如今,借助 Python 与 Pygame 库,我们能够在数字世界中复刻其魅力,深入探究代码背后…...
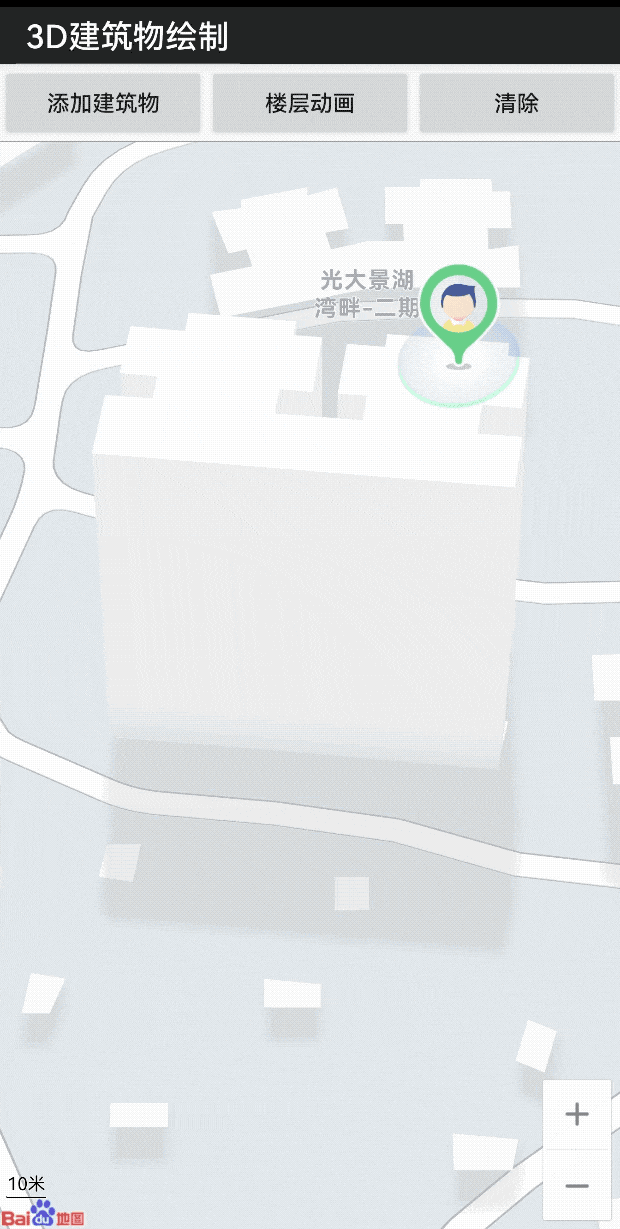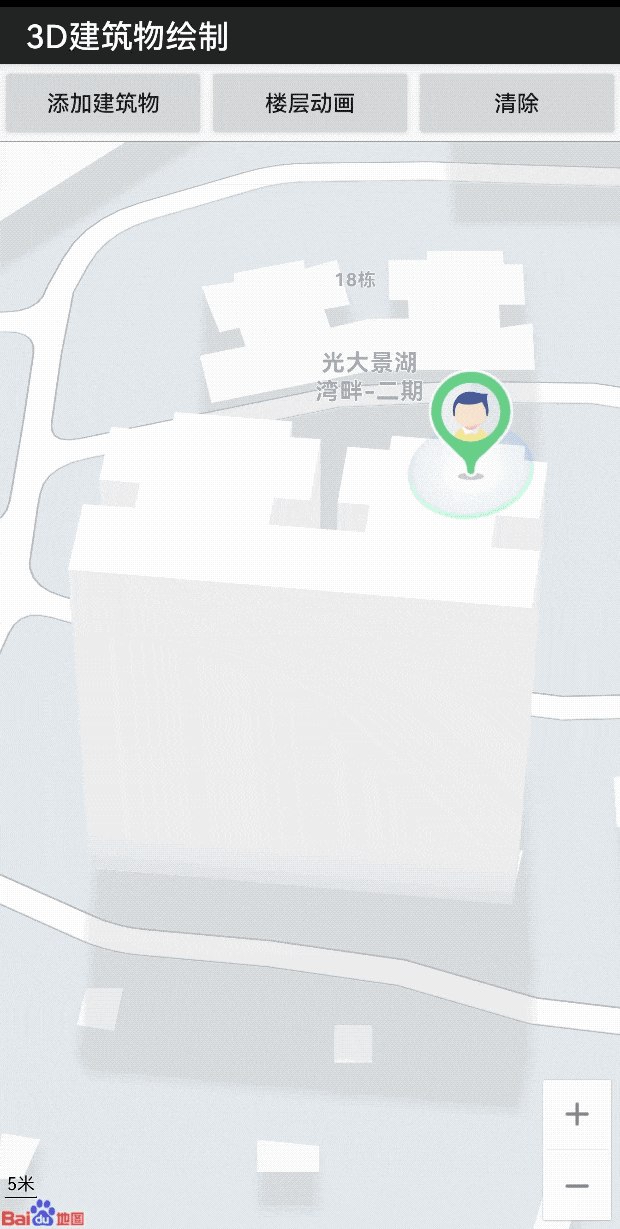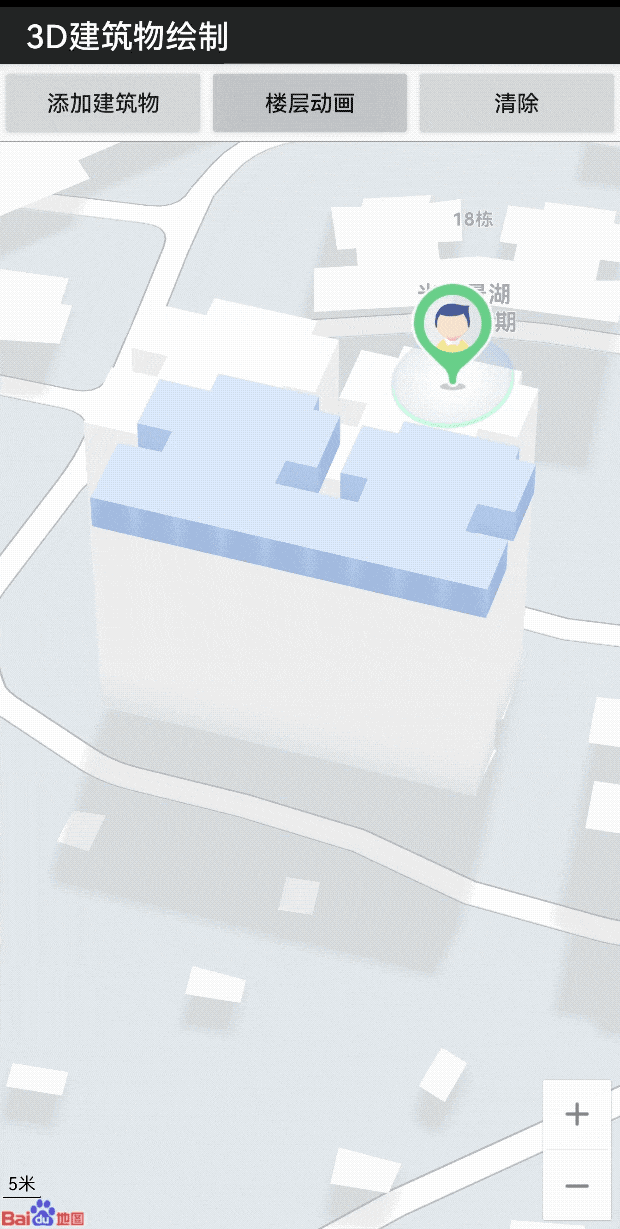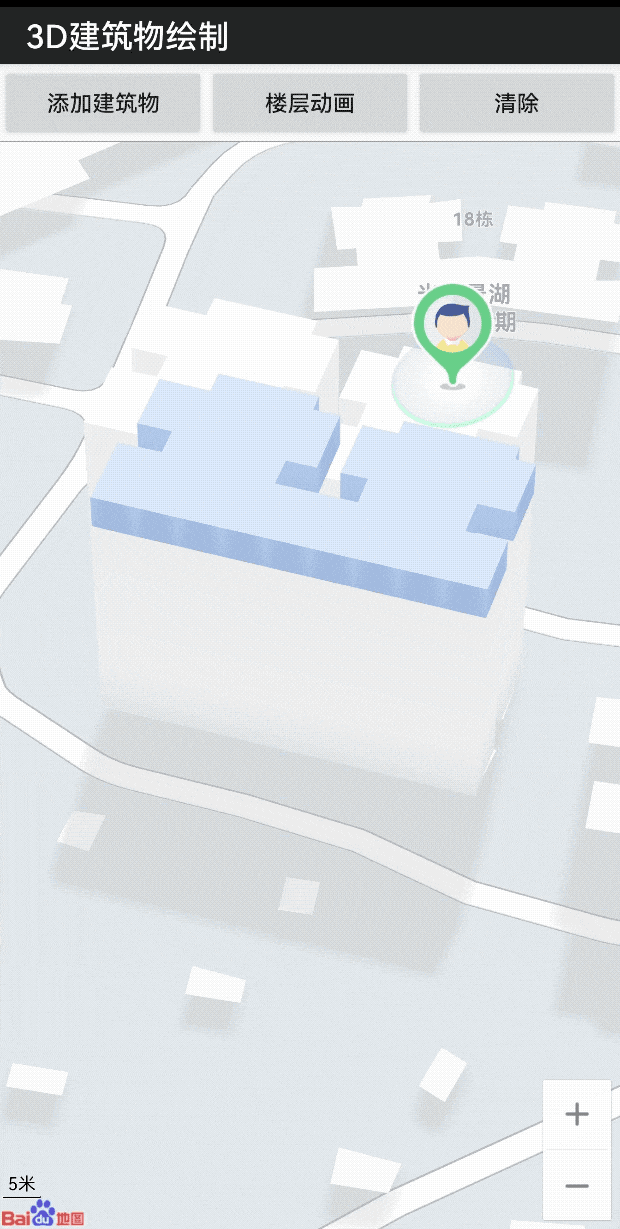
LBS 开发微课堂|通过openGL ES轻松实现建筑物渲染及动画
为了让广大开发者 更深入地了解 百度地图开放平台的 技术能力 轻松掌握满满的 技术干货 更加简单地接入 位置服务 我们特别推出了 “位置服务(LBS)开发微课堂” 系列技术案例 第五期的主题是 通过openGL ES轻松实现 建筑物渲染及动画 对于…...
的区别为何前者取出的是空,后者取出的是正确的值)
map1[item.id]和map1.get(item.id)的区别为何前者取出的是空,后者取出的是正确的值
在 JavaScript 中,map1[item.id] 和 map1.get(item.id) 用于从 Map 对象中获取值,但它们的工作方式有所不同: map1[item.id]:这种方式用于普通对象(Object),它将 item.id 作为键来获取对应的值…...

window端sqlplus连接linux_oracle11g
1. 环境配置回顾 下载 Oracle Instant Client:根据查询到的版本到链接: oracle官网下载对应版本的三个文件(比如我这里查询到的版本是12.2.0.1.0): instantclient-basic-windows.x64-12.2.0.1.0.zip instantclient-sqlplus-win…...

FLUX.小红书极致真实V2企业案例:连锁茶饮品牌月产2000+新品宣传图
FLUX.小红书极致真实V2企业案例:连锁茶饮品牌月产2000新品宣传图 1. 项目背景与价值 在当今快消品行业,视觉营销已经成为品牌竞争的关键战场。对于连锁茶饮品牌而言,每个月都需要推出多款新品,而每一款新品都需要配套的宣传图片…...

GME-Qwen2-VL-2B-Instruct参数详解:is_query=False与指令前缀修复逻辑全解析
GME-Qwen2-VL-2B-Instruct参数详解:is_queryFalse与指令前缀修复逻辑全解析 1. 项目背景与核心问题 在图文匹配任务中,我们经常需要判断一张图片与多个文本描述之间的匹配程度。GME-Qwen2-VL-2B-Instruct作为一个强大的多模态模型,本应在这…...

从0实现OnCall基于Python语言框架
Step01第一步做的事情,先把 Python 版 OnCall 的后端外壳搭起来。也就是说,先验证了一件最关键的事:这个项目能不能先以 Python 服务的形式真正跑起来,并且具备最基础的对外通信能力。只有这一步成立,后面接模型、接 R…...

从计算机组成原理角度看AI模型推理:春联生成的GPU算力消耗
从计算机组成原理角度看AI模型推理:春联生成的GPU算力消耗 春节临近,想用AI模型生成一副独一无二的春联,体验一下科技与传统文化的碰撞。你可能已经试过,输入几个关键词,几秒钟后一副对仗工整、寓意吉祥的春联就跃然屏…...

Formula-Editor:颠覆公式编辑体验的开源解决方案
Formula-Editor:颠覆公式编辑体验的开源解决方案 【免费下载链接】Formula-Editor 基于百度kityformula-editor的公式编辑器 项目地址: https://gitcode.com/gh_mirrors/fo/Formula-Editor Formula-Editor是一款基于百度kityformula-editor开发的开源公式编辑…...

TensorFlow-v2.15模型训练可视化:准确率曲线一目了然
TensorFlow-v2.15模型训练可视化:准确率曲线一目了然 1. 为什么需要训练可视化? 当你训练一个深度学习模型时,最让人焦虑的问题莫过于:"模型到底学得怎么样了?" 想象一下,你花了几个小时甚至几…...

cv_unet_image-colorization与ComfyUI工作流集成:可视化图像着色方案
cv_unet_image-colorization与ComfyUI工作流集成:可视化图像着色方案 你有没有遇到过这样的情况?手头有一张很棒的黑白线稿,或者一张充满年代感的老照片,你想给它上色,让它焕发新生。传统的做法是打开专业的图像处理软…...

避坑指南:Xilinx ZYNQ Ultrascale+ MPSoC DP转HDMI线材选择与电视兼容性实测
Xilinx ZYNQ Ultrascale MPSoC DP转HDMI实战:线材选择与电视兼容性深度解析 当你在实验室里调试ZYNQ MPSoC的DisplayPort输出时,最令人抓狂的瞬间莫过于:代码和硬件配置都完美,却因为一根转接线导致屏幕一片漆黑。这不是假设——根…...

效率倍增:基于快马AI构建chromedriver自动更新与团队分发管理工具
最近团队里做Web自动化测试的小伙伴们经常抱怨,说Chrome浏览器一更新,对应的chromedriver就得跟着换,手动去官网找、下载、再分发给组里每个人的测试机,一套流程下来,小半天就没了。尤其是项目赶进度的时候,…...

Harmonyos应用实例113:圆锥体积实验室
应用实例三:圆锥体积实验室 知识点:理解圆锥体积是等底等高圆柱体积的三分之一。 功能:提供一个“倒沙子”模拟实验。学生有一个装满“沙子”的圆柱容器,点击“倒沙”按钮,沙子会以动画形式倒入一个等底等高的圆锥容器中。需要倒3次才能倒满圆锥,直观验证 V锥=13V柱V_{锥…...